【Apache Paimon】-- 2 -- 核心特性 (0.9.0)
目录
1、实时更新
1.1、实时大批量更新
1.2、支持定义合并引擎
1.3、支持定义更新日志生成器
2、海量数据追加处理
2.1、append table
2.2、快速查询
3、数据湖功能(类比:hudi、iceberg、delta)
3.1、支持 ACID 事务
3.2、支持 Time travel(时间旅行)
3.3、支持 Schema Evolution(元数据变更)
3.4、可扩展元数据:存储 PB 级大规模数据集和存储大量分区
3.4.1、表级别的元数据管理
3.4.2、架构可扩展性
3.4.3、自定义扩展
3.4.4、版本管理和一致性
3.4.5、与其他系统的兼容性
3.5、分区过期设置
4、参考
1、实时更新
1.1、实时大批量更新
通过 Flink streaming 可以实现 primary key 表的实时大批量更新。
1.2、支持定义合并引擎
用户可以随心所欲地更新记录。复制以保留最后一行,或部分更新,或汇总记录,或第一行,提供了很灵活的处理方式,总之可以用户自己决定。
主键表的数据更新提供了以下合并机制:
| 合并机制 | 详情 |
| (1)去重(Deduplicate) | 去重机制(deduplicate)是默认的数据合并机制。对于多条具有相同primary key的数据,Paimon结果表仅会保留最新一条数据,并丢弃其它具有primary key的数据。 说明 如果最新一条数据是一条delete消息,所有具有该primary key的数据都将被丢弃。 |
| (2)部分更新(Partial Update) | 通过指定部分更新机制(partial-update),您可以通过多条消息对数据进行逐步更新,并最终得到完整的数据。具体来说,具有相同primary key的新数据将会覆盖原来的数据,但值为null的列不会进行覆盖。 例如,假设Paimon结果表按顺序收到了以下三条数据:
第一列是primary key,则最终结果为<1, 25.2, 10, 'This is a book'>。 说明
|
| (3)预聚合(Aggregation) | 部分场景下,可能只关心聚合后的值。预聚合机制(aggregation)将具有相同primary key的数据根据您指定的聚合函数进行聚合。对于不属于primary key的每一列,都需要通过 price列将会根据max函数进行聚合,而sales列将会根据sum函数进行聚合。给定两条输入数据 <1, 23.0, 15>和 <1, 30.2, 20>,最终结果为<1, 30.2, 35>。当前支持的聚合函数与对应的数据类型如下:
说明
|
参数设置如下:
| 参数 | 说明 | 类型 | 必填 | 默认值 | 备注 |
| merge-engine | 相同primary key数据的合并机制。 | String | 否 | deduplicate | 参数取值如下:
关于数据合并机制的具体分析,详情请参见数据合并机制。 |
1.3、支持定义更新日志生成器
用户可以在更新中为合并引擎生成正确、完整的更新日志,简化流式分析。
Paimon 每个数据文件包含多行,每行都有一种行类型(用字母表示),该类型将行标记为插入 (+I)、更新 (+U) 或删除 (-D)。更新可以支持变更日志生成器的更新前 (-U) 和更新后 (+U)。

2、海量数据追加处理
2.1、append table
追加表(非 primary key table )提供大规模批处理和流式处理能力,并实现小文件合并。
Paimon 表目前支持的写入模式如下:
| 模式 | 详情 |
| Change-log | change-log写入模式是Paimon表的默认写入模式。该写入模式支持根据primary key对数据进行插入、删除与更新,您也可以在该写入模式下使用上文提到的数据合并机制与增量数据产生机制。 |
| Append-only | append-only写入模式仅支持数据的插入,且不支持primary key。该模式比change-log模式更加高效,可在对数据新鲜度要求一般的场景下(例如分钟级新鲜度)作为消息队列的替代品。 关于append-only写入模式的详细介绍,请参见Apache Paimon官方文档。在使用append-only写入模式时,需要注意以下两点:
|
2.2、快速查询
支持数据压缩,使用 Z 排序优化文件布局,使用最小最大等索引提供基于数据跳转的快速查询。
Z-order 基本介绍:Z-Order 是一种可以将多维数据压缩到一维的技术,在时空索引以及图像方面使用较广。Z曲线可以以一条无限长的一维曲线填充任意维度的空间,对于数据库的一条数据来说,我们可以将其多个要排序的字段看作是数据的多个维度,z曲线可以通过一定的规则将多维数据映射到一维数据上,构建 z-value 进而可以基于该一维数据进行排序。
3、数据湖功能(类比:hudi、iceberg、delta)
3.1、支持 ACID 事务
Paimon 通过提供 ACID(原子性、一致性、隔离性、持久性)事务,确保数据的一致性和可靠性,这对于在复杂数据处理流水线中维护数据完整性至关重要。
3.2、支持 Time travel(时间旅行)
当用户在查询数据的时候, 若要从之前的某一个时间点开始查询数据, 即任务启动时想要查一些历史数据, 则需用时间旅行这个特性。用户可通过 scan.mode 参数设置Paimon源表的消费位点。scan.mode 参数的可选值以及行为如下:
| 参数值 | 批读行为 | 流读行为 |
| default | 默认值,根据其他参数确定实际的行为。
如果以上两个参数都没有设置,则行为与latest-full参数值相同。 | |
| latest-full | 读产出表的最新 snapshot。 | 作业启动时,读首先产出表的最新snapshot,之后持续产出增量数据。 |
| compacted-full | 只读取产出表最近一次 compact后的snapshot。 | 作业启动时,首先产出表最近一次compact后的snapshot,之后持续产出增量数据。 |
| latest | 与latest-full相同。 | 只读取最新的变更数据 |
| from-timestamp | 只读取指定时间戳(含该时间戳)的快照中的所有数据。 | 作业启动时不产出snapshot,之后持续产出从 |
| from-snapshot | 产出表的snapshot,snapshot编号由 | 作业启动时不产出snapshot,之后持续产出从 |
| from-snapshot-full | 与from-snapshot相同。 | 作业启动时产出表的snapshot,snapshot编号由 |
3.3、支持 Schema Evolution(元数据变更)
即源端增加列、不用重启 Flink 作业、可以自动识别实时导入到 Paimon 表。目前,Paimon支持的 CDC 形式包括:Mysql、Postgres、Kafka、Mongo、Pulsar。
3.4、可扩展元数据:存储 PB 级大规模数据集和存储大量分区
Apache Paimon 元数据可扩展主要指的是其在元数据管理上的扩展能力和灵活性。具体包括以下方面:
3.4.1、表级别的元数据管理
- 多表支持:Paimon能够同时管理大量表的元数据,且性能随表的数量扩展良好。
- 动态分区管理:支持大规模分区动态加载和裁剪,适合高并发场景和海量分区表。
3.4.2、架构可扩展性
- 元数据分布式存储:Paimon的元数据可以存储在分布式存储(如 HDFS、S3)或集中式系统(如 Hive Metastore)中,能够支持大规模的元数据查询和更新。
- 元数据分片和分区:通过分布式存储或缓存优化元数据访问,提升查询效率,减少热点问题。
3.4.3、自定义扩展
- Schema 演进:支持字段的添加、修改、删除等操作,而无需重新生成全量数据表。
- 自定义元数据:支持用户根据需求自定义元数据字段,如表注释、存储策略、访问权限等。
3.4.4、版本管理和一致性
- 多版本管理:Paimon对表的元数据支持多版本管理,可以随时回滚或查询历史元数据。
- 事务支持:确保元数据更新的一致性和隔离性(ACID),即便在高并发操作下也能保证正确性。
3.4.5、与其他系统的兼容性
- 与 Hive Metastore 的集成:通过标准接口与现有大数据生态兼容(如 Hive、Spark、Flink 等)。
- 统一视图:Paimon中的元数据能够被多个计算引擎同时使用,实现数据湖与数据仓的统一。
3.5、分区过期设置
Paimon表支持自动删除存活时长大于分区过期时长的分区的功能,以节省存储成本。详情如下:
-
存活时长:当前系统时间减去分区值转化后的时间戳。分区值转化后的时间戳是按照以下顺序转化而得:
-
通过格式串
partition.timestamp-pattern参数,将一个分区值转换为时间字符串。在该格式串中,分区列由美元符号($)加上列名表示。例如,假设分区列由year、month、day、hour四列组成,格式串
$year-$month-$day $hour:00:00会将分区year=2023,month=04,day=21,hour=17转换为字符串2023-04-21 17:00:00。 -
通过格式串
partition.timestamp-formatter参数,将时间字符串转换为时间戳。如果该参数没有设置,将默认尝试
yyyy-MM-dd HH:mm:ss与yyyy-MM-dd两个格式串。任何Java的DateTimeFormatter兼容的格式串都可以使用。
-
-
分区过期时间:您设置的
partition.expiration-time参数值。
4、参考
Overview | Apache Paimon
Paimon连接器_实时计算 Flink版(Flink)-阿里云帮助中心
Understanding Apache Paimon's Consistency Model Part 1 — Jack Vanlightly
相关文章:
【Apache Paimon】-- 2 -- 核心特性 (0.9.0)
目录 1、实时更新 1.1、实时大批量更新 1.2、支持定义合并引擎 1.3、支持定义更新日志生成器 2、海量数据追加处理 2.1、append table 2.2、快速查询 3、数据湖功能(类比:hudi、iceberg、delta) 3.1、支持 ACID 事务 3.2、支持 Time…...

golang对日期格式化
1.对日期格式化为 YYYY-mm-dd, 并且没有数据时,返回空 import ("encoding/json""time" )type DateTime time.Timetype SysRole struct {RoleId int64 gorm:"type:bigint(20);primary_key;auto_increment;角色ID;" json:&quo…...
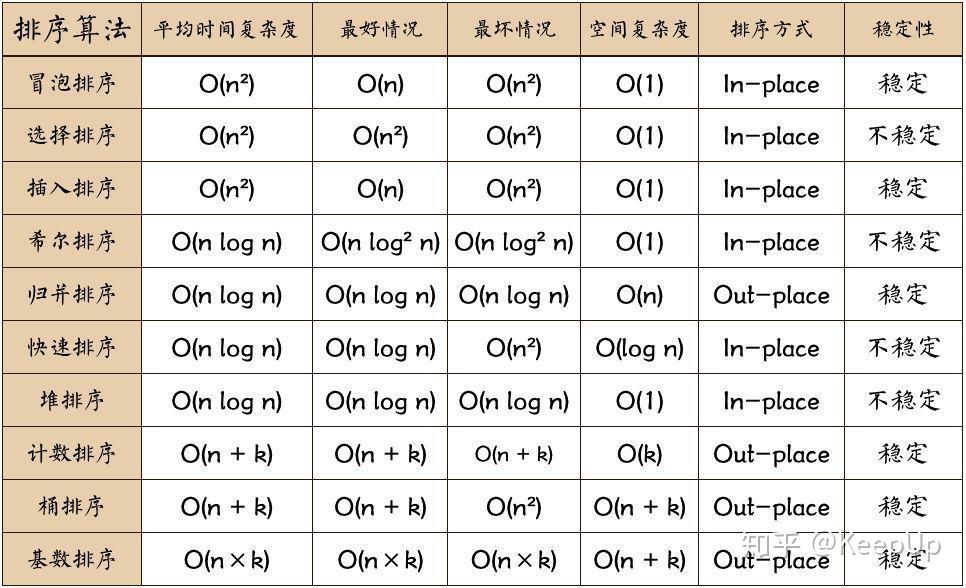
【数据结构与算法】排序
文章目录 排序1.基本概念2.分类2.存储结构 一.插入排序1.1直接插入排序1.2折半插入排序1.3希尔排序 二.选择排序2.1简单选择排序2.2堆排序 三.交换排序3.1冒泡排序3.2快速排序 四.归并排序五.基数排序**总结** 排序 1.基本概念 排序(sorting)又称分类&…...

前端常见的几个包管理工具详解
文章目录 前端常见的几个包管理工具详解一、引言二、包管理工具详解1、npm1.1、npm的安装与使用 2、yarn2.1、yarn的安装与使用 3、pnpm3.1、pnpm的安装与使用 三、步骤二4、包管理工具的选择 四、总结优缺点对比 前端常见的几个包管理工具详解 一、引言 在前端开发的世界里&…...
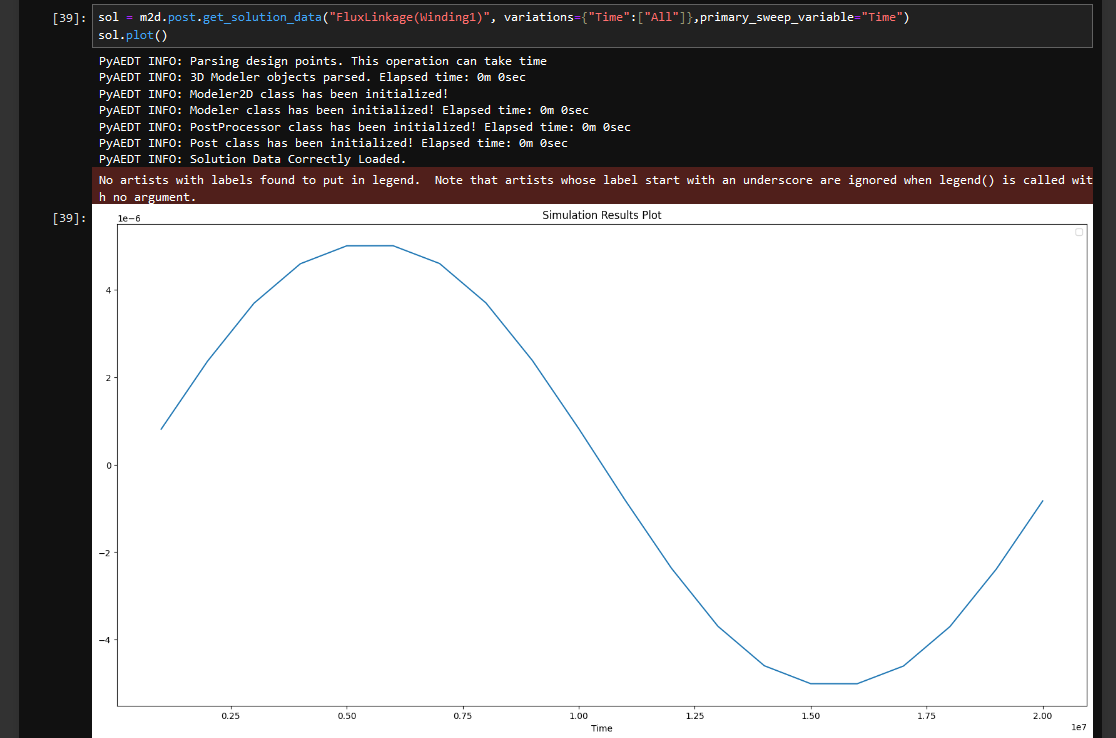
PyAEDT:Ansys Electronics Desktop API 简介
在本文中,我将向您介绍 PyAEDT,这是一个 Python 库,旨在增强您对 Ansys Electronics Desktop 或 AEDT 的体验。PyAEDT 通过直接与 AEDT API 交互来简化脚本编写,从而允许在 Ansys 的电磁、热和机械求解器套件之间无缝集成。通过利…...
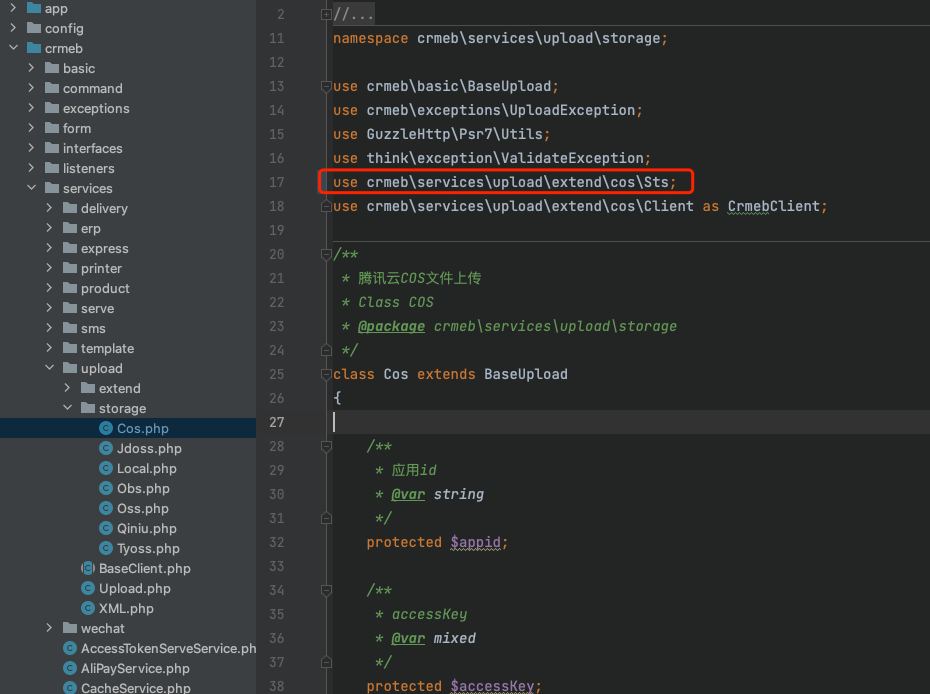
腾讯云存储COS上传视频报错
bug表现为:通过COS上传视频时报错"Class \"QCloud\\COSSTS\\Sts\" not found" 修复办法为:找到文件crmeb/services/upload/storage/Cos.php 将Sts引入由QCloud\COSSTS\Sts;改为crmeb\services\upload\extend\cos\Sts; 修改后重启服…...
 如何在Tomcat中配置访问日志?)
Tomcat(17) 如何在Tomcat中配置访问日志?
在Apache Tomcat中配置访问日志是一个重要的步骤,它可以帮助你跟踪和分析服务器的HTTP请求。访问日志通常记录了每个请求的详细信息,如客户端IP地址、请求时间、请求的URL、HTTP状态码等。以下是如何在Tomcat中配置访问日志的详细步骤和代码示例。 步骤…...

根据频繁标记frequent_token,累加size
根据频繁标记frequent_token,累加size for k, v in contents.items(): 0 (LDAP Built with OpenLDAP LDAP / SDK, /:=@) 1 (LDAP SSL support unavailable, :) 2 (suEXEC mechanism enabled lili wrapper /usr/sbin/suexec, ()/:) 3 (Digest generating secret for digest au…...

2、计算机网络七层封包和解包的过程
计算机网络osi七层模型 1、网络模型总体预览2、数据链路层4、传输层5.应用层 1、网络模型总体预览 图片均来源B站:网络安全收藏家,没有本人作图 2、数据链路层 案例描述:主机A发出一条信息,到路由器A,这里封装目标MAC…...

无人机飞手入门指南
无人机飞手入门指南旨在为初学者提供一份全面的学习路径和实践建议,帮助新手快速掌握无人机飞行技能并了解相关法规知识。以下是一份详细的入门指南: 一、了解无人机基础知识 1. 无人机构造:了解无人机的组成部分,如机身、螺旋桨…...

Redis与IO多路复用
1. Redis与IO多路复用概述 1.1 Redis的单线程特性 Redis是一个高性能的键值存储系统,其核心优势之一便是单线程架构。在Redis 6.0之前,其所有网络IO和键值对的读写操作都是由一个主线程顺序串行处理的。这种设计简化了多线程编程中的锁和同步问题&…...

基于Java和Vue实现的上门做饭系统上门做饭软件厨师上门app
市场前景 生活节奏加快:在当今快节奏的社会中,越来越多的人因工作忙碌、时间紧张而无法亲自下厨,上门做饭服务恰好满足了这部分人群的需求,为他们提供了便捷、高效的餐饮解决方案。个性化需求增加:随着人们生活水平的…...

spi 回环
///tx 极性0 (sclk信号线空闲时为低电平) /// 相位0 (在sclk信号线第一个跳变沿进行采样) timescale 1ns / 1ps//两个从机 8d01 8d02 module top(input clk ,input rst_n,input [7:0] addr ,input …...

数据库审计工具--Yearning 3.1.9普民的使用指南
1 页面登录 登录地址:18000 (不要勾选LDAP) 2 修改用户密码 3 DML/DDL工单申请及审批 工单申请 根据需要选择【DML/DDL/查询】中的一种进行工单申请 填写工单信息提交SQL检测报错修改sql语句重新进行SQL检测,如检测失败可以进行SQL美化后…...

JAVA接口代码示例
public class VehicleExample {// 定义接口public interface Vehicle {void start(); // 启动车辆void stop(); // 停止车辆void status();// 检查车辆状态}public interface InnerVehicleExample {void student();}// 实现接口的类:Carpublic static class Car imp…...

【Android】Proxyman 抓 HTTP 数据包
前言 抓包(Packet Capture)是指在网络通信中截取、分析数据包的过程。 抓包通常用于网络调试、性能优化、安全分析等工作,可以帮助开发者或运维人员查看网络请求的详细内容,包括请求的URL、请求头、响应状态、数据内容等信息。 …...
基于Java Springboot活力健身馆管理系统
一、作品包含 源码数据库设计文档万字PPT全套环境和工具资源部署教程 二、项目技术 前端技术:Html、Css、Js、Vue、Element-ui 数据库:MySQL 后端技术:Java、Spring Boot、MyBatis 三、运行环境 开发工具:IDEA/eclipse 数据…...

Excel SUMIFS
SUMIFS 是 Excel 中一个非常强大的函数,用于根据多个条件对数值区域进行求和。它是 SUMIF 函数的升级版,能够处理多个条件,使得数据分析变得更加精确和方便。 SUMIFS 函数的语法 excel 复制代码 SUMIFS(sum_range, criteria_range1, criteri…...

复制Qt项目后常见问题解决
前言 很多时候因为我们不想在原有的重要代码上作修改,常常将代码复制一份。今天讨论的就是代码复制后,复制的代码运行不正常或出错的问题。 第一个问题:图片等资源文件运行时加载失败 当我将程序运行起来后,我发现有些图片没有显…...
)
C#-WPF 常见类型转换方法(持续更新)
目录 一、普通类型转换 1、Convert类 2、Parse(转String) 3、TryParse(转String) 4、ToString(转String) 5、int转double 6、自定义类型的显示/隐式转换 二、byte[]转ImageSource 方法一 方法二 一、普通类型转换 1、Convert类 提供了一种安全的方式来执行类型转换&…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...