网络层9——虚拟专用网VPN和网络地址转换NAT
目录
一、为什么有虚拟专用网?
二、如何理解“虚拟专用网”?
三、IP隧道技术实现虚拟专用网
四、网络地址变换
一、为什么有虚拟专用网?
第一,IPv4只有32位,最多有40亿个全球唯一的IP地址
数量不够,无法保证每一个用户都拥有一个全球唯一的IP地址
而没有IP地址,就意味着无法接入互联网
第二,很多情况下,一台主机主要和本机构内的其他主机进行通信
基于此,主机并没有必须连接互联网的必要
因此,仅在一个内部进行通信的主机,
可以在机构内部进行分配IP地址,该IP地址仅在该机构内有效
于是,一个机构内的主机就不需要申请全球唯一的IP地址
就可以让本机构内的所有主机进行互相通信
可是,有时机构内部的某些主机需要和连接互联网
此时内部分配的IP地址可能会和全球唯一的IP地址重复
引起歧义
如何解决这个问题?
使用专用地址
什么是专用地址?
专用地址只用于本地地址,而不能作为全球地址
对所有的路由器来说,接收到目的地址为网络为专用地址的任何数据一律丢弃
以下是三个专用地址块:
(只要目的地址属于这三个地址块范围内,就是专用地址)

于是,采用上述专用IP地址的互连网就叫做专用互联网 / 本地互联网
世界上可能会存在很多重复的专用IP地址
但是由于专用的IP地址只在本地使用,因此没有问题
因此,专用IP地址也叫做可重用地址
有时一个机构可能很大,分布在很远的不同地方(例如一个非洲,一个南极)
此时,如何通信?
第一,租用专用通道
多个分散的机构可以通过租用电信公司的专用通道,但是贵
第二,通过互联网进行通信
使用互联网作为一个专用网之间的两个不同场所的通信载体
于是,这样的专用网就叫做虚拟专用网VPN
如果数据通过互联网有保密需求,则可以进行加密
二、如何理解“虚拟专用网”?
虚拟专用网并不是一个整体的实际客体
因为多个机构在物理上是分散的
但是,因为对于机构的每一个主机来说,
他们可以对本机构内的所有主机进行畅通无阻的通信
而且无论主机在现实世界的位置
于是,一个机构内的所有主机就好像是在同一个网络内一样
因此,称之为“虚拟专用网”
但是实际上并不存在这样的网络,故名“虚拟”
在计算机网络中,存在很多“虚拟”的概念
例如“虚拟局域网”、“虚拟存储器”、“虚拟专用网”等等
要深刻理解这种逻辑上抽象的技术概念
这对整个计算机的体系认识是都好处的
学习这些知识不能只有知识点的堆砌和拼凑
不能零散,没有组织,不成体系
这样的认识,将很难在思维层次上帮助你构建起一个对计算机世界的整体观
三、IP隧道技术实现虚拟专用网
每一个场所必须保证至少有一个路由器具有全球唯一合法的IP地址
这个接口作为路由器与互联网连接的接口
如图所示:

于是,虚拟专用网的通信分为三种:
一、内部通信,不需要经过互联网
二、跨场所,需经过互联网(重点!!!)
三、外地员工的个人主机连接公司主机
对第二种情况:
第一、专用网内部主机将数据发送给连接的路由器
第二、路由器接到内部数据后发现需经过互联网,加密,加上首部,封装为互联网需要的IP数据报
第三、修改源地址为本路由器的IP地址,目的地址为目的专用网连接的路由器的IP地址
第四、目的路由接收到数据后,解包,恢复内部数据报,根据目的地址发送给本路由器连接的网络中的对应主机
对第三种情况:
这种技术叫做远程VPN
感兴趣可自行了解
四、网络地址变换
为什么要进行网络地址转换?
因为考虑到这样一种情况:
一个在专用网内的主机
已经获取了专用玩的IP地址,但是还向和外部的互联网上的主机通信
此时,就需要进行网络地址转换
进行网络地址转换
需在专用网和互联网之间的路由器上安装NAT软件
安装NAT的软件叫做NAT路由器
NAT路由器至少有一个全球IP地址,但也可以有多个
从专用网内部的主机A发送到互联网上的主机B的发送过程:(内网A->外网B)
此时源地址为专用网的主机地址,目的地址为互联网的主机地址
1、路由器C根据NAT路由表,修改数据报的源地址为本路由器的全球唯一IP地址
2、目的主机B收到后,发送回应报文IP数据报
3、回应IP数据报的源地址为B的IP地址,目的地址为路由器C的IP地址
4、路由器C收到回应报文,根据NAT路由表修改目的地址,将路由器IP地址修改为主机A的专用网地址
5、地址转换后,从IP数据报变为数据报,发送给主机A
当NAT路由器有n个全球唯一IP地址时,最多有n台主机接入互联网
一个NAT项目对应一个专用网主机和接口IP地址(这样才可以转换)
同时,通过NAT路由器的通信只能由专用网内部的主机发起
如果外部互联网主机发起的通信,即使能够到达NAT路由器,
但是接下来不知道该发给哪个专用网主机
因此,专用网的主机不能用做服务器
因为服务器需要对请求进行回应
思考:为什么不能由互联网的主机发起通信?
外部主机发送到专用网的请求需要通过NAT路由器的端口映射或者端口转发机制进行处理。
NAT表中的条目只有在内网主机先发起通信时才会建立并允许响应,因为外部主机无法直接访问私有IP。
思考:既然不能由互联网的主机发起通信,可是为什么互联网到内网的回应报文却可以通信呢?
NAT路由器之所以能够将回应报文正确转换并转发,是因为在大多数情况下,NAT操作是“状态感知的”。
也就是说,NAT路由器知道哪些内网主机发起了哪些外部请求,因此它能基于已有的连接和转换记录来正确处理回应报文。
这些记录是基于连接的状态而创建的,因此外部的回应数据包可以通过NAT路由器的地址转换规则,正确地转发给发起请求的内网主机。
相关文章:
网络层9——虚拟专用网VPN和网络地址转换NAT
目录 一、为什么有虚拟专用网? 二、如何理解“虚拟专用网”? 三、IP隧道技术实现虚拟专用网 四、网络地址变换 一、为什么有虚拟专用网? 第一,IPv4只有32位,最多有40亿个全球唯一的IP地址数量不够,无法…...

开源科学工程技术软件介绍 – EDA工具KLayout
link 今天向各位知友介绍的 KLayout是一款由德国团队开发的开源EDA工具。 KLayout是使用C开发的,用户界面基于Qt。它支持Windows、MacOS和Linux操作系统。安装程序可以从下面的网址下载: https://www.klayout.de/build.html KLayout图形用户界面&…...

【网络安全】Cookie SameSite属性
未经许可,不得转载。 文章目录 背景CSRF 攻击SameSite 属性StrictLaxNone背景 为了有效防止 CSRF 攻击并保护用户隐私,Chrome 从 51 版本开始引入了 SameSite 属性,专门用于限制第三方 Cookie 的使用,进而减少安全风险。 CSRF 攻击 跨站请求伪造(CSRF)攻击是指恶意网站…...
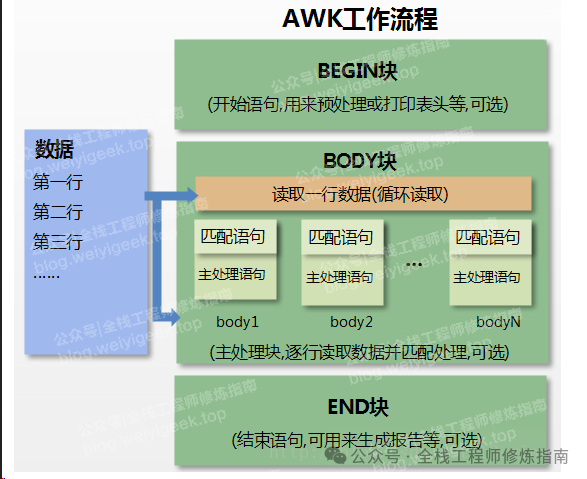
Linux 命令 | 每日一学,文本处理三剑客之awk命令实践
[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ] 0x00 前言简述 描述:前面作者已经介绍了文本处理三剑客中的 grep 与 sed 文本处理工具,今天将介绍其最后一个且非常强大的 awk 文本处理输出工具,它可以非常方便…...

RabbitMQ的工作队列在Spring Boot中实现(详解常⽤的⼯作模式)
上文着重介绍RabbitMQ 七种工作模式介绍RabbitMQ 七种工作模式介绍_rabbitmq 工作模式-CSDN博客 本篇讲解如何在Spring环境下进⾏RabbitMQ的开发.(只演⽰部分常⽤的⼯作模式) 目录 引⼊依赖 一.工作队列模式 二.Publish/Subscribe(发布订阅模式) …...
方法实现全局注册组件的通用代码)
【web前端笔记】vue3 + vite的前端项目中,使用import.meta.glob()方法实现全局注册组件的通用代码
目录 1.1、如何读取所有文件 1.2、通用代码 1.3、在main.js引入 这篇文章介绍一下,在vue3和vite搭建的项目中,如何将【src/components】目录下所有的【*.vue】文件,当做一个组件全局注册到Vue对象里面。 1.1、如何读取所有文件 在vue3和vite搭建的项目里面,它给我们提…...

保险行业建立知识管理系统:提高效率和安全性的策略
在保险行业,知识管理系统(KMS)的建立对于提高工作效率和保障数据安全性至关重要。保险公司需要在复杂的生态系统中航行,这个生态系统由不断发展的法规、错综复杂的保单和投保人不断变化的需求所定义。以下是一些关键策略ÿ…...

小程序如何完成订阅
小程序如何完成订阅 参考相关文档实践问题处理授权弹窗不再触发引导用户重新授权 参考相关文档 微信小程序实现订阅消息推送的实现步骤 发送订阅消息 小程序订阅消息(用户通过弹窗订阅)开发指南 实践 我们需要先选这一个模板,具体流程参考…...

JS学习日记(jQuery库)
前言 今天先更新jQuery库的介绍,它是一个用来帮助快速开发的工具 介绍 jQuery是一个快速,小型且功能丰富的JavaScript库,jQuery设计宗旨是“write less,do more”,即倡导写更少的代码,做更多的事…...

Uni-APP+Vue3+鸿蒙 开发菜鸟流程
参考文档 文档中心 运行和发行 | uni-app官网 AppGallery Connect DCloud开发者中心 环境要求 Vue3jdk 17 Java Downloads | Oracle 中国 【鸿蒙开发工具内置jdk17,本地不使用17会报jdk版本不一致问题】 开发工具 HBuilderDevEco Studio【目前只下载这一个就…...

Linux的基本用法
Linux的基本用法涵盖多个方面,包括用户登录、系统操作、文件和目录管理、系统工具使用等。以下是对Linux基本用法的详细介绍: 一、用户登录与系统操作 用户登录 普通用户登录:选择用户名并输入密码。超级用户(root)登…...

如何找出爬取网站的来源IP呢?
1.背景 最近网站数据库性能很不稳定,查询性能在某段时间很慢,服务器CPU也很高,平常时间很低,感觉被爬虫恶意搞了,因此我分析了一下最近的nginx访问日志 2.方法 找出访问量最大20个ip [root100 nginx]# cat liuhaih…...
详解)
Java爬虫(Jsoup)详解
文章目录 Java爬虫(Jsoup)详解一、引言二、Jsoup 快速入门1、Jsoup 简介1.1、添加依赖 2、解析 HTML 文档2.1、解析 HTML 字符串2.2、从 URL 加载 Document2.3、解析 body 片断 三、数据抽取1、使用 DOM 方法遍历文档3.1、获取元素 2、使用选择器语法查找…...

力扣周赛:第424场周赛
👨🎓作者简介:爱好技术和算法的研究生 🌌上期文章:力扣周赛:第422场周赛 📚订阅专栏:力扣周赛 希望文章对你们有所帮助 第一道题模拟题,第二道题经典拆分数组/线段树都…...

预处理(1)(手绘)
大家好,今天给大家分享一下编译器预处理阶段,那么我们来看看。 上面是一些预处理阶段的知识,那么明天给大家讲讲宏吧。 今天分享就到这里,谢谢大家!!...

利用OpenAI进行测试需求分析——从电商网站需求到测试用例的生成
在软件测试工程师的日常工作中,需求分析是测试工作中的关键步骤。需求文档决定了测试覆盖的范围和测试策略,而测试用例的编写往往依赖于需求的准确理解。传统手工分析需求耗时长,尤其在面对大量需求和复杂逻辑时容易遗漏细节。本文将以电商网…...

深入探索:Scrapy深度爬取策略与实践
标题:深入探索:Scrapy深度爬取策略与实践 引言 在数据驱动的时代,深度爬取成为了获取丰富信息的重要手段。Scrapy,作为一个强大的Python爬虫框架,提供了多种工具和设置来帮助我们实现深度爬取。本文将详细介绍如何在…...

《生成式 AI》课程 第3講:訓練不了人工智慧嗎?你可以訓練你自己
资料来自李宏毅老师《生成式 AI》课程,如有侵权请通知下线 Introduction to Generative AI 2024 Spring 摘要 这一系列的作业是为 2024 年春季的《生成式 AI》课程设计的,共包含十个作业。每个作业都对应一个具体的主题,例如真假难辨的世界…...

如何编译 Cesium 源码
如何编译 Cesium 源码 Cesium 是一个开源的 JavaScript 库,用于构建 3D 地球和地图应用程序。它提供了一套强大的 API 和工具,使开发者能够创建丰富的地理空间应用。本文将指导您如何从 GitHub 下载 Cesium 源码,并在本地进行编译。 TilesB…...

前端开发设计模式——责任链模式
目录 一、定义和特点 1. 定义 2. 特点 二、实现方式 定义抽象处理者(Handler)类 创建具体处理者(ConcreteHandler)类 构建责任链 以下是一个用 JavaScript 实现的示例: 三、应用场景 1. 表单验证 2. 请求处…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...

0.2毫秒快速启动的操作系统
在工业控制以及航空航天等核心场景,极速启动就是高可靠系统的生命线。0.2毫秒超快启动搭配硬件看门狗,让设备在掉电重启、异常恢复时瞬时归位,关键任务永不延误! https://www.bilibili.com/video/BV11mLY6VERt/?spm_id_from333.1…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...

JWT弱密钥爆破实战:从HS256签名原理到CTF权限提升
1. 这不是密码学考试,而是一场“密钥猜谜”实战JWT(JSON Web Token)在现代Web系统中早已不是可选项,而是默认配置。登录成功后返回一串形如eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjMsIm5hbWUiOiLnlKjliYkiLCJpYX…...

抖音内容批量下载实战:从零开始构建个人视频资料库
抖音内容批量下载实战:从零开始构建个人视频资料库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

怎么理解Filter不是在afterCompetition里面remove掉ThreadLocal里面的东西,而是说在finally块里面remove
文章目录1. 核心原因:Filter 的“套娃(洋葱圈)”执行模型2. 为什么不能(也无法)在这里用 afterCompletion?维度一:Filter 拿不到 afterCompletion维度二:生命周期顺序的致命冲突总结…...

Win11Debloat:Windows系统精简与隐私保护的专业解决方案
Win11Debloat:Windows系统精简与隐私保护的专业解决方案 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and …...
)
仅限首批200位架构师获取:DeepSeek-DDD联合建模工作坊实录(含领域事件风暴原始会议录像+决策日志)
更多请点击: https://kaifayun.com 第一章:DeepSeek领域驱动设计的范式演进与本质洞察 DeepSeek作为面向大规模智能体协同与复杂业务语义建模的新一代AI原生架构,其领域驱动设计(DDD)实践已突破传统分层单体范式&…...