使用亚马逊 S3 连接器为 PyTorch 和 MinIO 创建地图式数据集

在深入研究 Amazon 的 PyTorch S3 连接器之前,有必要介绍一下它要解决的问题。许多 AI 模型需要使用无法放入内存的数据进行训练。此外,许多为计算机视觉和生成式 AI 构建的真正有趣的模型使用的数据甚至无法容纳在单个服务器附带的磁盘驱动器上。解决存储问题很容易。如果您的数据集无法在单个服务器上容纳,则需要与 S3 兼容的对象存储。在云中,这很可能是 Amazon 的 S3 对象存储。对于本地模型训练,您将需要 MinIO。S3 兼容性非常重要,因为 S3 已成为非结构化数据的实际接口,使用 S3 接口的解决方案将为工程师在选择数据访问库时提供更多选择。解决内存问题更具挑战性。您需要找出一种策略,以便在每次需要一批数据进行训练时读取数据,而不是在训练管道开始时加载一次数据集。一种常见的方法是在训练管道开始时加载对象路径列表,然后在批处理此路径列表时,检索每个对象以获取实际的对象数据。下面的两个可视化效果显示了前端加载与批量加载的详细信息。

Training Pipeline,用于在训练管道开始时检索整个数据集
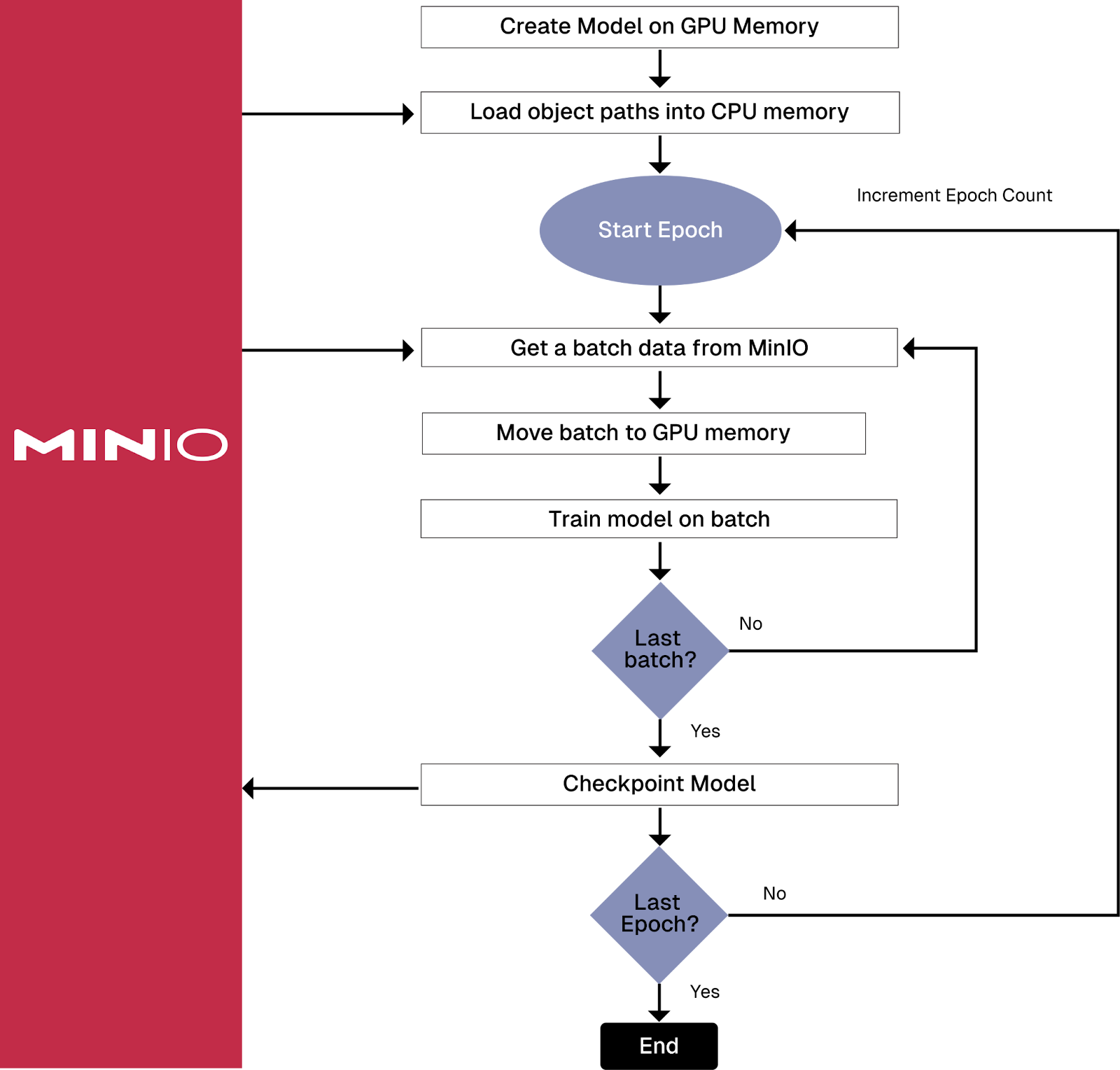
从存储中检索每个批次的数据的训练管道
如您所见,批量加载会给您的网络和存储解决方案带来更大的负担,这两者都需要快速。这是 Amazon 的 S3 Connector for PyTorch 解决“大型数据集问题”的方法之一,它提高了数据访问效率,减少了需要编写的代码量。事实证明,以前曾尝试解决大型数据集问题。让我们研究一下历史,并简要谈谈 Amazon 新连接器之前的库。其中许多库仍然可用,因此了解它们是什么非常重要,这样您就不会使用它们。
昔日的图书馆
Amazon 于 2021 年 9 月宣布推出适用于 PyTorch 的 Amazon S3 插件。这个插件从未作为真正的 Python 库进入 PyPI。相反,它可以通过 Amazon 的容器注册表获得,也可以从其 GitHub 存储库安装。如果您今天导航到这篇文章,您将看到一条通知,推荐适用于 PyTorch 的 S3 连接器。2023 年 7 月,PyTorch 宣布推出基于 CPP 的 S3 IO DataPipe。这个库看起来很有前途,因为它是作为 C++ 扩展实现的(将其解释为意味着它会非常快),并且具有用于列出和加载对象的类。列出 S3 存储桶中的对象有时可能会很慢,因此看起来 PyTorch 人员走在正确的道路上。原始公告仍然存在,没有警告,但如果您导航到 S3 IO Datapipe 文档的 GitHub 页面,您将看到弃用警告和使用 S3 Connector for PyTorch 的建议。用户文档也有类似的警告。现在我们知道了什么不应该使用,让我们看看适用于 PyTorch 的 S3 连接器。
适用于 PyTorch 的 S3 连接器简介
2023 年 11 月,Amazon 宣布推出适用于 PyTorch 的 S3 连接器。适用于 PyTorch 的 Amazon S3 连接器提供了专为 S3 对象存储构建的 PyTorch 数据集基元(数据集和数据加载器)的实现。它支持用于随机数据访问模式的地图样式数据集和用于流式处理顺序数据访问模式的可迭代样式数据集。在这篇文章中,我将重点介绍地图样式的数据集。在以后的文章中,我将介绍可迭代样式的数据集。此外,此连接器的文档仅显示了从 Amazon S3 加载数据的示例 - 我将向您展示如何对 MinIO 使用它。适用于 PyTorch 的 S3 连接器还包括一个检查点接口,用于将检查点直接保存和加载到 S3 存储桶中,而无需先保存到本地存储。如果您还没有准备好采用正式的 MLOps 工具,而只需要一种简单的方法来保存模型,那么这是一个非常好的选择。我还将在以后的文章中介绍此功能。为了好玩,让我们手动构建一个地图样式的数据集。如果您需要连接到不兼容 S3 的数据源,则需要采用这种技术。
手动构建地图样式数据集
地图样式数据集是通过实现一个类来创建的,该类覆盖了 PyTorch 的 Dataset 基类中的 getitem() 和 len() 方法。实例化后,各个样本将映射到索引或键。下面的代码显示了如何覆盖这些方法。它使用 MinIO SDK 手动检索存储的对象并对其应用转换。完整的代码下载可以在这里找到。
class ImageDatasetMap(Dataset):def __init__(self, bucket_name: str, image_list: List[str], y, transform=None):self.bucket_name = bucket_nameself.X = image_listself.y = yself.transform = transformdef __len__(self):return len(self.y)def __getitem__(self, index):img = du.get_image_from_minio(self.bucket_name, self.X[index])if self.transform is not None:img = self.transform(img)return img, self.y[index]请注意这个类的两件事。首先,当它被实例化时,它会收到一个 S3 路径列表,而不是一个 S3 对象列表。本文的代码下载中使用以下函数来获取存储桶中的对象列表。
def get_mnist_lists(bucket_name: str, split: str='train', smoke_test_size: int=0) -> Tuple[Any]:# Get a list of objects and split them according to train and test. object_list = get_object_list(bucket_name, split)X = []y = []for path in object_list:X.append(path)label = int(path.split('/')[1]) #int(obj[6])y.append(label)if smoke_test_size > 0:X = X[0:smoke_test_size]y = y[0:smoke_test_size]return X, y其次,每次请求单个样本时,都会连接到数据源 MinIO 以检索样本。换句话说,将对数据集中的每个单独对象发出网络请求。下面的代码片段显示了如何实例化这个类并使用 dataset 对象创建一个 Dataloader。
# Define a transform to normalize the data
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))])# The file loader type will download and load the training data directly into a
# dataset.
# Get a list of objects and split them according to train and test.
X_train, y_train = du.get_mnist_lists(bucket_name)
train_dataset = ImageDatasetMap(bucket_name, X_train, y_train, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)最后,下面的代码段是一个简短的训练循环,显示了如何使用这个数据加载器。高亮显示的代码是批处理循环的开始。每当 for 循环产生并返回一批 ImageDatasetMap 对象时,就会发生 IO。此时,将调用所有 getitem() 方法。这会导致调用 MinIO 来检索对象数据。例如,如果您的批次大小设置为 200,则此循环的每次迭代将导致 200 次网络调用,以检索当前训练批次所需的 200 个样本。
# Epoch loop
for epoch in range(training_parameters['epochs']):# Batch loopfor images, labels in loader:# Move to the specified device.images, labels = images.to(device), labels.to(device)# Start of compute time for the batch.compute_start = time.perf_counter()# Flatten MNIST images into a 784 long vector.images = images.view(images.shape[0], -1)# Training passoptimizer.zero_grad()output = model(images)loss = loss_func(output, labels)loss.backward()optimizer.step()上面的代码使您的训练循环受 IO 限制。如果您的数据集太大,无法在训练管道开始时加载到内存中,并且每个样本都是一个单独的对象,那么这是在模型训练期间访问数据集的最佳选择。
将 S3 连接器连接到 MinIO
将 S3 连接器连接到 MinIO 就像设置环境变量一样简单。之后,一切都会顺利进行。诀窍是以正确的方式设置正确的环境变量。本文的代码下载使用 .env 文件来设置环境变量,如下所示。此文件还显示了我用于使用 MinIO Python SDK 直接连接到 MinIO 的环境变量。请注意,AWS_ENDPOINT_URL 需要 protocol,而 MinIO 变量不需要。此外,你可能会注意到 AWS_REGION 变量的一些奇怪行为。从技术上讲,访问 MinIO 时不需要它,但如果为此变量选择错误的值,则 S3 连接器中的内部检查可能会失败。如果您收到这些错误之一,请仔细阅读该消息并指定它请求的值。
AWS_ACCESS_KEY_ID=admin
AWS_ENDPOINT_URL=http://172.31.128.1:9000
AWS_REGION=us-east-1
AWS_SECRET_ACCESS_KEY=password
IMAGENET_BUCKET_NAME=imagenet
MINIO_URL=172.31.128.1:9000
MINIO_ACCESS_KEY=admin
MINIO_SECRET_KEY=password
MINIO_SECURE=false
MNIST_BUCKET_NAME=mnist使用 S3 连接器创建地图样式数据集
要使用 S3 连接器创建地图样式数据集,您无需像上一节中那样编写代码和创建类。S3MapDataset.from_prefix() 函数将为您完成所有工作。此函数假定您已设置环境变量以连接到 S3 对象存储,如上一节所述。它还要求可以通过 S3 前缀找到您的对象。下面显示了一个演示如何使用此函数的代码段。
from s3torchconnector import S3MapDataseturi = 's3://mnist/train'
aws_region = os.environ['AWS_REGION']
train_dataset = S3MapDataset.from_prefix(uri, region=aws_region,transform=MNISTTransform(transform))请注意,URI 是 S3 路径。在路径 mnist/train 下可以递归找到的每个对象都应该是属于训练集的对象。上述函数还需要一个 transform 来将对象转换为张量并确定标签。这是通过如下所示的可调用类的实例完成的。
from s3torchconnector import S3Readerclass MNISTTransform:def __init__(self, transform):self.transform = transformdef __call__(self, object: S3Reader) -> torch.Tensor:content = object.read()image_pil = Image.open(BytesIO(content))image_tensor = self.transform(image_pil)label = int(object.key.split('/')[1])return (image_tensor, label)
这就是使用 S3 Connector for PyTorch 创建地图样式数据集所需要做的全部工作。
结论
适用于 PyTorch 的 S3 连接器易于使用,工程师在使用时编写的数据访问代码更少。在本文中,我展示了如何将其配置为使用环境变量连接到 MinIO。配置完成后,三行代码创建一个 dataset 对象,并使用简单的可调用类转换 dataset 对象。高速存储和高速数据访问与高速计算齐头并进。适用于 PyTorch 的 S3 连接器专为高效 S3 访问而构建,由为我们提供 S3 的公司编写。最后,如果您的网络是训练管道中最薄弱的环节,请考虑创建包含多个样本的对象,您甚至可以使用 tar 或 zip 来生成这些样本。Iterable 样式的数据集专为这些场景而设计。我关于 PyTorch 的 S3 连接器的下一篇文章将介绍这项技术。
相关文章:
使用亚马逊 S3 连接器为 PyTorch 和 MinIO 创建地图式数据集
在深入研究 Amazon 的 PyTorch S3 连接器之前,有必要介绍一下它要解决的问题。许多 AI 模型需要使用无法放入内存的数据进行训练。此外,许多为计算机视觉和生成式 AI 构建的真正有趣的模型使用的数据甚至无法容纳在单个服务器附带的磁盘驱动器上。解决存…...

自动化运维:提升效率与稳定性的关键技术实践
自动化运维:提升效率与稳定性的关键技术实践 在数字化转型的浪潮中,企业对于IT系统的依赖日益加深,系统的复杂性和规模也随之膨胀。面对这一挑战,传统的运维模式——依靠人工进行服务器的监控、配置变更、故障排查等任务…...

Google Go编程风格指南-介绍
关于 首先应该明确的是:Go语言是Google搞出来的,这个编程风格指南也是它提出来的,详见:https://google.github.io/styleguide/go/。 然后国内翻译组跟上,于是有了中文版:https://gocn.github.io/stylegui…...

思科模拟器路由器配置实验
一、实验目的 了解路由器的作用。掌握路由器的基本配置方法。掌握路由器模块的使用和互连方式。 二、实验环境 设备: 2811 路由器 1 台计算机 2 台Console 配置线 1 根网线若干根 拓扑图:实验拓扑图如图 8-1 所示。计算机 IP 地址规划:如表…...

机器学习—选择激活函数
可以为神经网络中的不同神经元选择激活函数,我们将从如何为输出层选择它的一些指导开始,事实证明,取决于目标标签或地面真相标签y是什么,对于输出层的激活函数,将有一个相当自然的选择,然后看看激活函数的选…...

[ Linux 命令基础 4 ] Linux 命令详解-文本处理命令
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...

Odoo:免费开源的钢铁冶金行业ERP管理系统
文 / 开源智造 Odoo亚太金牌服务 简介 Odoo免费开源ERP集成计质量设备大宗原料采购,备件设材全生命周期,多业务模式货控销售,全要素追溯单品,无人值守计量物流,大宗贸易交易和精细化成本管理等方案;覆盖…...

33.Redis多线程
1.Redis队列与Stream Redis5.0 最大的新特性就是多出了一个数据结构 Stream,它是一个新的强大的支持多播的可持久化的消息队列。 Redis Stream 的结构如上图所示,每一个Stream都有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯…...

【Python】解析 XML
1、Python 对 XML 的解析 1.1 SAX (simple API for XML ) SAX 解析器使用事件驱动模型,通过在解析XML的过程中触发一个个的事件并调用用户定义的回调函数来处理XML文件。 xml.sax 模块牺牲了便捷性来换取速度和内存占用。 事件驱动指一种基于回调(ca…...

【复平面】-复数相乘的几何性质
文章目录 从数学上证明1. 计算乘积 z 1 ⋅ z 2 z_1 \cdot z_2 z1⋅z22. 应用三角恒等式3. 得出结果 从几何角度证明1.给出待乘的复数 u i u_i ui2.给出任意复数 l l l3.复数 l l l 在不同坐标轴下的表示图 首先说结论: 在复平面中,两个复数&a…...

为什么ta【给脸不要脸】:利他是一种选择,善良者的自我救赎与智慧策略
你满腔热忱,他却视而不见; 你伸出援手,他却恩将仇报; 你谦让包容,他却得寸进尺; 你善意提拔,他却并不领情,反而“给脸不要脸”。 所有人都曾被这种“好心当成驴肝肺”遭遇内耗&a…...

mysql 配置文件 my.cnf 增加 lower_case_table_names = 1 服务启动不了的原因
原因:在MySQL8.0之后的版本,只允许在数据库初始化时指定,之后不允许修改了 mysql 配置文件 my.cnf 增加 lower_case_table_names 1 服务启动不了 报错信息:Job for mysqld.service failed because the control process exited …...
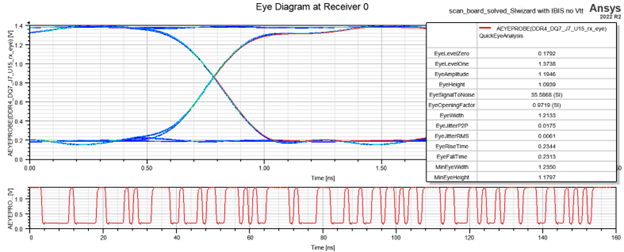
SIwave:释放 SIwizard 求解器的强大功能
SIwave 是一种电源完整性和信号完整性工具。SIwizard 是 SIwave 中 SI 分析的主要工具,也是本博客的主题。 SIwizard 用于研究 RF、clock 和 control traces 的信号完整性。该工具允许用户进行瞬态分析、眼图分析和 BER 计算。用户可以将 IBIS 和 IBIS-AMI 模型添加…...
强化学习不愧“顶会收割机”!2大创新思路带你上大分,毕业不用愁!
强化学习之父Richard Sutton悄悄搞了个大的,提出了一个简单思路:奖励聚中。这思路简单效果却不简单,等于是给几乎所有的强化学习算法上了一个增强buff,所以这篇论文已经入选了首届强化学习会议(RLC 2024)&a…...

mac 修改启动图图标数量
调整每行显示图标数量: defaults write com.apple.dock springboard-rows -int 7 调整每列显示的数量 defaults write com.apple.dock springboard-columns -int 8 最后重置一下启动台 defaults write com.apple.dock ResetLaunchPad -bool TRUE;killall Dock 其…...

网站架构知识之Ansible进阶(day022)
1.handler触发器 应用场景:一般用于分发配置文件时候,如果配置文件有变化,则重启服务,如果没有变化,则不重启服务 案列01:分发nfs配置文件,若文件发生改变则重启服务 2.when判断 用于给ans运…...

VMware调整窗口为可以缩小但不改变显示内容的大小
也就是缩小窗口不会影响内容的大小 这样设置就好...

Vue 3 中,ref 和 reactive的区别
在 Vue 3 中,ref 和 reactive 是两种用于创建响应式数据的方法。它们有一些关键的区别和适用场景。以下是它们的主要区别: ref 用途: ref 主要用于处理基本数据类型(如字符串、数字、布尔值等)以及需要单独响应的复杂…...

window 利用Putty免密登录远程服务器
1 在本地电脑用putty-gen生成密钥 参考1 参考2 2 服务器端操作 将公钥上传至Linux服务器。 复制上述公钥到服务器端的authorized_keys文件 mkdir ~/.ssh vi ~/.ssh/authorized_keys在vi编辑器中,按下ShiftInsert键或者右键选择粘贴,即可将剪贴板中的文…...

OGNL表达式
介绍 OGNL生来就是为了简化Java属性的取值,比如想根据名称name引用当前上下文环境中的对象,则直接键入即可,如果想要引用当前上下文环境中对象text的属性title,则键入text.title即可。如果想引用对象的非值属性,OGNL也…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...