向量数据库FAISS之五:原理(LSH、PQ、HNSW、IVF)
1.Locality Sensitive Hashing (LSH) 使用 Shingling + MinHashing 进行查找

左侧是字典,右侧是 LSH。目的是把足够相似的索引放在同一个桶内。
LSH 有很多的版本,很灵活,这里先介绍第一个版本,也是原始版本

-
Shingling

-
one-hot

-
MinHash

从 shingled 等于 1 的那一行找,找哈希值最小的,四个颜色里面得到的最终签名是 2412.
-
根据签名划分桶,对桶进行哈希

-
最后让两个向量在同一个桶内进行相似检索

-
不同的 b 值的相似度对比

在 FAISS 中的实现
import numpy as np
import faiss# 生成随机数据集(10000个128维向量)
np.random.seed(42)
d = 128 # 向量维度
nb = 10000 # 数据集大小
nq = 5 # 查询数量
xb = np.random.random((nb, d)).astype('float32') # 数据库向量
xq = np.random.random((nq, d)).astype('float32') # 查询向量# 创建 LSH 索引
**n_bits = 16 # 每个哈希签名的比特数(控制分布的细粒度)
nlist = 100 # 哈希桶的数量**# 使用余弦相似度的 LSH 索引
index = faiss.IndexLSH(d, n_bits) # d 是向量维度,n_bits 是每个哈希签名的比特数# 为数据集添加索引
index.add(xb)# 执行查询
k = 5 # 要找到的最近邻数量
D, I = index.search(xq, k) # 查询xq中k个最近邻
- n_bits(哈希签名比特数)
- 较大的 n_bits 的值意味着哈希分布更精细,每个哈希签名的长度更长,从而减少哈希冲突,提升检索的准确度。
- nlist(桶的数量)
- 代码中未显示
nlist调节,但你可以通过构建带有倒排表(IVF)的 LSH 来设置nlist。增加nlist可以减少每个桶中的向量数量,提高查询速度,但会增加空间分配的细粒度。
- 代码中未显示
2.PQ
补充概念
code
code 指数据点被量化后生成的一个索引值,表示该数据点在量化器所创建的 码本(codebook) 中的位置
当数据经过量化之后,他被映射到码本中的一个 质心(centroid),每个质心有一个对应的索引,这个索引就是 code
例如,如果有 64 个质心,那么每个数据点的 code 将是 0 到 63 之间的一个整数,表示该数据点最接近哪个质心。
Codebook
码本(codebook) 是一组质心的集合,用于表示数据集中的典型向量或原型。码本中的每个质心是一个向量,代表了量化后的数据点可以映射到的“典型”位置。
质心(centroid) 是通过聚类算法(如 k-means)在训练阶段学到的,用来表示数据点的分布。
码本的大小由质心的数量决定。例如,一个码本可能包含 64 个质心,表示数据可以被量化为 64 种不同的状态。
总结
Code 是数据点量化后对应质心的索引,用来表示该数据点最接近的质心。
Codebook 是质心的集合,表示数据点被聚类后可以映射到的典型位置。
1.摘要
其思想是将空间分解为低维子空间的笛卡尔积,并分别对每个子空间进行插值。
向量由其子空间量化索引组成的短码表示。
两个向量之间的欧氏距离可以有效地从它们的代码估计。非对称版本提高了精度,因为它计算了向量和代码之间的近似距离。
实验结果表明,我们的方法有效地搜索最近的邻居,特别是在与倒排文件系统相结合。
2.引言
已经提出了几种多维索引方法,例如流行的 KD树[5]或其他分支和界限技术,以减少搜索时间。然而,对于高维,事实证明这种方法并不比穷举距离计算更有效,其复杂度为 O ( n D ) O(nD) O(nD)。
在本文中,我们利用量化来构造短码。
目标是使用向量到质心距离来估计距离,例如,查询向量不被量化,code 仅被分配给数据库向量。这减少了量化噪声,并随后提高了搜索质量。为了获得精确的距离,必须限制量化误差。因此,质心的总数k应该足够大。这就提出了关于如何学习码本和分配向量的若干问题。
首先,学习量化器所需的样本数量是巨大的,即,几次 K。
其次,算法本身的复杂性是禁止的。
最后,地球上可用的计算机内存量不足以存储表示质心的浮点值。
3.背景
-
向量量化
向量量化是一个破坏的过程,他会减少表示空间的基数,尤其是输入数据是实数的时候
形式上,量化器是将 D 维向量 x x x 映射到向量 q ( x ) ∈ C = { c i , i ∈ I } , I = 0... k − 1 q(x)\in C = \{c_i, i\in I\}, I=0...k-1 q(x)∈C={ci,i∈I},I=0...k−1 的函数 q q q。
再现值 c i c_i ci 被称为质心。再现值的集合 C C C 是大小为 k k k 的码本。
映射到给定索引 i i i 的向量的集合 V i V_i Vi 被称为(Voronoi)单元
量化器的 k k k 个单元形成 R D R^D RD 的分区。根据定义,位于相同单元 V i V_i Vi 中的所有向量由相同质心 c i c_i ci 重构。
量化器的评价指标通常通过输入向量 x x x 和其再现值 q ( x ) q(x) q(x) 之间的均方误差 MSE 来测量。

其中, d ( x , y ) = ∣ ∣ x − y ∣ ∣ d(x,y)=||x-y|| d(x,y)=∣∣x−y∣∣, p ( x ) p(x) p(x) 是相关变量 X 的概率分布函数
为了使量化器是最佳的,它必须满足两个属性称为 Lloyd 最优性条件。首先,向量 x 必须量化到其最近的码本质心,根据欧几里得距离:

因此,单元由超平面界定。
第二个 Lloyd 条件是重建值必须是位于 Voronoi 单元中的向量的期望:

Lloyd 量化器对应于 k 均值聚类算法,通过迭代地将训练集的向量分配给质心并从分配的向量重新估计这些质心来找到接近最优的码本。
在没有任何进一步处理(熵编码)的情况下,存储索引值的存储器成本是 l o g 2 k log_2k log2k bit 。因此,对于k使用2的幂是方便的,因为量化器产生的代码存储在二进制存储器中。
-
乘积量化
考虑 128 维向量。一个量化器产生 64bits 的 code,即包含 2 64 2^{64} 264 个质心。大的离谱,内存不能接受。
乘积量化是一个处理这种问题的解决方案。
输入向量 x x x 被分成 m m m 个不同的子向量 u j u_j uj, 维度为 D ∗ = D / m D^*=D/m D∗=D/m, D D D 需要是 m m m 的倍数。
使用 m m m 个不同的量化器分别量化 子向量。

D 维向量 x 的被量化如图
乘积量化器的再现值由乘积索引集合 I = I 1 × . . . × I m I=I_1×...×I_m I=I1×...×Im 的元素来标识。因此,码本被定义为笛卡尔积

并且该集合的质心是 M 个子量化器的质心的级联。
从现在开始,我们假设所有的子量化器都有相同的有限数量 k 的再现值。在这种情况下,质心的总数由下式给出:

注意,在 m = D的极端情况下,向量 x 的分量全部被单独量化。然后,乘积量化器变成标量量化器,其中与每个分量相关联的量化函数可以不同。
乘积量化器的优点是从几个小的质心集合中产生一个大的质心集合:与子量化器相关联的质心集合。

k 是质心数,假设 k = 2 64 k=2^{64} k=264 的情况下,效果还是相当可观的
4.量化搜索

见图2。
对称和非对称距离计算的图解。利用距离 d ( q ( x ) , q ( y ) ) d(q(x), q(y)) d(q(x),q(y))(左)或距离 d ( x , q ( y ) ) d(x,q(y)) d(x,q(y))(右)来估计距离 d ( x , y ) d(x,y) d(x,y)。
距离上的均方误差平均地由量化误差限定。
最近邻搜索取决于查询向量和数据库向量之间的距离,或者等效地平方距离。
-
使用量化 code 计算距离
让我们考虑查询向量 x 和数据库向量 y。我们提出了两种方法来计算这些向量之间的近似欧氏距离,对称和非对称的。有关说明,请参见图2。
Symmetric distance computation (SDC):
向量 x 和 y 都由它们各自的质心 q(x) 和 q(y) 表示,距离 d(x,y) 近似为距离 d ( q ( x ) , q ( y ) ) d(q(x),q(y)) d(q(x),q(y)).

-
Asymmetric distance computation (ADC)
数据库向量 y y y 由 q ( y ) q(y) q(y) 表示,但查询 x x x 未被编码。距离 d ( x , y ) d(x,y) d(x,y) 近似为距离 d ( x , q ( y ) ) d(x,q(y)) d(x,q(y)),其使用分解计算

表 II 总结了不同步骤中的复杂度,涉及了 x x x 的 k k k 个最近邻邻居,在 n = ∣ y ∣ n=|y| n=∣y∣ 的数据集 Y Y Y中。可以看出,SDC 和 ADC 具有相同的查询准备成本,这与数据集大小 n 无关。

与 ADC 相比,SDC 的唯一优点是限制了与查询相关的内存使用,因为查询向量是由 code 定义的。这是大多数情况下不相关的,然后应该使用非对称版本,它获得了类似的复杂性较低的距离失真。我们将在本节的其余部分重点介绍 ADC。
-
非详尽搜索

图5.基于非对称距离计算的倒排文件(IVFADC)索引系统概述。上图:插入载体。底部:搜索。
5.总结
上面有点乱,总结一下
-
核心思想
PQ 的关键思想是将一个高维向量分成若干低维的子向量,然后对每个子向量分别进行量化。
- 高维向量分割:假设你有一个 D D D 维的向量,PQ 会将这个向量分成 m m m 个子向量。每个子向量的维度为 D / m D/m D/m 。
- 每个子向量独立量化:每个子向量分别用自己的码本(codebook)进行量化。每个码本有 k 个质心(centroid),也就是 k 种可能的量化结果
- 存储方式:每个高维向量的量化结果是 m 个子向量的量化码(code)的组合。这样。存储一个向量时,不再存储整个向量。而是存储 m 个索引
-
工作流程
假设有一个 D 维向量 x,使用 PQ 进行量化。
- 分割向量:将 x 划分为 m 个子向量 x = ( x 1 , … , x m ) x=(x_1, …, x_m) x=(x1,…,xm),每个子向量维度时 D / m D/m D/m
- 对每个子向量进行独立量化:
- 为每个子向量训练一个量化器,生成对应的码本(centroid)
- 将每个子向量 x i x_i xi 用码本中的质心替代,即找到与该子向量最近的质心,返回质心的索引
- 存储结果:量化后,将 x 表示为一个由 m 个量化索引组成的组合,这些索引指向各自子向量的质心
- 查询阶段:在查询时,将查询向量分块,分别与每个子向量的码本进行距离计算。最后,将每个子向量的距离累加,得到总距离。
6.faiss 中实现
import faiss# 维度
d = 128# 定义PQ量化器,分成m个子空间,每个子空间使用k个质心
m = 8 # 子空间数量
k = 256 # 每个子空间使用256个质心(8比特码)# 创建PQ索引
index = faiss.IndexPQ(d, m, k)# 训练PQ索引(假设有xb作为训练数据)
index.train(xb)# 添加数据
index.add(xb)# 查询
D, I = index.search(xq, k) # 查询xq中的k个近邻
- m(子空间数量)
- 将 原始向量划分为 m 个子空间,每个空间独自量化。
- m 需要被 d 整除
- m 越大,单个子向量维度越小,量化误差可能越大;存储开销和搜索速度可能降低。
- 较小的
m会保留更多原始向量的结构信息,但会增加存储和查询的计算复杂度。
- k(码表大小)
- 每个子空间使用的质心数,即每个子向量被量化为 k 种不同的值。常见的选择是
k = 256(8 比特编码),也可以选择其他值 k越大,量化的精度越高,但存储需求和计算复杂度也会增加。常见的值为 256
- 每个子空间使用的质心数,即每个子向量被量化为 k 种不同的值。常见的选择是
3.HNSW
1.解决的问题
- 高维空间中的最近邻搜索问题:在高维空间中,传统的最近邻搜索算法(如K-Nearest Neighbor Search,K-NNS)由于“维度的诅咒”而变得低效。HNSW 通过引入层次结构来克服这个问题,提供了更好的搜索性能。
- 近似搜索中的准确性与效率平衡:在近似最近邻搜索中,需要在搜索的准确性(召回率)和搜索效率之间找到平衡。HNSW 通过层次化的结构和启发式邻居选择策略,提高了搜索的效率和准确性。
- 大规模数据集的可扩展性:随着数据集规模的增长,传统的ANNS算法可能会遇到性能瓶颈。HNSW 通过其层次化的设计,实现了对大规模数据集的可扩展性。
2.原理
HNSW 的核心思想是构建一个多层次的图结构,每个层次包含一个嵌套的邻近图(proximity graph),用于存储元素的子集。

Fig. 1 HNSW的图解。
搜索从顶层的元素开始(显示为红色)。红色箭头显示贪婪算法从入口点到查询的方向(显示为绿色)。
每个元素在图中的最大层数是随机选择的,遵循指数衰减的概率分布。这种设计允许在保持图的连通性的同时,通过不同长度尺度的链接分离来提高搜索性能。
搜索过程从最高层(具有最长链接的层)开始,然后根据需要逐步向下层搜索,直到达到底层。
这种“放大-缩小”(zoom-out and zoom-in)的策略有助于快速定位到目标区域,并在局部区域内进行精确搜索。
HNSW还采用了一种启发式方法来选择邻近图中的邻居节点,这种方法不仅考虑了候选节点与查询点的距离,还考虑了候选节点之间的距离,以创建多样化的连接。这有助于在高度聚集的数据中保持全局连通性,并提高搜索的准确性。

图2.用于为两个孤立的集群选择图邻居的启发式图示。
在簇 1 的边界上插入一个新的元素,该元素的所有最近邻居都属于簇 1,因此丢失了簇之间的 Delaunay 图的边。然而,试探法从簇 2 中选择元素 e2,从而在插入的元素与来自簇 1 的任何其他元素相比最接近 e2 的情况下保持全局连通性。
3.总结
HNSW 会构建一个 分层的 导航小世界图 来加速搜索。
-
小世界网络

这是一个NSW图,图中两个顶点的距离为 4 跳。
如图,这允许通过少数跳跃,能够快速遍历网络中的大部分节点
-
分层导航结构
HNSW 使用多层图结构,其中每一层是一个稀疏图,越往上层图越稀疏、节点数越少,而下层的图更密集,包含更多节点:
- 顶层(高层):包含少数数据点,节点之间的连通性较弱。这里的作用是快速浏览整个数据集。
- 底层(低层):连接更密集的数据点,允许更精确的搜索。
每一个数据点都会随机分配到不同的层中,层次越高,点的密度越低。搜索从最顶层开始,依次向下跳转,逐渐进入更加密集的底层图,最终完成近似最近邻搜索。
-
邻居连接和随机跳跃
为了在各层图中有效进行导航,HNSW 使用了“随机邻居连接”的策略。
每个点通过固定数量的边与其他点连接,形成邻居节点集。这些连接不仅仅局限于靠近的点,还包含一定的随机性,从而确保图的连通性和避免局部最优。
- 随机性:初始构建图时,每个节点根据一定的概率与其他节点连接,特别是在高层图中,随机连接允许跨越较大距离的跳跃。
- 局部连接:在较低层次图中,节点之间的连接更多是局部的,与几何上相近的节点形成密集连接。
-
搜索过程
搜索过程可以分为以下几个阶段:
- 从最高层开始:从顶层的一个起始节点出发,使用贪心搜索逐步寻找距离目标向量最近的邻居。
- 逐层向下跳跃:一旦在顶层找到距离目标较近的节点,搜索算法会转移到下一层,继续在下一层寻找更接近目标的邻居。这种逐层跳跃过程可以加速搜索,因为每层的图连接性不同,可以提供全局导航和局部细化。
- 局部搜索:当搜索到最底层时,图的密度更高,搜索会在局部邻居之间进行更精确的距离计算,最终找到目标的近似最近邻。
4.代码
M = 16 # 每个顶点的连接数
ef_search = 8 # 搜索的深度
ef_construction = 64 # 构建时的扩展因子,决定了在构建图时为每个点找到最近邻的搜索深度index = faiss.IndexHNSWFlat(d, M)index.hnsw.efSearch = ef_search
index.hnsw.efConstruction = ef_constructionindex.add(xb)D, I = index.search(xq, k)
- M(最大连接数)
- 每个节点最大的连接边数。
- 值越大,搜索的结果更精确,但构建和查询的成本会变大。通常 16 - 48
- efConstruction(构建阶段的扩展因子))
- 控制图的构建质量
- 值越大,构建的图结构越精细,精度越高,但构建时间增加。
efConstruction通常设定为大于M的值。- 其实设置一个比较大的值最好
- efSearch(查询阶段的扩展因子)
- 控制查询阶段的搜索广度。
- 值越大,搜索的邻居节点越多,精度越高,但查询速度变慢
- 常为 50 - 200
4.IVF
1.解决的问题
IVF(Inverted File Index)主要是为了解决大规模、高维向量数据集的最近邻搜索问题。
在高维数据集上,执行精确的最近邻搜索代价极高,尤其是当数据量大、维度高时,计算距离的成本成指数级增长,导致搜索时间和内存占用都难以接受。
2.原理

-
数据分簇(clustering)
IVF 的核心思想是聚类。通过将数据点分成多个簇,算法可以大大减少在查询时需要计算的向量数量。
- 使用聚类进行分簇:常用 k-means。将数据集划分为多个簇,每个簇用一个质心(centroid) 表示。
- 构建倒排文件:一旦聚类完成,算法会为每个簇构建一个倒排列表。每个倒排索引列表中存储了归属于该簇的所有向量的 ID。这类似于搜索引擎中倒排索引的结构,用于快速定位相关文档
- 数据划分:数据集中的每个向量会被分配到某个簇,即它与该簇的质心距离最近。这样,整个数据集被划分为多个部分,每部分对应一个簇。
倒排索引
倒排索引是一种数据结构,它将向量空间中的特征(通常是聚类中心或代表向量)映射到包含该特征的所有数据点(向量)的列表。这种结构通过预先对数据进行分组,实现了快速的近似最近邻搜索,特别适用于高维向量空间中的大规模数据检索。
例如传统索引(正向索引):
- 条目:“番茄炒蛋的做法 A” -> 页码:10-20页
倒排索引:
- “番茄” -> 条目列表:{“番茄炒蛋的做法 A”, …}
- “炒蛋” -> 条目列表:{“番茄炒蛋的做法 A”, …}
-
查询阶段
在进行搜索时,IVF 只需在部分簇中执行最近邻搜索,从而大大减少了距离计算的次数。搜索过程如下:
- 查找最近的质心:首先,查询向量会与所有质心进行距离计算,从中选出与查询向量距离最近的几个质心。这一步用于粗略定位查询向量可能所在的簇。通常选择距离最近的
nprobe个质心,而不是所有质心。 - 在对应的簇中搜索:选定最近的质心后,搜索会在这些对应的簇中查找最近邻。由于这些簇包含的数据点较少,算法只需在这些簇内进行精细的距离计算,从而有效减少了搜索范围。
- 返回最近邻:通过在选中的簇中执行最近邻搜索,最终返回最接近查询向量的几个数据点
- 查找最近的质心:首先,查询向量会与所有质心进行距离计算,从中选出与查询向量距离最近的几个质心。这一步用于粗略定位查询向量可能所在的簇。通常选择距离最近的
3.代码
nlist = 128 # 质心数量quantizer = faiss.IndexFlatIP(d) # 可以减少内存占用,并提高搜索速度
index = faiss.IndexIVFFlat(quantizer, d, nlist)index.train(xb) # 需要训练!index.add(xb)index.nprobe = 1%%time
D, I = index.search(xq, k)
- nlist(聚类数量)
- 在训练阶段创建的聚类(桶)的数量
nlist的值越大,划分的簇越多,簇内的向量数量就越少,查询速度更快,但索引构建时间和内存占用可能会增加。- 通常
nlist的选择取决于数据的规模,经验上建议nlist与数据量的平方根成比例
nprobe(探测簇的数量)- 在查询时,
nprobe控制查询向量要搜索的簇的数量。 nprobe值越大,查询精度越高,但计算成本也相应增加。- 一般而言,可以通过调节
nprobe来在搜索精度和速度之间找到平衡
- 在查询时,
相关文章:
向量数据库FAISS之五:原理(LSH、PQ、HNSW、IVF)
1.Locality Sensitive Hashing (LSH) 使用 Shingling MinHashing 进行查找 左侧是字典,右侧是 LSH。目的是把足够相似的索引放在同一个桶内。 LSH 有很多的版本,很灵活,这里先介绍第一个版本,也是原始版本 Shingling one-hot …...

要素市场与收入分配
生产要素与家庭收入 生产要素:企业用于生产产品或劳务的最初投入,主要分为三类: 劳动:工人的时间和技能 土地:代指自然资源 资本:指的是货币形式的资本,可以供企业用来购置厂房、设备等资本品…...

Web3的核心技术:区块链如何确保信息安全与共享
在互联网不断迭代的进程中,Web3被视为下一代互联网的核心发展方向,其目标是构建更加开放、安全、去中心化的数字生态。在这一过程中,区块链作为核心技术,为信息安全与共享提供了全新解决方案。本文将深入探讨区块链如何在Web3中实…...

2025蓝桥杯(单片机)备赛--扩展外设之UART1的原理与应用(十二)
一、串口1的实现原理 a.查看STC15F2K60S2数据手册: 串口一在590页,此款单片机有两个串口。 串口1相关寄存器: SCON:串行控制寄存器(可位寻址) SCON寄存器说明: 需要PCON寄存器的SMOD0/PCON.6为0,使SM0和SM1一起指定工作模式,这里选择工作模式1,REN位置1,允许接受, …...

Js中的常见全局函数
文章目录 1、encodeURI、decodeURI2、encodeURIComponent、decodeURIComponent3、parseInt4、parseFloat5、String6、Number7、Boolean8、isNaN、Number.isNaN()9、JSON10、toString Js内置了一些函数和变量,全局都可以获取使用(本文归纳非构造函数作用的…...

MySQL连接查询之自连接
自连接 相当于等值连接,只不过是自己连接自己,不像等值连接是两个不同的表之间的 案例 查询员工名和他的上司的名字 select e.last_name,m.last_name from employees e, employees m #把同一张表当成两张不同表 where e.manager_id m.employee_id;...
基础 | 基础操作)
Python 爬虫 (1)基础 | 基础操作
一、基础操作 1、快速构建一个爬虫 ConvertCurl: https://curlconverter.com/选择URL,点击右键,选择 Copy >> Copy as cURL(bash) 安装JS环境:https://www.jb51.net/python/307069k7q.htm...

JAVA八股与代码实践----如何为springboot设置Servlet容器为jetty,jetty的优点是什么?
1、实践 排除原来的springboot-web依赖(默认是tomcat),加入jetty的依赖 <dependencies><!-- Spring Boot Web --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-s…...

idea怎么打开两个窗口,运行两个项目
今天在开发项目的时候,前端希望运行一下以前的项目,于是就需要开两个 idea 窗口,运行两个项目 这里记录一下如何设置:首先依次点击: File -> Settings -> Appearance & Behavior ->System Settings 看到如…...

wend看源码-APISJON
项目地址 腾讯APIJSON官方网站 定义 APIJSON 可以定义为一个面向HTTP 协议的JSON 规范,一个面向数据访问层的ORM 框架。其主要工作流程包括:前端按照既定格式组装 JSON 请求报文,通过 APIJSON-ORM 将这些报文直接转换为 SQL 语句,…...

堆外内存泄露排查经历
优质博文:IT-BLOG-CN 一、问题描述 淘宝后台应用从今年某个时间开始docker oom的量突然变多,确定为堆外内存泄露。 后面继续按照上一篇对外内存分析方法的进行排查(jemalloc、pmap、mallocpmap/mapsNMTjstackgdb),但都没有定位到问题。至于…...
SpringBoot Task
相关文章链接 定时任务工具类(Cron Util)SpringBoot Task 参数详解 Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE}) Retention(RetentionPolicy.RUNTIME) Documented Repeatable(Schedules.class) public interface Scheduled {String C…...

学习路之压力测试--jmeter安装教程
Jmeter安装 0、先安装jdk:这里是安装jdk-8u211-windows-x64 1、百度网盘上下载 jdk和jmeter 链接: https://pan.baidu.com/s/1qqqaQdNj1ABT1PnH4hfeCw?pwdkwrr 提取码: kwrr 复制这段内容后打开百度网盘手机App,操作更方便哦 官网:Apache JMeter - D…...

大模型部署,运维,测试所需掌握的知识点
python环境部署: python3 -m site --user-base 返回用户级别的Python安装基础目录 sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.8 1 将python3的默认路径/usr/bin/python3替…...

ECharts柱状图-带圆角的堆积柱状图,附视频讲解与代码下载
引言: 在数据可视化的世界里,ECharts凭借其丰富的图表类型和强大的配置能力,成为了众多开发者的首选。今天,我将带大家一起实现一个柱状图图表,通过该图表我们可以直观地展示和分析数据。此外,我还将提供…...
Thread 类和 Runnable 接口详解)
java 并发编程 (2)Thread 类和 Runnable 接口详解
目录 1. Thread 类和 Runnable 接口的设计目的 1.1 为什么有 Thread 类和 Runnable 接口? 2. Thread 类实现的详细分析 2.1 Thread 类的构造方法 2.2 start() 方法的工作原理 2.3 run() 方法 2.4 join() 方法 3. Runnable 接口的实现和作用 3.1 Runnable 接…...

人工智能之数学基础:线性代数在人工智能中的地位
本文重点 从本文开始,我们将开启线性代数的学习,在线性代数中有向量、矩阵,以及各种性质,那么这些数学知识究竟和人工智能有什么关系呢? 重要性 机器学习和深度学习的本质就是训练模型,要想训练模型需要使…...

PostgreSQL WITH 子句:提高查询效率和可读性
PostgreSQL WITH 子句:提高查询效率和可读性 PostgreSQL 是一种功能强大的开源关系数据库管理系统,它以其稳定性、可靠性和高级功能而闻名。在 PostgreSQL 中,WITH 子句(也称为公用表表达式,CTE)是一种非常有用的特性,它允许用户在一个大的查询中创建一个临时的结果集,…...

TransFormer--解码器:前馈网络层、叠加和归一组件
TransFormer--解码器:前馈网络层、叠加和归一组件 解码器的下一个子层是前馈网络层,如下图所示。 解码器的前馈网络层的工作原理与我们在编码器中学到的完全相同 叠加和归一组件 和在编码器部分学到的一样,叠加和归一组件连接子层的输入和输…...

2024亚太杯国际赛C题参考文章50页+完整解题思路+数据处理+最终结果
中国宠物食品行业的发展趋势与汇率情景分析:基于多模型的量化预测与决策分析 一 、 摘要 本文针对宠物产业及相关产业的发展分析问题,采用多种数学建模方法和数据 分析技术,构建了一系列预测和评估模型。从宠物数量预测、全球市场分析、产业 …...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...

排序算法总结(C++)
目录 一、稳定性二、排序算法选择、冒泡、插入排序归并排序随机快速排序堆排序基数排序计数排序 三、总结 一、稳定性 排序算法的稳定性是指:同样大小的样本 **(同样大小的数据)**在排序之后不会改变原始的相对次序。 稳定性对基础类型对象…...

Unity UGUI Button事件流程
场景结构 测试代码 public class TestBtn : MonoBehaviour {void Start(){var btn GetComponent<Button>();btn.onClick.AddListener(OnClick);}private void OnClick(){Debug.Log("666");}}当添加事件时 // 实例化一个ButtonClickedEvent的事件 [Formerl…...
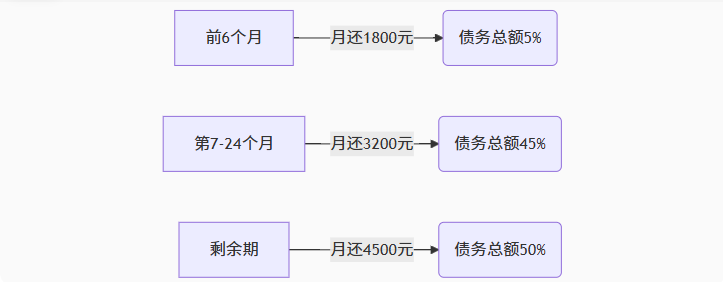
【无标题】湖北理元理律师事务所:债务优化中的生活保障与法律平衡之道
文/法律实务观察组 在债务重组领域,专业机构的核心价值不仅在于减轻债务数字,更在于帮助债务人在履行义务的同时维持基本生活尊严。湖北理元理律师事务所的服务实践表明,合法债务优化需同步实现三重平衡: 法律刚性(债…...

Vue3中的computer和watch
computed的写法 在页面中 <div>{{ calcNumber }}</div>script中 写法1 常用 import { computed, ref } from vue; let price ref(100);const priceAdd () > { //函数方法 price 1price.value ; }//计算属性 let calcNumber computed(() > {return ${p…...