基于 Levenberg - Marquardt 法的 BP 网络学习改进算法详解
基于 Levenberg - Marquardt 法的 BP 网络学习改进算法详解
一、引言
BP(Back Propagation)神经网络在众多领域有着广泛应用,但传统 BP 算法存在收敛速度慢、易陷入局部最优等问题。Levenberg - Marquardt(LM)算法作为一种有效的优化算法,被应用于改进 BP 网络学习,能够显著提高训练效率和网络性能。本文将深入阐述基于 Levenberg - Marquardt 法的 BP 网络学习改进算法,包括其原理、实现步骤和详细的代码示例。
二、传统 BP 网络学习算法回顾
(一)网络结构与前向传播
BP 神经网络一般由输入层、隐藏层和输出层构成。设输入层有 n n n 个神经元,输入向量为 x = ( x 1 , x 2 , ⋯ , x n ) \mathbf{x}=(x_1,x_2,\cdots,x_n) x=(x1,x2,⋯,xn);隐藏层有 m m m 个神经元,输出向量为 h = ( h 1 , h 2 , ⋯ , h m ) \mathbf{h}=(h_1,h_2,\cdots,h_m) h=(h1,h2,⋯,hm);输出层有 p p p 个神经元,输出向量为 y = ( y 1 , y 2 , ⋯ , y p ) \mathbf{y}=(y_1,y_2,\cdots,y_p) y=(y1,y2,⋯,yp)。
在前向传播过程中,对于输入层到隐藏层,隐藏层神经元的输入为:
n e t j = ∑ i = 1 n w i j 1 x i + b j 1 net_{j}=\sum_{i = 1}^{n}w_{ij}^{1}x_{i}+b_{j}^{1} netj=∑i=1nwij1xi+bj1
其中, w i j 1 w_{ij}^{1} wij1 是输入层到隐藏层的连接权重, b j 1 b_{j}^{1} bj1 是隐藏层的偏置。隐藏层神经元的输出通常经过激活函数(如 Sigmoid 函数 h j = 1 1 + e − n e t j h_{j}=\frac{1}{1 + e^{-net_{j}}} hj=1+e−netj1)处理。
从隐藏层到输出层,输出层神经元的输入为:
u k = ∑ j = 1 m w j k 2 h j + b k 2 u_{k}=\sum_{j = 1}^{m}w_{jk}^{2}h_{j}+b_{k}^{2} uk=∑j=1mwjk2hj+bk2
输出层神经元的输出 y k = 1 1 + e − u k y_{k}=\frac{1}{1 + e^{-u_{k}}} yk=1+e−uk1(这里以 Sigmoid 函数为例)。
(二)误差计算与反向传播
对于训练样本集 { ( x ( μ ) , t ( μ ) ) } μ = 1 N \{(\mathbf{x}^{(\mu)},\mathbf{t}^{(\mu)})\}_{\mu = 1}^{N} {(x(μ),t(μ))}μ=1N,其中 x ( μ ) \mathbf{x}^{(\mu)} x(μ) 是第 μ \mu μ 个输入样本, t ( μ ) \mathbf{t}^{(\mu)} t(μ) 是对应的目标输出。常用的误差函数是均方误差:
E = 1 2 ∑ μ = 1 N ∑ k = 1 p ( y k ( μ ) − t k ( μ ) ) 2 E=\frac{1}{2}\sum_{\mu = 1}^{N}\sum_{k = 1}^{p}(y_{k}^{(\mu)}-t_{k}^{(\mu)})^{2} E=21∑μ=1N∑k=1p(yk(μ)−tk(μ))2
在反向传播过程中,根据误差函数对权重的梯度来更新权重。以输出层到隐藏层的权重 w j k 2 w_{jk}^{2} wjk2 为例,其梯度计算为:
∂ E ∂ w j k 2 = ∑ μ = 1 N ( y k ( μ ) − t k ( μ ) ) y k ( μ ) ( 1 − y k ( μ ) ) h j ( μ ) \frac{\partial E}{\partial w_{jk}^{2}}=\sum_{\mu = 1}^{N}(y_{k}^{(\mu)}-t_{k}^{(\mu)})y_{k}^{(\mu)}(1 - y_{k}^{(\mu)})h_{j}^{(\mu)} ∂wjk2∂E=∑μ=1N(yk(μ)−tk(μ))yk(μ)(1−yk(μ))hj(μ)
然后根据梯度下降法更新权重:
w j k 2 ( t + 1 ) = w j k 2 ( t ) − η ∂ E ∂ w j k 2 w_{jk}^{2}(t + 1)=w_{jk}^{2}(t)-\eta\frac{\partial E}{\partial w_{jk}^{2}} wjk2(t+1)=wjk2(t)−η∂wjk2∂E
其中, η \eta η 是学习率, t t t 表示训练次数。类似地,可以计算输入层到隐藏层的权重更新公式。
三、传统 BP 算法的问题分析
(一)收敛速度问题
- 学习率的影响
在传统 BP 算法中,学习率的选择至关重要且困难。若学习率过大,权重更新可能会过度,导致网络在误差曲面上跳过最小值点,甚至使训练过程发散;若学习率过小,权重更新缓慢,需要大量的训练迭代才能使误差降低到可接受的水平,尤其在处理复杂的高维数据或复杂函数逼近问题时,收敛速度会非常慢。 - 梯度下降的局限性
传统 BP 基于梯度下降方法,每次权重更新仅沿着当前梯度的负方向进行。在复杂的误差曲面中,如存在狭长的峡谷或平坦区域,梯度方向可能并不直接指向全局最小值,这会导致在这些区域收敛效率低下。
(二)局部最优问题
由于传统 BP 算法沿着梯度下降方向更新权重,容易陷入局部最优解。在误差曲面中,当达到局部最优点时,梯度为零或接近零,此时权重更新停止,但这个局部最优点可能并非全局最优解,使得网络的性能无法进一步提升。
四、Levenberg - Marquardt 法原理
(一)基本思想
Levenberg - Marquardt 法是一种结合了梯度下降法和牛顿法优点的优化算法。它在接近最优解时具有牛顿法的二次收敛速度,在远离最优解时表现得像梯度下降法一样稳定。
对于目标函数 E ( w ) E(\mathbf{w}) E(w)(这里 w \mathbf{w} w 表示网络的所有权重和偏置组成的向量),牛顿法的迭代公式为:
w t + 1 = w t − [ ∇ 2 E ( w t ) ] − 1 ∇ E ( w t ) \mathbf{w}^{t + 1}=\mathbf{w}^{t}-[\nabla^{2}E(\mathbf{w}^{t})]^{-1}\nabla E(\mathbf{w}^{t}) wt+1=wt−[∇2E(wt)]−1∇E(wt)
其中, ∇ E ( w t ) \nabla E(\mathbf{w}^{t}) ∇E(wt) 是目标函数在 w t \mathbf{w}^{t} wt 处的梯度向量, ∇ 2 E ( w t ) \nabla^{2}E(\mathbf{w}^{t}) ∇2E(wt) 是目标函数在 w t \mathbf{w}^{t} wt 处的 Hessian 矩阵。然而,计算 Hessian 矩阵及其逆矩阵在实际中计算量很大。
Levenberg - Marquardt 法使用一个近似的 Hessian 矩阵。它将目标函数 E ( w ) E(\mathbf{w}) E(w) 在当前点 w t \mathbf{w}^{t} wt 处进行二阶泰勒展开:
E ( w ) ≈ E ( w t ) + ∇ E ( w t ) T ( w − w t ) + 1 2 ( w − w t ) T H ( w − w t ) E(\mathbf{w})\approx E(\mathbf{w}^{t})+\nabla E(\mathbf{w}^{t})^{T}(\mathbf{w}-\mathbf{w}^{t})+\frac{1}{2}(\mathbf{w}-\mathbf{w}^{t})^{T}\mathbf{H}(\mathbf{w}-\mathbf{w}^{t}) E(w)≈E(wt)+∇E(wt)T(w−wt)+21(w−wt)TH(w−wt)
其中, H \mathbf{H} H 是对 Hessian 矩阵的近似。在 LM 算法中,这个近似的 Hessian 矩阵为:
H = J T J + λ I \mathbf{H}=\mathbf{J}^{T}\mathbf{J}+\lambda\mathbf{I} H=JTJ+λI
其中, J \mathbf{J} J 是雅可比矩阵,它的元素是误差函数对权重的一阶偏导数, λ \lambda λ 是一个可调参数, I \mathbf{I} I 是单位矩阵。当 λ \lambda λ 很大时,算法接近梯度下降法;当 λ \lambda λ 很小时,算法接近牛顿法。
(二)参数更新公式
权重更新公式为:
w t + 1 = w t − ( J T J + λ I ) − 1 J T e \mathbf{w}^{t + 1}=\mathbf{w}^{t}-(\mathbf{J}^{T}\mathbf{J}+\lambda\mathbf{I})^{-1}\mathbf{J}^{T}\mathbf{e} wt+1=wt−(JTJ+λI)−1JTe
其中, e \mathbf{e} e 是误差向量。通过调整 λ \lambda λ 的值,可以控制算法的收敛速度和稳定性。在每次迭代中,如果误差减小,则减小 λ \lambda λ;如果误差增大,则增大 λ \lambda λ。
五、基于 Levenberg - Marquardt 法的 BP 网络学习改进算法步骤
(一)初始化
- 网络参数初始化
初始化 BP 网络的权重和偏置,可将权重随机初始化为较小的值,例如在区间 [ − 0.5 , 0.5 ] [-0.5,0.5] [−0.5,0.5] 内。同时,初始化参数 λ \lambda λ(通常初始化为一个较小的值,如 0.01)、雅可比矩阵 J \mathbf{J} J(初始化为相应大小的零矩阵)和其他相关变量。 - 训练参数初始化
设置训练的相关参数,如最大训练次数、误差阈值等,用于控制训练过程的终止条件。
(二)训练过程
- 前向传播
对于每个训练样本,按照传统 BP 算法的前向传播方式计算网络的输出。 - 误差计算与雅可比矩阵计算
计算当前样本的误差向量 e \mathbf{e} e,并通过反向传播计算雅可比矩阵 J \mathbf{J} J。雅可比矩阵的计算涉及到误差函数对每个权重的偏导数。 - 近似 Hessian 矩阵构建与权重更新
根据当前的雅可比矩阵 J \mathbf{J} J 和参数 λ \lambda λ,构建近似 Hessian 矩阵 H = J T J + λ I \mathbf{H}=\mathbf{J}^{T}\mathbf{J}+\lambda\mathbf{I} H=JTJ+λI。然后,求解线性方程组 ( J T J + λ I ) Δ w = J T e (\mathbf{J}^{T}\mathbf{J}+\lambda\mathbf{I})\Delta\mathbf{w}=\mathbf{J}^{T}\mathbf{e} (JTJ+λI)Δw=JTe,得到权重更新量 Δ w \Delta\mathbf{w} Δw,并更新网络的权重和偏置: w t + 1 = w t − Δ w \mathbf{w}^{t + 1}=\mathbf{w}^{t}-\Delta\mathbf{w} wt+1=wt−Δw。 - 参数调整
计算更新权重后的误差。如果误差减小,则减小 λ \lambda λ(例如, λ = λ / 10 \lambda=\lambda/10 λ=λ/10);如果误差增大,则增大 λ \lambda λ(例如, λ = 10 λ \lambda = 10\lambda λ=10λ)。 - 停止准则判断
检查是否满足停止准则,如达到最大训练次数或者当前误差小于设定的误差阈值。如果满足,则停止训练;否则,返回步骤 1 继续下一次迭代。
六、代码示例
以下是使用 Python 实现的基于 Levenberg - Marquardt 法的 BP 网络学习改进算法的代码示例:
import numpy as np# Sigmoid 激活函数
def sigmoid(x):return 1 / (1 + np.exp(-x))# Sigmoid 函数的导数
def sigmoid_derivative(x):return x * (1 - x)class NeuralNetwork:def __init__(self, input_size, hidden_size, output_size):self.input_size = input_sizeself.hidden_size = hidden_sizeself.output_size = output_size# 随机初始化权重self.W1 = np.random.rand(self.input_size, self.hidden_size)self.b1 = np.zeros((1, self.hidden_size))self.W2 = np.random.rand(self.hidden_size, self.output_size)self.b2 = np.zeros((1, self.output_size))self.lambda_value = 0.01 # 初始lambda值def forward_propagation(self, X):self.z1 = np.dot(X, self.W1) + self.b1self.a1 = sigmoid(self.z1)self.z2 = np.dot(self.a1, self.W2) + self.b2self.a2 = sigmoid(self.z2)return self.a2def back_propagation(self, X, y):m = X.shape[0]dZ2 = (self.a2 - y) * sigmoid_derivative(self.z2)dW2 = np.dot(self.a1.T, dZ2)db2 = np.sum(dZ2, axis=0, keepdims=True)dZ1 = np.dot(dZ2, self.W2.T) * sigmoid_derivative(self.z1)dW1 = np.dot(X.T, dZ1)db1 = np.sum(dZ1, axis=0, keepdims=True)return dW1, db1, dW2, db2def jacobian_matrix(self, X, y):m = X.shape[0]J = np.zeros((m * self.output_size, (self.input_size * self.hidden_size) + self.hidden_size + (self.hidden_size * self.output_size) + self.output_size))for i in range(m):sample_X = X[i].reshape(1, -1)sample_y = y[i].reshape(1, -1)dW1, db1, dW2, db2 = self.back_propagation(sample_X, sample_y)start_idx_W1 = 0end_idx_W1 = self.input_size * self.hidden_sizestart_idx_b1 = end_idx_W1end_idx_b1 = end_idx_W1 + self.hidden_sizestart_idx_W2 = end_idx_b1end_idx_W2 = end_idx_b1 + self.hidden_size * self.output_sizestart_idx_b2 = end_idx_W2end_idx_b2 = end_idx_W2 + self.output_sizeJ[i * self.output_size:(i + 1) * self.output_size, start_idx_W1:end_idx_W1] = dW1.flatJ[i * self.output_size:(i + 1) * self.output_size, start_idx_b1:end_idx_b1] = db1.flatJ[i * self.output_size:(i + 1) * self.output_size, start_idx_W2:end_idx_W2] = dW2.flatJ[i * self.output_size:(i + 1) * self.output_size, start_idx_b2:end_idx_b2] = db2.flatreturn Jdef levenberg_marquardt_update(self, X, y):output = self.forward_propagation(X)error = output - yJ = self.jacobian_matrix(X, y)H = np.dot(J.T, J) + self.lambda_value * np.eye(J.shape[1])gradient = np.dot(J.T, error.flat)update_vector = np.linalg.solve(H, gradient)self.W1 -= update_vector[:self.input_size * self.hidden_size].reshape(self.input_size, self.hidden_size)self.b1 -= update_vector[self.input_size * self.hidden_size:self.input_size * self.hidden_size + self.hidden_size].reshape(1, self.hidden_size)self.W2 -= update_vector[self.input_size * self.hidden_size + self.hidden_size:self.input_size * self.hidden_size + self.hidden_size + self.hidden_size * self.output_size].reshape(self.hidden_size, self.output_size)self.b2 -= update_vector[self.input_size * self.hidden_size + self.hidden_size + self.hidden_size * self.output_size:].reshape(1, self.output_size)new_error = np.mean((self.forward_propagation(X) - y) ** 2)old_error = np.mean((output - y) ** 2)if new_error < old_error:self.lambda_value = self.lambda_value / 10else:self.lambda_value = self.lambda_value * 10def train(self, X, y, epochs):for epoch in range(epochs):self.levenberg_marquardt_update(X, y)if epoch % 100 == 0:output = self.forward_propagation(X)error = np.mean((output - y) ** 2)print(f'Epoch {epoch}: Error = {error}, Lambda = {self.lambda_value}')
以下是一个简单的测试示例:
# 示例用法
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [1], [1], [0]])
neural_network = NeuralNetwork(2, 3, 1)
neural_network.train(X, y, 1000)
七、总结
基于 Levenberg - Marquardt 法的 BP 网络学习改进算法通过巧妙地近似 Hessian 矩阵,结合了梯度下降法和牛顿法的优点。这种算法在 BP 网络训练中能够更快地收敛,并且在一定程度上减少了陷入局部最优解的可能性。代码示例详细展示了该算法在 Python 中的实现过程,在实际应用中,可以根据具体的问题和数据集进一步优化算法,如更精细地调整 λ \lambda λ 的调整策略、改进雅可比矩阵的计算方法等,以提高网络的训练效果和泛化能力。该算法在函数逼近、数据分类等需要高效训练神经网络的场景中具有重要的应用价值。
相关文章:

基于 Levenberg - Marquardt 法的 BP 网络学习改进算法详解
基于 Levenberg - Marquardt 法的 BP 网络学习改进算法详解 一、引言 BP(Back Propagation)神经网络在众多领域有着广泛应用,但传统 BP 算法存在收敛速度慢、易陷入局部最优等问题。Levenberg - Marquardt(LM)算法作…...

MySQL 8.0与PostgreSQL 15.8的性能对比
根据搜索结果,以下是MySQL 8.0与PostgreSQL 15.8的性能对比: MySQL 8.0性能特点: MySQL在处理大量读操作时表现出色,其存储引擎InnoDB提供了行级锁定和高效的事务处理,适用于并发读取的场景。MySQL通过查询缓存来提高读…...

qt连接postgres数据库时 setConnectOptions函数用法
连接选项,而这些选项没有直接的方法对应,你可能需要采用以下策略之一: 由于Qt SQL API的限制,你可能需要采用一些变通方法或查阅相关文档和社区资源以获取最新的信息和最佳实践。如果你确实需要设置特定的连接选项,并且…...

MySQL45讲 第二十七讲 主库故障应对:从库切换策略与 GTID 详解——阅读总结
文章目录 MySQL45讲 第二十七讲 主库故障应对:从库切换策略与 GTID 详解一、一主多从架构与主备切换的挑战(一)一主多从基本结构(二)主备切换的复杂性 二、基于位点的主备切换(一)同步位点的概念…...

JavaWeb笔记整理——Spring Task、WebSocket
目录 SpringTask cron表达式 WebSocket SpringTask cron表达式 WebSocket...

基于SpringBoot+RabbitMQ完成应⽤通信
前言: 经过上面俩章学习,我们已经知道Rabbit的使用方式RabbitMQ 七种工作模式介绍_rabbitmq 工作模式-CSDN博客 RabbitMQ的工作队列在Spring Boot中实现(详解常⽤的⼯作模式)-CSDN博客作为⼀个消息队列,RabbitMQ也可以⽤作应⽤程…...
debug运行生成的项目,不能手动点击运行)
Flutter踩坑记录(一)debug运行生成的项目,不能手动点击运行
问题 IOS14设备,切后台划掉,二次启动崩溃。 原因 IOS14以上 flutter 不支持debugger模式下的二次启动 。 要二次启动需要以release方式编译工程安装至手机。 操作步骤 清理项目:在命令行中运行flutter clean来清理之前的构建文件。重新构…...

React的hook✅
为什么hook必须在组件内的顶层声明? 这是为了确保每次组件渲染时,Hooks 的调用顺序保持一致。React利用 hook 的调用顺序来跟踪各个 hook 的状态。每当一个函数组件被渲染时,所有的 hook 调用都是按照从上到下的顺序依次执行的。React 内部会…...

2024.5 AAAiGLaM:通过邻域分区和生成子图编码对领域知识图谱对齐的大型语言模型进行微调
GLaM: Fine-Tuning Large Language Models for Domain Knowledge Graph Alignment via Neighborhood Partitioning and Generative Subgraph Encoding 问题 如何将特定领域知识图谱直接整合进大语言模型(LLM)的表示中,以提高其在图数据上自…...
)
从熟练Python到入门学习C++(record 6)
基础之基础之最后一节-结构体 1.结构体的定义 结构体相对于自定义的一种新的变量类型。 四种定义方式,推荐第一种;第四种适合大量定义,也适合查找; #include <iostream> using namespace std; #include <string.h>…...

jenkins的安装(War包安装)
Jenkins是一个开源的持续集成工具,基于Java开发,主要用于监控持续的软件版本发布和测试项目。 它提供了一个开放易用的平台,使软件项目能够实现持续集成。Jenkins的功能包括持续的软件版本发布和测试项目,以及监控外部调用执行…...

WPS 加载项开发说明wpsjs
wpsjs几个常用的CMD命令: 1.打开cmd输入命令测试版本号 npm -v 2.首次安装nodejs,npm默认国外镜像,包下载较慢时,可切换到国内镜像 //下载速度较慢时可切换国内镜像 npm config set registry https://registry.npmmirror.com …...

【Anomaly Detection论文阅读记录】PaDiM与PatchCore模型的区别与联系
PaDiM与PatchCore模型的区别与联系 背景介绍 PADIM(Pretrained Anomaly Detection via Image Matching)和 PatchCore 都是基于深度学习的异常检测方法,主要用于图像异常检测,尤其是在无监督学习设置下。 PADIM 是一种通过利用预训练的视觉模型(例如,ImageNet预训练的卷…...

uni-app Vue3语法实现微信小程序样式穿透uview-plus框架
1 问题描述 我在用 uni-app vue3 语法开发微信小程序时,在项目中使用了 uview-plus 这一开源 UI 框架。在使用 up-text 组件时,想要给它添加一些样式,之前了解到微信小程序存在样式隔离的问题,也在uview-plus官网-注意事项中找到…...

K8S基础概念和环境搭建
K8S的基础概念 1. 什么是K8S K8S的全称是Kubernetes K8S是一个开源的容器编排平台,用于自动化部署、扩缩、管理容器化应用程序。 2. 集群和节点 集群:K8S将多个机器统筹和管理起来,彼此保持通讯,这样的关系称之为集群。 节点…...

[服务器] 腾讯云服务器免费体验,成功部署网站
文章目录 概要整体架构流程概要 腾讯云服务器免费体验一个月。 整体架构流程 腾讯云服务器体验一个月, 选择预装 CentOS 7.5 首要最重要的是: 添加阿里云镜像。 不然国外源速度慢, 且容易失败。 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/li…...

vue中el-select 模糊查询下拉两种方式
第一种:先获取所有下拉数据再模糊查询,效果如下 1,页面代码:speciesList是种类列表List, speciesId 是speciesList里面对应的id,filterable是过滤查询标签 <el-form-item label"种类" prop"species…...

深入解析PostgreSQL中的PL/pgSQL语法
在数据库管理系统中,PostgreSQL因其强大的功能和稳定性而受到广泛欢迎。其中,PL/pgSQL作为PostgreSQL的过程化语言,为用户提供了更为灵活和强大的编程能力。本文将深入解析PL/pgSQL的语法,帮助读者更好地掌握这门语言,…...
Vue 3集成海康Web插件实现视频监控
🌈个人主页:前端青山 🔥系列专栏:组件封装篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来组件封装篇专栏内容:Vue 3集成海康Web插件实现视频监控 引言 最近在项目中使用了 Vue 3 结合海康Web插件来实…...

多目标优化算法:多目标蛇鹫优化算法(MOSBOA)求解DTLZ1-DTLZ9,提供完整MATLAB代码
一、蛇鹫优化算法 蛇鹫优化算法(Secretary Bird Optimization Algorithm,简称SBOA)由Youfa Fu等人于2024年4月发表在《Artificial Intelligence Review》期刊上的一种新型的元启发式算法。该算法旨在解决复杂工程优化问题,特别是…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...
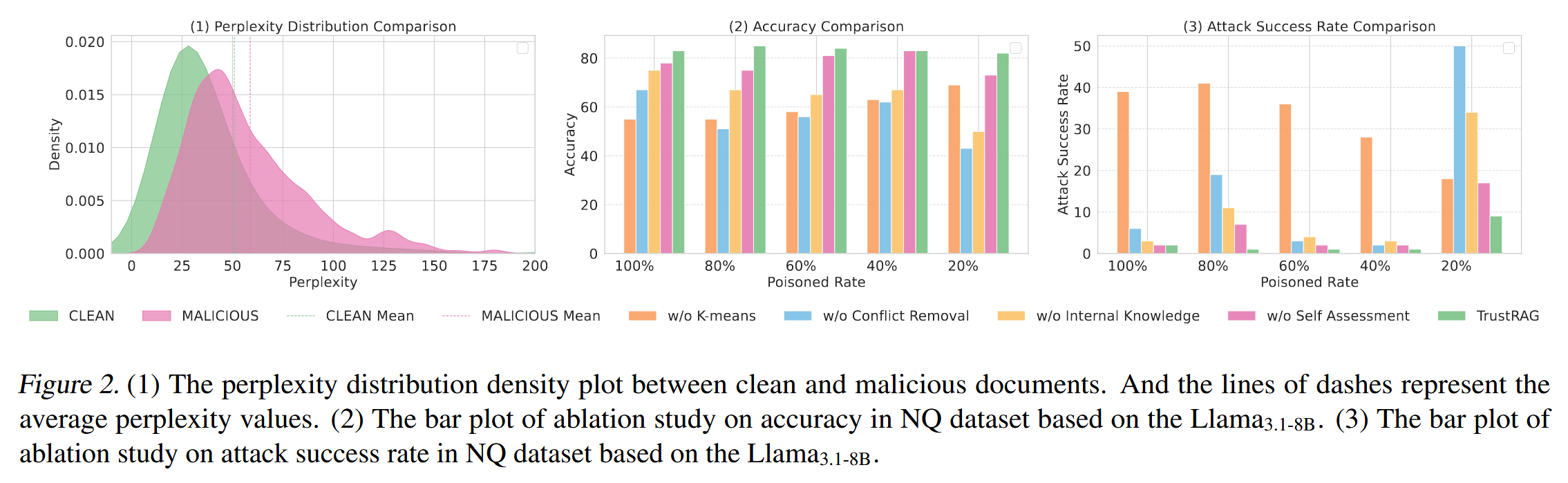
[论文阅读]TrustRAG: Enhancing Robustness and Trustworthiness in RAG
TrustRAG: Enhancing Robustness and Trustworthiness in RAG [2501.00879] TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation 代码:HuichiZhou/TrustRAG: Code for "TrustRAG: Enhancing Robustness and Trustworthin…...
QT开发技术【ffmpeg + QAudioOutput】音乐播放器
一、 介绍 使用ffmpeg 4.2.2 在数字化浪潮席卷全球的当下,音视频内容犹如璀璨繁星,点亮了人们的生活与工作。从短视频平台上令人捧腹的搞笑视频,到在线课堂中知识渊博的专家授课,再到影视平台上扣人心弦的高清大片,音…...

Django RBAC项目后端实战 - 03 DRF权限控制实现
项目背景 在上一篇文章中,我们完成了JWT认证系统的集成。本篇文章将实现基于Redis的RBAC权限控制系统,为系统提供细粒度的权限控制。 开发目标 实现基于Redis的权限缓存机制开发DRF权限控制类实现权限管理API配置权限白名单 前置配置 在开始开发权限…...
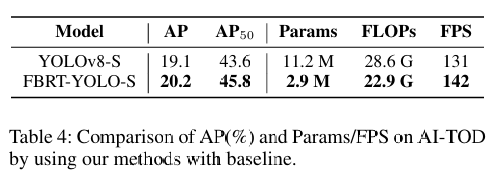
Yolo11改进策略:Block改进|FCM,特征互补映射模块|AAAI 2025|即插即用
1 论文信息 FBRT-YOLO(Faster and Better for Real-Time Aerial Image Detection)是由北京理工大学团队提出的专用于航拍图像实时目标检测的创新框架,发表于AAAI 2025。论文针对航拍场景中小目标检测的核心难题展开研究,重点解决…...