【C++】哈希表的实现详解
哈希表的实现详解
- 一、哈希常识
- 1.1、哈希概念
- 1.2、哈希冲突
- 1.3、哈希函数(直接定执 + 除留余数)
- 1.4、哈希冲突解决
- 闭散列(线性探测 + 二次探测)
- 开散列
- 二、闭散列哈希表的模拟实现
- 2.1、框架
- 2.2、哈希节点状态的类
- 2.3、哈希表的扩容
- 2.4、构建仿函数把所有数据类型转换为整型并特化
- 2.5、哈希表的插入
- 2.6、哈希表的查找
- 2.7、哈希表的删除
- 2.8闭散列模拟实现代码:
- 三、开散列哈希桶的模拟实现
- 3.1、框架
- 3.2、构建仿函数把字符类型转为整型并特化
- 3.3、哈希桶的插入
- 3.4、哈希桶的查找
- 3.5、哈希桶的删除
- 3.6开散列模拟实现代码:
一、哈希常识
1.1、哈希概念
- 在顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O(logN),搜索的效率决于搜索过程中元素的比较次数。
- 理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
- 当进行如下操作时:
- 插入元素:根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
- 搜索元素:对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)
- 例如:数据集合{1,7,6,4,5,9};哈希函数设置为:hash(key) = key % capacity(除留余数法); capacity为存储元素底层空间总的大小。图示如下:

用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快 问题:按照上述哈希方式,向集合中插入元素44,会出现什么问题?这就涉及到了哈希冲突
1.2、哈希冲突
对于两个数据元素的关键字 和 (i != j),有 != ,但也有:Hash(i) == Hash(j),即:不同关键字通过相同哈希函数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
当我们按照上述操作直接建立映射关系,还会出现如下几个问题:
- 数据范围很广,不集中,导致空间消耗太多怎么办?
- key的数据不是整数
发生哈希冲突该如何处理呢?这里我们首先使用哈希函数解决数据范围广,不集中,key的数据不是整数的问题,再来解决哈希冲突。
1.3、哈希函数(直接定执 + 除留余数)
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。 哈希函数设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见哈希函数
1、直接定址法–(常用)
- 取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B 优点:简单、均匀 缺点:需要事先知道关键字的分布情况 使用场景:适合查找比较小且连续的情况 面试题:字符串中第一个只出现一次字符
2、除留余数法–(常用)
- 设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址
比如我给出的数据集合为{5,8,100,9999,20,-10},如此不集中分布广的数据,就不能用直接定址法,因为分布太广,会导致空间浪费过多。这就需要用到除留余数法来解决:
除留余数法就是先统一将数字转换为无符号,解决了负数的问题,再用key%表的大小,随后映射到哈希表中,图示:

此时如果插入数字35的话,那么哈希冲突就会出现了,根据除留余数法的规则,35理应映射到下标5的位置,可是该位置已经有数值了,这就需要通过后文的开散列和闭散列的相关知识点来帮助我们解决哈希冲突。
3、平方取中法–(了解)
- 假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址; 再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址 平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况
4、折叠法–(了解)
- 折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况
5、随机数法–(了解)
- 选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。通常应用于关键字长度不等时采用此法
6、数学分析法–(了解)
- 设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只有某几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址。例如:

假设要存储某家公司员工登记表,如果用手机号作为关键字,那么极有可能前7位都是 相同的,那么我们可以选择后面的四位作为散列地址,如果这样的抽取工作还容易出现 冲突,还可以对抽取出来的数字进行反转(如1234改成4321)、右环位移(如1234改成4123)、左环移位、前两数与后两数叠加(如1234改成12+34=46)等方法。
数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均匀的情况
**注意:**哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突。
1.4、哈希冲突解决
解决哈希冲突的两种方法是:闭散列和开散列
闭散列(线性探测 + 二次探测)
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
1、线性探测
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。找下一个空位置的方法为:hash(key)%N + i。拿上图继续演示:

比如我在此基础上继续插入10,30,50。首先,10%10=0,下标0的位置有了20,继续往后找,下标1是空的,把10放进去;20%10=0,下标0为20,往后找,下标1是10,往后找,下标2是空的,放进去……。

线性探测优点:实现非常简单,
线性探测缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。
- 当再插入数值21时,21%10=1,可是下标1位置被下标0位置的冲突而被10占了,于是继续往后找空位,恶行循环,导致拥堵。
为了解决此麻烦,又推出了二次探测。
2、二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为:hash(key) + i^2(i = 0 1 2 3……)。以下图示例:

同样是插入10,30,50。10%10+0^2 = 0,下标0有值就加1^2 = 1,下标1为空放进去,20%10+2 ^ 2 = 4,下标4为空放进去,50%10+3 ^ 2 = 9,不为空,换成+4 ^ 2 =16,超过数组的长度,绕回来,数到16,为下标7为空放进去。

二次探测就是对上述线性探测的优化,不那么拥堵。简而言之,线性探测是依次寻找空位置,必然拥堵,而二次探测跳跃着寻找空位置,就没那么拥堵。不过这俩方法没有本质的冲突,本质都是在占别人的位置,只是一个挨着占,一个分散着占的区别罢了。
- 研究表明:当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
因此:闭散列最大的缺陷就是空间利用率比较低,这也是闭散列的缺陷,但是往后又推出一种开散列来解决哈希冲突的问题,此法还是比较优的。
开散列
开散列法又叫链地址法(开链法、哈希桶),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中
- 简而言之就是我的数据不存在表中,表里面存储一个链表指针,就是把冲突的数据通过链表的形式挂起来,示例:

从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素,大大减少了闭散列法冲突的弊端性。后文将会详细讲解闭散列哈希表以及开散列哈希桶的具体模拟实现。
二、闭散列哈希表的模拟实现
2.1、框架
在模拟实现之前,要清楚实现哈希表所需的必要成分:
- 哈希节点状态的类
- 哈希表的类
接下来依次展开说明。
2.2、哈希节点状态的类
我们都很清楚数组里的每一个值无非三种状态:
- 如果某下标没有值,则代表空EMPTY
- 如果有值在代表存在EXIST
- 如果此位置的值被删掉了,则表示为DELETE
而这三种状态我们可以借助enum枚举来帮助我们表示数组里每个位置的状态。这里我们专门封装一个类来记录每个位置的状态,以此汇报给后续的哈希表。
enum State
{EMPTY,EXIST,DELETE
};
//哈希节点状态的类
template<class K, class V>
struct HashData
{pair<K, V> _kv;State _state = EMPTY;//记录每个位置的状态,默认给空
};
//哈希表的类
template<class K, class V, class HashFunc = DefaultHash<K>>//添加仿函数便于把其他类型的数据转换为整型数据
class HashTable
{typedef HashData<K, V> Data;
public://相关功能的实现……
private:vector<Data> _tables;size_t _n = 0;//记录存放的有效数据的个数
};
实现好了哈希节点的类,就能够很好的帮助我们后续的查找,示例:
1、查找50:
- 50%10=0,下标0的值不是50,继续++下标往后查找,直至下标3的下标为止。
2、查找60:
- 60%10=0,下标0不是,往后++下标继续查找,找到下标4发现状态为EMPTY空,此时停止查询,因为往后就不可能出现了
3、删除10,再查找50
- 50%10=0,下标0的值不是,++下标到下标1,发现状态为DELETE删除,继续++下标直至下标3的值为50,找到了。
2.3、哈希表的扩容
- 散列表的载荷因子定义为:α = 填入表中的元素个数 / 散列表的长度
- α是散列表装满程度的标志因子。由于表长是定值,α与“填入表中的元素个数”成正比,所以α越大,表明填入表中的元素越多,产生冲突的可能性就越大;反之,α越小,表明填入表中的元素越少,产生冲突的可能性就越小。实际上,散列表的平均查找长度是载荷因子α的函数,只是不同处理冲突的方法有不同的函数。
- 对于开放定址法(闭散列),载荷因子是特别重要因素,应严格限制在0.7 ~ 0.8以下。超过0.8,查表时的CPU缓存不命中(cache missing)按照质数曲线上升。因此,一些采用开放定址法的hash库,如Java的系统库限制了载荷因子为0.75,超过此值将resize散列表。
综上,我们在后续的插入操作中,必然要考虑到扩容的情况,我们直接把负载因子控制在0.7,超过了就扩容。具体操作见下文哈希表的插入操作。
2.4、构建仿函数把所有数据类型转换为整型并特化
在我们后续的插入操作中,插入的数据类型如果是整数,那么可以直接建立映射关系,可若是字符串,就没那么容易了,因此,我们需要套一层仿函数,来帮助我们把字符串类型转换成整型的数据再建立映射关系。主要分为以下三类需要写仿函数的情况:
1、key为整型,为默认仿函数的情况
- 此时的数据类型为整型,直接强转size_t随后返回
2、key为字符串,单独写个字符串转整型的仿函数
针对于字符串转整型,我们推出下面两种方法,不过都是会存在问题的:
- 只用首字母的ascii码来映射,此法不合理,因为"abc"和"axy"本是俩不用字符串,经过转换,会引发冲突。
- 字符串内所有字符ASCII码值之和,此法也会产生冲突,因为"abcd"和"bcad"在此情况就会冲突。
为了避免冲突,几位大佬推出多种算法思想,下面我取其中一种算法思想来讲解:
BKDR哈希算法:
hash = hash * 131 + ch; // 也可以乘以31、131、1313、13131、131313..
为了能够让我们的哈希表能够自动识别传入数据的类型,不用手动声明,这里我们可以借助特化来解决,仿函数+特化总代码如下:
//利用仿函数将数据类型转换为整型
template<class K>
struct DefaultHash
{size_t operator()(const K& key){return (size_t)key;}
};
//模板的特化
template<>
struct DefaultHash<string>
{size_t operator()(const string& key){//BKDR哈希算法size_t hash = 0;for (auto ch : key){hash = hash * 131 + ch;//把所有字符的ascii码值累计加起来}return hash;}
};
2.5、哈希表的插入
哈希表的插入主要是三大步骤:
- 去除冗余
- 扩容操作
- 插入操作
下面分开来演示。
1、去除冗余:
- 复用Find查找函数,去帮助我们查找插入的值是否存在
- 若存在,直接返回false
- 不存在,再进行后续的插入操作
2、扩容操作:
- 如果哈希表一开始就为空,则要扩容
- 如果填入表中的元素个数*10 再 / 表的大小>=7,就扩容(*10是为了避免出现size_t的类型相除不会有小数的情况)
- 扩容以后要重新建立映射关系
- 创建一个新的哈希对象,扩容到需要的内存大小
- 遍历旧表,把旧表每个存在的元素依据该哈希表的规则(如:除留余数法)插入到新表,此步骤让新表自动完成映射关系,无序手动构建
- 利用swap函数把新表和旧表中的数据进行交换,此时的旧表就是已经扩好容且建立好映射关系的哈希表
3、插入操作:
- 借助仿函数把插入的数据类型转为整型并定义变量保存插入键值对的key
- 用此变量%=哈希表的size(),因为我们初始化的时候已经将哈希表的值全部赋零值了,且对于哈希表,应该尽量控制size和capacity一样大
- 遍历进行线性探测 / 二次探测,如果这个位置的状态为EXIST存在,说明还要往后遍历查找
- 遍历结束,说明此位置的状态为空EMPTY或删除DELETE,可以放值
- 把插入的值放进该位置,更新状态为EXIST,有效数据个数++
//插入
bool Insert(const pair<K, V>& kv)
{//1、去除冗余if (Find(kv.first)){//说明此值已经有了,直接返回falsereturn false;}//2、扩容//负载因子超过0.7,就扩容if (_tables.size() == 0 || _n * 10 / _tables.size() >= 7){size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;//扩容以后,需要重新建立映射关系HashTable<K, V, HashFunc> newHT;newHT._tables.resize(newSize);//遍历旧表,把旧表每个存在的元素插入newHTfor (auto& e : _tables){if (e._state == EXIST){newHT.Insert(e._kv);}}newHT._tables.swap(_tables);//建立映射关系后交换}//3、插入HashFunc hf;size_t starti = hf(kv.first);//取出键值对的key,并且避免了负数的情况,借用仿函数确保是整型数据starti %= _tables.size();size_t hashi = starti;size_t i = 1;//线性探测/二次探测while (_tables[hashi]._state == EXIST){hashi = starti + i;//二次探测改为 +i^2++i;hashi %= _tables.size();//防止hashi超出数组}_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;_n++;return true;
}
2.6、哈希表的查找
查找的核心逻辑就是找到key相同,就返回此对象的地址,找到空就返回nullptr,具体细分规则如下:
- 先去判断表的大小是否为0,为0直接返回nullptr
- 按照线性探测 / 二次探测的方式去遍历,遍历的条件是此位置的状态不为空EMPTY
- 如果遍历到某哈希表中的对象的值等于要查找的值(前提是此位置的状态不为DELETE删除),返回此对象的地址
- 当遍历结束后,说明此位置的状态为空EMPTY,哈希表没有我们要查找的值,返回nullptr
//查找
Data* Find(const K& key)
{//判断表的size是否为0if (_tables.size() == 0){return nullptr;}HashFunc hf;size_t starti = hf(key);//通过仿函数把其它类型数据转为整型数据starti %= _tables.size();size_t hashi = starti;size_t i = 1;//线性探测/二次探测while (_tables[hashi]._state != EMPTY)//不为空就继续{if (_tables[hashi]._state != DELETE && _tables[hashi]._kv.first == key){return &_tables[hashi];//找到了就返回此对象的地址}hashi = starti + i;//二次探测改为 +i^2++i;hashi %= _tables.size();//防止hashi超出数组}return nullptr;
}
2.7、哈希表的删除
删除的逻辑很简单,遵循下面的规则:
- 复用Find函数去帮我们查找删除的位置是否存在
- 若存在,把此位置的状态置为DELETE即可,此时表中的有效数据个数_n需要减减,最后返回true
- 若不存在,直接返回false
//删除
bool Erase(const K& key)
{//复用Find函数去帮助我们查找删除的值是否存在Data* ret = Find(key);if (ret){//若存在,直接把此位置的状态置为DELETE即可ret->_state = DELETE;return true;}else{return false;}
}
2.8闭散列模拟实现代码:
#pragma once
#include<iostream>
#include<string>
#include<vector>
using namespace std;//利用仿函数将数据类型转换为整型
template<class K>
struct DefaultHash
{size_t operator()(const K& key){return (size_t)key;}
};
//模板的特化
template<>
struct DefaultHash<string>
{size_t operator()(const string& key){//BKDR哈希算法size_t hash = 0;for (auto ch : key){hash = hash * 131 + ch;//把所有字符的ascii码值累计加起来}return hash;}
};//闭散列哈希表的模拟实现
enum State
{EMPTY,EXIST,DELETE
};
//哈希节点状态的类
template<class K, class V>
struct HashData
{pair<K, V> _kv;State _state = EMPTY;//记录每个位置的状态,默认给空
};//哈希表的类
template<class K, class V, class HashFunc = DefaultHash<K>>//添加仿函数便于把其他类型的数据转换为整型数据
class HashTable
{
typedef HashData<K, V> Data;
public:
//插入
bool Insert(const pair<K, V>& kv)
{//1、去除冗余if (Find(kv.first)){//说明此值已经有了,直接返回falsereturn false;}//2、扩容//负载因子超过0.7,就扩容if (_tables.size() == 0 || _n * 10 / _tables.size() >= 7){size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;//扩容以后,需要重新建立映射关系HashTable<K, V, HashFunc> newHT;newHT._tables.resize(newSize);//遍历旧表,把旧表每个存在的元素插入newHTfor (auto& e : _tables){if (e._state == EXIST){newHT.Insert(e._kv);}}newHT._tables.swap(_tables);//建立映射关系后交换}//3、插入HashFunc hf;size_t starti = hf(kv.first);//取出键值对的key,并且避免了负数的情况,借用仿函数确保是整型数据starti %= _tables.size();size_t hashi = starti;size_t i = 1;//线性探测/二次探测while (_tables[hashi]._state == EXIST){hashi = starti + i;//二次探测改为 +i^2++i;hashi %= _tables.size();//防止hashi超出数组}_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;_n++;return true;
}
//查找
Data* Find(const K& key)
{//判断表的size是否为0if (_tables.size() == 0){return nullptr;}HashFunc hf;size_t starti = hf(key);//通过仿函数把其它类型数据转为整型数据starti %= _tables.size();size_t hashi = starti;size_t i = 1;//线性探测/二次探测while (_tables[hashi]._state != EMPTY)//不为空就继续{if (_tables[hashi]._state != DELETE && _tables[hashi]._kv.first == key){return &_tables[hashi];//找到了就返回此对象的地址}hashi = starti + i;//二次探测改为 +i^2++i;hashi %= _tables.size();//防止hashi超出数组}return nullptr;
}
//删除
bool Erase(const K& key)
{//复用Find函数去帮助我们查找删除的值是否存在Data* ret = Find(key);if (ret){//若存在,直接把此位置的状态置为DELETE即可ret->_state = DELETE;return true;}else{return false;}
}
private:
vector<Data> _tables;
size_t _n = 0;//记录存放的有效数据的个数
};
三、开散列哈希桶的模拟实现
3.1、框架
根据我们先前对开散列哈希桶的了解,得知其根本就是一个指针数组,数组里每一个位置都是一个链表指针,因此我们要单独封装一个链表结构的类,以此来告知我们哈希表类的每个位置为链表指针结构。
//结点类
template<class K, class V>
struct HashNode
{pair<K, V> _kv;HashNode<K, V>* _next;//构造函数HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}
};//哈希表的类
template<class K, class V, class HashFunc = DefaultHash<K>>
class HashTable
{typedef HashNode<K, V> Node;
public://相关功能的实现……
private://指针数组vector<Node*> _tables;size_t _n = 0;//记录有效数据的个数
};
3.2、构建仿函数把字符类型转为整型并特化
此步操作的方法和闭散列哈希表所实现的步骤一致,目的都是为了能够让后续操作中传入的所有数据类型转换为整型数据,以此方便后续建立映射关系,直接看代码:
//利用仿函数将数据类型转换为整型
template<class K>
struct DefaultHash
{size_t operator()(const K& key){return (size_t)key;}
};
//模板的特化
template<>
struct DefaultHash<string>
{size_t operator()(const string& key){//BKDR哈希算法size_t hash = 0;for (auto ch : key){hash = hash * 131 + ch;//把所有字符的ascii码值累计加起来}return hash;}
};
3.3、哈希桶的插入
哈希桶的插入主要分为这几大步骤
- 去除冗余
- 扩容操作
- 头插操作
下面开始具体展开说明:
1、去除冗余:
- 复用Find查找函数,去帮助我们查找插入的值是否存在
- 若存在,直接返回false
- 不存在,再进行后续的插入操作
2、扩容操作:
针对哈希桶的扩容,我们有两种方法进行扩容,法一和哈希表扩容的方法一致
法一:
- 当负载因子==1时扩容
- 扩容后重新建立映射关系
- 创建一个新的哈希桶对象,扩容到newSize的大小
- 遍历旧表,把旧表每个存在的元素插入到新表,此步骤让新表自动完成映射关系,无序手动构建
- 利用swap函数把新表和旧表交换,此时的旧表就是已经扩好容且建立号映射关系的哈希表
此扩容的方法会存在一个问题:释放旧表会出错!!!
- 当我们把旧表的元素映射插入到新表的时候,最后都要释放旧表,按照先前哈希表的释放,我们无需做任何处理,但是现在定义的结构是vector,是自定义类型,会自动调用析构函数进行释放,vector存储的数据是Node*,Node*是内置类型,不会自动释放,最后会出现表我们释放了,但是链表结构的数据还没释放,因此,我们还需借助手写析构函数来帮助我们释放。
//析构函数
~HashTable()
{for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;//释放后置空}
}
此扩容的方法可以进行优化,见法二。
法二:
- 这里我们没必要再创建新的节点,相反把扩容前的节点拿过来重新映射到新表中,大体逻辑和前面差不太多,只是这里不需要再创建新节点。直接利用原链表里的节点。
3、头插操作:
- 借助仿函数找到映射的位置(头插的位置)
- 进行头插的操作
- 更新有效数据个数

//插入
bool Insert(const pair<K, V>& kv)
{//1、去除冗余if (Find(kv.first)){return false;}//构建仿函数,把数据类型转为整型,便于后续建立映射关系HashFunc hf;//2、负载因子 == 1就扩容if (_tables.size() == _n){/*法一size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;HashTable<K, V> newHT;//newHT._tables.resize(newSize, nullptr);//遍历旧表,把旧表的数据重新映射到新表for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur)//如果cur不为空,就插入{newHT.Insert(cur->_kv);cur = cur->_next;}}newHT._tables.swap(_tables);*///法二:size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;vector<Node*> newTable;newTable.resize(newSize, nullptr);for (size_t i = 0; i < _tables.size(); i++)//遍历旧表{Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = hf(cur->_kv.first) % newSize;//确认映射到新表的位置//头插cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}_tables[i] = nullptr;}newTable.swap(_tables);}//3、头插//找到对应的映射位置size_t hashi = hf(kv.first);hashi %= _tables.size();//头插到对应的桶即可Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;
}
3.4、哈希桶的查找
遵循下列规则:
- 先去判断表的大小是否为0,为0直接返回nullptr
- 利用仿函数去找到映射的位置
- 在此位置往后的一串链表中进行遍历查找,找到了,返回节点指针
- 遍历结束,说明没找到,返回nullptr
//查找
Node* Find(const K& key)
{//防止后续除0错误if (_tables.size() == 0){return nullptr;}//构建仿函数,把数据类型转为整型,便于后续建立映射关系HashFunc hf;//找到对应的映射下标位置size_t hashi = hf(key);//size_t hashi = HashFunc()(key);//匿名对象hashi %= _tables.size();Node* cur = _tables[hashi];//在此位置的链表中进行遍历查找while (cur){if (cur->_kv.first == key){//找到了return cur;}cur = cur->_next;}//遍历结束,没有找到,返回nullptrreturn nullptr;
}
3.5、哈希桶的删除
哈希桶的删除遵循这两大思路:
- 找到删除的值对应哈希桶的下标映射位置
- 按照单链表删除节点的方法对该值进行删除
//删除
bool Erase(const K& key)
{//防止后续除0错误if (_tables.size() == 0){return false;}//构建仿函数,把数据类型转为整型,便于后续建立映射关系HashFunc hf;//找到key所对应的哈希桶的位置size_t hashi = hf(key);hashi %= _tables.size();Node* cur = _tables[hashi];Node* prev = nullptr;//删除while (cur){if (cur->_kv.first == key){if (prev == nullptr)//头删{_tables[hashi] = cur->_next;}else//非头删{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}return false;
}
法二:替换法删除
- 上述的删除是实打实的删除,建立prev作为cur的前指针,以此利用prev和cur->next来建立关系从而删除cur节点,但是我们可以不用借助prev指针,就利用先前二叉搜索树的替换法删除的思想来解决。图示:
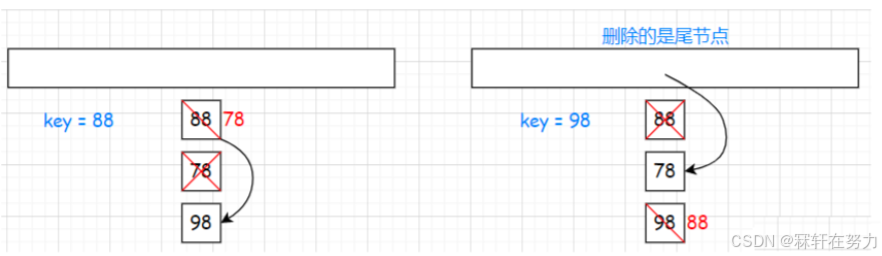
- 当我要删除88时,把节点88的下一个节点的值78替换掉88,随后删除节点78,再建立链表的关系即可。
- 当删除的是尾节点98时,直接和头节点进行交换,删除头节点,并建立链表关系。
这里就不代码演示了,因为整体的成本看还是法一更方便理解些。
3.6开散列模拟实现代码:
#pragma once
#include<iostream>
#include<string>
#include<vector>
using namespace std;//利用仿函数将数据类型转换为整型
template<class K>
struct DefaultHash
{size_t operator()(const K& key){return (size_t)key;}
};
//模板的特化
template<>
struct DefaultHash<string>
{size_t operator()(const string& key){//BKDR哈希算法size_t hash = 0;for (auto ch : key){hash = hash * 131 + ch;//把所有字符的ascii码值累计加起来}return hash;}
};//开散列哈希桶的实现
namespace Bucket
{
template<class K, class V>
struct HashNode
{pair<K, V> _kv;HashNode<K, V>* _next;//构造函数HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}
};
template<class K, class V, class HashFunc = DefaultHash<K>>
class HashTable
{typedef HashNode<K, V> Node;
public://析构函数~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;//释放后置空}}//插入bool Insert(const pair<K, V>& kv){//1、去除冗余if (Find(kv.first)){return false;}//构建仿函数,把数据类型转为整型,便于后续建立映射关系HashFunc hf;//2、负载因子 == 1就扩容if (_tables.size() == _n){/*法一size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;HashTable<K, V> newHT;//newHT._tables.resize(newSize, nullptr);//遍历旧表,把旧表的数据重新映射到新表for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur)//如果cur不为空,就插入{newHT.Insert(cur->_kv);cur = cur->_next;}}newHT._tables.swap(_tables);*///法二:size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;vector<Node*> newTable;newTable.resize(newSize, nullptr);for (size_t i = 0; i < _tables.size(); i++)//遍历旧表{Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = hf(cur->_kv.first) % newSize;//确认映射到新表的位置//头插cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}_tables[i] = nullptr;}newTable.swap(_tables);}//3、头插//找到对应的映射位置size_t hashi = hf(kv.first);hashi %= _tables.size();//头插到对应的桶即可Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}//查找Node* Find(const K& key){//防止后续除0错误if (_tables.size() == 0){return nullptr;}//构建仿函数,把数据类型转为整型,便于后续建立映射关系HashFunc hf;//找到对应的映射下标位置size_t hashi = hf(key);//size_t hashi = HashFunc()(key);//匿名对象hashi %= _tables.size();Node* cur = _tables[hashi];//在此位置的链表中进行遍历查找while (cur){if (cur->_kv.first == key){//找到了return cur;}cur = cur->_next;}//遍历结束,没有找到,返回nullptrreturn nullptr;}//删除/*法一*/bool Erase(const K& key){//防止后续除0错误if (_tables.size() == 0){return false;}//构建仿函数,把数据类型转为整型,便于后续建立映射关系HashFunc hf;//找到key所对应的哈希桶的位置size_t hashi = hf(key);hashi %= _tables.size();Node* cur = _tables[hashi];Node* prev = nullptr;//删除while (cur){if (cur->_kv.first == key){if (prev == nullptr)//头删{_tables[hashi] = cur->_next;}else//非头删{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}return false;}/*法二替换法……*/private://指针数组vector<Node*> _tables;size_t _n = 0;//记录有效数据的个数
};
}
分享就到这里了,有错误的地方还望指出,886!!!
相关文章:
【C++】哈希表的实现详解
哈希表的实现详解 一、哈希常识1.1、哈希概念1.2、哈希冲突1.3、哈希函数(直接定执 除留余数)1.4、哈希冲突解决闭散列(线性探测 二次探测)开散列 二、闭散列哈希表的模拟实现2.1、框架2.2、哈希节点状态的类2.3、哈希表的扩容2…...
高阶C语言之五:(数据)文件
目录 文件名 文件类型 文件指针 文件的打开和关闭 文件打开模式 文件操作函数(顺序) 0、“流” 1、字符输出函数fputc 2、字符输入函数fgetc 3、字符串输出函数fputs 4、 字符串输入函数fgets 5、格式化输入函数fscanf 6、格式化输出函数fpr…...
服务器上部署并启动 Go 语言框架 **GoZero** 的项目
要在服务器上部署并启动 Go 语言框架 **GoZero** 的项目,下面是一步步的操作指南: ### 1. 安装 Go 语言环境 首先,确保你的服务器上已安装 Go 语言。如果还没有安装,可以通过以下步骤进行安装: #### 1.1 安装 Go 语…...
【Java SE 】继承 与 多态 详解
🔥博客主页🔥:【 坊钰_CSDN博客 】 欢迎各位点赞👍评论✍收藏⭐ 目录 1. 继承 1.1 继承的原因 1.2 继承的概念 1.3 继承的语法 2. 子类访问父类 2.1 子类访问父类成员变量 2.1.1 子类与父类不存在同名成员变量 2.1.2 子类…...
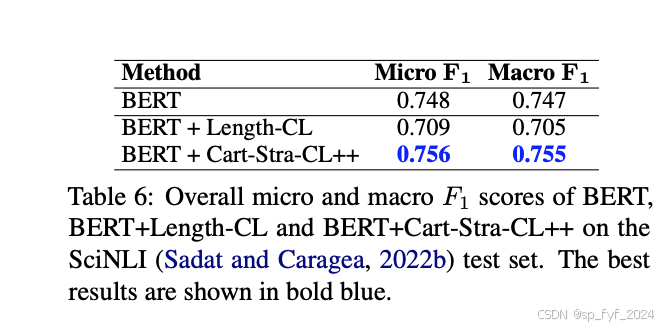
【大语言模型】ACL2024论文-16 基于地图制图的罗马尼亚自然语言推理语料库的新型课程学习方法
【大语言模型】ACL2024论文-16 基于地图制图的罗马尼亚自然语言推理语料库的新型课程学习方法 目录 文章目录 【大语言模型】ACL2024论文-16 基于地图制图的罗马尼亚自然语言推理语料库的新型课程学习方法目录摘要:研究背景:问题与挑战:如何解…...

秋招大概到此结束了
1、背景 学院本,软工,秋招只有同程,快手和网易面试,后两家kpi(因为面试就很水),秋招情况:哈啰(实习转正ing),同程测开offer。 2、走测开的原因 很…...

华为OD机试真题---字符串化繁为简
华为OD机试真题中的“字符串化繁为简”题目是一个涉及字符串处理和等效关系传递的问题。以下是对该题目的详细解析: 一、题目描述 给定一个输入字符串,字符串只可能由英文字母(a~z、A~Z)和左右小括号((、)࿰…...
概念解读|K8s/容器云/裸金属/云原生...这些都有什么区别?
随着容器技术的日渐成熟,不少企业用户都对应用系统开展了容器化改造。而在容器基础架构层面,很多运维人员都更熟悉虚拟化环境,对“容器圈”的各种概念容易混淆:容器就是 Kubernetes 吗?容器云又是什么?容器…...

初识Arkts
创建对象: 类: 类声明引入一个新类型,并定义其字段、方法和构造函数。 定义类后,可以使用关键字new创建实例 可以使用对象字面量创建实例 在以下示例中,定义了Person类,该类具有字段name和surname、构造函…...
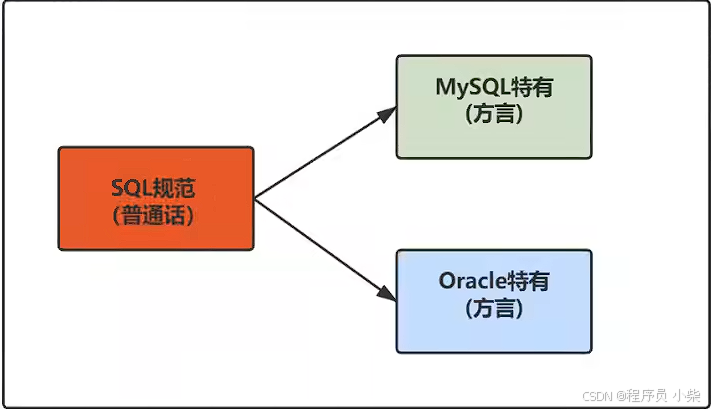
基本的SELECT语句
1.SQL概述 SQL(Structured Query Language)是一种用于管理和操作关系数据库的编程语言。它是一种标准化的语言,用于执行各种数据库操作,包括创建、查询、插入、更新和删除数据等。 SQL语言具有简单、易学、高效的特点,…...

51c自动驾驶~合集30
我自己的原文哦~ https://blog.51cto.com/whaosoft/12086789 #跨越微小陷阱,行动更加稳健 目前四足机器人的全球市场上,市场份额最大的是哪个国家的企业?A.美国 B.中国 C.其他 波士顿动力四足机器人 云深处 绝影X30 四足机器人 …...

Python Tutor网站调试利器
概述 本文主要是推荐一个网站:Python Tutor. 网站首页写道: Online Compiler, Visual Debugger, and AI Tutor for Python, Java, C, C++, and JavaScript Python Tutor helps you do programming homework assignments in Python, Java, C, C++, and JavaScript. It contai…...

h5小游戏实现获取本机图片
h5小游戏实现获取本机图片 本文使用cocos引擎 1.1 需求 用户通过文件选择框选择图片。将图片内容转换为Cocos Creator的纹理 (cc.Texture2D),将纹理设置到 cc.SpriteFrame 并显示到节点中。 1.2 实现步骤 创建文件输入框用于获取文件 let input document.createElement(&quo…...

前端 javascript a++和++a的区别
前端 javascript a和a的区别 a 是先执行表达式后再自增,执行表达式时使用的是a的原值。a是先自增再执行表达示,执行表达式时使用的是自增后的a。 var a0 console.log(a); // 输出0 console.log(a); // 输出1var a0 console.log(a); // 输出1 console.l…...

OceanBase V4.x应用实践:如何排查表被锁问题
DBA在日常工作中常常会面临以下两种常见情况: 业务人员会提出问题:“表被锁了,导致业务受阻,请帮忙解决。” 业务人员还会反馈:“某个程序通常几秒内就能执行完毕,但现在却运行了好几分钟,不清楚…...
ctfshow-web入门-SSRF(web351-web360)
目录 1、web351 2、web352 3、web353 4、web354 5、web355 6、web356 7、web357 8、web358 9、web359 10、web360 1、web351 看到 curl_exec 函数,很典型的 SSRF 尝试使用 file 协议读文件: urlfile:///etc/passwd 成功读取到 /etc/passwd 同…...

【日常记录-Git】如何为post-checkout脚本传递参数
1. 简介 在Git中,post-checkout 钩子是一个在git checkout 或git switch命令成功执行后自动调用的脚本。该脚本不接受任何来自Git命令的直接参数,因为Git设计该钩子是为了在特定的版本控制操作后执行一些预定义的任务,而不是作为一个通用的脚…...

《机器人控制器设计与编程》考试试卷**********大学2024~2025学年第(1)学期
消除误解,课程资料逐步公开。 复习资料: Arduino-ESP32机器人控制器设计练习题汇总_arduino编程语言 题-CSDN博客 试卷样卷: 开卷考试,时间: 2024年11月16日 001 002 003 004 005 ……………………装………………………...
后台管理系统(开箱即用)
很久没有更新博客了,给大家带上一波福利吧,大佬勿扰 现在市面上流行的后台管理模板很多,若依,芋道等,可是这些框架对我们来说可能会有点重,所以我自己从0到1写了一个后台管理模板,你们使用时候可扩展性也会更高 项目主要功能: 成员管理,部门管理&#…...

5G CPE与4G CPE的主要区别有哪些
什么是CPE? CPE是Customer Premise Equipment(客户前置设备)的缩写,也可称为Customer-side Equipment、End-user Equipment或On-premises Equipment。CPE通常指的是位于用户或客户处的网络设备或终端设备,用于连接用户…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

无人机侦测与反制技术的进展与应用
国家电网无人机侦测与反制技术的进展与应用 引言 随着无人机(无人驾驶飞行器,UAV)技术的快速发展,其在商业、娱乐和军事领域的广泛应用带来了新的安全挑战。特别是对于关键基础设施如电力系统,无人机的“黑飞”&…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...
快速排序算法改进:随机快排-荷兰国旗划分详解
随机快速排序-荷兰国旗划分算法详解 一、基础知识回顾1.1 快速排序简介1.2 荷兰国旗问题 二、随机快排 - 荷兰国旗划分原理2.1 随机化枢轴选择2.2 荷兰国旗划分过程2.3 结合随机快排与荷兰国旗划分 三、代码实现3.1 Python实现3.2 Java实现3.3 C实现 四、性能分析4.1 时间复杂度…...