【金融风控项目-08】:特征构造
文章目录
- 1.数据准备
- 1.1 风控建模特征数据
- 1.2 人行征信数据
- 1.3 据之间的内在逻辑
- 2 样本设计和特征框架
- 2.1 定义观察期样本
- 2.2 数据EDA(Explore Data Analysis)
- 2.3 梳理特征框架
- 3 特征构造
- 3.1 静态信息和时间截面特征
- 3.2 未来信息问题
- 3.2.1 未来信息案例
- 3.2.2 时间序列特征的未来信息
- 3.2.3 历史信贷特征出现未来信息
- 3.3 特征构造
- 3.3.1 时序数据特征衍生
- 3.3.2 用户关联特征
1.数据准备
1.1 风控建模特征数据
- 用户信息

- 数据来源

1.2 人行征信数据





1.3 据之间的内在逻辑
- 关系种类
- 一对一:一个用户注册对应有一个注册手机号
- 一对多:一个用户有多笔借款
- 多对多:一个用户可以登录多个设备,一个设备可以有多个用户登录
**举例:**下图中,蓝色框为二月当期账单,红色框为订单

- 梳理类ER图

- 任务:分析厚数据(数据量大)常登录首单用户的逾期情况

- 可以将表结构展示到特征文档中,说明取数逻辑

2 样本设计和特征框架
2.1 定义观察期样本
- 确定观察期(定义x时间切面)和表现期(定Y的标签)
- 确认样本数据是否合理
2.2 数据EDA(Explore Data Analysis)
- 查看数据总体分布
data.shape
data.isnull()
data.info()
data.describe()
- 查看好坏样本分布差异
data[data[label] == 0].describe() # 好用户
data[data[label] == 1].describe() # 坏用户
- 查看单个数据
data.sample(n=10,random_state=1)
2.3 梳理特征框架
-
RFM生成新特征
举例:行为评分卡中的用户账单还款特征 -
用户账单关键信息:时间、金额、还款、额度

小结:在构造特征之前,要完成
- 类ER图
- 样本设计表
- 特征框架图
3 特征构造
3.1 静态信息和时间截面特征
-
用户静态信息:用户的基本信息(半年以上不会发生变化)
- 姓名
- 性别
- 年龄
-
用户时间截面:取时间轴上的一个点,作为时间截面
- 截面时间点的购物GVM、银行存款额、逾期最大天数
-
用户时间序列特征:从观察点往前回溯一段时间的数据
- 过去 一个月的GPS数据
- 过去六个月的银行流水
- 过去一年的逾期记录
-
用户时间截面特征相关概念
- 未来信息:当前时间截面之后的数据
- 时间截面数据在取数据的时候,要避免使用未来信息
- 产生未来信息的直接原因:缺少快照表
- 金融相关数据原则上都需要快照表记录所有痕迹(额度变化情况,多次申请的通过和拒绝情况)
- 缺少快照表的原因
* 快照表消耗资源比较大,为了性能不做
* 原有数据表设计人员疏忽,没做
* 借用其他业务数据(如电商)做信贷
- 快照表:每天定时存储一个状态(类似于每天23:00都拍一张照片),每天会把当天的状态进行备份,只存储当天的最终状态。
- 日志表:每一次操作都会记录,不会进行update,只有insert操作,操作一次,插入一条记录。
3.2 未来信息问题
3.2.1 未来信息案例
- 首次借贷 --》二次借贷–》爬虫授权–》三次借贷
举例:




解决方式:加入快照表存储

3.2.2 时间序列特征的未来信息
时间序列特征:从观察点向前回溯一段时间的数据


- 以借贷2发生的时间为观测点,下表中的未来信息会将大量退货行为的用户认为是坏客户,但是上下之后效果会变差。

- 特征构建时的补救方法
- 对未来信息窗口外的订单计算有效的特征(NMV)
- 对未来信息窗口内的订单计算一般特征(GMV)
3.2.3 历史信贷特征出现未来信息
- 举例:信用卡每月1日为账单日,每月10日为还款日,次月10日左右为M1(逾期一个月)

- 在上图所示的截面时间(如3月5日)是看不到2月账单的逾期DPD30的情况的
- 但如果数据库没有快照表会导致我们可以拿到2月账单的DPD30情况
- 解决方案跟上面例子一样,分区间讨论,可以把账单分成3类
-
当前未出账账单
-
最后一个已出账账单
-
其他已出账账单 (只有这个特征可以构建逾期类特征)
-
小结:处理未来信息问题
- 及时增加快照表
- 没有快照表的情况下,将数据区分为是否有未来信息的区间,分别进行特征构造
3.3 特征构造
3.3.1 时序数据特征衍生
特征聚合:将单个特征的多个时间节点取值进行聚合。特征聚合是传统评分卡建模的主要特征构造方法
-
举例:计算每个用户的额度使用率,记为特征ft,按照时间轴以月份为切片展开
- 申请前30天内的额度使用率ft1
- 申请前30天至60天内的额度使用率ft2
- 申请前60天至90天内的额度使用率ft3
- 申请前330天至360天内的额度使用率ft12
- 得到一个用户的12个特征
import pandas as pd
import numpy as np
data = pd.read_excel('../data/textdata.xlsx')
data.head()

- 可以根据这个时间序列进行基于经验的人工特征衍生,例如计算最近P个月特征大于0的月份数
#最近p个月,ft>0的月份数
def Num(ft,p): #ft 特征名字 p特征大于0的月份数df=data.loc[:,ft+'1':ft+str(p)] # 选择ft1 - ftp的数据auto_value=np.where(df>0,1,0).sum(axis=1) return ft+'_num'+str(p),auto_value

- 计算最近P个月特征ft等于0的月份数
#最近p个月,ft>0的月份数
def Num(ft,p): #ft 特征名字 p特征大于0的月份数df=data.loc[:,ft+'1':ft+str(p)]auto_value=np.where(df>0,1,0).sum(axis=1)return ft+'_num'+str(p),auto_value
- 计算最近P个月特征ft等于0的月份数
#最近p个月,ft=0的月份数
def zero_cnt(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value=np.where(df==0,1,0).sum(axis=1)return ft+'_zero_cnt'+str(p),auto_value
- 计算近p个月特征ft大于0的月份数是否大于等于1
#最近p个月,ft>0的月份数是否>=1
def Evr(ft,p):df=data.loc[:,ft+'1':ft+str(p)]arr=np.where(df>0,1,0).sum(axis=1)auto_value = np.where(arr,1,0)return ft+'_evr'+str(p),auto_value
-
- 计算最近p个月特征ft的均值
#最近p个月,ft均值
def Avg(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value=np.nanmean(df,axis = 1 )return ft+'_avg'+str(p),auto_value
- 计算最近p个月特征ft的和,最大值,最小
#最近p个月,ft和
def Tot(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value=np.nansum(df,axis = 1)return ft+'_tot'+str(p),auto_value#最近(2,p+1)个月,ft和
def Tot2T(ft,p):df=data.loc[:,ft+'2':ft+str(p+1)]auto_value=df.sum(1)return ft+'_tot2t'+str(p),auto_value #最近p个月,ft最大值
def Max(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value=np.nanmax(df,axis = 1)return ft+'_max'+str(p),auto_value #最近p个月,ft最小值
def Min(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value=np.nanmin(df,axis = 1)return ft+'_min'+str(p),auto_value
- 其他衍生方法
#最近p个月,最近一次ft>0到现在的月份数def Msg(ft,p):df=data.loc[:,ft+'1':ft+str(p)]df_value=np.where(df>0,1,0)auto_value=[]for i in range(len(df_value)):row_value=df_value[i,:]if row_value.max()<=0:indexs='0'auto_value.append(indexs)else:indexs=1for j in row_value:if j>0:breakindexs+=1auto_value.append(indexs)return ft+'_msg'+str(p),auto_value#最近p个月,最近一次ft=0到现在的月份数
def Msz(ft,p):df=data.loc[:,ft+'1':ft+str(p)]df_value=np.where(df==0,1,0)auto_value=[]for i in range(len(df_value)):row_value=df_value[i,:]if row_value.max()<=0:indexs='0'auto_value.append(indexs)else:indexs=1for j in row_value:if j>0:breakindexs+=1auto_value.append(indexs)return ft+'_msz'+str(p),auto_value #当月ft/(最近p个月ft的均值)
def Cav(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value = df[ft+'1']/np.nanmean(df,axis = 1 ) return ft+'_cav'+str(p),auto_value #当月ft/(最近p个月ft的最小值)
def Cmn(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value = df[ft+'1']/np.nanmin(df,axis = 1 ) return ft+'_cmn'+str(p),auto_value #最近p个月,每两个月间的ft的增长量的最大值
def Mai(ft,p):arr=np.array(data.loc[:,ft+'1':ft+str(p)]) auto_value = []for i in range(len(arr)):df_value = arr[i,:]value_lst = []for k in range(len(df_value)-1):minus = df_value[k] - df_value[k+1]value_lst.append(minus)auto_value.append(np.nanmax(value_lst)) return ft+'_mai'+str(p),auto_value #最近p个月,每两个月间的ft的减少量的最大值
def Mad(ft,p):arr=np.array(data.loc[:,ft+'1':ft+str(p)]) auto_value = []for i in range(len(arr)):df_value = arr[i,:]value_lst = []for k in range(len(df_value)-1):minus = df_value[k+1] - df_value[k]value_lst.append(minus)auto_value.append(np.nanmax(value_lst)) return ft+'_mad'+str(p),auto_value #最近p个月,ft的标准差
def Std(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value=np.nanvar(df,axis = 1)return ft+'_std'+str(p),auto_value #最近p个月,ft的变异系数
def Cva(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value=np.nanvar(df,axis = 1)/(np.nanmean(df,axis = 1 )+1e-10)return ft+'_cva'+str(p),auto_value #(当月ft) - (最近p个月ft的均值)
def Cmm(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value = df[ft+'1'] - np.nanmean(df,axis = 1 ) return ft+'_cmm'+str(p),auto_value #(当月ft) - (最近p个月ft的最小值)
def Cnm(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value = df[ft+'1'] - np.nanmin(df,axis = 1 ) return ft+'_cnm'+str(p),auto_value #(当月ft) - (最近p个月ft的最大值)
def Cxm(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value = df[ft+'1'] - np.nanmax(df,axis = 1 ) return ft+'_cxm'+str(p),auto_value #( (当月ft) - (最近p个月ft的最大值) ) / (最近p个月ft的最大值) )
def Cxp(ft,p):df=data.loc[:,ft+'1':ft+str(p)]temp = np.nanmax(df,axis = 1 )auto_value = (df[ft+'1'] - temp )/ tempreturn ft+'_cxp'+str(p),auto_value #最近p个月,ft的极差
def Ran(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value = np.nanmax(df,axis = 1 ) - np.nanmin(df,axis = 1 ) return ft+'_ran'+str(p),auto_value #最近p个月中,特征ft的值,后一个月相比于前一个月增长了的月份数
def Nci(ft,p):arr=np.array(data.loc[:,ft+'1':ft+str(p)]) auto_value = []for i in range(len(arr)):df_value = arr[i,:]value_lst = []for k in range(len(df_value)-1):minus = df_value[k] - df_value[k+1]value_lst.append(minus) value_ng = np.where(np.array(value_lst)>0,1,0).sum()auto_value.append(np.nanmax(value_ng)) return ft+'_nci'+str(p),auto_value #最近p个月中,特征ft的值,后一个月相比于前一个月减少了的月份数
def Ncd(ft,p):arr=np.array(data.loc[:,ft+'1':ft+str(p)]) auto_value = []for i in range(len(arr)):df_value = arr[i,:]value_lst = []for k in range(len(df_value)-1):minus = df_value[k] - df_value[k+1]value_lst.append(minus) value_ng = np.where(np.array(value_lst)<0,1,0).sum()auto_value.append(np.nanmax(value_ng)) return ft+'_ncd'+str(p),auto_value #最近p个月中,相邻月份ft 相等的月份数
def Ncn(ft,p):arr=np.array(data.loc[:,ft+'1':ft+str(p)]) auto_value = []for i in range(len(arr)):df_value = arr[i,:]value_lst = []for k in range(len(df_value)-1):minus = df_value[k] - df_value[k+1]value_lst.append(minus) value_ng = np.where(np.array(value_lst)==0,1,0).sum()auto_value.append(np.nanmax(value_ng)) return ft+'_ncn'+str(p),auto_value #最近P个月中,特征ft的值是否按月份严格递增,是返回1,否返回0
def Bup(ft,p):arr=np.array(data.loc[:,ft+'1':ft+str(p)]) auto_value = []for i in range(len(arr)):df_value = arr[i,:]value_lst = []index = 0for k in range(len(df_value)-1):if df_value[k] > df_value[k+1]:breakindex =+ 1if index == p: value= 1 else:value = 0auto_value.append(value) return ft+'_bup'+str(p),auto_value #最近P个月中,特征ft的值是否按月份严格递减,是返回1,否返回0
def Pdn(ft,p):arr=np.array(data.loc[:,ft+'1':ft+str(p)]) auto_value = []for i in range(len(arr)):df_value = arr[i,:]value_lst = []index = 0for k in range(len(df_value)-1):if df_value[k+1] > df_value[k]:breakindex =+ 1if index == p: value= 1 else:value = 0auto_value.append(value) return ft+'_pdn'+str(p),auto_value #最近P个月中,ft的切尾均值,这里去掉了数据中的最大值和最小值
def Trm(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value = []for i in range(len(df)):trm_mean = list(df.loc[i,:])trm_mean.remove(np.nanmax(trm_mean))trm_mean.remove(np.nanmin(trm_mean))temp=np.nanmean(trm_mean) auto_value.append(temp)return ft+'_trm'+str(p),auto_value #当月ft / 最近p个月的ft中的最大值
def Cmx(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value = (df[ft+'1'] - np.nanmax(df,axis = 1 )) /np.nanmax(df,axis = 1 ) return ft+'_cmx'+str(p),auto_value #( 当月ft - 最近p个月的ft均值 ) / ft均值
def Cmp(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value = (df[ft+'1'] - np.nanmean(df,axis = 1 )) /np.nanmean(df,axis = 1 ) return ft+'_cmp'+str(p),auto_value #( 当月ft - 最近p个月的ft最小值 ) /ft最小值
def Cnp(ft,p):df=data.loc[:,ft+'1':ft+str(p)]auto_value = (df[ft+'1'] - np.nanmin(df,axis = 1 )) /np.nanmin(df,axis = 1 ) return ft+'_cnp'+str(p),auto_value #最近p个月取最大值的月份距现在的月份数
def Msx(ft,p):df=data.loc[:,ft+'1':ft+str(p)]xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxdf['_max'] = np.nanmax(df,axis = 1)for i in range(1,p+1):df[ft+str(i)] = list(df[ft+str(i)] == df['_max'])del df['_max']df_value = np.where(df==True,1,0)auto_value=[]for i in range(len(df_value)):row_value=df_value[i,:]indexs=1for j in row_value:if j == 1:breakindexs+=1auto_value.append(indexs)return ft+'_msx'+str(p),auto_value#最近p个月的均值/((p,2p)个月的ft均值)
def Rpp(ft,p):df1=data.loc[:,ft+'1':ft+str(p)]value1=np.nanmean(df1,axis = 1 )df2=data.loc[:,ft+str(p):ft+str(2*p)]value2=np.nanmean(df2,axis = 1 ) auto_value = value1/value2return ft+'_rpp'+str(p),auto_value #最近p个月的均值 - ((p,2p)个月的ft均值)
def Dpp(ft,p):df1=data.loc[:,ft+'1':ft+str(p)]value1=np.nanmean(df1,axis = 1 )df2=data.loc[:,ft+str(p):ft+str(2*p)]value2=np.nanmean(df2,axis = 1 ) auto_value = value1 - value2return ft+'_dpp'+str(p),auto_value #(最近p个月的ft最大值)/ (最近(p,2p)个月的ft最大值)
def Mpp(ft,p):df1=data.loc[:,ft+'1':ft+str(p)]value1=np.nanmax(df1,axis = 1 )df2=data.loc[:,ft+str(p):ft+str(2*p)]value2=np.nanmax(df2,axis = 1 ) auto_value = value1/value2return ft+'_mpp'+str(p),auto_value #(最近p个月的ft最小值)/ (最近(p,2p)个月的ft最小值)
def Npp(ft,p):df1=data.loc[:,ft+'1':ft+str(p)]value1=np.nanmin(df1,axis = 1 )df2=data.loc[:,ft+str(p):ft+str(2*p)]value2=np.nanmin(df2,axis = 1 ) auto_value = value1/value2return ft+'_npp'+str(p),auto_value
- 将上面的衍生方法定义为函数
#定义批量调用双参数的函数
def auto_var2(feature,p):#global data_newtry:columns_name,values=Num(feature,p)data_new[columns_name]=valuesexcept:print("Num PARSE ERROR",feature,p)try:columns_name,values=Nmz(feature,p)data_new[columns_name]=valuesexcept:print("Nmz PARSE ERROR",feature,p)try:columns_name,values=Evr(feature,p)data_new[columns_name]=valuesexcept:print("Evr PARSE ERROR",feature,p)try:columns_name,values=Avg(feature,p)data_new[columns_name]=valuesexcept:print("Avg PARSE ERROR",feature,p)try:columns_name,values=Tot(feature,p)data_new[columns_name]=valuesexcept:print("Tot PARSE ERROR",feature,p) try:columns_name,values=Tot2T(feature,p)data_new[columns_name]=valuesexcept:print("Tot2T PARSE ERROR",feature,p) try:columns_name,values=Max(feature,p)data_new[columns_name]=valuesexcept:print("Tot PARSE ERROR",feature,p)try:columns_name,values=Max(feature,p)data_new[columns_name]=valuesexcept:print("Max PARSE ERROR",feature,p)try:columns_name,values=Min(feature,p)data_new[columns_name]=valuesexcept:print("Min PARSE ERROR",feature,p)try:columns_name,values=Msg(feature,p)data_new[columns_name]=valuesexcept:print("Msg PARSE ERROR",feature,p)try:columns_name,values=Msz(feature,p)data_new[columns_name]=valuesexcept:print("Msz PARSE ERROR",feature,p)try:columns_name,values=Cav(feature,p)data_new[columns_name]=valuesexcept:print("Cav PARSE ERROR",feature,p)try:columns_name,values=Cmn(feature,p)data_new[columns_name]=valuesexcept:print("Cmn PARSE ERROR",feature,p) try:columns_name,values=Std(feature,p)data_new[columns_name]=valuesexcept:print("Std PARSE ERROR",feature,p) try:columns_name,values=Cva(feature,p)data_new[columns_name]=valuesexcept:print("Cva PARSE ERROR",feature,p) try:columns_name,values=Cmm(feature,p)data_new[columns_name]=valuesexcept:print("Cmm PARSE ERROR",feature,p) try:columns_name,values=Cnm(feature,p)data_new[columns_name]=valuesexcept:print("Cnm PARSE ERROR",feature,p) try:columns_name,values=Cxm(feature,p)data_new[columns_name]=valuesexcept:print("Cxm PARSE ERROR",feature,p) try:columns_name,values=Cxp(feature,p)data_new[columns_name]=valuesexcept:print("Cxp PARSE ERROR",feature,p)try:columns_name,values=Ran(feature,p)data_new[columns_name]=valuesexcept:print("Ran PARSE ERROR",feature,p)try:columns_name,values=Nci(feature,p)data_new[columns_name]=valuesexcept:print("Nci PARSE ERROR",feature,p)try:columns_name,values=Ncd(feature,p)data_new[columns_name]=valuesexcept:print("Ncd PARSE ERROR",feature,p)try:columns_name,values=Ncn(feature,p)data_new[columns_name]=valuesexcept:print("Ncn PARSE ERROR",feature,p)try:columns_name,values=Pdn(feature,p)data_new[columns_name]=valuesexcept:print("Pdn PARSE ERROR",feature,p) try:columns_name,values=Cmx(feature,p)data_new[columns_name]=valuesexcept:print("Cmx PARSE ERROR",feature,p) try:columns_name,values=Cmp(feature,p)data_new[columns_name]=valuesexcept:print("Cmp PARSE ERROR",feature,p) try:columns_name,values=Cnp(feature,p)data_new[columns_name]=valuesexcept:print("Cnp PARSE ERROR",feature,p) try:columns_name,values=Msx(feature,p)data_new[columns_name]=valuesexcept:print("Msx PARSE ERROR",feature,p)try:columns_name,values=Nci(feature,p)data_new[columns_name]=valuesexcept:print("Nci PARSE ERROR",feature,p)try:columns_name,values=Trm(feature,p)data_new[columns_name]=valuesexcept:print("Trm PARSE ERROR",feature,p)try:columns_name,values=Bup(feature,p)data_new[columns_name]=valuesexcept:print("Bup PARSE ERROR",feature,p)try:columns_name,values=Mai(feature,p)data_new[columns_name]=valuesexcept:print("Mai PARSE ERROR",feature,p)try:columns_name,values=Mad(feature,p)data_new[columns_name]=valuesexcept:print("Mad PARSE ERROR",feature,p)try:columns_name,values=Rpp(feature,p)data_new[columns_name]=valuesexcept:print("Rpp PARSE ERROR",feature,p)try:columns_name,values=Dpp(feature,p)data_new[columns_name]=valuesexcept:print("Dpp PARSE ERROR",feature,p)try:columns_name,values=Mpp(feature,p)data_new[columns_name]=valuesexcept:print("Mpp PARSE ERROR",feature,p)try:columns_name,values=Npp(feature,p)data_new[columns_name]=valuesexcept:print("Npp PARSE ERROR",feature,p)return data_new.columns.size
- 对之前数据应用封装的函数
# 创建空的df
data_new = pd.DataFrame()
# 遍历12个月
for p in range(1, 12): # 对所有ft-i和gt-i的列进行特征衍生for inv in ['ft', 'gt']: auto_var2(inv, p)
-
上面这种无差别聚合方法进行聚合得到的结果常具有较高的共线性,但信息量并无明显增加,影响模型的鲁棒性和稳定性
-
评分卡模型对模型的稳定性要求远高于其性能
-
在时间窗口为1年的场景下,p值会通过先验知识,人为选择3、6、12等,而不是遍历全部取值1~12
-
在后续特征筛选时,会根据变量的显著性、共线性等指标进行进一步筛选
-
最近一次(current) 和历史 (history)做对比
- current/history
- current-history
-
3.3.2 用户关联特征
如何评价一个没有内部数据的新客?
- 使用第三方数据
- 把新用户关联到内部用户,使用关联到的老客信息评估
用户特征关联,可以考虑用倒排表做关联
- 用户→[特征1,特征2,特征3…]
- 特征→[用户1,用户2,用户3…]
举例:用户所在地区的统计特征
- 将用户申请时的GPS转化为geohash位置块
- geohash:基本原理是将地球理解为一个二维平面,将平面递归分解成更小的子块,每个子块在一定经纬度范围内拥有相同的编码
- 对每个大小合适的位置块,统计申请时点GPS在该位置块的人的信用分
- 当新申请的人,查询其所在的位置块的平均信用分作为GPS倒排表特征

- 倒排表的组成:关键主键+统计指标
关键主键:新用户通过什么数据和平台存量用户发生关联
统计指标:使用存量用户的什么特征去评估这个新客户
-
信贷业务的特征要求:
- 逻辑简单
- 容易构造
- 容易排查错误
- 有强业务解释性
-
构造特征要从两个维度看数据:归纳+演绎
- 归纳:从大量数据的结果总结出规律(相关关系),从数据中只能得到相关性
- 演绎:从假设推导出必然的结果(因果关系)
相关文章:

【金融风控项目-08】:特征构造
文章目录 1.数据准备1.1 风控建模特征数据1.2 人行征信数据1.3 据之间的内在逻辑 2 样本设计和特征框架2.1 定义观察期样本2.2 数据EDA(Explore Data Analysis)2.3 梳理特征框架 3 特征构造3.1 静态信息和时间截面特征3.2 未来信息问题3.2.1 未来信息案例3.2.2 时间序列特征的未…...

计算机网络 (2)计算机网络的类别
计算机网络的类别繁多,根据不同的分类原则,可以得到各种不同类型的计算机网络。 一、按覆盖范围分类 局域网(LAN): 定义:局域网是一种在小区域内使用的,由多台计算机组成的网络。覆盖范围&#…...
)
10.《滑动窗口篇》---②长度最小的子数组(中等)
有了上一篇的基础。这道题我们就可以轻易分析可以使用滑动窗口来解决了 方法一:滑动窗口 这里注意 ret 在while循环外部更新 在 while 外部更新 ret,确保窗口在满足条件后再计算长度,避免错误计入正在调整中的窗口长度。 class Solution {pub…...

java的强,软,弱,虚引用介绍以及应用
写在前面 本文看下Java的强,软,弱,虚引用相关内容。 1:各种引用介绍 顶层类是java.lang.ref.Reference,注意是一个抽象类,而不是接口,其中比较重要的引用队列ReferenceQueue就在该类中定义,子…...

STL-stack栈:P1981 [NOIP2013 普及组] 表达式求值
这个题用的STL-栈来做 题目来源:洛谷 相关知识 [NOIP2013 普及组] 表达式求值 题目背景 NOIP2013 普及组 T2 题目描述 给定一个只包含加法和乘法的算术表达式,请你编程计算表达式的值。 输入格式 一行,为需要你计算的表达式ÿ…...

Java使用stream进行分组汇总失效问题
背景 在当前项目的开发任务中需要定制财务报表导出功能,格式比较特殊使用了VM。在汇总数据的过程中使用了stream.collect 进行分组汇总。在测试的过程中发现分组失败,最终原因是对象的对比方式问题,collect是根据对象对比的所以需要重写equa…...

VMWare虚拟机安装华为欧拉系统
记录一下安装步骤: 1.在vmware中创建一个新的虚拟机,步骤和创建centos差不多 2.启动系统 具体的看下图: 启动虚拟机 耐心等待 等待进度条走完重启系统就完成了...

阿里云轻量应用服务器可以用在哪些场景呢
在数字化转型的浪潮中,中小企业面临着如何快速、高效地上云的挑战。阿里云轻量应用服务器(SWAS)作为一款专为中小企业设计的云服务产品,提供了简单易用、经济实惠的解决方案,助力企业轻松实现云端部署,赋能…...

OrangePi 5plus yolov5 部署全过程
准备工作 一、下载用户手册 下载-Orange Pi官网-香橙派(Orange Pi)开发板,开源硬件,开源软件,开源芯片,电脑键盘 里面有详细的镜像烧录教程和桌面使用等 二、镜像下载 准备一张TF卡(32G以上),插入电脑,…...

Rust中::和.的区别
在 Rust 中,:: 和 . 是两种常用的操作符,它们的作用和语法用途不同。以下是详细的对比和解释: 1. ::(双冒号) :: 是 路径操作符,主要用于访问模块、结构体、枚举、函数、常量等的命名空间中的成员。 主要…...

集群聊天服务器(7)数据模块
目录 Mysql数据库代码封装头文件与源文件 Mysql数据库代码封装 业务层代码不要直接写数据库,因为业务层和数据层的代码逻辑也想完全区分开。万一不想存储mysql,想存redis的话,就要改动大量业务代码。解耦合就是改起来很方便。 首先需要安装m…...

VS Code 更改背景颜色
我们的 VS code 默认是 黑色,这个颜色在有光的情况下,个人感觉反光比较严重。 所以换成白色了。 步骤: 选择 File -> Preferences -> Settings Workbench -> Appearance -> Color Theme -> 选择喜欢的颜色 选择后会变为你选…...

OpenAI 助力数据分析中的模式识别与趋势预测
数据分析师的日常工作中,发现数据中的隐藏模式和预测未来趋势是非常重要的一环。借助 OpenAI 的强大语言模型(如 GPT-4),我们可以轻松完成这些任务,无需深厚的编程基础,也能快速上手。 在本文中࿰…...
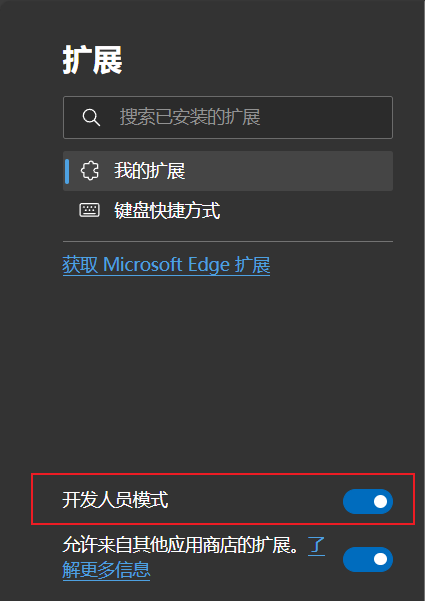
IDM扩展添加到Edge浏览器
IDM扩展添加到Edge浏览器 一般情况下,当安装IDM软件后,该软件将会自动将IDM Integration Module浏览器扩展安装到Edge浏览器上,但在某些情况下,需要我们手动安装,以下为手动安装步骤 手动安装IDM扩展到Edge浏览器 打…...
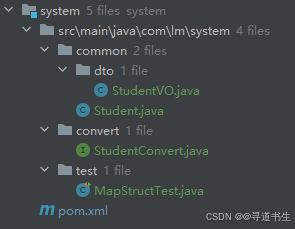
【SpringBoot】26 实体映射工具(MapStruct)
Gitee 仓库 https://gitee.com/Lin_DH/system 介绍 现状 为了让应用程序的代码更易于维护,通常会将项目进行分层。在《阿里巴巴 Java 开发手册》中,推荐分层如下图所示: 每层都有对应的领域模型,即不同类型的 Bean。 DO&…...

分层架构 IM 系统之架构演进
在电商业务日活几百万的情况下,IM 系统采用分层架构方式,如下图。 分层架构的 IM 系统,整体上包含了【终端层】、【入口层】、【业务逻辑层】、【路由层】、【数据访问层】和【存储层】,我们在上篇文章(分层架构 IM 系…...
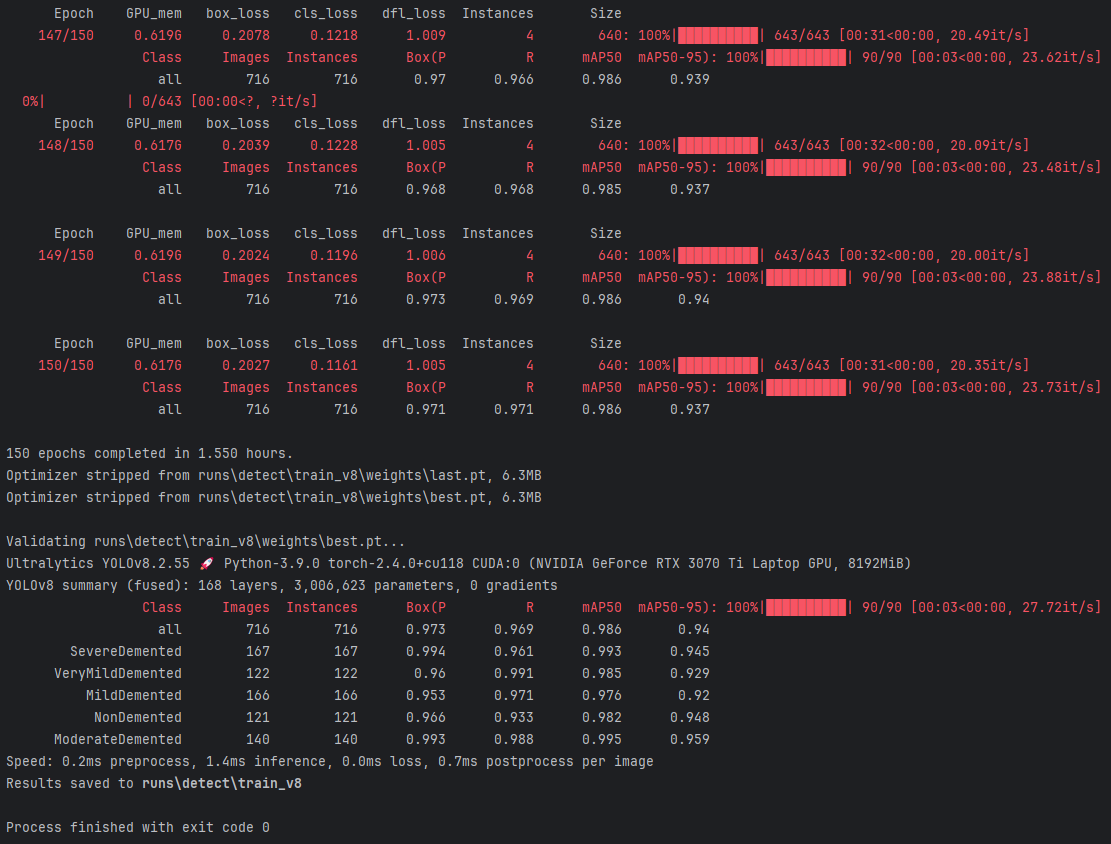
基于YOLOv8深度学习的医学影像阿尔兹海默症检测诊断系统研究与实现(PyQt5界面+数据集+训练代码)
阿尔茨海默症(Alzheimer’s disease)是一种常见的神经退行性疾病,主要表现为记忆丧失、认知能力下降以及行为和人格改变。随着全球老龄化问题的加剧,阿尔茨海默症的发病率也在逐年上升,给患者及其家庭带来了巨大的经济…...

【支持向量机(SVM)】:相关概念及API使用
文章目录 1 SVM相关概念1.1 SVM引入1.1.1 SVM思想1.1.2 SVM分类1.1.3 线性可分、线性和非线性的区分 1.2 SVM概念1.3 支持向量概念1.4 软间隔和硬间隔1.5 惩罚系数C1.6 核函数 2 SVM API使用2.1 LinearSVC API 说明2.2 鸢尾花数据集案例2.3 惩罚参数C的影响 1 SVM相关概念 1.1…...

Android kotlin之配置kapt编译器插件
配置项目目录下的gradle/libs.versions.toml文件,添加kapt配置项: 在模块目录下build.gradle.kt中增加 plugins {alias(libs.plugins.android.application)alias(libs.plugins.jetbrains.kotlin.android)// 增加该行alias(libs.plugins.jetbrains.kotl…...

时序数据库TDEngine
TDengine 是一款开源、高性能、云原生的时序数据库(Time Series Database, TSDB), 它专为物联网、车联网、工业互联网、金融、IT 运维等场景优化设计。同时它还带有内建的缓存、流式计算、数据订阅等系统功能,能大幅减少系统设计的复杂度&…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...