YOLO入门教程(三)——训练自己YOLO11实例分割模型并预测【含教程源码+一键分类数据集 + 故障排查】
目录
- 引言
- 前期准备
- Step0 环境部署
- 1.安装OpenCV
- 2.安装Pytorch
- 3.安装Ultralytics
- Step1 打标训练
- Step2 格式转换
- Step3 整理训练集
- Step4 训练数据集
- 4.1创建yaml文件
- 4.2训练
- 4.3预测
- 4.4故障排查
- 4.4.1OpenCV版本故障,把OpenCV版本升级到4.0以上
- 4.4.2NumPy版本故障,把NumPy降低版本到1.26.4
- 4.4.3没有安装ultralytics模块
- 4.4.4Arial.ttf下载超时
- 4.4.5‘torchvision::nms‘
- 4.4.6其他报错
- 参考博客
引言
YOLO(You Only Look Once)作为一个目标检测算法,支持训练和预测实例分割模型,其标注要求是点集合和txt文件,本文教程主要介绍如何训练自己的YOLO模型,LabelMe点集标注的标签如何训练。
前期准备
在开始前建议先下载YOLO11训练源码,安装Anaconda,VSCode,LabelMe并配置好Python环境,OpenCV3.10环境,PyTorch即可开始训练自己的数据集。
Step0 环境部署
1.安装OpenCV
下载所需版本的OpenCV包,将安装好的.whl文件拷贝到.\Anaconda3\Lib\site-packages文件夹中,并将原来的OpenCV卸载
pip uninstall opencv-python
pip uninstall opencv-contrib-python
cd .\Anaconda3\Lib\site-packages
pip install msgpack-python
pip install msgpack
pip install x.whl
2.安装Pytorch
根据CUDA版本和onnx版本选择pytorch套件
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
3.安装Ultralytics
必须要先安装CUDA版本的pytorch套件再安装YOLO环境
pip install ultralytics
Step1 打标训练
使用LabelMe软件进行打标签,会在原图路径下生成.json标签文件。


Step2 格式转换
LabelMe生成的.json标签文件格式不适用于YOLO训练,需要转换格式为.txt标签文件,利用以下代码将.json标签文件归一化为YOLO可直接训练的.txt标签文件。
import json
import osclass_name = ['background','dot','line','worn']
json_dir = './source/json'
labels_dir = './source/labels'def labelme2yolo_seg(class_name, json_dir, labels_dir):"""此函数用来将labelme软件标注好的json格式转换为yolov_seg中使用的txt格式:param json_dir: labelme标注好的*.json文件所在文件夹:param labels_dir: 转换好后的*.txt保存文件夹:param class_name: 数据集中的类别标签:return:"""list_labels = [] # 存放json文件的列表# 0.创建保存转换结果的文件夹if (not os.path.exists(labels_dir)):os.mkdir(labels_dir)# 1.获取目录下所有的labelme标注好的Json文件,存入列表中for files in os.listdir(json_dir): # 遍历json文件夹下的所有json文件file = os.path.join(json_dir, files) # 获取一个json文件list_labels.append(file) # 将json文件名加入到列表中for labels in list_labels: # 遍历所有json文件lawith open(labels, "r") as f:file_in = json.load(f)shapes = file_in["shapes"]print(labels)txt_filename = os.path.basename(labels).replace(".json", ".txt")txt_path = os.path.join(labels_dir, txt_filename) # 使用labels_dir变量指定保存路径with open(txt_path, "w+") as file_handle:for shape in shapes:line_content = [] # 初始化一个空列表来存储每个形状的坐标信息line_content.append(str(class_name.index(shape['label']))) # 添加类别索引# 添加坐标信息for point in shape["points"]:x = point[0] / file_in["imageWidth"]y = point[1] / file_in["imageHeight"]line_content.append(str(x))line_content.append(str(y))# 使用空格连接列表中的所有元素,并写入文件file_handle.write(" ".join(line_content) + "\n")if __name__ == '__main__':labelme2yolo_seg(class_name, json_dir, labels_dir)
json_dir替换成标签所在路径
labels_dir替换成新标签所在路径
class_name替换成标签
备注:转换后查看txt是否包含多点信息如下图所示

Step3 整理训练集
YOLO有数据集要求放置的格式要求,具体要求如下:
dataset/
├── train/
│ ├── images/
│ └── labels/
└── val/
├── images/
└── labels/
利用以下代码将快速将训练集整理好,划分为训练集和验证集:
import random
import shutil
import os
import shutil#通过相对路径索引到数据集
source_floder_path = './source'
# 图片目标路径
images_folder = source_floder_path + '/images'
# 定义图片尾缀
image_suffix = ['.jpg']# 标签目标路径
labels_folder = source_floder_path + '/labels'
# 定义标签尾缀
label_suffix = ['.txt']def CollateDataset(image_dir,label_dir): # image_dir:图片路径 label_dir:标签路径# 创建一个空列表来存储有效图片的路径valid_images = []# 创建一个空列表来存储有效 label 的路径valid_labels = []# 遍历 images 文件夹下的所有图片for image_name in os.listdir(image_dir):# 获取图片的完整路径image_path = os.path.join(image_dir, image_name)# 获取图片文件的扩展名ext = os.path.splitext(image_name)[-1]# 根据扩展名替换成对应的 label 文件名label_name = image_name.replace(ext, ".txt")# 获取对应 label 的完整路径label_path = os.path.join(label_dir, label_name)# 判断 label 是否存在if not os.path.exists(label_path):# # 删除图片# os.remove(image_path)print("there is no:", label_path)else:# 将图片路径添加到列表中valid_images.append(image_path)# 将 label 路径添加到列表中valid_labels.append(label_path)# 遍历每个有效图片路径for i in range(len(valid_images)):image_path = valid_images[i]label_path = valid_labels[i]# 随机生成一个概率r = random.random()# 判断图片应该移动到哪个文件夹# train:valid:test = 8:2:0if r < 0.0:# 移动到 test 文件夹destination = "./datasets/test"elif r < 0.1:# 移动到 valid 文件夹destination = "./datasets/valid"else:# 移动到 train 文件夹destination = "./datasets/train"# 创建目标文件夹中 images 和 labels 子文件夹os.makedirs(os.path.join(destination, "images"), exist_ok=True)os.makedirs(os.path.join(destination, "labels"), exist_ok=True)# 生成目标文件夹中图片的新路径image_destination_path = os.path.join(destination, "images", os.path.basename(image_path))# 移动图片到目标文件夹shutil.copy(image_path, image_destination_path)# 生成目标文件夹中 label 的新路径label_destination_path = os.path.join(destination, "labels", os.path.basename(label_path))# 移动 label 到目标文件夹shutil.copy(label_path, label_destination_path)def CopyImagesAndLabels(path):# 遍历源文件夹中的文件for filename in os.listdir(path):print(f"FileName is {filename}")# 将路径分隔符从 '\\' 替换为 '/'filename = filename.replace('\\', '/')# 检查文件是否为图片的后缀结尾for suffix in image_suffix:#图片移动到图片路径if filename.endswith(suffix):# 拼接路径字符串source_file = os.path.normpath(os.path.join(os.getcwd(), path, filename))dest_file = os.path.normpath(os.path.join(os.getcwd(), images_folder, filename))# 复制文件if os.path.exists(source_file):try:# 复制文件# 确保目标文件夹存在,递归创建目录os.makedirs(os.path.dirname(dest_file), exist_ok=True)print(f"Copying Image {source_file} to {dest_file}")shutil.copy(source_file, dest_file)except Exception as e:print(f"Error: {e}") # 检查文件是否为标签的后缀结尾for suffix in label_suffix:#图片移动到图片路径if filename.endswith(suffix):# 拼接路径字符串source_file = os.path.normpath(os.path.join(os.getcwd(), path, filename))dest_file = os.path.normpath(os.path.join(os.getcwd(), labels_folder, filename))# 复制文件print(f"Copy Label {source_file} to {dest_file}")if os.path.exists(source_file):try:# 复制文件# 确保目标文件夹存在,递归创建目录os.makedirs(os.path.dirname(dest_file), exist_ok=True)print(f"Copying Label {source_file} to {dest_file}")shutil.copy(source_file, dest_file)print("File copied successfully!")except Exception as e:print(f"Error: {e}")# 拷贝完成print("File copied successfully!")if __name__ == '__main__':# 整理训练集CopyImagesAndLabels(source_floder_path)CollateDataset(images_folder, labels_folder)
source_floder_path替换成数据集所在路径
images_folder和labels_folder为图片集和标记集所在路径
image_suffix和label_suffix为图片集和标签集的尾缀
destination为最终训练集和验证集所在路径
备注:转换后可以在本地路径上检查是否整理成功
Step4 训练数据集
4.1创建yaml文件

Train/val替换成数据集所在绝对路径
Classes为标签数量与名称
4.2训练
# coding:utf-8
from ultralytics import YOLO
import torch
import cv2
import os# 模型配置文件
model_yaml_path = "./yolo11-main/ultralytics/cfg/models/11/yolo11-seg.yaml"
# 数据集配置文件
data_yaml_path = os.path.normpath(os.path.join(os.getcwd(), './yolo11-main/ultralytics/cfg/datasets/mytrain.yaml'))
# 预训练模型
pre_model_name = os.path.normpath(os.path.join(os.getcwd(), './yolo11-main/weights/yolo11s-seg.pt'))
# 模型保存路径
save_model_name = os.path.normpath(os.path.join(os.getcwd(), './yolo11-main/runs/detect/mytrain_1120'))if __name__ == '__main__':print(torch.__version__) #注意,这里也是两个下划线print(cv2.__version__)# 加载预训练模型model = YOLO(model_yaml_path).load(pre_model_name)# 使用预训练权重结果更高 但是如果要论文的话建议不要用预训练权重# 不加载预训练模型# model = YOLOv(model_yaml_path)# 训练模型results = model.train(data=data_yaml_path, epochs=500, batch=8, name=save_model_name, imgsz=640, device='cuda:0')
data_yaml_path替换成4.1步骤下yaml的名称与路径
pre_model_name为预训练模型区别如下图
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| –data | str | ROOT/“data/coco128.yaml” | 数据集配置文件路径 |
| –epochs | int | 500 | 训练总轮数 |
| –batch | int | 8 | 所有 GPU 上的总批量大小,-1 表示自动批量大小 |
task:选择任务类型,可选[‘detect’, ‘segment’, ‘classify’, ‘init’]
mode: 选择是训练、验证还是预测的任务类型 可选[‘train’, ‘val’, ‘predict’]
model: 选择yolov8不同的模型配置文件,可选yolov8s.yaml、yolov8m.yaml、yolov8l.yaml、yolov8x.yaml
data: 选择生成的数据集配置文件
epochs:指的就是训练过程中整个数据集将被迭代多少次,显卡不行你就调小点。
batch:一次看完多少张图片才进行权重更新,梯度下降的mini-batch,显卡不行你就调小点。
4.3预测
from ultralytics import YOLO# Load a pretrained YOLOv10n model
# model = YOLOv10("runs/detect/train_v10/weights/best.pt")
model = YOLO("./yolo11-main/runs/detect/mytrain_1120/weights/best.pt")# Perform object detection on an image
# results = model("test1.jpg")
# results = model.predict("ultralytics/assets/bus.jpg")
results = model.predict("./source/images/8.jpg")# Display the results
results[0].show()

4.4故障排查
4.4.1OpenCV版本故障,把OpenCV版本升级到4.0以上
ModuleNotFoundError: No module named ‘cv2’
下载所需版本的OpenCV包,将安装好的.whl文件拷贝到.\Anaconda3\Lib\site-packages文件夹中,并将原来的OpenCV卸载
pip uninstall opencv-python
pip uninstall opencv-contrib-python
cd .\Anaconda3\Lib\site-packages
pip install msgpack-python
pip install msgpack
pip install x.whl
备注:版本cp后的数字代表了适配Python的版本。如果你的Python版本是3.9.11请务必选择cp39,其它依此类推。对于我们Windows64位系统,应当选择win_amd64系列。
4.4.2NumPy版本故障,把NumPy降低版本到1.26.4
A module that was compiled using NumPy 1.x cannot be run in NumPy 2.0.1 as it may crash. To support both 1.x and 2.x versions of NumPy, modules must be compiled with NumPy 2.0. Some module may need to rebuild instead e.g. with ‘pybind11>=2.12’.
pip uninstall numpy
pip install numpy==1.26.4
4.4.3没有安装ultralytics模块
New https://pypi.org/project/ultralytics/8.2.66 available 😃 Update with ‘pip install -U ultralytics’
pip install -U ultralytics
4.4.4Arial.ttf下载超时
解决yolov5环境配置报错Arial.ttf下载超时Downloading
4.4.5‘torchvision::nms‘
【问题解决】NotImplementedError: Could not run ‘torchvision::nms‘ with arguments from the ‘CUDA‘ backend
之前先执行pip install ultralytics指令再安装CUDA版本的pytorch套件
要先安装pytorch再安装yolo环境
4.4.6其他报错
其他报错可以搜索或者在YOLO官方常见问题文档中查找
参考博客
1.深度学习之目标检测从入门到精通——json转yolo格式
2.模型训练篇 | yolov10来了!手把手教你如何用yolov10训练自己的数据集(含网络结构 + 模型训练 + 模型推理等)
3.在win10下安装Anaconda环境并配置OpenCV
4.ModuleNotFoundError: No module named ‘torch‘ 解决方案
5.Labelme与YOLO标签格式互转,含实例分割和目标检测,轻松实现数据扩充
相关文章:
YOLO入门教程(三)——训练自己YOLO11实例分割模型并预测【含教程源码+一键分类数据集 + 故障排查】
目录 引言前期准备Step0 环境部署1.安装OpenCV2.安装Pytorch3.安装Ultralytics Step1 打标训练Step2 格式转换Step3 整理训练集Step4 训练数据集4.1创建yaml文件4.2训练4.3预测4.4故障排查4.4.1OpenCV版本故障,把OpenCV版本升级到4.0以上4.4.2NumPy版本故障…...

【加入默语老师的私域】C#面试题
什么是依赖注入,如何实现? 依赖注入是一种设计模式。我们不是直接在另一个类(依赖类)中创建一个类的对象,而是将对象作为参数传递给依赖类的构造函数。它有助于编写松散耦合的代码,并有助于使代码更加模块…...
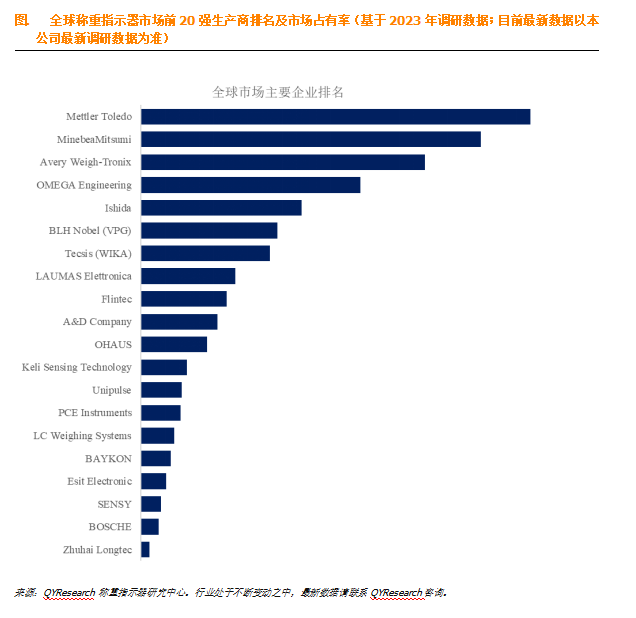
称重传感器指示器行业全面且深入的分析
称重传感器指示器是一种用于显示和解释称重传感器输出信号的设备,用于测量力、重量或压力。称重传感器是将物理力(如重量)转换为电信号的传感器,称重传感器指示器将该电信号转换为可读格式,通常以磅、公斤或牛顿等单位…...

NAT网络地址转换——Easy IP
NAT网络地址转换 Tip: EasylP没有地址池的概念,使用接口地址作为NAT转换的公有地址。EasylP适用于不具备固定公网IP地址的场景:如通过DHCP, PPPOE拨号获取地址的私有网络出口,可以直接使用获取到的动态地址进行转换。 本次实验模拟nat协议配置 AR1配置如下&…...
【Visual Studio系列教程】如何在 VS 上编程?
上一篇博客中,我们介绍了《什么是 Visual Studio?》。本文,我们来看第2篇《如何在 VS 上编程?》。阅读本文大约10 分钟。我们会向文件中添加代码,了解 Visual Studio 编写、导航和了解代码的简便方法。 本文假定&…...

Mybatis-Plus 多租户插件属性自动赋值
文章目录 1、Mybatis-Plus 多租户插件1.1、属性介绍1.2、使用多租户插件mavenymlThreadLocalUtil实现 定义,注入租户处理器插件测试domianservice & ServiceImplmapper 测试mapper.xml 方式 1.3、不使用多租户插件 2、实体对象的属性自动赋值使用1. 定义实体类2. 实现 Meta…...

AWTK-WIDGET-WEB-VIEW 实现笔记 (4) - Ubuntu
Ubuntu 上实现 AWTK-WIDGET-WEB-VIEW 开始以为很简单,后来发现是最麻烦的。因为 Ubuntu 上的 webview 库是 基于 GTK 的,而 AWTK 是基于 X11 的,两者的窗口系统不同,所以期间踩了几个大坑。 1. 编译 AWTK 在使用 Linux 的输入法时…...
--高级函数特性详解)
Python入门(7)--高级函数特性详解
Python高级函数特性详解 🚀 目录 匿名函数(Lambda)装饰器的使用生成器与迭代器递归函数应用实战案例:文件批处理工具 1. 匿名函数(Lambda)深入解析 🎯 1.1 Lambda函数基础与进阶 1.1.1 基本…...

【数据库原理】理解数据库,基础知识
第一代:网状数据库;第二代:关系数据库;第三代:新一代数据库系统BigData 一、理解数据库 什么是数据:信息,对事物的存在方方式、运动状态及特征的描述。数据,记录信息的识别方式有数…...

VConsole——(H5调试工具)前端开发使用于手机端查看控制台和请求发送
因为开发钉钉H5微应用在手机上一直查看不到日志等,出现安卓和苹果上传图片一边是成功的,一边是失败的,所以找了这个,之前在开发微信小程序进行调试的时候能看到,之前没想到过,这次被人提点发现可以单独使用…...

论文分享 | FuzzLLM:一种用于发现大语言模型中越狱漏洞的通用模糊测试框架
大语言模型是当前人工智能领域的前沿研究方向,在安全性方面大语言模型存在一些挑战和问题。分享一篇发表于2024年ICASSP会议的论文FuzzLLM,它设计了一种模糊测试框架,利用模型的能力去测试模型对越狱攻击的防护水平。 论文摘要 大语言模型中…...

vmWare虚拟环境centos7安装Hadoop 伪分布式实践
背景:近期在研发大数据中台,需要研究Hadoop hive 的各种特性,需要搭建一个Hadoop的虚拟环境,本来想着使用dock ,但突然发现docker 公共仓库的镜像 被XX 了,无奈重新使用vm 搭建虚拟机。 大概经历了6个小时完…...
】半小时入门C++开发(深入理解new+List+范围for+可变参数))
【C++入门(一)】半小时入门C++开发(深入理解new+List+范围for+可变参数)
目录 一.深入理解new 使用格式 二.List列表 定义一个列表 迭代器 添加元素 删除元素 排序 反转序列 三.范围for 四.可变参数 std::initializer_list 可变参数模板(variadic template) 一.深入理解new 类似于C语言中的malloc、calloc和reallo…...

Vue 3与TypeScript集成指南:构建类型安全的前端应用
在Vue 3中使用TypeScript,可以让你的组件更加健壮和易于维护。以下是使用TypeScript与Vue 3结合的详细步骤和知识点: 1. 环境搭建 首先,确保你安装了Node.js(推荐使用最新的LTS版本)和npm或Yarn。然后,安…...

MATLAB和Python发射光谱
在MATLAB和Python中,可以使用不同的库来生成发射光谱。以下是两种语言的简单示例: MATLAB: % 定义波长(nm)和强度(a.u.) wavelengths linspace(300, 1000, 1000); intensity sin(wavelengths / 500);…...

IEEE(常用)参考文献引用格式详解 | LaTeX参考文献规范(IEEE Trans、Conf、Arxiv)| 期刊会议名缩写查询
期刊 ** 期刊:已正式出版(有期卷号) ** 期刊:录用后在线访问即Early access(无期卷号)会议Arxiv论文 期刊 期刊:已正式出版(有期卷号) article{gu2024ai, title{{AI}-Enhanced Cloud-Edge-Terminal Collaborative Ne…...

第二十周:机器学习
目录 摘要 ABSTRACT 一、吴恩达机器学习exp2——逻辑回归 1、logistic函数 2、数据预处理 3、损失函数 4、梯度下降 5、设定评价指标 6、决策边界 7、正则化 二、动手深度学习pytorch——数据预处理 1、数据集读取 2、缺失值处理 3、转换为张量格式 总结 摘要…...

Elasticsearch面试内容整理-Elasticsearch 基础概念
Elasticsearch 是一个基于 Apache Lucene 的开源分布式搜索和分析引擎,提供强大的全文本搜索、实时数据分析、分布式存储等功能。以下是 Elasticsearch 的一些基础概念: 什么是 Elasticsearch? ● Elasticsearch 是一个用于全文搜索和实时分析的分布式搜索引擎。 ● 开源和可…...
机器学习算法模型系列——Adam算法
Adam是一种自适应学习率的优化算法,结合了动量和自适应学习率的特性。 主要思想是根据参数的梯度来动态调整每个参数的学习率。 核心原理包括: 动量(Momentum):Adam算法引入了动量项,以平滑梯度更新的方向…...

Qt按钮类-->day09
按钮基类 QAbstractButton 标题与图标 // 参数text的内容显示到按钮上 void QAbstractButton::setText(const QString &text); // 得到按钮上显示的文本内容, 函数的返回就是 QString QAbstractButton::text() const;// 得到按钮设置的图标 QIcon icon() const; // 给按钮…...

Linux定时任务实战:利用rsync实现跨服务器文件自动同步
1. 为什么选择rsync替代scp进行文件同步? 在企业服务器运维中,文件同步是再常见不过的需求。比如需要把A服务器的日志文件同步到B服务器做集中分析,或者把生产环境的配置文件分发到多台服务器。很多人的第一反应是用scp命令,这确实…...

SAP S/4HANA银行账户管理新姿势:Fiori App全流程操作指南
SAP S/4HANA银行账户管理新姿势:Fiori App全流程操作指南 在数字化转型浪潮中,SAP S/4HANA的Fiori界面正重塑企业财务管理的操作体验。想象一下:曾经需要记忆数十个事务代码的银行账户管理工作,现在只需在直观的磁贴界面点击几下就…...

LiveDraw:打破屏幕与现实界限的实时绘画神器
LiveDraw:打破屏幕与现实界限的实时绘画神器 【免费下载链接】live-draw A tool allows you to draw on screen real-time. 项目地址: https://gitcode.com/gh_mirrors/li/live-draw 你是否曾为无法在演示视频、设计稿或在线课堂上直接标注而感到困扰&#x…...

7款重塑音频体验的开源工具:用open-source-mac-os-apps构建全场景处理体系
7款重塑音频体验的开源工具:用open-source-mac-os-apps构建全场景处理体系 【免费下载链接】open-source-mac-os-apps serhii-londar/open-source-mac-os-apps: 是一个收集了众多开源 macOS 应用程序的仓库,这些应用程序涉及到各种领域,例如编…...

3个理由告诉你为什么Mermaid Live Editor是技术文档创作的终极工具
3个理由告诉你为什么Mermaid Live Editor是技术文档创作的终极工具 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-edito…...
预测到token伪造的CTF通关教程)
PHP伪随机数漏洞深度利用:从mt_rand()预测到token伪造的CTF通关教程
PHP伪随机数安全攻防实战:从种子预测到Token伪造的CTF全解析 1. PHP伪随机数机制的安全隐患 PHP的mt_rand()函数作为梅森旋转算法(Mersenne Twister)的实现,长期以来被开发者视为"足够随机"的选择。但鲜为人知的是,这个看似可靠的随…...

新手必看!万物识别镜像部署全攻略:从零到识别只需10分钟
新手必看!万物识别镜像部署全攻略:从零到识别只需10分钟 你是不是经常在网上看到一张图片,特别想知道里面是什么东西?或者工作中需要处理大量图片,手动给每张图打标签简直让人崩溃?今天我要分享的这个工具…...
Google TranslateGemma:27B多语言图文翻译新体验
Google TranslateGemma:27B多语言图文翻译新体验 【免费下载链接】translategemma-27b-it 项目地址: https://ai.gitcode.com/hf_mirrors/google/translategemma-27b-it 导语:Google推出基于Gemma 3架构的TranslateGemma-27B-IT模型,…...

Betweenness Centrality在社交网络分析中的实战应用
1. 什么是Betweenness Centrality? 在社交网络分析中,Betweenness Centrality(中介中心性)是一个非常重要的指标,它用来衡量一个节点在网络中作为"桥梁"的重要性。简单来说,就是看这个节点在连接…...

【stm32_1】集成开发环境的搭建 + KEIL5使用STM32标准固件库源码建立M4工程模板
1.MDK软件的下载 使用该链接直接下载所需mdk:https://armkeil.blob.core.windows.net/eval/MDK***.EXE 比如指定5.26版本,https://armkeil.blob.core.windows.net/eval/MDK526.EXE MDK软件的结构 2.软件安装完成后,要安装ST公司提供的芯片支持包xxxx.p…...