Logback实战指南:基础知识、实战应用及最佳实践全攻略
背景
在Java系统实现过程中,我们不可避免地会借助大量开源功能组件。然而,这些组件往往功能丰富且体系庞大,官方文档常常详尽至数百页。而在实际项目中,我们可能仅需使用其中的一小部分功能,这就造成了一个挑战:如何在有限的时间和精力下,高效地掌握并使用这些组件的核心功能,以实现投入产出最大化?
针对这一问题,我基于二八原则,整理编写本文。
首先,我会聚焦于组件的常见和核心功能,这些功能通常是我们在日常开发中频繁使用到的,也是构建稳定、高效系统的基石。通过深入了解这些核心功能的使用方法和最佳实践,我们可以确保在关键点上投入足够的精力,从而避免在实际使用中掉入陷阱。
其次,我会以问题为导向,将实用性作为第一要素,对组件的功能进行筛选和整理。这意味着我会优先关注那些在项目中实际需要用到的功能,而对于那些特定场景下才会用到的功能,我会在文中提及但不做详细展开。这样做的好处是,我们可以在保证核心功能得到充分理解的同时,减少不必要的阅读负担,提高学习效率,降低投入成本。
最后,我会注重内容的精炼和易读性。通过简明扼要的文字描述和直观的示例代码,帮助读者快速理解并掌握组件的核心用法。
同时,我也会结合经验指出常见的问题和注意事项,以便读者在使用过程中能够规避一些常见的错误和陷阱。
综上所述,通过这个系列的内容整理,我希望能够帮助读者在有限的时间和精力下,高效地掌握并使用这些开源功能组件的核心功能,满足系统实现的需要。
注:部分内容章节由AI辅助生成草稿,我对其进行了复核和修订,修复了有问题和有错误的部分。
理论
日志有什么用?
在Java开发中,日志记录是一个不可或缺的部分。它能帮助我们了解程序的运行状态,追踪和定位代码中的错误。特别是在生产环境异常排查,日志是非常重要的手段,甚至某些情况下是唯一的途径。
日志级别有哪些?
在Java开发中,日志级别是一个重要的概念。
常见的日志级别由低到高分别为TRACE、DEBUG、INFO、WARN、ERROR和FATAL。
每个级别都对应着不同的日志输出内容和场景。
例如,TRACE级别通常用于记录详细的程序执行流程,而ERROR级别则用于记录程序运行时的错误信息。
主流的日志组件有哪些?
日志功能具有通用性,与具体的业务系统无关,因此诞生了众多的日志组件,我们不需要也不应该去重复“造轮子”,而是拿来使用。
在选择和集成日志组件时,我们需要考虑组件的性能、稳定性以及兼容性等因素。当前主流在使用的日志组件主要有两个,一是logback,二是log4j2。这些组件都提供了丰富的功能和灵活的配置选项,可以根据项目的需求进行选择。
什么是日志门面?
虽然我们也可以直接使用上面说的logback或log4j2,但更好的方式是使用日志门面组件。
在Java中,SLF4J(Simple Logging Facade for Java)是一个为Java程序提供日志输出的简单门面或抽象层。它提供了一套统一的日志接口,使得开发者可以无需关心具体日志实现,并可以轻松切换日志组件。
注:这里虽然称之为门面,但使用到的设计模式并不是门面模式,而是适配器模式。
SLF4J的主要特点和优势是什么?
SLF4J的主要特点和优势包括:
统一的日志接口:SLF4J为各种日志组件提供了统一的调用方式,从而简化了日志记录的过程。
灵活性:由于SLF4J是一个抽象层,它可以与多种日志实现组件(如Logback、Log4j2等)集成。这意味着即使更改底层日志实现,应用程序代码也不需要做出任何更改。
参数化日志:SLF4J提供了参数化日志功能,这有助于减少字符串拼接操作,从而提高了日志记录的效率。
易于使用和学习:SLF4J的API设计得相对简洁,降低了学习成本,并且无需复杂的配置。
SLF4J的应用场景有哪些?
在项目中,SLF4J的应用场景包括但不限于:
为开发者提供统一的日志接口,减少开发过程中的代码侵入性。
结合不同的日志组件实现对日志进行定制输出。
替换不同的日志组件,使得日志输出更易于管理和控制。
SLF4J是一个非常有用的工具,它可以帮助开发人员更好地管理和记录应用程序的日志。
实战
如何引入SLF4J?
在Maven项目中,你可以在pom.xml文件中添加依赖:
<dependencies><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.30</version></dependency>
</dependencies>
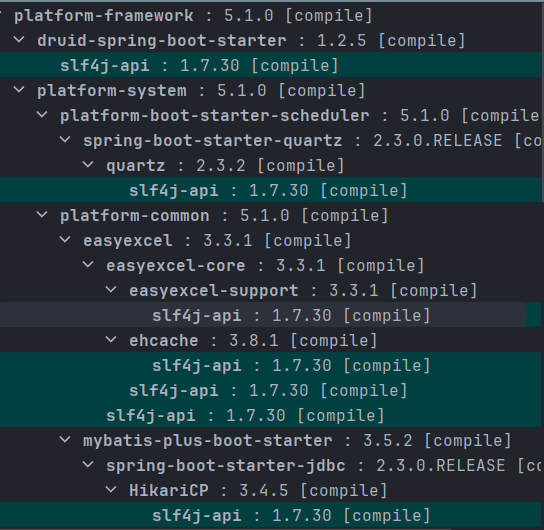
实际上,因为SLF4J应用非常广泛,大量的功能组件、中间件都使用并已经引入了它,所以通常不再需要单独引入,如下图所示,druid、easyexcel、mybatisplus都使用到了slf4j。
如何引入logback?
前文说过,slf4j只是接口定义而不是实现,日志功能需要具体的日志组件logback或log4j2等来实现。
以logback为例,在slf4j已添加的情况下,引入如下包:
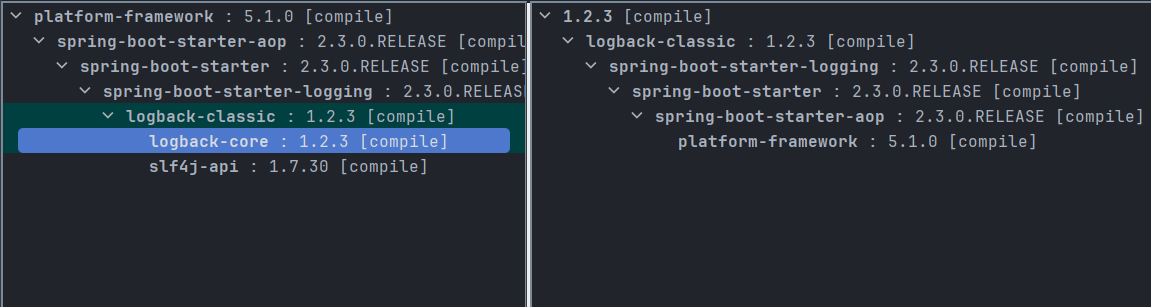
<dependencies><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.3</version></dependency>
</dependencies>
注意,因为SpringBoot 2.x版本默认使用的日志组件就是logback,所以引入包的操作也省了。
如何记录日志?
在引入slf4j和logback后,就可以按照以下方式来记录日志了。
public class PlatformBootApplication {private static final Logger logger = LoggerFactory.getLogger(PlatformBootApplication.class);public static void main(String[] args) {logger.info("当前时间: {}", System.currentTimeMillis());}
}
上面这种方式,需要在每个类中通过LoggerFactory构造一个logger对象,并且需要将当前类名传入,一方面比较繁琐;另一方面,从别的类中粘贴过来后容易忘记修改类名,结果就是日志输出的来源出现张冠李戴。
更简便的方法,是结合lombok注解使用,在类名上直接添加@slf4j注解,然后直接调用log.info即可。
@Slf4j
public class PlatformBootApplication {public static void main(String[] args) {log.info("当前时间: {}", System.currentTimeMillis());}
}
运行程序,控制台输出如下:
16:09:03.823 [main] INFO tech.abc.platform.boot.PlatformBootApplication - 当前时间: 1718093343816
如何进行配置?
前文我们通过logback在开发环境的控制台输出了info信息,使用的实际是logback的默认配置。
在实际使用过程中,特别是生产环境,我们需要对日志输出进行定制化,包括日志输出的格式、日志的级别、输出到哪(文件、控制台)……这就需要进行配置了。
logback的默认配置文件查找顺序是在类路径下依次查找logback.groovy、logback-test.xml、logback.xml文件。
在springboot项目的resources目录下新建一个logback.xml文件,我们来进一步做日志输出的定制化。
如何配置输出到控制台?
使用IDE开发时,输出到控制台是最常用的功能,配置也是最简单的,以此为例我们来说下配置。
先上一份配置:
<?xml version="1.0" encoding="UTF-8"?>
<configuration><!--控制台日志输出--><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><!--格式及编码--><encoder><pattern>%d{HH:mm:ss.SSS} %-5level [%-5thread] %logger - %msg%n</pattern><charset>utf-8</charset></encoder></appender><!-- 输出 --><root level="INFO"><appender-ref ref="STDOUT"/></root>
</configuration>
日志功能组件中,负责输出的称之为appender,用来进行定制化配置。
然后root节点来做全局管理,启用哪些输出,以及输出的最低日志级别。
如何控制输出日志的格式?
appender的encoder 部分的pattern属性设置日志输出的格式,包括时间戳、日志级别、线程名、logger名、日志消息等,需要按照规范来写。
这些格式项具有特定的约定,用来控制输出日志的样式和内容。
以下是一些常用的格式项及其意义:
%d{HH:mm:ss.SSS}:表示日期时间格式,其中HH小时、mm分钟、ss秒、SSS毫秒。
%-5level:日志级别,如DEBUG、INFO、WARN、ERROR等,-5表示左对齐并至少占用5个字符宽度。
[%-5thread]:当前线程名称,同样左对齐并至少占用5个字符宽度。
%logger{36} 或简写为 %logger:记录器(Logger)的名称,通常对应类名,{36}指定了最大长度为36个字符,超出部分省略。
%msg:日志消息本身。
%n:换行符。
其他可能用到但上述示例未包含的格式项还包括:
%r:自应用程序启动到创建该日志事件所经过的毫秒数。
%M:发出日志调用的方法名。
%F:发出日志调用的源文件名。
%L:发出日志调用的源文件中的行号。
%c 或 %C:完整的类名或仅类名(不包含包名)。
我们可以根据需要定制这些格式项来达到期望的日志输出格式。
将其调整如下:
<pattern>%d{HH:mm:ss.SSS} %-5level %r [%-5thread] %logger %M %F %L %C - %msg%n
</pattern>
控制台输入如下:
09:14:43.830 INFO 282 [main ] tech.abc.platform.boot.PlatformBootApplication main PlatformBootApplication.java 35 tech.abc.platform.boot.PlatformBootApplication - 当前时间: 1718154883827如何配置输出到文件?
系统开发调试环节,我们更关注即时结果,通常只需要将日志输出到控制台就行了。
系统部署到服务器后,无论是测试环境还是生产环境,我们都希望日志持久化,以文件的方式输出到磁盘,便于较长时间段的日志查看和分析。
我们增加一个appender,来将日志输出到文件。
<?xml version="1.0" encoding="UTF-8"?>
<configuration><!--控制台日志输出--><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><!--格式及编码--><encoder><pattern>%d{HH:mm:ss.SSS} %-5level [%-5thread] %logger - %msg%n</pattern><charset>utf-8</charset></encoder></appender><!-- 输出到文件 --><appender name="FILE" class="ch.qos.logback.core.FileAppender"><!-- 日志文件的路径 --><file>c:\logs\myApplication.log</file><!-- 设置追加模式 --><append>true</append><!-- 定义日志格式 --><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><!-- 全局配置 --><root level="INFO"><!--输出到控制台--><appender-ref ref="STDOUT"/><!--输出到文件--><appender-ref ref="FILE"/></root>
</configuration>
我们定义了一个名为FILE的appender,使用的类是FileAppender。
file节点指定输出日志文件的路径。
append属性指定追加模式,为true是在末尾追加,为false则会清空原内容,通常会设置为true。
encoder属性配置与前面控制台相同,与之不同的是我们把年月日给加上了。
启动应用,在磁盘上生成了日志文件,内容如下:

如何配置只输出指定级别的日志?
logback的默认配置是输出指定级别及以上的日志。
在上面的示例中,我们配置了日志级别时info,输出的日志文件中,不仅仅是info,warn和error也会输出。
在系统访问量比较大的情况下,info日志会输出大量内容,系统运维和异常排查时,我们往往只关注warn或error级别的日志,不希望info的大量内容混在其中形成干扰,如何做呢?
一种便捷的方式就是调整全局配置,将root节点的level属性调整为warn,此时所有的appender输出的最低级别日志就是warn,不过error也会输出,即warn和error日志还是输出到同一个文件中。此外,该调整是对所有appender生效,一定程度上也会影响开发测试环境希望输出info的设置。
如要实现精确的日志输出,则需要为appender配置filter,如下所示:
<appender name="FILE" class="ch.qos.logback.core.FileAppender"><!-- 此日志文件只记录warn级别的 --><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>warn</level><onMatch>ACCEPT</onMatch><onMismatch>DENY</onMismatch></filter><!-- 日志文件的路径 --><file>c:\logs\myApplication.log</file><!-- 设置追加模式 --><append>true</append><!-- 定义日志布局 --><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder>
</appender>
将level设置为warn,注意,只做这一步没用,会显示root定义的级别以上所有日志,还需要进一步配置下面两个属性。
onMatch代表匹配时接受,只配这一个属性,会显示warn级别以上的所有日志。
onMismatch设置为不匹配时拒绝,最终结果就是只会记录warn这一种类型的日志,不会有更高级别的error也混进来。
这时候停下来想一想,如果我们想只输出warn日志,是不是只配置onMismatch为DENY就可以了,并不需要配置onMatch为ACCEPT?
动手尝试了下,果然是这样。
总结下过滤器的用法:
只设置level没有任何用处。
设置onMismatch为DENY,可以只输出该级别的日志。
设置onMatch为ACCEPT,可以输出该级别及其以上的日志。
日志需要保留多久?
这不是一个技术问题,而是一个管理问题。
客观地说,日志具有一定时效性,几乎没有查看1个月以前的日志的需求,因此长时间保留意义不大。一般情况下,一周左右的日志就能满足大多数场景下系统异常问题的排查需要了。某些特殊业务场景或监管要求下,如重要的业务系统,需要保留操作痕迹用于审计,会要求保留一个月甚至3个月等长时间段的日志。
如何解决日志过大的问题?
通过上面的操作,我们把日志输出到一个文件中,新日志记录会追加到文件末尾。随着时间的累积,会带来两个问题,一是日志文件越来越大,从最初的几兆增加到数百兆甚至于好几个G,此时查看日志打开速度会很慢,以致于普通的文本编辑器都没法打开,搜索指定内容也难以实现,更不用说分析了;二是因为日志的膨胀,可能会占用大量的磁盘空间,进而导致磁盘空间耗尽引发应用系统异常、卡顿甚至宕机。
解决思路也有多个,最简单的就是人工定期清理,缺点就是带来了额外的运维工作量,且容易发生因疏忽导致的工作漏做。在这基础上可以做成自动化,通过定时任务+脚本或开发来实现清理。
实际上,最佳的实践是配置logback来实现滚动日志,新日志自动覆盖旧日志。
如何配置日志滚动覆盖?
我们再新增一个滚动日志的appender,如下:
<!-- 滚动日志 -->
<appender name="FILE_ROLLING" class="ch.qos.logback.core.rolling.RollingFileAppender"><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>INFO</level></filter><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!-- 按天滚动覆盖 --><fileNamePattern>c:\logs\info\%d{yyyy-MM-dd}.%i.log</fileNamePattern><maxHistory>5</maxHistory><maxFileSize>1KB</maxFileSize></rollingPolicy><!-- 设置追加模式 --><append>true</append><!-- 定义日志布局 --><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder>
</appender>
与普通文件日志相比,实现类发生了变化,由FileAppender变更为RollingFileAppender。
然后增加了滚动策略的配置:
SizeAndTimeBasedRollingPolicy,用于控制日志文件的滚动和管理,基于文件大小和时间两个维度来复合控制。
元素指定了日志文件的命名规则,%d{yyyy-MM-dd}.%i.log表示按日期进行回滚,每天生成一个新文件,文件名格式为yyyy-MM-dd.log,其中%i表示按大小进行滚动的索引编号。
元素指定了保留的历史日志文件的最大天数,这里设置为5,意味着只会保留最近5天的日志文件,旧的日志文件将会被删除。
元素指定了每个日志文件的最大体积,这里设置为1KB,当单个日志文件的体积超过1KB时,将会生成新的日志文件进行滚动。
上面的配置定义了一个基于大小和时间的滚动策略,用于按天回滚日志文件,并限制了历史日志文件的保留天数和单个日志文件的大小。
注意:这里有个误区,以为maxHistory是设定日志文件的数量,实际是日志天数。
上面为了测试效果,我设置了很小的值,输出如下:
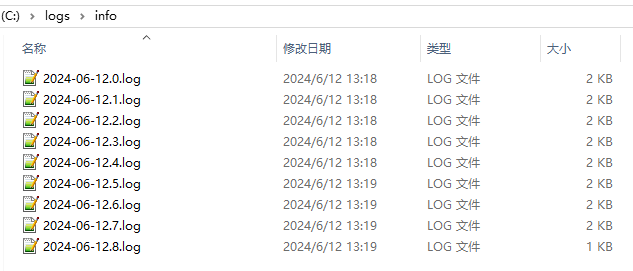
文件数量明显超出了5个。
至于设置了1KB,实际2KB,这是操作系统的估算而已。
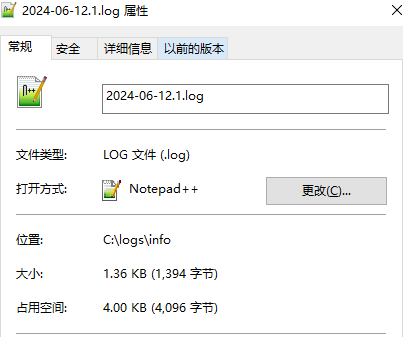
正常使用也不会设置单日志文件限制大小1KB,可忽略。
如何严格控制日志的磁盘占用?
从上面测试结果来看,实际仍有可能发生某一天因为系统异常产生了大量日志,导致磁盘耗尽的可能性,如何来解决呢?
实际logback提供了多种滚动策略,上面SizeAndTimeBasedRollingPolicy是基于大小和时间两个维度复合控制,还有两个类,分别实现基于大小和基于时间单个维度来控制。
基于时间的滚动策略 (TimeBasedRollingPolicy):
允许根据时间(如每小时、每天)滚动日志文件。
通过配置滚动后的文件名格式,例如%d{yyyy-MM-dd}.log表示每天生成一个新日志文件。
基于大小的滚动策略 (SizeBasedTriggeringPolicy):
当日志文件达到指定大小时触发滚动。
需要与其他滚动策略结合使用,比如与时间策略一起确保文件不会无限增长。
另有两个策略,分别是固定窗口滚动策略 (FixedWindowRollingPolicy) 和 滚动计数器策略 (RollingFixedWindowTriggeringPolicy)。
这两个策略常一起使用,基于固定窗口大小(如每10个文件一组)进行滚动。
不直接指定文件大小或时间,而是通过窗口和计数器控制文件数量。
来个实例:
<appender name="FILE_ROLLING_FIXED_WINDOW" class="ch.qos.logback.core.rolling.RollingFileAppender"><!-- 定义日志文件路径及基础文件名 --><file>c:\logs\app\app.log</file><!-- 使用固定窗口滚动策略 --><rollingPolicy class="ch.qos.logback.core.rolling.FixedWindowRollingPolicy"><!-- 指定窗口大小,比如每5个文件一组 --><minIndex>1</minIndex><maxIndex>5</maxIndex><!-- 文件命名模式,%i 代表窗口索引 --><fileNamePattern>c:\logs\app\app.%i.log</fileNamePattern></rollingPolicy><!-- 配合使用的滚动计数器策略,定义何时触发滚动 --><triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy"><!-- 每个日志文件最大大小 --><maxFileSize>1KB</maxFileSize></triggeringPolicy><!-- 日志内容格式化 --><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder><!-- 设置追加模式 --><append>true</append></appender>
启动应用,运行效果如下:
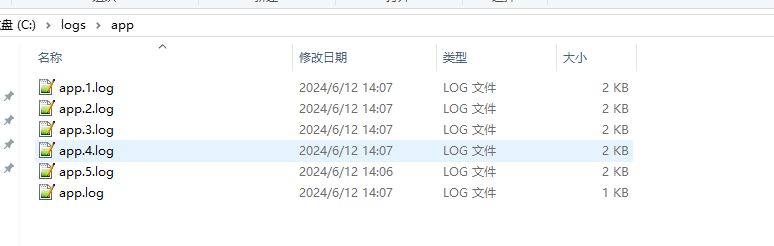
查看日志内容,发现app.1.log里的时间要晚于app.5.log里的时间,说明已经发生了日志覆盖情况,符合预期。
注意,除了编号1-5的日志外,还有一个无编号的本尊。在这种配置模式下,去除 c:\logs\app\app.log配置通不过logback验证。
进一步测试,发现情况有了变化,如下图:

日志大小超出了我们设置的1KB,推测是因为我们日志大小设置的值过小,而logback出于性能考虑,往往会分批往磁盘里写日志,每批次远大于1KB,这个值设置成5M或者更大,则不会存在问题。
通过固定窗口滚动策略+滚动计数器策略这两个组合,我们就能严格限定日志单个大小上限以及日志总个数,比如设置单个日志文件不能超出10M,日志文件最大为20个,那么占用磁盘空间上限就是(20+1)*10=210M。
另外你可能也想到了这种方式的一个弊端,就是异常情况下如产生了大量日志,新日志会覆盖旧日志,有可能造成你想查看问题发生初期甚至昨天的日志,因为被覆盖而无法实现的问题。
还有一个小问题,就是我们日常往往不会主动去查看日志,而是收到了系统异常反馈后,才会根据日志排查,这时基本可以确定异常发生的时间范围,而上述配置产生的日志通过文件名是无法确定相应的日志在哪个文件里(文件修改时间可以提供一定的参考),往往需要打开多个日志文件才能定位。
如何使用变量?
配置过程中,有些值需要多次使用,例如上面例子中,日志文件路径及基础文件名,在滚动策略命名中也会用到,最好是将其定义成参数,一次定义,多次使用。如果需要修改,也只修改一个地方就好了,而不是到处找哪些地方用到,既麻烦,也容易遗漏。
logback是支持变量的,定义方式如下:
<property name="MAX_SIZE" value="10MB"/>
使用方式如下:
<maxFileSize>${MAX_SIZE}</maxFileSize>
如何避免写日志操作影响业务处理?
默认配置下,写日志操作跟业务处理是在同一个进程(或线程)中的,在系统负荷大,特别是高并发情况下,写日志操作对系统性能还是有一定影响。
通常日志的重要性要远低于业务处理,所以我们可以采用异步方式。
logback自身支持异步,需要配置如下:
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender"><!-- 设置异步日志队列的大小为1000,即最多可以缓存1000个日志事件 --><queueSize>1000</queueSize><!-- 设置丢弃阈值为0,表示当队列满时不会丢弃任何日志事件 --><discardingThreshold>0</discardingThreshold><!-- 设置为true,表示当队列满时,写入日志的操作不会被阻塞,而是直接返回 --><neverBlock>true</neverBlock><!-- 引用的appender将作为异步日志输出的目标,即实际输出日志的地方 --><appender-ref ref="SOME_OTHER_APPENDER"/></appender>
实际上,就是定义一个异步的appender,然后使用appender-ref指向默认或者说同步的appender就好了,类似于套接了一层,是不是很灵活?记得最后在全局配置root节点下,启用的是这个异步appender,而不是原先的被套接的appender。
注意,异步日志的配置有坑点,下面来具体说一下。
queueSize是日志队列长度,底层实现是BlockingQueue,默认长度是256,设置过大有可能造成OOM。
discardingThreshold的默认设置是queueSize的20%,队列长1000,默认就是200,这个参数什么意思呢?
就是当队列中剩余的容量不足200时,会丢弃掉info级别及以下的日志。设置为0则代表永不丢弃。
AsyncAppender的异步机制的出现本来就是优化日志阻塞问题的,但是使用不当反而容易出现阻塞问题。
neverBlock的默认值是false,当队列满了的时候**或剩余容量达到阈值discardingThreshold就会出现阻塞问题**。设置为true时,明面上代表永不堵塞业务处理,实际意味着丢弃日志。
这三个参数实际是相互作用的,在具体项目中,需要好好权衡下取舍,是性能优先还是日志完整性优先。
如果性能排在首位,能接受一定的日志丢失,则将neverBlock设置为true。
如果完全不能接受日志丢失,需要将discardingThreshold 设置为0。
兼顾性能和日志不丢,将discardingThreshold 设置为0,把queueSize值设置的大一点。
所以异步日志一定注意合理配置,并且如果系统的并发访问量不大,也没必要启用异步日志。
典型配置什么样?
经过上述一步步从简单到复杂的探索,我们了解了logback的常用配置。
考虑到日志通常不会占用大量磁盘,而且服务器通常会有监控,磁盘不足时会进行报警。
从运维便利性角度考虑,我们采用的还是基于时间维度,限制单个文件大小的滚动覆盖的日志策略。
最终我们综合运用,输出一个典型配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration><!--设置系统日志目录--><property name="LOG_PATH" value="c:/logs/"/><!--设置应用日志目录--><property name="APP_DIR" value="platform"/><!--日志保留天数--><property name="MAX_HISTORY" value="30"/><!--单个日志最大体积--><property name="MAX_SIZE" value="10MB"/><!-- 仅错误日志 --><appender name="FILE_ERROR" class="ch.qos.logback.core.rolling.RollingFileAppender"><!-- 此日志文件只记录error级别的 --><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>error</level><onMismatch>DENY</onMismatch></filter><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!-- 按天滚动覆盖 --><fileNamePattern>${LOG_PATH}/${APP_DIR}/error/%d{yyyy-MM-dd}.%i.log</fileNamePattern><maxHistory>${MAX_HISTORY}</maxHistory><maxFileSize>${MAX_SIZE}</maxFileSize></rollingPolicy><!-- 追加方式记录日志 --><append>true</append><!-- 日志文件的格式 --><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger Line:%-3L - %msg%n</pattern><charset>utf-8</charset></encoder></appender><!-- 仅警告日志 --><appender name="FILE_WARN" class="ch.qos.logback.core.rolling.RollingFileAppender"><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>warn</level><onMismatch>DENY</onMismatch></filter><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!-- 按天滚动覆盖 --><fileNamePattern>${LOG_PATH}/${APP_DIR}/warn/%d{yyyy-MM-dd}.%i.log</fileNamePattern><maxHistory>${MAX_HISTORY}</maxHistory><maxFileSize>${MAX_SIZE}</maxFileSize></rollingPolicy><!-- 追加方式记录日志 --><append>true</append><!-- 日志文件的格式 --><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger Line:%-3L - %msg%n</pattern><charset>utf-8</charset></encoder></appender><!-- 所有日志 --><appender name="FILE_INFO" class="ch.qos.logback.core.rolling.RollingFileAppender"><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>info</level><onMatch>ACCEPT</onMatch></filter><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!-- 按天滚动覆盖 --><fileNamePattern>${LOG_PATH}/${APP_DIR}/info/%d{yyyy-MM-dd}.%i.log</fileNamePattern><maxHistory>${MAX_HISTORY}</maxHistory><maxFileSize>${MAX_SIZE}</maxFileSize></rollingPolicy><!-- 追加方式记录日志 --><append>true</append><!-- 日志文件的格式 --><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger Line:%-3L - %msg%n</pattern><charset>utf-8</charset></encoder></appender><!--控制台日志输出--><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><!--格式及编码--><encoder><pattern>%d{HH:mm:ss.SSS} %-5level [%-5thread] %logger - %msg%n</pattern><charset>utf-8</charset></encoder></appender><!-- 全局配置 --><root level="INFO"><!--仅错误日志--><appender-ref ref="FILE_ERROR"/><!--仅警告日志--><appender-ref ref="FILE_WARN"/><!--信息日志--><appender-ref ref="FILE_INFO"/><!--输出到控制台--><appender-ref ref="STDOUT"/></root>
</configuration>
上述配置将日志输出到两个地方,一个是控制台,STDOUT,用于开发环境;另外一个是磁盘文件,并且按日志级别进行了区分对待,单个日志文件不超过10M,按天滚动覆盖,最多不超过30天。
在配置的日志文件路径下,显示如下:
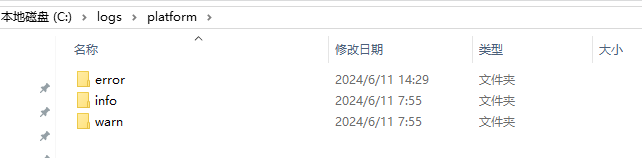
注意,以上配置文件设置中,info、warn和error分别建立目录,info代表是info及其级别以上的信息,即不仅包含info日志,warn和error日志也存在。warn和error日志使用了filter过滤器控制,分别只记录严格匹配的警告和错误信息。按照上述配置,warn类型的日志会记录两遍,一遍在warn中,一遍在info中,error也是一样的。
开发环境,建议全局配置中只保留控制台日志输出即可。
测试环境,建议完全按照上面配置,控制台和磁盘文件都输出,便于上生产前发现和排查问题。
生产环境,建议将全局日志级别的root level="INFO"调整为ERROR或者WARN,并注释掉info输出 以及控制台输出。
在系统异常的时候,仅靠warn和error日志难以排查时,在流量较小的情况下,短时间打开info日志,收集完日志数据后及时关闭。
相关文章:
Logback实战指南:基础知识、实战应用及最佳实践全攻略
背景 在Java系统实现过程中,我们不可避免地会借助大量开源功能组件。然而,这些组件往往功能丰富且体系庞大,官方文档常常详尽至数百页。而在实际项目中,我们可能仅需使用其中的一小部分功能,这就造成了一个挑战&#…...

基于python的机器学习(三)—— 关联规则与推荐算法
目录 一、关联规则挖掘 1.1 基本概念 1.2 Apriori算法 1.2.1 Apriori算法的原理 1.2.2 Apriori算法的实例 1.2.3 Apriori算法的程序实现(efficient-apriori模块) 1.3 FP-Growth算法 1.3.1 FP-Growth算法的原理 1.3.2 FP-Growth算法的实例 二、…...

【大模型】LLaMA: Open and Efficient Foundation Language Models
链接:https://arxiv.org/pdf/2302.13971 论文:LLaMA: Open and Efficient Foundation Language Models Introduction 规模和效果 7B to 65B,LLaMA-13B 超过 GPT-3 (175B)Motivation 如何最好地缩放特定训练计算预算的数据集和模型大小&…...

模拟器多开限制ip,如何设置单窗口单ip,每个窗口ip不同
很多手游多开玩家都是利用安卓模拟器实现手游多开,但是很多手游会限制ip,导致多开之后封号等问题,模拟器本身没有更换IP的功能,就需要通过第三方软件来实现 安卓模拟器概述 雷电模拟器、夜神模拟器、mum模拟器等都是目前市场上比较…...

hive的存储格式
1) 四种存储格式 hive的存储格式分为两大类:一类纯文本文件,一类是二进制文件存储。 Hive支持的存储数据的格式主要有:TEXTFILE、SEQUENCEFILE、ORC、PARQUET 第一类:纯文本文件存储 textfile: 纯文本文件存储格式…...
)
鸿蒙学习高效开发与测试-应用程序框架(3)
文章目录 1、应用程序框架1、规范化后台进程管理2、原生支持分布式3、支持多设备的统一窗口管理4、 组件共享及面向对象5、逻辑与界面解耦6、灵活扩展机制2、HarmonyOS SDK1、 开放能力 Kit2、开放能力的检索和使用3、 方舟工具链4、前端编译器架构1、应用程序框架 应 用 程 序…...

什么命令可以查看数据库中表的结构
1. MySQL 查看表结构 sql 复制代码 DESCRIBE 表名; 或者: sql 复制代码 SHOW COLUMNS FROM 表名; 更详细的表信息 sql 复制代码 SHOW CREATE TABLE 表名; 2. PostgreSQL 查看表结构 sql 复制代码 \d 表名 列出表的字段及类型 sql 复制代码 SELECT column_name, da…...

django基于python 语言的酒店推荐系统
摘 要 酒店推荐系统旨在提供一个全面酒店推荐在线平台,该系统允许用户浏览不同的客房类型,并根据个人偏好和需求推荐合适的酒店客房。用户可以便捷地进行客房预订,并在抵达后简化入住登记流程。为了确保连续的住宿体验,系统还提供…...

【深度学习|onnx】往onnx中写入训练的超参或者类别等信息,并在推理时读取
1、往onnx中写入 在训练完毕之后,我们先使用torch.onnx.export() 导出onnx模型,然后我们再使用以下代码来往metadata中写入信息: # Metadatad {# stride: int(max(model.stride)),names: model.names,mean : [0,0,0],std : [1,1,1],normali…...

WebSocket详解、WebSocket入门案例
目录 1.1 WebSocket介绍 http协议: webSocket协议: 1.2WebSocket协议: 1.3客户端(浏览器)实现 1.3.2 WebSocket对象的相关事宜: 1.3.3 WebSOcket方法 1.4 服务端实现 服务端如何接收客户端发送的请…...

05_Spring JdbcTemplate
在继续了解Spring的核心知识前,我们先看看Spring的一个模板类JdbcTemplate,它是一个JDBC的模板类,用来简化JDBC的操作。 接下来以实际来进行说明 一、实例环境准备 数据库及表准备 我们在本地mysql中新增一个数据库test,并新增一张数据表:user create database if not…...

Bug:引入Feign后触发了2次、4次ContextRefreshedEvent
Bug:引入Feign后发现监控onApplication中ContextRefreshedEvent事件触发了2次或者4次。 【原理】在Spring的文档注释中提示到: Event raised when an {code ApplicationContext} gets initialized or refreshed.即当 ApplicationContext 进行初始化或者刷…...
最新VSCode保姆级安装教程(附安装包)
文章目录 一、VSCode介绍 二、VSCode下载 下载链接:https://pan.quark.cn/s/19a303ff81fc 三、VSCode安装 1.解压安装文件:双击打开并安装VSCode 2.勾选我同意协议:然后点击下一步 3.选择目标位置:点击浏览 4.选择D盘安装&…...

layui 表格点击编辑感觉很好用,实现方法如下
1. 在 HTML 页面中引入 layui 的相关资源文件:html <link rel"stylesheet" href"https://cdn.staticfile.org/layui/2.5.6/css/layui.css"> <script src"https://cdn.staticfile.org/layui/2.5.6/layui.js"></script&…...
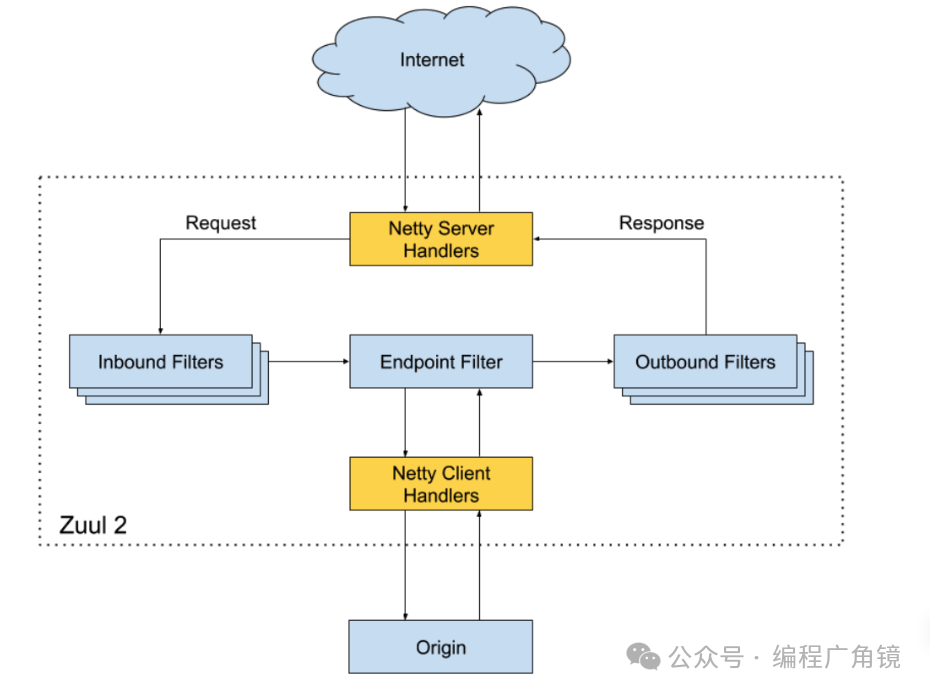
三十一、构建完善微服务——API 网关
一、API 网关基础 系统拆分为微服务后,内部的微服务之间是互联互通的,相互之间的访问都是点对点的。如果外部系统想调用系统的某个功能,也采取点对点的方式,则外部系统会非常“头大”。因为在外部系统看来,它不需要也没…...

非对称之美(贪心)
非对称之美(贪心) import java.util.*; public class Main{public static void main(String[] arg) {Scanner in new Scanner(System.in);char[] ch in.next().toCharArray(); int n ch.length; int flag 1;for(int i 1; i < n; i) {if(ch[i] ! ch[0]) {flag …...

详细教程-Linux上安装单机版的Hadoop
1、上传Hadoop安装包至linux并解压 tar -zxvf hadoop-2.6.0-cdh5.15.2.tar.gz 安装包: 链接:https://pan.baidu.com/s/1u59OLTJctKmm9YVWr_F-Cg 提取码:0pfj 2、配置免密码登录 生成秘钥: ssh-keygen -t rsa -P 将秘钥写入认…...

C#桌面应用制作计算器进阶版01
基于C#桌面应用制作计算器做出了少量改动,其主要改动为新增加了一个label控件,使其每一步运算结果由label2展示出来,而当点击“”时,最终运算结果将由label1展示出来,此时label清空。 修改后运行效果 修改后全篇代码 …...
[开源] 告别黑苹果!用docker安装MacOS体验苹果系统
没用过苹果电脑的朋友可能会对苹果系统好奇,有人甚至会为了尝鲜MacOS去折腾黑苹果。如果你只是想体验一下MacOS,这里有个更简单更优雅的解决方案,用docker安装MacOS来体验苹果系统。 一、项目简介 项目描述 Docker 容器内的 OSX(…...

多模态大模型(4)--InstructBLIP
BLIP-2通过冻结的指令调优LLM以理解视觉输入,展示了在图像到文本生成中遵循指令的初步能力。然而,由于额外的视觉输入由于输入分布和任务多样性,构建通用视觉语言模型面临很大的挑战。因而,在视觉领域,指令调优技术仍未…...

毕业设计新方式:8款AI工具让论文与代码不再困难
文章总结表格(工具排名对比) 工具名称 核心优势 aibiye 精准降AIGC率检测,适配知网/维普等平台 aicheck 专注文本AI痕迹识别,优化人类表达风格 askpaper 快速降AI痕迹,保留学术规范 秒篇 高效处理混AIGC内容&…...

2026 年重庆压浆料厂家选择 行业经验参考分析
2026 年,在重庆进行工程建设时,选择合适的压浆料厂家至关重要。本文将深入分析当前压浆料行业现状,为你提供可落地的厂家选择干货,助你解决选择难题。在压浆料的使用过程中,用户面临着诸多痛点。从材料性能来看&#x…...

Phi-4-reasoning-vision-15B在研发协作中的应用:代码IDE截图理解与问题定位
Phi-4-reasoning-vision-15B在研发协作中的应用:代码IDE截图理解与问题定位 1. 引言:研发协作中的视觉理解需求 在软件开发团队中,工程师们每天都要处理大量代码截图和IDE界面。当遇到问题时,最常见的做法是把报错截图或代码片段…...

springboot+deepseek实现AI接口调用
deepseek注册流程就不复述了,需要的小伙伴可以留言,单独指导。需要调用deepseek大模型接口的来看看了,直接上代码DsControllerpackage com.example.demo.controller;import com.example.demo.service.DsService; import org.springframework.…...

Fish Speech-1.5中文语音惊艳案例:古诗词吟诵/方言童谣/戏曲念白生成
Fish Speech-1.5中文语音惊艳案例:古诗词吟诵/方言童谣/戏曲念白生成 你听过AI用抑扬顿挫的语调吟诵唐诗宋词吗?你听过AI用地道的方言念出童年歌谣吗?你听过AI模仿戏曲念白,字正腔圆、韵味十足吗? 今天,我…...

高效电源芯片ASP3605性能优化全解析,使用Django从零开始构建一个个人博客系统。
ASP3605电源芯片的基本特性 ASP3605是一款高效同步降压DC-DC转换器芯片,输入电压范围通常在4.5V至18V之间,输出电流能力可达5A。其开关频率可调节(300kHz至2MHz),支持轻载高效模式(如PFM)&#…...

Agent Harness:AI Agent 时代那个「缺失的操作系统层」
文章目录前言当"最强大脑"得了"失忆症"Agent Harness:给AI装上"操作系统"Harness都管哪些事儿?1. 工具编排(Tool Orchestration)2. 记忆与状态持久化(Memory & State)3.…...

django基于大数据技术的医疗数据分析与研究_c1o2u99y_hxj031
前言随着信息技术的飞速发展,医疗领域产生的数据量呈爆炸式增长。这些数据蕴含着丰富的健康信息和疾病规律,但传统的数据处理方式往往只能进行简单的统计汇总,无法深入挖掘数据背后的关联性和趋势性规律,导致大量宝贵的医疗数据资…...

三极管基极电阻设计与工程实践
1. 三极管基极电阻的必要性解析在电子电路设计中,三极管作为最基础的半导体器件之一,其基极电阻的配置往往被初学者忽视。实际上,这两个电阻(限流电阻和上拉/下拉电阻)的设计直接影响着电路的可靠性和稳定性。以常见的…...

ATCODER ABC C题解炼
这,是一个采用C精灵库编写的程序,它画了一幅漂亮的图形: 复制代码 #include "sprites.h" //包含C精灵库 Sprite turtle; //建立角色叫turtle void draw(int d){for(int i0;i<5;i)turtle.fd(d).left(72); } int main(){ …...