Linux 命令 | 每日一学,文本处理三剑客之awk命令实践

[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ]
0x00 前言简述
描述:前面作者已经介绍了文本处理三剑客中的 grep 与 sed 文本处理工具,今天将介绍其最后一个且非常强大的 awk 文本处理输出工具,它可以非常方便我们读取文件内容或者将命令执行内容,根据脚本进行自定义格式化美化输出。
Linux中的awk工具以其强大的文本处理能力而闻名,它是一种专门用于模式扫描和处理的编程语言。本章节将深入探讨awk的语法结构,并提供一份简明易懂的学习指南。我们将覆盖格式输出、变量操作、算术运算、模式匹配、流程控制、数组应用、函数定义以及脚本编写等核心概念,旨在为初学者打下坚实的基础。通过一系列精心设计的实例,我们将引导您快速掌握awk的基础知识。这些实例不仅有助于理解理论,还能让您在实践中加深印象。此外,结合作者在实际工作中积累的丰富经验,我们将分享一些实用的awk应用案例,旨在帮助您更深入地掌握这一工具的高级用法。无论您是初学者还是希望提升技能的资深用户,本章节都将为您提供宝贵的学习资源。
不管是那一门编程语言,字符串类型都是及其重要的,所以在学习各种编程语言后会发现近40%左右都与字符串有关, 特别是在 php、java、python 编程中可以将数据进行筛选输出,在Shell中可以awk工具并且自定义函数进行输出各种样式,使用awk将会使我们在运维中可以更加的简单简便处理的数据, 所以这也是我们必须要学习并掌握 awk 命令的原因。
本文是作者花费一定的时间,从学习、运维开发工作中总结而来,让各位初学者可以快速了解使用awk命令进行更加复杂的内容编辑、替换、计算、过滤输出,使之看友们可以快速应用在运维工作,这也是作者的初衷,如果感觉此文对你有帮助的话,就请多多支持作者【#运维从业必学】专栏。
Linux 运维学习之路相关文章:
Linux 运维 | 1.从零开始,服务器远程连接与基础命令学习实践
Linux 运维 | 2.从零开始,文件系统目录结构及文件目录管理学习实践
Linux 运维 | 3.从零开始,用户和用户组管理实践
Linux 运维 | 4.从零开始,文件目录特殊权限管理实践
Linux 运维 | 5.从零开始,编辑器之神 vi/vim 速成指南
Linux 运维 | 6.从零开始,Shell编程中正则表达式 RegExp 速成指南
运维学习 | Linux 命令大全,从A到Z
Linux 命令 | 运维必学,文件目录管理操作命令实践集锦
Linux 命令 | 运维必学,用户和组管理命令实践集锦
Linux 命令 | 每日一学,文件目录特殊权限相关命令集锦
Linux 命令 | 每日一学,文本处理之文件内容查看实践
Linux 命令 | 每日一学,文本处理之内容分割排序实践
Linux 命令 | 每日一学,文本处理之内容统计比较实践
Linux 命令 | 每日一学,文本处理三剑客之grep命令实践
Linux 命令:每日一学,文件查找之find命令实践
Linux 命令:每日一学,参数传递之xargs命令实践
Linux 命令:每日一学,一文说尽打包压缩工具实践
Linux 命令 | 每日一学,文本处理三剑客之sed命令实践
以自身实践为第一标准,下面跟随作者一起学习实践吧!
0x01 awk 命令 - 报告生成格式化输出
1.awk 简介
描述:awk(Aho,Weinberger,Kernighan)报告生成器,主要用于格式化文本输出,此工具包含在GUN/Linux发行版的系统中,目前由软件基金会(FSF)进行开发维护,所以也称为 GUN AWK (GAWK)。

awk 命令与其说它是一个命令,更不如说它是一门脚本编程语言,因为其既可以命令行的方式运行,也可使用脚本方式运行,它是可针对文本和数据进行处理的编程语言,它拥有多种发行版本,如:awk、nawk、gawk。
awk :最先源于 AT & T 实验室发布的。
nawk :AT & T 实验室发布的 awk 的升级版本。
gawk :自由软件基金会发布的 GNU awk 版本,所有基于 GUN/Liunux 发行版中默认的 awk 与 nawk 是完全兼容的,这也是后续学习默认使用的版本。
awk 功能特点:
擅长对文本和数据进行灵活处理,并已自定义格式输出文本报表,
支持对数据排序、计算、统计功能,
支持脚本语言相关功能,例如变量、数组、函数、流程控制(顺序、条件、循环)等,这是它和C语言的相同之处。
支持用户使用动态正则表达式。
2.awk 语法格式
语法参数:
# 语法格式
awk [options] 'script' -v var=value file (s)
awk [options] -f scriptfile -v var=value file(s)
# 注:数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的管道输出.# 常用参数
-F 'Format String' # 指定输入分隔符,fs可以是字符串或正则表达式,如-F:
-v var=value # 赋值一个用户定义变量,将外部变量传递给awk
-f scripfile # 编写的脚本文件中读取awk命令
-m[fr] val # 对val值设置内在限制,-mf 选项限制分配给val的最大块数目,-mr 限制记录的最大数目。基础格式
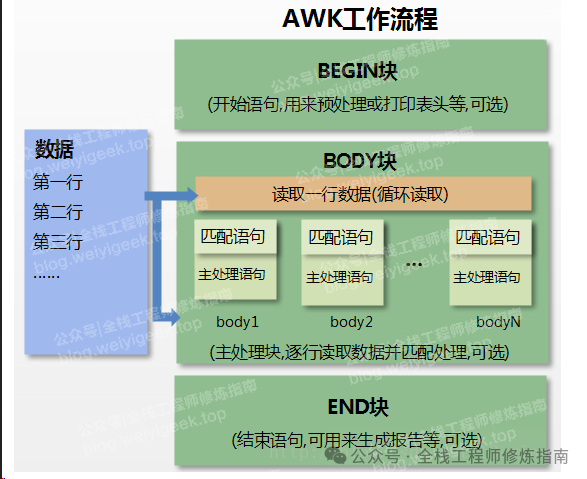
awk 中的 script 或者叫 Program 通常是被放在单引号中,并可以由三部分组成: BEGIN 语句块、通用语句块(可使用模式匹配)、END 语句块。
# 格式
Pattren {Action Statements;.....}# 简约
awk 'BEGIN{ commands;print "start" } pattern { commands } END{ commands;print "end" }' file.txt# Pattren:决定动作语句何时触发及其触发条件,例如:BEGIN、pattern、END 以及/正则/、关系表达式、模式匹配表达式等。# BEIGIN : 在输入流读取之前被执行,可选语句,主要用于变量初始化,打印输出表格的表头等# Pattern : 在输入流读取第一行到末尾执行,可选语句,即每一行都会执行该语句块,所以也是文本处理最重要部分,若没有提供此语句块,则默认执行 print。# END : 在输入流中全部被读取处理完后执行,也是可选语句,主要将前面针对每行处理分析的结果进行归纳汇总输出。
# Action :包含了对数据如何处理,类似一个循环体,会对文件中的每一行进行迭,例如 print $1 带换行,printf 不带换行。# Input Statements : 输入声明# Output Statements : 输出声明,例如 print,printf# Expressions : 算术表达式、正则表达式# Compound Statements : 组合语句声明# Control Statements : 控制语句声明,例如 if,whileawk 工作流程
Step 1.执行 BEIGN { commands } 语句块中的语句,进行初始化准备相关操作。
Step 2.从文件或者管道符(标准输入)读取一行(默认以
\n进行分隔行),然后执行 patter 语句块,逐行扫描运行直至文件被全部读取完毕。Step 3.当读取至输入流末尾时,执行 END 语句块中的语句,进行输出前的相关操作。
温馨提示:awk 必须有处理的文件或是通过管道符传入的字符串,否则会一直卡再输入状态,输入什么就会再次打印什么;
$ awk '{print $0}'
weiyigeek
weiyigeek
公众号:全栈工程师修炼指南
公众号:全栈工程师修炼指南
https://weiyigeek.top
https://weiyigeek.top
^c # Ctrl + C 停止输入温馨提示:默认读取带有\n行符分割的记录(即文件每一行),将记录按指定的域分隔符(默认以空格分隔)划分域,填充域,则表示所有域即一行内容,1 表示第一个域,$n 表示第 n 个域。
温馨提示:若省略 Action Statements 部分,则默认执行 print $0 操作。
awk 控制语句
组合语句:
{Statements;....}条件语句:
if(condition){Statements;..}或者if(condition){Statements;..}else{Statements;..}循环语句:
while (condition) {Statements;..}do {Statements;..} while (condition)for (expr1;expr2;expr3) {Statements;..}break continue退出语句:
exit其他语句:
next
awk 用户帮助手册:
https://www.gnu.org/software/gawk/manual/gawk.html
https://man7.org/linux/man-pages/man1/awk.1p.html
3.awk 学习指南
简单输出
描述:此小节将介绍 awk 命令中如何输出数据,包括:print、printf 命令的简单使用,固定字符需要用 "" 引用起来,而变量与数字则不需要。
# 换行
print item1,item2,...# 不会自动换行,且支持格式输出,与 C 语言中 printf 类似
printf "FORMAT",item1,item2,...
# 格式符
%s 字符串
%d,%i 十进制整数
%o,%O 八进制数
%x,%X 十六进数
%f 浮点数
%e,%E 指数形式
%c 显示字符ASCII码
%g,%G 科学计数法或者浮点数形式显示
%u 无符号整数
%% 输出一个百分号
# 修饰符
#.# 例如 3.2f 3 表示显示的最小位数,#2 表示小数点后的位数
- 左对齐,例如 %-15s
+ 显示数值前面的正负号范例演示:
输出文本内容
# 单次文本内容
$ echo | awk '{print "Hello,World! awk"}'Hello,World! awk# 多次输出内容
seq 3 | awk '{print "Hello,World! awk"}'Hello,World! awkHello,World! awkHello,World! awk# 输出内容到文件
echo | awk '{print("Hello World! awk\n") >> "hello.txt"}';cat hello.txtHello World!不同语句块内容输出
echo -e "A line 1\nA line 2" | awk 'BEGIN{ print "BEGIN" } { print } END{ print "END" }' #通过管道符号BEGINA line 1A line 2END运算输出内容
echo | awk '{print 2 + 3}'5echo | awk '{print (2 + 3) * 2 - 5}'5使用引号""拼接字符串输出
echo | awk '{ var1="v1"; var2="v2"; var3="v3"; print var1,var2,var3; }'
#v1 v2 v3echo | awk '{ var1="1"; var2="2"; var3="3"; print var1"=>"var2"=>"var3; }'
#1=>2=>3输入指定列, 助 -F 选项确定分割符号进行指定列输出,默认的字段定界符是空格:
# 查看系统用户默认Shell类型
awk -F: '{print $1,$7}' /etc/passwd | head -n 3
# 或者 $NF 表示最后一列
awk -F: '{ print $1,$NF }' /etc/passwdroot /bin/bashbin /sbin/nologindaemon /sbin/nologin# 输出文件系统挂载点及挂载目录
grep -E -v "#|^$" /etc/fstab | awk '{print $1,$2}'/dev/mapper/klas-root /UUID=a9d27d62-baa2-426e-949e-e0553e04976a /bootUUID=ECA2-8909 /boot/efi/dev/mapper/klas-swap none# 输出用户ID并以 | 分隔
awk -F: '{print $1"|"$3}' /etc/passwd | head -n 3root|0bin|1daemon|2# 指定分隔符时包含在 [ ] 中的字符将作为分隔字符,而 [ , ] 字符不作为分隔符处理
echo "[weiyigeek.top]" | awk -F "[ .]" '{ print $2}'
top]使用扩展正则分隔输出, 值得学习借鉴
# 面试题:取出分区利用率
df | awk -F '[[:space:]]+|%' '{print $1,$5}'
# 或者
df | awk -F ' +|%' '{print $1,$5}'文件系统 已用devtmpfs 0tmpfs 0tmpfs 2tmpfs 0/dev/mapper/klas-root 37tmpfs 1/dev/nvme0n1p2 29/dev/nvme0n1p1 2tmpfs 0tmpfs 0# 面试题:自定义提取指定硬盘设备的利用率
df | awk -F '[[:space:]]+|%' '/^\/dev/{print $1" -> "$7,$5}'/dev/mapper/klas-root -> / 37/dev/nvme0n1p2 -> /boot 29/dev/nvme0n1p1 -> /boot/efi 2# 面试题:统计当前系统正在使用连接端口以及来源IP数量
netstat -an | grep "ESTABLISHED" | grep -v "127.0.0.1" | awk -F "[ :]+" '{print $5,$6}' | sort | uniq -c
netstat -an | grep "ESTABLISHED" | awk -F "[ :]+" '{print $5,$6}' | sort |uniq -c6 127.0.0.11 183.232.94.2161 1521 10.20.172.1581 22 10.20.172.1031 42018 10.20.172.158# 面试题:取出ifconfig 命令结果中的 网卡和 IP 地址
ifconfig | awk -F ' +|:' '/netmask|UP/{print $1,$3}' | awk '{print $1}'
ens160
10.20.172.158
lo
127.0.0.1温馨提示:在 awk 中脚本通常是被单引号'{ 命令 }'或双引号"{ 命令 }"中, 的 print 语句中双引号是被当作拼接符使用,例如 '{ print $1"="$2}' 结果将以 = 分隔输出。
使用格式化占位符输出,常用值得学习借鉴
awk -F: '{printf "%s\n",$1}' /etc/passwd | head -n 3
awk -F: '{printf "%10s\n",$1}' /etc/passwd | head -n 3
awk -F: '{printf "%-10s\n",$1}' /etc/passwd | head -n 3
awk -F: '{printf "%-10s %10d\n",$1,$3}' /etc/passwd | head -n 3
awk -F: '{printf "user: %-18s , uid: %5d\n",$1,$3}' /etc/passwd | head -n 3# user: root , uid: 0# user: bin , uid: 1# user: daemon , uid: 2# ascii 字符输出
echo | awk 'BEGIN{printf "%c %d",65,"A"}'# A 0# 进制转换输出
echo | awk 'BEGIN{printf "%c %d %o %x \n",97,97,97,97;printf "%c %d %o %x \n",98,98,98,98}'a 97 141 61b 98 142 62变量调用
描述:在 awk 中变量分为内置变量和自定义变量, 其中内置变量(预定义变量)包括:NR、NF、FILENAME、FS、RS、OFS、ORS、OFMT、ARGC、ARGV 等;自定义变量通常是在命令行中或在 BEGIN 和 END 块中定义调用,特别注意 awk 中变量区分大小写。
内置变量
描述:其中不同的发行版本的awk工具,支持的内置变量可能不同,建议查看 awk 帮助手册,这里作者也简单罗列部分:
# 不同 awk 发行版,简写缩写
[A] = awk
[N] = nawk
[P] = POSIXawk
[G] = gawk ,基本都兼容# 内置变量
$n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
$0 这个变量包含执行过程中当前行的文本内容。
[N] ARGC # 命令行参数的数目。
[G] ARGIND # 命令行中当前文件的位置(从0开始算)。
[N] ARGV # 命令行参数的数组。
[G] CONVFMT # 数字转换格式(默认值为%.6g)。
[P] ENVIRON # 环境变量关联数组。
[N] ERRNO # 最后一个系统错误的描述。
[G] FIELDWIDTHS # 字段宽度列表(用空格键分隔)。
[A] FILENAME # 当前输入文件的名。
[P] FNR # 同NR,但相对于当前文件。
[A] FS # 字段分隔符(默认是任何空格)。
[G] IGNORECASE # 如果为真,则进行忽略大小写的匹配。
[A] NF # 表示字段数,在执行过程中对应于当前的字段数。常用
[A] NR # 表示记录数,在执行过程中对应于当前的行号。常用
[A] OFMT # 数字的输出格式(默认值是%.6g)。
[A] OFS # 输出字段分隔符(默认值是一个空格)。常用
[A] ORS # 输出记录分隔符(默认值是一个换行符)。
[A] RS # 记录分隔符(默认是一个换行符)。
[N] RSTART # 由match函数所匹配的字符串的第一个位置。
[N] RLENGTH # 由match函数所匹配的字符串的长度。
[N] SUBSEP # 数组下标分隔符(默认值是34)。简单示例
位置参数变量:从 $0~{n} 开始,类似于 shell 中位置参数变量
# 1.输出第几列的数据
echo -e "1 2 3\n4 5 6\n7 8 9" | awk '{print $0," ==",$1,"-",$2,"-",$3}'
# 1 2 3 == 1 - 2 - 3
# 4 5 6 == 4 - 5 - 6
# 7 8 9 == 7 - 8 - 9# 2.打印每一行的第二和第三个字段:
echo -e "1 2 3\n4 5 6\n7 8 9" | awk '{ print $2,$3 }'
# 2 3
# 5 6
# 8 9FS 变量 :默认为空白字符,功能相当于 -F 选项,注意同时使用时-F优先级最高。
相关文章:
Linux 命令 | 每日一学,文本处理三剑客之awk命令实践
[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ] 0x00 前言简述 描述:前面作者已经介绍了文本处理三剑客中的 grep 与 sed 文本处理工具,今天将介绍其最后一个且非常强大的 awk 文本处理输出工具,它可以非常方便…...

RabbitMQ的工作队列在Spring Boot中实现(详解常⽤的⼯作模式)
上文着重介绍RabbitMQ 七种工作模式介绍RabbitMQ 七种工作模式介绍_rabbitmq 工作模式-CSDN博客 本篇讲解如何在Spring环境下进⾏RabbitMQ的开发.(只演⽰部分常⽤的⼯作模式) 目录 引⼊依赖 一.工作队列模式 二.Publish/Subscribe(发布订阅模式) …...
方法实现全局注册组件的通用代码)
【web前端笔记】vue3 + vite的前端项目中,使用import.meta.glob()方法实现全局注册组件的通用代码
目录 1.1、如何读取所有文件 1.2、通用代码 1.3、在main.js引入 这篇文章介绍一下,在vue3和vite搭建的项目中,如何将【src/components】目录下所有的【*.vue】文件,当做一个组件全局注册到Vue对象里面。 1.1、如何读取所有文件 在vue3和vite搭建的项目里面,它给我们提…...

保险行业建立知识管理系统:提高效率和安全性的策略
在保险行业,知识管理系统(KMS)的建立对于提高工作效率和保障数据安全性至关重要。保险公司需要在复杂的生态系统中航行,这个生态系统由不断发展的法规、错综复杂的保单和投保人不断变化的需求所定义。以下是一些关键策略ÿ…...

小程序如何完成订阅
小程序如何完成订阅 参考相关文档实践问题处理授权弹窗不再触发引导用户重新授权 参考相关文档 微信小程序实现订阅消息推送的实现步骤 发送订阅消息 小程序订阅消息(用户通过弹窗订阅)开发指南 实践 我们需要先选这一个模板,具体流程参考…...

JS学习日记(jQuery库)
前言 今天先更新jQuery库的介绍,它是一个用来帮助快速开发的工具 介绍 jQuery是一个快速,小型且功能丰富的JavaScript库,jQuery设计宗旨是“write less,do more”,即倡导写更少的代码,做更多的事…...

Uni-APP+Vue3+鸿蒙 开发菜鸟流程
参考文档 文档中心 运行和发行 | uni-app官网 AppGallery Connect DCloud开发者中心 环境要求 Vue3jdk 17 Java Downloads | Oracle 中国 【鸿蒙开发工具内置jdk17,本地不使用17会报jdk版本不一致问题】 开发工具 HBuilderDevEco Studio【目前只下载这一个就…...

Linux的基本用法
Linux的基本用法涵盖多个方面,包括用户登录、系统操作、文件和目录管理、系统工具使用等。以下是对Linux基本用法的详细介绍: 一、用户登录与系统操作 用户登录 普通用户登录:选择用户名并输入密码。超级用户(root)登…...

如何找出爬取网站的来源IP呢?
1.背景 最近网站数据库性能很不稳定,查询性能在某段时间很慢,服务器CPU也很高,平常时间很低,感觉被爬虫恶意搞了,因此我分析了一下最近的nginx访问日志 2.方法 找出访问量最大20个ip [root100 nginx]# cat liuhaih…...
详解)
Java爬虫(Jsoup)详解
文章目录 Java爬虫(Jsoup)详解一、引言二、Jsoup 快速入门1、Jsoup 简介1.1、添加依赖 2、解析 HTML 文档2.1、解析 HTML 字符串2.2、从 URL 加载 Document2.3、解析 body 片断 三、数据抽取1、使用 DOM 方法遍历文档3.1、获取元素 2、使用选择器语法查找…...

力扣周赛:第424场周赛
👨🎓作者简介:爱好技术和算法的研究生 🌌上期文章:力扣周赛:第422场周赛 📚订阅专栏:力扣周赛 希望文章对你们有所帮助 第一道题模拟题,第二道题经典拆分数组/线段树都…...

预处理(1)(手绘)
大家好,今天给大家分享一下编译器预处理阶段,那么我们来看看。 上面是一些预处理阶段的知识,那么明天给大家讲讲宏吧。 今天分享就到这里,谢谢大家!!...

利用OpenAI进行测试需求分析——从电商网站需求到测试用例的生成
在软件测试工程师的日常工作中,需求分析是测试工作中的关键步骤。需求文档决定了测试覆盖的范围和测试策略,而测试用例的编写往往依赖于需求的准确理解。传统手工分析需求耗时长,尤其在面对大量需求和复杂逻辑时容易遗漏细节。本文将以电商网…...

深入探索:Scrapy深度爬取策略与实践
标题:深入探索:Scrapy深度爬取策略与实践 引言 在数据驱动的时代,深度爬取成为了获取丰富信息的重要手段。Scrapy,作为一个强大的Python爬虫框架,提供了多种工具和设置来帮助我们实现深度爬取。本文将详细介绍如何在…...

《生成式 AI》课程 第3講:訓練不了人工智慧嗎?你可以訓練你自己
资料来自李宏毅老师《生成式 AI》课程,如有侵权请通知下线 Introduction to Generative AI 2024 Spring 摘要 这一系列的作业是为 2024 年春季的《生成式 AI》课程设计的,共包含十个作业。每个作业都对应一个具体的主题,例如真假难辨的世界…...

如何编译 Cesium 源码
如何编译 Cesium 源码 Cesium 是一个开源的 JavaScript 库,用于构建 3D 地球和地图应用程序。它提供了一套强大的 API 和工具,使开发者能够创建丰富的地理空间应用。本文将指导您如何从 GitHub 下载 Cesium 源码,并在本地进行编译。 TilesB…...

前端开发设计模式——责任链模式
目录 一、定义和特点 1. 定义 2. 特点 二、实现方式 定义抽象处理者(Handler)类 创建具体处理者(ConcreteHandler)类 构建责任链 以下是一个用 JavaScript 实现的示例: 三、应用场景 1. 表单验证 2. 请求处…...

JavaWeb--MySQL
1. MySQL概述 首先来了解一下什么是数据库。 数据库:英文为 DataBase,简称DB,它是存储和管理数据的仓库。 像我们日常访问的电商网站京东,企业内部的管理系统OA、ERP、CRM这类的系统,以及大家每天都会刷的头条、抖音…...

Python | Leetcode Python题解之第564题数组嵌套
题目: 题解: class Solution:def arrayNesting(self, nums: List[int]) -> int:ans, n 0, len(nums)for i in range(n):cnt 0while nums[i] < n:num nums[i]nums[i] ni numcnt 1ans max(ans, cnt)return ans...
Spring Boot教程之Spring Boot简介
Spring Boot 简介 接下来一段时间,我会持续发布并完成Spring Boot教程 Spring 被广泛用于创建可扩展的应用程序。对于 Web 应用程序,Spring 提供了 Spring MVC,它是 Spring 的一个广泛使用的模块,用于创建可扩展的 Web 应用程序。…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...