Spark 中 RDD checkpoint 是通过启动两个独立的 Job 完成的。
在 Spark 中,RDD checkpoint 是通过启动两个独立的 Job 完成的。这两个 Job 分别用于生成 checkpoint 数据和更新依赖关系。下面从源码角度深入分析这个机制。
1. 为什么需要两个 Job?
当调用 RDD.checkpoint() 后:
- 第一个 Job:将 RDD 的每个分区数据计算后,写入到指定的 checkpoint 存储位置(如 HDFS)。这个步骤的目的是将 RDD 数据物化为可靠存储,减少后续计算的成本。
- 第二个 Job:在 checkpoint 成功完成后,更新 RDD 的依赖关系,将原始的血缘依赖(lineage)替换为从 checkpoint 存储加载数据的依赖。这个步骤的目的是确保后续的计算直接基于 checkpoint 数据,而不是重新计算血缘链。
这两个 Job 是独立的,且按顺序执行,确保 checkpoint 的一致性。
2. 源码分析
以下是 Spark RDD checkpoint 的源码路径和执行过程分析。
2.1 RDD.checkpoint() 的入口
调用 RDD.checkpoint() 方法时:
def checkpoint(): Unit = {if (!isCheckpointedAndMaterialized) {sc.checkpointFile[RDD类型](this)}
}
此方法会:
- 检查是否已经 checkpointed,如果是,直接返回。
- 如果没有,则调用
SparkContext的checkpointFile方法,提交一个任务将数据写入存储。
2.2 SparkContext.checkpointFile()
def checkpointFile[T: ClassTag](rdd: RDD[T]): Unit = {val cpManager = env.checkpointManagercpManager.addCheckpoint(rdd)
}
这里调用了 CheckpointManager 来处理 checkpoint 逻辑。
2.3 CheckpointManager 的作用
CheckpointManager 的核心任务是管理 checkpoint 的执行,分为以下两步:
2.3.1 第一个 Job:生成 checkpoint 数据
- 提交一个 Job,将 RDD 的每个分区数据写入存储。
代码核心逻辑:
def checkpointData[T](rdd: RDD[T]): Unit = {if (!rdd.isCheckpointed) {val newRDD = rdd.materialize() // 触发 RDD 的计算和数据写入rdd.updateCheckpointData(newRDD)}
}
关键点:
- 调用
materialize()触发 Job 提交:- 每个分区的数据会被写入到 checkpoint 目录中(例如 HDFS)。
- 使用的存储格式通常是 Sequence File。
- 数据写入存储后,生成一个新的 RDD。
2.3.2 第二个 Job:更新 RDD 的依赖关系
在 checkpoint 数据写入成功后,RDD 的依赖关系会被替换为从 checkpoint 文件加载数据的依赖。
def updateCheckpointData[T](rdd: RDD[T]): Unit = {rdd.dependencies.clear() // 清除原始的血缘依赖rdd.dependencies += new FileDependency(rdd.checkpointFile)
}
核心逻辑:
- 清除原来的 RDD 血缘关系。
- 为 RDD 添加一个新的文件依赖
FileDependency,确保后续任务直接读取 checkpoint 数据文件,而不是重新计算 lineage。
2.4 为什么需要分成两个 Job?
Spark 使用两个 Job 的原因是分离两种任务的目的:
- 第一个 Job 物化数据:确保所有 RDD 的分区数据被安全地保存到 checkpoint 目录。
- 第二个 Job 更新依赖关系:确保原 RDD 的 lineage 被替换为 checkpoint 数据的直接引用。
这种设计实现了:
- 容错性:即使第一个 Job 出现问题,原始 RDD 的血缘依赖仍然存在。
- 灵活性:两个 Job 分离后,可以分别处理物化和依赖更新的逻辑。
3. 示例说明
以下代码展示了两个 Job 的触发过程:
代码
val rdd = sc.parallelize(1 to 10).map(x => x * x)
rdd.checkpoint()// 触发 checkpoint 计算
println(rdd.collect().mkString(","))
运行过程
-
第一个 Job
- 提交一个任务,计算 RDD 的每个分区数据,并将结果写入 checkpoint 存储。
- 假设有两个分区,Job 会生成类似以下文件:
hdfs://checkpointDir/rdd_1/part-00000 hdfs://checkpointDir/rdd_1/part-00001
-
第二个 Job
- 更新 RDD 的依赖关系。
- 重新定义 RDD 的血缘链,指向 checkpoint 文件,而不是原始计算逻辑。
4. 性能与优化建议
4.1 小文件问题
如果 RDD 分区过多,checkpoint 会在存储中产生大量小文件,增加存储和读取成本。建议:
- 合理设置分区数(
coalesce()或repartition())。 - 优化存储系统(如 HDFS 的 block size)。
4.2 持久化与 checkpoint 配合
由于 checkpoint 需要在计算过程中生成数据,可以结合 persist() 使用,避免重复计算:
rdd.persist(StorageLevel.MEMORY_AND_DISK)
rdd.checkpoint()
4.3 避免不必要的 checkpoint
不要对不重要的 RDD 或生命周期较短的 RDD 设置 checkpoint,避免浪费计算资源。
5. 总结
在 Spark 中,RDD checkpoint 会启动两个 Job:
- 第一个 Job:物化 RDD 数据,将分区数据写入 checkpoint 存储。
- 第二个 Job:更新 RDD 的依赖,将 lineage 替换为对 checkpoint 文件的引用。
这种设计保证了容错性和灵活性,但也引入了一定的性能开销。合理使用 checkpoint 是优化 Spark 应用性能的重要手段。
相关文章:

Spark 中 RDD checkpoint 是通过启动两个独立的 Job 完成的。
在 Spark 中,RDD checkpoint 是通过启动两个独立的 Job 完成的。这两个 Job 分别用于生成 checkpoint 数据和更新依赖关系。下面从源码角度深入分析这个机制。 1. 为什么需要两个 Job? 当调用 RDD.checkpoint() 后: 第一个 Job:…...

如何下载TikTok视频没有水印
随着短视频平台的普及,TikTok(抖音国际版)成为了全球最受欢迎的社交媒体平台之一。它吸引了无数创作者发布自己的短视频内容,内容涵盖了舞蹈、搞笑、挑战、教程、旅行等各个方面。与此用户也常常希望能够下载自己喜欢的TikTok视频…...

天童美语:提升孩子的自信心的方法
每个孩子都渴望展翅高飞,但在成长的旅途中,难免会遇到风雨。不自信,就像一层薄雾,有时悄悄笼罩在孩子心头,阻碍了他们向阳而生的脚步。宁波天童教育认为,身为家长,我们的使命不仅是孩子的庇护伞…...

【网络编程】字节序:大端序和小端序
端序(Endianness),又称字节顺序,又称尾序,在计算机科学领域中,指存储器中或在数字通信链路中,组成多字节的字的字节的排列顺序。 在几乎所有的机器上,多字节对象都被存储为连续的字…...

视频融合×室内定位×数字孪生
随着物联网技术的迅猛发展,室内定位与视频融合技术在各行各业中得到了广泛应用。不仅能够提供精确的位置信息,还能通过实时视频监控实现全方位数据的可视化。 与此同时,数字孪生等技术的兴起为智慧城市、智慧工厂等应用提供了强大支持&#…...

RK3568平台开发系列讲解(platform虚拟总线驱动篇)注册 platform 驱动
🚀返回专栏总目录 文章目录 一、注册 platform 驱动二、platform_driver 结构体沉淀、分享、成长,让自己和他人都能有所收获!😄 一、注册 platform 驱动 platform_driver_register 函数用于在 Linux 内核中注册一个平台驱动程序。 下面是对该函数的详细介绍: 函数原型…...
杀掉Tomcat的几种方法)
Jmeter进阶篇(26)杀掉Tomcat的几种方法
📚Jmeter性能测试大全:Jmeter性能测试大全系列教程❤,这里有你想要的一切,欢迎订阅哦~ 📚前言 Tomcat 是一个广泛使用的开源 Java Servlet 容器,用于部署和运行 Java Web 应用程序。在我们进行压测测试过程中,很可能遇到被测系统崩溃,需要我们来操作一下子Tomcat的情…...

Solana 区块链的技术解析及未来展望 #dapp开发#公链搭建
随着区块链技术的不断发展和应用场景的扩展,性能和可拓展性成为各大公链竞争的关键因素。Solana(SOL)因其高吞吐量、低延迟和低成本的技术特性,在众多区块链项目中脱颖而出,被誉为“以太坊杀手”之一。本文将从技术层面…...
SMO算法-核方法支持向量机
我们现在的问题是要优化目标函数,同时求出参数向量 α \alpha α P m i n ⏟ α 1 2 ∑ i 1 , j 1 m α i α j y i y j K ( x i , x j ) − ∑ i 1 m α i s . t . ∑ i 1 m α i y i 0 0 ≤ α i ≤ C P\underbrace{ min }_{\alpha} \frac{1}{2}\sum\li…...

Java项目实战II基于微信小程序的科创微应用平台(开发文档+数据库+源码)
目录 一、前言 二、技术介绍 三、系统实现 四、文档参考 五、核心代码 六、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。获取源码联系方式请查看文末 一、前言 随着科技的…...

HTTP代理是什么,有什么用?
在互联网的世界里,数据采集已经成为许多企业和个人获取信息的重要手段。而在这个过程中,HTTP代理则是一个不可或缺的工具。那么,HTTP代理究竟是什么?它在数据采集中又有什么用呢?今天,我们就来深入探讨一下…...

Postman之newman
Postman之newman 1.基础环境node安装1.1.配置环境变量1.2.安装newman和html报告组件 2.newman运行 newman可以理解为,没有命令行的postman,把写好的测试脚本直接在命令行中运行,newman依赖于node环境,因此,需要先安装好…...

数据库查询表结构和数据量以及占用空间
数据库查询表结构和数据量以及占用空间 数据库查询表结构 mysql SELECT COLUMN_NAME 列名, COLUMN_TYPE 数据类型, DATA_TYPE 字段类型, CHARACTER_MAXIMUM_LENGTH 长度, IS_NULLABLE 是否为空, COLUMN_DEFAULT 默认值, COLUMN_COMMENT 备注 FROM INFORMATION_SC…...

android 性能分析工具(03)Android Studio Profiler及常见性能图表解读
说明:主要解读Android Studio Profiler 和 常见性能图表。 Android Studio的Profiler工具是一套功能强大的性能分析工具集,它可以帮助开发者实时监控和分析应用的性能,包括CPU使用率、内存使用、网络活动和能耗等多个方面。以下是对Android …...

vscode 执行 vue 命令无效/禁止运行
在cmd使用命令可以创建vue项目但是在vscode上面使用命令却不行 一、问题描述 在 cmd 中已确认vue、node、npm命令可以识别运行,但是在 vscode 编辑器中 vue 命令被禁止,详细报错为:vue : 无法加载文件 D:\Software\nodejs\node_global\vue.…...

C++语言系列-STL容器和算法
C语言系列-STL容器 容器类 本文将对C语言中的标准模板库STL容器进行简单介绍,重点在于如何使用。 容器类 STL中的容器包括以下类别: vector: 动态数组,底层基于数组来实现,在容量不足的时候能够自动进行扩容。list: 链表stack: …...

【Web前端】Promise的使用
Promise是异步编程的核心概念之一。代表一个可能尚未完成的操作,并提供了一种机制来处理该操作最终的成功或失败。具体来说,Promise是由异步函数返回的对象,能够指示该操作当前所处的状态。 当Promise被创建时,它会处于“待定”&a…...

TDK推出第二代用于汽车安全应用的6轴IMU
近日,据外媒报道,TDK株式会社推出用于汽车安全应用的第二代6轴 IMU,即为TDK InvenSense SmartAutomotive MEMS传感器系列增加了IAM-20685HP和IAM-20689,为决策算法提供可靠的运动数据,并实时准确地检测车辆动态。这对于…...
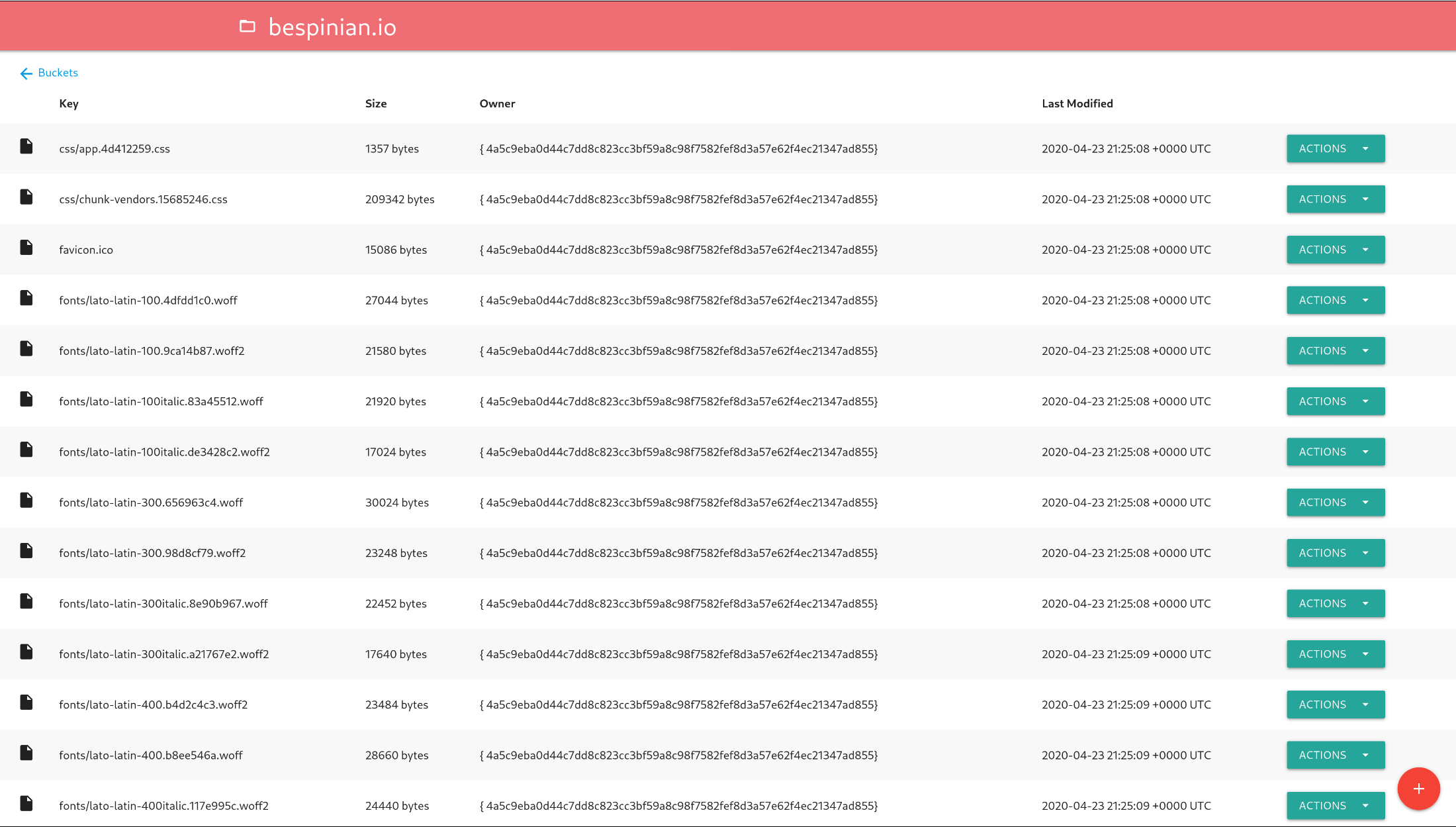
免费S3客户端工具大赏
首发地址(欢迎大家访问):S3免费客户端工具大赏 1. S3 GUI GitHub地址:https://github.com/aminalaee/s3gui 简介:S3 GUI 是一款基于 Flutter 构建的免费开源 S3 桌面客户端,支持桌面、移动和网络平台。 特…...

前端访问后端实现跨域
背景:前端在抖音里做了一个插件然后访问我们的后端。显然在抖音访问其他域名肯定会跨域。 解决办法: 1、使用比较简单的jsonp JSONP 优点:JSONP 是通过动态创建 <script> 标签的方式加载外部数据,属于跨域数据请求的一种…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

C++_哈希表
本篇文章是对C学习的哈希表部分的学习分享 相信一定会对你有所帮助~ 那咱们废话不多说,直接开始吧! 一、基础概念 1. 哈希核心思想: 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。理想目标:实现…...

AT模式下的全局锁冲突如何解决?
一、全局锁冲突解决方案 1. 业务层重试机制(推荐方案) Service public class OrderService {GlobalTransactionalRetryable(maxAttempts 3, backoff Backoff(delay 100))public void createOrder(OrderDTO order) {// 库存扣减(自动加全…...

MyBatis-Plus 常用条件构造方法
1.常用条件方法 方法 说明eq等于 ne不等于 <>gt大于 >ge大于等于 >lt小于 <le小于等于 <betweenBETWEEN 值1 AND 值2notBetweenNOT BETWEEN 值1 AND 值2likeLIKE %值%notLikeNOT LIKE %值%likeLeftLIKE %值likeRightLIKE 值%isNull字段 IS NULLisNotNull字段…...
)
后端下载限速(redis记录实时并发,bucket4j动态限速)
✅ 使用 Redis 记录 所有用户的实时并发下载数✅ 使用 Bucket4j 实现 全局下载速率限制(动态)✅ 支持 动态调整限速策略✅ 下载接口安全、稳定、可监控 🧩 整体架构概览 模块功能Redis存储全局并发数和带宽令牌桶状态Bucket4j Redis分布式限…...