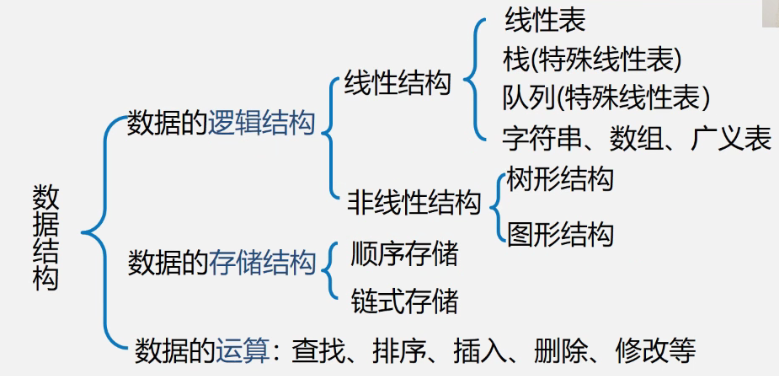
【数据结构与算法】查找
文章目录
- 一.查找
- 二.线性结构的查找
- 2.1顺序查找
- 2.2折半查找
- 2.3分块查找
- 三.树型结构的查找
- 3.1二叉排序树
- 1.定义
- 2.二叉排序树的常见操作
- 3.性能分析
- 3.2平衡二叉树
- 1.定义
- 2.平衡二叉树的常见操作
- 3.性能分析
- 3.3B树
- 1.定义
- 2.B树的相关操作
- 3.4B+树
- 1.定义
- 2.B树与B+树的比较
- 四.散列表
- 1.哈希函数的构造
- 1.常用构造方法
- 2.冲突处理
- 2.哈希表的查找

一.查找
问题:在哪里找?
——查找表
查找表(Search Table):是由同一类型的数据元素(或记录)构成的集合。由于“集合”中的数据元素之间存在着松散的关系,因此查找表是一种应用灵便的结构:我们可以根据需要把这些数据存成线性表,可以存成树表,或者是散列表。
那么,到底怎么存呢?
——取决于怎么做会使查找更方便
而查找的方法取决于查找表的结构,即表中数据元素是依何种关系组织在一起的。
静态查找表(Static Search Table):只作查找操作的查找表。
- 主要操作
- 查询某个“特定的”数据元素是否在查找表中。
- 检索某个“特定的”数据元素和各种属性。
动态查找表(Dynamic Search Table): 在查找过程中同时插入查找表中不存在的数据元素,或者从查找表中删除已经存在的某个数据元素。
- 主要操作
- 查找时插入不存在的数据元素。
- 查找时删除已存在的数据元素。
关键字(Key):数据元素中唯一标识该元素的某个数据项的值,使用基于关键字的查找,查找结果应该是唯一的。例如,在由一个学生元素构成的数据集合中,学生元素中“学号”这一数据项的值唯一地标识一名学生。
- 主关键字:可以唯一地标识一个记录的关键字是主关键字;
- 次关键字:反之,用以识别若干记录的关键字好死次关键字
问题:查找成功否?
查找(Searching):就是根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素( 或记录)。
- 若查找表中存在这样一个记录,则称“查找成功”。查找结果给出整个记录的信息,或指示该记录在查找表中的位置。
- 否则称“查找不成功”。查找结果给出“空记录”或“空指针”。

平均查找长度是衡量查找算法效率的最主要的指标。
问题:查找目的是什么?
——对查找表经常进行的操作。
为了提高查找效率,一个办法就是在构造查找表时,在集合中的数据元素之间人为地加上某种确定的约束关系。所以下面来研究查找表的各种组织方法及其查找过程的实施。
二.线性结构的查找
2.1顺序查找
【查找过程】从表的一端开始,依次将记录的关键字和给定值进行比较,若某个记录的关键字和给定值相等,则查找成功;反之,若扫描整个表后,仍未找到关键字和给定值相等的记录,则查找失败。
【应用范围】顺序查找既适用于顺序表,也适用于链表(链表表示的静态查找表)。若用顺序表,查找可以从前往后扫描,也可以从后往前扫描,但若采用单链表,则只能从前往后扫描。
【查找算法】 在顺序表L中查找值为 key 的数据元素。
//顺序表数据元素类型定义
typedef struct{KeyType key; //关键字域..... //其他域
}ElemType;
//顺序表结构类型定义
typedef struct{ElemType *R;//表基址int length; //表长
}SSTable; //Sequential Search Table
SSTable ST;//定义顺序表STint LocateELem(SSTable ST,KeyType key){ //若成功返回其位置信息,否则返回0for (i=0;i< ST.length;i++)if (ST.elem[i]==e) return i+1; return 0;
}//查找的其他形式:
int LocateELem(SSTable ST,KeyType key){ //若成功返回其位置信息,否则返回0for (i=0;ST.R[i].key!=key && i<ST.length;i++);//一次循环,两次比较if(i>0)return i;else return 0;
}
【性能分析】
时间复杂度:①查找成功时的平均查找长度(设表中各记录查找概率相等)
ASLs(n)=(1+2+ … +n)/n =(n+1)/2;
②查找不成功时的平均查找长度ASLf =n+1。
每执行一次循环都要进行两次比较,是否能改进呢?
【算法改进】 把待查关键字key存入表头(“哨兵”),从后向前逐个比较,可免去查找过程中每一步都要检测是否查找完毕,加快速度。

/*有哨兵顺序查找*/
int Sequential_Search(SSTable ST,KeyType key){ST.R[0].key = key; //把关键字放在下标为0的位置,称之为“哨兵”for (i=0;ST.R[i].key!=key && i<ST.length;i++);return i;}
这种在查找方向的尽头放置“哨兵”免去了在查找过程中每一次比较后都要判断查找位置是否越界的小技巧,看似与原先差别不大,但在总数据较多时,效率提高很大,是非常好的编码技巧。
上述顺序表查找时间复杂度是O ( n );空间复杂度是O(1)(多了一个哨兵)
【算法特点】 算法简单,对表结构无任何要求(顺序和链式),但n很大时查找效率较低;ASL太长,时间效率太低。
【改进措施】 非等概率查找时,可按照查找概率进行排序。
那么,记录的查找概率不相等时如何提高查找效率?
查找表存储记录原则——按查找概率高低存储:
(1)查找概率越高,比较次数越少,放在靠后的位置;
(2)查找概率越低,比较次数较多,放在靠前的位置。
记录的查找概率无法测定时如何提高查找效率?
——按查找概率动态调整记录顺序:
(1)在每个记录中设一个访问频度域;
(2)始终保持记录按非递增有序的次序排列;
(3)每次查找后均将刚查到的记录直接移至表头。
有序表查找有折半查找,插值查找,斐波那契查找,这里介绍折半查找:
2.2折半查找
折半查找(Binary Searh) 也称二分查找,它是一种效率较高的查找方法。
【应用范围】 折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列(递增或递减);不宜用于链式结构。
【查找过程】 从表的中间记录开始,如果给定值和 中间记录的关键字相等, 则查找成功;如果给定值大于或者小于中间记录的关键字, 则在表中大于或小于中间记录的那一半中查找,这样重复操作,直到查找成功,或者在某一步中查找区间为空(low>high),则代表查找失败。
例如,对序列5、13、19、21、37、56、64、75、80、88、92中查找21过程如下:
①初时,low=1,mid=(1+11)/2=6 ,high=11

②此时.r[mid].key>21,因此 high=mid-1=5,low=1,mid=(1+5)/2=3

③此时.r[mid].key<21,因此 low=mid+1=4,high=5,mid=(4+5)/2=4

④此时,k=R[mid].key,查找成功。
【算法思想】 非递归算法 设表长为n,low、high和mid分别指向待查元素所在区间的上界、下界和中点,k为给定值。 初始时,令low=1,high=n,mid=(low+high)/2让k与mid指向的记录比较:
①若k==R[mid].key,查找成功;
②若k<R[mid].key,则high=mid-1;
③若k>R[mid].key,则low=mid+1。重复上述操作,直至low>high时,查找失败。
【算法描述】
//采用折半查找发在顺序表上进行查找
int Search_Bin(SSTable ST,KeyType key){
//若找到,则函数值为该元素在表中的位置,否则为0low=1;high=ST.length; //置区间初值 while(low<=high){mid=(low+high)/2;//取中间位置if(key==ST.R[mid].key)return mid;//查找成功返回所在位置else if(key<ST.R[mid].key) //缩小查找区间high=mid-1; //从前半部分继续查找else low=mid+1; //从后半部分继续查找} return 0; //表中不存在待查元素
}
下面来看一下同一种操作的不同算法——递归算法:每一次判断是否与中间位置相等
int Search_Bin(SSTable ST,KeyType key,int low,int high){if(low>high)return 0;//区间不存在,查找不到是返回0mid=(low+high)/2;if(key==ST.elem[mid].key)return mid;else if(key<ST.elem[mid].key){high=mid-1;Search_Bin(SSTable ST,key,low,high)//递归,在前半区间进行查找}else{low=mid+1;Search_Bin(SSTable ST,key,low,high)//递归,在前半区间进行查找}
}
【性能分析】 折半查找使用判定树进行分析。该判定树是一颗二叉排序树,中序有序。判定树的构造过程为:
第一次,进行mid计算时的结点作为根节点,并进行low结点位置和high结点的位置进行计算,作为mid的左右孩子;将前一子表(low-mid)、后一子表(mid-high)分别重复上述步骤,直至所有结点都在判定树中。
如下,对序列5、13、19、21、37、56、64、75、80、88、92进行判定树构造,查找21 如下:

(图中有错误:二叉树的深度为⌈ l o g_2 ( n + 1 ) ⌉ )
所以,折半查找的时间复杂度为O ( l o g_2 n ) ,平均情况下比顺序查找的效率高。
- 假定每个元素的查找概率相等,求查找成功时的平均查找长度。

对比顺序查找法的平均查找长度是(11+1)/2=6,折半查找法减少了很多,因为折半查找法的时间效率是对数级的,而顺序查找法的时间效率是线性级的。
时间复杂度:查找成功时的平均查找长度(设表中各记录查找概率相等:P_i=1/n)
设表长n=2h-1,则h=log_2(n+1)(此时,判定树为深度=h的满二叉树):

利用二叉树的性质,将一个一个(n个)的元素比较转化为一层一层(j层)的结点的比较
【算法特点】
①优点:效率比顺序查找高。
②缺点:只适用于有序表,且限于顺序存储结构(对线性链表无效:找不到mid)。
线性索引查找有稠密索引,分块索引和倒排索引,下面介绍分块索引:

2.3分块查找
【应用范围】如果线性表既要快速查找又经常动态变化,则可采用分块查找。
条件:①分块有序,即分成若干子表,要求每个子表中的数值都比后一块中数值小(但子表内部未必有序)。
②然后将各子表中的最大关键字构成一个索引表,表中还要包含每个子表的起始地址(即头指针)。

【查找过程】
① 先确定待查记录所在快,对索引表使用折半查找法(因为索引表是有序表);
② 再在块内查找,在子表内采用顺序查找法(因为各子表内部是无序表);
【查找算法】 分块查找的算法为顺序查找和折半查找两种算法的简单合成。
【性能分析】

【优缺点】
①优点:插入和删除比较容易,无需进行大量移动。
②缺点:要增加一个索引表的存储空间并对初始索引表进行排序运算。
总结

三.树型结构的查找
线性表的查找更适用静态查找表,当表插入,删除操作频繁时,为维护表的有序性,需要移动表中很多记录,可采用几种特殊的二叉树作为查找表的组织形式,在此将它们统称为树表。表结构在查找过程中动态生成:对于给定值key,若表中存在则成功返回;否则,插入关键字等于key的记录。
根据用途不同动态查找表又分为很多种:二叉排序树,平衡二叉树,红黑树,B树,B+树,键树等。
3.1二叉排序树
1.定义
二叉排序树 (Binary Sort Tree) 又称二叉查找树,二叉搜索树,它是一种对排序和查找都很有用的特殊二叉树。
【性质】二叉排序树或是空树,或是满足如下性质的二叉树:
①若其左子树非空,则左子树上所有结点的值均小于根结点的值;
②若其右子树非空,则右子树上所有结点的值均大于等于根结点的值;
③其左右子树本身又各是一棵二叉排序树

易错:注意是“所有”,例如,下图所示树不是二叉排序树

【特点】 中序遍历二叉排序树得到一个关键字的递增有序序列。
下面来了解一下二叉树的操作:
2.二叉排序树的常见操作
(1)查找
【算法思想】 二叉排序树上进行递归算法的思想
(1)若二叉排序树为空,则查找失败,返回空指针。
(2)若二叉排序树非空,将给定值key与根结点的关键字T->data.key进行比较:
① 若key等于T->data.key,则查找成功,返回根结点地址;
② 若key小于T->data.key,则进一步查找左子树;
③ 若key大于T->data.key,则进一步查找右子树。
【算法描述】
//二叉排序树的存储用二叉链表
typedef struct{KeyType key; //关键字项InfoType otherinfo; //其他数据域
}ElemType;
typedef struct BSTNode{ElemType data; //数据域struct BSTNode *Ichild,*rchild; //左右孩子指针
}BSTNode,*BSTree;
BSTree T; //定义二叉排序树TBSTree SearchBST(BSTree T,KeyType key) {if((!T) || key==T->data.key) return T; //找到返回结点地址,找不到返回空指针 else if (key<T->data.key) return SearchBST(T->lchild,key); //在左子树中继续查找else return SearchBST(T->rchild,key); //在右子树中继续查找
}
}
(2)插入
【算法描述】 若二叉排序树为空,则插入结点应为根结点,否则,继续在其左、右子树上查找:
①树中已有,不再插入;
②树中没有,查找直至某个叶子结点的左子树或右子树为空为止,则插入结点应为该叶子结点的左孩子或右孩子。
【算法特点】插入的元素一定在叶结点上。
【算法过程】 在下图所示的二叉排序树上插入结点 20:

过程如下:①45>20,继续在结点45的左子树上查询;
②12<20,继续在结点12的右子树上查询;
③37>20,继续在结点37的左子树上查询;
④24>20,继续在结点24左子树查询,而该结点为叶子结点,将此结点20插入结点24的左子树中。

【算法过程】
/*
当二叉排序树T中不存在关键字等于key的数据元素时
插入key并返回TRUE,否则返回FALSE
*/
/*
当二叉排序树T中不存在关键字等于key的数据元素时
插入key并返回TRUE,否则返回FALSE
*/
bool InsertBST(BiTree *T, int key){BiTree p, s;if(!SearchBST(*T, key, NULL, &p)){//查找不成功s = (BiTree)malloc(sizeof(BiTNode));s->data = key;s->lchild = s->rchild = NULL;if(!p){*T = s; //插入s为新的根节点}else if(key < p->data){p->lchild = s; //插入s为左孩子}else{p->rchild = s; //插入s为右孩子}return TRUE;}else{return FALSE; //树种已有关键字相同的结点,不再插入}
}
(3)生成
从空树出发,经过一系列的查找,插入操作之后,可生成一棵二叉排序树。
- 一个无序序列可通过构造二叉排序树而变成一个有序序列,构造树的过程就是对无序序列进行排序的过程。
- 插入的结点均为叶子结点,故无需移动其他结点。相当于在有序序列插入记录而无需移动其他记录。
从空树出发,对序列{10, 18, 3, 8, 12, 2, 7} 构造二叉排序树。
【过程如下】 ①结点10作为根节点,18>10,插入为结点10的右子树;

②3<10,插入为结点10的左子树;

③8<10,3>8,插入为结点3的右孩子;

④12>10.12<18,插入为结点18的左孩子;

⑤2<10,3>2,插入为结点3的左孩子;

⑥7<10,3<7,8>7,插入为结点8的左孩子,至此二叉排序树生成。

【注意】 不同插入次序的序列生成不同形态的二叉排序树。如下图所示:

【算法过程】
有了二叉排序树的插入代码,我们要实现二叉排序树的构建就非常容易了,几个例子:
int i;
int a[10] = {62, 88, 58, 47, 35, 73, 51, 99, 37, 93};
BiTree T = NULL;
for(i = 0; i<10; i++){InsertBST(&T, a[i]);
}
上面的代码就可以创建一棵下图这样的树。

(4)删除
从二叉排序树中删除一个结点,不能把以该结点为根的子树都删去,只能删掉该结点,并且还应保证删除后所得的二叉树仍然满足二叉排序树的性质不变。
由于中序遍历二叉排序树可以得到一个递增有序的序列。那么,在二叉排序树中删去一个结点相当于删除有序序列中的一个结点。
【删除思想】将因删除结点而断开的二叉链表重新链接起来,防止重新链接后树的高度增加。
①删除叶结点,只需将其双亲结点指向它的指针清零,再释放它即可。
②被删结点缺右子树,可以拿它的左子女结点顶替它的位置,再释放它。
③被删结点缺左子树,可以拿它的右子女结点顶替它的位置,再释放它。
④被删结点左、右子树都存在,依据中序遍历思想以下有两种方法,具体情况考虑树的高度选择删除的方法:
- 以其中序前趋值替换之(值替换),然后再删除该前趋结点。前趋是左子树中最大的结点。
- 也可以用中序遍历的后继结点替换之,然后再删除该后继结点。后继是右子树中最小的结点。

【算法过程】
/*从二叉排序树中删除结点p,并重接它的左或右子树。*/
bool Delete(BiTree *p){BiTree q, s;if(p->rchild == NULL){//右子树为空则只需重接它的左子树q = p;p = p->lchild;free(q);}else if(p->lchild == NULL){//左子树为空则只需重接它的右子树q = p;p = p->rchild;free(q);}else{//左右子树均不空q = p;s = p->lchild; //先转左while(s->rchild){//然后向右到尽头,找待删结点的前驱q = s;s = s->rchild;}//此时s指向被删结点的直接前驱,p指向s的父母节点p->data = s->data; //被删除结点的值替换成它的直接前驱的值if(q != p){q->rchild = s->lchild; //重接q的右子树}else{q->lchild = s->lchild; //重接q的左子树}pree(s);}return TRUE;
}
3.性能分析
二叉排序树的优点明显,插入删除的时间性能比较好。而对于二叉排序树的查找,平均查找长度和二叉树的形态有关,查找的次数和关键字存在的位置有关,即:

①最好:ASL=⌈ l o g_2 ( n + 1 ) ⌉ (形态匀称,与折半查找中的判定树相同);
②最坏:ASL=(n+1)/2(单支树,退化成了顺序查找法)

问题:如何提高形态不均衡的二叉排序树的查找效率?
解决办法:做“平衡化”处理,即尽量让二叉树的形状均衡!
3.2平衡二叉树
1.定义
【概念】左、右子树是平衡二叉树AVL;所有结点的左、右子树深度之差的绝对值≤ 1 。任一结点的平衡因子只能取:-1、0 或 1;如果树中任意一个结点的平衡因子的绝对值大于1,则这棵二叉树就失去平衡,不再是AVL树;

【平衡因子】 为了方便起见,给每个结点附加一个数字,给出该结点左子树与右子树的高度差,这个数字称为平衡因子BF。
2.平衡二叉树的常见操作
(1)查找
在平衡二叉树上进行查找的过程与二叉排序树的相同。因此,在查找过程中,与给定值进行比较的关键字个数不超过树的深度。假设以 n_h表示深度为 h 的平衡树中含有的最少结点数。显然,有 n_0=0,n_1=1,n_2=2 ,并且有n_h=n_{h-1}+n_{h-2}+1。

(2)插入
二叉排序树保证平衡的基本思想如下:每当在二叉排序树中插入(或删除)一个结点时,首先检查其插入路径上的结点是否因为此次操作而导致了不平衡。若导致了不平衡,则先找到插入路径上离插入结点最近的平衡因子的绝对值大于1的结点A,再对以A为根的子树,在保持二叉排序树特性的前提下,调整各结点的位置关系,使之重新达到平衡。
注意:每次调整的对象都是最小不平衡子树,即以插入路径上离插入结点最近的平衡因子的绝对值大于1的结点作为根的子树。下图中的虚线框内为最小不平衡子树。

平衡二叉树的插入过程的前半部分与二叉排序树相同,但在新结点插入后,若造成查找路径上的某个结点不再平衡,则需要做出相应的调整。可将调整的规律归纳为下列4种情况:

调整原则:①降低高度 ②保持二叉排序树的性质(分析三个A,B,C结点的大小,旋转的结果为:左子树最小,右子树最大,根结点中间)
-
LL平衡调整
如下图所示,结点旁的数值代表结点的平衡因子,而用方块表示相应结点的子树,下方数值代表该子树的高度。


-
RR平衡调整


-
LR平衡调整


-
RL平衡调整

注意: LR和RL旋转时,新结点究竟是插入C的左子树还是插入C的右子树不影响旋转过程,而上图中是以插入C的左子树中为例。
举个例子:
假设关键字序列为15 , 3 , 7 , 10 , 9 , 8 {15,3, 7, 10, 9, 8}15,3,7,10,9,8,通过该序列生成平衡二叉树的过程如下图所示。

3.性能分析
对于一棵有n个结点的平衡二叉树AVL,其高度保持在O(log2n)数量级,平均查找长度ASL也保持在O(log2n)量级。
查找和二叉排序树一致,比较的次数不超过平衡二叉树的深度。
前面我们认识了二叉排序树,AVL树,这些树的原理就是先把数据加载到内存里面,然后在内存中进行处理,数据量通常不会很大,那如果数据量非常大,大到内存根本存不下的时候,为什么要存在内盘里面呢?不能直接在硬盘上面操作这些数据吗?

由此可见,树越高,硬盘的访问次数就越多,那么减少输的高度,是不是就可以减少非常耗时的这个硬盘操作呀?那么在数据量不变的情况下,如何让树高降低呢?多路查找树就应用而生啦~
【多路查找树】
多路查找树(muitl-way search tree), 其每一个结点的孩子数可以多于两个,且每一个结点处可以存储多个元素。由于它是查找树,所有元素之间存在某种特定的排序关系。
在这里,每一个结点可以存储多少个元素,以及它的孩子数的多少是非常关键的。常见的有4种特殊形式:2-3树、2-3-4树、B树和B+树。这里主要介绍B树和B+树,因为2-3树、2-3-4树都是B树的特例。
如下图所示是一颗2-3树:

3.3B树
1.定义
B树也称为B-树,B-树是一种所有结点的平衡因子均等于0的平衡的多路查找树。同时B树访问结点是在硬盘上进行的,结点内的数据操作是在内存中进行的。
【定义】 B树中所有结点的孩子个数的最大值称为B树的阶,通常用m 表示。一棵B树具有如下图所示的三个特点:平衡,有序,多路。

2.B树的相关操作
(1)查找
B树的查找包含两个基本操作:①在B树找结点(硬盘上操作):②在结点内找关键字(内存中操作):先在该结点有序表中进行查找,若找到则查找成功,否则按照对应的指针信息到所指的子树中去查找。
最后,如图所示,查找到叶结点时(对应指针为空指针),则说明树中没有对应的关键字,查找失败。

所有的叶子结点都出现在同一层次上,并且不带信息,通常称为失败结点即外部结点(失败结点并不存在,指向这些结点的指针为空。引入失败结点是为了便于分析B-树的查找性能)。
(2)插入
将关键字key插入B树的过程如下:

分裂的方法是:取一个新结点,在插入key后的原结点,从中间位置(⌈m/2⌉) 将其中的关键字分为两部分,左部分包含的关键字放在原结点中,右部分包含的关键字放到新结点中,中间位置(⌈ m/2⌉)的结点插入原结点的父结点。若此时导致其父结点的关键字个数也超过了上限,则继续进行这种分裂操作,直至这个过程传到根结点为止,进而导致B树高度增1。
对于m=3的B树,所有结点中最多有m-1=2个关键字,若某结点中已有两个关键字,则结点已满,如图中(a)所示。插入一个关键字60后,结点内的关键字个数超过了m-1,如图中(b)所示,此时必须进行结点分裂,分裂的结果如图中©所示。

(3)删除
删除结点在非叶结点的部分,需要按照类似于二叉搜索树,左右子树都有的情况,也就是用它的直接前趋或者后继去替换它(不管是前趋还是后继都落在叶子结点上);
B树中的删除操作与插入操作类似,但要稍微复杂一些,即要使得删除后的结点中的关键字个数>⌈m/2⌉-1(避免下溢出),因此将涉及**结点的“合并”**问题。当被删关键字在终端结点(最低层非叶结点)中时,有下列三种情况:

- 兄弟够借

- 兄弟不够借

尽管B树的诸多好处,但其实它还是有缺陷的。对于树结构来说,我们都可以通过中序遍历来顺序查找树中的元素,需要在结点之间来回移动,效率比较低,而且这一切都是在内存中进行。可是在B树结构中,我们往返于每个结点之间也就意味着,我们必须得在硬盘的页面之间进行多次访问。

如上图所示。我们希望遍历这棵B树,假设每个结点都属于硬盘的不同页面,我们中序遍历所有的元素:
页面 2 → 页面 1 → 页面 3 → 页面 1 → 页面 4 → 页面 1 → 页面 5
而且我们每次经过结点遍历时,都会对结点中的元素进行一次遍历,这就非常糟糕。有没有可能让遍历时每个元素只访问一次呢?
B+树来啦~
3.4B+树
1.定义
B+树是应数据库所需而出现的-种B树的变形树。
B+树中叶子结点是对记录的索引,非叶子结点层是对叶结点层关键字的索引,所以整个B+树是一个多级索引结构
- B+树的叶结点层包含了所有元素,同时这些元素是从小到大排列的,结点之间用指针连接起来。这样的话,我们就可以很轻松的通过第一个结点前的头指针,来快速的对所有的元素进行顺序遍历。同时因为B+树常被用作数据库中的索引结构,那实际上每个元素都包含指向对应记录存储地址的指针,此时结点内的元素又被称作关键字key,通过关键字包含的指针可以索引到数据库中的某一条记录。

- B+树中的非叶结点可以帮助我们快速的定位到叶结点上的某一关键字,相当于给叶子结点层建立了索引,为的就是实现以log级别的复杂度去查找叶子结点上的某一关键字记录。
下图所示为一棵4阶B+树

【性质】 一棵m阶的B+树需满足下列条件:
①每个分支结点最多有m棵子树(孩子结点);
②非叶根结点至少有两棵子树,其他每个分支结点至少有⌈ m/2 ⌉棵子树;
③结点的子树个数与关键字个数相等;
④所有分支结点(可视为索引的索引)中仅包含它的各个子结点(即下一级的索引块)中关键字的最大值及指向其子结点的指针。
【B+树的查找】
①顺序查找:从最小关键字开始
②随机查找:B+树的查找最终一定会落到叶子结点层,如果在非叶子结点上遇到了关键字还需要继续往下查找
③范围查找:结合顺序查找和随机查找
【应用范围】 B+树的查找、插入和删除操作和B树的基本类似。只是在查找过程中,非叶结点上的关键字值等于给定值时并不终止,而是继续向下查找,直到叶结点上的该关键字为止。所以,在B+树中查找时,无论查找成功与否,每次查找都是一条从根结点到叶结点的路径。
B+树的结构特别适合带有范围的查找。比如查找我们学校18~22岁的学生人数,我们可以通过从根结点出发找到第一个18岁的学生,然后再在叶子结点按顺序查找到符合范围的所有记录。
2.B树与B+树的比较
下图以3阶B数树和B+树为例,观察两种树形结构的不特性: m阶的B+树与m阶的B树的主要差异如下:
m阶的B+树与m阶的B树的主要差异如下:
四.散列表
散列表是根据关键字而直接进行访问的数据结构。也就是说,散列表建立了关键字和存储地址之间的一种直接映射关系。我们只需要通过某个函数f,使得
存储位置 = f ( 关键字 )
那样我们可以通过查找关键字不需要比较就可获得需要的记录的存储位置。
【哈希方法】 既是一种存储方法, 也是一种查找方法,散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置 f(key)。查找时,根据这个确定的对应关系找到位置上。
这里我们把这种对应关系 f 称为散列函数,又称为哈希(Hash) 函数。按这个思想,采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。那么关键字对应的记录存储位置我们称为散列地址。
【优点】 查找速度极快,时间复杂度为O(1),查找效率与元素个数n无关
1.哈希函数的构造
在构造散列函数时,必须注意以下几点:
- 散列表的大小:散列函数的定义域必须包含全部需要存储的关键字,而值域的范围则依赖于散列表的大小或地址范围。
- 关键字的分布情况:散列函数计算出来的地址应该能等概率、均匀地分布在整个地址空间中,从而减少冲突的发生。
- 执行速度:散列函数应尽量简单,能够在较短的时间内计算出任一关键字对应的散列地址。
1.常用构造方法

【直接定址法】 Hash(key) = a·key + b (a、b为常数)
①优点:以关键码key的某个线性函数值为哈希地址,不会产生冲突。
②缺点:要占用连续地址空间,空间效率低。
例如,给定序列{100,300,500,700,800,900},哈希函数Hash(key)=key/100,构造哈希表结果如下:

【数字分析法】 选取数码分布较为均匀的若干位作为散列地址,这种方法适合于已知的关键字集合,若更换了关键字,则需要重新构造新的散列函数。
【平方取中法】取关键字的平方值的中间几位作为散列地址,具体取多少位要视实际情况而定。这种方法得到的散列地址与关键字的每位都有关系,因此使得散列地址分布比较均匀,适用于关键字的每位取值都不够均匀或均小于散列地址所需的位数。
【除留余数法】 Hash(key)=key mod p (p是一个整数)。该方法的关键是选取有个合适的p值,一般情况下,若表长为m,取p为小于等于m的最大质数。
【随机数法】选择一个随机数,取关键字的随机函数值为它的散列地址。也就是H(key)=random (key)
这里random是随机函数。当关键字的长度不等时,采用这个方法构造散列函数是比较合适的。
2.冲突处理
【冲突】 不同的关键码映射到同一个哈希地址,即key1≠key2,但H(key1)=H(key2)。这些发生碰撞的不同关键字称为同义词。一方面,设计得好的散列函数应尽量减少这样的冲突;另一方面,由于这样的冲突总是不可避免的,所以还要设计好处理冲突的方法。

【减少冲突的方式】 ①构造好的哈希函数;②制定一个好的解决冲突方案(因为冲突是不可能避免的)。
(1)开放定址法
【基本思想】有冲突时就去寻找下一个空的哈希地址,只要哈希表足够大,空的哈希地址总能找到,并将数据元素存入。其冲突函数为
Hi=(Hash(key)+di) mod m ( 1≤i < m )

【线性探测法】 在该方法中:


-
优点:只要哈希表未被填满,保证能找到一个空地址单元存放有冲突的元素。
-
缺点:可能使第i个哈希地址的同义词存入第i+1个地址,这样本应存入第i+1个哈希地址的元素变成了第i+2个哈希地址的同义词,……,产生 聚集现象 ,降低查找效率。
【二次探测法】 对于上述方法产生的聚集现象,可采用二次探测法进行解决。在该方法中:


【伪随机探测法】 在该方法中:

(2)链地址法(拉链法)
【基本思想】相同哈希地址的记录链成一单链表,m个哈希地址就设m个单链表,然后用用一个数组将m个单链表的表头指针存储起来,形成一个动态的结构。
【建立哈希表步骤】
①取数据元素的关键字key,计算其哈希函数值(地址)。若该地址对应的链表为空,则将该元素插入此链表;否则执行②解决冲突。
②根据选择的冲突处理方法,计算关键字key的下一个存储地址。若该地址对应的链表不为空,则利用链表的前插法或后插法将该元素插入此表。
【优点】 ①非同义词不会冲突,无“聚集”现象;
②链表上结点空间动态申请,更适合于表长不确定的情况。
(3)公共溢出区法
这个方法其实就更加好理解,就是把凡是冲突的家伙额外找个公共场所待着。我们为所有冲突的关键字建立了一个公共的溢出区来存放。
就前面的例子而言,我们共有三个关键字37 , 48 , 34与之前的关键字位置有冲突,那么就将它们存储到溢出表中,如下图所示。

如果相对于基本表而言,有冲突的数据很少的情况下,公共溢出区的结构对查找性能来说还是非常高的。
2.哈希表的查找
【比较步骤】

【例子】

②用链地址法处理冲突

在此方法中,ASL=(16+24+3+4)/12=1.75。
【效率分析】 使用平均查找长度ASL来衡量查找算法,ASL取决于以下几个因素:
①哈希函数;
②处理冲突的方法;
③哈希表的装填因子。α越大,表中记录数越多,说明表装得越满,发生冲突的可能性就越大,查找时比较次数就越多。


【三种方法比较】
- 对哈希表技术具有很好的平均性能,优于一些传统的技术;
- 链地址法优于开地址法;
- 除留余数法作哈希函数优于其它类型函数。
相关文章:
【数据结构与算法】查找
文章目录 一.查找二.线性结构的查找2.1顺序查找2.2折半查找2.3分块查找 三.树型结构的查找3.1二叉排序树1.定义2.二叉排序树的常见操作3.性能分析 3.2平衡二叉树1.定义2.平衡二叉树的常见操作3.性能分析 3.3B树1.定义2.B树的相关操作 3.4B树1.定义2.B树与B树的比较 四.散列表1.…...

从零开始学习 sg200x 多核开发之 milkv-duo256 编译运行 sophpi
sophpi 是 算能官方针对 sg200x 系列的 SDK 仓库 https://github.com/sophgo/sophpi ,支持 cv180x、cv81x、sg200x 系列的芯片。 SG2002 简介 SG2002 是面向边缘智能监控 IP 摄像机、智能猫眼门锁、可视门铃、居家智能等多项产品领域而推出的高性能、低功耗芯片&a…...

LLM - 使用 LLaMA-Factory 微调大模型 Qwen2-VL SFT(LoRA) 图像数据集 教程 (2)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/143725947 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 LLaMA-…...
_265)
基于STM32设计的大棚育苗管理系统(4G+华为云IOT)_265
文章目录 一、前言1.1 项目介绍【1】项目开发背景【2】设计实现的功能【3】项目硬件模块组成【4】设计意义【5】国内外研究现状【6】摘要1.2 设计思路1.3 系统功能总结1.4 开发工具的选择【1】设备端开发【2】上位机开发1.5 参考文献1.6 系统框架图1.7 系统原理图1.8 实物图1.9…...

深入浅出《钉钉AI》产品体验报告
1. 引言 随着人工智能技术的迅猛发展,企业协同办公领域迎来了新的变革。钉钉作为阿里巴巴集团旗下的企业级通讯与协同办公平台,推出了钉钉AI助理,旨在提高工作效率,优化用户体验。本报告将对钉钉AI助理进行全面的产品体验分析&am…...
)
2020年计挑赛往届真题(C++)
因为17号要开赛了,甚至是用云端编辑器,debuff拉满,只能临时抱佛脚了 各个选择题的选择项我就不标出来了,默认ABCD排,手打太麻烦了 目录 单选题: 1.阅读以下语句:double m0;for(int i3;i>0;i--)m1/i;…...

ES6进阶知识二
一、promise方法的案例 Promise对象通过new Promise()语法创建,它接受一个函数作为参数,该函数接受两个参数:resolve和reject。resolve表示异步操作成功,reject表示异步操作失败。 案例:异步加载图片 const loadIma…...
)
大语言模型通用能力排行榜(2024年10月8日更新)
数据来源SuperCLUE 榜单数据为通用能力排行榜 排名 模型名称 机构 总分 理科 文科 Hard 使用方式 发布日期 - o1-preview OpenAI 75.85 86.07 76.6 64.89 API 2024年11月8日 - Claude 3.5 Sonnet(20241022) Anthropic 70.88 82.4…...

第六节、Docker 方式部署指南 github 上项目 mkdocs-material
一、简介 MkDocs 可以同时编译多个 markdown 文件,形成书籍一样的文件。有多种主题供你选择,很适合项目使用。 MkDocs 是快速,简单和华丽的静态网站生成器,可以构建项目文档。文档源文件在 Markdown 编写,使用单个 YAML 配置文件配置。 MkDocs—markdown项目文档工具,…...

【MySQL】MySQL中的函数之JSON_REPLACE
在 MySQL 中,JSON_REPLACE() 函数用于在 JSON 文档中替换现有的值。如果指定的路径不存在,则 JSON_REPLACE() 不会修改 JSON 文档。如果需要添加新的键值对,可以使用 JSON_SET() 函数。 基本语法 JSON_REPLACE(json_doc, path, val[, path,…...

【大数据学习 | HBASE高级】hbase的API操作
首先引入hbase的依赖 <dependencies><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>2.4.13</version></dependency><dependency><groupId>org.slf4j<…...

C++(Qt)软件调试---内存泄漏分析工具MTuner (25)
C(Qt)软件调试—内存泄漏分析工具MTuner (25) 文章目录 C(Qt)软件调试---内存泄漏分析工具MTuner (25)[toc]1、概述🐜2、下载MTuner🪲3、使用MTuner分析qt程序内存泄漏🦧4、相关地址ὁ…...

python核心语法
目录 核⼼语法第⼀节 变量0.变量名规则1.下⾯这些都是不合法的变量名2.关键字3.变量赋值4.变量的销毁 第⼆节 数据类型0.数值1.字符串2.布尔值(boolean, bool)3.空值 None 核⼼语法 第⼀节 变量 变量的定义变量就是可变的量,对于⼀些有可能会经常变化的数据&#…...

MATLAB用CNN-LSTM神经网络的语音情感分类深度学习研究
全文链接:https://tecdat.cn/?p38258 在语音处理领域,对语音情感的分类是一个重要的研究方向。本文将介绍如何通过结合二维卷积神经网络(2 - D CNN)和长短期记忆网络(LSTM)构建一个用于语音分类任务的网络…...
智能网页内容截图工具:AI助力内容提取与可视化
我们每天都会接触到大量的网页内容。然而,如何从这些内容中快速提取关键信息,并有效地进行整理和分享,一直是困扰我们的问题。本文将介绍一款我近期完成的基于AI技术的智能网页内容截图工具,它能够自动分析网页内容,截…...

Axure设计之文本编辑器制作教程
文本编辑器是一个功能强大的工具,允许用户在图形界面中创建和编辑文本的格式和布局,如字体样式、大小、颜色、对齐方式等,在Web端实际项目中,文本编辑器的使用非常频繁。以下是在Axure中模拟web端富文本编辑器,来制作文…...

【MyBatis源码】深入分析TypeHandler原理和源码
🎮 作者主页:点击 🎁 完整专栏和代码:点击 🏡 博客主页:点击 文章目录 原始 JDBC 存在的问题自定义 TypeHandler 实现TypeHandler详解BaseTypeHandler类TypeReference类型参考器43个类型处理器类型注册表&a…...

号卡分销系统,号卡系统,物联网卡系统源码安装教程
号卡分销系统,号卡系统,物联网卡系统,,实现的高性能(PHP协程、PHP微服务)、高灵活性、前后端分离(后台),PHP 持久化框架,助力管理系统敏捷开发,长期持续更新中。 主要特性 基于Auth验证的权限…...

常用命令之LinuxOracleHivePython
1. 用户改密 passwd app_adm chage -l app_adm passwd -x 90 app_adm -> 执行操作后,app_adm用户的密码时间改为90天有效期--查看该euser用户过期信息使用chage命令 --chage的参数包括 ---m 密码可更改的最小天数。为零时代表任何时候都可以更改密码。 ---M 密码…...

从dos上传shell脚本文件到Linux、麒麟执行报错“/bin/bash^M:解释器错误:没有那个文件或目录”
[rootkylin tmp]#./online_update_wars-1.3.0.sh ba51:./online_update_wars-1.3.0.sh:/bin/bash^M:解释器错误:没有那个文件或目录 使用scp命令上传文件到麒麟系统,执行shell脚本时报错 “/bin/bash^M:解释器错误:没有那个文件或目录” 解决方法: 执行…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...

go 里面的指针
指针 在 Go 中,指针(pointer)是一个变量的内存地址,就像 C 语言那样: a : 10 p : &a // p 是一个指向 a 的指针 fmt.Println(*p) // 输出 10,通过指针解引用• &a 表示获取变量 a 的地址 p 表示…...
设计模式-3 行为型模式
一、观察者模式 1、定义 定义对象之间的一对多的依赖关系,这样当一个对象改变状态时,它的所有依赖项都会自动得到通知和更新。 描述复杂的流程控制 描述多个类或者对象之间怎样互相协作共同完成单个对象都无法单独度完成的任务 它涉及算法与对象间职责…...

【学习记录】Office 和 WPS 文档密码破解实战
文章目录 📌 引言📁 Office 与 WPS 支持的常见文件格式Microsoft Office 格式WPS Office 格式 🛠 所需工具下载地址(Windows 官方编译版)🔐 破解流程详解步骤 1:提取文档的加密哈希值步骤 2&…...