Python入门(7)--高级函数特性详解
Python高级函数特性详解 🚀
目录
- 匿名函数(Lambda)
- 装饰器的使用
- 生成器与迭代器
- 递归函数应用
- 实战案例:文件批处理工具
1. 匿名函数(Lambda)深入解析 🎯
1.1 Lambda函数基础与进阶
1.1.1 基本语法与类型注解
from typing import Callable, List, Any, Dict, Optional, Union# 基础lambda函数(带类型注解)
square: Callable[[int], int] = lambda x: x ** 2
greeting: Callable[[str, Optional[str]], str] = lambda name, msg="你好": f"{msg}, {name}!"# 带类型注解的复杂lambda函数
process_data: Callable[[Dict[str, Any]], List[Any]] = lambda d: [v for k, v in d.items() if isinstance(v, (int, float))]
1.1.2 函数式编程应用
# 1. 组合多个lambda函数
compose = lambda f, g: lambda x: f(g(x))
double = lambda x: x * 2
increment = lambda x: x + 1# 先加1再乘2
double_after_increment = compose(double, increment)
print(double_after_increment(3)) # 输出: 8# 2. 柯里化示例
curry = lambda f: lambda x: lambda y: f(x, y)
add = lambda x, y: x + y
curried_add = curry(add)
increment = curried_add(1)
print(increment(5)) # 输出: 6# 3. 偏函数应用
from functools import partial
multiply = lambda x, y: x * y
double = partial(multiply, 2)
print(double(4)) # 输出: 8
1.2 Lambda函数实战应用
1.2.1 数据处理与转换
# 1. 复杂数据结构处理
users = [{"name": "张三", "age": 25, "salary": 8000, "department": "技术"},{"name": "李四", "age": 30, "salary": 12000, "department": "销售"},{"name": "王五", "age": 28, "salary": 15000, "department": "技术"},{"name": "赵六", "age": 35, "salary": 20000, "department": "管理"}
]# 按多个条件排序(先按部门,再按薪资降序)
sorted_users = sorted(users,key=lambda u: (u["department"], -u["salary"])
)# 数据转换和筛选
tech_salaries = list(map(lambda u: u["salary"],filter(lambda u: u["department"] == "技术", users)
))# 2. 数据聚合
from collections import defaultdict# 按部门统计平均薪资
dept_avg_salary = defaultdict(list)
for user in users:dept_avg_salary[user["department"]].append(user["salary"])dept_averages = {dept: sum(salaries) / len(salaries)for dept, salaries in dept_avg_salary.items()
}
1.2.2 事件处理与回调
class EventSystem:def __init__(self):self.handlers: Dict[str, List[Callable]] = defaultdict(list)def register(self, event_name: str, handler: Callable) -> None:self.handlers[event_name].append(handler)def trigger(self, event_name: str, *args, **kwargs) -> None:for handler in self.handlers[event_name]:handler(*args, **kwargs)# 使用lambda作为事件处理器
event_system = EventSystem()# 注册多个简单的事件处理器
event_system.register("user_login", lambda user: print(f"用户 {user} 登录"))
event_system.register("user_login", lambda user: print(f"发送欢迎邮件给 {user}"))# 注册带条件判断的处理器
event_system.register("payment",lambda amount, user: print(f"大额支付警告: {user} 支付了 {amount}元")if amount > 10000 else None
)
1.3 Lambda函数最佳实践与性能考虑
1.3.1 性能优化技巧
from timeit import timeit
import operator# 1. 使用operator模块替代简单lambda
numbers = list(range(1000))# 不推荐
lambda_time = timeit(lambda: list(map(lambda x: x + 1, numbers)), number=1000)# 推荐
operator_time = timeit(lambda: list(map(operator.add, numbers, [1]*len(numbers))), number=1000)# 2. 缓存计算结果
from functools import lru_cache# 使用缓存装饰器包装lambda
cached_computation = lru_cache(maxsize=128)(lambda x: sum(i * i for i in range(x)))
1.3.2 代码可维护性建议
# ✅ 适合使用Lambda的场景
# 1. 简单的键函数
sorted_items = sorted(items, key=lambda x: x.priority)# 2. 简单的数据转换
transformed = map(lambda x: x.upper(), items)# 3. 简单的过滤条件
filtered = filter(lambda x: x > 0, numbers)# ❌ 不建议使用Lambda的场景
# 1. 复杂的业务逻辑
# 不推荐
process = lambda data: {k: [i * 2 for i in v if i > 0]for k, v in data.items()if isinstance(v, list)
}# ✅ 推荐使用常规函数
def process_data(data: Dict[str, List[int]]) -> Dict[str, List[int]]:"""处理数据集合Args:data: 输入数据字典Returns:处理后的数据字典"""result = {}for key, values in data.items():if isinstance(values, list):result[key] = [i * 2 for i in values if i > 0]return result
1.4 实战示例:数据分析管道
from typing import List, Dict, Any
from datetime import datetimeclass DataPipeline:"""数据处理管道"""def __init__(self):self.transforms: List[Callable] = []def add_transform(self, transform: Callable) -> 'DataPipeline':"""添加转换步骤"""self.transforms.append(transform)return selfdef process(self, data: List[Dict[str, Any]]) -> List[Dict[str, Any]]:"""执行所有转换"""result = datafor transform in self.transforms:result = transform(result)return result# 使用示例
# 1. 创建转换函数
filter_active = lambda data: [item for item in dataif item.get('status') == 'active'
]calculate_metrics = lambda data: [{**item, 'efficiency': item['output'] / item['input'] if item['input'] else 0}for item in data
]add_timestamp = lambda data: [{**item, 'processed_at': datetime.now().isoformat()}for item in data
]# 2. 构建和使用管道
pipeline = DataPipeline()
pipeline.add_transform(filter_active)\.add_transform(calculate_metrics)\.add_transform(add_timestamp)# 3. 处理数据
sample_data = [{'id': 1, 'status': 'active', 'input': 100, 'output': 85},{'id': 2, 'status': 'inactive', 'input': 90, 'output': 70},{'id': 3, 'status': 'active', 'input': 95, 'output': 80}
]processed_data = pipeline.process(sample_data)
2. 装饰器的使用 🎨
2.1 基本装饰器
from functools import wraps
import time
from typing import Callable, TypeVar, AnyT = TypeVar('T', bound=Callable[..., Any])def timing_decorator(func: T) -> T:"""测量函数执行时间的装饰器"""@wraps(func)def wrapper(*args, **kwargs):start_time = time.time()result = func(*args, **kwargs)end_time = time.time()print(f"函数 {func.__name__} 执行时间: {end_time - start_time:.4f} 秒")return resultreturn wrapper@timing_decorator
def slow_function():time.sleep(1)return "完成"
2.2 带参数的装饰器
def retry(max_attempts: int = 3, delay: float = 1.0):"""创建一个重试装饰器Args:max_attempts: 最大重试次数delay: 重试间隔(秒)"""def decorator(func: Callable) -> Callable:@wraps(func)def wrapper(*args, **kwargs):attempts = 0while attempts < max_attempts:try:return func(*args, **kwargs)except Exception as e:attempts += 1if attempts == max_attempts:raise etime.sleep(delay)return Nonereturn wrapperreturn decorator@retry(max_attempts=3, delay=2.0)
def unstable_network_call():"""模拟不稳定的网络调用"""if random.random() < 0.7: # 70%的失败率raise ConnectionError("网络连接失败")return "成功"
2.3 多个装饰器的组合
def log_decorator(func: Callable) -> Callable:@wraps(func)def wrapper(*args, **kwargs):print(f"调用函数: {func.__name__}")return func(*args, **kwargs)return wrapperdef validate_inputs(func: Callable) -> Callable:@wraps(func)def wrapper(*args, **kwargs):if not args and not kwargs:raise ValueError("函数参数不能为空")return func(*args, **kwargs)return wrapper@log_decorator
@validate_inputs
@timing_decorator
def process_data(data: List[Any]) -> List[Any]:"""处理数据的函数"""return [item for item in data if item is not None]
3. 生成器与迭代器 🔄
3.1 生成器函数
from typing import Generator, Iterator, Listdef fibonacci_generator(n: int) -> Generator[int, None, None]:"""生成斐波那契数列的生成器Args:n: 要生成的数字个数Yields:斐波那契数列中的下一个数字"""a, b = 0, 1for _ in range(n):yield aa, b = b, a + b# 内存效率对比
def get_numbers_list(n: int) -> List[int]:"""返回列表的方式"""return [i ** 2 for i in range(n)]def get_numbers_generator(n: int) -> Generator[int, None, None]:"""生成器方式"""for i in range(n):yield i ** 2
3.2 生成器表达式
# 列表推导式 vs 生成器表达式
numbers = [1, 2, 3, 4, 5]# 列表推导式(立即计算)
squares_list = [x ** 2 for x in numbers] # 创建新列表# 生成器表达式(惰性计算)
squares_gen = (x ** 2 for x in numbers) # 创建生成器对象# 条件筛选
even_squares = (x ** 2 for x in numbers if x % 2 == 0)# 多重生成器
matrix = ((i, j) for i in range(3) for j in range(3))
3.3 自定义迭代器
class DataIterator:"""自定义数据迭代器"""def __init__(self, data: List[Any]):self.data = dataself.index = 0def __iter__(self) -> 'DataIterator':return selfdef __next__(self) -> Any:if self.index >= len(self.data):raise StopIterationvalue = self.data[self.index]self.index += 1return value# 使用示例
class DataContainer:def __init__(self, data: List[Any]):self.data = datadef __iter__(self) -> DataIterator:return DataIterator(self.data)
4. 递归函数应用 🌳
4.1 基本递归模式
from typing import Any, List, Optionaldef factorial(n: int) -> int:"""计算阶乘的递归实现"""if n <= 1: # 基本情况return 1return n * factorial(n - 1) # 递归情况def binary_search(arr: List[int], target: int, left: int = 0, right: Optional[int] = None) -> int:"""递归实现二分查找Returns:目标值的索引,如果未找到返回-1"""if right is None:right = len(arr) - 1if left > right:return -1mid = (left + right) // 2if arr[mid] == target:return midelif arr[mid] > target:return binary_search(arr, target, left, mid - 1)else:return binary_search(arr, target, mid + 1, right)
4.2 高级递归应用
class TreeNode:def __init__(self, value: Any):self.value = valueself.left: Optional[TreeNode] = Noneself.right: Optional[TreeNode] = Nonedef tree_traversal(root: Optional[TreeNode], method: str = "inorder") -> Generator[Any, None, None]:"""通用的树遍历生成器Args:root: 树的根节点method: 遍历方法 ("preorder", "inorder", "postorder")"""if not root:returnif method == "preorder":yield root.valueyield from tree_traversal(root.left, method)yield from tree_traversal(root.right, method)elif method == "inorder":yield from tree_traversal(root.left, method)yield root.valueyield from tree_traversal(root.right, method)elif method == "postorder":yield from tree_traversal(root.left, method)yield from tree_traversal(root.right, method)yield root.value
5. 实战案例:文件批处理工具 🛠️
5.1 文件处理工具类
from pathlib import Path
from typing import Generator, List, Dict, Callable
import os
import shutilclass FileBatchProcessor:"""文件批处理工具"""def __init__(self, source_dir: str):self.source_dir = Path(source_dir)self.processors: Dict[str, Callable] = {}def register_processor(self, extension: str, processor: Callable) -> None:"""注册文件处理器"""self.processors[extension] = processordef find_files(self, pattern: str = "*") -> Generator[Path, None, None]:"""递归查找文件"""for item in self.source_dir.rglob(pattern):if item.is_file():yield itemdef process_files(self) -> Dict[str, List[str]]:"""处理所有文件"""results = {"success": [], "error": []}for file_path in self.find_files():try:extension = file_path.suffix.lower()if extension in self.processors:self.processors[extension](file_path)results["success"].append(str(file_path))except Exception as e:results["error"].append(f"{file_path}: {str(e)}")return results
5.2 实际应用示例
# 文件处理器函数
def process_text_file(file_path: Path) -> None:"""处理文本文件"""with file_path.open('r', encoding='utf-8') as f:content = f.read()# 处理文本内容processed_content = content.upper()# 保存处理后的文件backup_path = file_path.with_suffix(file_path.suffix + '.bak')shutil.copy2(file_path, backup_path)with file_path.open('w', encoding='utf-8') as f:f.write(processed_content)def process_image_file(file_path: Path) -> None:"""处理图片文件(示例)"""# 这里可以添加图片处理逻辑pass# 使用示例
def main():# 创建处理器实例processor = FileBatchProcessor("./documents")# 注册文件处理器processor.register_processor(".txt", process_text_file)processor.register_processor(".md", process_text_file)processor.register_processor(".jpg", process_image_file)processor.register_processor(".png", process_image_file)# 执行批处理results = processor.process_files()# 输出处理结果print(f"成功处理的文件: {len(results['success'])}")print(f"处理失败的文件: {len(results['error'])}")if results['error']:print("\n错误详情:")for error in results['error']:print(f"- {error}")if __name__ == "__main__":main()
本文详细介绍了Python的高级函数特性,从匿名函数到装饰器,从生成器到递归函数,最后通过一个实战案例展示了这些特性的实际应用。
希望这些内容对你的Python编程之旅有所帮助!
如果你觉得这篇文章有帮助,欢迎点赞转发,也期待在评论区看到你的想法和建议!👇
咱们下一期见!
相关文章:
--高级函数特性详解)
Python入门(7)--高级函数特性详解
Python高级函数特性详解 🚀 目录 匿名函数(Lambda)装饰器的使用生成器与迭代器递归函数应用实战案例:文件批处理工具 1. 匿名函数(Lambda)深入解析 🎯 1.1 Lambda函数基础与进阶 1.1.1 基本…...

【数据库原理】理解数据库,基础知识
第一代:网状数据库;第二代:关系数据库;第三代:新一代数据库系统BigData 一、理解数据库 什么是数据:信息,对事物的存在方方式、运动状态及特征的描述。数据,记录信息的识别方式有数…...

VConsole——(H5调试工具)前端开发使用于手机端查看控制台和请求发送
因为开发钉钉H5微应用在手机上一直查看不到日志等,出现安卓和苹果上传图片一边是成功的,一边是失败的,所以找了这个,之前在开发微信小程序进行调试的时候能看到,之前没想到过,这次被人提点发现可以单独使用…...

论文分享 | FuzzLLM:一种用于发现大语言模型中越狱漏洞的通用模糊测试框架
大语言模型是当前人工智能领域的前沿研究方向,在安全性方面大语言模型存在一些挑战和问题。分享一篇发表于2024年ICASSP会议的论文FuzzLLM,它设计了一种模糊测试框架,利用模型的能力去测试模型对越狱攻击的防护水平。 论文摘要 大语言模型中…...

vmWare虚拟环境centos7安装Hadoop 伪分布式实践
背景:近期在研发大数据中台,需要研究Hadoop hive 的各种特性,需要搭建一个Hadoop的虚拟环境,本来想着使用dock ,但突然发现docker 公共仓库的镜像 被XX 了,无奈重新使用vm 搭建虚拟机。 大概经历了6个小时完…...
】半小时入门C++开发(深入理解new+List+范围for+可变参数))
【C++入门(一)】半小时入门C++开发(深入理解new+List+范围for+可变参数)
目录 一.深入理解new 使用格式 二.List列表 定义一个列表 迭代器 添加元素 删除元素 排序 反转序列 三.范围for 四.可变参数 std::initializer_list 可变参数模板(variadic template) 一.深入理解new 类似于C语言中的malloc、calloc和reallo…...

Vue 3与TypeScript集成指南:构建类型安全的前端应用
在Vue 3中使用TypeScript,可以让你的组件更加健壮和易于维护。以下是使用TypeScript与Vue 3结合的详细步骤和知识点: 1. 环境搭建 首先,确保你安装了Node.js(推荐使用最新的LTS版本)和npm或Yarn。然后,安…...

MATLAB和Python发射光谱
在MATLAB和Python中,可以使用不同的库来生成发射光谱。以下是两种语言的简单示例: MATLAB: % 定义波长(nm)和强度(a.u.) wavelengths linspace(300, 1000, 1000); intensity sin(wavelengths / 500);…...

IEEE(常用)参考文献引用格式详解 | LaTeX参考文献规范(IEEE Trans、Conf、Arxiv)| 期刊会议名缩写查询
期刊 ** 期刊:已正式出版(有期卷号) ** 期刊:录用后在线访问即Early access(无期卷号)会议Arxiv论文 期刊 期刊:已正式出版(有期卷号) article{gu2024ai, title{{AI}-Enhanced Cloud-Edge-Terminal Collaborative Ne…...

第二十周:机器学习
目录 摘要 ABSTRACT 一、吴恩达机器学习exp2——逻辑回归 1、logistic函数 2、数据预处理 3、损失函数 4、梯度下降 5、设定评价指标 6、决策边界 7、正则化 二、动手深度学习pytorch——数据预处理 1、数据集读取 2、缺失值处理 3、转换为张量格式 总结 摘要…...

Elasticsearch面试内容整理-Elasticsearch 基础概念
Elasticsearch 是一个基于 Apache Lucene 的开源分布式搜索和分析引擎,提供强大的全文本搜索、实时数据分析、分布式存储等功能。以下是 Elasticsearch 的一些基础概念: 什么是 Elasticsearch? ● Elasticsearch 是一个用于全文搜索和实时分析的分布式搜索引擎。 ● 开源和可…...
机器学习算法模型系列——Adam算法
Adam是一种自适应学习率的优化算法,结合了动量和自适应学习率的特性。 主要思想是根据参数的梯度来动态调整每个参数的学习率。 核心原理包括: 动量(Momentum):Adam算法引入了动量项,以平滑梯度更新的方向…...

Qt按钮类-->day09
按钮基类 QAbstractButton 标题与图标 // 参数text的内容显示到按钮上 void QAbstractButton::setText(const QString &text); // 得到按钮上显示的文本内容, 函数的返回就是 QString QAbstractButton::text() const;// 得到按钮设置的图标 QIcon icon() const; // 给按钮…...

基于xr-frame实现微信小程序的手部、手势识别3D模型叠加和石头剪刀布游戏功能
前言 xr-frame是一套小程序官方提供的XR/3D应用解决方案,基于混合方案实现,性能逼近原生、效果好、易用、强扩展、渐进式、遵循小程序开发标准。xr-frame在基础库v2.32.0开始基本稳定,发布为正式版,但仍有一些功能还在开发&#…...

基于Kafka2.1解读Consumer原理
文章目录 概要整体架构流程技术名词解释技术细节coordinatorfetcherclientconsumer#poll的主要流程 全局总览小结 概要 继上一篇讲Producer原理的文章过去已经一个多月了,今天来讲讲Consumer的原理。 其实源码早就读了部分了,但是最近工作比较忙&#x…...

深度学习:ResNet每一层的输出形状
其中 /**在输出通道数为64、步幅为2的7 7卷积层后,接步幅为2的3 3的最大汇聚层,与GoogLeNet区别是每个卷积层后增加了批量规范层**/ b1 nn.Sequential(nn.Conv2d(1, 64, kernel_size7, stride2, padding3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_s…...

国内几大网络安全公司介绍 - 网络安全
Posted by zhaol under 安全 , 电信 , 评论 , 中国 中国国内的安全市场进入“战国时期”,启明星辰、绿盟、天融信、安氏、亿阳、联想网御、华为等战国七雄拥有雄厚的客户资源和资金基础,帐前皆有勇猛善战之士,渐渐开始统领国内安全市场的潮流…...

修改Android Studio项目配置JDK路径和项目Gradle路径的GUI工具
概述 本工具提供了一个基于Python Tkinter的图形用户界面(GUI),用于帮助用户搜索并更新Android Studio项目中的config.properties文件里的java.home路径,以及workspace.xml文件中的last_opened_file_path路径。该工具旨在简化手动…...
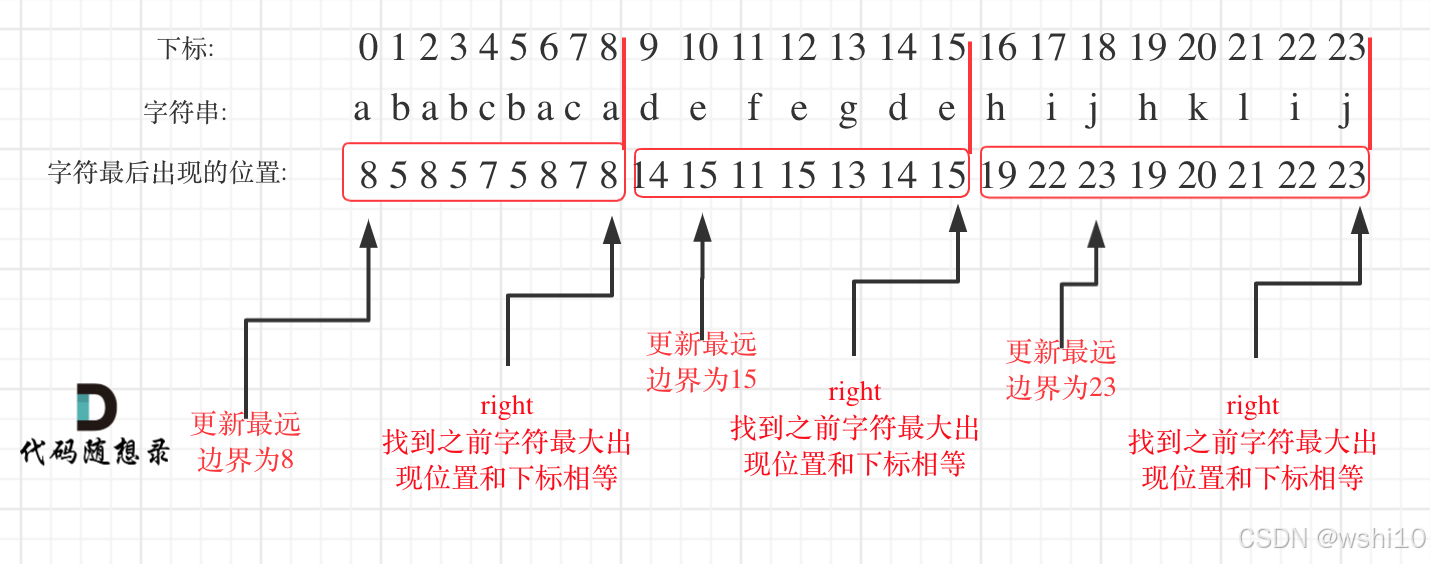
✅DAY30 贪心算法 | 452. 用最少数量的箭引爆气球 | 435. 无重叠区间 | 763.划分字母区间
452. 用最少数量的箭引爆气球 解题思路:首先把原数组按左边界进行排序。然后比较[i-1]的右边界和[i]的左边界是否重叠,如果重叠,更新当前右边界为最小右边界和[i1]的左边界判断是重叠。 class Solution:def findMinArrowShots(self, points:…...

关于Redis单线程模型以及IO多路复用的理解
IO多路复用 -> redis主线程 -> 事件队列 -> 事件处理器 1.IO多路复用机制的作用: 操作系统的多路复用机制(如 epoll、select)负责监听多个文件描述符(如客户端连接)上的事件。 当某个文件描述符上的事件就绪…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...
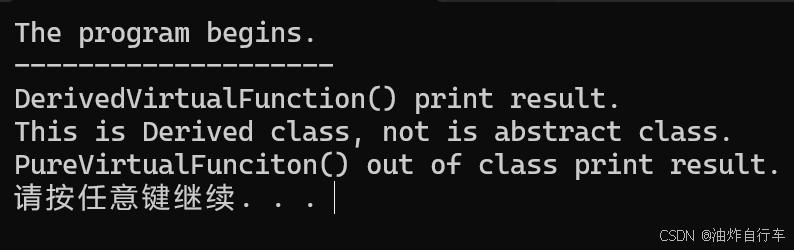
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...