集合Queue、Deque、LinkedList、ArrayDeque、PriorityQueue详解
1、 Queue与Deque的区别
在研究java集合源码的时候,发现了一个很少用但是很有趣的点:Queue以及Deque;
平常在写leetcode经常用LinkedList向上转型Deque作为栈或者队列使用,但是一直都不知道Queue的作用,于是就直接官方文档好了。
Queue和Deque:
Deque是Queue的子接口;
从源码中可以得知:Queue以及Deque都是继承于Collection,Deque是Queue的子接口。
public interface Deque<E> extends Queue<E> {}
Queue——单端队列;Deque——双端队列;
从Deque的解释中,我们可以得知:Deque是double ended queue,我将其理解成双端队列,就是可以在首和尾都进行插入或删除元素。
而Queue的解释中,Queue就是简单的FIFO(先进先出)队列。所以在概念上来说,Queue是FIFO的单端队列,Deque是双端队列。
Queue常用子类——PriorityQueue;Deque常用子类——LinkedList以及ArrayDeque;
Queue有一个直接子类PriorityQueue。
而Deque中直接子类有两个:LinkedList以及ArrayDeque。
PriorityQueue:
我觉得重点就在圈定的两个单词:无边界的,优先级的堆。
从源码中,明显看到PriorityQueue的底层数据结构是数组,而无边界的形容,那么指明了PriorityQueue是自带扩容机制的,具体请看PriorityQueue的grow方法。
2 PriorityQueue源码解读
top k算法的经典实现是大顶堆和小顶堆,而在JAVA中可以用PriorityQueue实现小顶堆,话不多说,直接上代码
public static List<Integer> getTopMapNum(int[] arr, int k) {Queue<Integer> priorityQueue = new PriorityQueue();List<Integer> topKList = new ArrayList<>();if (arr == null || k > arr.length || k <= 0) {return topKList;}for (int i : arr) {if (priorityQueue.size() < k) {priorityQueue.add(i);} else {if (priorityQueue.peek() < i) {priorityQueue.poll();priorityQueue.add(i);}}}while (k-- > 0) {topKList.add(priorityQueue.poll());}return topKList;
}作为程序员,只知道简单的如何实现是不够的,最好能够深入源码,下面我们就来聊一聊PriorityQueue
PriorityQueue是优先队列,作用是保证每次取出的元素都是队列中权值最小的,这里涉及到了大小关系,元素大小的评判可以通过元素自身的自然顺序(使用默认的比较器),也可以通过构造时传入的比较器。
Java中PriorityQueue实现了Queue接口,不允许放入null元素;其通过堆实现,具体说是通过完全二叉树(complete binary tree)实现的小顶堆(任意一个非叶子节点的权值,都不大于其左右子节点的权值),也就意味着可以通过数组来作为PriorityQueue的底层实现。


上图中我们给每个元素按照层序遍历的方式进行了编号,如果你足够细心,会发现父节点和子节点的编号是有联系的,更确切的说父子节点的编号之间有如下关系:
leftNo = parentNo*2+1
rightNo = parentNo*2+2
parentNo = (nodeNo-1)/2
通过上述三个公式,可以轻易计算出某个节点的父节点以及子节点的下标。这也就是为什么可以直接用数组来存储堆的原因。
PriorityQueue的peek()和element操作是常数时间,add(), offer(), 无参数的remove()以及poll()方法的时间复杂度都是log(N)。
方法解析(JDK 1.8)
add()和offer
add()方法内部是调用的offer(),所以两个方法没啥区别,都是向队列中插入元素


新加入的元素可能会破坏小顶堆的性质,所以需要进行调整
/*** The number of times this priority queue has been* <i>structurally modified</i>. See AbstractList for gory details.*队列调整的次数*/
transient int modCount = 0; // non-private to simplify nested class access
/*** The number of elements in the priority queue.*队列中元素的个数*/
private int size = 0;
public boolean add(E e) {//add方法内部调用的offer方法return offer(e);
}
public boolean offer(E e) {if (e == null)throw new NullPointerException();//队列调整的次数modCount++;int i = size;//如果队列元素个数大于等于队列的长度,则需要进行扩容if (i >= queue.length)grow(i + 1);size = i + 1;//如果是第一个元素,直接插入即可if (i == 0)queue[0] = e;elsesiftUp(i, e);//如果不是第一个元素,则需要进行调整return true;
}
/*** Increases the capacity of the array.*队列扩容* @param minCapacity the desired minimum capacity*/
private void grow(int minCapacity) {//原始队列容量int oldCapacity = queue.length;// Double size if small; else grow by 50%//如果原始队列容量没有超过64,则翻倍扩容,否则扩容50%int newCapacity = oldCapacity + ((oldCapacity < 64) ?(oldCapacity + 2) :(oldCapacity >> 1));// overflow-conscious code//如果扩容后的队列大小超过了最大队列大小,则需要进行特殊处理if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);queue = Arrays.copyOf(queue, newCapacity);
}
private static int hugeCapacity(int minCapacity) {if (minCapacity < 0) // overflowthrow new OutOfMemoryError();return (minCapacity > MAX_ARRAY_SIZE) ?Integer.MAX_VALUE :MAX_ARRAY_SIZE;
}
/*** Inserts item x at position k, maintaining heap invariant by* promoting x up the tree until it is greater than or equal to* its parent, or is the root.** To simplify and speed up coercions and comparisons. the* Comparable and Comparator versions are separated into different* methods that are otherwise identical. (Similarly for siftDown.)** @param k the position to fill* @param x the item to insert* 元素添加*/
private void siftUp(int k, E x) {//使用构造方法传进来的比较器if (comparator != null)siftUpUsingComparator(k, x);elsesiftUpComparable(k, x);//使用默认的比较器
}
private void siftUpComparable(int k, E x) {Comparable<? super E> key = (Comparable<? super E>) x;while (k > 0) {//获取父节点的下标int parent = (k - 1) >>> 1;//父节点的元素值Object e = queue[parent];//如果新插入的元素比父节点的元素值大,循环结束,新插入节点直接插入最后即可if (key.compareTo((E) e) >= 0)break;//否则需要把父节点元素值放到新插入节点的下标(可以理解为父节点与新插入元素调换位置)queue[k] = e;//重复进行,知道父节点比子节点小k = parent;}//新插入元素放入排序后的下标queue[k] = key;
}poll 类似,poll 从上往下进行,然后将左右进行比较,将小的一个和 父节点交换
3 LinkedList以及ArrayDeque:
从官方解释来看,ArrayDeque是无初始容量的双端队列,LinkedList则是双向链表。
而我们还能看到,ArrayDeque作为队列时的效率比LinkedList要高。
而在栈的使用场景下,无疑具有尾结点,不需判空的LinkedList更为高效。
演示ArrayDeque作为队列以及LinkedList作为栈的使用:
private static void usingAsQueue() {Deque<Integer> queue=new ArrayDeque<>();System.out.println("队列为空:"+queue.isEmpty()); //判断队列是否为空queue.addLast(12); //添加元素System.out.println(queue.peekFirst()); //获取队列首部元素System.out.println(queue.pollFirst()); //获取并移除栈顶元素}private static void usingAsStack() {//作为栈使用Deque<Integer> stack=new LinkedList<>();System.out.println("栈为空:"+stack.isEmpty()); //判断栈是否为空stack.addFirst(12);//添加元素System.out.println(stack.peekFirst()); //获取栈顶元素System.out.println(stack.pollFirst()); //获取并移除栈顶元素}小提示:
在Deque中,获取并移除元素的方法有两个,分别是removeXxx以及peekXxx。
存在元素时,两者的处理都是一样的。
但是当Deque内为空时,removeXxx会直接抛出NoSuchElementException,
而peekXxx则会返回null。
所以无论在实际开发或者算法时,推荐使用peekXxx方法。
其实ArrayDeque和LinkedList都可以作为栈以及队列使用,但是从执行效率来说,ArrayDeque作为队列,以及LinkedList作为栈使用,会是更好的选择。
注意:
ArrayDeque 是 Deque 接口的一种具体实现,是依赖于可变数组来实现的。ArrayDeque 没有容量限制,可根据需求自动进行扩容。ArrayDeque 可以作为栈来使用,效率要高于 Stack。ArrayDeque 也可以作为队列来使用,效率相较于基于双向链表的 LinkedList 也要更好一些。注意,ArrayDeque 不支持为 null 的元素。
之后,再说为什么建议使用ArrayDeque而不是LinkedList:
链表比数组花费更多空间
链表的随机访问性质比数组差(虽然这个对栈来说问题不大)
链表的每次插入和删除都涉及到一个节点对象的创建和弃用,非常低效和浪费空间,而动态数组几乎是0花费的(数组充满时重新拷贝除外)
链表是非连续的,访问时候不能充分利用cpu cache
所以无论是栈还是队列,JDK都是建议使用ArrayDeque而不是LinkedList实现,ArrayDeque比较复杂的一点就是需要指定初始大小,当然你不指定也行。但是它的效率确实是比LinkedList高的
小结:
PriorityQueue可以作为堆使用,而且可以根据传入的Comparator实现大小的调整,会是一个很好的选择。
ArrayDeque可以作为栈或队列使用,但是栈的效率不如LinkedList高,通常作为队列使用。
LinkedList可以作为栈或队列使用,但是队列的效率不如ArrayQueue高,通常作为栈使用。
Queue和Deque的方法区别:
在java中,Queue被定义成单端队列使用,Deque被定义成双端队列使用。
而由于双端队列的定义,Deque可以作为栈或者队列使用;
而Queue只能作为队列或者依赖于子类的实现作为堆使用。
方法上的区别如下:

add offer add 底层调用offer 无区别
remove 无元素 抛出异常 poll 返回null 删除元素
peek element 不删除元素 ,element 无元素 抛出异常,peek 返回null
LinkedList与ArrayDeque在栈与队列中的使用
LinkedList
增加:
add(E e):在链表后添加一个元素; 通用方法
addLast(E e):在链表尾部添加一个元素; 特有方法
offer(E e):在链表尾部插入一个元素
offerLast(E e):JDK1.6本之后,在尾部添加; 特有方法
特点:add 与 addLast 一个有返回值 boolean,一个无
offer 与 add 与 offerLast 一样
addFirst(E e):在链表头部插入一个元素; 特有方法
offerFirst(E e):JDK1.6版本之后,在头部添加; 特有方法
特点:offerFirst 有返回值 addFirst无
add(int index, E element):在指定位置插入一个元素。
删除:
remove() :移除链表中第一个元素; 通用方法
removeFirst() 移除第一个元素
pollFirst():删除头; 特有方法
pop():和removeFirst方法一致,删除头。 ==
poll():查询并移除第一个元素 特有方法 ==
特点:remove 抛异常,poll 返回null pop 与 removeFirst remove一致
remove(E e):移除指定元素; 通用方法
removeFirst(E e):删除头,获取元素并删除; 特有方法
removeLast(E e):删除尾; 特有方法
pollLast():删除尾; 特有方法
查:
poll():查询并移除第一个元素 特有方法
pollFirst():查询并删除头; 特有方法
getFirst():获取第一个元素; 特有方法
peek():获取第一个元素,但是不移除; 特有方法
peekFirst():获取第一个元素,但是不移除;
特点:poll 弹出数据,无数据返回null :getFirst 无数据 抛出异常, peek 返回数据,无数据返回null
getLast():获取最后一个元素; 特有方法
peekLast():获取最后一个元素,但是不移除;
pollLast():删除尾; 特有方法
get(int index):按照下标获取元素; 通用方法
ArrayDeque
特点:
ArrayDeque实现了Deque接口。可当作栈来用,效率高于stack。也可当作队列来用,效率高于LinkedList。
底层用可变数组实现,无容量限制。
ArrayDeque是不安全的。
增加:
addFirst(E e)在数组前面添加元素
addLast(E e)在数组后面添加元素
offerFirst(E e)在数组前面添加元素,并返回是否添加成功
offerLast(E e)在数组后添加元素,并返回是否添加成功
push(E e):与addFirst方法一致
offer(E e):在链表尾部插入一个元素
删除:
removeFirst()删除第一个元素,并返回删除元素的值,如果为null,将抛出异常
removeLast()删除最后一个元素,并返回删除元素的值,如果为null,将抛出异常
pollFirst()删除第一个元素,并返回删除元素的值,如果为null,将返回null
pollLast()删除最后一个元素,并返回删除元素的值,如果为null,将返回null
pop():和removeFirst方法一致,删除头。 ==
poll():查询并移除第一个元素 特有方法
查:
getFirst()获取第一个元素,如果为null,将抛出异常
getLast()获取最后一个元素,如果为null,将抛出异常
peek():获取第一个元素,但是不移除; 特有方法
注意
add() 和 offer()的区别
在容量已满的情况下,add() 方法会抛出IllegalStateException异常,offer() 方法只会返回 false
remove方法和poll方法都是删除队列的头元素,remove方法,队列为空的情况下将抛异常,而poll方法将返回null;
element和peek方法都是返回队列的头元素,但是不删除头元素,区别在与element方法在队列为空的情况下,将抛异常,而peek方法将返回null。
相关文章:
集合Queue、Deque、LinkedList、ArrayDeque、PriorityQueue详解
1、 Queue与Deque的区别 在研究java集合源码的时候,发现了一个很少用但是很有趣的点:Queue以及Deque; 平常在写leetcode经常用LinkedList向上转型Deque作为栈或者队列使用,但是一直都不知道Queue的作用,于是就直接官方…...

谈一下开源生态对 AI人工智能大模型的促进作用
谈一下开源生态对 AI人工智能大模型的促进作用 作者:开源呼叫中心系统 FreeIPCC,Github地址:https://github.com/lihaiya/freeipcc 开源生态对大模型的促进作用是一个多维度且深远的话题,它不仅加速了技术创新的速度,…...

基于python的机器学习(四)—— 聚类(一)
目录 一、聚类的原理与实现 1.1 聚类的概念和类型 1.2 如何度量距离 1.2.1 数据的类型 1.2.2 连续型数据的距离度量方法 1.2.3 离散型数据的距离度量方法 1.3 聚类的基本步骤 二、层次聚类算法 2.1 算法原理和实例 2.2 算法的Sklearn实现 2.2.1 层次聚类法的可视化实…...

实时数据开发 | 怎么通俗理解Flink容错机制,提到的checkpoint、barrier、Savepoint、sink都是什么
今天学Flink的关键技术–容错机制,用一些通俗的比喻来讲这个复杂的过程。参考自《离线和实时大数据开发实战》 需要先回顾昨天发的Flink关键概念 检查点(checkpoint) Flink容错机制的核心是分布式数据流和状态的快照,从而当分布…...

C++设计模式-策略模式-StrategyMethod
动机(Motivation) 在软件构建过程中,某些对象使用的算法可能多种多样,经常改变,如果将这些算法都编码到对象中,将会使对象变得异常复杂;而且有时候支持不使用的算法也是一个性能负担。 如何在运…...

小程序免备案:快速部署与优化的全攻略
小程序免备案为开发者提供了便捷高效的解决方案,省去繁琐的备案流程,同时通过优化网络性能和数据传输,保障用户体验。本文从部署策略、应用场景到技术实现,全面解析小程序免备案的核心优势。 小程序免备案:快速部署与优…...
Jmeter中的定时器
4)定时器 1--固定定时器 功能特点 固定延迟:在每个请求之间添加固定的延迟时间。精确控制:可以精确控制请求的发送频率。简单易用:配置简单,易于理解和使用。 配置步骤 添加固定定时器 右键点击需要添加定时器的请求…...
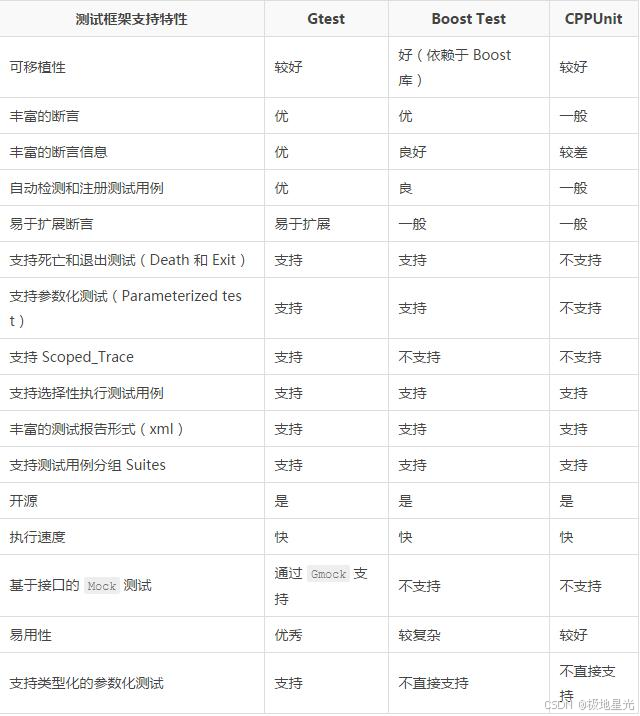
C++自动化测试:GTest 与 GitLab CI/CD 的完美融合
在现代软件开发中,自动化测试是保证代码质量和稳定性的关键手段。对于C项目而言,自动化测试尤为重要,它能有效捕捉代码中的潜在缺陷,提高代码的可维护性和可靠性。本文将重点介绍如何在C项目中结合使用Google Test(GTe…...

vscode连接远程开发机报错
远程开发机更新,vscode连接失败 报错信息 "install" terminal command done Install terminal quit with output: Host key verification failed. Received install output: Host key verification failed. Failed to parse remote port from server ou…...
神经网络12-Time-Series Transformer (TST)模型
Time-Series Transformer (TST) 是一种基于 Transformer 架构的深度学习模型,专门用于时序数据的建模和预测。TST 是 Transformer 模型的一个变种,针对传统时序模型(如 RNN、LSTM)在处理长时间依赖、复杂数据关系时的限制而提出的…...
IDEA 2024安装指南(含安装包以及使用说明 cannot collect jvm options 问题 四)
汉化 setting 中选择插件 完成 安装出现问题 1.可能是因为之前下载过的idea,找到连接中 文件,卸载即可。...
Fakelocation Server服务器/专业版 Centos7
前言:需要Centos7系统 Fakelocation开源文件系统需求 Centos7 | Fakelocation | 任务一 更新Centos7 (安装下载不再赘述) sudo yum makecache fastsudo yum update -ysudo yum install -y kernelsudo reboot//如果遇到错误提示为 Another app is curre…...
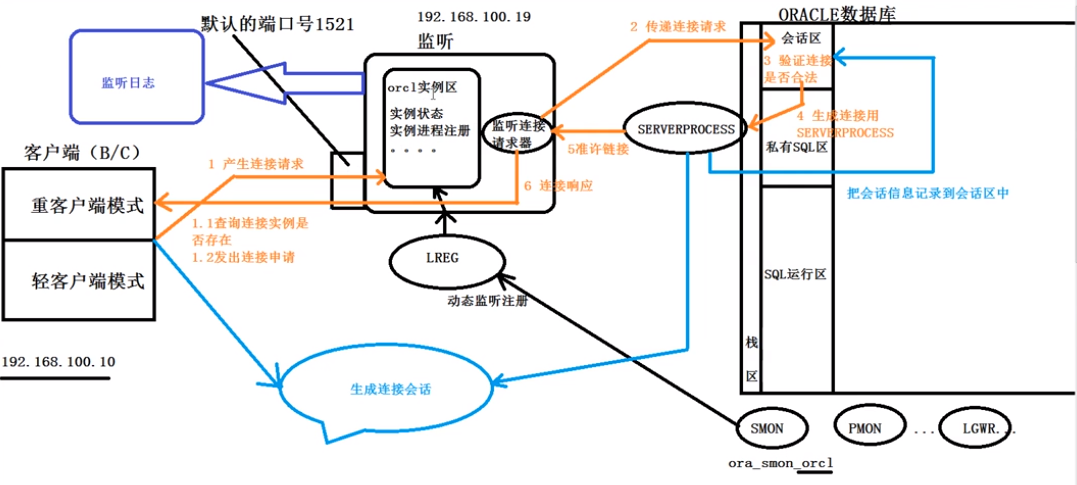
oracle的静态注册和动态注册
oracle的静态注册和动态注册 静态注册: 静态注册 : 指将实例的相关信息手动告知 listener 侦 听 器 , 可以使用netmgr,netca,oem 以及直接 vi listener.ora 文件来实现静态注册,在动态注册不稳定时使用,特点是:稳定&…...
机器翻译基础与模型 之四:模型训练
1、开放词表 1.1 大词表和未登陆词问题 理想情况下,机器翻译应该是一个开放词表(Open Vocabulary)的翻译任务。也就是,无论测试数据中包含什么样的词,机器翻译系统都应该能够正常翻译。 现实的情况是即使不断扩充词…...

Vue——响应式数据,v-on,v-bind,v-if,v-for(内含项目实战)
目录 响应式数据 ref reactive 事件绑定指令 v-on v-on 鼠标监听事件 v-on 键盘监听事件 v-on 简写形式 属性动态化指令 v-bind iuput标签动态属性绑定 img标签动态属性绑定 b标签动态属性绑定 v-bind 简写形式 条件渲染指令 v-if 遍历指令 v-for 遍历对象的值 遍历…...

ceph 18.2.4二次开发,docker镜像制作
编译环境要求 #需要ubuntu 22.04版本 参考https://docs.ceph.com/en/reef/start/os-recommendations/ #磁盘空间最好大于200GB #内存如果小于100GB 会有OOM的情况发生,需要重跑 目前遇到内存占用最高为92GB替换阿里云ubuntu 22.04源 将下面内容写入/etc/apt/sources.list 文件…...

产品经理的项目管理课
各位产品经理,大家下午好,今天我给大家分享的主题是“产品经理如何做好项目管理”。 其实,我是不想分享这个主题的,是因为在周会中大家投票对这个议题最感兴趣,11个同学中有7个投了这个主题,所以才有了这次…...

Linux 下的 AWK 命令详细指南与示例
目录 简介AWK 的主要特性基本语法示例1. 打印文件的所有行2. 打印特定字段3. 打印匹配模式的行4. 基于条件过滤并打印5. 使用内置变量6. 执行算术运算7. 字符串操作8. 使用 BEGIN 和 END 块9. 处理分隔符文件 高级功能自定义脚本使用外部变量 总结 简介 AWK 是 Linux 中功能强…...

FPGA经验谈系列文章——8、复位的设计
前言 剑法往往有着固定的招式套路,而写代码似乎也存在类似的情况。不知从何时起,众多 FPGA 工程师们在编写代码时开启了一种关于 always 语句块的流行写法,那就是: always @(posedge i_clk or negedge i_rstn) 就笔者所经历的诸多项目以及所接触到的不少工程师而言,大家在…...

C#里怎么样实现操作符重载?
C#里怎么样实现操作符重载? 一般情况,都是表示某种类型的类时,才会使用到操作符重载。 比如实现一个复数类。 在C#中,重载运算符是通过在类或结构中定义特殊的方法来实现的,这些方法的名称是operator关键字后跟要重载的运算符。例如,要重载+运算符,可以定义一个名为op…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

Java求职者面试指南:Spring、Spring Boot、Spring MVC与MyBatis技术解析
Java求职者面试指南:Spring、Spring Boot、Spring MVC与MyBatis技术解析 一、第一轮基础概念问题 1. Spring框架的核心容器是什么?它的作用是什么? Spring框架的核心容器是IoC(控制反转)容器。它的主要作用是管理对…...
ubuntu22.04有线网络无法连接,图标也没了
今天突然无法有线网络无法连接任何设备,并且图标都没了 错误案例 往上一顿搜索,试了很多博客都不行,比如 Ubuntu22.04右上角网络图标消失 最后解决的办法 下载网卡驱动,重新安装 操作步骤 查看自己网卡的型号 lspci | gre…...

简单介绍C++中 string与wstring
在C中,string和wstring是两种用于处理不同字符编码的字符串类型,分别基于char和wchar_t字符类型。以下是它们的详细说明和对比: 1. 基础定义 string 类型:std::string 字符类型:char(通常为8位)…...
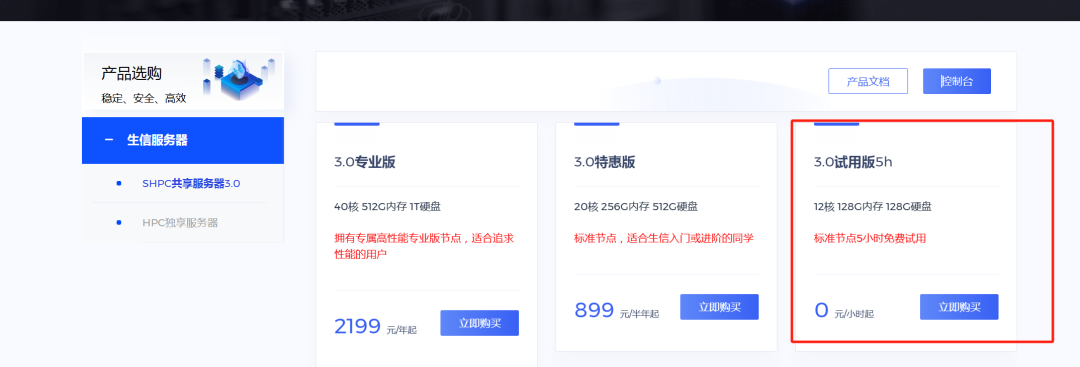
生信服务器 | 做生信为什么推荐使用Linux服务器?
原文链接:生信服务器 | 做生信为什么推荐使用Linux服务器? 一、 做生信为什么推荐使用服务器? 大家好,我是小杜。在做生信分析的同学,或是将接触学习生信分析的同学,<font style"color:rgb(53, 1…...