【STL】set,multiset,map,multimap的介绍以及使用
关联式容器
在C++的STL中包含序列式容器和关联式容器
1.关联式容器:它里面存储的是元素本身,其底层是线性序列的数据结构,比如:vector,list,deque,forward_list(C++11)等
2.关联式容器里面储存的是<key,value>结构的键值对,在数据检索时比序列式容器效率更高。
注意:stack,queue,priority_queue这些都属于容器适配器,其底层都是vector,list,deque等
键值对
这种结构通常用来表示具有 一 一 对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。
比如:现在要建立一个英汉互译的字典,那该字典中必然 有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应 该单词,在词典中就可以找到与其对应的中文含义。
SGI-STL中关于键值对的定义:
template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair():first(T1()),second(T2()){}pair(const T1& a, const T2& b):first(a),second(b){}
};树形结构的关联式容器
根据应用场景的不桶,STL总共实现了两种不同结构的管理式容器:树型结构与哈希结构。树型结 构的关联式容器主要有四种:map、set、multimap、multiset。这四种容器的共同点是:使用平衡搜索树(即红黑树)作为其底层结果,容器中的元素是一个有序的序列。下面一依次介绍每一 个容器。
set
set的介绍
管方英文介绍:

中文介绍:
1. set是按照一定次序存储元素的容器,使用set的迭代器遍历set中的元素,可以得到有序序列
2. 在set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的。 set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。

它的迭代器都是const_iterator
3. 在内部,set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行排序。当我们没有传入比较函数时它默认使用小于来进行比较
4.set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对子集进行直接迭代。
5. set在底层是用二叉搜索树(红黑树)实现的。s所以在set中查找某个元素,时间复杂度为:O(logN)
6.与map/multimap不同,map/multimap中存储的是真正的键值对,set中只放value,但在底层实际存放的是由<value, value>构成的键值对。所以在set中插入元素时,只需要插入value即可,不需要构造键值对。
7.set中的元素不可以重复(因此可以使用set进行去重),并且set中的元素不允许修改,如果你修改了set的某个元素,那么它的底层的树状结构就会被破坏
注意:我们不能对set容器中的单个元素进行修改,如果修改,那么就会破坏它底层的树状结构
set的使用
1. set的模板参数列表

T: set中存放元素的类型,实际在底层存储<value, value>的键值对。
set的底层实现:

从它的底层实现也可以看出来,它只有一个key值,但在底层它是<value, value>(<key_type, value_type>)键值对结构
Compare:set中元素默认按照小于来比较
Alloc:set中元素空间的管理方式,使用STL提供的空间配置器管理
2. set的构造

1.构造某类型的一个空容器
set<int> N1; //构造int类型的空容器
set<double> N2; //构造double类型的空容器
set<char> N3; //构造char类型的空容器2.用 [first, last) 区间中的元素构造 set
int a[] = { 4,2,1,5,224,253,235,4,3456,4575,567 };
set<int> N4(a, a + sizeof(a) / sizeof(a[0]));for (const auto& e : N4)
{cout << e << ' ';
}
cout << endl;
排序 + 去重
3.set的拷贝构造
set<int> N5(N4);
for (const auto& e : N5)
{cout << e << ' ';
}
cout << endl;
4.构造一个某类型的空容器,比较方式指定为大于
set<int, greater<int>> N6set的成员函数
set常用的成员函数:
| 成员函数 | 功能 |
| insert | 插入指定元素 |
| erase | 删除指定元素 |
| find | 寻找指定元素 |
| size | 查看当前容器中的有效元素 |
| empty | 判断该容器是否为空 |
| clear | 清空容器中所以元素 |
| swap | 交换两个容器中的数据 |
| count | 统计指定的元素在该容器中的出现次数 |
| lower_bound | 返回一个大于或等于指定元素的迭代器 |
| uuper_bound | 返回指定元素下一个位置的迭代器(大于指定元素的迭代器) |
迭代器:
| begin | 返回set第一个元素的迭代器 |
| end | 返回set最后一个元素下一个位置的迭代器 |
| rbegin | 返回set最后一个元素的迭代器 |
| rend | 返回set第一个元素的前一个位置的迭代器 |
常用的成员函数的使用:
int main()
{set<int> N1;//insert//若key不在在树中,则返回pair<树里面key所在结点的iterator,true>//若key已经在树中,则返回pair<树里面key所在结点的iterator,false>N1.insert(7);N1.insert(12);N1.insert(10);for (const auto& e : N1) cout << e << ' '; // 7 10 12 cout << endl;N1.erase(7);N1.erase(10);for (const auto& e : N1) cout << e << ' '; // 12cout << endl;//set<int>::iterator it = N1.find(12);//find找到指定元素后就会返回它的迭代器,否则,返回end()迭代器if (N1.find(12) != N1.end()) cout << "true" << endl; // trueelse cout << "false" << endl;if (N1.count(12)) cout << "true" << endl; // trueelse cout << "false" << endl;if (N1.find(10) != N1.end()) cout << "true" << endl; // falseelse cout << "false" << endl;if (N1.count(10)) cout << "true" << endl; // falseelse cout << "false" << endl;cout << N1.size() << endl; // size: 1cout << N1.empty() << endl; // 0N1.clear();cout << N1.empty() << endl; // 1//多参数的隐式类型转换set<int> N2({2,342,25,123});N1.insert(888);N1.insert(88);N1.insert(8888);cout << "N2: ";for (const auto& e : N2) cout << e << ' '; // 2 25 123 342cout << endl;//交换两个容器的数据swap(N1, N2);cout << "N1: ";for (const auto& e : N1) cout << e << ' '; // 2 25 123 342cout << endl;cout << "N2: ";for (const auto& e : N2) cout << e << ' '; // 88 888 8888cout << endl;set<int>::iterator itlow, itup;itlow = N1.lower_bound(1); // 返回 >= 指定元素的迭代器itup = N1.upper_bound(128); // 返回 > 指定元素的迭代器cout << *itlow << endl; // 2cout << *itup << endl; // 342while (itlow != itup) cout << *(itlow++) <<' '; //2 25 123return 0;
}
迭代器:
begin() 和 end()
int main()
{int a[] = { 4,2,1,5,224,253,235,4,3456,4575,567 };set<int> N1(a, a + sizeof(a) / sizeof(a[0]));set<int> N2(N1.begin(), N1.end());cout << "N2: ";for (const auto& e : N2){cout << e << ' ';}cout << endl;return 0;
}
rbegin() 和rend()
int main()
{int a[] = { 4,2,1,5,224,253,235,4,3456,4575,567 };set<int> N1(a, a + sizeof(a) / sizeof(a[0]));set<int>::reverse_iterator it = N1.rbegin();while (it != N1.rend()){cout << *it << ' ';++it;}cout << endl;return 0;
}
multiset
multiset的介绍以及使用
与set所有接口一样,用法也一样,只有一个本质区别,那就是multiset这个容器允许数据冗余,它的结构模型中允许出现相同的元素(map中的key是唯一的,而multimap中key是可以 重复的。)
这里展示与set有区别的接口:
| 成员函数 | set | multiset |
| find | 找寻指定元素,并返回它的迭代器,否则,返回end()迭代器 | 找寻指定元素(如果数据冗余,则返回这一组数据的第一个元素的迭代器),否则,返回end()迭代器 |
| count | 统计指定元素出现次数 | 统计指定元素出现次数 |
| equal_bound | 返回一个只有相同元素区间 | 返回一个只有相同元素区间 |
其实我们可以看到除了find函数,另外两个函数就是为了multiset这个容器而创造的
find,count,equal_bound的使用
int main()
{//multisetmultiset<int> N1({10,124,123,10,10,10,10,1,5,6,8,3});for (const auto& e : N1) cout << e << ' '; // 1 3 5 6 8 10 10 10 10 10 123 124cout << endl;//findmultiset<int>::iterator it = N1.find(10);while (it != N1.end()) cout << *it++ << ' '; // 10 10 10 10 10 123 124cout << endl;//countcout << N1.count(10) << endl; // 5//pair<multiset<int>::iterator, multiset<int>::iterator> it1 = N1.equal_range(10);auto it1 = N1.equal_range(10);auto itfir = it1.first;auto itsed = it1.second;N1.erase(itfir, itsed);for (const auto& e : N1) cout << e << ' '; // 1 3 5 6 8 123 124return 0;
}map
map的介绍
官方英文介绍:

中文介绍:
1. map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元 素。
2. 在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的 内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型 value_type绑定在一起,为其取别名称为pair: typedef pair value_type;
3. 在内部,map中的元素总是按照键值key进行比较排序的。
4. map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序 对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
5. map支持下标访问符,即在[ ]中放入key,就可以找到与key对应的value,与set不一样map可以修改value,所以它的迭代器并不都是const。
![]()

可以看它的底层实现,它通过在key前面加const,禁止修改key,这个设计非常巧妙
6. map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。
map的使用
1. map的模板参数说明

key: 键值对中key的类型
T: 键值对中value的类型
Compare: 比较器的类型,map中的元素是按照key来比较的,缺省情况下按照小于来比 较,一般情况下(内置类型元素)该参数不需要传递,如果无法比较时(自定义类型),需要用户 自己显式传递比较规则(一般情况下按照函数指针或者仿函数来传递)
Alloc:通过空间配置器来申请底层空间,不需要用户传递,除非用户不想使用标准库提供的 空间配置器
注意:在使用map时,需要包含头文件。
2. map的构造
1.指定key和value的类型构造一个空容器
map<string, int> M1; //构造一个key为double,value为int的容器
map<string, string> M1; //构造一个key为double,value为int的容器2.使用迭代器区间进行初始化
map<string, int> M3(M2.begin(), M2.end());3.map的拷贝构造
map<string, int> M2(M1); //拷贝M1的数据给M24.构造一个某类型的空容器,比较方式指定为大于
map<string, int, greater<string>> M4;map的成员函数
常用的成员函数:
| 成员函数声明 | 功能 |
| pair<iterator, bool> insert ( const value_type & x) | 在map中插入键值对x,注意x是一个键值对,返回值也是键值对:iterator代表新插入元素的位置,bool代表释放插入成功 声明中的value_type是 typedef pair<const Key, T> value_type; |
| void erase ( iterator position ) | 删除指定位置的元素 |
| size_type erase ( const key_type& x ) | 删除键值为x的元素 |
| void erase ( iterator first, iterator last ) | 删除[first, lat)区间的元素 |
| void swap ( map& mp ) | 交换两个map中的元素 |
| void clear ( ) | 清空map中的元素 |
| iterator find ( const key_type& x ) | 在map中插入key为x的元素,找到返回该元 素的位置的迭代器,否则返回end |
| size_type count ( const key_type& x ) const | 返回key为x的键值在map中的个数,注意 map中key是唯一的,因此该函数的返回值 要么为0,要么为1,因此也可以用该函数来 检测一个key是否在map中 |
| bool empty ( ) const | 检测map中的元素是否为空,是返回 true,否则返回false |
| size_type size() const | 返回map中有效元素的个数 |
| mapped_type& operator[] (const key_type& k) | 返回去key对应的value |
迭代器:
| begin()和 end() | begin:首元素的位置,end最后一个元素的下一个位置 |
| rbegin()和 rend() | 反向迭代器,rbegin在end位置,rend在begin位置,其 ++和--操作与begin和end操作移动相反 |
常见成员函数的使用
map<string, int> M1;insert的使用
pair<iterator, bool> insert ( const value_type & x)方法1:实例化一个pair类型的P1对象,根据这个P1对象来初始化M1
pair<string, int> P1("nxbw", 10);
M1.insert(P1);方法2:使用pair的匿名对象
M1.insert(pair<string, int>());方法3:使用make_pair函数


M1.insert(make_pair("nxbw", 10));这里推荐使用方法三,比较方便,简洁
insert的返回值也是一个pair对象,pair对象的第一个成员变量的类型是map,第二个成员变量的类型是bool类型
若key不在在树中,则返回pair<树里面key所在结点的iterator,true>
若key已经在树中,则返回pair<树里面key所在结点的iterator,false>
erase
使用迭代器进行删除
void erase ( iterator position )map<string, int> M1;
M1.insert(make_pair("AB", 7));
M1.insert(make_pair("ABC", 8));
M1.insert(make_pair("ABCD", 9));
M1.insert(make_pair("ABCDE", 10));
M1.erase(M1.begin());
for(const auto& e : M1) cout << e.first << ' ' << e.second << endl; //e是M1的元素
cout << endl;
使用键值删除
size_type erase ( const key_type& x )size_t n = M1.erase("AB");
cout << n << endl; //1
n = M1.erase("ABf");
cout << n << endl; //0删除成功返回1,否则0
使用迭代器区间删除
map<string, int> M1;
M1.insert(make_pair("AB", 7));
M1.insert(make_pair("ABC", 8));
M1.insert(make_pair("ABCD", 9));
M1.insert(make_pair("ABCDE", 10));
M1.erase(++M1.begin(), M1.end());
for(const auto& e : M1) cout << e.first << ' ' << e.second << endl; //e是M1的元素
cout << endl;
swap
map<string, int> M2;
M2.insert(make_pair("nxbw", 666));
swap(M1, M2);
for (const auto& e : M2) cout << e.first << ' ' << e.second << endl;
cout << endl <<"M1: ";
for (const auto& e : M1) cout << e.first << ' ' << e.second << endl;
cout << endl;
clear
M1.clear();
for (const auto& e : M1) cout << e.first << ' ' << e.second << endl;
cout << endl;
find
通过键值寻找,如果找到键值,那么find就返回键值所在结点的迭代器,否则返回end()
map<string, int>::iterator it = M1.find("AB");
cout << it->first << ' ' << it->second << endl;
其他几个接口很简单这里就不演示了
还有一个接口在map中很关键
operator[]重载

以上是map的底层,结点和迭代器的实现代码,注意它的迭代器返回的是pair对象的指针或者引用
看下面例子
int main()
{map<string, int> M1;string str[] = { "苹果", "苹果", "香蕉", "香蕉", "苹果", "梨子", "梨子", "梨子" };for (auto e : str){map<string, int>::iterator it = M1.find(e);if (it == M1.end()){M1.insert(make_pair(e, 1));}else{it->second++;}}for (const auto& e : M1){cout << e.first << ' ' << e.second << endl;}return 0;
}
如果没有重载operator[]我们只能像上面那种写法一样
使用operator[]更改之后
int main()
{map<string, int> M1;string str[] = { "苹果", "苹果", "香蕉", "香蕉", "苹果", "梨子", "梨子", "梨子" };for (auto e : str) M1[e]++;for (const auto& e : M1) cout << e.first << ' ' << e.second << endl;
}
是不是觉得很神奇
我们来看看operator[ ]它底层是怎么实现的

主要还是理解这段代码
(*((insert(value_type(k, T()))).first)).second我们分开分析一下
1.向map中插入指定元素,因为value_type的T可以是任意类型,所以它给了匿名对象T()
2.insert不管插入成功还是失败都会会返回key所在结点的迭代器和bool值,可以我们先找到它的迭代器 ((insert(value_type(k, T()))).first)
3.找到迭代器之后,我们就可以通过解引用来访问它的value值
对map的总结:
1. map中的的元素是键值对
2. map中的key是唯一的,并且不能修改
3. 默认按照小于的方式对key进行比较
4. map中的元素如果用迭代器去遍历,可以得到一个有序的序列
5. map的底层为平衡搜索树(红黑树),查找效率比较高 O(logN)
6. 支持[]操作符,operator[]中实际进行插入查找。
multimap
multimap的介绍以及使用
官方英文介绍:

中文介绍:
1. Multimaps是关联式容器,它按照特定的顺序,存储由key和value映射成的键值对,其中多个键值对之间的key是可以重复的。
2. 在multimap中,通常按照key排序和惟一地标识元素,而映射的value存储与key关联的内 容。key和value的类型可能不同,通过multimap内部的成员类型value_type组合在一起, value_type是组合key和value的键值对: typedef pair value_type;
3. 在内部,multimap中的元素总是通过其内部比较对象,按照指定的特定严格弱排序标准对 key进行排序的。
4. multimap通过key访问单个元素的速度通常比unordered_multimap容器慢,但是使用迭代 器直接遍历multimap中的元素可以得到关于key有序的序列。
5. multimap在底层用二叉搜索树(红黑树)来实现。
注意:multimap和map的唯一不同就是:map中的key是唯一的,而multimap中key是可以 重复的。
multimap的使用
multimap中的接口可以参考map,功能都是类似的,这里就不细讲了
注意:
1. multimap中的key是可以重复的。
2. multimap中的元素默认将key按照小于来比较
3. multimap中没有重载operator[]操作,在multimap中可以存在多个重复的key值,使用operator会映射出多个不同的value值
4. 使用时与map包含的头文件相同:
相关文章:
【STL】set,multiset,map,multimap的介绍以及使用
关联式容器 在C的STL中包含序列式容器和关联式容器 1.关联式容器:它里面存储的是元素本身,其底层是线性序列的数据结构,比如:vector,list,deque,forward_list(C11)等 2.关联式容器里面储存的…...

新能源二手车交易量有望破百万,二手车市场回暖了吗?
这些年,伴随着新能源汽车市场的高速发展,各种新能源车的二手车也在逐渐增加,不过之前的二手车市场相对比较冷清,就在最近一则新闻传出新能源二手车交易量有望破百万,二手车市场这是回暖了吗? 一、新能源二手…...

哈佛商业评论 | 项目经济的到来:组织变革与管理革新的关键
在21世纪,项目经济(Project Economy)逐步取代传统运营,成为全球经济增长的核心动力。项目已不再是辅助工具,而是推动创新和变革的重要载体。然而,只有35%的项目能够成功,显示出项目管理领域存在巨大的改进空间。本文将详细探讨项目经济的背景、项目管理的挑战,以及适应…...
打开PDF文件不是预览,而是下载文件?)
web浏览器环境下使用window.open()打开PDF文件不是预览,而是下载文件?
如果你使用 window.open() 方法打开 PDF 文件,但浏览器不是预览而是下载文件,这可能是由于以下几个原因: 服务器配置:服务器可能将 PDF 文件配置为下载而不是预览。例如,服务器可能设置了 Content-Disposition 响应头…...

【GeekBand】C++设计模式笔记12_Singleton_单件模式
1. “对象性能” 模式 面向对象很好地解决了 “抽象” 的问题, 但是必不可免地要付出一定的代价。对于通常情况来讲,面向对象的成本大都可以忽略不计。但是某些情况,面向对象所带来的成本必须谨慎处理。典型模式 SingletonFlyweight 2. Si…...

Pyhon基础数据结构(列表)【蓝桥杯】
a [1,2,3,4,5] a.reverse() print("a ",a) a.reverse() print("a ",a)# 列表 列表(list)有由一系列按照特定顺序排序的元素组成 列表是有顺序的,访问任何元素需要通过“下标访问” 所谓“下标”就是指元素在列表从左…...

Linux篇(权限管理命令)
目录 一、权限概述 1. 什么是权限 2. 为什么要设置权限 3. Linux中的权限类别 4. Linux中文件所有者 4.1. 所有者分类 4.2. 所有者的表示方法 属主权限 属组权限 其他权限 root用户(超级管理员) 二、普通权限管理 1. ls查看文件权限 2. 文件…...

深入理解 Spark 中的 Shuffle
Spark 的介绍与搭建:从理论到实践_spark环境搭建-CSDN博客 Spark 的Standalone集群环境安装与测试-CSDN博客 PySpark 本地开发环境搭建与实践-CSDN博客 Spark 程序开发与提交:本地与集群模式全解析-CSDN博客 Spark on YARN:Spark集群模式…...

leetcode-8-字符串转整数
题解: 代码:...
)
SQL注入注入方式(大纲)
SQL注入注入方式(大纲) 常规注入 通常没有任何过滤,直接把参数存放到SQL语句中。 宽字节注入 GBK 编码 两个字节表示一个字符ASCII 编码 一个字节表示一个字符MYSQL默认字节集是GBK等宽字节字符集 原理: 设置MySQL时错误配置…...

OpenCV基础(1)
1.图像读写与窗口显示 1.1.imread读取图像文件 Mat cv::imread(const string &filename,int flags IMREAD_COLOR); filename:要读取的图像文件名flags:读取模式,可以从枚举cv::ImreadModes中取值,默认取值是IMREAD_COLOR&am…...

【freertos】FreeRTOS信号量的介绍及使用
FreeRTOS信号量 一、概述二、PV原语三、函数接口1.创建一个计数信号量2.删除一个信号量3.信号量释放4.在中断释放信号量5.获取一个信号量,可以是二值信号量、计数信号量、互斥量。6.在中断获取一个信号量,可以是二值信号量、计数信号量7.创建一个二值信号…...

React Native 全栈开发实战班 - 图片加载与优化
在移动应用中,图片加载与优化 是提升用户体验和减少资源消耗的重要环节。图片加载不当可能导致应用卡顿、内存泄漏甚至崩溃。本章节将介绍 React Native 中常用的图片加载方法,包括 Image 组件的使用、第三方图片加载库(如 react-native-fast…...

Golang云原生项目:—实现ping操作
熟悉报文结构 ICMP校验和算法: 报文内容,相邻两个字节拼接到一起组成一个16bit数,将这些数累加求和若长度为奇数,则将剩余一个字节,也累加求和得出总和之后,将和值的高16位与低16位不断求和,直…...

mysql如何查看当前事务的事务id
-- 开启一个事务,但不执行写操作 START TRANSACTION; -- 查询 InnoDB 事务信息 SELECT * FROM information_schema.innodb_trx;在 MySQL 的 MVCC (多版本并发控制) 中,事务 ID (Transaction ID) 是由 InnoDB 存储引擎分配的,它的分配机制与事…...

在linux里如何利用vim对比两个文档不同的行数
在Linux中,可以使用vimdiff命令来对比两个文档中不同的行。首先确保你的系统中安装了vim编辑器。 打开终端,使用以下命令来启动vimdiff: vimdiff file1 file2 这里file1和file2是你想要对比的两个文件的路径。 vimdiff会以并排方式打开两…...

深入解析Python中的逻辑回归:从入门到精通
引言 在数据科学领域,逻辑回归(Logistic Regression)是一个非常重要的算法,它不仅用于二分类问题,还可以通过一些技巧扩展到多分类问题。逻辑回归因其简单、高效且易于解释的特点,在金融、医疗、广告等多个…...

【数据库】mysql数据库迁移前应如何备份数据?
MySQL 数据库的备份是确保数据安全的重要措施之一。在进行数据库迁移之前,备份现有数据可以防止数据丢失或损坏。以下是一套详细的 MySQL 数据库备份步骤,适用于大多数情况。请注意,具体的命令和工具可能因 MySQL 版本的不同而有所差异。整个…...

C语言——鸡兔同笼问题
没注释的源代码 #include <stdio.h> #include <stdlib.h> /* run this program using the console pauser or add your own getch, system("pause") or input loop */ int main(int argc, char *argv[]) { int tou 10; i…...

数据结构王道P234第二题
#include<iostream> using namespace std; int visit[MAxsize]; int color[MaxSize];//1表示红,2表示白; bool dfs(Graph G, int i){visit[i]1;ArcNode *p;bool flag1;for(pG.vertices[i].firsrarc; p ; pp->next){int jp->adjvex;if(!visi…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...
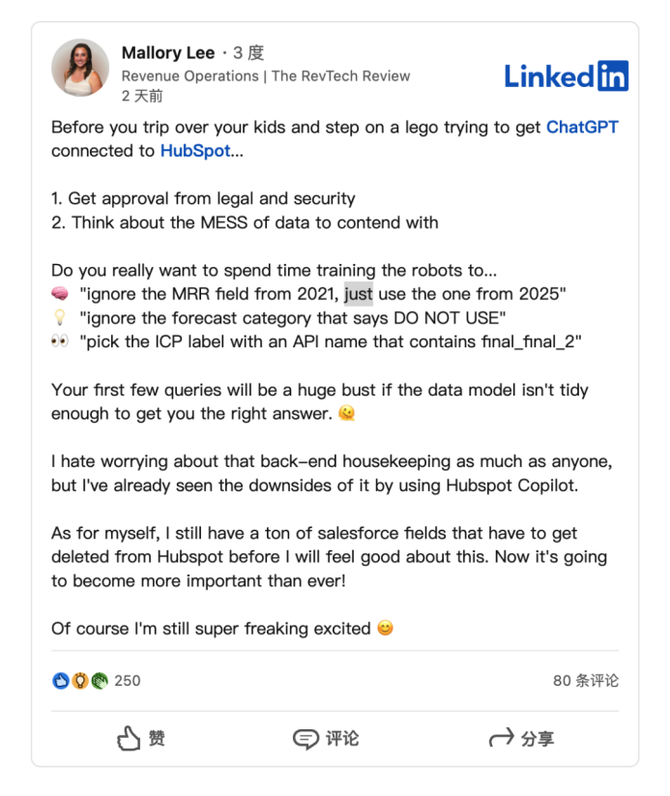
HubSpot推出与ChatGPT的深度集成引发兴奋与担忧
上周三,HubSpot宣布已构建与ChatGPT的深度集成,这一消息在HubSpot用户和营销技术观察者中引发了极大的兴奋,但同时也存在一些关于数据安全的担忧。 许多网络声音声称,这对SaaS应用程序和人工智能而言是一场范式转变。 但向任何技…...

绕过 Xcode?使用 Appuploader和主流工具实现 iOS 上架自动化
iOS 应用的发布流程一直是开发链路中最“苹果味”的环节:强依赖 Xcode、必须使用 macOS、各种证书和描述文件配置……对很多跨平台开发者来说,这一套流程并不友好。 特别是当你的项目主要在 Windows 或 Linux 下开发(例如 Flutter、React Na…...