Flink学习连载第二篇-使用flink编写WordCount(多种情况演示)
使用Flink编写代码,步骤非常固定,大概分为以下几步,只要牢牢抓住步骤,基本轻松拿下:
1. env-准备环境
2. source-加载数据
3. transformation-数据处理转换
4. sink-数据输出
5. execute-执行
DataStream API开发
//nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/datastream/overview/
0. 添加依赖
<properties><flink.version>1.13.6</flink.version>
</properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-shaded-hadoop-2-uber</artifactId><version>2.7.5-10.0</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version></dependency></dependencies><build><extensions><extension><groupId>org.apache.maven.wagon</groupId><artifactId>wagon-ssh</artifactId><version>2.8</version></extension></extensions><plugins><plugin><groupId>org.codehaus.mojo</groupId><artifactId>wagon-maven-plugin</artifactId><version>1.0</version><configuration><!--上传的本地jar的位置--><fromFile>target/${project.build.finalName}.jar</fromFile><!--远程拷贝的地址--><url>scp://root:root@bigdata01:/opt/app</url></configuration></plugin></plugins></build>-
编写代码
package com.bigdata.day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCount01 {/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception {// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类DataStream<String> dataStream01 = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");DataStream<String> flatMapStream = dataStream01.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {String[] arr = line.split(" ");for (String word : arr) {// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStreamcollector.collect(word);}}});//flatMapStream.print();// Tuple2 指的是2元组DataStream<Tuple2<String, Integer>> mapStream = flatMapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1); // ("hello",1)}});DataStream<Tuple2<String, Integer>> sumResult = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}// 此处的1 指的是元组的第二个元素,进行相加的意思}).sum(1);sumResult.print();// 执行env.execute();}
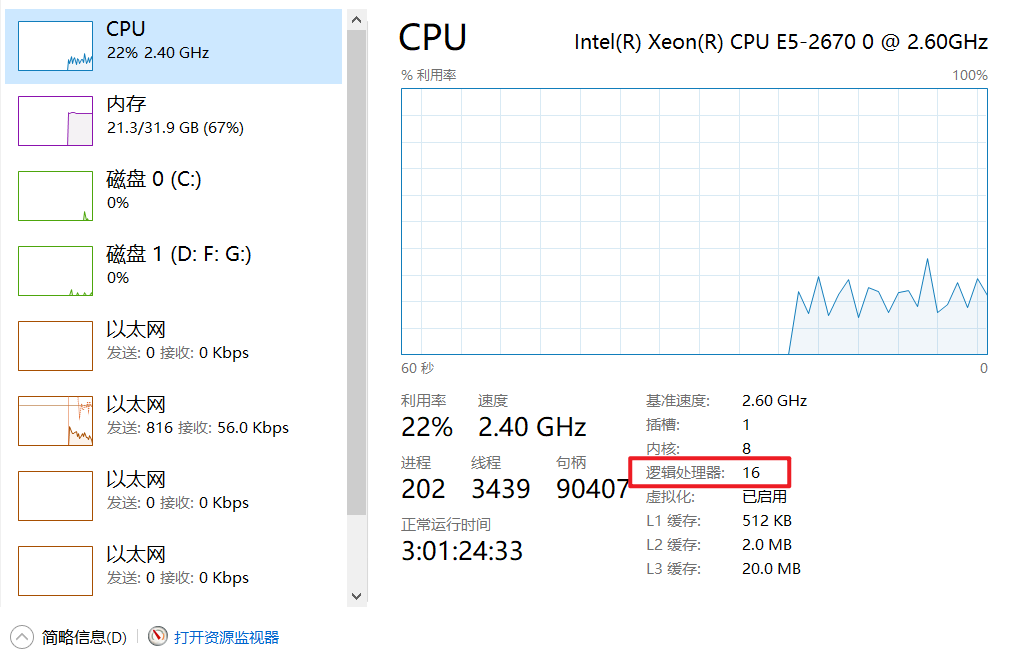
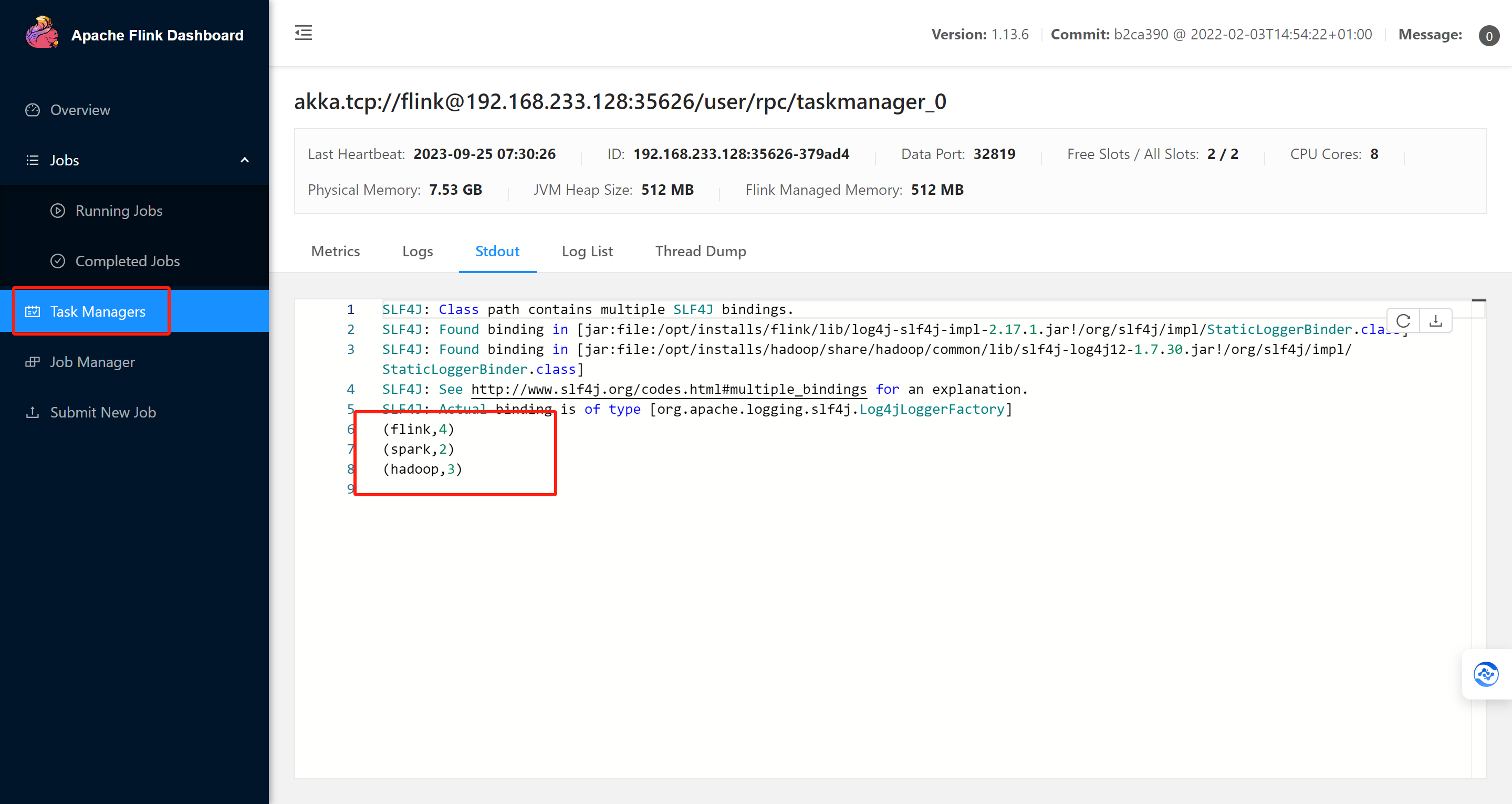
}查看本机的CPU的逻辑处理器的数量,逻辑处理器的数量就是你的分区数量。
12> spark
13> kakfa
11> spark
11> flink
11> kafka
13> hadoop
12> sqoop
13> flink
12> flink前面的数字是分区数,默认跟逻辑处理器的数量有关系。对结果进行解释:
什么是批,什么是流?
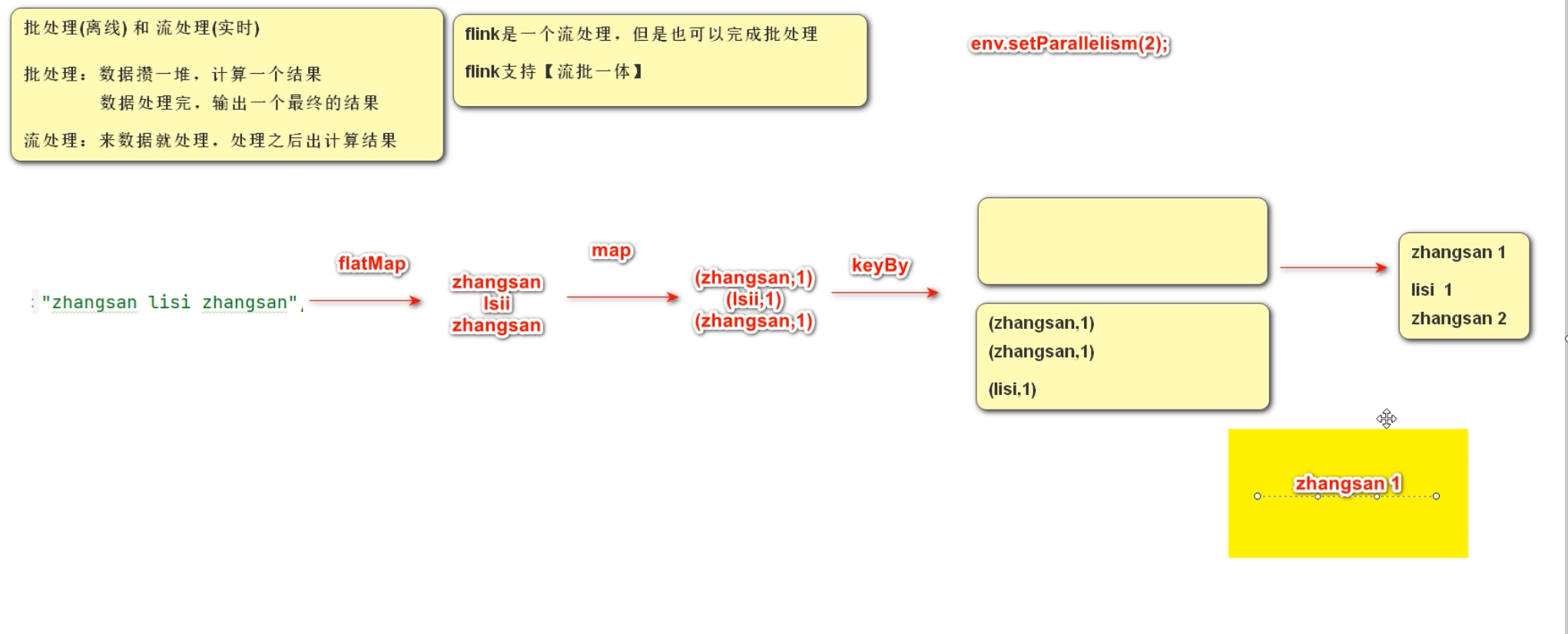
批处理结果:前面的序号代表分区
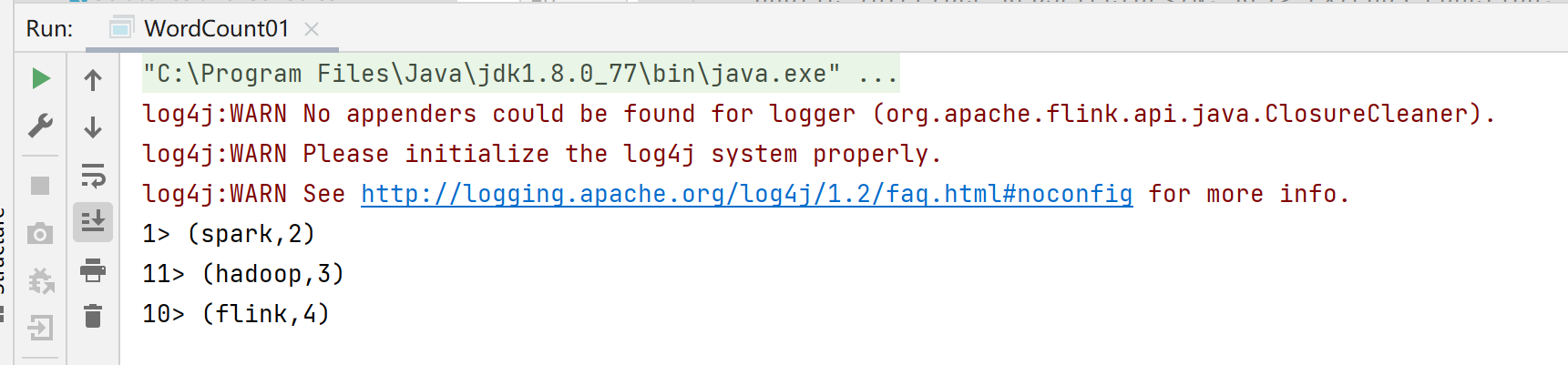
流处理结果:
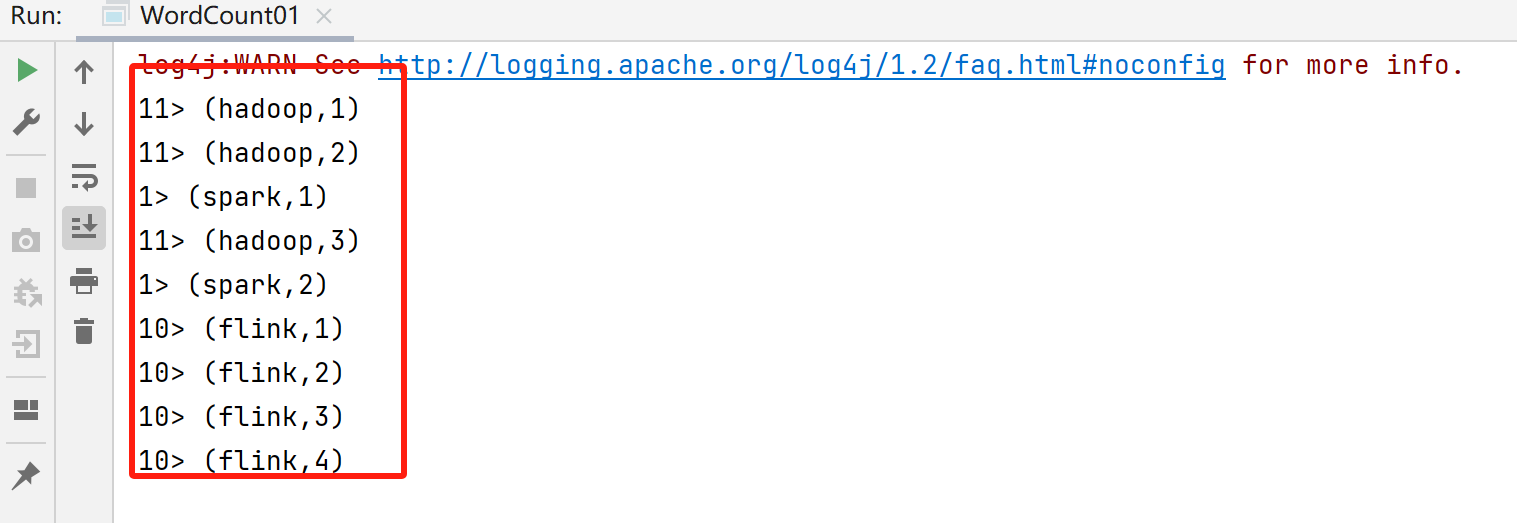
也可以通过如下方式修改分区数量:
env.setParallelism(2);关于并行度的代码演示:
系统以及算子都可以设置并行度,或者获取并行度
package com.bigdata.day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCount01 {/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception {// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 将任务的并行度设置为2// env.setParallelism(2);// 通过这个获取系统的并行度int parallelism = env.getParallelism();System.out.println(parallelism);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类DataStream<String> dataStream01 = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");DataStream<String> flatMapStream = dataStream01.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {String[] arr = line.split(" ");for (String word : arr) {// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStreamcollector.collect(word);}}});// 每一个算子也有自己的并行度,一般跟系统保持一致System.out.println("flatMap的并行度:"+flatMapStream.getParallelism());//flatMapStream.print();// Tuple2 指的是2元组DataStream<Tuple2<String, Integer>> mapStream = flatMapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1); // ("hello",1)}});DataStream<Tuple2<String, Integer>> sumResult = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}// 此处的1 指的是元组的第二个元组,进行相加的意思}).sum(1);sumResult.print();// 执行env.execute();}
}
- 打包、上传
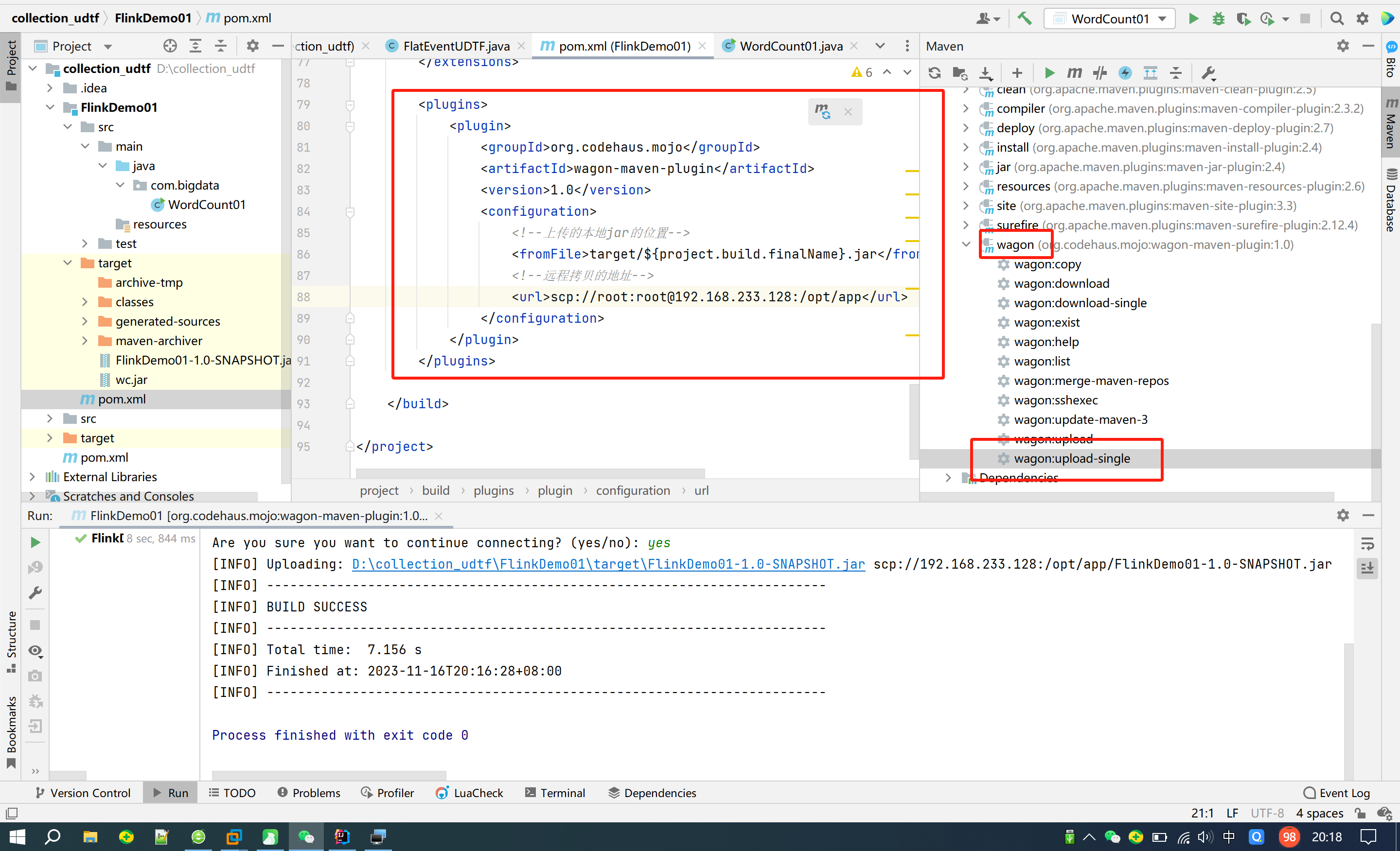
文件夹不需要提前准备好,它可以帮我创建
- 提交我们自己开发打包的任务
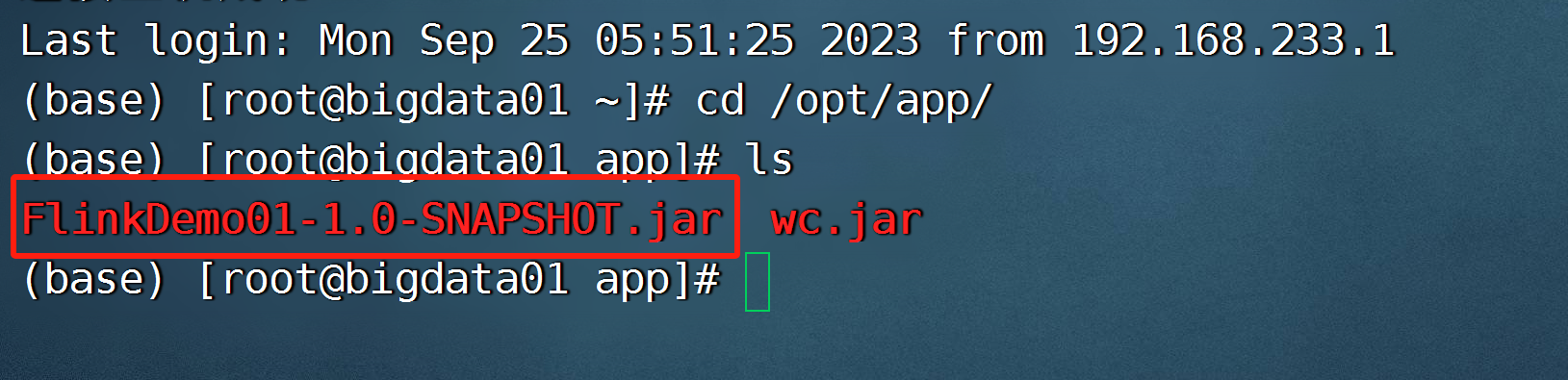
flink run -c com.bigdata.day01.WordCount01 /opt/app/FlinkDemo-1.0-SNAPSHOT.jar
去界面中查看运行结果:
因为你这个是集群运行的,所以标准输出流中查看,假如第一台没有,去第二台查看,一直点。
获取主函数参数工具类
可以通过外部传参的方式给定一个路径
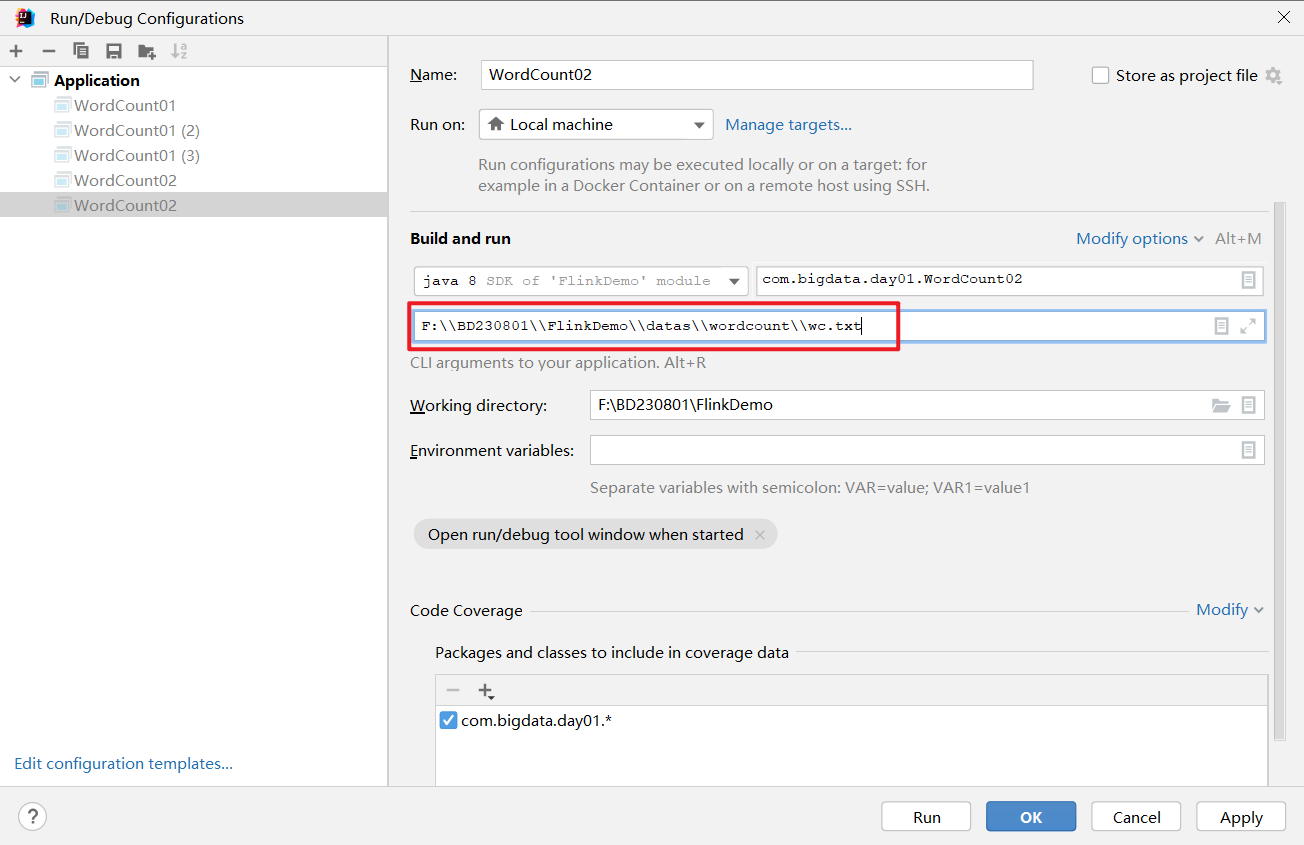
以下代码可以做到,假如给定路径,就获取路径的数据,假如没给,就读取默认数据:
package com.bigdata.day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCount02 {/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception {// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 将任务的并行度设置为2// env.setParallelism(2);// 通过这个获取系统的并行度int parallelism = env.getParallelism();System.out.println(parallelism);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类// 连着写的本质就是 因为每一个算子的返回值都是DataStream的子类,所以可以这么写// 以下代码中路径是写死的,能不能通过外部传参进来,当然可以! agrsDataStream<String> dataStream = null;System.out.println(args.length);if(args.length !=0){String path = args[0];dataStream = env.readTextFile(path);}else{dataStream = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");}dataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {String[] arr = line.split(" ");for (String word : arr) {// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStreamcollector.collect(word);}}}).map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1); // ("hello",1)}}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}// 此处的1 指的是元组的第二个元组,进行相加的意思}).sum(1).print();// 执行env.execute();}
}
flink run -c com.bigdata.day01.Demo02 FlinkDemo-1.0-SNAPSHOT.jar /home/wc.txt
这样做,跟我们以前的做法还是不一样。以前的运行方式是这样的
flink run /opt/installs/flink/examples/batch/WordCount.jar --input /home/wc.txt
这个写法,传递参数的时候,带有--字样,而我们的没有。
以上代码进行升级,我想将参数前面追加一个 --input 这样,怎么写?
ParameterTool parameterTool = ParameterTool.fromArgs(args);
if(parameterTool.has("output")){path = parameterTool.get("output");
}在代码中的使用:
ParameterTool parameterTool = ParameterTool.fromArgs(args);String output = "";if (parameterTool.has("output")) {output = parameterTool.get("output");System.out.println("指定了输出路径使用:" + output);} else {output = "hdfs://node01:9820/wordcount/output47_";System.out.println("可以指定输出路径使用 --output ,没有指定使用默认的:" + output);}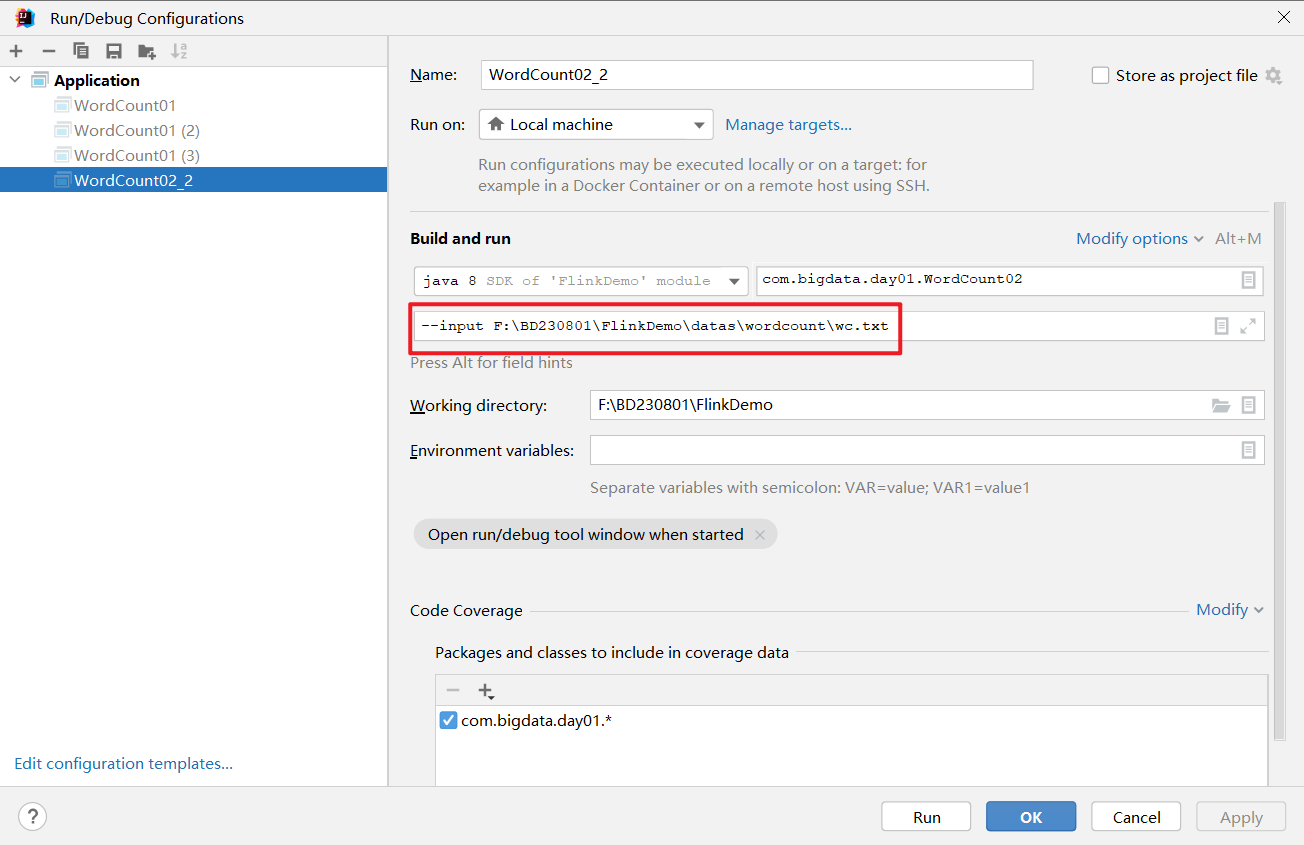
升级过的代码:
package com.bigdata.day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCount02 {/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception {// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 将任务的并行度设置为2// env.setParallelism(2);// 通过这个获取系统的并行度int parallelism = env.getParallelism();System.out.println(parallelism);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类// 连着写的本质就是 因为每一个算子的返回值都是DataStream的子类,所以可以这么写// 以下代码中路径是写死的,能不能通过外部传参进来,当然可以! agrsDataStream<String> dataStream = null;System.out.println(args.length);if(args.length !=0){String path ;ParameterTool parameterTool = ParameterTool.fromArgs(args);if(parameterTool.has("input")){path = parameterTool.get("input");}else{path = args[0];}dataStream = env.readTextFile(path);}else{dataStream = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");}dataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {String[] arr = line.split(" ");for (String word : arr) {// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStreamcollector.collect(word);}}}).map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1); // ("hello",1)}}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}// 此处的1 指的是元组的第二个元组,进行相加的意思}).sum(1).print();// 执行env.execute();}
}
DataStream (Lambda表达式-扩展 了解)
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;import java.util.Arrays;/*** Desc 演示Flink-DataStream-流批一体API完成批处理WordCount* 使用Java8的lambda表示完成函数式风格的WordCount*/
public class WordCount02 {public static void main(String[] args) throws Exception {//TODO 1.env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);//指定计算模式为流//env.setRuntimeMode(RuntimeExecutionMode.BATCH);//指定计算模式为批env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//自动//不设置的话默认是流模式defaultValue(RuntimeExecutionMode.STREAMING)//TODO 2.source-加载数据DataStream<String> dataStream = env.fromElements("flink hadoop spark", "flink hadoop spark", "flink hadoop", "flink");//TODO 3.transformation-数据转换处理//3.1对每一行数据进行分割并压扁/*public interface FlatMapFunction<T, O> extends Function, Serializable {void flatMap(T value, Collector<O> out) throws Exception;}*//*DataStream<String> wordsDS = dataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] words = value.split(" ");for (String word : words) {out.collect(word);}}});*///注意:Java8的函数的语法/lambda表达式的语法: (参数)->{函数体}DataStream<String> wordsDS = dataStream.flatMap((String value, Collector<String> out) -> {String[] words = value.split(" ");for (String word : words) {out.collect(word);}}).returns(Types.STRING);//3.2 每个单词记为<单词,1>/*public interface MapFunction<T, O> extends Function, Serializable {O map(T value) throws Exception;}*//*DataStream<Tuple2<String, Integer>> wordAndOneDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}});*/DataStream<Tuple2<String, Integer>> wordAndOneDS = wordsDS.map((String value) -> Tuple2.of(value, 1)).returns(Types.TUPLE(Types.STRING, Types.INT));//3.3分组//注意:DataSet中分组用groupBy,DataStream中分组用keyBy//KeyedStream<Tuple2<String, Integer>, Tuple> keyedDS = wordAndOneDS.keyBy(0);/*public interface KeySelector<IN, KEY> extends Function, Serializable {KEY getKey(IN value) throws Exception;}*//*KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordAndOneDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});*/KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordAndOneDS.keyBy((Tuple2<String, Integer> value) -> value.f0);//3.4聚合SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedDS.sum(1);//TODO 4.sink-数据输出result.print();//TODO 5.execute-执行env.execute();}
}此处有一个大坑,就是使用完lambda表达式以后,需要添加一个returns(Types.STRING); 否则报错,这样的话,使用lambda也不是特别快了。
连着写的版本如下:
package com.bigdata.day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCount03 {/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception {// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 将任务的并行度设置为2// env.setParallelism(2);// 通过这个获取系统的并行度int parallelism = env.getParallelism();System.out.println(parallelism);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类// 连着写的本质就是 因为每一个算子的返回值都是DataStream的子类,所以可以这么写// 以下代码中路径是写死的,能不能通过外部传参进来,当然可以! agrsDataStream<String> dataStream = null;System.out.println(args.length);if(args.length !=0){String path ;ParameterTool parameterTool = ParameterTool.fromArgs(args);if(parameterTool.has("input")){path = parameterTool.get("input");}else{path = args[0];}dataStream = env.readTextFile(path);}else{dataStream = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");}dataStream.flatMap((String line, Collector<String> collector) -> {String[] arr = line.split(" ");for (String word : arr) {// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStreamcollector.collect(word);}}).returns(Types.STRING).map((String word)-> {return Tuple2.of(word, 1); // ("hello",1)}).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy((Tuple2<String, Integer> tuple2)-> {return tuple2.f0;}).sum(1).print();// 执行env.execute();}
}相关文章:
Flink学习连载第二篇-使用flink编写WordCount(多种情况演示)
使用Flink编写代码,步骤非常固定,大概分为以下几步,只要牢牢抓住步骤,基本轻松拿下: 1. env-准备环境 2. source-加载数据 3. transformation-数据处理转换 4. sink-数据输出 5. execute-执行 DataStream API开发 //n…...
是数学分析中用于解决带有约束条件的优化问题的一种重要方法,特别是SVM)
拉格朗日乘子(Lagrange Multiplier)是数学分析中用于解决带有约束条件的优化问题的一种重要方法,特别是SVM
拉格朗日乘子(Lagrange Multiplier)是数学分析中用于解决带有约束条件的优化问题的一种重要方法,也称为拉格朗日乘数法。 例如之前博文写的2月7日 SVM&线性回归&逻辑回归在支持向量机(SVM)中,为了…...

鸿蒙征文|鸿蒙心路旅程:始于杭研所集训营,升华于横店
始于杭研所 在2024年7月,我踏上了一段全新的旅程,前往风景如画的杭州,参加华为杭研所举办的鲲鹏&昇腾集训营。这是一个专门为开发者设计的培训项目,中途深入学习HarmonyOS相关技术。对于我这样一个对技术充满热情的学生来说&…...

c语言数据结构与算法--简单实现线性表(顺序表+链表)的插入与删除
老规矩,点赞评论收藏关注!!! 目录 线性表 其特点是: 算法实现: 运行结果展示 链表 插入元素: 删除元素: 算法实现 运行结果 线性表是由n个数据元素组成的有限序列ÿ…...
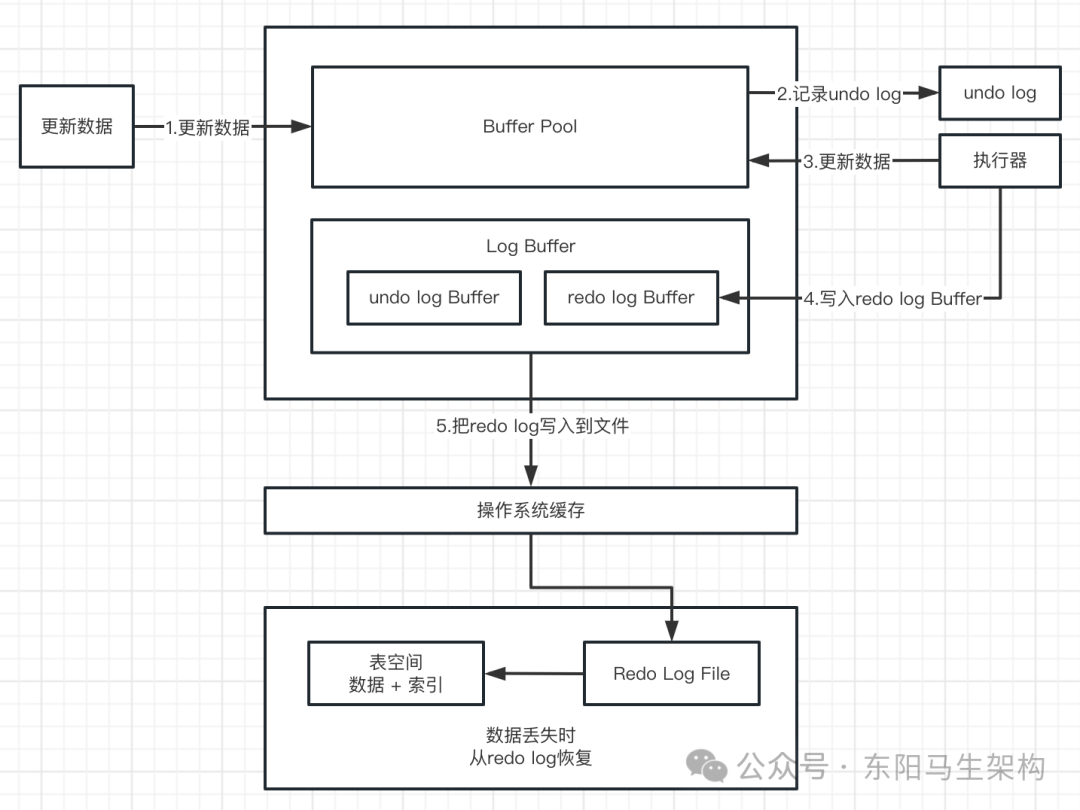
MySQL底层概述—1.InnoDB内存结构
大纲 1.InnoDB引擎架构 2.Buffer Pool 3.Page管理机制之Page页分类 4.Page管理机制之Page页管理 5.Change Buffer 6.Log Buffer 1.InnoDB引擎架构 (1)InnoDB引擎架构图 (2)InnoDB内存结构 (1)InnoDB引擎架构图 下面是InnoDB引擎架构图,主要分为内存结构和磁…...
计算两个日期天数之差)
MySQL:DATEDIFF()计算两个日期天数之差
题目需求: 计算出比前一天温度要高的日期。 select a.id from weather a, weather b where a.temperature > b.temperature and datediff(a.recordDate, b.recordDate) 1; DATEDIFF(date1, date2)函数用于计算两个日期之间的天数差。函数返回date1和date2之…...

Linux 编译Ubuntu24内核
参考来源: 编译并更新内核:https://www.cnblogs.com/smlile-you-me/p/18248433 编译报错–sub-make: https://forum.linuxfoundation.org/discussion/865005/facing-error-in-building-the-kernel 1.下载源码,执行如下命令,会在/usr/src下多…...

Android系统中init进程、zygote进程和SystemServer进程简单学习总结
Android系统中,init、zygote和SystemServer进程是系统启动和运行的关键进程,它们之间有着密切的关系,本文针对这三个进程的学习做一个简单汇总,方便后续查询。 1、init进程 Android用户空间执行的第一个程序就是它,可…...

Flask 基于wsgi源码启动流程
1. 点击 __call__ 进入到源码 2. 找到 __call__ 方法 return 执行的是 wsgi方法 3. 点击 wsgi 方法 进到 wsgi return 执行的是 response 方法 4. 点击response 方法 进到 full_dispatch_request 5. full_dispatch_request 执行finalize_request 方法 6. finalize_request …...

leetcode代码 50道答案
简单难度:两数之和 def twoSum(nums, target): for i in range(len(nums)): for j in range(i 1, len(nums)): if nums[i] nums[j] target: return [i, j] return [] 简单难度:有效的括号 def isVa…...

Centos-stream 9,10 add repo
Centos-stream repo前言 Centos-stream 9,10更换在线阿里云创建一键更换repo 自动化脚本 华为centos-stream 源 , 阿里云centos-stream 源 华为epel 源 , 阿里云epel 源vim /centos9_10_repo.sh #!/bin/bash # -*- coding: utf-8 -*- # Author: make.h...

【隐私计算大模型】联邦深度学习之拆分学习Split learning原理及安全风险、应对措施以及在大模型联合训练中的应用案例
Tips:在两方场景下,设计的安全算法,如果存在信息不对等性,那么信息获得更多的一方可以有概率对另一方实施安全性攻击。 1. 拆分学习原理 本文介绍了一种适用于隐私计算场景的深度学习实现方案——拆分学习,又称分割…...

DataWhale—PumpkinBook(TASK05决策树)
课程开源地址及相关视频链接:(当然这里也希望大家支持一下正版西瓜书和南瓜书图书,支持文睿、秦州等等致力于开源生态建设的大佬✿✿ヽ(▽)ノ✿) Datawhale-学用 AI,从此开始 【吃瓜教程】《机器学习公式详解》(南瓜…...

elasticsearch7.10.2集群部署带认证
安装elasticsearch rpm包安装 下载地址 https://mirrors.aliyun.com/elasticstack/7.x/yum/7.10.2/ 生成证书 #1.生成CA证书 # 生成CA证书,执行命令后,系统还会提示你输入密码,可以直接留空 cd /usr/share/elasticsearch/bin ./elasticsearch-certutil ca#会在/usr/share/el…...

Java基础-I/O流
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 字节流 定义 说明 InputStream与OutputStream示意图 说明 InputStream的常用方法 说明 OutputStrea…...
全面解析多种mfc140u.dll丢失的解决方法,五种方法详细解决
当你满心期待地打开某个常用软件,却突然弹出一个错误框,提示“mfc140u.dll丢失”,那一刻,你的好心情可能瞬间消失。这种情况在很多电脑用户的使用过程中都可能出现。无论是游戏玩家还是办公族,面对这个问题都可能不知所…...

详细探索xinput1_3.dll:功能、问题与xinput1_3.dll丢失的解决方案
本文旨在深入探讨xinput1_3.dll这一动态链接库文件。首先介绍其在计算机系统中的功能和作用,特别是在游戏和输入设备交互方面的重要性。然后分析在使用过程中可能出现的诸如文件丢失、版本不兼容等问题,并提出相应的解决方案,包括重新安装相关…...
)
InfluxDB时序数据库笔记(一)
InfluxDB笔记一汇总 1、时间序列数据库概述2、时间序列数据库特点3、时间序列数据库应用场景4、InfluxDB数据生命周期5、InfluxDB历史数据需要另外归档吗?6、InfluxDB历史数据如何归档?7、太麻烦了,允许的话选择设施完备的InfluxDB云产品吧8、…...

Spring Boot 3.x + OAuth 2.0:构建认证授权服务与资源服务器
Spring Boot 3.x OAuth 2.0:构建认证授权服务与资源服务器 前言 随着Spring Boot 3的发布,我们迎来了许多新特性和改进,其中包括对Spring Security和OAuth 2.0的更好支持。本文将详细介绍如何在Spring Boot 3.x版本中集成OAuth 2.0…...

2024年09月CCF-GESP编程能力等级认证Scratch图形化编程二级真题解析
本文收录于《Scratch等级认证CCF-GESP图形化真题解析》专栏,专栏总目录:点这里,订阅后可阅读专栏内所有文章。 一、单选题(共 10 题,每题 3 分,共 30 分) 第 1 题 据有关资料,山东大学于 1972 年研制成功 DJL-1 计算机,并于 1973 年投入运行,其综合性能居当时全国第…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...