YOLO-FaceV2: A Scale and Occlusion Aware Face Detector
《YOLO-FaceV2:一种尺度与遮挡感知的人脸检测器》
- 1.引言
- 2.相关工作
- 3.YOLO-FaceV2
- 3.1网络结构
- 3.2尺度感知RFE模型
- 3.3遮挡感知排斥损失
- 3.4遮挡感知注意力网络
- 3.5样本加权函数
- 3.6Anchor设计策略
- 3.7 归一化高斯Wasserstein距离
- 4.实验
- 4.1 数据集
- 4.2 训练
- 4.3 消融实验
- 4.3.1 SEAM块
- 4.3.2 多尺度特征融合
- 4.3.3 Slide损失
- 4.3.4 锚框设计
- 4.3.5 NWD损失
- 4.3.6 RepGT与RepBox的平衡
- 4.4 与现有人脸检测器的比较
- 5 结论

原文地址:官方论文地址
代码地址:官方代码地址
《YOLO-FaceV2:一种尺度与遮挡感知的人脸检测器》
来源:《Pattern Recognition》
类别:SCI期刊
学科分类:计算机科学
中科院分区:一区
JCR分区:一区
影响因子:8分
出版社:ELSEVIER
发表时间:2024年
创新点:
- 多尺度感知能力的提升:为了检测不同尺度的人脸,作者设计了一个名为RFE(Receptive Field Enhancement)的模块,通过使用扩张卷积来增强小尺度人脸的感受野。这有助于提高对小尺度目标的检测精度。
- 解决遮挡问题:针对人脸遮挡问题,作者提出了一个注意力模块SEAM(Separated and Enhancement Attention Module),并引入了Repulsion Loss来改善遮挡人脸的检测。这有助于提高在复杂场景中人脸检测的准确性。
- 解决样本不平衡问题:为了解决容易样本和困难样本之间的不平衡问题,作者设计了一个名为Slide的权重函数,该函数根据IoU(Intersection over Union)自动调整正负样本的权重,使模型在训练过程中更加关注困难样本。
- 锚点(Anchor)设计:作者根据有效感受野的信息重新设计了锚点的大小和比例,使其更适合人脸的尺度和比例,从而提高了模型的准确性和收敛速度。
- 回归损失函数的改进:为了弥补IoU损失函数对小目标敏感度的不足,作者引入了Normalized Wasserstein Distance(NWD)Loss,这是一种新的评估小目标检测的方法,它通过计算预测目标和真实目标之间的高斯分布相似度来衡量它们之间的相似性。
摘要:
近年来,基于深度学习的人脸检测算法取得了巨大进展。这些算法一般可以分为两类,即像Faster R-CNN这样的两阶段检测器和像YOLO这样的一阶段检测器。由于一阶段检测器在精度和速度之间取得了更好的平衡,因此已被广泛应用于多种场景。在本文中,我们提出了一种基于一阶段检测器YOLOv5的实时人脸检测器,命名为YOLO-FaceV2。我们设计了一个称为RFE的感受野增强模块 来增强小人脸的感受野,并使用NWD Loss来弥补loU对小物体位置偏差的敏感性。针对人脸遮挡问题我们提出了一种称为SEAM的注意力模块,并引入了排斥损失(Repulsion Loss) 来解决它。此外我们使用 滑动权重函数(Slide) 来解决简单样本和困难样本之间的不平衡问题,并利用有效感受野的信息来设计锚框。在WiderFace数据集上的实验结果表明,我们的人脸检测器优于YOLO,并且其变体在所有简单、中等和困难子集上均表现优异。
关键词 —— 人脸检测,YOLO,尺度感知,损失函数,不平衡问题
1.引言
人脸检测是许多人脸相关应用(如人脸识别、人脸验证和人脸属性分析等)中的关键步骤。近年来随着深度卷积神经网络口的蓬勃发展,人脸检测器的性能得到了极大的提升。许多基于深度学习的高性能人脸检测算法被提出。一般来说,这些算法可以分为两个分支。一个分支的典型基于深度学习的人脸检测算法[1,2,3]使用神经网络的级联方式作为特征提取器和分类器,从粗到细地检测人脸。尽管它们取得了巨大的成功,但值得注意的是,级联检测器存在一些缺点,如训练困难和检测速度慢。另一个分支是从通用目标检测算法[4,5,6]改进而来的。通用目标检测器考虑了物体更常见和更广泛的特征。因此,特定任务的检测器可以共亨这些信息,然后通过特殊设计来强化显著特性。一些流行的人脸检测器,包括YOLO[7,8,9,10]、Faster R-CNN [5]和RetinaNet [6],都属于这一类。在本文中,受YOLOv5[11]、TridentNet [12]和FAN中的注意力网络[13]的启发,我们提出了一种新型的人脸检测器,它在一阶段人脸检测中达到了最先进的水平。
尽管深度卷积网络极大地改善了人脸检测,但在现实场景中检测尺度、姿态、遮挡、表情、外观和光照等方面具有高度变化的人脸仍然是一个巨大的挑战。在我们之前的工作中,我们提出了YOLOFace[14],这是一种基于YOLOv3[9]的改进人脸检测器,它主要关注尺度变化问题 ,设计了适合人脸的锚框比例,并使用了更准确的回归损失函数。在WiderFace[15]验证集上,Easy、Medium和Hard的mAP分别达到了0.899、0.872和0.693。自那以后,出现了各种新型检测器,人脸检测性能得到了显著提升。然而,对于小物体,一阶段检测器必须以更细的粒度划分搜索空间,因此容易导致正负样本不平衡的问题[16]。此外,复杂场景中的人脸遮挡[13]对人脸检测器的准确性产生了显著影响。为了解决人脸尺度变化、简单和困难样本不平衡以及人脸遮挡的问题, 我们提出了一种基于YOLOv5的人脸检测方法,称为YOLO-FaceV2。
通过仔细分析人脸检测器遇到的困难和YOLOv5检测器的不足,我们提出了以下解决方案。
多尺度融合: 在许多场景中,图像中通常存在不同尺度的人脸,这使得人脸检测器很难全部检测到它们。因此,解决不同尺度的人脸问题是人脸算法中非常重要的任务。目前,解决尺度变化问题的主要方法是构建一个金字塔来融合人脸的多尺度特征[17,18,19,20]。例如,在YOLOv5中,FPN[20]融合了P3、P4和P5层的特征。然而,对于小尺度目标,信息在经过多层卷积后很容易丢失,即使在较浅的P3层中,保留的像素信息也非常少。因此,提高特征图的分辨率无疑有利于小目标的检测。
注意力机制: 在许多复杂场景中,人脸遮挡经常发生,这是人脸检测器精度下降的主要原因之一。为了解决这个问题,一些研究人员尝试使用注意力机制进行人脸特征提取。FAN[13]提出了一种锚点级注意力机制。他们建议的解决方案是保持未遮挡区域的响应值,并通过注意力机制补偿遮挡区域降低的响应值。然而,它并没有充分利用通道之间的信息。
困难样本: 在一阶段检测器中,许多边界框没有被迭代过滤掉。因此,一阶段检测器中的简单样本数量非常大。在训练过程中,它们的累积贡献主导了模型的更新,导致模型过拟合[16]。这被称为样本不平衡问题。为了解决这个问题,Lin等人提出了Focal Loss,以动态地为困难样本分配更多权重[6]。与Focal Loss类似,梯度调和机制(GHM)[21]抑制了来自正负简单样本的梯度,以更多地关注困难样本。Cao等人提出的Prime Sample Attention(PISA)[22]根据不同标准为正负样本分配权重。然而,当前的困难样本挖掘方法需要设置太多的超参数,这在实践中非常不便。
锚点设计: 如[23]所指出的,卷积神经网络(CNN)特征图中的一个区域有两种类型的感受野,即理论感受野和实际感受野。实验表明,感受野中的所有像素并不都同等响应,而是服从高斯分布。这使得基于理论感受野的锚点尺寸大于其实际尺寸,从而增加了边界框回归的难度。Zhang等人在S3FD[24]中根据有效感受野设计了锚点的大小。而FaceBoxes[25]设计了多尺度锚点来丰富感受野,并在不同层上对锚点进行离散化,以处理不同尺度的人脸。因此,锚点框的尺度和比例设计非常重要,这可能极大地提高模型的准确性和收敛过程。
回归损失: 回归损失用于衡量预测边界框和真实边界框之间的差异。目标检测器中常用的回归损失函数有L1/L2损失、平滑L1损失、交并比(loU)损失及其变体[26,27,28,29]。YOLOv5采用IoU损失作为其目标回归函数。然而,loU对不同尺度目标的敏感性差异很大。很容易理解的是,对于小目标轻微的位置偏差就会导致loU显著下降。Wang等人[30]提出了一种基于Wasserstein距离的小目标评估方法,以有效减轻小目标的影响。然而,他们的方法对于大目标的效果并不显著。
在本文中,为解决上述问题,我们基于YOLOv5设计了一种新的人脸检测器。我们的目标是找到一个最优的组合检测器 , 有效解决小脸、尺度变化大、遮挡场景以及难易样本不平衡等问题有效解决小脸、尺度变化大、遮挡场景以及难易样本不平衡等问题。第一,我们融合了特征金字塔网络(FPN)的P2层信息,以获得更多的像素级信息,并补偿小脸的信息。然而这样会导致大、中目标的检测精度略有降低,因为输出特征图的感受野变小了。为改善这种情况,我们为P5层设计了感受野增强(RFE)模块,通过使用空洞卷积来增大感受野。第二,受特征注意力网络(FAN)和ConvMixer[31]的启发,我们重新设计了一个多头注意力网络,以补偿遮挡人脸响应值的损失。此外,我们还引入了排斥损失(Repulsion Loss)[32],以提高类内遮挡的召回率。第三,为挖掘难样本,受自适应训练样本选择(ATSS)[33]的启发,我们设计了具有自适应阈值的滑动权重函数,使模型在训练过程中更加关注难样本。第四,为了使锚框更适合回归,我们根据有效感受野和人脸比例重新设计了锚框的大小和比例。第五,我们借鉴了归一化Wasserstein距离度量[30],并将其引入回归损失函数中,以平衡在预测小脸时交并比(loU)的不足。
综上所述,我们提出了一种新的人脸检测器YOLO-FaceV2,其主要贡献如下。
1.对于多尺度人脸检测,感受野和分辨率是关键因素。因此, 我们设计了一个感受野增强模块(称为RFE),以学习特征图的不同感受野,并增强特征金字塔的表示能力。
2.我们将人脸遮挡分为两类,即不同人脸之间的遮挡和其他物体对人脸的遮挡。前者使得检测精度对非极大值抑制(NMS)阈值非常敏感,从而导致漏检。 我们使用排斥损失进行人脸检测,该损失会对预测框向其他真实对象偏移进行惩罚,并要求每个预测框远离具有不同指定目标的其他预测框,从而使检测结果对NMS的敏感性降低。后者会导致特征消失,从而导致定位不准确, 我们设计了注意力模块SEAM来增强人脸特征的学习。
3.为解决难易样本不平衡的问题,我们根据loU对易样本和难样本进行加权。为减少超参数调整,我们将所有候选正样本与真实对象之间的loU均值作为正负样本的分界线。我们还设计了一个名为Slide的加权函数,为难样本赋予更高的权重,这有助于模型学习更难的特征。 该函数的详细信息将在第3-5节中介绍。
本文的其余部分安排如下:第2节回顾了该领域的相关文献;第3节详细描述了模型结构,并分别介绍了主要改进,包括感受野增强模块、注意力模块、自适应样本加权函数、锚框设计、排斥损失和归一化高斯Wasserstein距离(NWD)损失;第4节描述了实验和相应的结果分析,包括消融实验和与其他模型的比较:第5节总结了我们的工作,并给出了未来研究的建议。
2.相关工作
人脸检测。 人脸检测几十年来一直是计算机视觉领域的一个热门研究方向。在深度学习的早期,人脸检测算法通常使用神经网络自动提取图像特征进行分类。CascadeCNN提出了一种具有三个阶段精心设计的深度卷积网络的级联结构,以由粗到细的方式预测人脸和特征点位置。MTCNN[2]开发了一种类似的级联架构,用于联合对齐人脸特征点和检测人脸位置。PCN使用角度预测网络来校正人脸,提高人脸检测的准确性。但早期基于深度学习的人脸检测算法存在一些缺点,如训练繁琐、局部最优、检测速度慢、检测精度低等。
当前的人脸检测算法主要通过继承通用目标检测算法(如SSD[4]、Faster R-CNN[5]、RetinaNet[6]等)的优点进行改进。CMSRCNN[34]以Faster R-CNN为主干网络,并引入上下文信息和多尺度特征来检测人脸。Zhang等人[25]设计了一个基于SSD结构的轻量级网络FaceBoxes,通过32倍下采样快速缩小特征图尺寸,并使用多尺度网络模块在网络的宽度和深度维度上增强特征。SRN[35]在通用目标检测算法RefineDet[36]和RetinaNet[6]的基础上进行了改进,通过引入两阶段分类和回归实现高性能,并设计了一个多分支模块来增强感受野的效果。
尺度不变性。 作为人脸检测中最具挑战性的问题之一,复杂场景中的大人脸尺度变化对检测器的准确性有重要影响。多尺度检测能力主要取决于尺度不变特征,许多工作致力于更准确、有效地提取这些特征[13,24,37,38]。对于小目标检测,使用较少的下采样层和空洞卷积可以显著提高检测性能[39,40]。解决这一问题的另一种方法是使用更多的锚框。锚框可以提供良好的先验信息,因此使用更密集的锚框和相应的匹配策略可以有效提高目标候选框的质量[24,25,37,40]。多尺度训练有助于构建图像金字塔并增加样本多样性,这是提高多尺度目标检测性能的一种简单而有效的方法。另一方面,感受野会增加,相应的语义信息也会更丰富,但空间信息可能会相应缺失。一个自然的想法是将深层语义信息与浅层特征相融合,如[20,41,42]。此外,SNIP[43]和TridentNet[12]也为解决多尺度问题提供了新的思路,将在以下部分详细讨论。
遮挡问题。 密集人脸及其带来的遮挡问题导致部分数据缺失被遮挡人脸的信息,因为一些区域不可见或边界模糊,这很容易导致漏检和召回率低。一些工作已经证明,上下文信息有助于人脸检测以缓解遮挡问题。SSH[37]通过使用简单的卷积层来扩大候选框周围的窗口,从而结合上下文信息。FAN[13提出了一种锚框级注意力机制,通过突出人脸区域的特征来检测被遮挡的人脸。PyramidBox[44]设计了一个上下文敏感预测模块,其中用DSSD的残差预测模块替换了SSH中上下文模块的卷积层。RetinaFace[45]在五个特征金字塔级别上应用独立的上下文模块,以增加感受野并增强刚性上下文建模能力。上述方法在遮挡问题上取得了良好的效果。因此,利用上下文信息来提高遮挡区域的有效性是一个可行的方向,值得进一步探索。
易难样本不平衡。 对于单阶段人脸检测,易样本的数量非常大,它们主导了损失的变化,导致模型只能学习易样本的特征,而忽略了难样本的学习。为了解决这个问题,OHEM[46]算法根据样本损失选择难样本,并将难样本的损失应用于随机梯度下降的训练中。针对OHEM算法中忽略易样本的问题Focal Loss[6]通过对样本进行加权来更好地利用所有样本,并获得更高的准确性。SRN[35]也遵循了这一思路。Faceboxes[25]根据样本的loU损失进行排序,并控制正负样本的比例小于1:3。虽然上述方法可以有效解决样本不平衡问题,但它们也人为地引入了一些超参数,增加了调整的难度。因此我们设计了一个具有自适应参数的样本平衡函数。
3.YOLO-FaceV2
3.1网络结构
YOLOv5是一款出色的通用目标检测器。我们将其引入人脸检测领域,并尝试解决小人脸和人脸遮挡等问题。
我们的YOLO-FaceV2检测器的架构如图1所示。它包含三个部分:主干结构、颈部和头部。我们采用CSPDarknet53作为主干结构,并在P5层用RFE模块替换Bottleneck,以融合多尺度特征。在颈部部分,我们保留了SPP[47]和PAN[48]的结构。此外, 为了提高目标位置感知能力,我们还将P2层融入PAN中。头部用于分类目标类别并回归目标位置。我们还向头部添加了一个特殊分支,以增强模型对遮挡检测的能力。

图1:YOLO-FaceV2的网络架构。(a) 主干网络:一个前馈CSPDarknet53架构用于提取多尺度特征图。为了扩大感受野,P5中的CSP模块被替换为感受野增强模块(RFE),如蓝色虚线框所示。(b) 颈部:空间金字塔池化(SPP)分离出最重要的上下文特征,并增大感受野;路径聚合网络(PAN)从不同主干层级的参数进行聚合,以供不同检测器层级使用。为了补偿因感受野扩大而导致的分辨率损失,P2层被融合到PAN中,如图(a)和(b)之间所示。(c)分离与增强注意力模块(SEAM)利用特征图之间的关系来恢复被遮挡的特征,如红色虚线框所示。
在图1(a)中,左侧的红色部分是检测器的主干结构,由CSP块和CBS块组成。它主要用于提取输入图像的特征。我们在P5层添加RFE模块,以扩大有效感受野并增强多尺度特征的融合能力。在图1(b)中,右侧的蓝色和黄色部分称为颈部层,由SPP和PAN组成。我们额外融合了P2层的特征,以提高目标定位的精确度。在图1(c)中,我们在颈部层的输出部分之后引入了分离和增强注意力模块(SEAM),以增强遮挡人脸的响应性。
3.2尺度感知RFE模型
由于不同大小的感受野意味着捕获长距离依赖性的能力不同,我们设计了RFE模块,通过使用空洞卷积来充分利用特征图中感受野的优势。受TridentNet启发,我们使用四个不同空洞率的空洞卷积分支来捕获多尺度信息和不同范围的依赖性。所有分支共享权重,唯一不同的是它们独特的感受野。一方面,这减少了参数数量,从而降低了潜在过拟合的风险。另一方面,它可以充分利用每个样本。所提出的RFE模块可分为两部分:基于空洞卷积的多分支部分和收集加权层, 如图2所示。多分支部分分别以1、2和3作为不同空洞卷积的空洞率,均使用固定的3x3卷积核大小。此外,我们添加了一个残差连接,以防止训练过程中出现梯度爆炸和消失的问题。收集和加权层用于从不同分支收集信息并为每个分支的特征加权。加权操作用于平衡不同分支的表示。
为了明确说明,我们用RFE模块替换了YOLOv5中C3模块的瓶颈部分,以增加特征图的感受野,从而提高多尺度目标检测和识别的准确性,如图2所示。

图2:改进的CSP块和RFE模块。对于P5中的CSP块,我们用RFE替换了瓶颈层。右图展示了RFE的详细架构。它包含1x1卷积、具有不同膨胀率的3x3卷积以及平均池化层。
3.3遮挡感知排斥损失
类内遮挡可能导致人脸A包含人脸B的特征,从而导致更高的误检率。通过排斥力引入排斥损失可以有效地缓解这个问题。排斥损失分为两部分:RepGT和RepBox。RepGT损失的功能是使当前边界框尽可能远离周围的真实框。这里的周围真实框是指除边界框本身要返回的对象外,与面部loU最大的面部标签。RepGT损失函数的公式如下:

其中


RepBox损失的目的是使预测框尽可能远离周围的预测框,并减小它们之间的交并比(loU),从而避免属于两张脸的其中一个预测框被非极大值抑制(NMS)抑制。我们将预测框分为多个组。假设有g个独立的人脸,分组形式如等式3所示。同一组内的预测框返回相同的人脸标签,不同组之间的预测框对应不同的人脸标签。

然后,对于不同组之间的预测框pi和pj,我们希望得到相应的函数。总体损失函数如下:

3.4遮挡感知注意力网络
类间遮挡会导致对齐误差、局部混和特征丢失。我们添加了多头注意力网络,即SEAM模块(见图3),该模块有三个目的:实现多尺度人脸检测,强调图像中的人脸区域,并相应地削弱背景区域。 SEAM的第一部分是带残差连接的深度可分离卷积 。深度可分离卷积是逐层进行的,即通道间分离的卷积。虽然深度可分离卷积可以学习不同通道的重要性并减少参数量,但它忽略了通道间的信息关系。为了弥补这一损失,不同深度卷积的输出随后通过逐点(1x1)卷积进行组合。然后使用一个两层全连接网络来融合每个通道的信息,从而使网络能够加强所有通道之间的联系。希望该模型能够通过在前一步中学习到的遮挡人脸与非遮挡人脸之间的关系,来弥补遮挡场景下的上述损失。全连接层学习到的输出逻辑值随后通过指数函数进行处理,将值范围从[0,1]扩展到[1,e]。这种指数归一化提供了一个单调映射关系,使结果对位置误差具有更高的容忍度。最后,将SEAM模块的输出作为注意力,与原特征相乘,从而使模型能够更有效地处理人脸遮挡。

图3:SEAM示意图。左侧是SEAM的架构,右侧是CSMM(通道和空间混合模块)的结构。CSMM利用不同的块处理多尺度特征,并使用深度可分离卷积来学习空间维度和通道之间的相关性。
3.5样本加权函数
样本不平衡问题,即大多数情况下简单样本数量相当大,而困难样本相对较少,已引起广泛关注。在我们的工作中,我们设计了一个看起来像“"滑块”的Slide损失函数 来解决这个问题。简单样本和困难样本的区别是基于预测框和真实框的loU大小。为了减少超参数,我们取所有边界框的loU值的平均值作为阈值”,将小于u的样本作为负样本,大于此的样本作为正样本。然而,边界附近的样本往往由于分类不明确而损失较大。我们希望模型能够学习优化这些样本,并更充分地利用这些样本来训练网络.然而,这类样本的数量相对较少。因此,我们尝试为困难样本分配更高的权重。我们首先通过参数μ将样本分为正样本和负样本。然后,我们通过如图4所示的加权函数Slide来强调边界附近的样本。Slide加权函数可以表示为等式5(下图)。

3.6Anchor设计策略
在人脸检测中,Anchor设计策略至关重要。在我们的模型中,三个检测头中的每一个都与一个特定的Anchor尺度相关联。Anchor的设计包括根据P2、P3和P4的步长设计的宽高比和Anchor大小(见表1)。对于宽高比,我们根据WiderFace训练集中的真实人脸比例计算统计值。在人脸检测中,我们根据统计结果将宽高比设置为1:1.2。对于Anchor的大小,我们根据每层的感受野进行设计,这可以通过卷积和池化层的数量来计算。然而,理论感受野中的每个像素对最终输出的贡献并不相同。一般来说,中心像素比外围像素的影响更大,如图5(a)所示。换句话说,只有一小部分区域对输出值有有效影响。实际效果可以等效于一个有效感受野。根据这一假设,为了匹配有效感受野,Anchor应该明显小于理论感受野(见图5(b)中的具体示例)。因此,我们重新设计了初始Anchor大小,如表1所示。
表1:三个检测层及九个锚框尺度


图4:我们提出了一种新的损失函数,我们称之为滑动损失(Slide Loss),该函数自适应地学习正样本和负样本的阈值参数µ。在µ附近设置较高的权重会增加难以分类样本的相对损失,从而使模型更加关注那些难以分类、被错误分类的样本。
图5(b)。因此,我们根据表1重新设计了初始锚框尺寸。

图5:(a) 有效感受野:整个黑色框是理论感受野(TRF),而带有高斯分布的白色圆圈是有效感受野(ERF)。该图来自[23]。(b) 一个特例:整个框是TRF设定的原始锚框,而蓝色框是由红色圆圈(即ERF)估计的新锚框。
3.7 归一化高斯Wasserstein距离
归一化Wasserstein距离(命名为NWD)是一种小目标检测的新评价方法。首先,将边界框建模为维高斯分布,并通过它们对应的高斯分布来计算预测目标与真实目标之间的相似性,即根据公式计算它们之间的归一化Wasserstein距离。对于检测到的目标,无论它们是否重叠,都可以通过分布相似性来衡量。NWD对目标的尺度不敏感,因此更适合衡量小目标之间的相似性。在我们的回归损失函数中,我们添加了NWD损失以弥补交并比(loU)损失在小目标检测方面的不足。 但我们仍然保留了loU损失,因为它适用于大目标检测。


4.实验
在本部分,我们对我们提出的方法进行了全面的消融实验,包括我们注意力模块、多尺度融合金字塔结构和损失函数设计的有效性。然后,我们将我们提出的检测器与其他最先进的(SOTA)人脸检测器进行了性能比较。
4.1 数据集
我们在WiderFace数据集上评估了我们的模型,该数据集包含32203张图像,其中包括40多万张人脸。它分为三个部分:40%用于训练集,10%用于验证集,50%用于测试集。训练集和验证集的结果可以从WiderFace的官方网站上获得。根据难度,数据集可分为三部分:简单、中等和困难。其中,困难子集最具挑战性,其性能可以更好地反映人脸检测器的有效性。我们在WiderFace训练集上训练了我们的模型,并在验证集和测试集上对其进行了评估。
4.2 训练
我们以YOLOv5为基线,并使用PyTorch实现这些方法。我们使用的优化器是具有动量的随机梯度下降(SGD)。初始学习率设置为1e-2,最终学习率设置为1e-3,权重衰减设置为5e -3。在前3个预热周期中使用0.8的动量。之后,动量变为0.937。非极大值抑制(NMS)的loU设置为0.5。我们在具有4个CPU工作线程的1080ti上训练模型。微调过程消耗了100次迭代,批量大小为16张图像。
4.3 消融实验
在本节中,我们在WiderFace数据集上对每个模块进行了全面的实验,以评估它们对 模型性能只的影响。然后将模块逐一组合并分析。此外,还评估了所有损失函数。
4.3.1 SEAM块
我们提出的SEAM块是注意力网络。通过使用此块,我们通过增强未遮挡人脸的响应来弥补遮挡人脸的响应损失。结果如表2的第二行所示。我们可以看到,在简单、中等和困难子集验证集上,准确率分别提高了0.88、0.82和1.06。
表2:在WiderFace验证数据集上的消融研究结果

4.3.2 多尺度特征融合
首先,我们在PAN的基础上融合了P2层特征,使融合后的特征图包含更多小目标的信息。根据表2的第三行,可以观察到困难子集提高了0.57。为了弥补颈部层输出特征图的有限感受野导致的中大日标检测精度下降,我们应用了设计的感受野增强模块,并使用了膨胀率分别为1、2和3的膨胀卷积来提高长距离依赖的效果。效果如表2的第四行所示。准确率分别提高了0.5、0.6和2.17。
4.3.3 Slide损失
Slide损失函数的主要目的是使模型更加关注困难样本。根据表中第五行的结果,Slide函数在中等和困难子集上略微提高了模型的性能。
4.3.4 锚框设计
锚框的比例和大小与有效感受野密切相关。不同的模型具有不同的有效感受野。根据有效感受野和人脸形状特征,设计锚框对性能的影响如表2的第六行所示。在简单、中等和困难数据集上分别提高了0.24、0.75、0.9。正如我们所期望的,适当设计的锚框可以召回更多的小人脸目标。
4.3.5 NWD损失
我们首次采用NWD代替loU作为回归损失。然而,结果并没有改善。因此,我们选择保留oU损失,并通过调整它们之间的比例关系来提高我们模型在小目标检测方面的鲁棒性。因为实验结果表明,对于中大日标,IoU测量的效果优于NWD,而NWD可以有效提高小目标的检测精度。结果如表3所示:
表3:我们的YOLO-FaceV2与现有面部检测器在WiderFace验证数据集上的比较

4.3.6 RepGT与RepBox的平衡
受行人检测中遮挡问题解决方案的启发,我们将排斥损失(Repulsion Loss)引入到了人脸检测中并分析了不同的人脸遮挡阈值,以使该损失函数适用于人脸检测。根据表格第八行的结果,排斥损失函数在简单、中等和困难子集上分别将模型精度提高了0.71、0.63和0.5。
4.4 与现有人脸检测器的比较
我们主要与最近提出的各种优秀的人脸检测器进行比较。表4根据基于不同通用检测器(如快速RCNN、SSD、Yolo等)的人脸检测器进行了分类。表格中的数据来自WiderFace的官方网站。
表4:我们的YOLO-FaceV2与现有面部检测器在WiderFace验证数据集上的对比

同时,我们的YOLO-FaceV2人脸检测器与竞争对手的精确率-召回率(PR)曲线如图6所示。



图6:在WiderFace验证数据集上的检测结果。(a):在‘简单’数据集上的结果 (b):在‘中等’数据集上的结果 ©:在‘困难’数据集上的结果
5 结论
本文旨在解决人脸尺度变化、简单与困难样本不平衡以及人脸遮挡等问题,提出了一种基于YOLOv5的人脸检测方法,称为YOLO-FaceV2。针对人脸尺度变化的问题,我们将P2层融入特征金字塔以提高小物体的分辨率,设计了RFE模块以增强感受野,并使用NWD损失来提高模型对小目标检测的鲁棒性。此外,我们引入了滑动(Slide)函数来缓解简单与困难样本不平衡的问题。对于人脸遮挡问题我们采用了SEAM模块和排斥损失(Repulsion Loss)进行解决。同时,我们还利用有效感受野的信息来设计锚框。最终,我们在WiderFace验证集的Easy和Medium子集上实现了接近或超越当前最优(SOTA)的性能。
相关文章:
YOLO-FaceV2: A Scale and Occlusion Aware Face Detector
《YOLO-FaceV2:一种尺度与遮挡感知的人脸检测器》 1.引言2.相关工作3.YOLO-FaceV23.1网络结构3.2尺度感知RFE模型3.3遮挡感知排斥损失3.4遮挡感知注意力网络3.5样本加权函数3.6Anchor设计策略3.7 归一化高斯Wasserstein距离 4.实验4.1 数据集4.2 训练4.3 消融实验4.3.1 SEAM块4…...

进程间通信--详解
目录 前言一、进程间通信介绍1、进程间通信目的2、进程间通信发展3、进程间通信的分类4、进程间通信的必要性5、进程间通信的技术背景6、进程间通信的本质理解 二、管道1、什么是管道2、匿名管道pipe(1)匿名管道的原理(2)pipe函数…...
零基础上手WebGIS+智慧校园实例(1)【html by js】
请点个赞收藏关注支持一下博主喵!!! 等下再更新一下1. WebGIS矢量图形的绘制(超级详细!!),2. WebGIS计算距离, 以及智慧校园实例 with 3个例子!!…...
【Github】如何使用Git将本地项目上传到Github
【Github】如何使用Git将本地项目上传到Github 写在最前面1. 注册Github账号2. 安装Git工具配置用户名和邮箱仅为当前项目配置(可选) 3. 创建Github仓库4. 获取仓库地址5. 本地操作(1)进入项目文件夹(2)克隆…...

集合Queue、Deque、LinkedList、ArrayDeque、PriorityQueue详解
1、 Queue与Deque的区别 在研究java集合源码的时候,发现了一个很少用但是很有趣的点:Queue以及Deque; 平常在写leetcode经常用LinkedList向上转型Deque作为栈或者队列使用,但是一直都不知道Queue的作用,于是就直接官方…...

谈一下开源生态对 AI人工智能大模型的促进作用
谈一下开源生态对 AI人工智能大模型的促进作用 作者:开源呼叫中心系统 FreeIPCC,Github地址:https://github.com/lihaiya/freeipcc 开源生态对大模型的促进作用是一个多维度且深远的话题,它不仅加速了技术创新的速度,…...

基于python的机器学习(四)—— 聚类(一)
目录 一、聚类的原理与实现 1.1 聚类的概念和类型 1.2 如何度量距离 1.2.1 数据的类型 1.2.2 连续型数据的距离度量方法 1.2.3 离散型数据的距离度量方法 1.3 聚类的基本步骤 二、层次聚类算法 2.1 算法原理和实例 2.2 算法的Sklearn实现 2.2.1 层次聚类法的可视化实…...

实时数据开发 | 怎么通俗理解Flink容错机制,提到的checkpoint、barrier、Savepoint、sink都是什么
今天学Flink的关键技术–容错机制,用一些通俗的比喻来讲这个复杂的过程。参考自《离线和实时大数据开发实战》 需要先回顾昨天发的Flink关键概念 检查点(checkpoint) Flink容错机制的核心是分布式数据流和状态的快照,从而当分布…...

C++设计模式-策略模式-StrategyMethod
动机(Motivation) 在软件构建过程中,某些对象使用的算法可能多种多样,经常改变,如果将这些算法都编码到对象中,将会使对象变得异常复杂;而且有时候支持不使用的算法也是一个性能负担。 如何在运…...

小程序免备案:快速部署与优化的全攻略
小程序免备案为开发者提供了便捷高效的解决方案,省去繁琐的备案流程,同时通过优化网络性能和数据传输,保障用户体验。本文从部署策略、应用场景到技术实现,全面解析小程序免备案的核心优势。 小程序免备案:快速部署与优…...
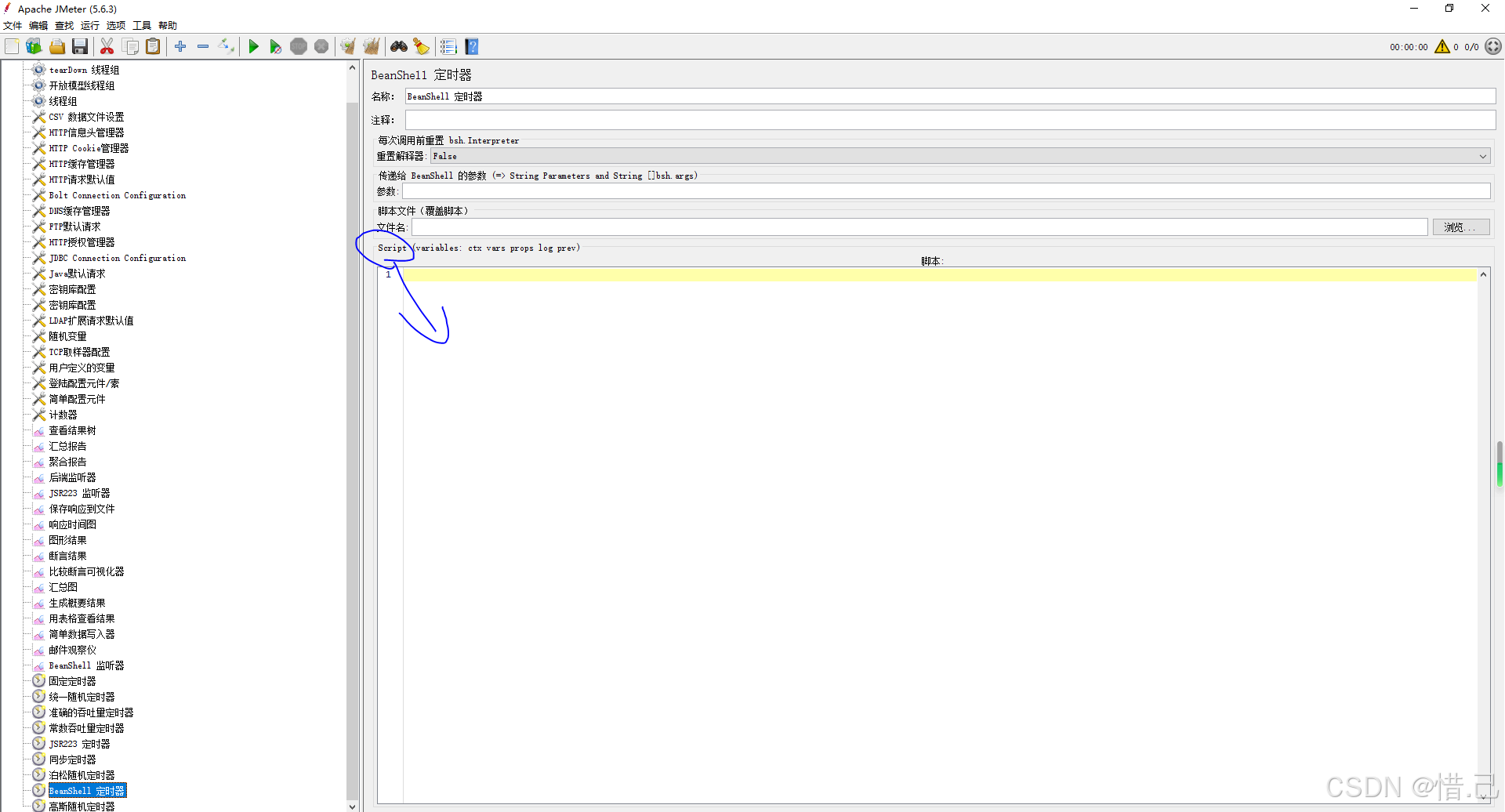
Jmeter中的定时器
4)定时器 1--固定定时器 功能特点 固定延迟:在每个请求之间添加固定的延迟时间。精确控制:可以精确控制请求的发送频率。简单易用:配置简单,易于理解和使用。 配置步骤 添加固定定时器 右键点击需要添加定时器的请求…...
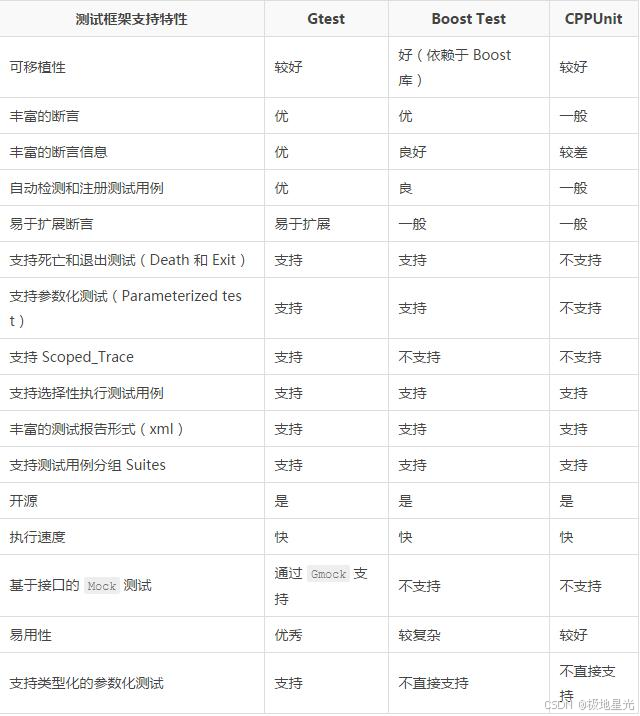
C++自动化测试:GTest 与 GitLab CI/CD 的完美融合
在现代软件开发中,自动化测试是保证代码质量和稳定性的关键手段。对于C项目而言,自动化测试尤为重要,它能有效捕捉代码中的潜在缺陷,提高代码的可维护性和可靠性。本文将重点介绍如何在C项目中结合使用Google Test(GTe…...

vscode连接远程开发机报错
远程开发机更新,vscode连接失败 报错信息 "install" terminal command done Install terminal quit with output: Host key verification failed. Received install output: Host key verification failed. Failed to parse remote port from server ou…...
神经网络12-Time-Series Transformer (TST)模型
Time-Series Transformer (TST) 是一种基于 Transformer 架构的深度学习模型,专门用于时序数据的建模和预测。TST 是 Transformer 模型的一个变种,针对传统时序模型(如 RNN、LSTM)在处理长时间依赖、复杂数据关系时的限制而提出的…...
IDEA 2024安装指南(含安装包以及使用说明 cannot collect jvm options 问题 四)
汉化 setting 中选择插件 完成 安装出现问题 1.可能是因为之前下载过的idea,找到连接中 文件,卸载即可。...
Fakelocation Server服务器/专业版 Centos7
前言:需要Centos7系统 Fakelocation开源文件系统需求 Centos7 | Fakelocation | 任务一 更新Centos7 (安装下载不再赘述) sudo yum makecache fastsudo yum update -ysudo yum install -y kernelsudo reboot//如果遇到错误提示为 Another app is curre…...
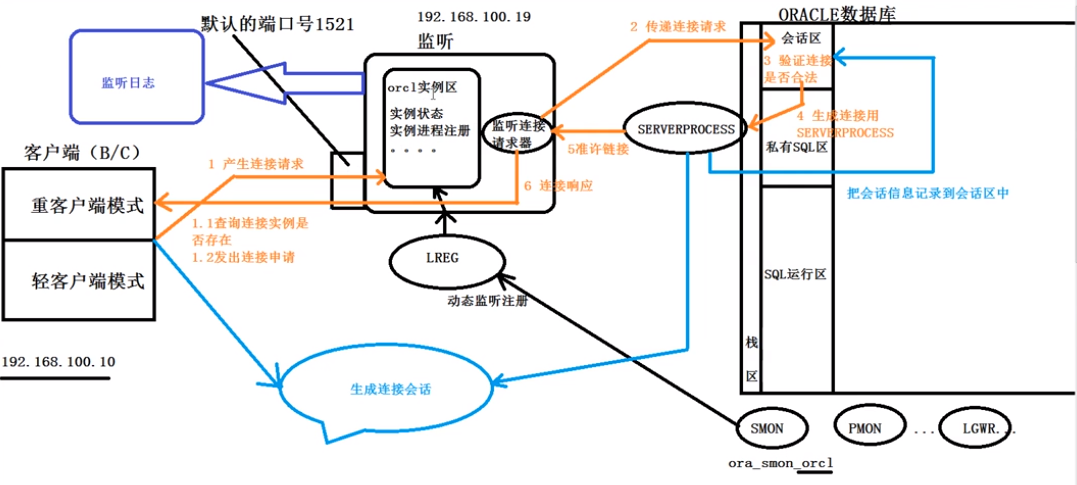
oracle的静态注册和动态注册
oracle的静态注册和动态注册 静态注册: 静态注册 : 指将实例的相关信息手动告知 listener 侦 听 器 , 可以使用netmgr,netca,oem 以及直接 vi listener.ora 文件来实现静态注册,在动态注册不稳定时使用,特点是:稳定&…...
机器翻译基础与模型 之四:模型训练
1、开放词表 1.1 大词表和未登陆词问题 理想情况下,机器翻译应该是一个开放词表(Open Vocabulary)的翻译任务。也就是,无论测试数据中包含什么样的词,机器翻译系统都应该能够正常翻译。 现实的情况是即使不断扩充词…...

Vue——响应式数据,v-on,v-bind,v-if,v-for(内含项目实战)
目录 响应式数据 ref reactive 事件绑定指令 v-on v-on 鼠标监听事件 v-on 键盘监听事件 v-on 简写形式 属性动态化指令 v-bind iuput标签动态属性绑定 img标签动态属性绑定 b标签动态属性绑定 v-bind 简写形式 条件渲染指令 v-if 遍历指令 v-for 遍历对象的值 遍历…...

ceph 18.2.4二次开发,docker镜像制作
编译环境要求 #需要ubuntu 22.04版本 参考https://docs.ceph.com/en/reef/start/os-recommendations/ #磁盘空间最好大于200GB #内存如果小于100GB 会有OOM的情况发生,需要重跑 目前遇到内存占用最高为92GB替换阿里云ubuntu 22.04源 将下面内容写入/etc/apt/sources.list 文件…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...
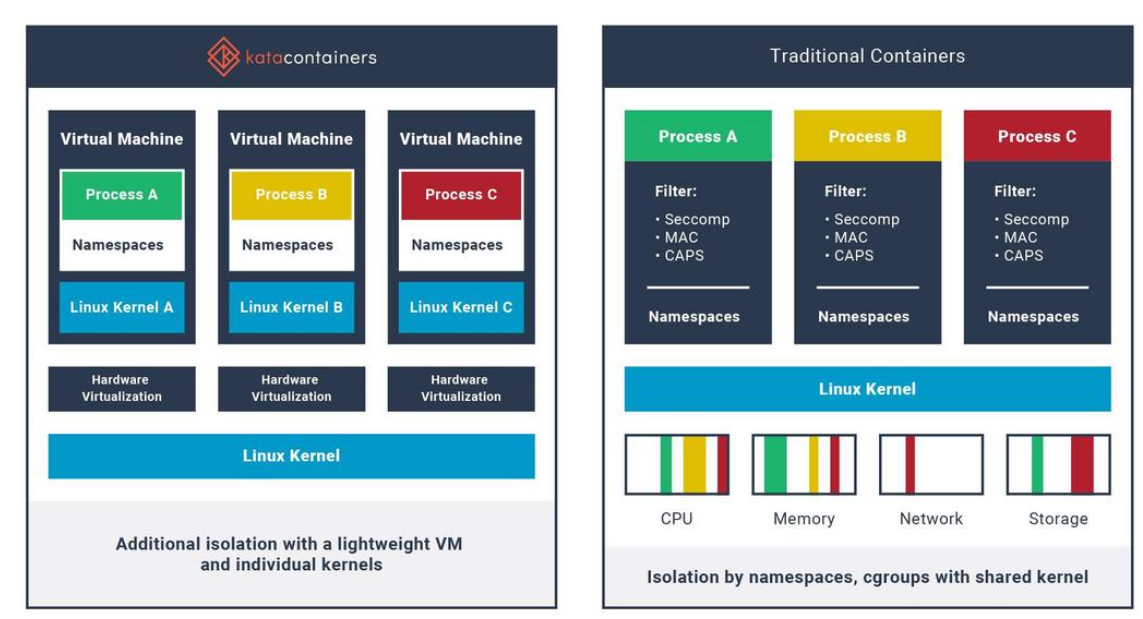
沙箱虚拟化技术虚拟机容器之间的关系详解
问题 沙箱、虚拟化、容器三者分开一一介绍的话我知道他们各自都是什么东西,但是如果把三者放在一起,它们之间到底什么关系?又有什么联系呢?我不是很明白!!! 就比如说: 沙箱&#…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...
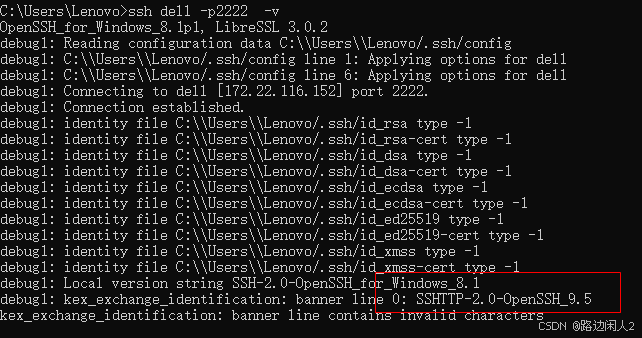
sshd代码修改banner
sshd服务连接之后会收到字符串: SSH-2.0-OpenSSH_9.5 容易被hacker识别此服务为sshd服务。 是否可以通过修改此banner达到让人无法识别此服务的目的呢? 不能。因为这是写的SSH的协议中的。 也就是协议规定了banner必须这么写。 SSH- 开头,…...