数据结构(基本概念及顺序表——c语言实现)
基本概念:
1、引入
程序=数据结构+算法
数据:
数值数据:能够直接参加运算的数据(数值,字符)
非数值数据:不能够直接参加运算的数据(字符串、图片等)
数据即是信息的载体,能够被输入到计算机中存储,识别和处理的符号总称;
数据元素:
数据的一个基本单位,又叫做记录;
数据类型:
数据元素决定了数据的存储范围以及计算方法;例如:short x;则这个x的取值范围【-32768,+32767】,限定计算{+ - * / %}
数据结构:
数据结构就是去探讨数据元素与数据元素之间的相互关系的学科;
2、基本概念
逻辑结构:数据元素之间的抽象关系(相邻/隶属)
存储结构:在计算机中的具体实现方法
数据运算:对数据进行的操作,例如:增删改查
3、逻辑结构
集合(gather):数据元素在同一范围内部,无其他关系
表(list):一对一,例如:线性表,队列,栈
树(tree):一对多
图(graph):多对多
4、存储结构
存储结构又叫做物理结构,存放到地址上的关系;
顺序存储(sequence):在存储器上按照顺序存放
链式存储(link):利用元素存储地址的指针来描述元素之间的关系
索引存储:(index):在存储数据时额外提供一张索引表
散列存储(hash):先提供一个散列函数,利用散列函数去计算存储位置
数据的逻辑结构与存储结构关系密切
算法的设计:取决于决定的逻辑结构
算法的实现:依赖与采用的存储结构
5、算法
算法是一个有穷规则(语句、命令)的有序集合,它确定了解决某一个问题的一个运算序列。对于问题的初始输入,通过算法的有限步的运行,产生一个或多个输出。
算法的特性:
1)有穷性——算法执行的步骤是有限的
2)确定性——每一个计算步骤是唯一的
3)可行性——每个计算步骤能在有效的时间内完成
4)输入——算法可以有零个或者多个外部输入
5)输出——算法有一个或多个输出
算法的优劣:
1)消耗的时间的多少
2)消耗的存储空间的多少
3)容易理解,容易实现调试和维护是否容易
6、时间复杂度T(n)
通过问题的规模,算法所消耗的时间的多少
#include <stdio.h>
int main(int argc, char *argv[])
{for(int i=0;i<n-1;i++) //=>n-1{for(int j=0;j<n-1-i;j++) //=>(n-1)/2{}}return 0;
}
频度:语句执行的次数
每一条语句的频度之和就是这个算法的时间复杂度
上述代码的时间复杂度为:(n-1)*(n-1)/2 ==>n²/2 - n + 1/2 (当n趋于无穷大时和n²为同阶无穷大)
冒泡排序的时间复杂度(o(n²))
7、空间复杂度D(n)
通过问题规模的扩大,所需要的额外空间的量

8、线性表
线性表的特征:
1)对于非空表而言,a0表头没有前驱
2)an-1表尾,没有后继
3)对于其它的每一个元素ai有且仅有一个直接前驱和直接后继
9、数据结构创建表时之所以常在堆区开空间,主要基于以下几点原因:
1. 灵活性和动态性
-
动态内存分配:堆区允许程序员在运行时动态地分配和释放内存,这意味着可以根据实际需要调整数据结构的大小,而无需在编译时就确定其大小。这对于链表、动态数组等需要频繁调整大小的数据结构尤为重要。
-
避免栈溢出:栈区通常用于存储局部变量和函数调用信息,其空间有限。如果数据结构过大或复杂,可能会导致栈溢出。而在堆区分配内存可以避免这一问题,因为堆区的空间相对较大,且由程序员控制释放。
2. 内存管理灵活性
-
手动管理内存:在堆区分配的内存需要程序员手动释放(使用如
free等函数),这提供了更大的内存管理灵活性。程序员可以根据需要决定何时释放内存,从而优化内存使用。 -
生命周期控制:堆区分配的内存的生命周期由程序员控制,这意味着可以在数据结构不再需要时立即释放内存,减少内存泄漏的风险。
3. 链表等特殊数据结构的需要
-
链表节点:链表节点通常需要在堆区分配内存,因为链表节点的数量和位置在运行时是动态变化的。每个节点都包含数据域和指针域(指向下一个节点的指针),这些节点在内存中的位置不连续,因此适合在堆区分配。
-
内存碎片化:链表等数据结构能够很好地适应内存碎片化的情况,因为它们在堆区分配内存时不需要连续的内存块。
4. 性能优化
-
局部性原理:虽然堆区分配的内存可能不如栈区分配的内存那样具有局部性(即内存访问的集中性),但对于某些数据结构(如哈希表、红黑树等),其内存访问模式可能更适合在堆区分配内存。
-
减少栈空间占用:将大型数据结构放在堆区可以减少栈空间的占用,从而降低栈溢出的风险,并提高程序的稳定性。
顺序表
顺序存储的线性表
顺序存储结构的特点:
1)逻辑上相邻的元素ai,ai+1,其存储位置也是相邻的;
2)对数据元素ai的存取为随机存取或按地址存取
3)存储密度高,存储密度=(数据结构中元素所占存储空间)/(整个数据结构所占空间)
顺序存储结构的不足:
1)对表的插入和删除等运算的时间复杂度较差
2)要求系统提供一片较大的连续存储空间
3)插入、删除等运算耗时,且存在元素在存储器中成片移动的现象
#ifndef _SEQLIST_H
#define _SEQLIST_H#include <stdio.h>
#include <stdlib.h>typedef int Type; //声明顺序表的数据类型
#define LEN 10 //顺序表的大小
#define OUT(A) {printf("%d ",A);} //宏函数最好加;和{}typedef struct{Type data[LEN]; //表的存储空间int count; //记录表的已存元素量
}list; //线性表结构体//创建
list *create_list(); //结构体指针
//判满(满为0,不满为1,错误为-1)
int full_list(list *l);
//判空(空为0,非空为1,错误为-1)
int null_list(list *l);void whether_full(int a);//初始化
void init_list(list *l);
//求长度
int length_list(list *l);
//首插入
void head_insert_list(list *l,Type data);
//插入(尾插)
void insert_list(list *l,Type data);
//查找 按值找,把找到值的下标返回
int search_list(list *l,Type data);
//更新 按值更新,把原值改为新值
void update_list(list *l,Type oldData,Type newData);
//删除
void delete_list(list *l,Type data);
//遍历
void traverse_list(list *l);
//回收
void free_list(list **l);#endif
顺序表的代码较多,所以使用多文件封装来写比较清晰;顺序表的存储既然是要连续的空间地址,那么我们就使用数组来存储,因为数组中的元素就是连续存储的;一个顺序表中除了数组来存储元素外,还需要一个变量来存储数组的长度,因此我定义了一个结构体来存放这两个成员,将结构体重命名为list方便后续使用。
#include "seqlist.h"
//创建
list *create_list()
{list *p = (list *)malloc(sizeof(list));if(NULL == p){perror("create malloc");return NULL;}return p;
}
//判满(满为0,不满为1,错误为-1)
int full_list(list *l)
{if(NULL == l){puts("list is NULL");return -1;}else if(LEN == l->count){puts("表已放满");return 0;}else{//puts("表未满");return 1;}
}
//判空(空为0,非空为1,错误为-1)
int null_list(list *l)
{if(NULL == l){puts("list is NULL");return -1;}return l->count==0?0:1;
}void whether_full(int a)
{if(0 == a)puts("表已满");else if(1 == a)puts("表未满");
}
//初始化
void init_list(list *l)
{if(NULL == l){puts("list is NULL");return;}l->count=0;
}
//求长度
int length_list(list *l)
{if(NULL == l){puts("list is NULL");return -1;}return l->count;// printf("index:%d\n",l->count);
}
//首插入
void head_insert_list(list *l,Type data)
{if(0 == full_list(l))return;int n = l->count;while(n){l->data[n] = l->data[n-1];n--;}l->data[0] = data;l->count++;
}
//插入(尾插)
void insert_list(list *l,Type data)
{if(0 == full_list(l))return;//if(full_list(l))//{//l->data[l->count] = data;//l->count++;//}l->data[l->count] = data;l->count++;
}
//查找 按值找,把找到值的下标返回
int search_list(list *l,Type data)
{if(NULL == l){puts("list is NULL");return -1;}for(int i=0;i<l->count;i++){//memcmp(&data,&l->data[i],sizeof(Type))==0;if(data == l->data[i])return i;}return -1;
}
//更新 按值更新,把原值改为新值
void update_list(list *l,Type oldData,Type newData)
{
#if 1if(NULL == l){puts("list is NULL");return;}for(int i=0;i<l->count;i++){if(oldData==l->data[i])l->data[i]=newData;//break;}
#elseint t;while((t=search_list(l,oldData))!=-1)l->data[t]=newData;
#endif
}
//删除
void delete_list(list *l,Type data)
{if(NULL == l){puts("list is NULL");return;}
#if 0for(int i=0;i<l->count;i++){if(data == l->data[i])for(int j=i;j<l->count-1;j++){l->data[j] = l->data[j+1]}l->count--;i--;}
#elif 1int index = 0;for(int i=0;i<l->count;i++){if(data != l->data[i]) //不是要删的值就赋值,是要删的就不赋,直到是不删的数再把它放到之前要删那个数的位置,相当于是以覆盖的形式删除{l->data[index++]=l->data[i];}}l->count = index;
#endif
}
//遍历
void traverse_list(list *l)
{if(NULL == l){puts("list is NULL");return;}for(int i=0;i<l->count;i++){OUT(l->data[i]);}puts("");
}
//回收
void free_list(list **l) //传二级指针是为了让开辟空间所用的指针指向空 传参传指针的地址
{if(NULL == l){puts("list is NULL");return;}free(*l);*l=NULL;
}
创建:list *create_list()
创建一个顺序表,在堆区开空间,并且创建完之后我们需要拿到表的首地址,因此函数的类型为list *型,创建空间的大小就是结构体的大小,结构体有多大就开多大的空间,开完空间之后我们需要做一个简单的判断,让我们知道开辟空间是否开辟成功,不成功返回NULL,成功返回首地址。
判断表是否放满:int full_list(list *l)
对于顺序表来说,因为在结构体里面我们有一个专门用来记录表中元素个数的变量,因此判断表是否放满直接判断这个变量的值是否等于表的长度LEN即可,满返回一个0,不满返回一个1。
判断表是否为空:int null_list(list *l)
判空跟判满其实差不多,也是判断记录个数的变量的值是否为0,为0就是空,不为0就是非空。
顺序表的初始化和求长度也是跟判空一样的操作,都是操作变量count,初始化就直接把count置零就可以,因为在后续插入内容的时候会将以前的内容覆盖;求长度其实就是直接将count的值当做函数返回值反出去即可。
头部插入:void head_insert_list(list *l,Type data)
对于插入函数来说,我们需要操作表因此需要传参传入表的地址,还有我们需要插入的元素,首先需要判断这个表是否放满,如果放满那就不可以继续再插入,此时直接return即可;为放满那就可以插入,因为是头部插入,因此在插入之前,我们需要给要插入的元素把第一个位置空出来,所以我们需要把表中已有的元素全部往后移动一位,通过一个循环从最后一个元素开始移动,有几个元素就移动几次,移动完之后就可以把要放入的元素放入第一个位置,之后一定不要忘记count要自增1。
尾部插入:void insert_list(list *l,Type data)
尾部插入相对于头部插入就简单得多,首先也是需要判断表满没满,没满之后直接再最后一个元素后面放入要插入的元素即可,l->data[l->count] = data;之后count自增1。
查找:int search_list(list *l,Type data)
查找传入的也是两个参数,表和要查找的值,返回值为该值的下标,通过一个循环遍历的方式来查找我们所需要的元素的下标,找到这个元素循环就结束,如果循环结束都没有找到这个数,那就返回一个-1代表表中没有这个数。
更新:void update_list(list *l,Type oldData,Type newData)
更新函数不需要返回值,传参的话就是表,原值以及需要修改的值,还是跟查找一样的使用循环的方法,找到需要修改的值就直接将这个值修改为更新后的值即可;在这里如果只想要更新查找到的第一个值的话就在循环里面加一个break即可,这样查找到第一个之后就会结束循环。
删除:void delete_list(list *l,Type data)
对于顺序表的删除,我们有两个办法,但是都需要使用到循环;第一种方法是找到要删除的值之后就将它后面的每一个元素都往前移动一位,将这个删除的值直接覆盖掉;第二种方法也是覆盖,首先定义一个变量作为赋值下标,然后判断的条件是当元素不是我要删除的那个数时,就给数组中的数赋值,l->data[index++]=l->data[i];这里的index和i都是从0开始,对于相同的值,再赋值一遍也不会产生影响,但是要是这个数是我们要删除的数,那就不进行这一个赋值操作,这时index的值就不会增加,会停留在要删除的值的前一个,但是i每次都会自增,当下一次循环时,i所对应的元素就是要删除的元素的后一个元素,这时再将这个元素赋值给index下标对应的位置,就可以将要删除的元素覆盖掉;切记一定要在删除的同时count的值也要发生改变。

遍历:void traverse_list(list *l)
顺序表的遍历其实也就是数组的遍历,通过循环遍历数组再输出即可。
回收:void free_list(list **l)
在回收的传参这里,我们只传这个表是不行的,我们需要释放这片空间地址,并且还需要将指向这片空间的指针指向空,因此必须传参传入指针的地址,也就是传一个二级指针,将这个空间free之后还需要将指针指向NULL,这样回收才算结束。
测试(主函数)
#include "seqlist.h"
int main(int argc, char *argv[])
{list *p = create_list();insert_list(p,1);insert_list(p,2);insert_list(p,3);puts("尾插入后");traverse_list(p);head_insert_list(p,4);head_insert_list(p,5);head_insert_list(p,6);puts("首插入后");traverse_list(p);printf("length=%d\n",length_list(p));whether_full(full_list(p));printf("3的下标为:%d\n",search_list(p,3));update_list(p,4,8);puts("将4更改为8后:");traverse_list(p);delete_list(p,5);puts("删除5之后:");traverse_list(p);puts("回收");free_list(&p);printf("p=%p\n",p);return 0;
} 
相关文章:
数据结构(基本概念及顺序表——c语言实现)
基本概念: 1、引入 程序数据结构算法 数据: 数值数据:能够直接参加运算的数据(数值,字符) 非数值数据:不能够直接参加运算的数据(字符串、图片等) 数据即是信息的载…...

ZYNQ程序固化——ZYNQ学习笔记7
一、ZYNQ启动过程 二、 SD卡启动实操 1、对ZYNQ进行配置添加Flash 2、添加SD卡 3、重新生成硬件信息 4、创建vitis工程文件 5、勾选板级支持包 6、对系统工程进行整体编译,生成两个Debug文件,如图所示。 7、插入SD卡,格式化为 8、考入BOOT.…...

labview使用报表工具从数据库导出数据
之前写了一篇labview从数据库导出数据到excel电子表格,但是是基于调用excel的activeX控件,有时候会有一些bug,就比如我工作机就无法显示方法,后面大哥指点才知道没有的原因是excel安装不完整。像我的工作机就没有这个选项。就需要…...

#define定义宏(2)
大家好,今天给大家分享两个技巧。 首先我们应该先了解一下c语言中字符串具有自动连接的特点。注意只有将字符串作为宏参数的时候才可以把字符串放在字符串中。 下面我们来讲讲这两个技巧 1.使用#,把一个宏参数变成对应的字符串。 2.##的作用 可以把位…...

CentOS网络配置
上一篇文章:VMware Workstation安装Centos系统 在CentOS系统中进行网络配置是确保系统能够顺畅接入网络的重要步骤。本文将详细介绍如何配置静态IP地址、网关、DNS等关键网络参数,以帮助需要的人快速掌握CentOS网络配置的基本方法和技巧。通过遵循本文的…...

基于vue框架的的网上宠物交易管理系统46sn1(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。
系统程序文件列表 项目功能:用户,宠物分类,宠物信息 开题报告内容 基于Vue框架的网上宠物交易管理系统开题报告 一、研究背景 随着互联网技术的飞速发展和人们生活水平的提高,宠物已成为许多家庭的重要成员。宠物市场的繁荣不仅体现在实体店的遍地开…...

MySQL数据库:SQL语言入门 【2】(学习笔记)
目录 2,DML —— 数据操作语言(Data Manipulation Language) (1)insert 增加 数据 (2)delete 删除 数据 truncate 删除表和数据,再创建一个新表 (3…...

MySQL深度剖析-索引原理由浅入深
什么是索引? 官方上面说索引是帮助MySQL高效获取数据的数据结构,通俗点的说,数据库索引好比是一本书的目录,可以直接根据页码找到对应的内容,目的就是为了加快数据库的查询速度。 索引是对数据库表中一列或多列的值进…...
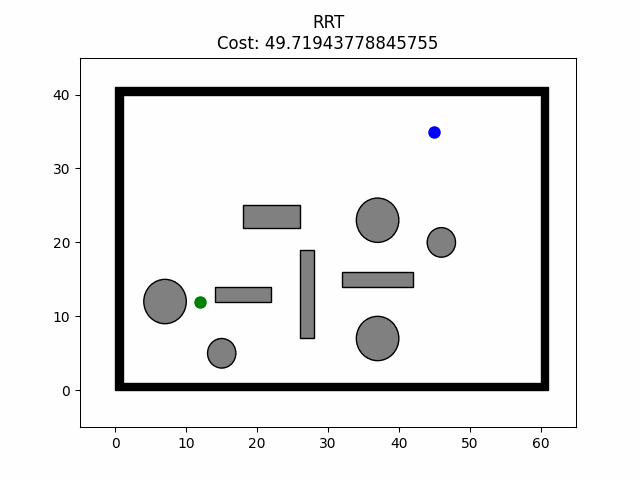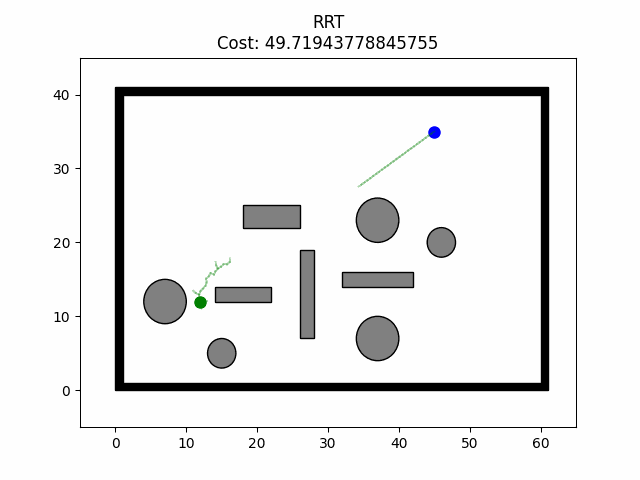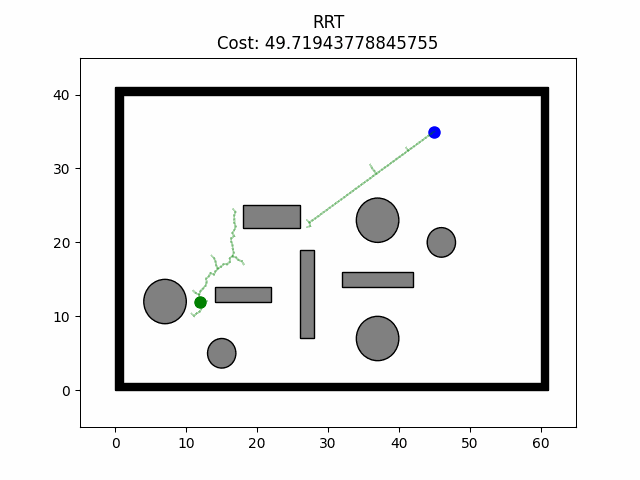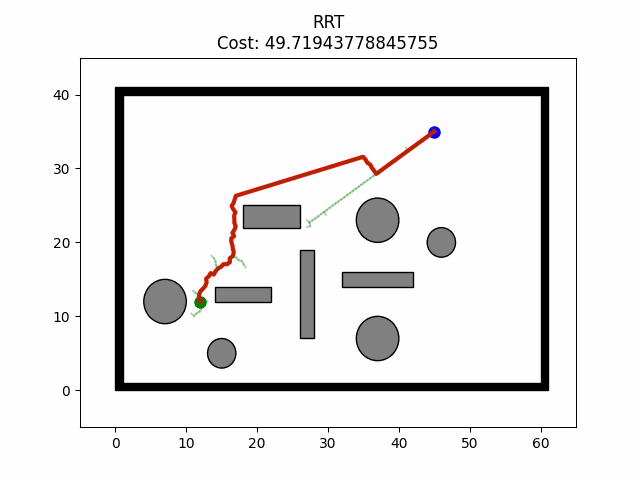
路径规划——RRT-Connect算法
路径规划——RRT-Connect算法 算法原理 RRT-Connect算法是在RRT算法的基础上进行的扩展,引入了双树生长,分别以起点和目标点为树的根节点同时扩展随机树从而实现对状态空间的快速搜索。在此算法中以两棵随机树建立连接为路径规划成功的条件。并且&…...

数据科学与SQL:如何计算排列熵?| 基于SQL实现
目录 0 引言 1 排列熵的计算原理 2 数据准备 3 问题分析 4 小结 0 引言 把“熵”应用在系统论中的信息管理方法称为熵方法。熵越大,说明系统越混乱,携带的信息越少;熵越小,说明系统越有序,携带的信息越多。在传感…...

Redis/Codis性能瓶颈揭秘:网卡软中断的影响与优化
目录 现象回顾 问题剖析 现场分析 解决方案 总结与反思 1.调整中断亲和性(IRQ Affinity): 2.RPS(Receive Packet Steering)和 RFS(Receive Flow Steering): 近期,…...
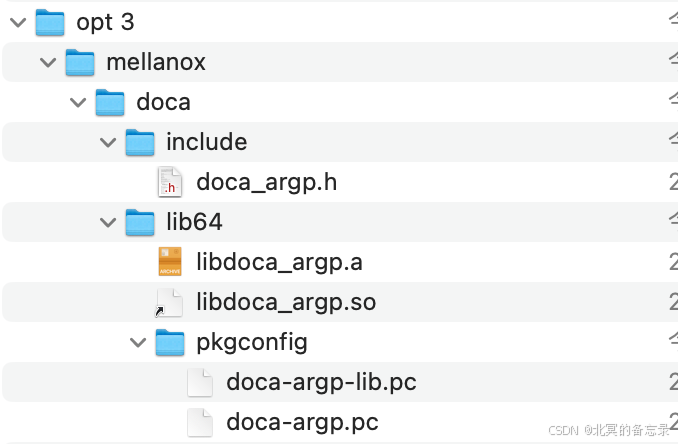
微知-DOCA ARGP参数模块的相关接口和用法(config单元、params单元,argp pipe line,回调)
文章目录 1. 背景2. 设置参数的主要流程2.1 初始化2.2 注册某个params的处理方式以及回调函数2.4 定义好前面的params以及init指定config地点后start处理argv 3. 其他4. DOCA ARGP包相关4.1 主要接口4.2 DOCA ARGP的2个rpm包4.2.1 doca-sdk-argp-2.9.0072-1.el8.x86_64.rpm4.2.…...
)
PostgreSQL高可用Patroni安装(超详细)
目录 一 安装Patroni 0 Patroni 对Python的版本要求 1 卸载原来的Python 3.6 版本 2 安装Python 3.7 之上版本 3 安装依赖 psycopg3 4 安装patroni 5 卸载 patroni 二 安装ETCD 1 使用 yum 安装 etcd 2 etcd 配置文件 3 管理 etcd 4 设置密码 5 常用命令 三 安装…...
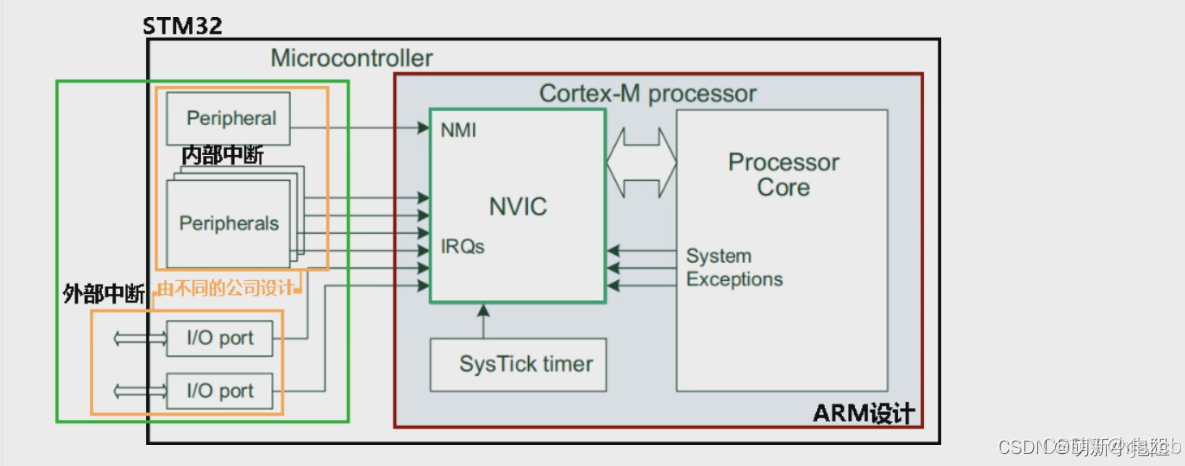
mcu之,armv7架构,contex-M4系列,时钟树,中断,IO架构(一)
写这篇文章的目的,是记录一下arm架构的32mcu,方便记忆芯片架构原理,方便我展开对,BootLoader的研究。 arm架构,时钟树,先做个记录,有空写。...
)
论文解析:基于区块链的去中心化服务选择,用于QoS感知的云制造(四区)
目录 论文解析:基于区块链的去中心化服务选择,用于QoS感知的云制造(四区) 基于区块链的去中心化云制造服务选择方法 一、核心内容概述 二、核心创新点及原理与理论 三、实验与理论分析 PBFT(实用拜占庭容错) 论文解析:基于区块链的去中心化服务选择,用于QoS感知的…...
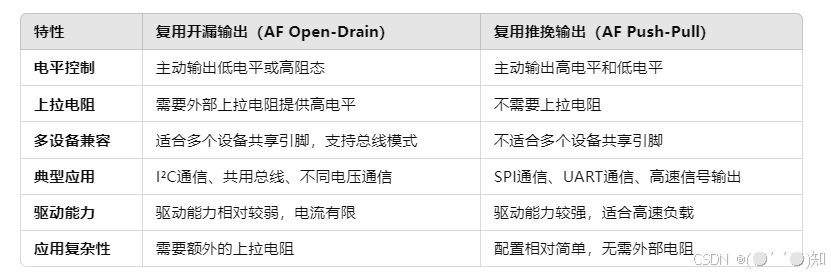
详细解析STM32 GPIO引脚的8种模式
目录 一、输入浮空(Floating Input):GPIO引脚不连接任何上拉或下拉电阻,处于高阻态 1.浮空输入的定义 2.浮空输入的特点 3.浮空输入的应用场景 4.浮空输入的缺点 5.典型配置方式 6.注意事项 二、输入上拉(Inpu…...

【hacker送书第16期】Python数据分析、挖掘与可视化、AI全能助手ChatGPT职场工作效率提升技巧与案例
解锁数据分析与AI应用的双重秘密:全面推广《Python数据分析、挖掘与可视化从入门到精通》与《AI全能助手ChatGPT职场工作效率提升技巧与案例》 前言Python数据分析、挖掘与可视化从入门到精通💕内容简介获取方式 AI全能助手ChatGPT职场工作效率提升技巧与…...

翼鸥教育:从OceanBase V3.1.4 到 V4.2.1,8套核心集群升级实践
引言:自2021年起,翼鸥教育便开始应用OceanBase社区版,两年间,先后部署了总计12套生产集群,其中核心集群占比超过四分之三,所承载的数据量已突破30TB。自2022年10月,OceanBase 社区发布了4.2.x 版…...

WebGIS开发中不同坐标系坐标转换问题
在 JavaScript 中,使用 proj4 库进行坐标系转换是一个非常常见的操作。proj4 是一个支持多种坐标系的 JavaScript 库,提供了从一种坐标系到另一种坐标系的转换功能。 以下是使用 proj4 进行坐标系转换的基本步骤: 1. 安装 proj4 你可以通过…...
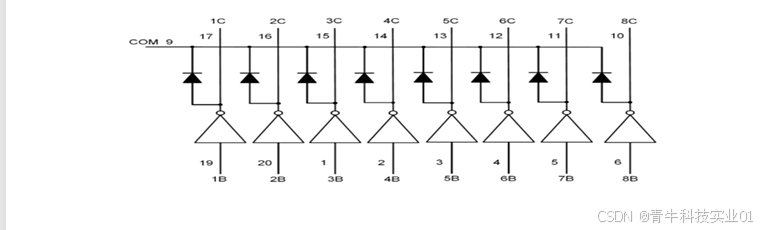
【青牛科技】视频监控器应用
1、简介: 我司安防产品广泛应用在视频监控器上,产品具有性能优良,可 靠性高等特点。 2、图示: 实物图如下: 3、具体应用: 标题:视频监控器应用 简介:视频监控器工作原理是光&#x…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...

Python爬虫实战:研究Restkit库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的有价值数据。如何高效地采集这些数据并将其应用于实际业务中,成为了许多企业和开发者关注的焦点。网络爬虫技术作为一种自动化的数据采集工具,可以帮助我们从网页中提取所需的信息。而 RESTful API …...