Spark的Standalone集群环境安装
一.简介
与MR对比:
| 概念 | MR+YARN | Spark Standalone |
| 主节点 | ResourceManager | Master |
| 从节点 | NodeManager | Worker |
| 计算进程 | MapTask,ReduceTask | Executor |
架构:普通分布式主从架构
主:Master:管理节点:管理从节点、接客、资源管理和任务
调度,等同于YARN中的ResourceManager
从:Worker:计算节点:负责利用自己节点的资源运行主节点
分配的任务
功能:提供分布式资源管理和任务调度,基本上与YARN是一致的
看起来很像yarn ,其实作用和yarn一样,是spark自带的计算引擎。
注意:集群环境的每一台服务器都要Annaconda ,否则会出现python3 找不到的错误!!
二.Standalone集群部署
使用的资源如下:虚拟机中使用的Anaconda,具体:Anaconda3-2021.05-Linux-x86-64,spark使用需要资源-CSDN文库
虚拟机使用的spark,详情:spark-3.1.2-bin-hadoop3.2.tgz资源-CSDN文库
首先在所有服务器按如下安装Anaconda:
上传,或者同步:
xsync.sh /opt/modules/Anaconda3-2021.05-Linux-x86_64.sh
# 添加执行权限
chmod u+x Anaconda3-2021.05-Linux-x86_64.sh
# 执行
sh ./Anaconda3-2021.05-Linux-x86_64.sh
# 过程
#第一次:【直接回车,然后按q】Please, press ENTER to continue>>>
#第二次:【输入yes】Do you accept the license terms? [yes|no][no] >>> yes
#第三次:【输入解压路径:/opt/installs/anaconda3】[/root/anaconda3] >>> /opt/installs/anaconda3#第四次:【输入yes,是否在用户的.bashrc文件中初始化
Anaconda3的相关内容】Do you wish the installer to initialize Anaconda3by running conda init? [yes|no][no] >>> yes刷新环境变量:
# 刷新环境变量
source /root/.bashrc
# 激活虚拟环境,如果需要关闭就使用:conda deactivate
conda activate
配置环境变量:
# 编辑环境变量
vi /etc/profile
# 添加以下内容
# Anaconda Home
export ANACONDA_HOME=/opt/installs/anaconda3
export PATH=$PATH:$ANACONDA_HOME/bin
制作软链接:
# 刷新环境变量
source /etc/profile
小结:实现Linux机器上使用Anaconda部署Python3:单机部署:Spark Python Shell
目标:掌握Spark Shell的基本使用
实施
功能:提供一个交互式的命令行,用于测试开发Spark的程序代码
Spark的客户端bin目录下:提供了多个测试工具客户端
启动
核心
# 创建软连接
ln -s /opt/installs/anaconda3/bin/python3 /usr/bin/python3
# 验证
echo $ANACONDA_HOME然后在自己使用的虚拟机上安装spark:
# 解压安装
cd /opt/modules
tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /opt/installs
# 重命名
cd /opt/installs
mv spark-3.1.2-bin-hadoop3.2 spark-standalone
# 重新构建软连接
rm -rf spark
ln -s spark-standalone spark去修改spark配置文件:
cd /opt/installs/spark/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
修改如下:
export JAVA_HOME=/opt/installs/jdk
export HADOOP_CONF_DIR=/opt/installs/hadoop/etc/hadoop
export SPARK_MASTER_HOST=bigdata01 # 主节点所在的地址
export SPARK_MASTER_PORT=7077 #主节点内部通讯端口,用于接收客户端请求
export SPARK_MASTER_WEBUI_PORT=8080 #主节点用于供外部提供浏览器web访问的端口
export SPARK_WORKER_CORES=1 # 指定这个集群总每一个从节点能够使用多少核CPU
export SPARK_WORKER_MEMORY=1g #指定这个集群总每一个从节点能够使用多少内存
export SPARK_WORKER_PORT=7078
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_DAEMON_MEMORY=1g # 进程自己本身使用的内存
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://bigdata01:9820/spark/eventLogs/ -Dspark.history.fs.cleaner.enabled=true"
# Spark中提供了一个类似于jobHistoryServer的进程,就叫做HistoryServer, 用于查看所有运行过的spark程序
在HDFS上创建程序日志存储目录
首先如果没有启动hdfs,需要启动一下
启动
start-dfs.sh
# 创建程序运行日志的存储目录
hdfs dfs -mkdir -p /spark/eventLogs/继续修改配置文件:
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf添加如下:“
# 末尾
spark.eventLog.enabled true
spark.eventLog.dir hdfs://bigdata01:9820/spark/eventLogs
spark.eventLog.compress true在workers:从节点地址配置文件
mv workers.template workers
vim workers# 删掉localhost,添加自己的主机名
bigdata01
bigdata02
bigdata03修改日志文件,可有可无
mv log4j.properties.template log4j.properties
vim log4j.properties
# 19行:修改日志级别为WARN
log4j.rootCategory=WARN, consolelog4j的5种 级别 debug --> info --> warn --error -->fatal为什么要修改?因为我们运行的时候info非常多,比较影响体验,而且也不是报错,对我们一般来说也没什么用。所以把它修改成更高一级的warn。因此说这一步可有可无,做了可以优化使用体验,但是不做也没有任何影响。
同步集群:
xsync.sh /opt/installs/spark-standalone/使用脚本:
虚拟机中使用的分发文件,和分发命令脚本资源-CSDN文库
可以直接把虚拟机的文件分发给集群中的其他机器
分发完成在其他机器创建软链接:
cd /opt/installs/
ln -s spark-standalone spark换个思路,是否可以同步软链接:
xsync.sh /opt/installs/spark集群启动:
启动master:
cd /opt/installs/spark
sbin/start-master.sh
启动所有worker:
sbin/start-workers.sh
如果你想启动某一个worker
sbin/start-worker.sh启动日志服务:
sbin/start-history-server.sh要想关闭某个服务,将start换为stopmaster的监控页面:
http://bigdata01:8080/
其中bigdata换成自己的ip
至此搭建完毕,来个圆周率测试一下:
# 提交程序脚本:bin/spark-submit
/opt/installs/spark/bin/spark-submit --master spark://bigdata01:7077 /opt/installs/spark/examples/src/main/python/pi.py 200相关文章:
Spark的Standalone集群环境安装
一.简介 与MR对比: 概念MRYARNSpark Standalone主节点ResourceManagerMaster从节点NodeManagerWorker计算进程MapTask,ReduceTaskExecutor 架构:普通分布式主从架构 主:Master:管理节点:管理从节点、接…...
Android Glide动态apply centerCropTransform(),transition withCrossFade动画,Kotlin
Android Glide动态apply centerCropTransform(),transition withCrossFade动画,Kotlin import android.graphics.Bitmap import android.os.Bundle import android.widget.ImageView import androidx.appcompat.app.AppCompatActivity import com.bumptech.glide.Glide import …...

shukla方差和相对平均偏差
参考资料:实用统计学【李奉令】 Eberhart-Russell模型、Shukla模型、相对平均偏差稳定性分析比较 相对平均偏差在品种稳定性分析中的作用 1、Shukla方差 生物统计中,用于描述一个群体离散程度的统计量有离差、方差、极差等, 国内品种区域试…...

双指针(二)双指针到底是怎么个事
一.有效的三角形个数 有效的三角形个数 class Solution {public int triangleNumber(int[] nums) {Arrays.sort(nums);int i0,end nums.length-1;int count 0;for( i end;i>2;i--){int left 0;int right i-1;while(left<right){if(nums[left]nums[right]>nums…...

vscode通过remote-ssh连接远程开发机
文章目录 安装扩展注意事项:tips其他参数安装扩展 安装VS Code和SSH-Remote扩展:首先,需要确保你已经在本地计算机上安装了VS Code,并且在扩展市场中搜索并安装了"Remote - SSH"扩展。配置SSH:在本地计算机上,打开VS Code的命令面板(使用快捷键"Ctrl+Shi…...

uniapp实现H5和微信小程序获取当前位置(腾讯地图)
之前的一个老项目,使用 uniapp 的 uni.getLocation 发现H5端定位不准确,比如余杭区会定位到临平区,根据官方文档初步判断是项目的uniapp的版本太低。 我选择的方式不是区更新uniapp的版本,是直接使用高德地图的api获取定位。 1.首…...

SQL HAVING子句
SQL 是一种基于“面向集合”思想设计的语言。HAVING 子句是一个聚合函数,用于过滤分组结果。 1 实践 1.1 缺失的编号 图 连续编号记录表t_seq_record 需求:判断seq 列编号是否有缺失。 SELECT 存在缺失的编号 AS res FROM t_seq_record HAVING COUN…...

计算机视觉基础:OpenCV库详解
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 计算机视觉基础:OpenCV库详解 计算机视觉基础:OpenCV库详解 计算机视觉基础:OpenCV库详解 引…...
UI自动化测试工具(超详细总结)
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 常用工具 1、QTP:商业化的功能测试工具,收费,可用于web自动化测试 2、Robot Framework:基于Python可扩展的关…...

AJAX 全面教程:从基础到高级
AJAX 全面教程:从基础到高级 目录 什么是 AJAXAJAX 的工作原理AJAX 的主要对象AJAX 的基本用法AJAX 与 JSONAJAX 的高级用法AJAX 的错误处理AJAX 的性能优化AJAX 的安全性AJAX 的应用场景总结与展望 什么是 AJAX AJAX(Asynchronous JavaScript and XML…...

ONLYOFFICE 8.2测评:功能增强与体验优化,打造高效办公新体验
引言 随着数字化办公需求的不断增长,在线办公软件市场竞争愈加激烈。在众多办公软件中,ONLYOFFICE 无疑是一个颇具特色的选择。它不仅支持文档、表格和演示文稿的在线编辑,还通过开放的接口与强大的协作功能,吸引了众多企业和个人…...

Science Robotics 综述揭示演化研究新范式,从机器人复活远古生物!
在地球46亿年的漫长历史长河中,生命的演化过程充满着未解之谜。如何从零散的化石证据中还原古生物的真实面貌?如何理解关键演化节点的具体过程?10月23日,Science Robotics发表重磅综述,首次系统性提出"古生物启发…...

uni-app表格带分页,后端处理过每页显示多少条
uni-app表格带分页,后端处理过每页可以显示多少条,一句设置好了每页显示的数据量,不需要钱的在进行操作,在进行对数据的截取 <th-table :column"column" :listData"data" :checkSort"checkSort"…...
_262)
基于STM32设计的矿山环境监测系统(NBIOT)_262
文章目录 一、前言1.1 项目介绍【1】开发背景【2】研究的意义【3】最终实现需求【4】项目硬件模块组成1.2 设计思路【1】整体设计思路【2】上位机开发思路1.3 项目开发背景【1】选题的意义【2】摘要【3】国内外相关研究现状【5】参考文献1.4 开发工具的选择【1】设备端开发【2】…...

【初阶数据结构与算法】线性表之链表的分类以及双链表的定义与实现
文章目录 一、链表的分类二、双链表的实现1.双链表结构的定义2.双链表的初始化和销毁初始化函数1初始化函数2销毁函数 3.双链表的打印以及节点的申请打印函数节点的申请 4.双链表的头插和尾插头插函数尾插函数 5.双链表的查找和判空查找函数判空函数 6.双链表的头删和尾删头删函…...

219页华为供应链管理:市场预测SOP计划、销售预测与存货管理精要
一、华为ISC供应链管理 华为的集成供应链(ISC)领先实践和SISC(Siyuan Integrated Supply Chain)架构体现了其在供应链管理领域的深度和广度,以下是7点关键介绍: 全面的供应链视野:华为ISC涵盖…...

mac 安装指定的node和npm版本
mac 安装指定的node和npm版本 0.添加映像: export N_NODE_MIRRORhttps://npmmirror.com/mirrors/node 1、使用 npm 全局安装 n npm install -g n 如果报了sudo chown -R 502:20 "/Users/xxx/.npm" sudo npm install -g n 2、根据需求安装指定版本的 node …...
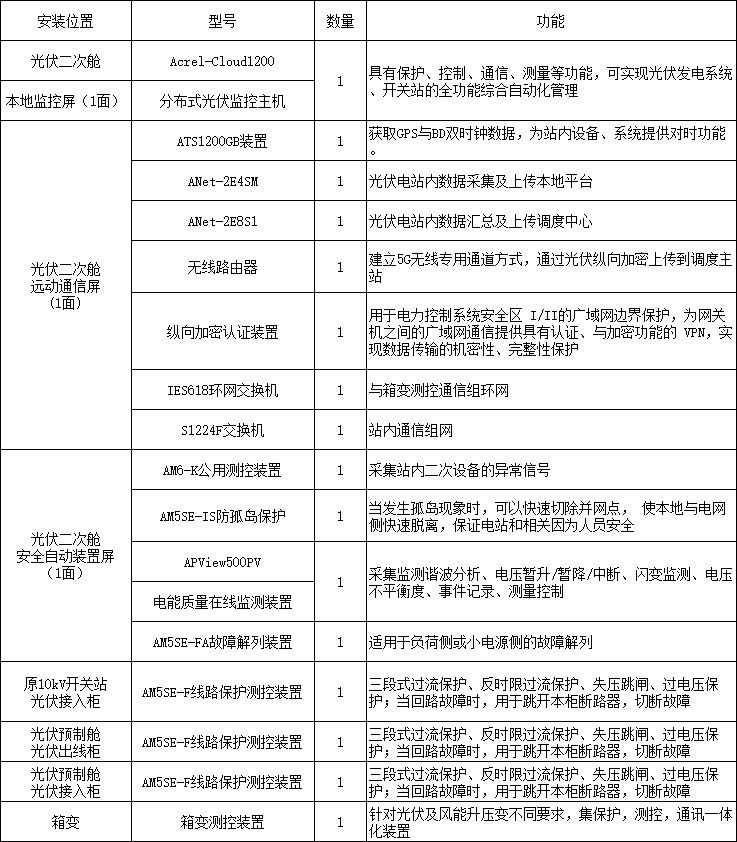
为什么分布式光伏规模是6MW为界点?
安科瑞 Acrel-Tu1990 最近,能源局颁布了一项规定,明确指出6兆瓦(MW)及以上的分布式光伏电站必须实现自发自用,自行消纳电力。多个省份的能源局进一步规定,规模超过6兆瓦的电站需按照集中式管理进行操作。此…...

arm64架构的linux 配置vm_page_prot方式
在 ARM64 架构上,通过 vm_page_prot 属性可以修改 UIO 映射内存的访问权限及缓存策略,常见的有非缓存(Non-cached)、写合并(Write Combine)等。下面是 ARM64 常用的 vm_page_prot 设置及其对应的操作方式。…...

vue3 + naive ui card header 和 title 冲突 bug
背景描述 最近发现一个 naive ui 上的问题,之前好好的,某一次升级后就出现了一个 bug,Modal 使用 card 布局后,Header Solt 下面的内容不见了,变成了 title,因为这个 solt 里面是有操作 action 的…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

C++_哈希表
本篇文章是对C学习的哈希表部分的学习分享 相信一定会对你有所帮助~ 那咱们废话不多说,直接开始吧! 一、基础概念 1. 哈希核心思想: 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。理想目标:实现…...
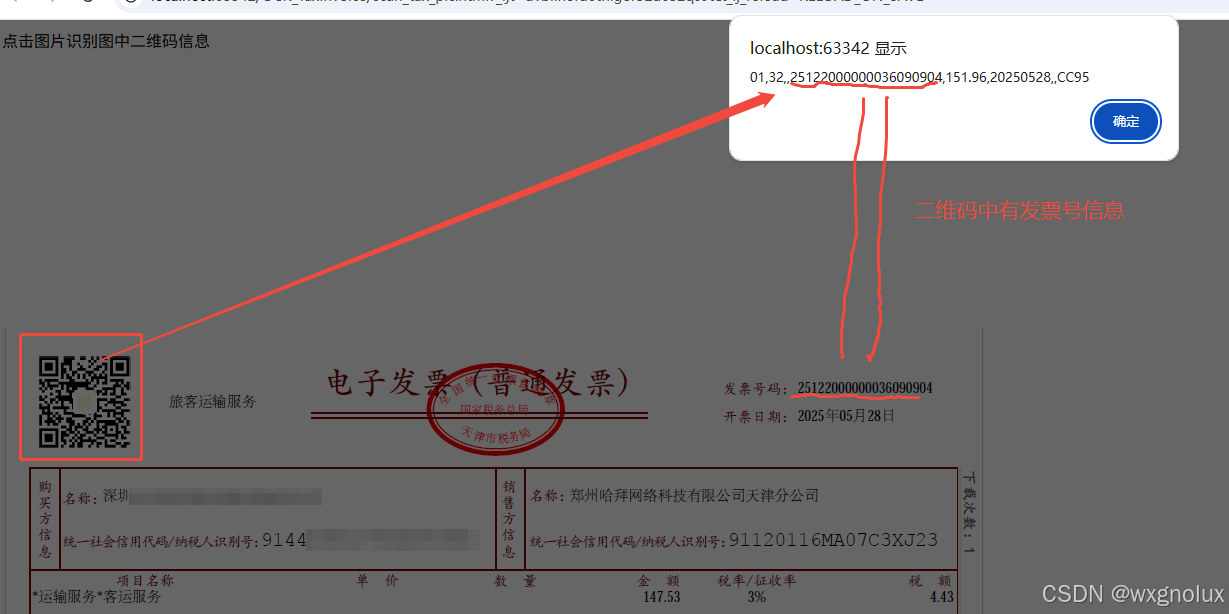
网页端 js 读取发票里的二维码信息(图片和PDF格式)
起因 为了实现在报销流程中,发票不能重用的限制,发票上传后,希望能读出发票号,并记录发票号已用,下次不再可用于报销。 基于上面的需求,研究了OCR 的方式和读PDF的方式,实际是可行的ÿ…...