探索大规模语言模型(LLM)在心理健康护理领域中的应用与潜力
概述
心理健康是公共卫生最重要的领域之一。根据美国国家精神卫生研究所(NIMH)的数据,到 2021 年,22.8% 的美国成年人将患上某种形式的精神疾病。在全球范围内,精神疾病占非致命性疾病负担的 30%,并被世界卫生组织确定为导致残疾的主要原因。此外,据估计,抑郁症和焦虑症每年给全球经济造成 1 万亿美元的损失。这些数据表明,预防和管理心理健康问题是多么重要。
语言交流是心理健康管理的重要组成部分,包括症状评估和谈话治疗。自然语言处理(NLP)是计算机科学的一个分支,它能以有意义的方式处理自由形式的文本信息。其中,大规模语言建模(LLM)技术的进步为心理健康护理领域带来了更多创新可能性。大规模语言模型能有效汇总来自电子健康记录和社交媒体平台的数据,具有识别心理状态和构建情感支持聊天机器人等多种优势。
然而,关于大规模语言模型在心理健康护理中的应用的全面综述尚不存在。本文旨在填补这一空白,首次对该领域进行全面评述。特别是,本文研究了大规模语言模型在过去四年中的演变及其对心理健康护理的影响,重点关注自 2019 年推出 T5 以来开发的模型。
在心理健康护理领域,大规模语言模型凭借其处理大量文本数据和模拟人类互动的能力,有可能协助完成各种任务,如解释行为模式、识别心理压力源和提供情感支持。如果有适当的监管、伦理和隐私保护措施,大规模语言模型还有望为面向临床的任务做出贡献,如支持诊断过程、促进精神障碍管理和加强治疗干预。
技术
本研究按照《系统综述和元分析推荐报告项目》(PRISMA)2020 年版的指导原则,遵循严格透明的流程。下图概述了这一流程。
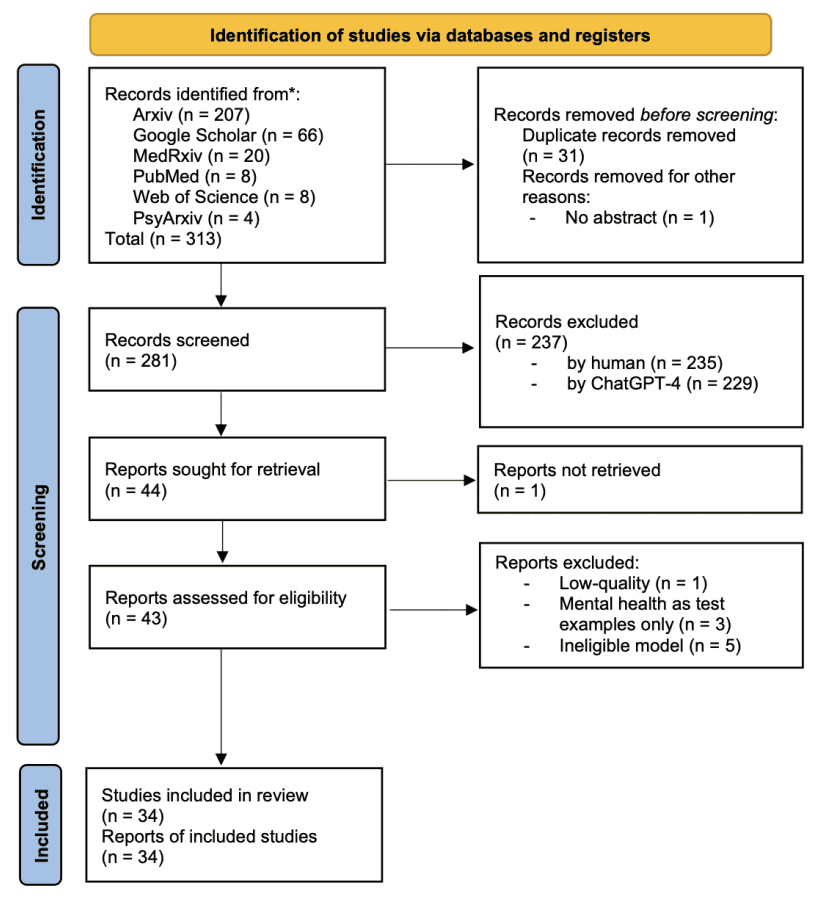
参考文献的选择侧重于最新的研究,其标准是这些研究至少使用了一个自 T5 出版以来发布的大规模语言模型,而且这些模型直接解决了心理健康护理环境中的研究问题。
早期研究发现,与这一主题相关的已发表研究非常有限,尤其是在 PubMed 上。鉴于大规模语言建模的快速发展,研究范围已超出传统的同行评议文献。同行评议和非同行评议研究(如预印本)都包括在内,以捕捉大规模语言建模的最新进展。收录了 2019 年 10 月 1 日至 2023 年 12 月 2 日期间发表的任何形式的原创研究。不设语言限制。
使用关键词 "大型语言模型 "和 "精神或精神病学或心理学 “搜索了多个数据库和登记簿(ArXiv、MedRxiv、ACM 数字图书馆、PubMed、Web of Science、Google Scholar)。心理学”,并在可能的情况下,使用这些关键词的组合进行了广泛的搜索,将搜索范围限制在标题和摘要上,并在不具备此功能的数据库中搜索全文。
在剔除重复文章和非摘要文章后,初步筛选出 281 篇文章。最近的研究表明,GPT-4 可以帮助筛选文章,其表现不亚于人类。因此,GPT-4 被引入作为这一过程的辅助审稿人。在使用之前,我们尝试了不同的提示,以最大限度地提高 GPT-4 的筛选效率。
YH 和 GPT-4 独立审阅文章的标题和摘要,并评估是否应纳入该研究。有三个选项:1(纳入)、0(排除)和 2(不确定)。出现的任何差异都将通过与审稿小组其他成员(YH、KY、ZL、FL)讨论来解决。为了定量评估人类评审员(YH)和人工智能(GPT-4)之间的一致程度,我们计算了科恩卡帕系数(Cohen’s Kappa coefficient),得到了约 0.9024 的高分。这表明双方的意见非常一致:GPT-4 通常比人工审稿人更具包容性,能将更多文章归类为与精神卫生保健相关。不过,"不确定 "选项虽然略微降低了 Kappa 系数,但对于全面收录相关论文非常重要,有助于在全面性和准确性之间取得平衡。
在最终的全文审阅中,选出了43 篇论文。团队成员 YH、KY、ZL 和 FL对所有这些论文进行了仔细审查,并排除了9 篇论文,原因包括论文质量低、仅将心理健康作为测试案例或模型规模不符合标准。具体来说,1 篇论文因质量低而被排除,3 篇论文因精神健康仅作为试验案例而被排除,5 篇论文因模型规模不足而被排除。
在审查过程中,研究报告根据各自的研究问题和目标分为以下几类
- 数据集和基准:使用标准化测试或基准数据集,在受控条件下评估和比较不同方法、系统或模型性能的研究。
- 模型开发和微调:研究提出新的大规模语言模型,并利用微调和提示等方法改进和调整现有的大规模语言模型,用于心理保健。
- 应用与评估:在实际应用中评估大规模语言模型在心理健康相关任务中的性能的研究。还包括在特定任务中评估大规模语言模型的案例(仅推理)。
- 伦理、隐私和安全考虑因素:一项研究,探讨在敏感的心理健康环境中部署大规模语言模型可能带来的风险、伦理困境和隐私问题,并提出缓解这些问题的框架和指导原则。
符合这一标准的 34 篇论文是后面分析的主题。为了将重点放在研究问题的应用上,并确保分析的全面性,"数据集和基准 "中的研究将单独总结。
结果概述
下图显示了纳入最终分析的出版物和呈文的时间和类型。如图所示,有关心理健康护理中大规模语言模型的研究出现在 2022 年 9 月,发表量逐渐增加,10 月尤其明显激增。
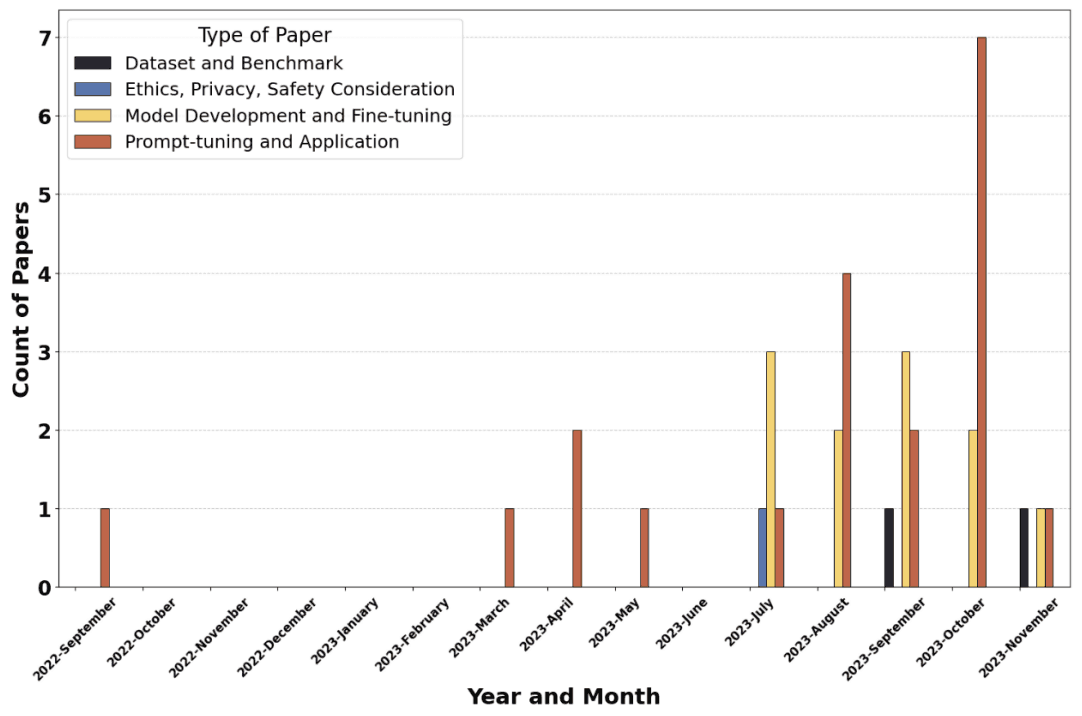
这些研究大多侧重于 “及时调整和应用”,从 7 月份开始增加。另一方面,关于 "模型开发和微调 "的研究在年初很少,10 月份开始明显增加。本年度仅发表了两篇关于 "数据集和基准 "的研究,年中仅发表了一篇关于伦理、隐私和其他问题的研究。
应用领域和相关的精神健康状况
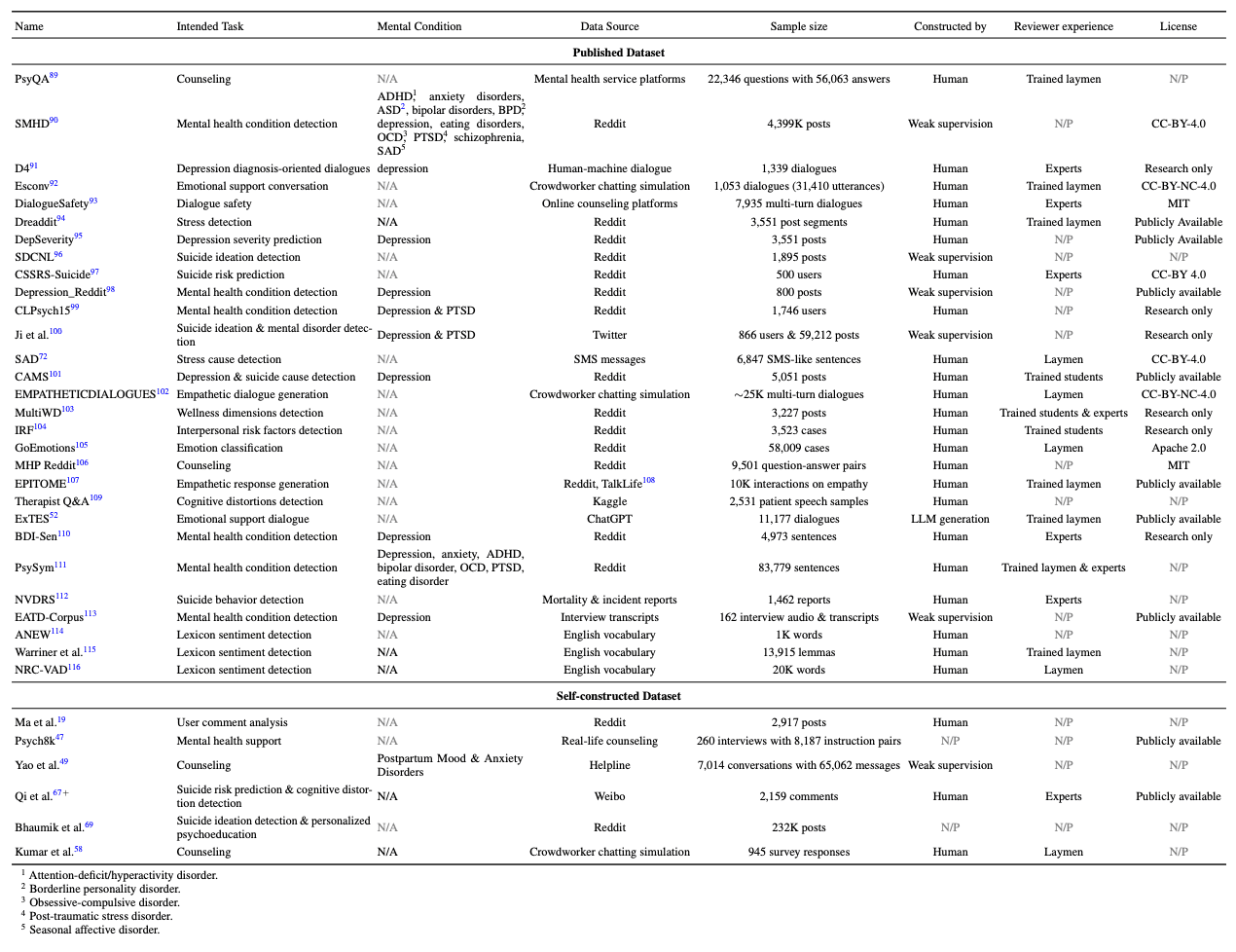
在整个审查过程中,我们发现研究范围与研究数据集之间存在紧密联系。本节概述了这些研究的应用领域及其所针对的心理健康问题。下表详细概述了这些研究中使用的数据集,并详细说明了其预期用途。
应用领域和相关的精神健康状况
2022 年 9 月,精神卫生保健领域对大规模语言模型(LLM)的研究初具规模。发表的研究报告数量逐渐增加,10 月份的高峰尤为明显。图 2 显示了这一趋势,这些研究集中于 “及时调整和应用”,其数量从 7 月份开始增加。与此相反,关于 "模型开发和微调 "的研究在年初基本没有,而在 10 月份出现了显著增长。此外,今年晚些时候只出现了两份关于 "数据集和基准 "的研究报告。年中只发表了一项关于伦理、隐私和其他问题的研究。
与心理健康护理相关的大规模语言模型研究涉及三个主要领域:首先是开发对话代理,旨在提高模型生成移情和情境感知响应的能力。这些代理可满足广泛的心理健康需求,而不是针对特定的精神障碍。它还包括旨在通过各种平台(如个人数字伴侣、按需在线咨询和情感支持)与寻求支持的人直接互动的研究。一些研究扩展到了特定的应用领域,如夫妻治疗。其他研究提供了具体的建议和分析,以支持护理提供者并缓解提供者短缺的问题。
第二个领域的研究旨在丰富资源。这包括多任务分析和教育内容的开发,如创建虚拟病例小故事和与社会精神病学相关的个性化心理教育材料。此外,大规模语言模型提供的合成数据正被用于扩充数据和微调临床问卷,以丰富抑郁症的症状。
在第三个领域,大规模语言模型被用作详细诊断的分类模型。这通常涉及二元分类和多类分类,前者可检测特定语境中是否存在单一病症,后者则包括有关病症、严重程度和亚型的更详细信息。
多级分类的例子包括预测抑郁症的严重程度(根据 DSM-5,分为轻微、轻度、中度和重度)、自杀的亚型(根据哥伦比亚自杀严重程度评定量表(C-SRS),分为支持、指标、想法、行为和企图)以及确定压力来源(学校、经济、家庭和社会关系,根据 SAD 确定基于 SAD)包括
在所审查的 34 篇文章中,有 23 篇侧重于特定的心理健康问题,其余的文章则探讨了一般的心理健康知识和对话,没有涉及特定的情况。关于特定心理健康问题的研究涵盖了一系列心理健康问题,包括压力、自杀和抑郁等经常被研究的问题。
模型和学习技术
为了深入了解大规模语言模型在精神卫生保健领域的发展和应用,本文将重点关注模型和训练技术。预训练模型的有效性在很大程度上取决于训练数据、规模以及是否开源等基本因素。这些因素共同决定了模型对于特定任务或人群的代表性或潜在偏差。
下表列出了为心理健康护理开发的现有大规模语言模型的摘要。该摘要包括基础模型的详细信息、以参数数量表示的模型规模、基础模型训练数据的透明度、训练过程中采用的策略以及开放源代码的可访问性信息。B "代表十亿。TFP 和 IFT 分别代表"免调提示 "和 “指令微调”。
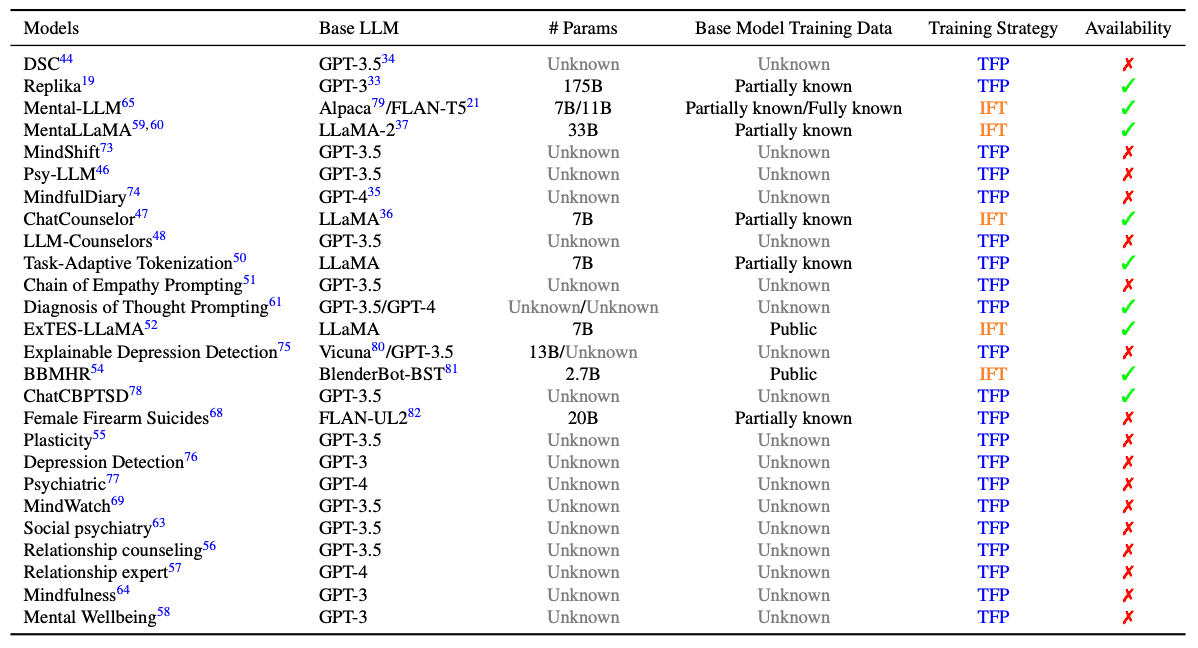
许多研究都是由 GPT-3.5 和 GPT-4 等模型直接推动的,这些模型专门用于抑郁检测、自杀检测、认知扭曲检测和关系咨询等心理健康应用。这些模型就像智能聊天机器人一样,提供广泛的心理健康服务,包括分析、预测和支持。为了提高有效性,我们使用了四射提示和思维链(CoT)提示等方法。这些都是在大规模语言模型中生成人类情绪认知推断的新方法。
一些研究还侧重于利用心理健康特定文本进一步训练或微调通用大规模语言模型。这种方法旨在将心理健康知识注入现有的大规模语言模型中,使其在分析和支持方面更具相关性和准确性;MentaLLaMA 和 Mental-LLM 等项目利用社交媒体数据来训练 LLaMA-2模型和 Alpaca/FLAN-T 模型来改进心理健康预测;ChatCounselor 正在使用包括客户与心理学家之间真实互动的 Psych8k 数据集来微调 LLaMA 模型。.
在微调方面,鉴于从头开始训练大型语言模型成本高、时间长,现有研究一直采用在心理健康数据上微调现有模型的方法。其目的是在心理健康数据上增强现有模型。这种方法可以让模型获得专门的领域知识,并发展成为以心理健康为重点的大型语言模型。所有采用微调技术的研究都采用了指导性微调(IFT)技术。指导性微调(IFT)技术是一种新型的微调技术,可指导模型执行任务。这种方法将领域知识注入大规模语言模型,以提高模型遵循人类指令的能力。例如,ChatCounselor 根据客户与心理学家的对话向 GPT-4 发出指令,以生成特定的输入和输出。这样,大规模语言模型就能更恰当地应用于心理健康护理领域。
数据集特征。
数据完整性在心理健康护理领域的研究中发挥着重要作用。特别是,数据集的代表性、质量和潜在偏差会对研究成果产生重大影响,因此准确了解数据集的来源和特征对于获得公平的研究成果至关重要。本文将详细回顾所使用的数据集,并在下表列出其相关任务、数据来源、样本大小、注释方法、人类审阅者经验和许可证。
所审查的 34 项研究确定了 36 个数据集,其中包含适用于心理保健任务的各种数据。大多数数据集专门用于检测和分类任务,包括检测抑郁症和创伤后应激障碍(PTSD)、识别应激原因和预测人际关系风险因素。还有一个小组专注于文本生成任务,如模拟咨询会话、回复医疗询问和生成共情对话。其他专业应用包括对大规模情感支持语言模型的用户论点分析和对话安全探索。
数据集通常从 Reddit、Twitter 和微博等社交媒体平台收集,有些数据集来自受控地点,但也有由 LLM 合成的数据、现有的情感字典和由人群工作者模拟的数据其他来源的模拟对话等。
数据集的规模和单位因数据来源和注释方法而异,由专家内容组成的数据集往往样本量较小。大多数数据集是通过人工收集和注释生成的,也有一些研究使用了弱监督学习。大多数数据集都经过了专家审查,许多研究依赖于公开可用的数据集,还有一些数据集是独立构建的,但根据仅限于非商业使用的许可发布。
核查指数
验证指标的选择对于有效、公平地评估大规模语言模型(LLM)至关重要。本文分析了两类评估:自动评估和人工评估。下表总结了用于自动评估的指标,并详细说明了用于人工评估的属性。本文从语言能力和心理健康适用性两个角度对这些指标进行了进一步分类,并讨论了每个指标的适当性。
在心理健康适用性方面,不同形式的 F1 分数是最常用的指标。同样,准确度也被广泛用作基本指标。召回率(灵敏度)和精确度(准确度)也被广泛使用,通常与 F1 分数和准确度一起使用。针对特定诊断的研究还采用了其他指标,如受体操作特征(AUROC)和特异性(Specificity),以全面了解大规模语言模型的诊断有效性。
BLEU、ROUGE、Distinct-N 和 METEOR 等指标被广泛用于评估类似人类语言的一致性、表达的多样性和生成文本的质量;GPT3-Score、BARTScore 和 BERT-Score 等高级指标旨在评估特定语境下文本的语义连贯性和相关性。GPT3-Score、BARTScore 和 BERT-Score 等高级指标旨在评估特定语境中文本的语义连贯性和相关性。Perplexity 用于评估模型的可预测性和文本的自然度,而 Extrema 和 Vector Extrema 则反映了模型的语言创造性和深度。之所以使用这些传统的语言评估指标,是因为缺乏高效、易懂的自动指标来评估心理健康护理中大规模语言模型的自由文本生成质量。因此,许多研究经常采用人工评估。
在所审查的 34 项研究中,19 项结合使用了自动评级和人工评级,5 项仅使用了人工评级,其余 10 项仅依赖于自动方法。然而,目前还没有一个广为接受的统一评估框架,虽然有些研究采用或调整了已公布的评估标准或以往研究中讨论过的属性,但这些框架并未被广泛采用。共鸣、相关性、流畅性、理解力和实用性等属性经常被用于评估用户参与和技术采用等方面,特别是在干预应用中。有些属性虽然名称相同,但在不同的研究中可能有不同的定义。例如,"信息量 "可能与大规模语言模型中响应的丰富程度有关,也可能衡量个人对情绪困扰的详细描述程度。专家评分侧重于对模型输出和专家问卷评分的直接分析。可靠性指标的使用对于验证研究方法非常重要,审核者的人数从 3 到 50 不等。
问题
在心理健康护理中使用大规模语言模型 (LLM) 所涉及的隐私问题是整个研究过程中特别关注的问题。心理健康护理应用程序所处理的敏感数据的性质尤其突出了这一点。有几项研究强调了敏感数据暴露的风险以及严格的数据保护和道德标准的必要性。安全性和可靠性也是基本要求,重点是防止产生有害内容,确保提供准确和相关的回复。
在利用大规模语言模型的优势的同时,还要注重确保安全的重要平衡,重点是不断追求心理健康支持方面的风险评估、可靠性和一致性 关切日益依赖人工智能可能导致忽视和过度依赖现实生活中的互动.含有不准确或偏见的内容会对心理健康背景下的认知和决策产生严重影响。
技术和性能方面的挑战包括从模型限制和泛化问题到内存和上下文限制。这些问题尤其会影响人工智能应用在复杂现实世界环境中的可靠性和有效性。对性能可变性、稳健性和透明度的需求是一个需要不断创新和审查的领域。
转向现实世界的应用带来了更多的复杂性,尤其是在要求准确性和敏感性的心理健康领域。长期效应、实验室与现实环境之间的差异、可及性和数字差异等挑战说明了缩小大规模语言模型的潜力与其实际应用之间的差距所面临的挑战。
多样化和广泛的数据集、专业培训和数据注释的重要性也得到了强调。这些都是以负责任的方式推动该领域发展的关键因素。大规模计算资源和专家参与也被认为是取得进展的基本要素。
审查还包括基准研究,以客观评估大规模语言模型在心理保健方面的有效性,并确定需要改进的领域。目前已进行了两项基准研究,对 GPT-4、GPT-3.5、Alpaca、Vicuna 和 LLaMA-2 等模型在诊断预测、情绪分析、语言建模和问题解答等各种任务中的表现进行了全面评估。数据来自社交媒体和治疗过程。 Qi 等人的研究特别关注利用中国社交媒体数据对认知扭曲进行分类和预测自杀风险,对 ChatGLM2-6B 和 GPT-3.5 等模型进行了评估。
总结
这是自 2019 年推出 T5 模型以来,首次全面回顾大规模语言模型(LLM)在精神卫生保健领域的发展历程;它仔细研究了 34 项相关研究,全面概述了这些模型的各种特点、方法、数据集、验证指标、应用领域,并对具体的精神卫生问题进行了全面总结。全面总结了各种特点、方法、数据集、验证指标、应用领域和具体的心理健康问题。本综合综述旨在成为计算科学界与心理健康界之间的桥梁,并广泛分享所获得的见解。
大规模语言模型是在自然语言处理(NLP)领域表现卓越的算法。这些模型非常符合心理健康相关任务的要求,有可能成为该领域的基础工具。然而,尽管有人认为大规模语言模型可能有助于改善心理健康护理,但目前的技术水平与其实际临床应用性之间仍存在巨大差距。
因此,本文提出了以下改进方向,以最大限度地发挥大规模语言模型在临床实践中的潜力。
- 提高数据质量:用于开发和验证大规模语言模型的数据质量对其有效性有直接影响。提示调整是目前采用的主要方法,但 GPT-3.5 和 GPT-4 等模型在复杂的心理健康环境中偶尔会出现不尽如人意的情况。为了应对这些挑战,有必要探索开源大规模语言模型的微调技术。
- 加强推理和换位思考:心理健康护理中以对话为基础的任务需要高级推理和换位思考技能,以分析用户的陈述并提供适当的反馈。缺乏评估这些能力的统一框架正在影响整个领域的发展。
- 隐私、安全和道德/法规合规性:将大规模语言模型应用于心理健康应用时,严格遵守患者隐私、安全和道德标准至关重要。必须确保遵守数据保护法规、模型透明度和知情同意。
本综述强调了在心理健康护理中使用大规模语言模型的技术现状和未来潜力。技术进步、评估标准的标准化以及在伦理使用方面的合作是促进该领域取得进一步进展的关键。希望这将使大规模语言模型在支持心理健康护理方面充分发挥其潜力。
注:
论文地址:https://arxiv.org/abs/2401.02984
相关文章:
探索大规模语言模型(LLM)在心理健康护理领域中的应用与潜力
概述 心理健康是公共卫生最重要的领域之一。根据美国国家精神卫生研究所(NIMH)的数据,到 2021 年,22.8% 的美国成年人将患上某种形式的精神疾病。在全球范围内,精神疾病占非致命性疾病负担的 30%,并被世界…...

Infisical开源密钥管理平台实战指南
1. 引言 在现代软件开发中,安全地管理环境变量和敏感信息已成为一个关键挑战。Infisical作为一个开源的密钥管理平台,为这一问题提供了强大而灵活的解决方案。本指南将深入探讨Infisical的功能,并通过实际操作步骤,帮助读者全面了解和使用这个工具。 2. Infisical概述 I…...

AI大模型:重塑软件开发流程与模式
人工智能技术的飞速发展,尤其是AI大模型的兴起,正以前所未有的速度和深度影响着各行各业,其中软件开发领域尤为显著。AI大模型,如GPT系列、BERT、Claude等通过其强大的自然语言处理能力、代码理解和生成能力,正在从根本…...

AMD(Xilinx) FPGA配置Flash大小选择
目录 1 FPGA配置Flash大小的决定因素2 为什么选择的Flash容量大小为最小保证能够完成整个FPGA的配置呢? 1 FPGA配置Flash大小的决定因素 在进行FPGA硬件设计时,选择合适的配置Flash是我们进行硬件设计必须考虑的,那么配置Flash大小的选择由什…...
基于Java Springboot图书借阅系统
一、作品包含 源码数据库设计文档万字PPT全套环境和工具资源部署教程 二、项目技术 前端技术:Html、Css、Js、Vue、Element-ui 数据库:MySQL 后端技术:Java、Spring Boot、MyBatis 三、运行环境 开发工具:IDEA/eclipse 数据…...

DDRPHY数字IC后端设计实现系列专题之数字后端floorplanpowerplan设计
3.2.3 特殊单元的布局 布图阶段除了布置 I/O 单元和宏单元,在 28nm 制程工艺时,还需要处理两种特 殊的物理单元,Endcap 和 Tapcell。 DDRPHY数字IC后端设计实现系列专题之后端设计导入,IO Ring设计 (1)拐…...

【Mysql】Mysql函数(上)
1、概述 在Mysql中,为了提高代码重用性和隐藏实现细节,Mysql提供了很多函数。函数可以理解为封装好的模块代码。 2、分类 在Mysql中,函数非常多,主要可以分为以下几类: (1)聚合函数 …...

Java连接MySQL(测试build path功能)
Java连接MySQL(测试build path功能) 实验说明下载MySQL的驱动jar包连接测试的Java代码 实验说明 要测试该情况,需要先安装好MySQL的环境,其实也可以通过测试最后提示的输出来判断build path是否成功,因为如果不成功会直…...

卡尔曼滤波器
卡尔曼滤波器概述 卡尔曼滤波器(Kalman Filter)是一种递归的最优估计方法,广泛应用于信号处理、控制理论、导航定位等领域。它基于线性动态系统模型,通过观测数据不断更新系统的状态估计,从而使得估计值能够在噪声干扰…...

基于BERT的情感分析
基于BERT的情感分析 1. 项目背景 情感分析(Sentiment Analysis)是自然语言处理的重要应用之一,用于判断文本的情感倾向,如正面、负面或中性。随着深度学习的发展,预训练语言模型如BERT在各种自然语言处理任务中取得了…...

推荐15个2024最新精选wordpress模板
以下是推荐的15个2024年最新精选WordPress模板,轻量级且SEO优化良好,适合需要高性能网站的用户。中文wordpress模板适合搭建企业官网使用。英文wordpress模板,适合B2C网站搭建,功能强大且兼容性好,是许多专业外贸网站的…...

AWTK-WIDGET-WEB-VIEW 实现笔记 (2) - Windows
在 Windows 平台上的实现,相对比较顺利,将一个窗口嵌入到另外一个窗口是比较容易的事情。 1. 创建窗口 这里有点需要注意: 父窗口的大小变化时,子窗口也要跟着变化,否则 webview 显示不出来。创建时窗口的大小先设置…...

Linux四剑客及正则表达式
正则表达式 基础正则(使用四剑客命令时无需加任何参数即可使用) ^ # 匹配以某一内容开头 如:^grep匹配所有以grep开头的行。 $ # 匹配以某一内容结尾 如:grep$ 匹配所有以grep结尾的行。 ^$ # 匹配空行。 . # 匹配…...
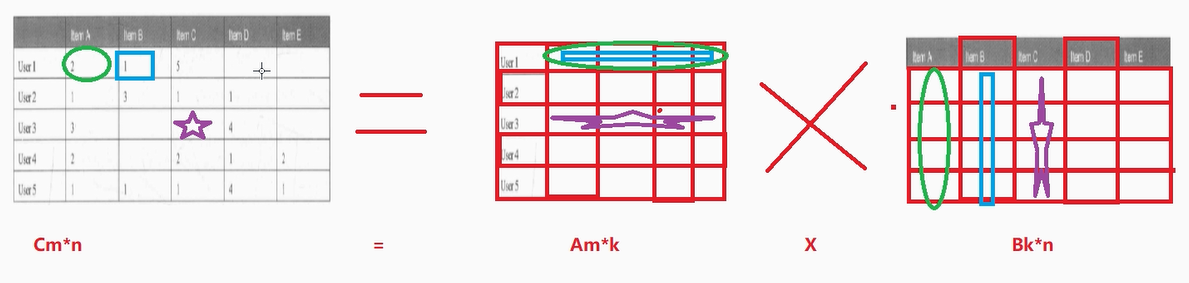
ALS 推荐算法案例演示(python)
数学知识补充:矩阵 总结来说: Am*k X Bk*n Cm*n ----至于乘法的规则,是数学问题, 知道可以乘即可,不需要我们自己计算 反过来 Cm*n Am*k X Bk*n ----至于矩阵如何拆分/如何分解,是数学问题,知道可以拆/可以分解即可 ALS 推荐算法案例:电影推…...

labview中连接sql server数据库查询语句
当使用数据库查询功能时,我们需要用到数据库的查询语句,这里已调用sql server为例,我们需要按照时间来查询,这里在正常调用数据库查询语句时,我们需要在前面给他加一个限制条件这里用到了,数据库的查询语句…...

leetcode_二叉树最大深度
对二叉树的理解 对递归调用的理解 对内存分配的理解 基础数据结构(C版本) - 飞书云文档 每次函数的调用 都会进行一次新的栈内存分配 所以lmax和rmax的值不会混在一起 /*** Definition for a binary tree node.* struct TreeNode {* int val;* …...

Elasticsearch 重建索引 数据迁移
Elasticsearch 重建索引 数据迁移 处理流程创建临时索引数据迁移重建索引写在最后 大家都知道,es的索引创建完成之后就不可以再修改了,包括你想更改字段属性或者是分词方式等。那么随着业务数据量的发展,可能会出现需要修改索引,或…...

2411rust,异步函数
原文 Rust异步工作组很高兴地宣布,在实现在特征中使用异步 fn的目标方面取得了重大进度.将在下周发布稳定的Rust1.75版,会包括特征中支持impl Trait注解和async fn. 稳定化 自从RFC#1522在Rust1.26中稳定下来以来,Rust就允许用户按函数的返回类型(一般叫"RPIT")编…...

前端网络性能优化问题
DNS预解析 DNS 解析也是需要时间的,可以通过预解析的⽅式来预先获得域名所对应的 IP。 <link rel"dns-prefetch" href"//abcd.cn"> 缓存 强缓存 在缓存期间不需要请求, state code 为 200 可以通过两种响应头实现&#…...
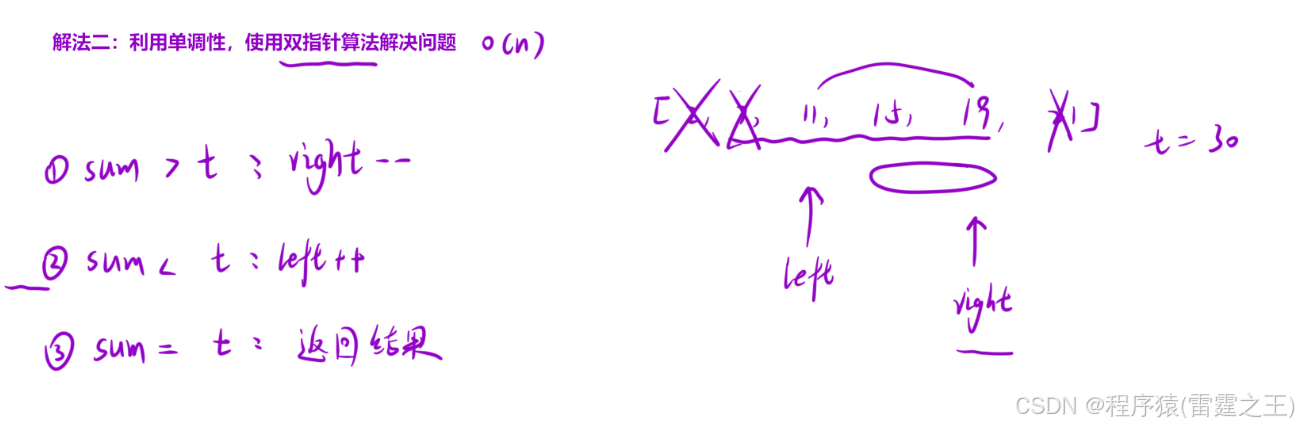
优选算法——双指针
前言 本篇博客为大家介绍双指针问题,它属于优选算法中的一种,也是一种很经典的算法;算法部分的学习对我们来说至关重要,它可以让我们积累解题思路,同时也可以大大提升我们的编程能力,本文主要是通过一些题…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

接口自动化测试:HttpRunner基础
相关文档 HttpRunner V3.x中文文档 HttpRunner 用户指南 使用HttpRunner 3.x实现接口自动化测试 HttpRunner介绍 HttpRunner 是一个开源的 API 测试工具,支持 HTTP(S)/HTTP2/WebSocket/RPC 等网络协议,涵盖接口测试、性能测试、数字体验监测等测试类型…...

省略号和可变参数模板
本文主要介绍如何展开可变参数的参数包 1.C语言的va_list展开可变参数 #include <iostream> #include <cstdarg>void printNumbers(int count, ...) {// 声明va_list类型的变量va_list args;// 使用va_start将可变参数写入变量argsva_start(args, count);for (in…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...