《C++搭建神经网络基石:开启智能编程新征程》
在人工智能的璀璨星空中,神经网络无疑是最为耀眼的星座之一。而 C++以其卓越的性能和高效的执行效率,成为构建神经网络模型的有力武器。今天,就让我们一同探索如何使用 C++构建一个基础的神经网络模型,踏上智能编程的奇妙旅程。
一、神经网络基础概念解析
在着手构建之前,先来明晰神经网络的一些关键概念。神经网络是一种模拟人类大脑神经元结构的计算模型,它由大量的节点(神经元)和连接这些节点的边组成。神经元接收输入数据,经过特定的计算处理后,产生输出。而这些神经元通常分层排列,包括输入层、隐藏层和输出层。输入层负责接收原始数据,隐藏层进行复杂的特征提取和转换,输出层则给出最终的预测或分类结果。神经网络的强大之处在于它能够通过大量的数据训练,自动学习到数据中的模式和规律,从而实现对未知数据的准确预测和分类。
二、C++构建神经网络的准备工作
要使用 C++构建神经网络,首先需要确保开发环境的就绪。这意味着安装一款合适的 C++编译器,如 GCC 或者 Visual Studio 等,它们将把我们编写的 C++代码转换为可执行程序。同时,由于神经网络计算涉及到大量的数学运算,我们还需要引入数学库,例如 Eigen 库,它为矩阵和向量运算提供了丰富且高效的功能支持,这对于神经网络中权重矩阵的计算、数据的线性代数变换等操作至关重要。此外,为了方便数据的处理和管理,还可以考虑使用一些数据结构和算法库,如 STL(标准模板库),它提供了诸如向量、列表、映射等实用的数据结构,能够帮助我们高效地组织和操作神经网络中的数据,比如存储训练数据、中间计算结果等。
三、设计神经网络结构
接下来便是设计神经网络的结构。这就如同规划一座大厦的蓝图,决定了神经网络的规模和功能。首先确定输入层神经元的数量,它应该与输入数据的特征数量相匹配。例如,如果我们要构建一个识别手写数字的神经网络,输入数据可能是图像的像素值,那么输入层神经元数量就等于图像像素的总数。然后,选择合适数量的隐藏层以及每个隐藏层的神经元个数。隐藏层的数量和神经元个数会影响神经网络的学习能力和表达能力。一般来说,较复杂的任务可能需要更多的隐藏层和神经元,但同时也会增加计算量和训练时间。最后,确定输出层神经元的数量,它取决于我们要解决的问题的类别数量。比如,对于手写数字识别,输出层有 10 个神经元,分别对应 0 - 9 这十个数字。
四、初始化神经网络参数
在确定了神经网络结构之后,需要对网络中的参数进行初始化。这些参数主要包括神经元之间连接的权重和每个神经元的偏置。权重决定了输入数据在神经元中所占的比重,而偏置则为神经元提供了一个额外的可调节常数。初始化权重时,通常采用随机初始化的方法,使权重在一个较小的范围内随机取值,这样可以避免神经元在初始阶段的对称性,有利于神经网络的学习。例如,可以使用均匀分布或者正态分布来生成随机权重值。偏置的初始化则相对简单,可以初始化为零或者一个较小的常数。
五、前向传播实现
前向传播是神经网络的核心计算过程之一。它是数据从输入层经过隐藏层逐步传递到输出层的过程。在这个过程中,每个神经元根据接收到的输入数据和自身的权重、偏置进行计算,并将计算结果传递给下一层神经元。具体来说,对于输入层的神经元,其输出就是接收到的输入数据本身。而对于隐藏层和输出层的神经元,首先计算输入数据与权重的加权和,然后通过一个激活函数对加权和进行非线性变换,得到神经元的输出。激活函数的作用是引入非线性因素,使得神经网络能够学习到数据中的复杂模式。常见的激活函数有 Sigmoid 函数、ReLU 函数等。通过一层一层的计算和传递,最终在输出层得到神经网络对输入数据的预测结果。
六、损失函数与反向传播
为了让神经网络能够学习到正确的参数值,需要定义一个损失函数来衡量神经网络预测结果与真实结果之间的差距。常用的损失函数有均方误差(MSE)函数、交叉熵(Cross-Entropy)函数等。均方误差适用于回归问题,它计算预测值与真实值之间的平方差的平均值。交叉熵则常用于分类问题,它衡量了预测概率分布与真实概率分布之间的差异。在定义了损失函数之后,就可以通过反向传播算法来更新神经网络的参数。反向传播算法基于链式法则,从输出层开始,逐层计算损失函数对每个参数的梯度,然后根据梯度下降算法,沿着梯度的反方向更新参数值,使得损失函数逐渐减小,从而让神经网络的预测结果更加接近真实结果。这个过程需要反复进行多次训练,直到损失函数收敛到一个较小的值或者达到预定的训练次数。
七、训练与优化神经网络
在完成了前向传播、损失函数定义和反向传播算法的实现之后,就可以对神经网络进行训练了。训练过程就是不断地将训练数据输入到神经网络中,进行前向传播计算预测结果,然后根据损失函数计算损失值,再通过反向传播更新参数的循环过程。在训练过程中,还可以采用一些优化算法来提高训练效率和效果。例如,学习率调整策略可以动态地改变每次参数更新的步长,避免步长过大导致无法收敛或者步长过小导致训练过慢。动量(Momentum)方法可以加速梯度下降的收敛速度,使参数更新更加平滑。此外,还可以采用正则化技术,如 L1 正则化和 L2 正则化,防止神经网络过拟合,提高其泛化能力。
八、模型评估与应用
当神经网络训练完成后,需要对其性能进行评估。通常将一部分独立的测试数据输入到训练好的神经网络中,计算预测结果与真实结果之间的准确率、召回率、F1 值等指标,以衡量神经网络的优劣。如果评估结果不理想,则需要进一步调整神经网络的结构、参数初始化方法、训练算法等,重新进行训练。当得到一个满意的神经网络模型后,就可以将其应用到实际问题中,如进行图像识别、语音识别、数据预测等任务,为解决各种复杂的现实问题提供智能解决方案。
使用 C++构建基础的神经网络模型是一项富有挑战性但又极具意义的工作。它需要我们深入理解神经网络的原理和 C++编程技术,通过精心设计结构、初始化参数、实现前向传播和反向传播等关键步骤,逐步打造出一个能够学习和预测的智能模型。随着不断地学习和实践,我们可以进一步优化和扩展这个基础模型,使其在人工智能的广阔天地中发挥更大的作用,为科技的进步和创新贡献力量。
相关文章:

《C++搭建神经网络基石:开启智能编程新征程》
在人工智能的璀璨星空中,神经网络无疑是最为耀眼的星座之一。而 C以其卓越的性能和高效的执行效率,成为构建神经网络模型的有力武器。今天,就让我们一同探索如何使用 C构建一个基础的神经网络模型,踏上智能编程的奇妙旅程。 一、…...
 { return true; } return false; 简写为 return 条件 详解)
if (条件) { return true; } return false; 简写为 return 条件 详解
在 Java 中,将以下代码: if (条件) {return true; } return false;简写为: return 条件;原理 在 Java 中,条件 是一个布尔表达式,它直接返回 true 或 false。所以,if-else 结构中的逻辑判断和返回值的逻…...
)
Pytorch使用手册-Datasets DataLoaders(专题三)
数据集与数据加载器(Datasets & DataLoaders) 在 PyTorch 中,torch.utils.data.Dataset 和 torch.utils.data.DataLoader 是数据处理的两种核心工具。它们通过模块化的方式,将数据加载与模型训练分离,提高代码的可读性和可维护性。 1. 加载数据集 以 Fashion-MNIST …...
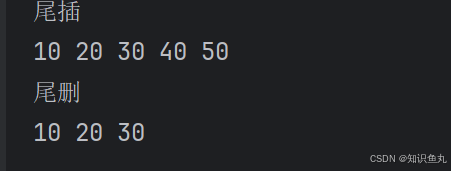
【数据结构】双向链表、单向循环链表、双向循环链表、栈、链栈
目录 一、双向链表 定义类和封装函数以及测试样例如下: 注意事项: 二、循环链表 单循环列表的类和函数封装如下: 注意事项: 三、双向循环链表 结点类和双循环链表的定义部分 函数封装之判空和尾插 双循环链表遍历 双循…...

(动画)Qt控件 QProgressBar
文章目录 QProgressBar1. 介绍一、基本特性二、核心属性 2. 代码实现3. 动画效果 QProgressBar 1. 介绍 QProgressBar是Qt框架中的一个控件,主要用于显示进度条,以图形化的方式表示任务的完成进度或操作的进度。 一、基本特性 显示方向:…...

【AI】基础原理
文章目录 前言1. AI 是如何学习的?2. AI 怎么做决定?3. AI 的“大脑”是什么样的?4. AI 为什么会犯错?5. AI 的不同类型总结:AI 的本质是什么? 前言 人工智能(AI)这个词对很多人来说…...
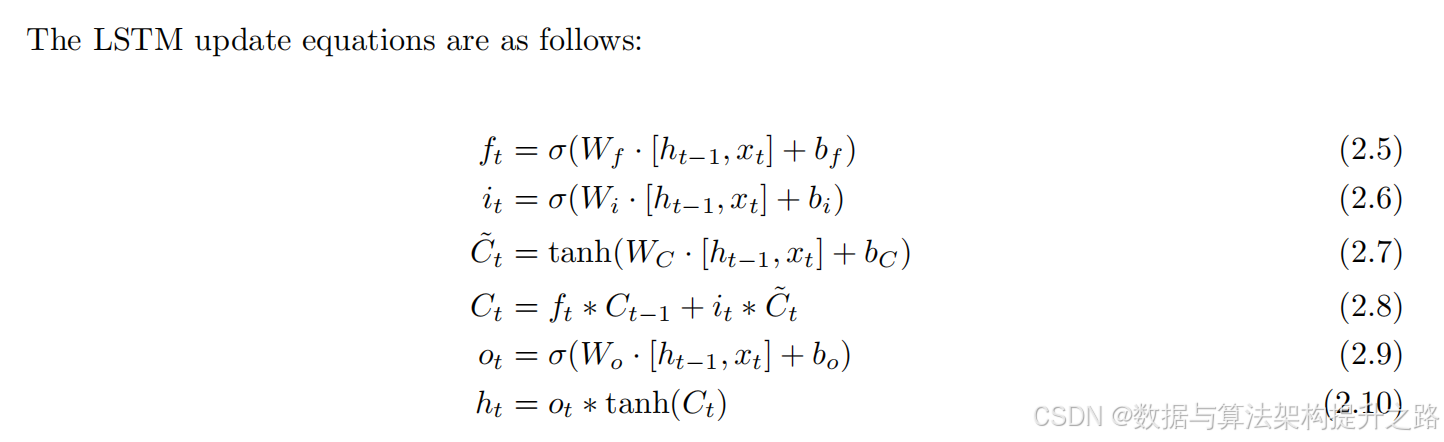
多模态大型语言模型(MLLM)综述
目录 多模态大语言模型的基础 长短期网络结构(LSTM) 自注意力机制 基于Transformer架构的自然语言处理模型 多模态嵌入概述 多模态嵌入关键步骤 多模态嵌入现状 TF-IDF TF-IDF的概念 TF-IDF的计算公式 TF-IDF的主要思路 TF-IDF的案例 训练和微调多模态大语言模…...
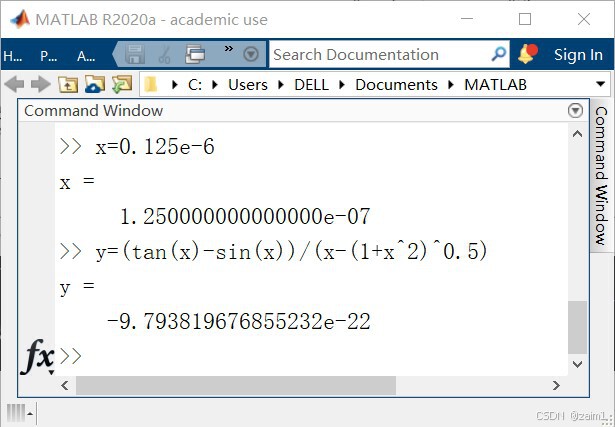
计算机的错误计算(一百六十六)
摘要 探讨 MATLAB 关于算式 的计算误差。 例1. 已知 计算 直接贴图吧: 然而,16位的正确结果为 -0.9765626220703239e-21(ISRealsoft 提供)。这样,MATLAB输出的有效数字的错误率为 (16-2)/16 87.5% . 注&…...

typeof 和 as 关键字
在编程语言中,类型系统是确保代码正确性和可维护性的关键。JavaScript和TypeScript作为现代前端开发的两大支柱,它们在处理类型方面有着不同的机制。本文将探讨typeof和as这两个关键字在JavaScript和TypeScript中的应用,帮助开发者更好地理解…...

Python酷库之旅-第三方库Pandas(237)
目录 一、用法精讲 1116、pandas.tseries.offsets.BusinessHour.is_year_end方法 1116-1、语法 1116-2、参数 1116-3、功能 1116-4、返回值 1116-5、说明 1116-6、用法 1116-6-1、数据准备 1116-6-2、代码示例 1116-6-3、结果输出 1117、pandas.tseries.offsets.Cu…...

git提交到远程仓库如何撤回?
git提交到远程仓库如何撤回? 要撤回已经提交到远程仓库的更改,你可以使用以下步骤: 首先,确保你的本地仓库是最新状态。如果不是,请先执行 git pull 来更新你的本地仓库。 使用 git log 查看提交历史,找到你想要撤回…...

微信小程序常用全局配置项及窗口组成部分详解
微信小程序常用全局配置项及窗口组成部分详解 引言 微信小程序作为一种新兴的应用形态,凭借其轻量级、便捷性和丰富的功能,已成为开发者和用户的热门选择。在开发小程序的过程中,了解全局配置项和窗口组成部分是至关重要的。本文将详细介绍微信小程序的常用全局配置项及窗…...

ThingsBoard规则链节点:Azure IoT Hub 节点详解
目录 引言 1. Azure IoT Hub 节点简介 2. 节点配置 2.1 基本配置示例 3. 使用场景 3.1 数据传输 3.2 数据分析 3.3 设备管理 4. 实际项目中的应用 4.1 项目背景 4.2 项目需求 4.3 实现步骤 5. 总结 引言 ThingsBoard 是一个开源的物联网平台,提供了设备…...

「Mac玩转仓颉内测版32」基础篇12 - Cangjie中的变量操作与类型管理
本篇将深入探讨 Cangjie 编程语言中的变量操作与类型管理,涵盖变量的定义、作用域、类型推断、常量、变量遮蔽、类型转换等方面的知识。通过这些概念的学习,开发者将更好地理解和灵活掌握变量的使用与管理技巧。 关键词 变量定义类型推断常量变量作用域…...

【Android】RecyclerView回收复用机制
概述 RecyclerView 是 Android 中用于高效显示大量数据的视图组件,它是 ListView 的升级版本,支持更灵活的布局和功能。 我们创建一个RecyclerView的Adapter: public class MyRecyclerView extends RecyclerView.Adapter<MyRecyclerVie…...

麒麟系统性能瓶颈分析
1.使用率,表示资源用于服务的时间或容量百分比。100% 的使用率,表示容量已经用尽或者全部时 间都用于服务。 2. 饱和度,表示资源的繁忙程度,通常与等待队列的长度相关。100% 的饱和度,表示资源无法接受 更多的请求。 3…...

Java二分查找+冒泡排序
二分查找在编程中是用来查找目标元素在有序数组中的位置,并返回目标元素的索引 先给定一个有序数组,在创建一个方法来进行二分 主要思想是:根据数组具有下标的特点来分别计算,最左边的索引,以及最右边的索引,在判断目标元素与中间元素的大小,如果目标元素小于中间元素,我们可…...

(三)手势识别——动作识别应用【代码+数据集+python环境(免安装)+GUI系统】
(三)手势识别——动作识别应用【代码数据集python环境(免安装)GUI系统】 (三)手势识别——动作识别【代码数据集python环境GUI系统】 背景意义 随着互联网的普及和机器学习技术的进一步发展,手…...

大数据实战——MapReduce案例实践
🌟欢迎来到 我的博客 —— 探索技术的无限可能! 🌟博客的简介(文章目录) 大数据实战——MapReduce案例实践 一.过程分析(截图)1. 确定Hadoop处于启动状态2. 在/usr/local/filecotent…...
)
OpenCV基础(3)
1.图像直方图 1.1.像素统计 计算图像均值: Scalar cv::mean(InputArray src,InputArray masknoArray()); src:输入图像mask:掩膜层过滤 返回值是对输入图像通道数计算均值后的Scalar对象 计算图像均值与方差: void cv::meanSt…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...