第二十周:机器学习
目录
摘要
ABSTRACT
一、吴恩达机器学习exp2——逻辑回归
1、logistic函数
2、数据预处理
3、损失函数
4、梯度下降
5、设定评价指标
6、决策边界
7、正则化
二、动手深度学习pytorch——数据预处理
1、数据集读取
2、缺失值处理
3、转换为张量格式
总结
摘要
本周接着上周的线性回归,进一步学习了逻辑回归的完整代码,不仅包含了逻辑回归模型的整个训练过程,还对逻辑回归中的损失函数和梯度下降函数进行代码表达。在复习了逻辑回归模型的数学原理后,对其进行代码实践,并且可视化决策边界函数,将自定义模型与库函数自带模型进行准确率、损失函数及其边界函数的比较。最后,接着pytorch动手深度学习的内容,学习了数据预处理部分。
ABSTRACT
This week follows up on last week's linear regression by further studying the complete code for logistic regression, which not only includes the entire training process of a logistic regression model, but also provides a code representation of the loss function and gradient descent function in logistic regression. After reviewing the mathematical principles of the logistic regression model, code practice on it and visualize the decision boundary function, comparing the accuracy, loss function and its boundary function of the custom model with the model that comes with the library function. Finally, the pytorch hands-on deep learning was followed by learning the data preprocessing component.
一、吴恩达机器学习exp2——逻辑回归
1、logistic函数

sigmoid函数不仅可以调用scikit-learn 库中自带的LogisticRegression模型,还可以自己定义,自定义及验证如下:
def sigmoid(z): #定义sigmoid函数return 1 / (1 + np.exp(-z))#验证sigmoid函数的正确性
nums = np.arange(-10, 10, step=1) #np.arange()函数返回一个有终点和起点的固定步长的排列
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(nums, sigmoid(nums), 'r')
plt.show()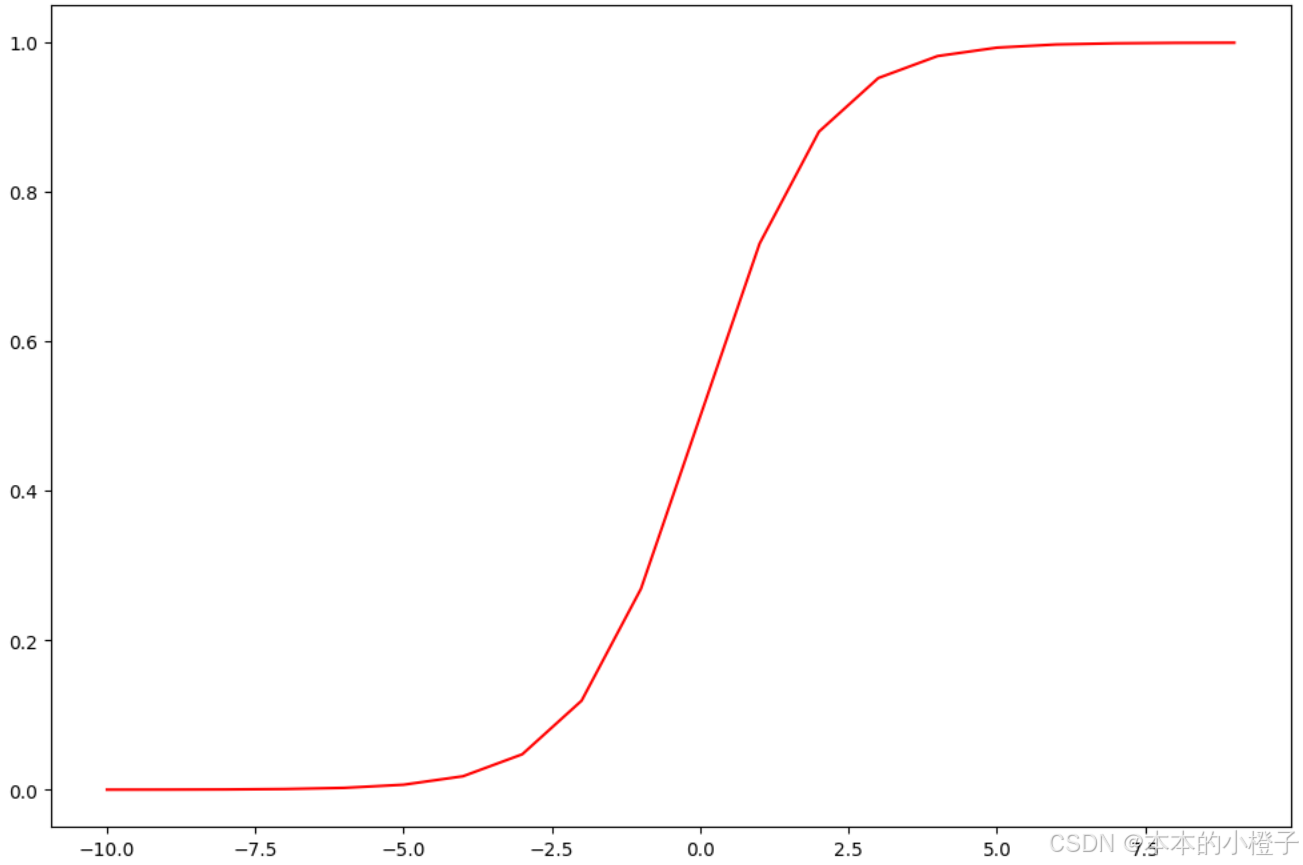
import time
import matplotlib.pyplot as plt
import numpy as npfrom LogisticRegression import sigmoid
nums = np.arange(-5, 5, step=0.1)
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(nums, sigmoid(nums), 'r')
ax.set_title("Sigmoid Function")
ax.grid()
plt.show()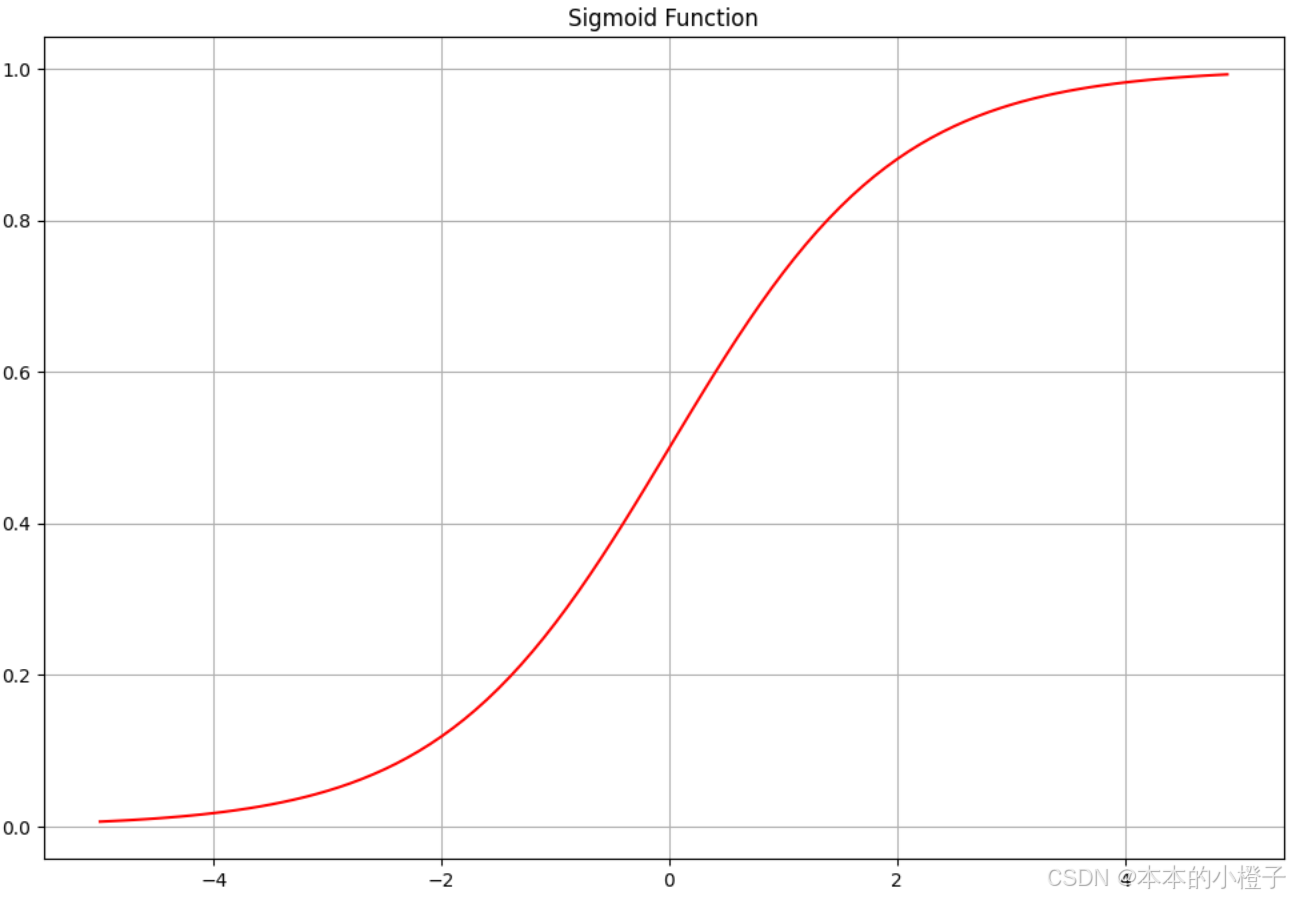
2、数据预处理
加载数据
import pandas as pd
data = np.loadtxt(fname='ex2data1.txt',delimiter=",")
data = pd.read_csv('ex2data1.txt', header=None, names=['Exam 1', 'Exam 2', 'Admitted'])
data.head()查看数据集正负样本
import matplotlib.pyplot as plt
import numpy as np# 将列表转换为NumPy数组
data = np.array(data)#绘制数据集正负样本的散点图
fig, ax = plt.subplots(figsize=(12,8))
positive_data_idx= np.where(data[:,2]==1)
positive_data = data[positive_data_idx]
negative_data_idx= np.where(data[:, 2] == 0)
negative_data = data[negative_data_idx]
ax.scatter(x=positive_data[:, 0], y=positive_data[:, 1], s=10, color="red",label="positive")
ax.scatter(x=negative_data[:, 0], y=negative_data[:, 1], s=10, label="negative")
ax.set_title("Dataset")
plt.legend(loc=2)
plt.show()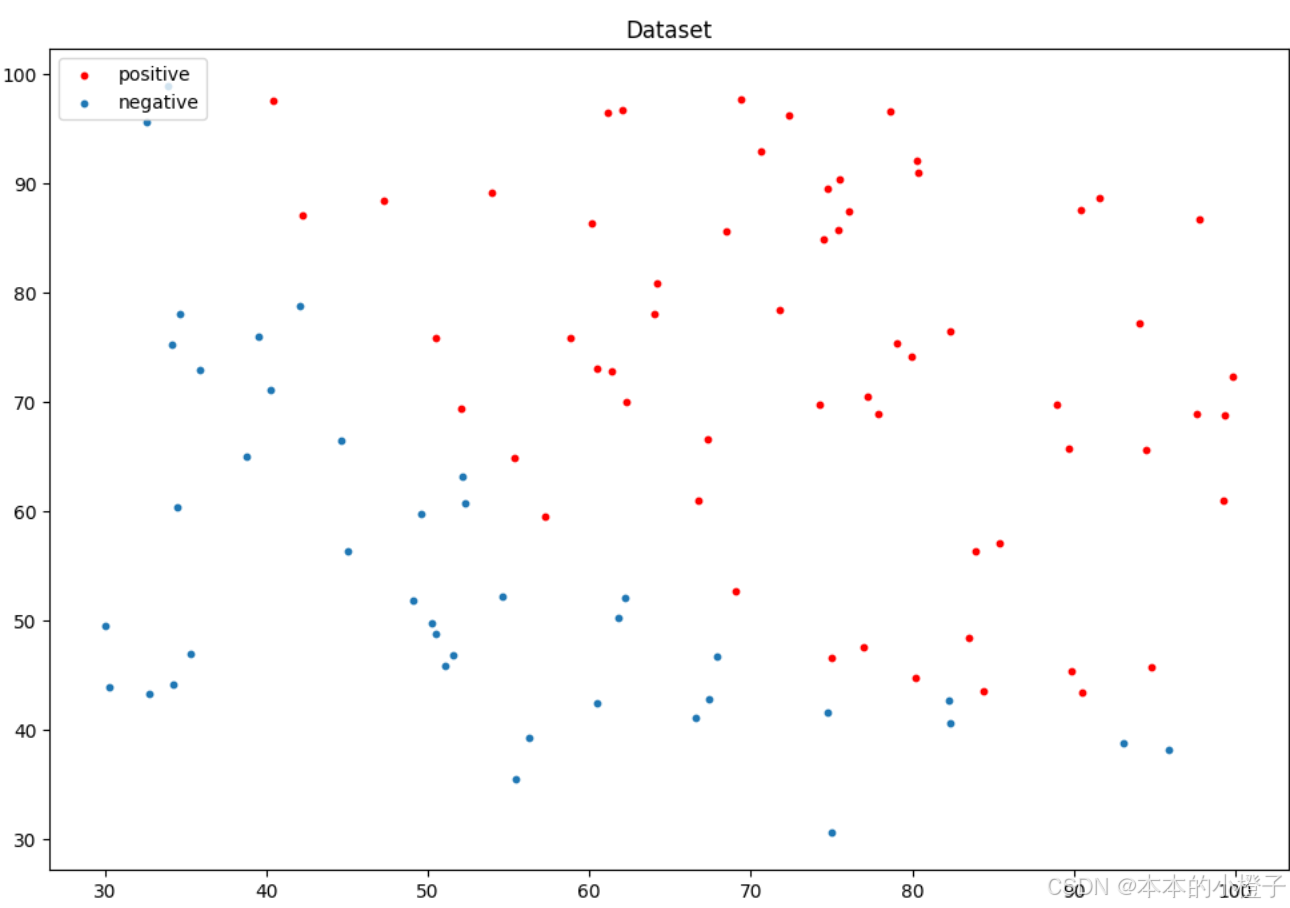
同理,训练集和验证集分别的分布散点图如下:
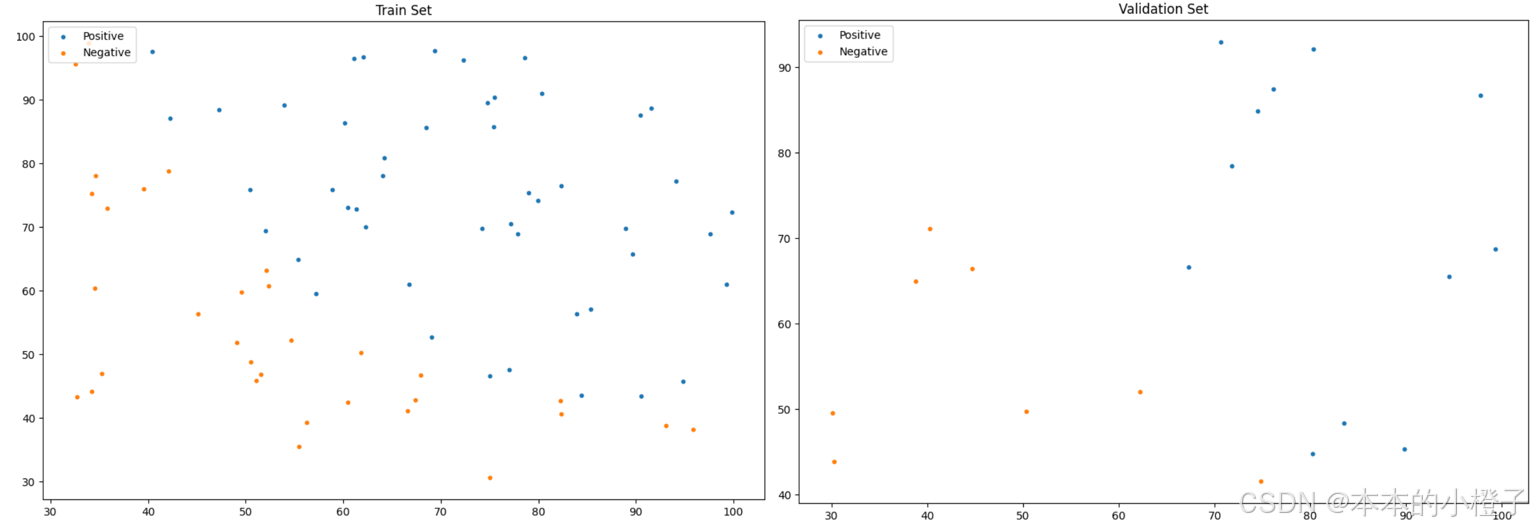
划分训练集额、验证集
from sklearn.model_selection import train_test_split
train_x, val_x, train_y, val_y = train_test_split(data[:, :-1], data[:, -1], test_size=0.2)
# train_x, val_x, train_y, val_y = data[:, :-1], data[:, :-1], data[:, -1], data[:, -1]#绘制数据集中训练集和验证集的各个分数段的分布散点图
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(x=train_x[:,0], y=train_x[:,1], s=10, label="Train")
ax.scatter(x=val_x[:,0], y=val_x[:,1], s=10, color="red", label="Validation")
ax.set_title('Dataset for Train and Validation')
ax.legend(loc=2)
plt.show()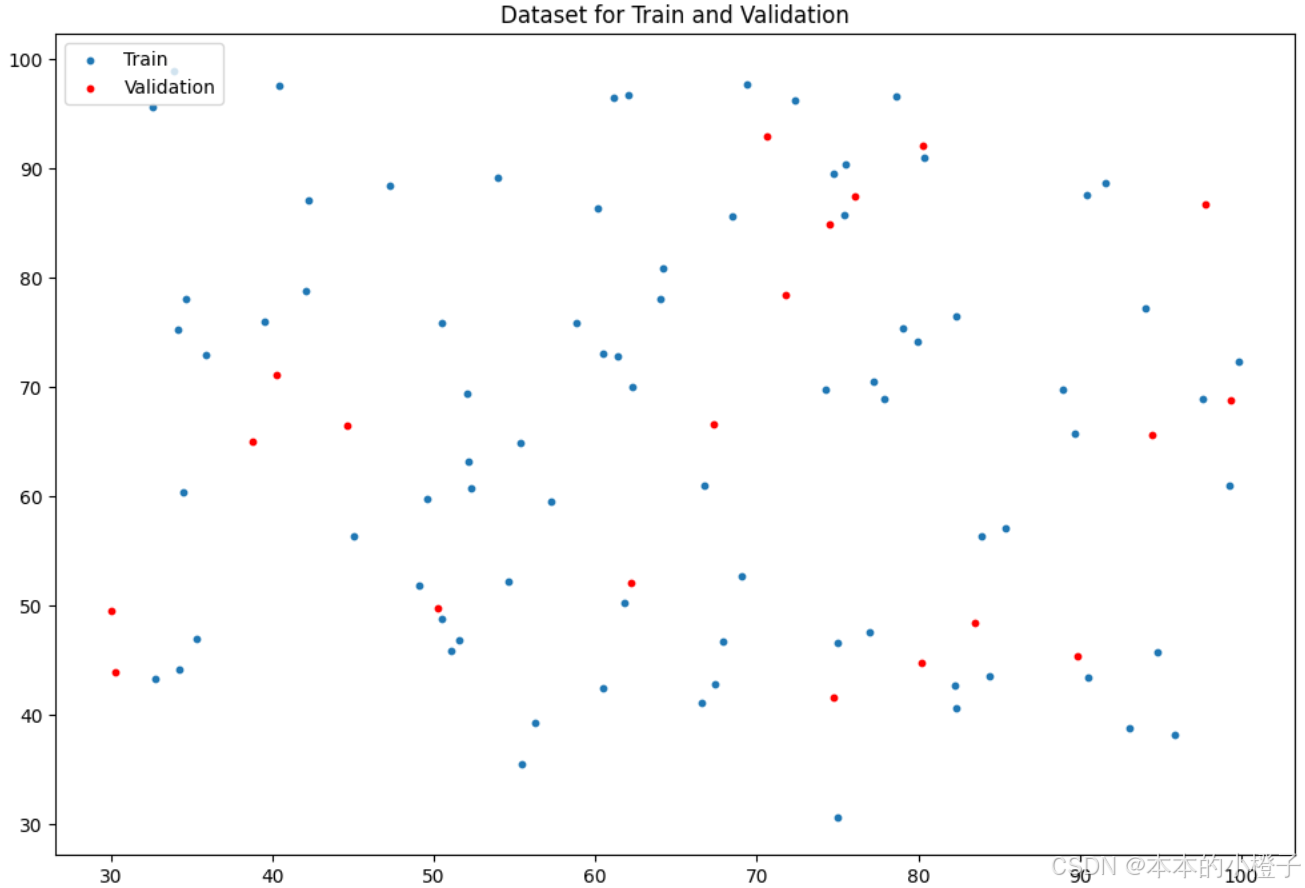
3、损失函数
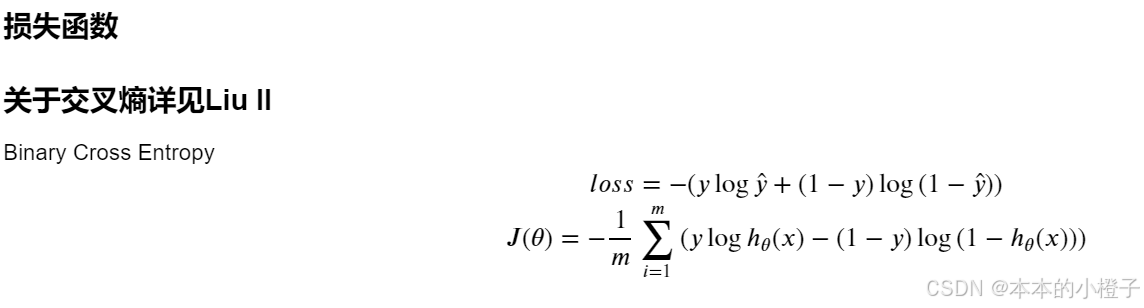
定义损失函数
def cost(theta, X, y):theta = np.matrix(theta)X = np.matrix(X)y = np.matrix(y)first = np.multiply(-y, np.log(sigmoid(X * theta.T)))#这个是(100,1)乘以(100,1)就是对应相乘second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)))return np.sum(first - second) / (len(X))初始化参数
data.insert(0, 'Ones', 1) #增加一列,使得矩阵相乘更容易cols = data.shape[1]
X = data.iloc[:,0:cols-1] #训练数据
y = data.iloc[:,cols-1:cols]#标签#将X、y转化为数组格式
X = np.array(X.values)
y = np.array(y.values)
theta = np.zeros(3) #初始化向量theta为0
theta,X,y检查矩阵属性和当前损失
X.shape, theta.shape, y.shape
cost(theta, X, y)![]()
![]()
4、梯度下降
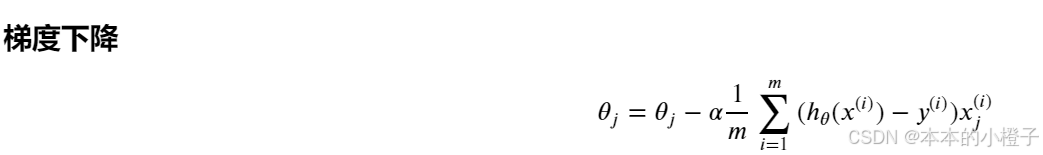
定义梯度下降函数
def gradient(theta, X, y): #梯度下降theta = np.matrix(theta) #将参数theta、特征值X和标签y转化为矩阵形式X = np.matrix(X)y = np.matrix(y)parameters = int(theta.ravel().shape[1]) #.ravel()将数组维度拉成一维数组, .shape()是长度,parameters指theta的下标个数grad = np.zeros(parameters) error = sigmoid(X * theta.T) - y #误差for i in range(parameters): #迭代的计算梯度下降term = np.multiply(error, X[:,i])grad[i] = np.sum(term) / len(X)return gradgradient(theta, X, y) 最优化
import scipy.optimize as opt
result = opt.fmin_tnc(func=cost, x0=theta, fprime=gradient, args=(X, y))#opt.fmin_tnc()函数用于最优化
result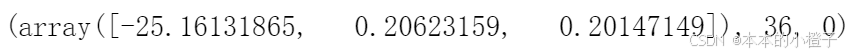
最优化后的损失
cost(result[0], X, y) ![]()
以上的1、2、3、4条都是可以自定义的函数模块,把很多个功能封装到LogisticRegression类中,后面逻辑回归的训练过程就是直接调用其内部的函数即可。
5、设定评价指标
定义准确率函数
def predict(theta, X): #准确率probability = sigmoid(X * theta.T)return [1 if x >= 0.5 else 0 for x in probability]theta_min = np.matrix(result[0])
predictions = predict(theta_min, X)
correct = [1 if ((a == 1 and b == 1) or (a == 0 and b == 0)) else 0 for (a, b) in zip(predictions, y)]#zip 可以同时比较两个列表
accuracy = (sum(map(int, correct)) % len(correct))#map会对列表correct的每个元素调用int函数,将其转换成一个整数,然后返回一个迭代器,可以用来迭代所有转换后的结果
print ('accuracy = {0}%'.format(accuracy)) #因为数据总共100 个所以准确率只加测对的就行不用除了 
查看精确度、损失和F1-score
acc = logistic_reg.test(val_x,val_y_ex)
print("Accuracy on Test Set: {:.2f}%".format(acc * 100))
from sklearn.metrics import f1_score
f1 = f1_score(y_true=val_y_ex,y_pred=logistic_reg.predict(val_x))
print("My F1 Score: {:.4f}".format(f1)) 
调用库函数进行验证
from sklearn.linear_model import LogisticRegression
sk_lr = LogisticRegression(max_iter=50000)
sk_lr.fit(train_x,train_y)
sk_pred = sk_lr.predict(val_x)
count = np.sum(np.equal(sk_pred,val_y))
sk_acc = count/val_y.shape[0]
sk_prob = sk_lr.predict_proba(val_x)from LogisticRegression import bce_loss
sk_loss = bce_loss(sk_prob[:,1], val_y_ex)
sk_theta = np.array([[sk_lr.intercept_[0],sk_lr.coef_[0,0],sk_lr.coef_[0,1]]])
sk_f1 = f1_score(y_true=val_y_ex,y_pred=sk_pred)
print("Sklearn Accuracy: {:.2f}%".format(sk_acc * 100))
print("Sklearn Val Loss: {:.4f}".format(sk_loss))
print("SKlearn Parameters: ",sk_theta)
print("Sklearn F1 Score: {:.4f}".format(sk_f1))
6、决策边界
绘制决策边界函数
#计算系数:结果是2*3维数组
coef = -(theta/ theta[0, 2])
coef1 = -(sk_theta / sk_theta[0, 2])data = data.to_numpy() # 将dataframe形式的数据转化为numpy形式: 使用.to_numpy()方法x = np.arange(0,100, step=10) #x轴是等距刻度
y = coef[0,0] + coef[0,1]*x #y是自定义边界函数
y1 = coef1[0,0] + coef[0,1]*x #y1是调用边界函数#绘制边界函数
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(x,y,label="My Prediction",color='purple')
ax.plot(x,y1,label="Sklearn",color='orange')#绘制散点图
ax.scatter(x=positive_data[:, 0], y=positive_data[:, 1], s=10, color="red",label="positive")
ax.scatter(x=negative_data[:, 0], y=negative_data[:, 1], s=10, color="blue",label="negative")
ax.set_title("Decision Boundary")
plt.legend(loc=2)
plt.show() 绘制训练过程
绘制训练过程
记录每一轮的损失值
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(np.arange(1,epochs+1), train_loss, 'r', label="Train Loss")
ax.plot(np.arange(1,epochs+1), val_loss, 'b', label="Val Loss")
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss')
ax.set_title('Train Curve')
plt.legend(loc=2)
plt.show()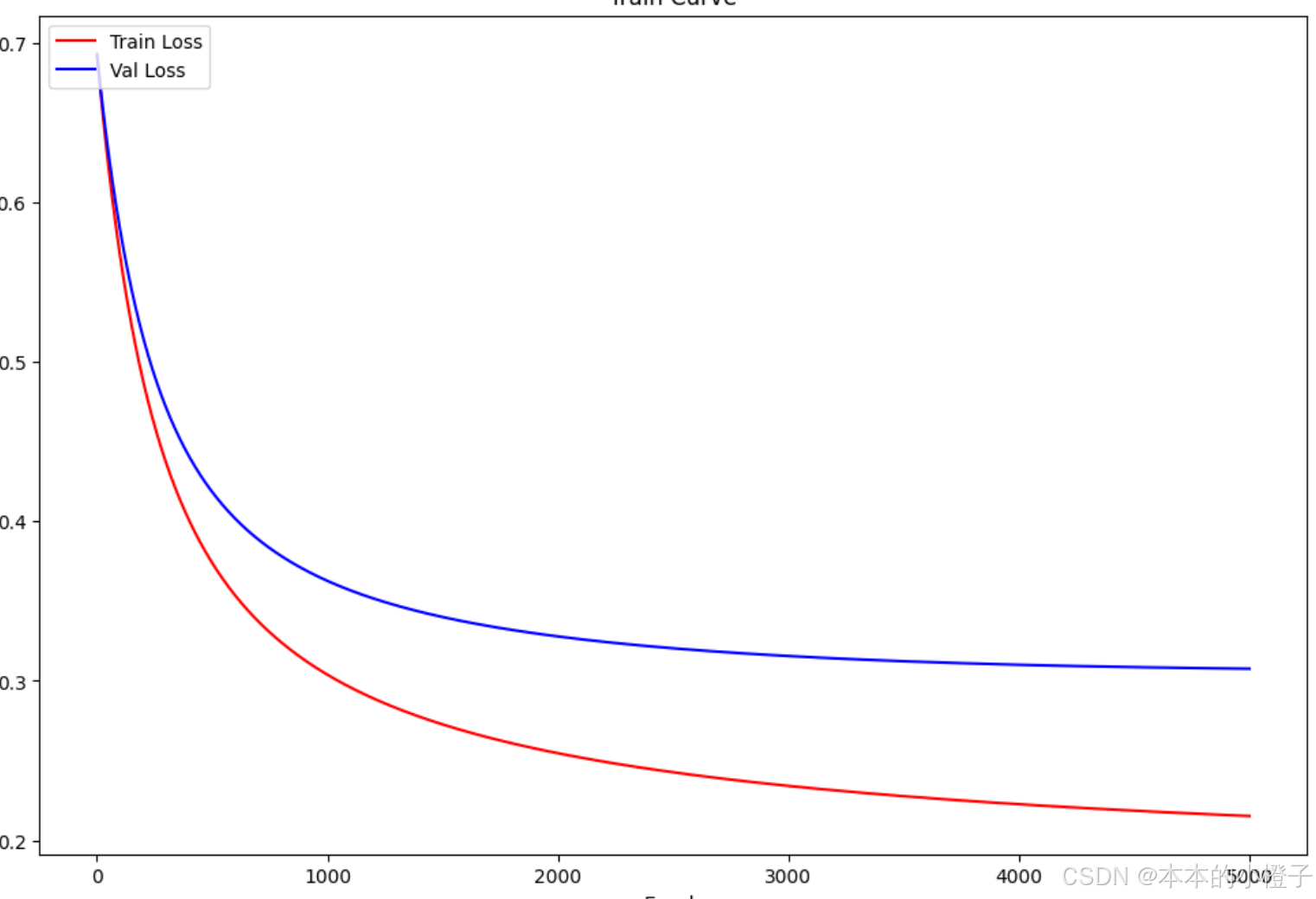
7、正则化
正则化实际上就是对损失函数及梯度下降的一种改进方式,它在其他数据预处理、训练过程及结果可视化的方面都都跟普通的逻辑回归没什么差别。下面仅指出不同的地方进行修改

正则化损失函数
相比于正常的损失函数,多了一个正则项reg
#正则化代价函数
def costReg(theta, X, y, learningRate):theta = np.matrix(theta)X = np.matrix(X)y = np.matrix(y)first = np.multiply(-y, np.log(sigmoid(X * theta.T)))second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)))reg = (learningRate / (2 * len(X))) * np.sum(np.power(theta[:,1:theta.shape[1]], 2))#注意下标 j是从1开始到n的 不包含0return np.sum(first - second) / len(X) + reg正则化梯度下降
在迭代的计算梯度的时候,如果是第一次计算梯度就不需要加正则化项,其余轮次需要加上正则化项
#正则化梯度下降
def gradientReg(theta, X, y, learningRate):theta = np.matrix(theta)X = np.matrix(X)y = np.matrix(y)parameters = int(theta.ravel().shape[1])grad = np.zeros(parameters)error = sigmoid(X * theta.T) - yfor i in range(parameters):term = np.multiply(error, X[:,i])if (i == 0):grad[i] = np.sum(term) / len(X) #和上文一样,我们这里没有执行梯度下降,我们仅仅在计算一个梯度步长else:grad[i] = (np.sum(term) / len(X)) + ((learningRate / len(X)) * theta[:,i])return grad决策边界可视化
fig, ax = plt.subplots(figsize=(12,8))# 使用更鲜明的颜色和更小的点
ax.plot(x, y, label="My Prediction", color='purple', linestyle='--') # 虚线
ax.plot(x, y1, label="Sklearn", color='orange', linestyle=':') # 点线
# ax.scatter(x=my_bd[:, 0], y=my_bd[:, 1], s=5, color="yellow", edgecolor='black', label="My Decision Boundary")
# ax.scatter(x=sk_bd[:, 0], y=sk_bd[:, 1], s=5, color="gray", edgecolor='black', label="Sklearn Decision Boundary")# 保持正负样本点的颜色鲜艳,但可以适当减小大小
ax.scatter(x=positive_data[:, 0], y=positive_data[:, 1], s=20, color="red", label="positive")
ax.scatter(x=negative_data[:, 0], y=negative_data[:, 1], s=20, color="blue", label="negative")ax.set_title('Decision Boundary')
ax.legend(loc=2)
plt.show()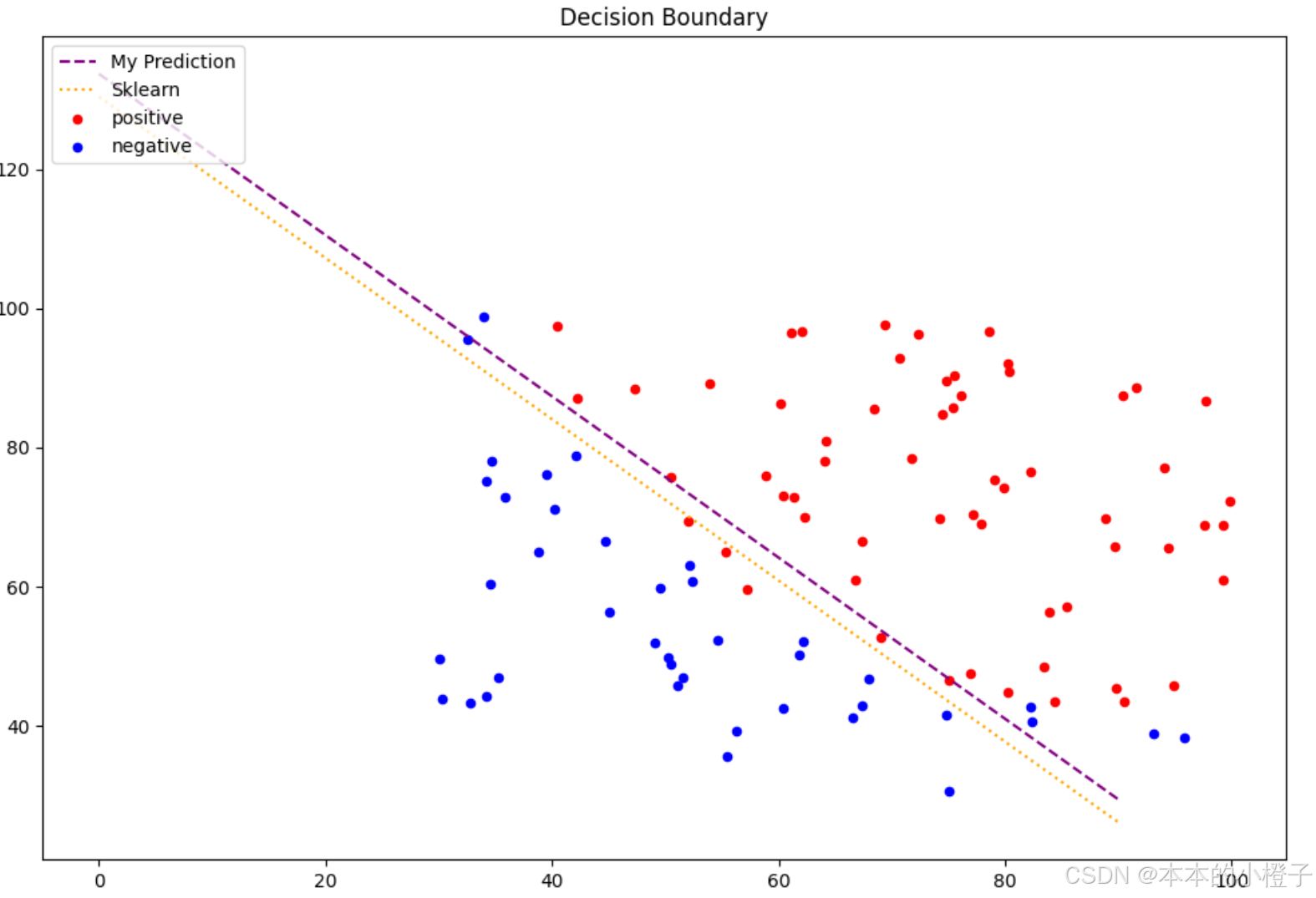
二、动手深度学习pytorch——数据预处理
1、数据集读取
创建一个人工数据集,并存储在CSV(逗号分隔值)文件
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:f.write('NumRooms,Alley,Price\n')f.write('NA,Pave,127500\n')f.write('2,NA,106000\n')f.write('4,NA,178100\n')f.write('NA,NA,140000\n')从创建的CSV文件中加载原始数据集
import pandas as pddata = pd.read_csv(data_file)
print(data)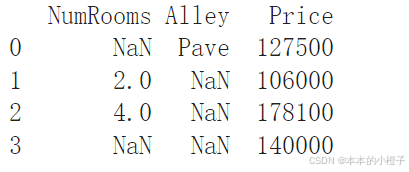
2、缺失值处理
处理缺失值的方法有插值法和删除法,下面代码以插值法为例
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
print(inputs)
3、转换为张量格式
import torchX = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
X, y
总结
本周继续完成吴恩达机器学习的实验2部分——逻辑回归 ,并且复习了对应的理论知识,对交叉熵、梯度更新、正则化表示的数学原理进行推导并且实现在代码上;pytorch学习了数据集的读取、缺失值的处理以及张量格式的转换。下周继续完成吴恩达实验,并接着学习pytorch比较细致的知识点。
相关文章:
第二十周:机器学习
目录 摘要 ABSTRACT 一、吴恩达机器学习exp2——逻辑回归 1、logistic函数 2、数据预处理 3、损失函数 4、梯度下降 5、设定评价指标 6、决策边界 7、正则化 二、动手深度学习pytorch——数据预处理 1、数据集读取 2、缺失值处理 3、转换为张量格式 总结 摘要…...

Elasticsearch面试内容整理-Elasticsearch 基础概念
Elasticsearch 是一个基于 Apache Lucene 的开源分布式搜索和分析引擎,提供强大的全文本搜索、实时数据分析、分布式存储等功能。以下是 Elasticsearch 的一些基础概念: 什么是 Elasticsearch? ● Elasticsearch 是一个用于全文搜索和实时分析的分布式搜索引擎。 ● 开源和可…...
机器学习算法模型系列——Adam算法
Adam是一种自适应学习率的优化算法,结合了动量和自适应学习率的特性。 主要思想是根据参数的梯度来动态调整每个参数的学习率。 核心原理包括: 动量(Momentum):Adam算法引入了动量项,以平滑梯度更新的方向…...

Qt按钮类-->day09
按钮基类 QAbstractButton 标题与图标 // 参数text的内容显示到按钮上 void QAbstractButton::setText(const QString &text); // 得到按钮上显示的文本内容, 函数的返回就是 QString QAbstractButton::text() const;// 得到按钮设置的图标 QIcon icon() const; // 给按钮…...

基于xr-frame实现微信小程序的手部、手势识别3D模型叠加和石头剪刀布游戏功能
前言 xr-frame是一套小程序官方提供的XR/3D应用解决方案,基于混合方案实现,性能逼近原生、效果好、易用、强扩展、渐进式、遵循小程序开发标准。xr-frame在基础库v2.32.0开始基本稳定,发布为正式版,但仍有一些功能还在开发&#…...

基于Kafka2.1解读Consumer原理
文章目录 概要整体架构流程技术名词解释技术细节coordinatorfetcherclientconsumer#poll的主要流程 全局总览小结 概要 继上一篇讲Producer原理的文章过去已经一个多月了,今天来讲讲Consumer的原理。 其实源码早就读了部分了,但是最近工作比较忙&#x…...

深度学习:ResNet每一层的输出形状
其中 /**在输出通道数为64、步幅为2的7 7卷积层后,接步幅为2的3 3的最大汇聚层,与GoogLeNet区别是每个卷积层后增加了批量规范层**/ b1 nn.Sequential(nn.Conv2d(1, 64, kernel_size7, stride2, padding3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_s…...

国内几大网络安全公司介绍 - 网络安全
Posted by zhaol under 安全 , 电信 , 评论 , 中国 中国国内的安全市场进入“战国时期”,启明星辰、绿盟、天融信、安氏、亿阳、联想网御、华为等战国七雄拥有雄厚的客户资源和资金基础,帐前皆有勇猛善战之士,渐渐开始统领国内安全市场的潮流…...

修改Android Studio项目配置JDK路径和项目Gradle路径的GUI工具
概述 本工具提供了一个基于Python Tkinter的图形用户界面(GUI),用于帮助用户搜索并更新Android Studio项目中的config.properties文件里的java.home路径,以及workspace.xml文件中的last_opened_file_path路径。该工具旨在简化手动…...
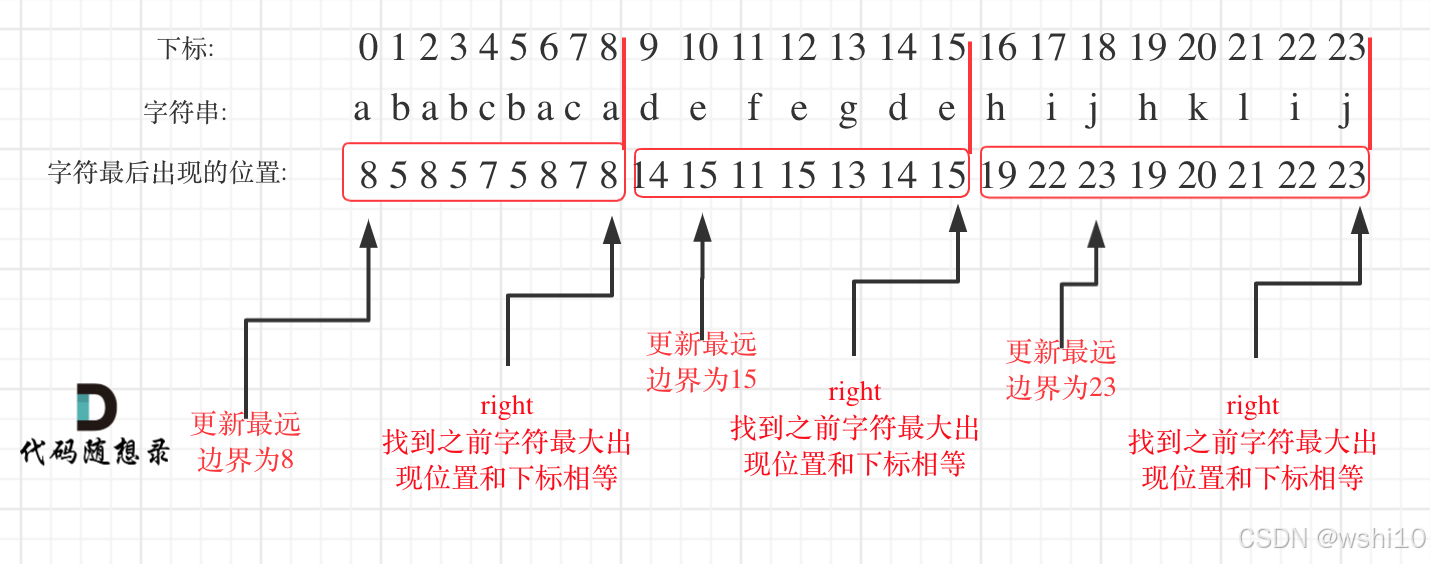
✅DAY30 贪心算法 | 452. 用最少数量的箭引爆气球 | 435. 无重叠区间 | 763.划分字母区间
452. 用最少数量的箭引爆气球 解题思路:首先把原数组按左边界进行排序。然后比较[i-1]的右边界和[i]的左边界是否重叠,如果重叠,更新当前右边界为最小右边界和[i1]的左边界判断是重叠。 class Solution:def findMinArrowShots(self, points:…...

关于Redis单线程模型以及IO多路复用的理解
IO多路复用 -> redis主线程 -> 事件队列 -> 事件处理器 1.IO多路复用机制的作用: 操作系统的多路复用机制(如 epoll、select)负责监听多个文件描述符(如客户端连接)上的事件。 当某个文件描述符上的事件就绪…...

学习ASP.NET Core的身份认证(基于Cookie的身份认证1)
B/S架构程序可通过Cookie、Session、JWT、证书等多种方式认证用户身份,虽然之前测试过用户登录代码,也学习过开源项目中的登录认证,但其实还是对身份认证疑惑甚多,就比如登录验证后用户信息如何保存、客户端下次连接时如何获取用户…...

奇门遁甲中看债务时用神该怎么取?
奇门遁甲中看债务的用神 一、值符 值符在债务关系中可代表债权人(放贷人)。例如在预测放贷时,以值符为放贷人,如果值符克天乙(借贷人)或者天乙生值符,这种情况下可以放贷;反之&#…...

Redis 集群主要有以下几种类型
Redis 集群主要有以下几种类型: 主从复制模式: 这种模式包含一个主数据库实例(master)与一个或多个从数据库实例(slave)。客户端可以对主数据库进行读写操作,对从数据库进行读操作,主…...

使用 Axios 拦截器优化 HTTP 请求与响应的实践
目录 前言1. Axios 简介与拦截器概念1.1 Axios 的特点1.2 什么是拦截器 2. 请求拦截器的应用与实践2.1 请求拦截器的作用2.2 请求拦截器实现 3. 响应拦截器的应用与实践3.1 响应拦截器的作用3.2 响应拦截器实现 4. 综合实例:一个完整的 Axios 配置5. 使用拦截器的好…...
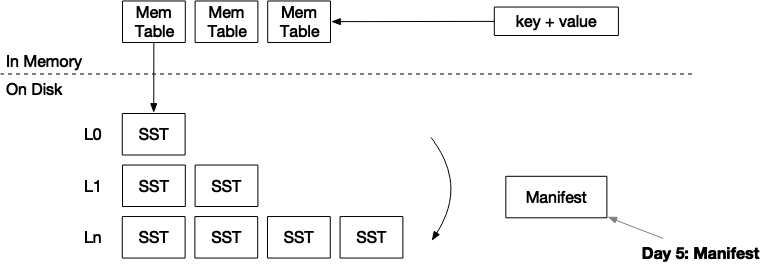
mini-lsm通关笔记Week2Day5
项目地址:https://github.com/skyzh/mini-lsm 个人实现地址:https://gitee.com/cnyuyang/mini-lsm Summary 在本章中,您将: 实现manifest文件的编解码。系统重启时从manifest文件中恢复。 要将测试用例复制到启动器代码中并运行…...

mybatis的动态sql用法之排序
概括 在最近的开发任务中,涉及到了一些页面的排序,其中最为常见的就是时间的降序和升序。这个有的前端控件就可以完成,但是对于一些无法用前端控件的,只能通过后端来进行解决。 后端的解决方法就是使用mybatis的动态sql拼接。 …...

OneToMany 和 ManyToOne
在使用 ORM(如 TypeORM)进行实体关系设计时,OneToMany 和 ManyToOne 是非常重要的注解,常用来表示两个实体之间的一对多关系。下面通过例子详细说明它们的使用场景和工作方式。 OneToMany 和 ManyToOne 的基本概念 ManyToOne 表示…...

《生成式 AI》课程 第3講 CODE TASK 任务3:自定义任务的机器人
课程 《生成式 AI》课程 第3講:訓練不了人工智慧嗎?你可以訓練你自己-CSDN博客 我们希望你创建一个定制的服务机器人。 您可以想出任何您希望机器人执行的任务,例如,一个可以解决简单的数学问题的机器人0 一个机器人,…...

反转链表、链表内指定区间反转
反转链表 给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1),长度为n,反转该链表后,返回新链表的表头。 如当输入链表{1,2,3}时,经反转后,原链表变…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

RSS 2025|从说明书学习复杂机器人操作任务:NUS邵林团队提出全新机器人装配技能学习框架Manual2Skill
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。 尽管 VLMs 取得了显著进展,机器人仍难以胜任复杂的长时程任务(如家具装配),主要受限于人…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...