深入解析 Transformers 框架(四):Qwen2.5/GPT 分词流程与 BPE 分词算法技术细节详解
前面我们已经通过三篇文章,详细介绍了 Qwen2.5 大语言模型在 Transformers 框架中的技术细节,包括包和对象加载、模型初始化和分词器技术细节:
- 深入解析 Transformers 框架(一):包和对象加载中的设计巧思与实用技巧
- 深入解析 Transformers 框架(二):AutoModel 初始化及 Qwen2.5 模型加载全流程
- 深入解析 Transformers 框架(三):Qwen2.5 大模型的 AutoTokenizer 技术细节
在第 3 篇文章中,我们简要介绍了 Qwen2.5 使用的 Byte Pair Encoding (BPE) 分词算法,并用英文序列 “Hello World.” 举例说明了分词过程。然而,这只是 BPE 分词的一部分内容。今天,我们将继续深入探讨 Qwen2.5 的分词流程,重点介绍 Qwen2.5 如何处理中英文混合的文本序列,并解析 BPE 分词算法的具体实现。
一、中英文分词示例与初步分析
为深入理解 Qwen2.5 的分词过程,我们以一段中英文混合的文本序列“Transformers分词:台风又双叒叕来了!”为例进行剖析。以下是相关的代码示例:
import osfrom transformers import AutoTokenizer# 初始化分词器,从本地文件加载模型
model_dir = os.path.join('D:', os.path.sep, 'ModelSpace', 'Qwen2.5', 'Qwen2.5-1.5B-Instruct')
tokenizer = AutoTokenizer.from_pretrained(model_dir,local_files_only=True,
)text = 'Transformers分词:台风又双叒叕来了!'
tokens = tokenizer.tokenize(text)print(tokens)# 输出:['Transform', 'ers', 'åĪĨ', 'è¯į', 'ï¼ļ', 'åı°é£İ', 'åıĪ', 'åıĮ', 'åı', 'Ĵ', 'åıķ', 'æĿ¥äºĨ', 'ï¼ģ']ids = tokenizer.convert_tokens_to_ids(tokens)print(ids)# 输出:[8963, 388, 17177, 99689, 5122, 108118, 99518, 99493, 5758, 240, 122378, 101161, 6313]
我们先看看tokenizer.convert_tokens_to_ids()方法:它的实现比较简单,就是从词表中获取Token对应的ID;而词表其实就是一个字典,即vocab.json文件内容,每个 Token 都对应一个数字,即 Token ID。
如下随便挑选了上面结果几个 Token,在vocab.json文件中都可以找到他们的对应关系:
"Transform": 8963,
"åıķ": 122378,
"æĿ¥äºĨ": 101161,
第 1 个问题:为什么英文序列分词之后仍可以明确地识别出来,而中文分词之后看起来像是乱码呢?
实际上,这并非真正的乱码,而是字节 Byte 的 Unicode 字符表示。这也揭示了 BPE 算法的核心特性——基于 Byte 字节进行分词。无论是英文、中文,还是其他任何语言的字符序列,在计算机的存储与计算体系中,均以字节为基本单元进行处理。这一特性使得 BPE 算法具备了天然的通用性,能够跨越不同语言的界限,为大语言模型的多语言处理能力奠定了坚实基础。
二、Tokenize 分词流程详解
接下来,我们重点聚焦于tokenizer.tokenize()方法,深入探究其如何实现分词操作,其中 BPE 算法的具体实现过程尤为关键。通过对 Transformers 框架源代码的逐步解读,可以将其分词流程分解为以下几个关键步骤:
-
执行
PreTrainedTokenizer.tokenize()父类方法:在这一初始步骤中,借助 Python 内置的unicodedata.normalize()函数对输入的文本序列进行规范化处理。其主要目的在于消除因字符编码差异可能引发的后续处理问题,确保文本序列在字符编码层面的一致性与规范性。在当前示例中,由于输入的文本序列本身已经是规范化的文本,因此该步骤直接返回原文本序列,未进行实质性的修改操作。 -
处理特殊 Token:特殊 Token 在分词过程中具有特殊的处理方式,它们将直接作为分词结果的一部分被返回,无需经过复杂的分词逻辑处理。
-
执行
Qwen2Tokenizer._tokenize()方法:这一步骤构成了分词的核心逻辑部分,其中 BPE 算法将被实际应用于文本序列的分词操作。从该方法的注释Copied from transformers.models.gpt2.tokenization_gpt2.GPT2Tokenizer._tokenize可以清晰地看出,Qwen2.5 的分词逻辑实现,是复制GPT2的实现代码。
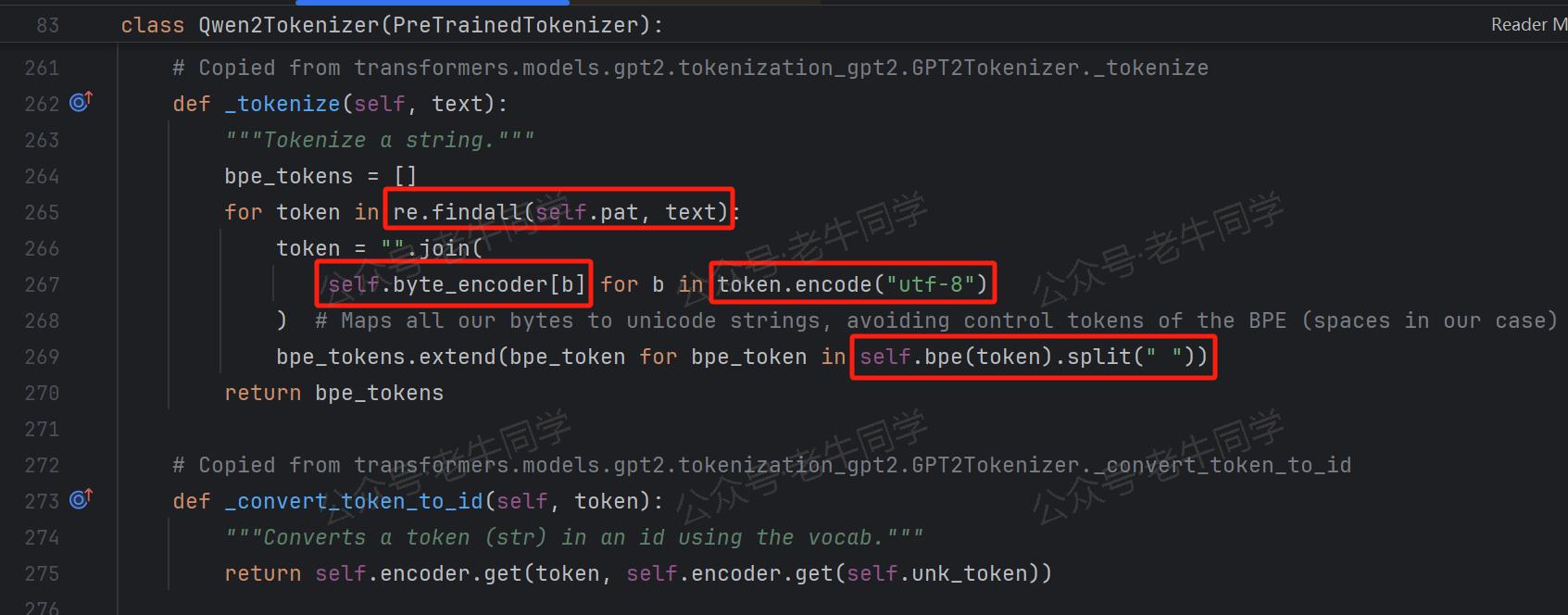
第一行代码:re.findall(self.pat, text) 通过正则表达式对文本序列进行初步分割:(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+,该正则表达式从基础语法层面进行初步分割,包括英文缩写词、字母数字、空白符和换行符等。
如,对于我们的输入序列Transformers分词:台风又双叒叕来了!,会被分割成[Transformers分词, :台风又双叒叕来了, !]三个文本片段。
第二行代码:token = "".join(self.byte_encoder[b] for b in token.encode("utf-8")) 对正则表达式分割的文本片段进行处理
-
首先,通过
token.encode("utf-8")方法编码为 UTF-8 格式的字节序列,对于 ASCII 字符(0-127)字符,UTF-8 编码与其相同,这也是为什么分词结果,英文单词我们可以明确识别出来;而对于中文等非 ASCII 字符(128 及以上),UTF-8 会编码使用 2 到 4 个字节,如果 BPE 按照字节分词的话,一个汉字会被拆分几个部分,因此看起来就像是乱码了。如:Transformers分词字节序列的 16 进展表示为Transformers\xe5\x88\x86\xe8\xaf\x8d。 -
然后,通过
self.byte_encoder[b]字典映射成字符,然后把每个 Byte 的字符表示拼接起来。
那么,self.byte_encoder字典又是如何实现的呢?
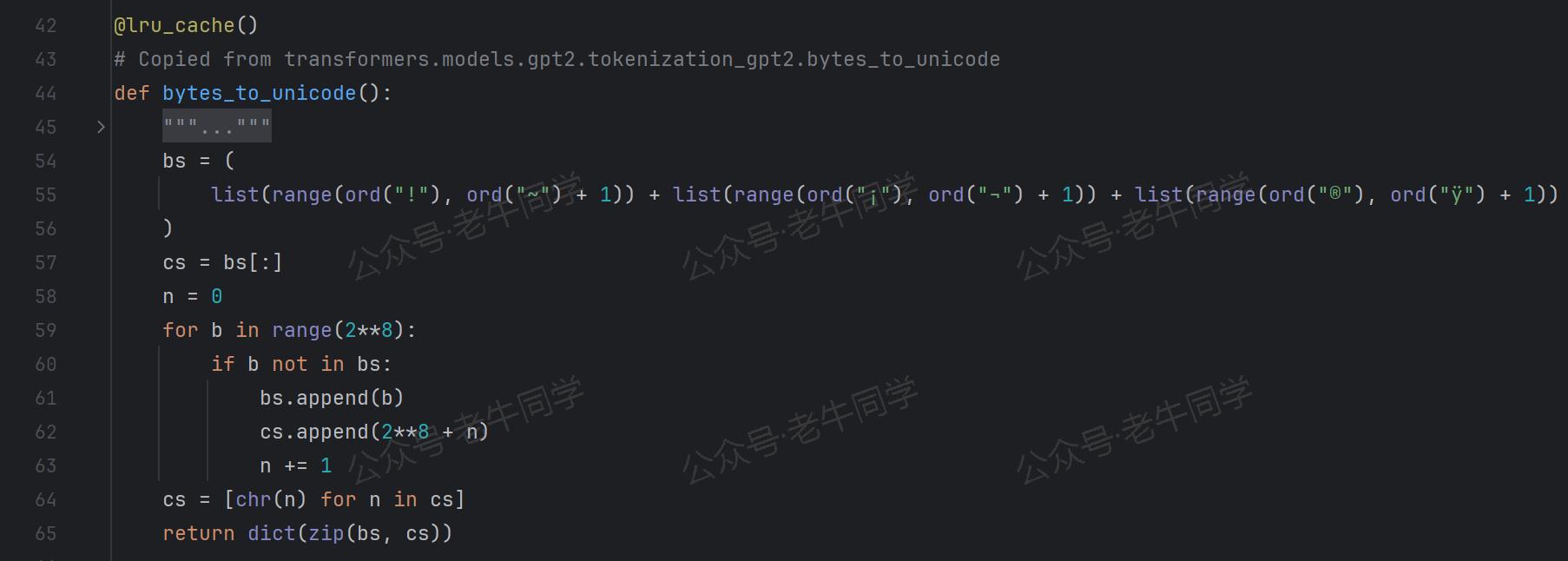
寥寥几行代码,Qwen2.5 继续复制GPT2的实现代码:
-
对于
!到~、¡到¬和®到ÿ这些可见字符,字典键就是这些字符,值为对应的 Byte 值。 -
对于其他的非可见字符(空白和控制字符),字典键为256+序号,值为对应的 Byte 值。
第 2 个问题:为什么可见字符和非可见字符需要分开处理?其实原因也比较好理解:因为 BPE 代码无法处理的空白和控制字符,所以需要特殊处理。
因此,第 2 行代码的结果是,通过正则表达式初步分割的序列片段,把他们的每个字节按照其对应的 Unicode 字符拼接起来了,这也是为什么最终结果看起来像乱码的原因了。
第三行代码:bpe_tokens.extend(bpe_token for bpe_token in self.bpe(token).split(" ")) 对于 Unicode 字符串,执行 BPE 算法,进行分词操作。
BPE 分词算法的核心逻辑,都在这个方法里面,下面老牛同学进行详细介绍!
三、BPE 分词算法核心逻辑解析
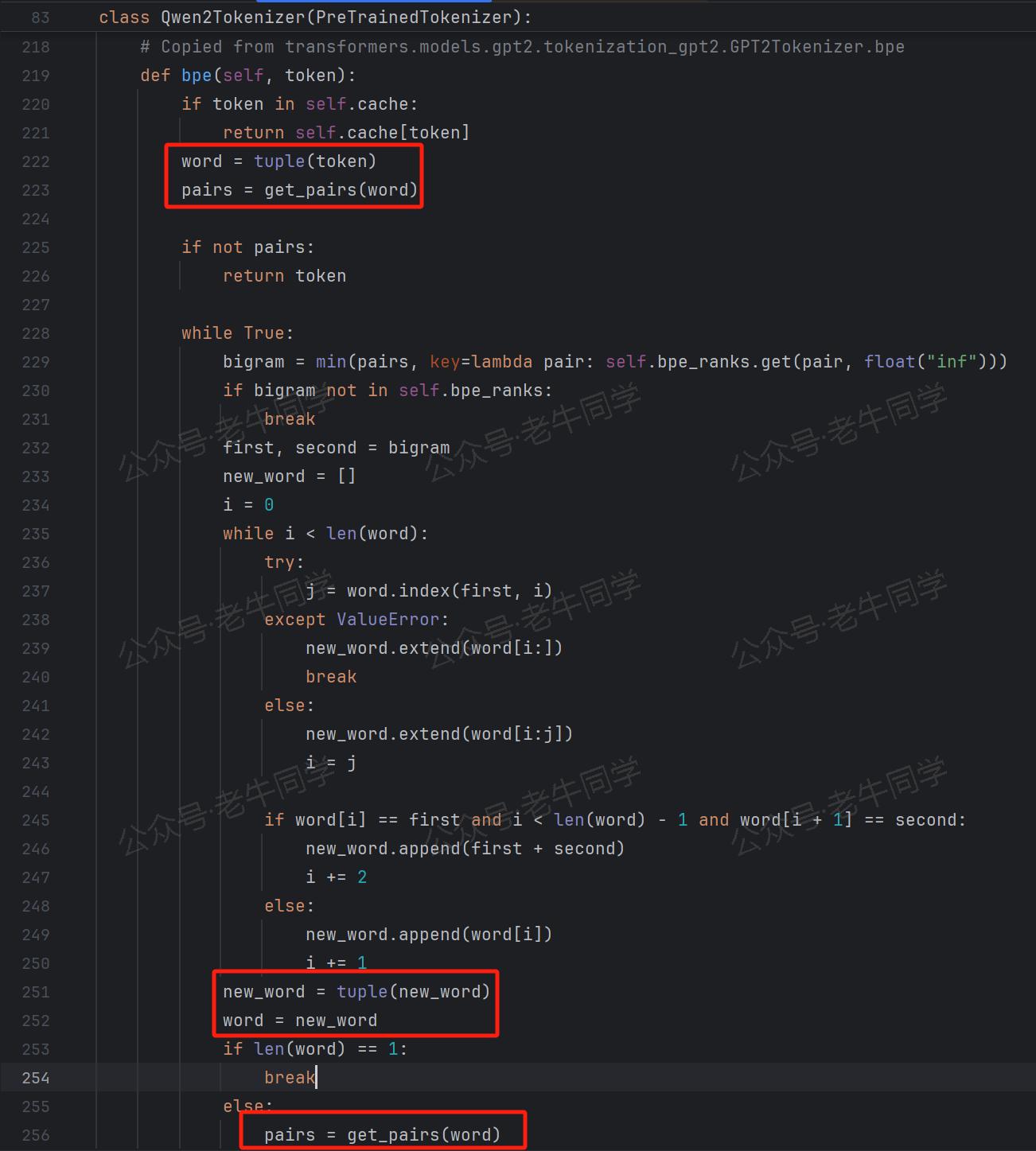
bpe()方法作为 BPE 分词算法的核心枢纽,其代码实现主要借鉴了 GPT2 的相关代码:
在深入探讨其核心代码之前,有必要对 BPE 算法的基本思想进行简要回顾(可参考本系列文章的第三篇:深入解析 Transformers 框架(三):Qwen2.5 大模型的 AutoTokenizer 技术细节)。
首先,算法会检查缓存中是否已经存在当前 Unicode 字符串的分词结果。若缓存命中,则直接返回缓存中的分词后的 Token 列表,从而避免重复计算,提高分词效率。
若缓存未命中,则进入以下核心逻辑处理流程:
-
第 1 行代码:
word = tuple(token):将输入的 Unicode 字符串拆分为单个 Unicode 字符的元组形式。这一操作将原始字符串打散为最基本的Unicode字符单元,为后续基于字符对的合并操作奠定了基础。 -
第 2 行代码:
pairs = get_pairs(word):该方法同样源自 GPT2 的代码实现,其功能是获取给定 Unicode 字符串中所有可能的字符对组合。例如,对于“ABCD”这样的 Unicode 字符串,其返回的结果将是[(A,B),(B,C),(C,D)],即包含了字符串中相邻两个字符组成的所有字符对。 -
第 3 行代码:
bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf")))对于pairsUnicode字符对集合中的每个元素,取bpe_ranks的最小值,如果不存在,则返回float("inf")无限大值。
那么,self.bpe_ranks又是什么呢?它也是一个字典,它的键是merges.txt文件内容去掉第 1 行版本号行后的每一行内容,值就是对应的行号。
也就是说,bigram的内容是pairs中的所有的 Unicode 字符对从merges.txt匹配到的最先出现的行号(即:最小值)。
第 3 个问题:为什么首先合并的 Unicode 字符对要取merges.txt文件中最小行号的字符对?
这需要我们理解merges.txt文件中存储的是什么内容:它存储的就是 GPT2/Qwen2.5 等大语言模型在预训练时,使用 BPE 算法进行分词时 Unicode 字符对的合并顺序。最小行号,意味着最先合并的 Unicode 字符对,也意味着出现频次最高的字符对。在我们推理时,保持同样的合并顺序,就可以保证合并结果和预训练时一致,同样保证了词表中有我们合并的Token!
BPE 算法在while True:循环中,持续进行字符对的合并操作:若在当前循环中成功合并了字符对,则将原有的单个 Unicode 字符对从待处理列表中移除,并将合并后的结果添加到待合并 Unicode 字符列表中。例如,对于初始字符列表:['T','r','a','n','s','f','o','r','m','e','r','s'],最小行号 Unicode 字符对是('e','r'),则在本次循环中会将“er”进行合并,下一轮循环时word的内容将更新为['T','r','a','n','s','f','o','r','m','er','s']。循环将持续进行,直到无法再找到可合并的字符对,或者所有字符对在merges.txt中均无法匹配到有效行号(即:bigram=float("inf"))时,循环终止,此时word中的内容即为最终的 Token 列表,代表了经过 BPE 算法分词后的结果。
至此,Qwen2.5 分词流程和 BPE 分词算法实现逻辑基本完成,下面进行简单总结。
总结:Qwen2.5 分词流程与 BPE 算法要点
Qwen2.5 的分词流程可以概括为以下几个关键步骤:
-
规范化预处理:对输入的文本序列运用规范化处理手段,消除因字符编码差异可能带来的干扰因素,确保文本序列在进入分词流程前的一致性与规范性。
-
正则表达式初步分割:借助精心设计的正则表达式,依据常见的语义和语法规则,将文本序列初步分割为多个片段序列,为后续的精细化分词操作提供基础框架。
-
BPE 算法分词:针对每个片段序列,运用 BPE 算法进行深度分词处理,将片段序列进一步分解为 Token 列表,从而完成整个文本序列的分词任务。
BPE 分词算法的核心要点包括:
-
文本序列转换:将输入的文本序列通过 UTF-8 编码转换为 Byte 字节序列,再将每个字节映射为 Unicode 字符,实现文本序列在字符表示层面的转换,为基于字节的分词操作提供基础数据格式。
-
预训练阶段字符对合并与记录:在 Qwen2.5/GPT2 等大模型的预训练阶段,对语料中的 Unicode 字符进行逐对分析与合并操作。按照字符对在语料中出现的频次高低,逐步合并出现频次最高的 Unicode 字符对,并将每次合并的字符对信息逐行记录到“merges.txt”文件中,形成预训练阶段的字符对合并顺序知识库。
-
推理阶段字符对匹配与合并:在模型推理阶段,将每个 Unicode 字符转换为字符对形式,然后依据“merges.txt”文件中的合并顺序信息,每次仅合并最小行号(即最先合并)的字符对,持续进行合并操作直至无法再进行合并为止。最终得到的合并结果即为分词后的 Token 列表,完成对输入文本序列的分词任务,并确保推理阶段的分词结果与预训练阶段保持高度一致,从而为大语言模型在多语言文本处理中的准确性与稳定性提供有力保障。
往期推荐文章:
基于 Qwen2.5-Coder 模型和 CrewAI 多智能体框架,实现智能编程系统的实战教程
vLLM CPU 和 GPU 模式署和推理 Qwen2 等大语言模型详细教程
基于 Qwen2/Lllama3 等大模型,部署团队私有化 RAG 知识库系统的详细教程(Docker+AnythingLLM)
使用 Llama3/Qwen2 等开源大模型,部署团队私有化 Code Copilot 和使用教程
基于 Qwen2 大模型微调技术详细教程(LoRA 参数高效微调和 SwanLab 可视化监控)
ChatTTS 长音频合成和本地部署 2 种方式,让你的“儿童绘本”发声的实战教程

相关文章:
深入解析 Transformers 框架(四):Qwen2.5/GPT 分词流程与 BPE 分词算法技术细节详解
前面我们已经通过三篇文章,详细介绍了 Qwen2.5 大语言模型在 Transformers 框架中的技术细节,包括包和对象加载、模型初始化和分词器技术细节: 深入解析 Transformers 框架(一):包和对象加载中的设计巧思与…...

【Python-AI篇】K近邻算法(KNN)
0. 前置----机器学习流程 获取数据集数据基本处理特征工程机器学习模型评估在线服务 1. KNN算法概念 如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中大多数属于某一个类别,则该样本也属于这一个类别 1.1 KNN算法流程总…...

aws xray如何实现应用log和trace的关联关系
参考资料 https://community.aws/tutorials/solving-problems-you-cant-see-using-aws-x-ray-and-cloudwatch-for-user-level-observability-in-your-serverless-microservices-applicationshttps://stackoverflow.com/questions/76000811/search-cloudwatch-logs-for-aws-xra…...

centos服务器登录失败次数设定
实现的效果 一台centos服务,如果被别人暴力或者登录次数超过多少次,就拒绝或者在规定时间内拒绝ip登录。这里使用的是fail2ban 安装fail2ban sudo yum install epel-release -y # 先安装 EPEL 源 sudo yum install fail2ban -y配置fail2ban # 复制默…...

实时高效,全面测评快递100API的物流查询功能
一、引言 你是否曾经在网购后焦急地等待包裹,频繁地手动刷新订单页面以获取最新的物流信息?或者作为一名开发者,正在为如何在自己的应用程序中高效地实现物流查询功能而发愁?其实,有一个非常好用的解决方案——快递10…...

第14张 GROUP BY 分组
一、分组功能介绍 使用group by关键字通过某个字段进行分组,对分完组的数据分别 “SELECT 聚合函数”查询结果。 1.1 语法 SELECT column, group_function(column) FROM table [WHERE condition] [GROUP BY group_by_expression] [ORDER BY column]; 明确&#…...
input子系统与相关框架)
笔记整理—linux驱动开发部分(10)input子系统与相关框架
关于输入类设备的系统有touch、按键、鼠标等,在系统中,命令行也是输入类系统。但是GUI的引入,不同输入类设备数量不断提升,带来麻烦,所以出现了struct input_event。 struct input_event {struct timeval time;//内核…...

[算法初阶]埃氏筛法与欧拉筛
素数的定义: 首先我们明白:素数的定义是只能整除1和本身(1不是素数)。 我们判断一个数n是不是素数时,可以采用试除法,即从i2开始,一直让n去%i,直到i*i<n c语言: #include<…...

【THM】linux取证 DisGruntled
目录 0x00 房间介绍 0x01 连接并简单排查 0x02 让我们看看做没做坏事 0x03 炸弹已埋下。但何时何地? 0x04 收尾 0x05 结论 0x00 房间介绍 嘿,孩子!太好了,你来了! 不知道您是否看过这则新闻,我…...
)
SpringBoot整合Freemarker(四)
escape, noescape 语法 <#escape identifier as expression>...<#noescape>...</#noescape>... </#escape> 用例 主要使用在相似的字符串变量输出,比如某一个模块的所有字符串输出都必须是html安全的,这个时候就可以使用&am…...

centos docker 安装 rabbitmq
安装docker 1.更新现有的软件包 首先,确保您的系统是最新的,可以通过运行以下命令来实现: sudo yum update -y 2.移除旧版本的Docker 如果您之前安装过Docker,可能需要先卸载旧版本。使用以下命令来卸载旧版本的Docker&#…...

手动实现promise的all,race,finally方法
Promise.all 是一个非常有用的工具,它接受一个 Promise 对象数组,并返回一个新的 Promise。当所有输入的 Promise 都成功解决时,新的 Promise 会解决为一个包含所有结果的数组;如果任何一个 Promise 被拒绝,新的 Prom…...

H5移动端预览PDF方法
新建页面 新建一个页面以便去预览对应的pdf 新建完后在 pages.json 文件内去新增对应路由 页面内容 <template><view class"page"><view class"pdf"><view id"demo"></view></view><view class"b…...

uniapp—android原生插件开发(1环境准备)
本篇文章从实战角度出发,将UniApp集成新大陆PDA设备RFID的全过程分为四部曲,涵盖环境搭建、插件开发、AAR打包、项目引入和功能调试。通过这份教程,轻松应对安卓原生插件开发与打包需求! 项目背景: UniApp集成新大陆P…...

《潜行者2切尔诺贝利之心》游戏引擎介绍
潜行者2切尔诺贝利之心是基于虚幻5引擎,所以画面效果大家不必担心。游戏目前已经跳票了很久,预计发售时间是2024 年 11 月 21 日,这次应该不会再跳票。 潜行者2切尔诺贝利之心是虚幻5吗 答:是虚幻5。 潜行者官方推特之前回复了…...

winform 加载 office excel 插入QRCode图片如何设定位置
需求:winform 加载 office excel 并加载QRCode图片,但是每台PC打印出来QRCode位置都不太一样,怎么办呢? 我的办法: 1、在sheet中插入一个 textbox ,改名 qrcode (这个名字随便设置)…...

简易入手《SOM神经网络》的本质与原理
原创文章,转载请说明来自《老饼讲解神经网络》:www.bbbdata.com 关于《老饼讲解神经网络》: 本网结构化讲解神经网络的知识,原理和代码。 重现matlab神经网络工具箱的算法,是学习神经网络的好助手。 目录 一、入门原理解说 01.…...

21.assert断言
assert(断言)主要用于在程序运行过程中检查某个条件是否满足,如果不满足则会触发错误并终止程序执行,可以帮助程序员在开发阶段及时发现可能存在的逻辑错误等问题。 通过断言调试程序,abotr() has been called 就是断言…...

15分钟学 Go 第 46 天 : 监控与日志
第46天:监控与日志 学习目标 了解如何实现应用监控与日志管理,掌握相关工具和最佳实践。 内容结构 引言监控的概念与工具 监控的定义常见监控工具 日志管理的概念与工具 日志的重要性常见日志管理工具 实现监控与日志的最佳实践 监控指标日志格式 实战…...

BFS 算法专题(四):多源 BFS
目录 1. 01 矩阵 1.1 算法原理 1.2 算法代码 2. 飞地的数量 2.1 算法原理 2.2 算法代码 3. 地图中的最高点 3.1 算法原理 3.2 算法代码 4. 地图分析 4.1 算法原理 4.2 算法代码 1. 01 矩阵 . - 力扣(LeetCode) 1.1 算法原理 采用 BFS 正难…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...