首次超越扩散模型和非自回归Transformer模型!字节开源RAR:自回归生成最新SOTA!

文章链接:https://arxiv.org/pdf/2411.00776
项目链接:https://yucornetto.github.io/projects/rar.html
代码&模型链接:https://github.com/bytedance/1d-tokenizer
亮点直击
RAR(随机排列自回归训练策略),这是一种改进的训练策略,使得标准的自回归图像生成器能够实现SOTA性能。
引入双向上下文学习:RAR通过最大化所有可能的分解顺序的期望似然值,打破了自回归模型在视觉任务中的单向上下文限制,使模型能够在图像生成中更有效地利用双向上下文信息。
保持与语言建模框架的兼容性:RAR在提升图像生成性能的同时,保留了自回归建模的核心结构,它与大语言模型(LLM)的优化技术(如KV-cache)完全兼容,相比于MAR-H或MaskBit,采样速度显著更快,同时保持了更好的性能,便于在多模态统一模型中应用。
创新的退火训练策略:训练初期将输入序列随机排列,随着训练逐步回归至标准光栅顺序。这一过程使模型在各类上下文排列中均能获得优化,提升生成质量。
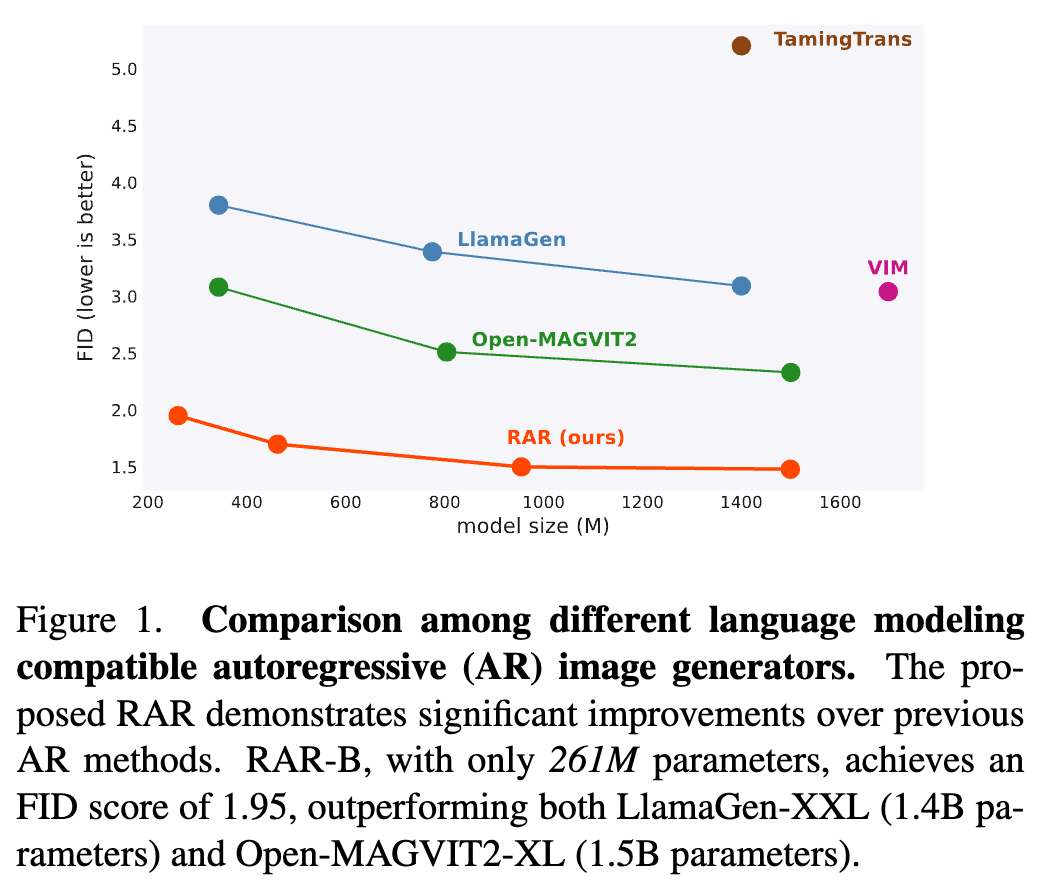
显著的性能提升:在 ImageNet-256 基准测试中,RAR实现了1.48的 FID 分数,显著超越了先前的自回归图像生成器,显示了其在图像生成任务中的突破性改进。
总结速览
解决的问题:
RAR(随机自回归建模)旨在提升图像生成任务的表现,同时保持与语言建模框架的完全兼容性。
提出的方案:
RAR采用了一种简单的方法,通过标准的自回归训练过程并结合下一个 token 预测目标,将输入序列随机打乱到不同的分解顺序。在训练过程中,使用概率 r 将输入序列的排列顺序随机化,其中 r 从 1 开始并逐渐线性衰减至 0,以让模型学习所有分解顺序的期望似然值。
应用的技术:
RAR在训练中应用了一种退火策略,使模型能够更好地利用双向上下文信息来建模,同时仍然保持自回归建模框架的完整性,从而实现了语言建模的完全兼容性。
达到的效果:
在 ImageNet-256 基准测试中,RAR 获得了 1.48 的 FID 分数,超越了之前最先进的自回归图像生成器,并优于领先的基于扩散和掩码Transformer的方法。
方法
背景
简要概述了基于下一个 token 预测目标的自回归建模。给定一个离散的 token 序列 ,自回归建模的目标是通过正向自回归分解来最大化该序列的似然。具体而言,目标是最大化在给定所有先前 tokens 的情况下预测当前 token 的联合概率
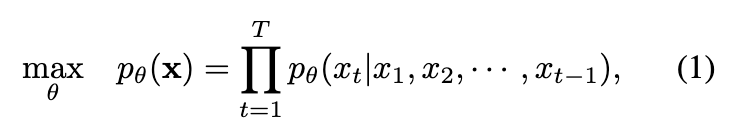
在自回归建模中,模型参数 定义了一个 token 分布预测器 ,用于预测给定位置的 token 分布。
由于在自回归模型中每个位置 t 的 token 仅依赖于之前的 tokens,这限制了模型只能进行单向的上下文建模。与此不同的是,masked transformer和扩散模型能够在训练时利用双向上下文。此外,尽管自然语言有固有的顺序(例如大多数语言从左到右),图像数据却缺乏固定的处理顺序。在图像生成任务中,行优先顺序(即光栅扫描)被广泛采用,并显示出优于其他替代方法的效果。

RAR: 随机自回归建模
视觉信号天然存在双向关联,因此全局上下文建模在视觉任务中至关重要。然而,传统的自回归模型依赖因果注意力掩码,仅允许 token 序列呈单向依赖,这与视觉数据的双向关联性不符。已有研究表明,对于视觉模态,双向注意力显著优于因果注意力。
此外,图像 token 排列成因果序列时没有统一的“正确”方式,常用的光栅扫描顺序虽有效果,但在训练过程中引入了偏差,因为每个 token 仅依赖于扫描顺序中的前序 token,限制了模型学习来自其他方向的依赖关系。
为了解决这些问题,本文提出了一种随机自回归建模方法,将双向上下文的优化目标纳入自回归建模。
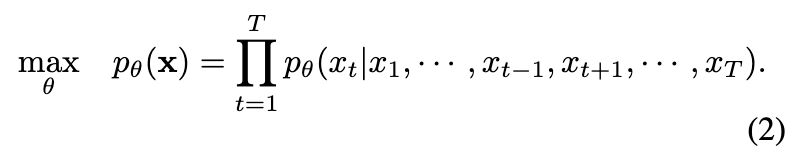
与 BERT 风格 或 MaskGIT 风格方法不同,本文的方法采用了置换目标的方法,在所有可能的分解顺序上以自回归方式训练模型。这使得模型在保持自回归框架的同时,能够在期望上收集双向上下文信息。公式表示如下:
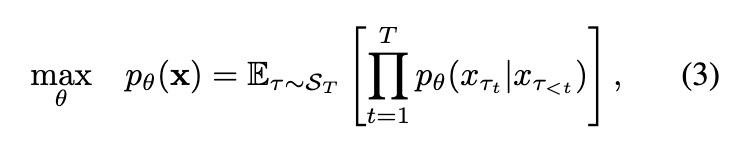
其中, 表示所有可能的索引序列 的置换集合, 代表从 中随机采样的一个置换。符号 指的是置换序列中的第 t 个元素,而 表示在 之前的所有位置。由于模型参数 在所有采样的分解顺序上是共享的,每个 token 在训练过程中会接触到每一个可能的上下文,从而学习与其他所有 token 的关系。这种方法使模型能够在保持自回归结构完整性的同时有效捕捉双向上下文信息。
虽然方法简单,但这种修改显著提升了图像生成性能,突显了双向上下文在提升自回归图像生成器能力方面的重要性。与自然语言处理 (NLP) 中的自回归训练观察结果一致。
讨论:尽管置换目标允许在自回归框架中实现双向上下文学习,但在生成过程中完全捕获“全局上下文”仍具挑战性。这是因为在生成过程中,总会有一些 tokens 在其他 tokens 之前生成,无法完全利用全局上下文。这种限制不仅存在于自回归方法中,也存在于非自回归模型中。重新采样或精炼等技术可能有助于确保每个 token 都能在充分的上下文下生成。然而,这些设计可能会增加系统的复杂性,因此探索这些解决方案超出了本文的范围,留待未来研究。
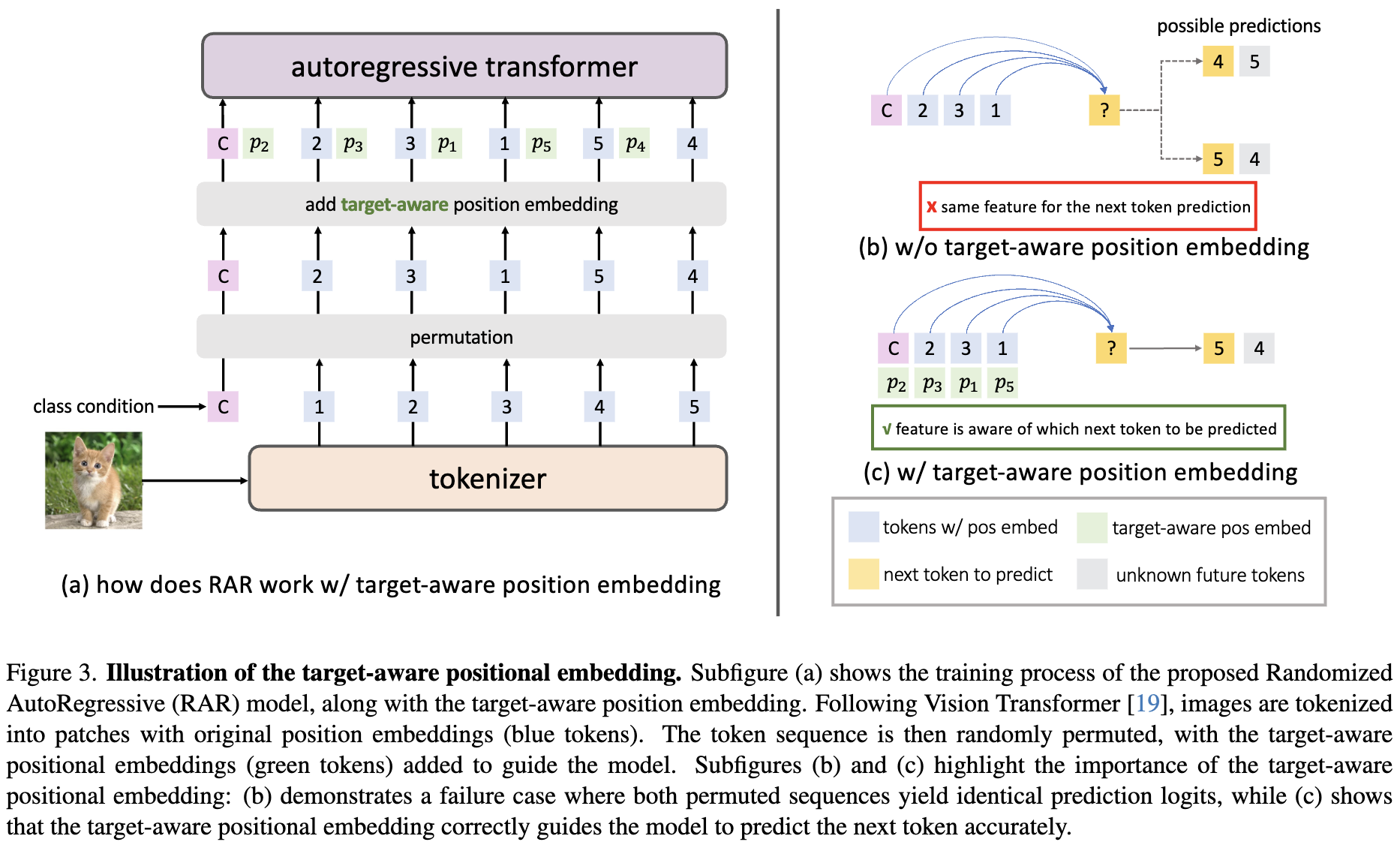
目标感知位置嵌入:置换训练目标的一个限制在于,标准的位置嵌入在某些场景下可能会失效。例如,考虑两个不同的置换: 和 (即仅最后两个 tokens 的位置交换)。当预测倒数第二个 token 时,这两个置换会产生相同的特征,从而生成相同的预测 logits,即使它们对应不同的真实标签(即 对于置换 和 相同)。在一般的随机自回归训练过程中,除最后一个 token 外,这个问题可能发生在所有 token 位置上(因为最后一个 token 不需要预测下一个 token)。为了解决这个问题,本文引入了一组额外的位置嵌入,称为目标感知位置嵌入。这些嵌入编码了关于下一个要预测的 token 的信息。
形式上,定义了一组目标感知位置嵌入 。与下一个 token 对应的位置嵌入会被添加到当前 token 嵌入中,形成目标感知的 token 嵌入 :
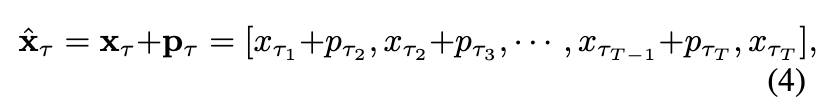
其中, 和 分别是与置换 对应的置换后的 token x 和目标感知位置嵌入 。通过将目标 token 的位置嵌入与下一个 token 的预测关联起来,每个 token 的预测都能意识到目标 token 的索引,从而缓解了置换目标带来的潜在混淆。值得注意的是,对于最后一个 token ,省略了目标感知位置嵌入,因为它不参与损失计算且没有预测目标。此概念的可视化说明见下图 3。此外,目标感知位置嵌入在训练结束后可以与原始位置嵌入合并,因为本文的方法在最终会退火到固定的行优先扫描,从而在推理时不会增加参数或计算量。
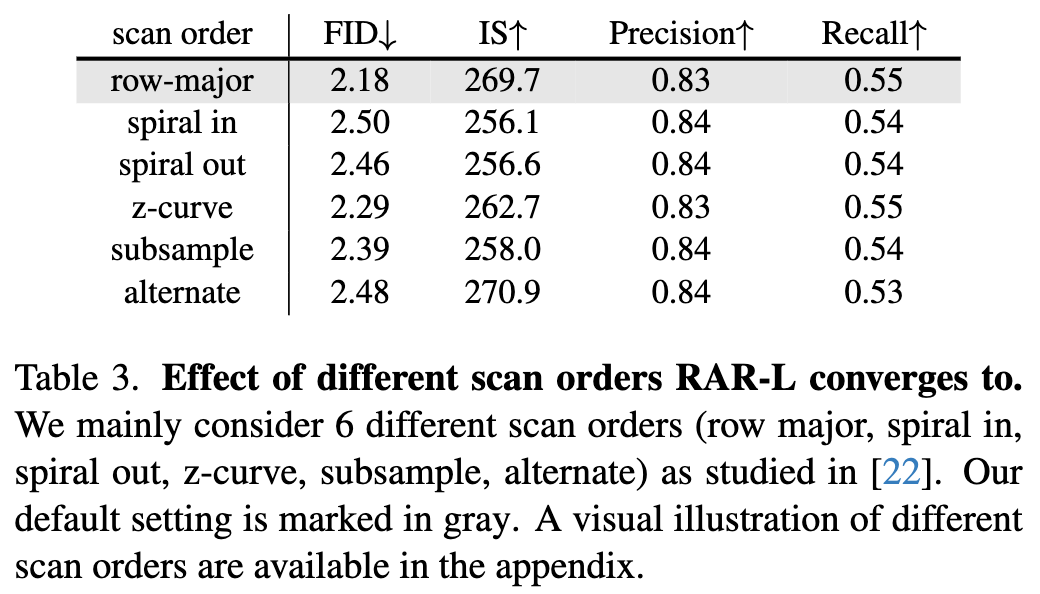
随机退火:虽然通过置换的随机自回归训练使模型能够在单向框架中捕获双向上下文,但它可能会因两个主要因素而引入次优的视觉生成行为:(1) 可能的置换数量极多,可能导致模型过于关注如何处理不同的置换顺序,而不是提高生成质量。例如,对于长度为 256 的 token 序列,可能的置换数为 (256! > 10^{506}),这会让模型不堪重负,降低训练效率。(2) 尽管图像可以按任意顺序处理,某些扫描顺序往往优于其他顺序。例如,[22] 评估了六种不同的扫描顺序(行优先、向内螺旋、向外螺旋、Z 曲线、子采样和交替顺序),并发现行优先(即栅格顺序)始终表现最佳,这使其成为视觉生成中最广泛使用的顺序。
为了解决这些问题,本文提出了随机退火策略,以平衡置换的随机性与行优先顺序的已知效果。此方法引入了一个控制随机置换和行优先顺序使用概率的单一参数 r。在训练开始时,r = 1,意味着模型完全使用随机置换。随着训练的进行,r 线性衰减至 0,逐步将模型转换为行优先顺序。具体而言,定义了r 的训练调度,由两个超参数 start 和 end 控制,分别表示 r 开始退火和退火结束的训练轮次。公式如下:

其中,epoch 表示当前的训练轮次。在实验中,我们将对超参数 start 和 end 进行消融实验。该调度策略允许模型在初期探索多种随机置换,以更好地学习双向表示,最终收敛到更有效的行优先扫描顺序,从而提升视觉生成质量,类似于其他典型的自回归方法。值得注意的是,该策略不仅提升了生成性能,还保持了与先前工作中使用的标准扫描顺序的兼容性。
实验结果
本节首先介绍方法的实现细节。接这展示了关于关键设计选择的消融研究。再讨论了主要结果,最后还包括了缩放研究和可视化内容。
实现细节
本文在语言建模自回归框架的基础上实现了RAR方法,做了最小的改动。
VQ分词器:采用了与先前工作 [10, 22] 相似的VQ分词器,将输入图像转换为离散的token 序列。我们使用的是基于CNN的MaskGIT-VQGAN [10] 分词器,使用在ImageNet上训练的官方权重。该分词器将256 × 256的图像转化为256个离散的token (下采样因子为16),并且字典大小(即词汇表大小)为1024。
自回归Transformer:本文使用不同配置的视觉Transformer(ViT),包括RAR-S(133M)、RAR-B(261M)、RAR-L(461M)、RAR-XL(955M)和RAR-XXL(1499M)。对于所有这些模型变体,我们在自注意力模块中应用了因果注意力掩码,并使用QK层归一化来稳定大规模模型的训练。为了加速实验,在消融研究中使用了普通的ViT,而在最终模型中增强了AdaLN 。架构配置和模型大小可以在下表1中找到。
位置嵌入:本文为ViT中的原始位置嵌入和目标感知位置嵌入使用了可学习的嵌入。值得注意的是,由于我们的模型在训练结束后会退火到基于栅格顺序的自回归图像生成,最终这两种位置嵌入可以合并为一个,使得最终模型与传统的自回归图像生成器相同。
数据集:研究者们在ImageNet-1K训练集上训练我们的模型,该数据集包含128,1167张图像,涵盖1000个物体类别。我们使用MaskGIT-VQGAN分词器对整个训练集进行预分词,以加速训练。对于消融研究,仅使用中心裁剪和水平翻转数据增强进行预分词,而对于最终模型,使用了十裁剪变换来增强数据集的多样性。
训练协议:研究者们所有模型变体使用相同的训练超参数。模型使用批量大小2048训练400个epoch(250k步)。在前100个epoch(热身阶段)内,学习率从0线性增加到4 × 10⁻⁴,然后按照余弦衰减计划逐渐衰减至1 × 10⁻⁵。使用AdamW优化器,其中beta1为0.9,beta2为0.96,权重衰减为0.03。我们对梯度进行了裁剪,最大梯度范数为1.0。在训练过程中,类别条件会以0.1的概率被丢弃。消融研究和主要结果中所有RAR模型变体的训练设置保持一致。
采样协议:本文使用[18]的评估代码对50,000张图像进行FID计算。我们不使用任何基于top-k或top-p的过滤技术。还遵循先前的工作使用无分类器指导。在消融研究中,使用更简单的线性指导调度,而在最终模型中使用改进的幂余弦指导调度。
消融研究
本文研究了RAR的不同配置,包括随机退火策略和RAR最终收敛的扫描顺序。
随机退火策略:在下表2中,比较了不同的随机退火策略。采用了线性衰减的调度,并通过改变超参数 start 和 end 来研究何时应该开始和结束随机化退火,具体定义见公式(5)。对于持续400个epoch的训练,我们枚举了每100个epoch的所有可能组合。例如,当 start = 200 和 end = 300 时,模型在前200个epoch采用随机排列,在后100个epoch采用栅格顺序。在第200到300个epoch之间,模型通过以概率 r 进行随机排列,或者以概率 1−r 进行栅格顺序训练,其中 r 按照公式(5)计算。值得注意的是,当 start = end = 0 时,模型仅使用栅格顺序进行训练,即标准的自回归训练;当 start = end = 400 时,模型始终使用随机排列的输入序列进行训练。两种情况都是提出的随机退火方法的重要基准,分别达到了FID得分3.08和3.01。令人感兴趣的是,我们观察到所有其他变体都比这两个基准取得了显著的改进。例如,简单地将前100个epoch的栅格顺序替换为随机排列(即,start = 100 和 end = 100),就将FID得分提高到了2.48,提升了0.6。此外,模型倾向于保留一些初期的epoch进行纯随机排列训练,并且在最后一些epoch更好地适应栅格顺序,这通常比其他变体表现更好。所有结果表明,通过引入带有排列目标的随机化自回归训练,有助于自回归视觉生成器的性能,并提升FID得分,这得益于改进的双向表示学习过程。
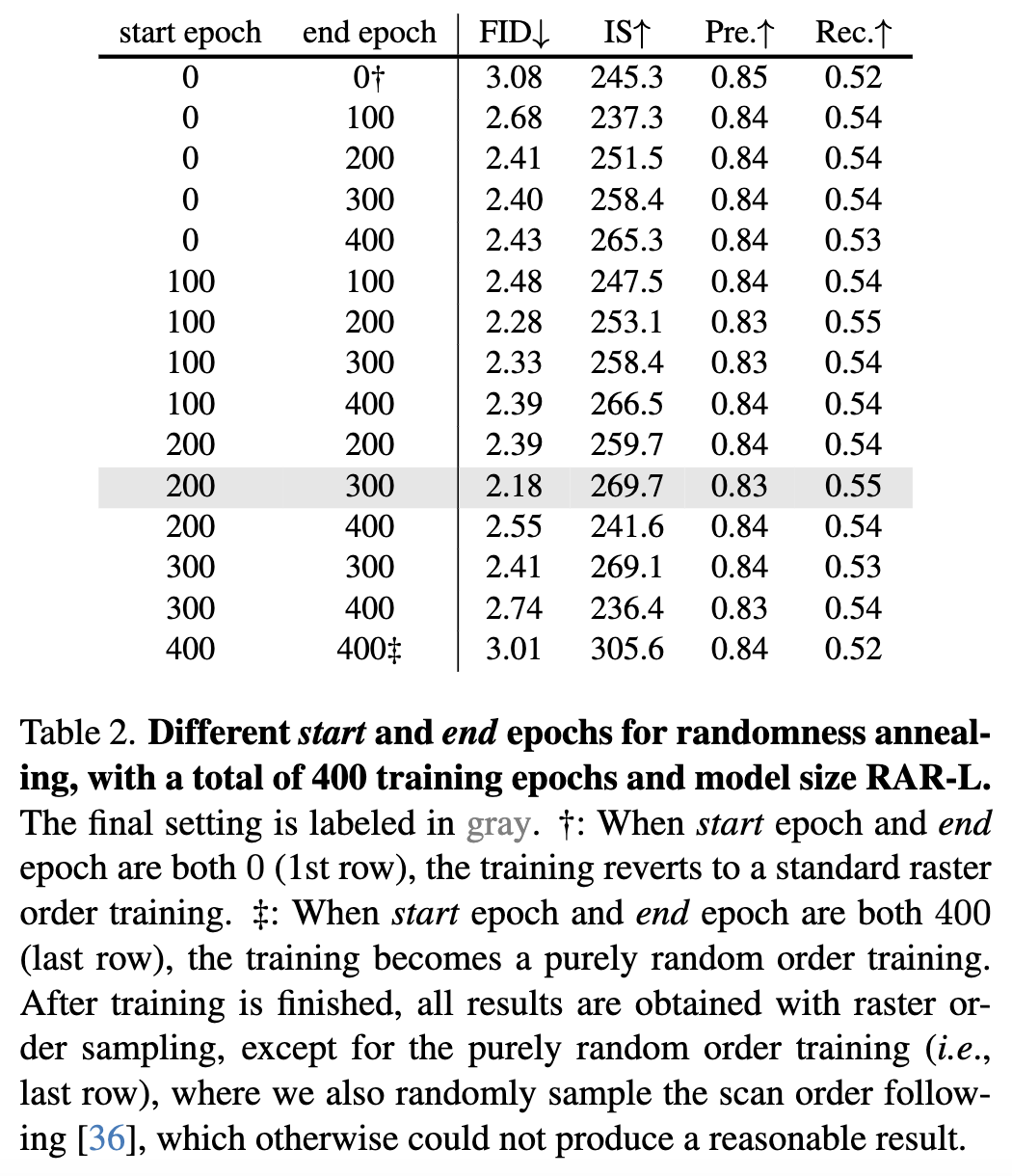
此外,在所有变体中,发现当 start = 200 和 end = 300 时表现最佳,将基准(纯栅格顺序)的FID从3.08提高到2.18。该策略将稍多的计算分配给随机排列顺序的训练,并将最后100个epoch专注于纯栅格顺序。因此,我们默认采用这种退火策略用于所有RAR模型。
不同的扫描顺序(除了栅格顺序):尽管行主序(即栅格扫描)一直是视觉生成中事实上的扫描顺序,但缺乏系统的研究来比较它与其他扫描顺序的优劣。我们注意到,四年前的工作 [22] 进行了类似的研究。然而,考虑到近年来生成模型取得的显著进展,值得重新审视这一结论。具体来说,我们考虑了6种不同的扫描顺序(行主序、螺旋内、螺旋外、Z曲线、子采样和替代扫描顺序),这些扫描顺序是RAR可能最终收敛的目标。本文没有像那样报告训练损失和验证损失作为对比指标,而是直接评估它们的生成性能。结果总结在下表3中。有趣的是,我们观察到所有变体的得分都相当不错,这表明RAR能够处理不同的扫描顺序。考虑到行主序(栅格扫描)仍然在其他扫描顺序中表现出优势,我们因此为所有最终RAR模型使用栅格扫描顺序。
主要结果
本文报告了RAR与最先进的图像生成器在ImageNet-1K 256×256基准测试上的结果。
如下表4所示,RAR相较于之前的AR图像生成器表现出了显著更好的性能。具体来说,最紧凑的RAR-B(仅有261M参数)就达到了FID得分1.95,已经显著超越了当前最先进的AR图像生成器LlamaGen-3B-384(3.1B,FID 2.18,裁剪尺寸384)和 Open-MAGVIT2-XL(1.5B,FID 2.33),并且分别减少了91%和81%的模型参数。它还超越了广泛使用的扩散模型,例如DiT-XL/2(FID 1.95 vs. 2.27)和SiT-XL(FID 1.95 vs. 2.06),并且仅使用了相对于这些模型的39%的参数。
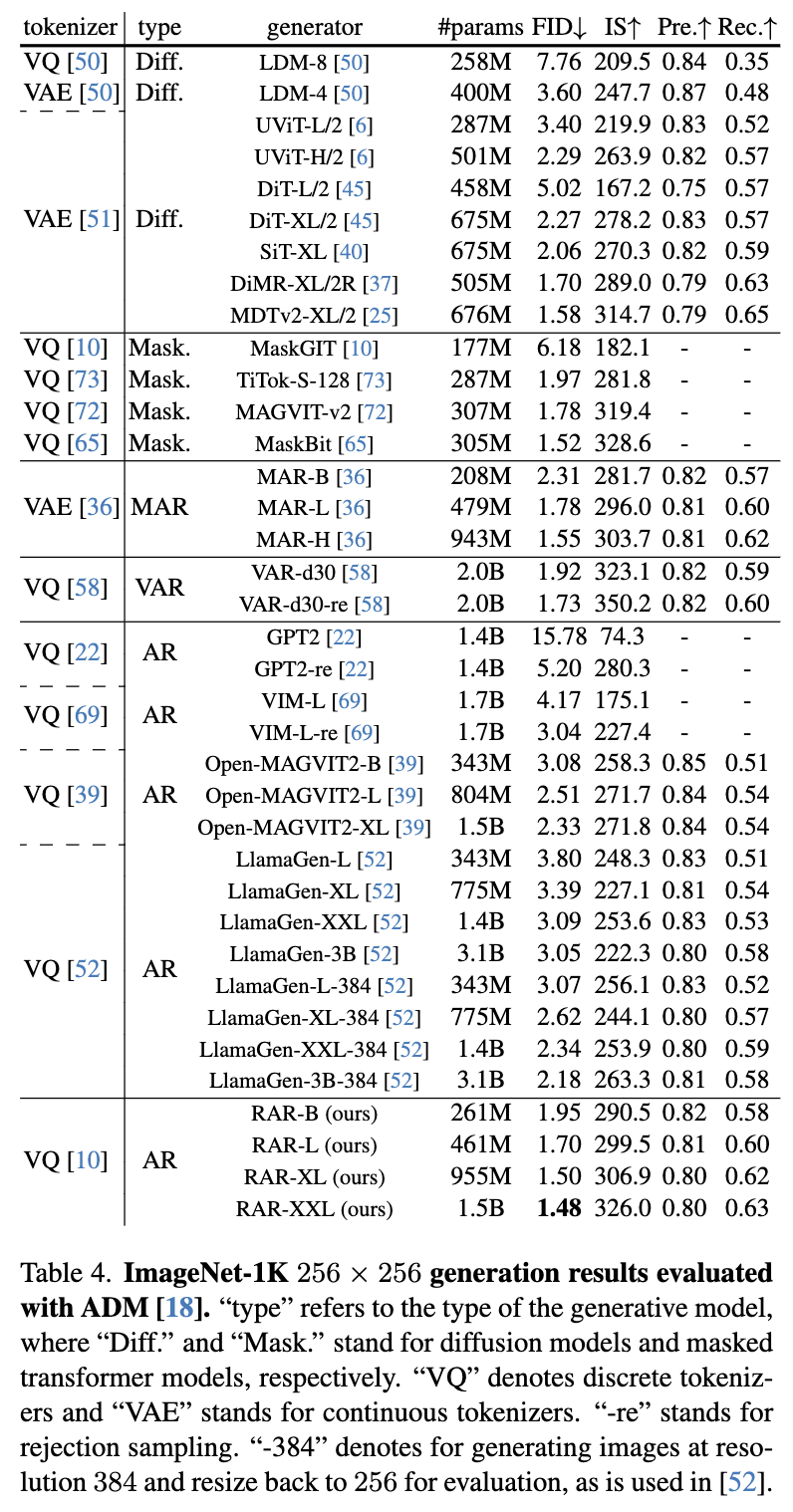
在表4中,进一步探讨了不同模型尺寸下的RAR(从261M到1.5B),我们观察到RAR在不同尺寸下具有强大的可扩展性,并且随着模型尺寸的增大,性能不断提升。特别地,最大的变体RAR-XXL在ImageNet基准测试上创下了新的最先进结果,FID得分为1.48。与其他两种近期方法VAR和MAR相比,这两种方法都尝试通过改进AR公式来提升视觉生成质量,RAR不仅在性能上表现更优(RAR的FID为1.48,而VAR为1.73,MAR为1.55),而且保持了整个框架与语言建模的兼容性,因此更适合将成熟的优化和加速技术应用于大型语言模型,从而推动视觉生成的发展。
此外,RAR在不同框架中的表现超越了最先进的视觉生成器。它在对比领先的自回归模型、扩散模型和掩蔽Transformer模型时,表现得更好,分别超越了LlamaGen-3B-384、MDTv2-XL/2和 MaskBit(RAR的FID为1.48,相比之下LlamaGen为2.18,MDTv2为1.58,MaskBit为1.52)。据所知,这是首次语言建模风格的自回归视觉生成器超越最先进的扩散模型和掩蔽Transformer模型。
采样速度:自回归方法的一个关键优势是能够利用LLM中已建立的优化技术,如KV缓存。在表5中,我们将RAR与其他类型的生成模型进行采样速度比较(以每秒生成图像数为衡量标准),包括扩散模型、masked transformer器、VAR和 MAR。其中,自回归模型(RAR)和VAR模型(VAR-d30)与KV缓存优化兼容,因此在生成速度上显著优于其他方法。如表5所示,RAR不仅在FID得分上达到了最先进的水平,同时在生成速度上也大大超越了其他方法。例如,在FID得分约为1.5时,MaskBit和 MAR-H的生成速度分别为每秒0.7和0.3张图像。相比之下,RAR-XL不仅获得了更好的FID得分,还能每秒生成8.3张高质量视觉样本——比MaskBit快11.9倍,比MAR-H快27.7倍。最大的RAR变体RAR-XXL进一步提高了FID得分,同时保持了显著的速度优势,速度是MaskBit的9.1倍,是MAR-H的21.3倍。此外,RAR可能进一步受益于LLM优化技术,例如vLLM,这一点与其他AR方法一致。
扩展性行为
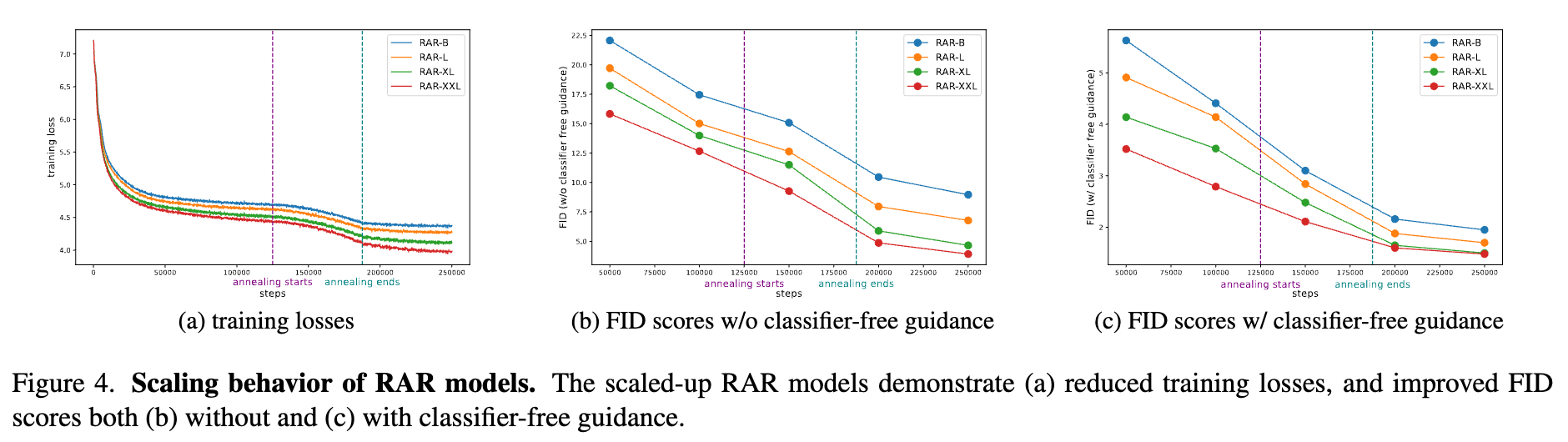
本文研究了RAR的扩展性行为。具体来说,我们绘制了训练损失曲线和FID得分曲线(有无无分类器引导的情况)如下图4所示。如图所示,我们观察到RAR在不同模型尺寸下均表现出良好的扩展性,较大的模型尺寸在训练损失和FID得分上持续表现出较好的性能,无论是否使用无分类器引导增强。我们注意到,由于RAR保持了AR公式和框架的完整性,它也继承了AR方法的可扩展性。
可视化
在下图5中可视化了不同RAR变体生成的样本,结果表明RAR能够生成高质量、具有高度保真度和多样性的样本。更多可视化结果见附录。

结论
本文提出了一种简单而有效的策略,以增强与语言建模兼容的自回归图像生成器的视觉生成质量。通过采用随机化排列目标,本文的方法在保持自回归结构的同时,改善了双向上下文学习。因此,所提出的RAR模型不仅超越了以前的最先进自回归图像生成模型,还超过了领先的非自回归Transformer和扩散模型。希望本研究有助于推动自回归Transformer朝着视觉理解与生成统一框架的方向发展。
参考文献
[1] Randomized Autoregressive Visual Generation
相关文章:
首次超越扩散模型和非自回归Transformer模型!字节开源RAR:自回归生成最新SOTA!
文章链接:https://arxiv.org/pdf/2411.00776 项目链接:https://yucornetto.github.io/projects/rar.html 代码&模型链接:https://github.com/bytedance/1d-tokenizer 亮点直击 RAR(随机排列自回归训练策略)&#x…...
)
C语言最简单的扫雷实现(解析加原码)
头文件 #define ROW 9 #define COL 9 #define ROWS ROW2 #define COLS COL2 #include <stdio.h> #include <stdlib.h> #include <time.h> #define numlei 10do while可以循环玩 两个板子,内板子放0,外板子放* set函数初始化两个板子 …...

20. 类模板
一、什么是类模板 类模板用于建立一个通用类,类中的成员数据类型可以不具体指定,用一个虚拟的类型来代替。它的语法格式如下: template<typename T>类模板与函数模板相比主要有两点区别:1) 类模板没有自动类型推导的方式。…...

SSL证书以及实现HTTP反向代理
注意: 本文内容于 2024-11-09 19:20:07 创建,可能不会在此平台上进行更新。如果您希望查看最新版本或更多相关内容,请访问原文地址:SSL证书以及实现HTTP反向代理。感谢您的关注与支持! 之前写的HTTP反向代理工具&…...

多种算法解决组合优化问题平台
🏡作者主页:点击! 🤖编程探索专栏:点击! ⏰️创作时间:2024年11月11日7点12分 点击开启你的论文编程之旅https://www.aspiringcode.com/content?id17302099790265&uidef7618fa204346ff9…...
【笔记】LLC电路工作频点选择 2-1 输出稳定性的限制
LLC工作模式的分析参考了:现代电力电子学,电力出版社,李永东 1.LLC电路可以选择VCS也可以选择ZVS 1.1选择ZCS时,开关管与谐振电感串联后,与谐振电容并联: 1.2选择ZVS时,开关管仅仅安装在谐振电…...

Linux系统程序设计--2. 文件I/O
文件I/O 标准C的I/O FILE结构体 下面只列出了5个成员 可以观察到,有些函数没有FILE类型的结构体指针例如printf主要是一些标准输出,因为其内部用到了stdin,stdout,stderr查找文件所在的位置:find \ -name stat.h查找头文件所…...
)
右值引用——C++11新特性(一)
目录 一、右值引用与移动语义 1.左值引用与右值引用 2.移动构造和移动赋值 二、引用折叠 三、完美转发 一、右值引用与移动语义 1.左值引用与右值引用 左值:可以取到地址的值,比如一些变量名,指针等。右值:不能取到地址的值…...

JavaScript 观察者设计模式
观察者模式:观察者模式(Observer mode)指的是函数自动观察数据对象,一旦对象有变化,函数就会自动执行。而js中最常见的观察者模式就是事件触发机制。 ES5/ES6实现观察者模式(自定义事件) - 简书 先搭架子 要有一个对象ÿ…...

鸿蒙进阶篇-网格布局 Grid/GridItem(二)
hello大家好,这里是鸿蒙开天组,今天让我们来继续学习鸿蒙进阶篇-网格布局 Grid/GridItem,上一篇博文我们已经学习了固定行列、合并行列和设置滚动,这一篇我们将继续学习Grid的用法,实现翻页滚动、自定义滚动条样式&…...

数据仓库之 Atlas 血缘分析:揭示数据流奥秘
Atlas血缘分析在数据仓库中的实战案例 在数据仓库领域,数据血缘分析是一个重要的环节。血缘分析通过确定数据源之间的关系,以及数据在处理过程中的变化,帮助我们更好地理解数据生成的过程,提高数据的可靠性和准确性。在这篇文章中…...

AndroidStudio-滚动视图ScrollView
滚动视图 滚动视图有两种: 1.ScrollView,它是垂直方向的滚动视图;垂直方向滚动时,layout_width属性值设置为match_parent,layout_height属性值设置为wrap_content。 例如: (1)XML文件中: <?xml ve…...

嵌入式硬件实战基础篇(一)-STM32+DAC0832 可调信号发生器-产生方波-三角波-正弦波
引言:本内容主要用作于学习巩固嵌入式硬件内容知识,用于想提升下述能力,针对学习STM32与DAC0832产生波形以及波形转换,对于硬件的降压和对于前面硬件篇的实际运用,针对仿真的使用,具体如下: 设…...

ElasticSearch的Python Client测试
一、Python环境准备 1、下载Python安装包并安装 https://www.python.org/ftp/python/3.13.0/python-3.13.0-amd64.exe 2、安装 SDK 参考ES官方文档: https://www.elastic.co/guide/en/elasticsearch/client/index.html python -m pip install elasticsearch一、Client 代…...

【eNSP】企业网络架构链路聚合、数据抓包、远程连接访问实验(二)
一、实验目的 网络分段与VLAN划分: 通过实验了解如何将一个大网络划分为多个小的子网(VLAN),以提高网络性能和安全性。 VLAN间路由: 学习如何配置VLAN间的路由,使不同VLAN之间能够通信。 网络设备配置&am…...

独立站 API 接口的性能优化策略
一、缓存策略* 数据缓存机制 内存缓存:利用内存缓存系统(如 Redis 或 Memcached)来存储频繁访问的数据。例如,对于商品信息 API,如果某些热门商品的详情(如价格、库存、基本描述等)被大量请求…...

不一样的CSS(一)
目录 前言: 一、规则图形 1.介绍: 2.正方形与长方形(实心与空心) 2.1正方形: 2.2长方形 3.圆形与椭圆形(空心与实心) 3.1圆形与椭圆形 4.不同方向的三角形 4.1原理 4.2边框属性 5.四…...

题目:Wangzyy的卡牌游戏
登录 - XYOJ 思路: 使用动态规划,设dp[n]表示当前数字之和模三等于0的组合数。 状态转移方程:因为是模三,所以和的可能就只有0、1、2。等号右边的f和dp都表示当前一轮模三等于k的组合数。以第一行为例:等号右边表示 j转…...

国外云服务器高防多少钱一年?
国外云服务器高防多少钱一年?入门级高防云主机:这类主机通常具有较低的防御峰值,如30G或60G,价格相对较低。例如,30G峰值防御的高防云主机年费可能在2490元左右,而60G峰值防御的则可能在5044元左右。中等防…...
架构篇(04理解架构的演进)
目录 学习前言 一、架构演进 1. 初始阶段的网站架构 2. 应用服务和数据服务分离 3. 使用缓存改善网站性能 4. 使用应用服务器集群改善网站的并发处理能力 5. 数据库读写分离 6. 使用反向代理和CDN加上网站相应 7. 使用分布式文件系统和分布式数据库系统 8. 使用NoSQL和…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...