机器翻译基础与模型 之四:模型训练
1、开放词表
1.1 大词表和未登陆词问题
理想情况下,机器翻译应该是一个开放词表(Open Vocabulary)的翻译任务。也就是,无论测试数据中包含什么样的词,机器翻译系统都应该能够正常翻译。
现实的情况是即使不断扩充词表,也不可能覆盖所有可能的单词。这个问题在使用受限词表时会更加严重,因为低频词和未见过的词都会被看作未登录词。这时会将这些单词用符号 <UNK> 代替。
在建模中,词表中的每一个单词都会被转换为分布式(向量)表示,即词嵌入。如果要覆盖更多的翻译现象,词表会不断膨胀,并带来两个问题:
• 数据稀疏。很多不常见的低频词包含在词表中,而这些低频词的词嵌入表示很难得到充分学习。
• 参数及计算量的增大。大词表会增加词嵌入矩阵的大小,同时也会显著增加输出层中线性变换和 Softmax 的计算量。
1.2 子词
有没有一种方式能够兼顾基于单词和基于字符方法的优点的方法,来解决开放词表翻译问题?
常用的手段包括两种,一种是采用字词融合的方式构建词表,将未知单词转换为字符的序列并通过特殊的标记将其与普通的单词区分开来。而另一种方式是将单词切分为子词(Sub-word),它是介于单词和字符中间的一种语言单元表示形式。
在神经机器翻译中,基于子词的切分是很常用的数据处理方法,称为子词切分。主要包括三个步骤:
• 对原始数据进行分词操作;
• 构建符号合并表;
• 根据合并表,将字符合并为子词。
这里面的核心是如何构建符号合并表。
1.3 双字节编码
字节对编码或双字节编码(BPE)是一种常用的子词词表构建方法。把子词切分看作是学习对自然语言句子进行压缩编码表示的问题。
不仅可以单独对源语言和目标语言句子进行子词的切分,也可以联合两种语言,共同进行子词切分,被称作双字节联合编码(Joint-BPE)。相比于单语 BPE, Joint-BPE 可以增加两种语言子词切分的一致性。对于相似语系中的语言,如英语和德语,常使用 Joint-BPE 的方法联合构建词表。而对于汉语和英语这些差异比较大的语种,则需要独立地进行子词切分。
1.4 其他方法
基于 Word Piece 的子词切分方法利用语言模型进行子词词表的构造。本质上,基于语言模型的方法和基于 BPE 的方法的思路相同,即通过合并字符和子词不断生成新的子词。它们的区别在于合并子词的方式,基于BPE 的方法选择出现频次最高的连续字符进行合并,而基于语言模型的方法则是根据语言模型输出的概率选择要合并哪些子词。
一些规范化方法来避免切分错误引起的翻译效果变差:
• 子词规范化方法。其做法是根据 1-gram 语言模型采样出多种子词切分候选。之后,最大化整个句子的概率为目标来构建词表。
• BPE-Dropout。在训练时,按照一定概率 p 随机丢弃一些可行的合并操作,从而产生不同的子词切分结果。相当于在子词的粒度上对输入的序列进行扰动,进而达到增加训练健壮性的目的。
• 动态规划编码(Dynamic Programming Encoding, DPE)。引入了混合字符-子词的切分方式,将句子的子词切分看作一种隐含变量。机器翻译解码端的输入是基于字符表示的目标语言序列,推断时将每个时间步的输出映射到预先设定好的子词词表之上,得到当前最可能的子词结果。
2、正则化
用于缓解过拟合问题。
适定的(Well-posed)。所谓适定解,需要满足三个条件:解是存在的、解是唯一的、解是稳定的(即 y 微小的变化会导致 x 微小的变化,也被称作解连续)。所有不存在唯一稳定解的问题都被称作不适定问题(Ill-posed Problem)。
存在性和唯一性并不会对机器学习方法造成太大困扰,因为在实践中往往会找到近似的解。但是,解的稳定性却给神经机器翻译带来了很大的挑战。
在神经机器翻译模型中,稳定性训练还面临两方面问题:
• 观测数据不充分。从样本的表示空间上看,对于没有观测样本的区域,根本无法知道真实解的样子,因此也很难描述这些样本的性质,更不用说稳定性训练了。
• 数据中存在噪声。噪声问题是稳定性训练最大的挑战之一。因为,即使是很小的噪声,也可能会导致解的巨大变化。
以上问题体现出来的现象就是过拟合。因为训练数据有限且存在噪声,因此模型参数会过分拟合噪声数据。正则化正是针对这个问题。有时候,正则化也被称作降噪(Denoising)。
正则化的一种实现是在训练目标中引入一个正则项。在神经机器翻译中,引入正则项的训练目标为:![]() 其中, w 是模型参数, Loss(w) 是损失函数, R(w) 是正则项, λ 是正则项的系数,用于控制正则化对训练影响的程度。
其中, w 是模型参数, Loss(w) 是损失函数, R(w) 是正则项, λ 是正则项的系数,用于控制正则化对训练影响的程度。
R(w) 通常也可以被看作是一种先验,因为在数据不充分且存在噪声的情况下,可以根据一些先验知识让模型偏向正确的方向一些,而不是一味地根据受噪声影响的 Loss(w) 进行优化。引入正则化后的模型可以获得更好的泛化(Generalization)能力,在新的未见数据上表现会更好。
2.1 L1/L2正则化

从几何的角度看, L1和 L2 正则项都是有物理意义的。二者都可以被看作是空间上的一个区域,比如,在二维平面上, l1 范数表示一个以 0 点为中心的菱形, l2 范数表示一个以 0 点为中心的圆。
L1 和 L2正则项引入了一个先验:模型的解不应该离 0 点太远。而 L1 和 L2 正则项实际上是在度量这个距离。L1 和 L2 正则项的目的是防止模型为了匹配少数(噪声)样本而导致模型参数的值过大。反过来说, L1 和 L2 正则项会鼓励那些参数值在 0 点附近的情况。
2.2 标签平滑
标签平滑的思想很简单:答案所对应的单词不应该“独享”所有的概率,其它单词应该有机会作为答案。在复杂模型的参数估计中,往往需要给未见或者低频事件分配一些概率,以保证模型具有更好的泛化能力。标签平滑也可以被看作是对损失函数的一种调整,并引入了额外的先验知识。
2.3 Dropout
随着每一层神经元数量的增加以及网络结构的复杂化,神经元之间会出现相互适应(Co-adaptation)的现象。所谓相互适应是指,一个神经元对输出的贡献与同一层其它神经元的行为是
相关的,也就是说这个神经元已经适应到它周围的“环境”中。
相互适应的好处在于神经网络可以处理更加复杂的问题,因为联合使用两个神经元要比单独使用每个神经元的表示能力强。不过另一方面,相互适应会导致模型变得更加“脆弱”。因为相互适应的神经元可以更好的描述训练数据中的现象,但是在测试数据上,由于很多现象是未见的,细微的扰动
会导致神经元无法适应。具体体现出来就是过拟合问题。
Dropout 方法的另一种解释是,在训练中屏蔽掉一些神经元相当于从原始的神经网络中抽取出了一个子网络。这样,每次训练都在一个随机生成的子网络上进行,而不同子网络之间的参数是共享的。在推断时,则把所有的子网络集成到一起。这种思想也有一些集成学习(Ensemble Learning)的味道,只不过 Dropout 中子模型(或子网络)是在指数级空间中采样出来的。由于 Dropout 可以很好的缓解复杂神经网络模型的过拟合问题,因此也成为了大多数神经机器翻译系统的标配。
对于深层神经网络,Layer Dropout 也是一种有效的防止过拟合的方法。
3、对抗样本训练
决定神经网络模型健壮性的因素主要包括训练数据、模型结构、正则化方法等。仅仅从模型的角度来改善健壮性一般是较为困难的。一种简单直接的方法是从训练样本出发,让模型在学习的过程中能对样本中的扰动进行处理,进而在推断时更加健壮。具体来说,可以在训练过程中构造有噪声的样本,即基于对抗样本(Adversarial Examples)进行对抗训练(Adversarial Training)
3.1 对抗样本及对抗攻击
通过在原样本上增加一些难以察觉的扰动,从而使模型得到错误判断的样本被称为对抗样本。
对于模型的输入 x 和输出 y,对抗样本形式上可以被描述为:

其中, (x′,y) 为输入中含有扰动的对抗样本,函数 C(·) 为模型。公式中 Ψ(x,x′)表示扰动后的输入 x′ 和原输入 x 之间的距离, ε 表示扰动的受限范围。当模型对包含噪声的数据容易给出较差的结果时,往往意味着该模型的抗干扰能力差,因此可以利用对抗样本检测现有模型的健壮性。
采用类似数据增强的方式将对抗样本混合至训练数据中,能够使模型得到稳定的预测能力,这种方式也被称为对抗训练。
关键问题:如何生成对抗样本?
通过当前模型 C 和样本 (x,y),生成对抗样本的过程被称为对抗攻击(Adversarial Attack)。
对抗攻击可以被分为黑盒攻击和白盒攻击。
在白盒攻击中,攻击算法可以访问模型的完整信息,包括模型结构、网络参数、损失函数、激活函数、输入和输出数据等。
黑盒攻击通常依赖启发式方法来生成对抗样本,不需要知道神经网络的详细信息,仅仅通过访问模型的输入和输出就可以达到攻击的目的。由于神经网络其本身便是一个黑盒模型,因此在神经网络的相关应用中黑盒攻击方法更加实用。
3.2 基于黑盒攻击的方法
实现对抗样本生成的方法:
(1)对文本加噪声。噪声可以分为自然噪声和人工噪声。自然噪声一般是指在语料库中自然出现的错误,如输入错误、拼写错误等。人为噪声是通过人工设计的自动方法修改文本,例如,可以通过规则或是噪声生成器,在干净的数据中以一定的概率引入拼写错误、语法错误等。
(2)通过文本编辑的方式,在不改变语义的情况下尽可能修改文本,从而构建对抗样本。文本的编辑方式主要包括交换、插入、替换和删除操作。
可以利用如 FGSM 等算法,验证文本中每一个单词的贡献度,同时为每一个单词构建一个候选池,包括该单词的近义词、拼写错误词、同音词等。对于贡献度较低的词,如语气词、副词等,可以使用插入、删除操作进行扰动。对于其他的单词,可以在候选池中选择相应的单词并进行替换。其中,交换操作可以是基于词级别的,比如交换序列中的单词,也可以是基于字符级别的,例如交换单词中的字符。重复进行上述的编辑操作,直至编辑出的文本可以误导模型做出错误的判断。
(3)回译技术也是生成对抗样本的一种有效方式。回译就是,通过反向模型将目标语言翻译成源语言,并将翻译得到的双语数据用于模型训练。
3.3 基于白盒攻击的方法
在模型内部增加扰动。
(1)在每一个词的词嵌入上,累加一个正态分布的变量,之后将其作为模型的最终输入。
(2)可以在编码器输出中引入额外的噪声,能起到与在层输入中增加扰动相类似的效果。
(3)可以使用基于梯度的方法来生成对抗样本 。
4、学习策略
4.1 模型训练时遇到的一些问题:
(1)曝光偏执问题。
(2)训练目标函数(极大似然估计)与任务评价指标(BLEU等)不一致问题。
4.3 强化学习方法
(1)最小风险训练
引入了评价指标作为损失函数,并优化模型将预期风险降至最低。
(2)演员-评价家方法
演员就是策略 p,而评论家就是动作价值函数 Q 的估计 Q˜。
5、知识蒸馏
把“大”模型的知识传递给“小”模型,就是知识蒸馏的基本思想。
5.1 什么是知识蒸馏
知识蒸馏可以被看作是一种知识迁移的手段。如果把“大”模型的知识迁移到“小”模型,这种方法的直接结果就是模型压缩(Model Compression)
知识蒸馏基于两个假设:
• “知识”在模型间是可迁移的。即一个模型中蕴含的规律可以被另一个模型使用。
• 模型所蕴含的“知识”比原始数据中的“知识”更容易被学习到。
第二个假设对应了机器学习中的一大类问题 —— 学习难度(Learning Difficulty)。所谓难度是指:在给定一个模型的情况下,需要花费多少代价对目标任务进行学习。
知识蒸馏本身也体现了一种“自学习”的思想。即利用模型(自己)的预测来教模型(自己)。这样既保证了知识可以向更轻量的模型迁移,同时也避免了模型从原始数据中学习难度大的问题。在需要一个性能优越,存储较小的模型时,也会考虑将大模型压缩得到更轻量模型。
通常把“大”模型看作是传授知识的“教师”,被称作教师模型(Teacher Model);把“小”模型看作是接收知识的“学生”,被称作学生模型(Student Model)。比如,可以把 Transformer-Big 看作是教师模型,把 Transformer-Base 看作是学生模型。
5.2 知识蒸馏的基本方法
知识蒸馏的基本思路是让学生模型尽可能去拟合教师模型,通常有两种实现方式:
(1)基于单词的知识蒸馏(Word-level Knowledge Distillation)
该方法的目标是使得学生模型的预测(分布)尽可能逼近教师模型的预测(分布)。基于单词的知识蒸馏的损失函数被定义为:![]()
实际上在最小化教师模型和学生模型输出分布之间的交叉熵。
(2)基于序列的知识蒸馏(Sequence-level Knowledge Distillation)
基于序列的知识蒸馏希望在序列整体上进行拟合。其损失函数被定义为:![]() 考虑用教师模型的真实输出序列 yˆ 来代替整个空间,即假设 Pt(ˆ y|x) = 1。于是,目标函数变为:
考虑用教师模型的真实输出序列 yˆ 来代替整个空间,即假设 Pt(ˆ y|x) = 1。于是,目标函数变为:![]()
这样的损失函数最直接的好处是,知识蒸馏的流程会非常简单。因为只需要利用教师模型将训练数据(源语言)翻译一遍,之后把它的输出替换为训练数据的目标语言部分。之后,利用新得到的双语数据训练学生模型即可。
5.3 机器翻译中的知识蒸馏
通过知识蒸馏,教师模型构造伪数据,之后让学生模型从伪数据中学习。另一个问题是:如何构造教师模型和学生模型。
以 Transformer 为例,通常有两种思路:
(1)固定教师模型,通过减少模型容量的方式设计学生模型。
使用容量较大的模型作为教师模型,然后通过将神经网络变“窄”、变“浅”的方式得到学生模型。例如,可以用 Transformer-Big做教师模型,然后把它的解码器变为一层网络,作为学生模型。
(2)固定学生模型,通过模型集成的方式设计教师模型。
可以组合多个模型生成更高质量的译文。比如,融合多个 Transformer-Big 模型(不同参数初始化方式),之后学习一个 Transformer-Base 模型。
(3)迭代式知识蒸馏的方式。
6、基于样本价值的学习
当训练机器翻译模型时,通常是将全部的样本以随机的方式输入模型中进行学习,换句话说,就是让模型来平等地对待所有的训练样本。这种方式忽略了样本对于模型训练的“价值”,显然,更加理想的方式是优先使用价值高的样本对模型进行训练。
围绕训练样本的价值差异产生了诸如数据选择、主动学习、课程学习等一系列的样本使用方法,这些学习策略本质上是在不同任务、不同背景、不同假设下,对如何高效地利用训练样本这一问题进行求解。
6.1 数据选择
数据选择则是缓解领域差异和标签噪声等问题的一种有效手段,它的学习策略是让模型有选择地使用样本进行学习。
上述方法都基于一个假设:在训练过程中,每个样本都是有价值的,且这种价值可以计算。
价值在不同任务背景下有不同的含义,这与任务的特性有关。比如,在领域相关数据选择中,样本的价值表示这个样本与领域的相关性;在数据降噪中,价值表示样本的可信度;在主动学习中,价值表示样本的难易程度。
(1)领域相关的数据选择
机器翻译的领域适应(Domain Adaptation),即从资源丰富的领域(称为源领域, Source Domain)向资源稀缺的领域(称为目标领域, Target Domain)迁移。
数据选择(Data Selection)从源领域训练数据中选择与目标领域更加相关的样本进行模型训
练,降低不相关样本数据的比例。
数据选择所要解决的核心问题是:给定一个目标领域/任务数据集,如何衡量原始训练样本与目标领域/任务的相关性?主要方法可以分为以下几类:
• 基于交叉熵差(Cross-entropy Difference, CED) 的方法。该方法在目标领域数据和通用数据上分别训练语言模型,然后用两个语言模型来给句子打分并做差,差越小说明句子与目标领域越相关。
• 基于文本分类的方法。将问题转化为文本分类问题,先构造一个领域分类器,之后利用分类器对给定的句子进行领域分类,最后用输出的概率来打分,选择得分高的样本。
• 基于特征衰减算法(Feature Decay Algorithms, FDA) 的方法。该算法基于特征匹配,试图从源领域中提取出一个句子集合,这些句子能够最大程度覆盖目标领域的语言特征。
这个方法也有它的缺点,比如选定的子集导致词表覆盖率低,加剧单词长尾分布问题。
动态学习策略,主要有两种方法,一种是将句子的领域相似性表达成概率分布,然后在训练过程中根据该分布对数据进行动态采样,另一种是在计算损失函数时根据句子的领域相似性以加权的方式进行训练。相比于静态方法的二元选择方式,动态方法是一种“软”选择的方式,这使得模型有机会使用到其它数据,提高了训练数据的多样性,因此性能也更稳定。
(2)数据降噪
训练数据中存在噪声,比如经常出现句子未对齐、多种语言文字混合、单词丢失等问题。
可以用诸如句子长度比、词对齐率、最长连续未对齐序列长度等一些特征来对句子进行综合评分;也可以将该问题转化为分类任务来对句子进行筛选。
(3)主动学习(Active Learning)
主动学习主要由五个部分组成,包括:未标注样本池、筛选策略、标注者、标注样本集、目标模型。在主动学习过程中,会根据当前的模型状态找到未标注样本池中最有价值的样本,之后送给标
注者。标注结束后,会把标注的样本加入到标注样本集中,之后用这些标注的样本更新模型。之后,重复这个过程,直到到达某种收敛状态。
主动学习的一个核心问题是:如何选择出那些最有价值的未标注样本?通常会假设模型认为最“难”的样本是最有价值的。具体实现有很多思路,例如,基于置信度的方法、基于分类错误的方法等等
6.2 课程学习
课程学习(Curriculum Learning)的基本思想是:先学习简单的、普适性的知识,然后逐渐增加难度,学习更复杂、更专业化的知识。在统计模型训练中,这种思想可以体现在让模型按照由“易”到“难”的顺序对样本进行学习。
好处是: 加速模型训练,使模型获得更好的泛化性能。
设计课程学习方法的核心问题是:
• 如何评估每个样本的难度?即设计评估样本学习难易度的准则,简称难度评估准则(Difficulty Criteria) ---难度评估器。
• 以何种策略来规划训练数据?即何时为训练提供更复杂的样本,以及提供多少样本等,称为课程规划(Curriculum Schedule)。--训练调度器。
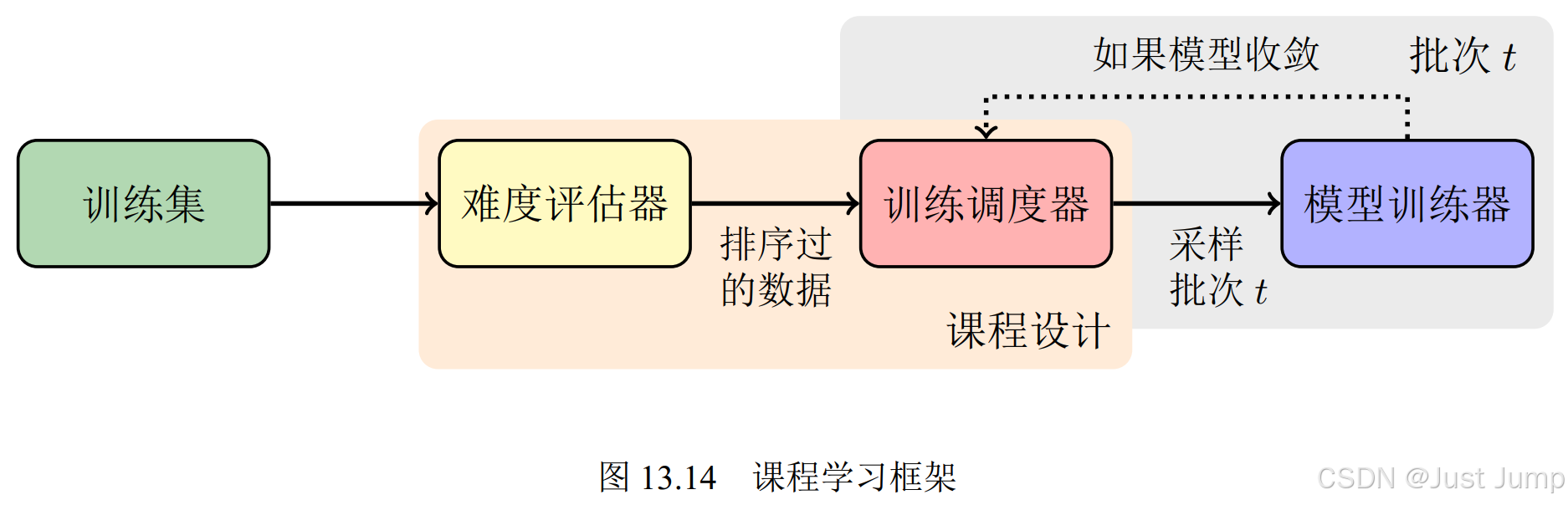
样本难度的评估方法有很多,比如句子长度、句子平均词频、句法树深度等,基于模型的方法等。
调度策略可以分为预定义的和自动的两种。预定义的调度策略通常将按照难易程度排序好的样本划分为块,每个块中包含一定数量的难度相似的样本。然后按照“先易后难”的原则人工定义一个调度策略。另一种方法是自动的方法,根据模型的反馈来动态调整样本的难度或调度策略,模型的反馈
可以是模型的不确定性、模型的能力等。这些方法在一定程度上使得整个训练过程和模型的状态相匹配,同时样本的选择过渡得更加平滑,因此在实践中取得了不错的效果。
6.3 持续学习
当把模型切换到新的任务时,本质上是数据的分布发生了变化,从这种分布差异过大的数据中不断增量获取可用信息很容易导致灾难性遗忘(Catastrophic Forgetting)问题,即用新数据训练模型的时候会干扰先前学习的知识。
稳定性-可塑性(Stability-Plasticity)问题:学习系统一方面必须能连续获取新知识和完善现有知
识,另一方面,还应防止新数据输入明显干扰现有的知识。可塑性指整合新知识的能力,稳定性指保留先前的知识不至于遗忘。
要解决这些问题,就需要模型在保留先前任务的知识与学习当前任务的新知识之间取得平衡。目前的解决方法可以分为以下几类:
(1)基于正则化的方法。通过对模型参数的更新施加约束来减轻灾难性的遗忘,通常是在损失函数中引入了一个额外的正则化项,使得模型在学习新数据时巩固先前的知识。
(2)基于实例的方法。在学习新任务的同时混合训练先前的任务样本以减轻遗忘,这些样本可以是从先前任务的训练数据中精心挑选出的子集,或者利用生成模型生成的伪样本。
(3)基于动态模型架构的方法。例如,增加神经元或新的神经网络层进行重新训练,或者是在新任务训练时只更新部分参数。
相关文章:
机器翻译基础与模型 之四:模型训练
1、开放词表 1.1 大词表和未登陆词问题 理想情况下,机器翻译应该是一个开放词表(Open Vocabulary)的翻译任务。也就是,无论测试数据中包含什么样的词,机器翻译系统都应该能够正常翻译。 现实的情况是即使不断扩充词…...

Vue——响应式数据,v-on,v-bind,v-if,v-for(内含项目实战)
目录 响应式数据 ref reactive 事件绑定指令 v-on v-on 鼠标监听事件 v-on 键盘监听事件 v-on 简写形式 属性动态化指令 v-bind iuput标签动态属性绑定 img标签动态属性绑定 b标签动态属性绑定 v-bind 简写形式 条件渲染指令 v-if 遍历指令 v-for 遍历对象的值 遍历…...

ceph 18.2.4二次开发,docker镜像制作
编译环境要求 #需要ubuntu 22.04版本 参考https://docs.ceph.com/en/reef/start/os-recommendations/ #磁盘空间最好大于200GB #内存如果小于100GB 会有OOM的情况发生,需要重跑 目前遇到内存占用最高为92GB替换阿里云ubuntu 22.04源 将下面内容写入/etc/apt/sources.list 文件…...

产品经理的项目管理课
各位产品经理,大家下午好,今天我给大家分享的主题是“产品经理如何做好项目管理”。 其实,我是不想分享这个主题的,是因为在周会中大家投票对这个议题最感兴趣,11个同学中有7个投了这个主题,所以才有了这次…...

Linux 下的 AWK 命令详细指南与示例
目录 简介AWK 的主要特性基本语法示例1. 打印文件的所有行2. 打印特定字段3. 打印匹配模式的行4. 基于条件过滤并打印5. 使用内置变量6. 执行算术运算7. 字符串操作8. 使用 BEGIN 和 END 块9. 处理分隔符文件 高级功能自定义脚本使用外部变量 总结 简介 AWK 是 Linux 中功能强…...

FPGA经验谈系列文章——8、复位的设计
前言 剑法往往有着固定的招式套路,而写代码似乎也存在类似的情况。不知从何时起,众多 FPGA 工程师们在编写代码时开启了一种关于 always 语句块的流行写法,那就是: always @(posedge i_clk or negedge i_rstn) 就笔者所经历的诸多项目以及所接触到的不少工程师而言,大家在…...

C#里怎么样实现操作符重载?
C#里怎么样实现操作符重载? 一般情况,都是表示某种类型的类时,才会使用到操作符重载。 比如实现一个复数类。 在C#中,重载运算符是通过在类或结构中定义特殊的方法来实现的,这些方法的名称是operator关键字后跟要重载的运算符。例如,要重载+运算符,可以定义一个名为op…...
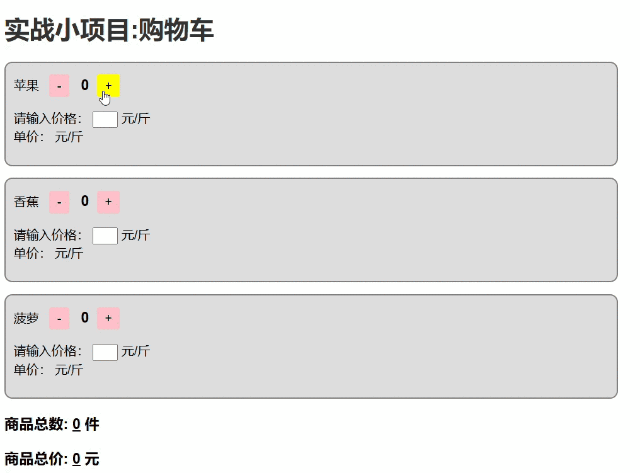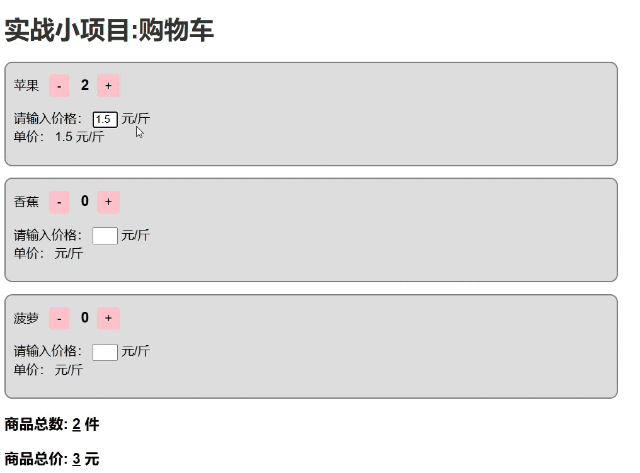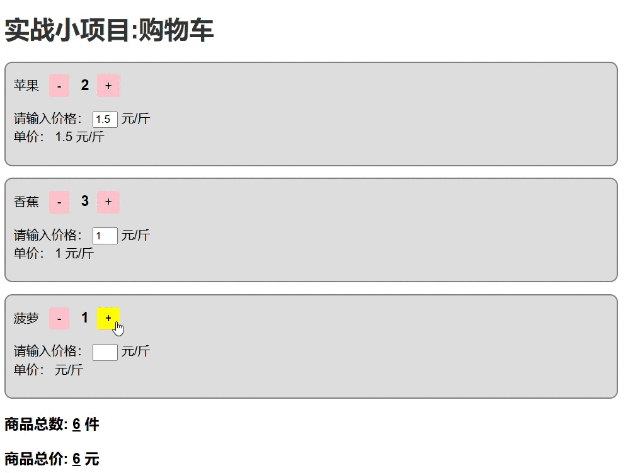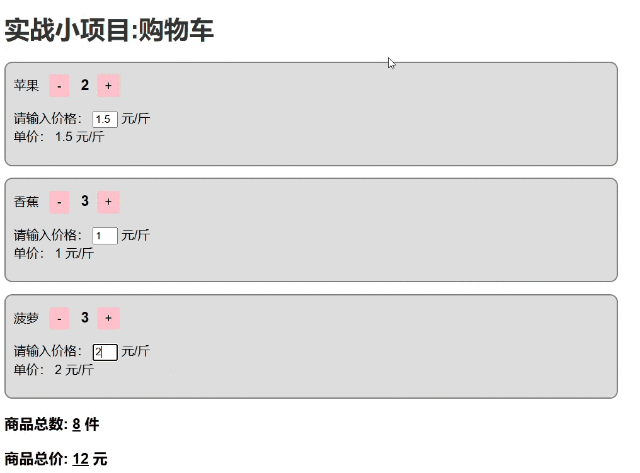
项目实战:Vue3开发一个购物车
这段HTML代码实现了一个简单的购物车实战小项目的前端页面,结合了Vue.js框架来实现数据响应式和交互逻辑。页面展示了购物车中的商品项,每个商品项有增减数量的按钮,并且能显示商品总数以及目前固定为0元的商品总价和总价计算。 【运用响应式…...

Oracle SQL*Plus中的SET VERIFY
在 Oracle SQL*Plus 中,SET VERIFY ON 和 SET VERIFY OFF 是两个用于控制命令执行前后显示变量值的命令。这些命令主要用于调试和验证 SQL 脚本中的变量替换情况。 一、参数说明 1.1 SET VERIFY ON 作用:启用变量替换的验证功能。当启用时,S…...
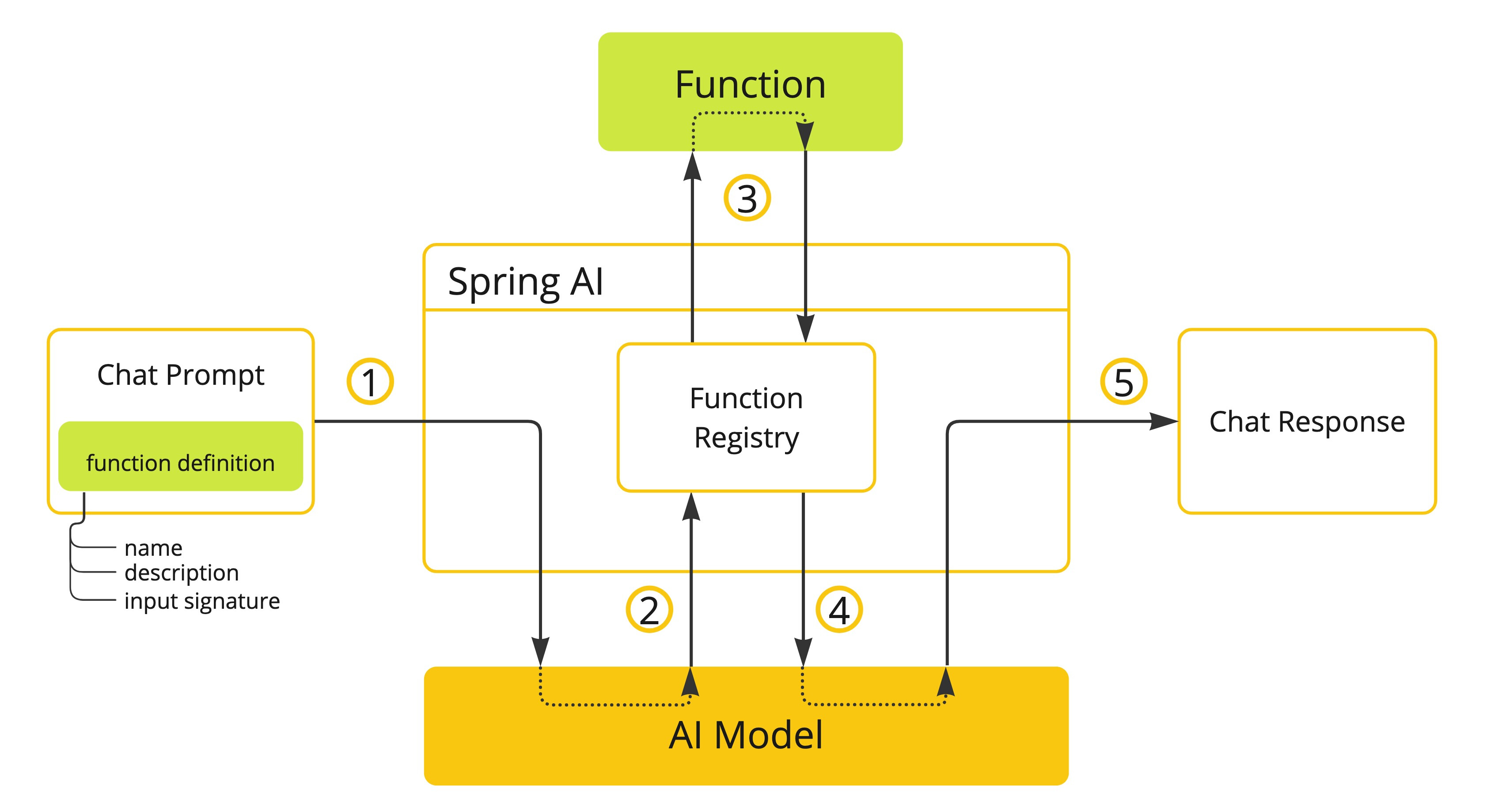
Spring AI 框架使用的核心概念
一、模型(Model) AI 模型是旨在处理和生成信息的算法,通常模仿人类的认知功能。通过从大型数据集中学习模式和见解,这些模型可以做出预测、文本、图像或其他输出,从而增强各个行业的各种应用。 AI 模型有很多种&…...
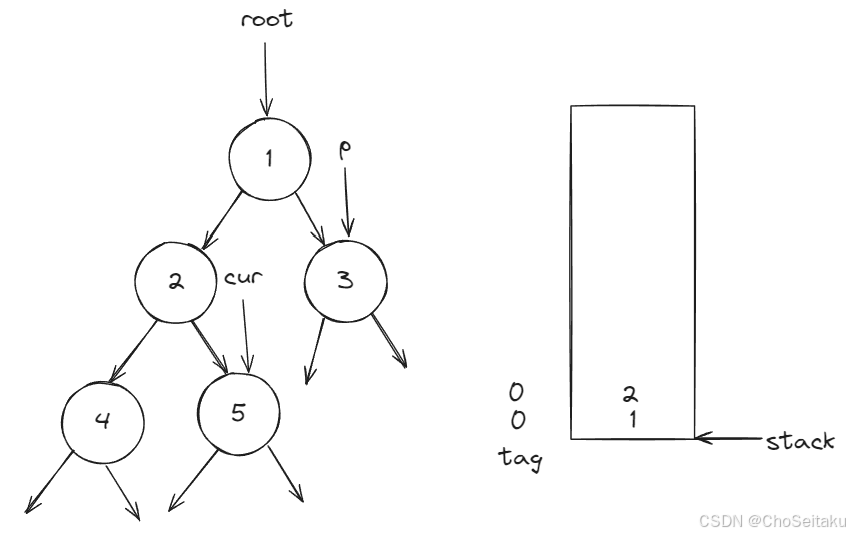
二叉树路径相关算法题|带权路径长度WPL|最长路径长度|直径长度|到叶节点路径|深度|到某节点的路径非递归(C)
带权路径长度WPL 二叉树的带权路径长度(WPL)是二叉树所有叶节点的带权路径长度之和,给定一棵二叉树T,采用二叉链表存储,节点结构为 其中叶节点的weight域保存该节点的非负权值,设root为指向T的根节点的指针,设计求W…...

前端:JavaScript (学习笔记)【2】
目录 一,数组的使用 1,数组的创建 [ ] 2,数组的元素和长度 3,数组的遍历方式 4,数组的常用方法 二,JavaScript中的对象 1,常用对象 (1)String和java中的Stri…...

[面试]-golang基础面试题总结
文章目录 panic 和 recover**注意事项**使用 pprof、trace 和 race 进行性能调试。**Go Module**:Go中new和make的区别 Channel什么是 Channel 的方向性?如何对 Channel 进行方向限制?Channel 的缓冲区大小对于 Channel 和 Goroutine 的通信有…...
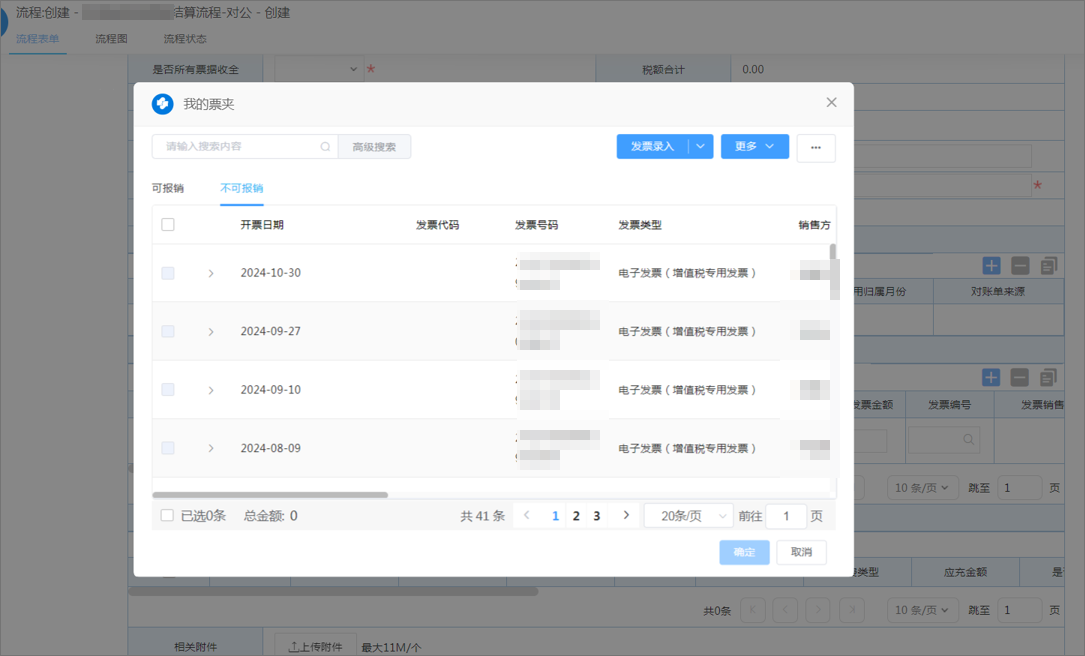
【案例】泛微.齐业成助力北京中远大昌汽车实现数电票全流程管理
中远大昌统一发票共享平台上线三个多月以来,实现: 5000份 60000元 发票开具 成本节约 客户简介及需求分析 北京中远大昌汽车服务有限公司(以下简称“中远大昌”)成立于2002年,是中远海运集团所属香远(北…...

微软安全文章合集
说明:文章来自微软很多年前旧帖,有用的部分拿去,没用的就忽略吧,另外提一句,微软会清理文章,很多我收藏的帖子都无法查看了,所以收藏的最好办法是,用word复制粘贴下来保存到云盘&…...
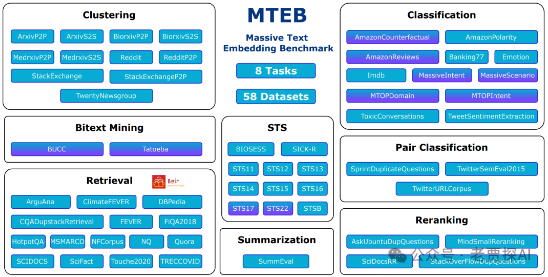
自然语言处理: RAG优化之Embedding模型选型重要依据:mteb/leaderboard榜
本人项目地址大全:Victor94-king/NLP__ManVictor: CSDN of ManVictor git地址:https://github.com/opendatalab/MinerU 写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!! 写在前面: 笔者更新不易,希望走过路…...

鸿蒙主流路由详解
鸿蒙主流路由详解 Navigation Navigation更适合于一次开发,多端部署,也是官方主流推荐的一种路由控制方式,但是,使用起来入侵耦合度高,所以,一般会使用HMRouter,这也是官方主流推荐的路由 Navigation官网地址 个人源码地址 路由跳转 第一步-定义路由栈 Provide(PageInfo) pag…...

C#构建一个简单的循环神经网络,模拟对话
循环神经网络(Recurrent Neural Network, RNN)是一种用于处理序列数据的神经网络模型。与传统的前馈神经网络不同,RNN具有内部记忆能力,可以捕捉到序列中元素之间的依赖关系。这种特性使得RNN在自然语言处理、语音识别、时间序列预…...

Linux上安装单机版Kibana6.8.1
1. 下载安装包 kibana-6.8.1-linux-x86_64.tar.gz 链接:https://pan.baidu.com/s/1b4kION9wFXIVHuWDn2J-Aw 提取码:rdrc 2. Kibana启动不能使用root用户,使用ES里创建的elsearch用户,进行赋权: chown -R elsearch:els…...
短视频矩阵矩阵,矩阵号策略
随着数字媒体的迅猛发展,短视频平台已经成为企业和个人品牌推广的核心渠道。在这一背景下,短视频矩阵营销策略应运而生,它通过高效整合和管理多个短视频账号,实现资源的最优配置和营销效果的最大化。本文旨在深入探讨短视频矩阵的…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...
麒麟系统使用-进行.NET开发
文章目录 前言一、搭建dotnet环境1.获取相关资源2.配置dotnet 二、使用dotnet三、其他说明总结 前言 麒麟系统的内核是基于linux的,如果需要进行.NET开发,则需要安装特定的应用。由于NET Framework 是仅适用于 Windows 版本的 .NET,所以要进…...
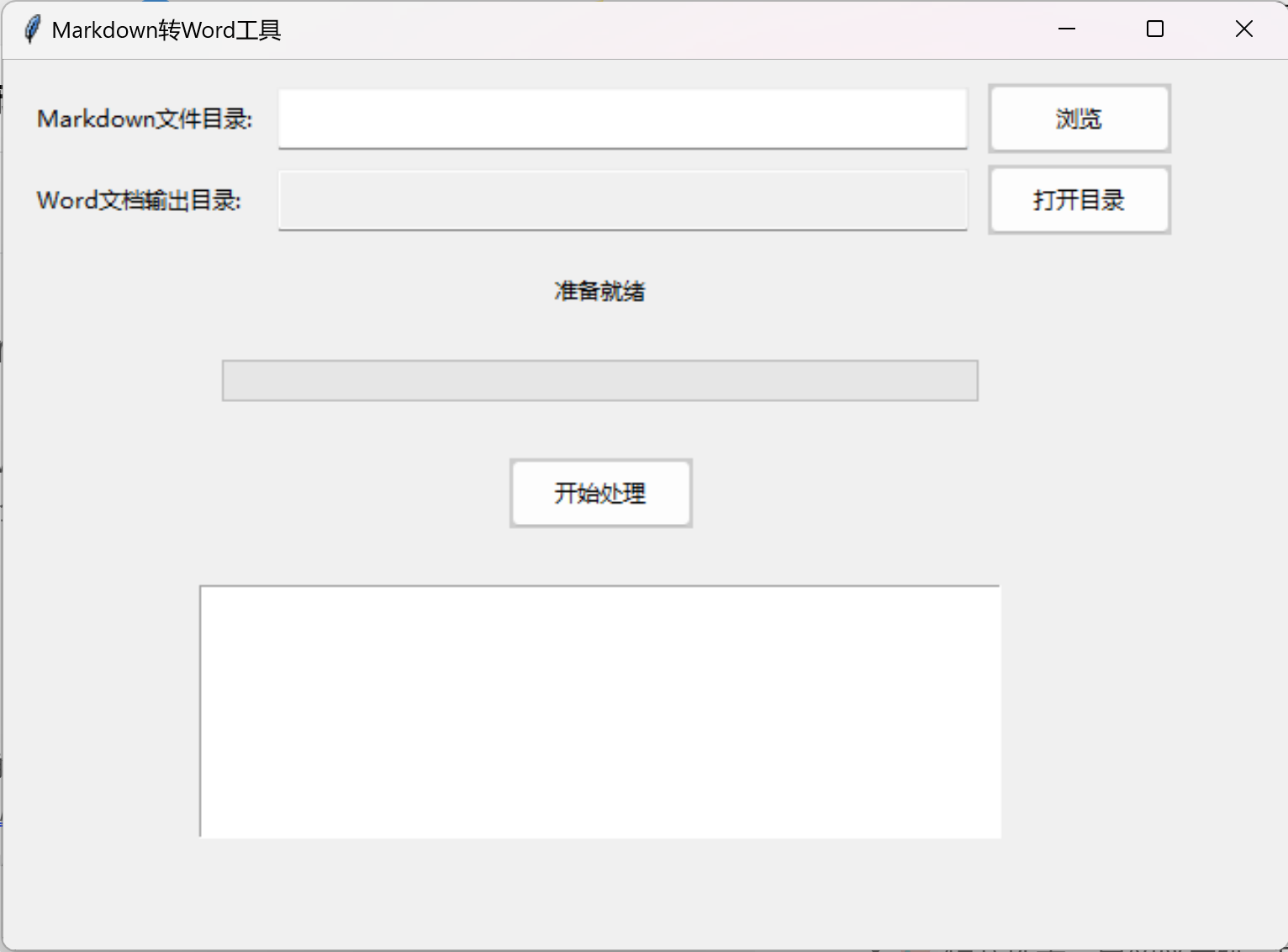
免费批量Markdown转Word工具
免费批量Markdown转Word工具 一款简单易用的批量Markdown文档转换工具,支持将多个Markdown文件一键转换为Word文档。完全免费,无需安装,解压即用! 官方网站 访问官方展示页面了解更多信息:http://mutou888.com/pro…...

使用 uv 工具快速部署并管理 vLLM 推理环境
uv:现代 Python 项目管理的高效助手 uv:Rust 驱动的 Python 包管理新时代 在部署大语言模型(LLM)推理服务时,vLLM 是一个备受关注的方案,具备高吞吐、低延迟和对 OpenAI API 的良好兼容性。为了提高部署效…...