【论文分享】采用现场测量、卫星影像和机器学习方法研究空气温度与城市发展强度之间的关系
鉴于城市热问题的严重性,城市化与空气温度之间的关系已成为全球关注的关键问题。本次我们给大家带来一篇SCI论文的全文翻译。该论文提取了常见城市规划指标,这些指标通过卫星影像来确定城市发展的强度。该论文确定的关系可以帮助在城市化和植被平衡的决策过程中提供支持。
【论文题目】
Investigating the relationship between air temperature and the intensity of urban development using on-site measurement, satellite imagery and machine learning
【题目翻译】
采用现场测量、卫星影像和机器学习方法研究空气温度与城市发展强度之间的关系
【期刊信息】
Sustainable Cities and Society,Volume 100, January 2024, 104982
【作者信息】
Tsz-Kin Lau, 国立成功大学建筑系,台湾台南市东区大学路1号,邮政编码701
Tzu-Ping Lin,国立成功大学建筑系,台湾台南市东区大学路1号,邮政编码701,lintp@mail.ncku.edu.tw
【论文链接】
https://doi.org/10.1016/j.scs.2023.104982
【关键词】
城市规划、卫星影像、机器学习、空气温度、城市气候
【本文亮点】
-
空气温度可以通过从卫星影像中提取的特征进行预测。
-
建筑覆盖率增加10%可能导致空气温度上升0.28°C。
-
绿化覆盖率增加10%可能在一个区域内产生良好的降温效果。
-
训练良好的机器学习模型可以帮助理解城市总体气候。
-
训练良好的神经网络可以帮助评估和绘制空气温度分布图。
【摘要】
鉴于城市热问题的严重性,城市化与空气温度之间的关系已成为全球关注的关键问题。在这项研究中,提取了包括建筑覆盖率(BCR)、建筑容积率(FAR)和植被覆盖率(FVC)等常见城市规划指标,这些指标通过卫星影像来确定城市发展的强度。通过现场测量和机器学习(ML),观察和分析了城市发展强度与空气温度之间的关系。根据现场测量结果,台北市中心的空气温度在植被覆盖率每增加10%时平均下降约0.32°C。然而,建筑覆盖率和建筑容积率每增加10%时,空气温度平均分别上升约0.28°C和0.03°C。机器学习模型的结果展示了相同的趋势,尽管与现场测量结果存在一些微小差异,但这些差异被认为是合理和可接受的。在这项研究中,提出了一种更便捷的方法来提取城市规划指标,描述区域内城市发展的强度,并有助于估计没有测量仪器的地区的空气温度。本研究确定的关系可以帮助在城市化和植被平衡的决策过程中提供支持。
【引言】
由于全球变暖问题的严重性,城市热岛效应的缓解已成为全球关注的关键问题。随着空气温度和城市化的增加,城市热岛效应也在加剧(Li et al., 2021; Zou et al., 2021)。高温增加了人类的发病率和死亡率(Singh et al., 2020),极端高温与多种健康问题有关,如心肺疾病、血管内脱水和电解质失衡(Kim et al., 2012; Osilla et al., 2018)。高温还会降低城市热舒适度。生理等效温度(PET)是用于确定微尺度户外热舒适度的指标;较高的空气温度通常与较高的PET值相关,这表明城市区域的生物气候条件恶化(Matzarakis & Amelung, 2008)。鉴于高温的影响,许多研究者试图明晰空气温度与城市环境之间的关系。在城市规划中,平衡土地利用/土地覆盖(LULC)和植被被认为是缓解城市热岛效应的最重要策略之一(Lin et al., 2017)。因此,研究空气温度与城市发展强度之间的关系对于缓解城市热岛效应并创造热舒适的环境至关重要。
遥感技术在城市研究和环境观测中得到了广泛应用。这项技术使得能够收集城市规划信息,如植被覆盖、水体位置和地表温度(LST)(Hsiao-Tung, 2014; Kaplan & Avdan, 2017; Avdan & Jovanovska, 2016)。卫星影像还提供了高分辨率的地表图像。例如,SPOT 6是一颗能够提供高分辨率地表图像的卫星,其成本较低(Kganyago et al., 2018)。该卫星提供1.5米分辨率的全色影像,能够获取全面的地表影像。同时,它还提供6米分辨率的多光谱影像,可以较好地描绘地表特征(Forsyth et al., 2014)。先前的城市研究已经使用SPOT 6来调查城市变化和分类土地利用/土地覆盖(Akay & Sertel, 2016; Gxumisa & Breytenbach, 2017)。除了平衡LULC和植被,控制建筑高度也可以用来缓解城市热岛效应。通过仔细控制场地覆盖率也可以缓解城市热岛效应(Yuan & Chen, 2011)。归一化数字表面模型(nDSM)是一种利用数字地形模型(DTM)和数字表面模型(DSM)之间的高程差异来计算建筑高度的模型(Beumier & Idrissa, 2016)。研究应用nDSM的城市研究集中在估计城市绿地体积、城市对象提取和LULC分类(Huang et al., 2013; Grigillo & Kanjir, 2012; Zhou, 2013)。根据遥感获得的结果,卫星影像被认为是城市研究的绝佳工具。
随着计算机技术的进步,机器学习(ML)已成为全球范围内流行的工具。这项技术通过基于经验的自动改进来帮助解决问题。许多研究者已在金融建模、医疗保健和市场营销等各种决策过程中使用了机器学习(Jordan & Mitchell, 2015)。机器学习算法也被应用于城市研究中,以预测城市建筑能源性能、促进城市规划决策、识别城市热岛效应的关键变量,并绘制城市空气温度图(Fathi et al., 2020; Koumetio et al., 2021; Yoo, 2018; Venter et al., 2020)。除了城市研究,机器学习还被广泛用于遥感中。例如,它被用来研究液化现象、解释遥感图像和表征岩石体(Lary et al., 2016)。这意味着机器学习适用于结合遥感和城市环境的研究。
从以往的研究来看,许多分析依赖于由政府或营利组织提供的官方城市数据集,这些数据集包括建筑、植被和人口信息。收集这些数据集需要大量的人力、技术和时间,使得城市研究变得更加具有挑战性。除了上述问题,我们还发现,大多数空气温度图是通过插值生成的,这种方法准确度较低,且高度依赖于测量点的密集分布。因此,提出了一种结合遥感和机器学习的方法,以提取详细的建筑信息,而不仅仅依赖于卫星图像的反射率计算。为了解决数据集收集问题,使用了相对经济的卫星影像来观察地表,并使用机器学习方法从卫星影像中提取特征,以帮助进一步的计算和分析。在空气温度映射方面,机器学习方法被用于分析空气温度与城市特征之间的关系,尤其是在夏季最热时段(下午1点)。利用这种关系,可以有效而准确地绘制出夏季下午1点的城市空气温度分布。虽然类似的研究已被进行,但本研究计算并应用了常见的城市规划指标,包括建筑覆盖率(BCR)、建筑容积率(FARa)近似值和植被覆盖率(FVC)。这些指标提供了更直观的见解,并为未来的城市规划工作提供了更大的便利。此外,与依赖插值绘制空气温度分布的先前研究不同,机器学习提供了一种更准确和高效的方法来绘制夏季下午1点的空气温度分布,考虑了城市发展强度,而不仅仅是统计空气温度数据。
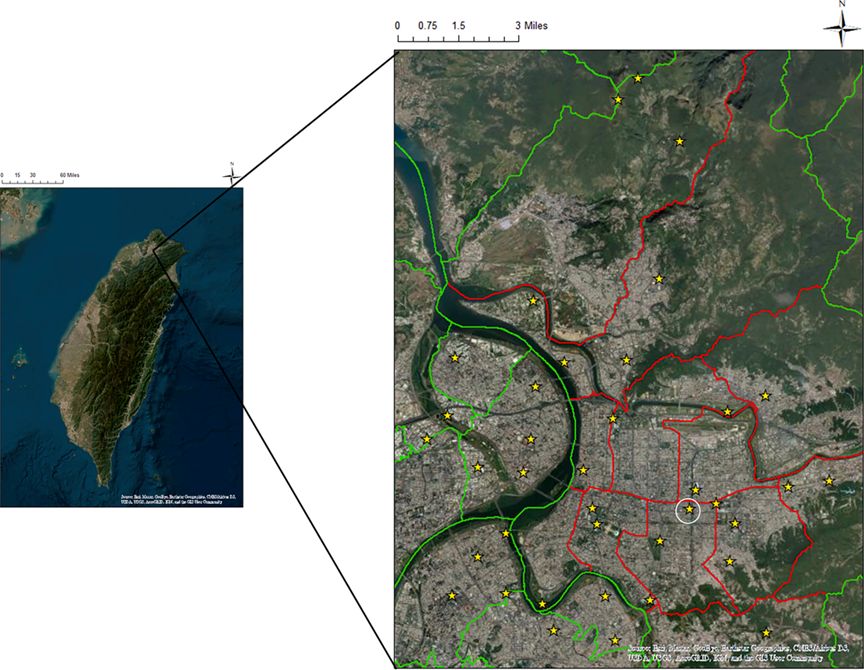
图1. 研究区域,包括台北市和部分新北市。红色突出显示的区域是台北市,绿色突出显示的区域是新北市。黄色星星标记的点是HiSAN和CWB的测量点。圈出的点是用于机器学习模型训练和预测的空气温度参考点。(来源:ArcGIS软件中的基础地图)。
【材料和方法】
2.1 研究区域
本研究选择了台北市和新北市的多个区域作为研究区域(见图1)。台湾北部属于亚热带气候,夏季从5月底持续到9月。1981年至2010年,台北市的年均气温约为23°C。7月和1月分别是最热和最冷的月份,气温约为29.6°C和16.1°C。由于全球变暖的影响,台北市的高温天气变得越来越频繁。除了气象条件外,这两个城市都高度城市化,拥有高层建筑,并设有多个商业中心,例如三峡、万华和信义区。除了这些高层建筑外,两个城市还拥有密集的三至九层楼建筑。在包括研究区域在内的台湾北部,可以观察到强烈的城市热岛效应(UHI),这既是由于城市化的影响,也与地形有关(Lin et al., 2008)。因此,由于台北市和新北市的高度城市化和强烈的城市热效应,这些地区被认为是研究城市发展强度与空气温度关系的理想地点。
2.2 卫星影像处理
考虑到遥感技术的成熟,本研究使用了SPOT 6影像来提取地表特征并计算城市规划指标,以描述城市发展的强度。所用的SPOT 6影像由国防医学院空间与遥感研究中心(CSRSR)提供。在台湾,SPOT、先进陆地观测卫星(ALOS)和TerraSAR-X影像均可用于非营利性用途。为了调查城市地表特征,SPOT 6影像拍摄于2021年1月13日凌晨1:57,影像捕捉了低云覆盖和研究区域的完整覆盖。获得了分辨率为1.5米的全色影像,能够详细描绘城市地表特征,包括建筑物形状、道路网络和建筑物之间的小巷。
为了研究研究区域内建筑高度的分布,计算了归一化数字表面模型(nDSM)。为此,使用了数字地形模型(DTM)和数字表面模型(DSM)。DTM的空间分辨率为20米,由内政部地政司卫星调查中心提供。此外,使用了分辨率为30米的ALOS世界3D模型(AW3D30)作为DSM模型来计算nDSM。DSM来自于ALOS上的立体遥感仪器(Takaku et al., 2020),具有30米的分辨率,可免费用于商业和非商业用途。
在收集了DTM和DSM后,使用ArcGIS软件进行了重采样和计算。在重采样过程中,将DTM重采样至30米空间分辨率,与DSM相同。重采样后,计算DTM和DSM之间的差异,生成了nDSM。在估算建筑高度之前,nDSM和U-net分割结果都被重采样至1米的空间分辨率。随后,将nDSM与U-net的分割结果叠加,以提取建筑高度信息。nDSM的像素值与非建筑像素重叠的部分被替换为0,与建筑分类像素重叠的部分保持为建筑高度。
2.3. 气象数据
气象数据在分析城市发展强度与气温之间的关系时至关重要。为了研究人类的生物热环境,使用了通过现场测量获得的气温数据。尽管地表温度(LST)广泛用于评估城市热岛效应的分布和分析人类热舒适度,但现场测量获得的气温数据能更好地指示人类最直接暴露的生物热环境(Bokaie et al., 2016; Imran et al., 2021)。为了研究研究区域内的气温分布,数据来自高密度街道级气温观测网络(HiSAN,建筑与气候实验室,国防医学院)和中央气象局(CWB)。为了确定热条件与城市发展模式之间的关系,在HiSAN中安装了几个传感器(LOGPRO TR-32;Tecpel,新北市,台湾),这些传感器高度距离地面2米,并分布在不同的城市化程度较高的区域(Chen et al., 2018)。在1980年代初期,CWB开发了全球数值天气预报系统。该系统提供包括气温、风速和相对湿度在内的气象信息(Liou et al., 1997)。在研究区域内使用了HiSAN和CWB识别的共38个测量点(图1)。这些点大多数位于城市化程度较高的区域,仅有少数位于绿色覆盖程度不同的区域。由于台湾北部夏季的强烈城市热效应,收集了台北市和新北市的数据。统计数据显示,八月大多数天气温较高。2020年8月有29天(约94%)和22天(约71%)的气温高于33°C和35°C。即使在雨天,气温仍然很高,而且最高气温大多出现在下午1点。为了更好地理解高气温与城市发展强度之间的关系,2020年8月的气象数据和每日气温数据在下午1点进行收集,以进行后续分析。此外,还在2020年7月和9月的下午1点收集了每日数据,以确定和分析城市发展强度与气温之间的关系。
2.4. 城市发展强度
为了客观描述城市发展的强度,使用了常见的城市规划指标,包括建筑覆盖率(BCR)、容积率(FAR)和植被覆盖率(FVC),以确定和分析城市发展强度与气温之间的关系。通常,较高的城市发展强度值会导致更高的BCR和FAR值,而高FVC值通常出现在农村地区和城市中的绿地。在识别一个区域的BCR时,应确定该区域内建筑物的投影面积。在本研究中,为了准确提取建筑物的投影面积,使用了U-net从卫星图像中确定建筑物的形状。U-net是一种在医疗领域开发的细胞分割的机器学习算法。该算法能够快速高效地执行物体分割,即使标注图像较少(Ronneberger et al., 2015)。除了医疗领域,U-net也在城市研究中得到了良好的应用。U-net被用于建筑物分割以及城市和郊区森林的分类(Awad & Lauteri, 2021; Sariturk & Seker, 2022)。U-net在城市研究中的可行性和性能已得到验证。由于建筑物分割需要详细的地表特征,使用了来自SPOT 6的标注全色图像进行模型训练。设计了一个包含四层卷积层和四层上采样层的U-net模型。为了避免过拟合,还添加了丢弃层。在经过100个训练周期后,U-net模型得到了良好的训练,能够分割建筑物。然后使用建筑物分割的结果提取建筑高度,将nDSM和建筑物分割图像重采样到1米的分辨率并进行叠加。任何与未分割建筑物的像素重叠的nDSM值都被移除。随后,在计算建筑高度后,使用以下公式计算FARa:

在FARa的计算中,假设建筑物覆盖面积的100%对应于楼面面积,因为使用卫星图像准确分类土地使用类型面临挑战。此外,建筑物楼层高度被认为是重要的,台湾的平均楼层高度约为3米。基于这些假设,计算了每个网格的FARa。FARa提供了网格建筑强度和整体城市发展强度的直接而清晰的表示。
根据绿色空间的降温效果,如小型城市公园,它通常影响到公园宽度约一半的区域。绿色区域不仅增强了降温效果,还提供了对太阳辐射的保护,这在夏季尤为重要(Motazedian et al., 2020)。从SPOT 6获得的多光谱图像包含四个波段(蓝色波段、绿色波段、红色波段和近红外波段),这些波段提供了不同的反射值,用于观察各种地表特征,如归一化植被指数(NDVI)和植被覆盖率(FVC)。FVC定义为单位面积内的植被百分比,易于理解,适用于城市规划(Chang et al., 2021)。在这里,NDVI的计算公式为:

总体而言,本研究旨在计算城市规划指标,如建筑覆盖率(BCR)、楼面面积比(FARa)和植被覆盖率(FVC),以评估台北市的城市发展强度。为了分析高温与这些城市指标之间的关系,采用了100米的半径对38个测量点进行了分区统计,这代表了最近周围环境的影响(大约一个城市街区;Eliasson & Svensson, 2003;Potgieter et al., 2021)。从HiSAN和CWB获得的38个测量点与城市规划指标图重叠,通过分区统计提取了BCR、FARa和FVC的相应数据,用于后续分析。
2.5. 机器学习算法
为了理解城市发展强度与空气温度之间的关系,本研究使用了深度神经网络(DNN)和极端梯度提升(XGB)模型。一般来说,神经网络(NNs)广泛应用于多个任务,例如物体检测、语音识别和自动驾驶导航(Peng & Chen, 2019)。神经网络也用于人工智能应用和城市研究。经过良好训练的神经网络可以帮助准确预测城市水需求,预测城市空气污染情境中的污染物浓度,以及预测地表温度(LST)以了解未来LST趋势(Ghiassi et al., 2008;Viotti et al., 2002;Maduako et al., 2016)。XGB是另一种有效的机器学习算法,因其高计算效率和处理过拟合问题的能力而广泛使用(Chen & Guestrin, 2016;Fan et al., 2018)。一些城市研究使用XGB通过遥感数据获取城市环境中的浓度估计,并利用极高分辨率图像进行土地利用/土地覆盖(LULC)分类(Fan et al., 2020;Georganos et al., 2018)。鉴于神经网络和XGB的巨大成就和广泛应用,本研究决定使用DNN和XGB来分析高空气温度与城市发展强度之间的关系。
在本研究中,构建了一个具有四个隐藏层的DNN模型,经过5000次训练迭代,并使用了均方绝对误差(MAE)作为损失函数和Adam优化器进行编译。同时,使用了普通的XGB回归器。由于该算法具有多个决策树,前一个树的残差为每棵树提供信息。尽管XGB的结果是所有树结果的总和,但它们与随机森林中的多数投票输出不同(Wang et al., 2019)。总共从HiSAN和CWB收集了1143个数据点,这些数据点是在2020年8月的下午1点收集的,其中914个(80%)作为训练样本输入,229个(20%)作为测试样本输入。
【结果】
在进行U-net分割、气象数据处理、城市规划指标计算和机器学习算法分析后,开发出了城市规划指标的地图,以及城市发展强度与空气温度之间关系的地图。
3.1 城市规划指标的制图
为了检查分割结果的准确性,对台北市政府提供的建筑物形状矢量文件进行了比较。然而,由于数据收集的限制,仅对台北市的城市区域内的分割结果进行了比较。在建筑数据收集后,将数据导出为1米空间分辨率的栅格数据以进行比较。基于像素的比较显示,使用U-net模型进行建筑物形状分割的准确度为76.2%,这一数值被认为是可以接受的(Liu et al., 2007)。图2展示了台北市政府提供的建筑形状与U-net分割结果的比较。尽管U-net模型成功分类并分割了大多数建筑物,但对一些特殊建筑物(如体育馆、带特殊屋顶设备(例如太阳能板)的建筑物以及极高层建筑)的投影区域分割敏感度不足。除了注释减少外,卫星图像的混合像素问题也强烈影响了分割过程(Foody, 1996)。鉴于U-net分割的性能结果是可以接受的,应用了获得的分割结果并进行了处理,以创建城市规划指标地图。
为了随后进行全面和方便的分析,使用了网格大小为50米的地图进行观察和分析。为了提取建筑覆盖率比(BCR),创建了一个显示建筑分割像素百分比的地图。在研究区域内,BCR范围从0到0.93。除了空地和农村地区外,大多数城市区域的BCR为0.1–0.6。仅少数区域的BCR超过0.6,这些区域大多数位于高度开发的地区,如三峡、大安和内湖。为了评估研究区域内的建筑容积率(FARa),通过将建筑分割结果与nDSM叠加计算得出了建筑高度地图。随后,还计算了平均FARa地图。结果表明,研究区域内的FARa范围为0–6,而大多数城市区域的FARa为0.2–4。这些高FARa值大多数是由于存在用于住宅和商业用途的高层建筑。利用SPOT 6多光谱影像的红色和近红外波段的反射率计算了植被覆盖率(FVC)地图。然后使用NDVI和FVC方程计算了FVC地图。结果表明,研究区域内的FVC范围为0–0.97,其中大多数高FVC值(超过0.6)出现在农村地区。FVC地图清晰地反映了城市区域内的绿地,如大安森林公园、双园河滨公园和228和平公园。图3展示了城市规划指标的地图。
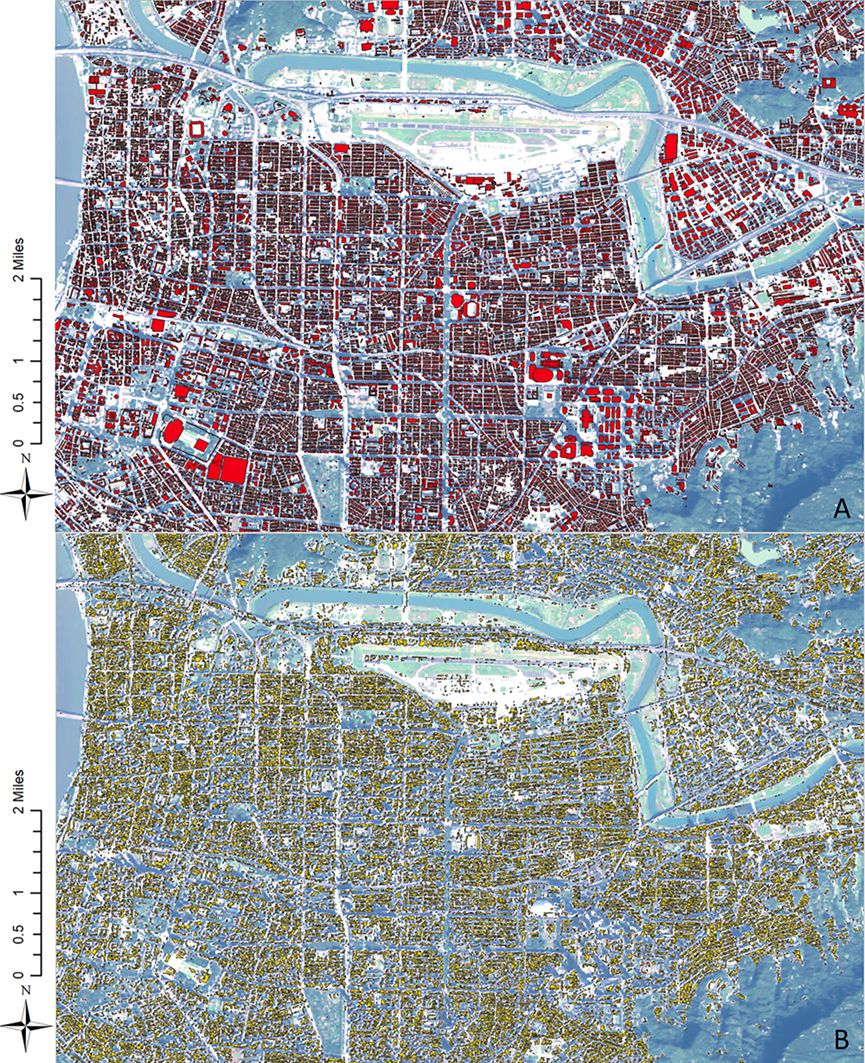
图2. 台北市政府提供的建筑形状(A)与U-net分割结果(B)的比较。底图来源于2021年1月13日1:57拍摄的SPOT 6多光谱影像。

图3. 经过多次计算获得的城市规划指标地图。建筑形状图来自U-net分割(A),网格大小为1米;建筑覆盖率(B)的地图;楼地板面积比(FARa)(C)的地图;以及植被覆盖率(FVC)(D)的地图,网格大小为50米。
3.2. 现场测量结果
现场测量结果表明,研究区域的空气温度范围为20.60°C至38.72°C,平均空气温度约为33.50°C。此外,大多数农村地区的空气温度较低,低于30°C,这些地区表现出高FVC值和低BCR及FARa值。为了在微观尺度上确定城市发展强度与空气温度之间的关系,使用了半径为100米的区域统计来代表最近的周围环境(大约一个街区;Eliasson等,2003)。选择了约200米的网格大小作为后续分析的单位。此外,将来自HiSAN和CWB的38个测量点与城市规划指标地图进行了重叠,并通过区域统计提取了BCR、FARa和FVC的背景数据。除了FVC外,BCR和FARa与空气温度呈正相关。为了清晰识别FVC、BCR、FARa和空气温度之间的关系,计算了2020年8月每个测量点在下午1:00的平均空气温度(见图4)。趋势线和线性方程也呈现出来。这些线性方程表明,FARa的影响远低于FVC和BCR。然而,结果表明,植被覆盖的降温效应明显,而高城市化带来的城市热效应也很显著。除了FVC、BCR、FARa和空气温度之间的关系外,表1还展示了城市规划指标值增加的影响。每增加10% FVC,空气温度明显降低了约1.23°C。由于一些测量点位于较高的农村地区,这可能导致空气温度样本较低,从而使得FVC增加导致的空气温度降低结果略有高估。然而,总体趋势仍被认为是可接受和现实的。空气温度随着BCR和FARa的增加而升高。每增加10% BCR和FARa,空气温度分别平均增加约0.82°C和0.21°C。为了提高结果的可靠性,我们进一步分析了来自台北市中心的测量点,详细研究了空气温度与城市规划指标之间的关系。台北市中心共有28个测量点。通过相同的重叠分析,调查了FVC、BCR和FARa的增加与空气温度的关系,如表1所示。台北市中心调查的关系与之前的结果类似,呈现出相同的趋势。空气温度的增加来源于BCR和FARa的增加,而空气温度的下降来源于FVC的增加。尽管趋势类似,但结果有所不同,台北市中心的空气温度变化较少。根据台北市中心的现场测量结果,FVC每增加10%,空气温度平均降低0.32°C;而BCR和FARa每增加10%,空气温度分别平均增加0.28°C和0.03°C。除了台北市中心空气温度变化较少外,台北市中心的多项式方程的R2值低于之前的结果,呈现出台北市中心更复杂的情况。在图4中,FVC与空气温度之间的关系清晰地展示了植被覆盖对降低空气温度的降温效应。相比之下,在BCR和FARa相对较低的地方,空气温度随着BCR和FARa的增加而升高,但在BCR和FARa相对较高的地方,空气温度的变化变得不可预测。结果不仅展示了由城市化造成的城市热问题,还包括其他因素(如地形、太阳辐射、人为热的稀释不足以及商业和工业活动)造成的城市热问题(Mutiibwa等,2015;Nojarov,2018;Yuan等,2020;Lai & Cheng,2010)。尽管有多个因素影响空气温度,但现场测量结果具体表明,高城市发展强度与高空气温度相关。
表1 现场测量和机器学习模型模拟中,空气温度随城市规划指标增加的平均变化

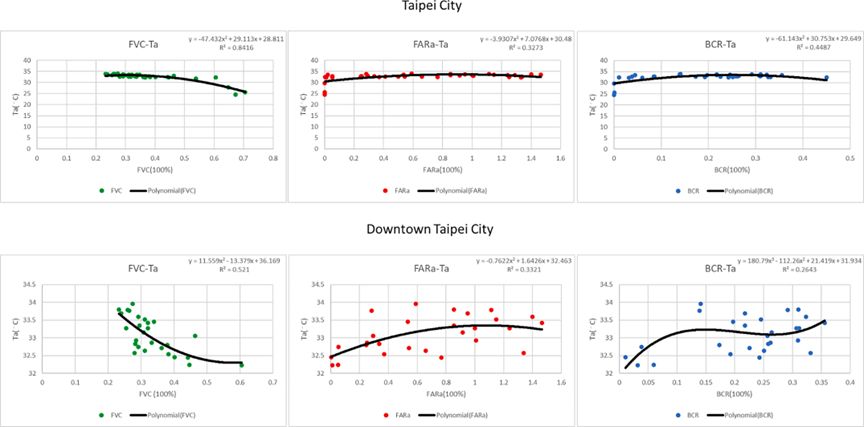
图 4. 基于现场测量的FVC(A)、FARa(B)、BCR(C)与空气温度(Ta)的关系。
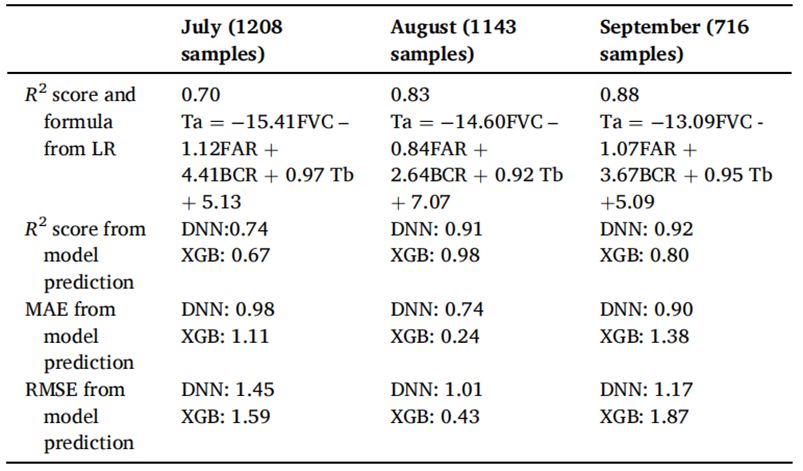
表 2 使用城市规划指标和空气温度(Ta)数据的线性回归(LR)模型结果。列出了使用2020年7月、8月和9月下午1:00获得的数据的机器学习(ML)模型预测性能结果。
3.3. 机器学习算法结果
除了城市规划指标,参考空气温度(Tb)在预测空气温度中也至关重要。例如,东区的HiSAN测量点的空气温度被用作机器学习训练和预测的参考空气温度。然而,在进行深度神经网络(DNN)和极端梯度提升(XGB)模型处理之前,首先使用多元线性回归(LR)验证了使用从卫星影像中提取的城市规划指标进行空气温度预测的可行性。LR模型的R²值用于评估数据的解释程度。通常,R²值为0.75、0.50和0.25分别被描述为强、中和弱(Henseler, 2017)。LR和机器学习的结果如表2所示。使用2020年8月1:00 p.m.的数据,LR模型的R²值为0.83,表明该点的空气温度可以较好地通过从卫星影像中提取的城市规划指标来解释。
这些空气温度数据随后被拆分并输入到机器学习模型中进行训练和测试。DNN和XGB模型的R²值分别为0.91和0.98,这意味着机器学习模型准确地学习了城市规划指标与空气温度之间的关系,并准确地预测了空气温度。机器学习模型的结果也呈现在表2中。均方误差(MAE)和均方根误差(RMSE)通常用于评估机器学习模型的性能。一般来说,MAE和RMSE值越低,预测值与真实值之间的差异越小。在本研究中,DNN模型和XGB模型的MAE值分别为0.74和0.24,均为较低且可接受的,而RMSE值分别为1.01和0.43。在所有机器学习模型性能指标中,XGB模型的值高于DNN模型,这意味着XGB模型在2020年8月1:00 p.m.的空气温度预测中更为准确。
为了检查机器学习模型在不同月份预测空气温度的实际效果,还测试了2020年7月和9月1:00 p.m.的数据,使用训练好的DNN和XGB模型。然而,在测试之前,这些数据使用LR进行了评估,以确定城市规划指标对预测空气温度的解释能力。使用这些数据的LR模型的R²值为0.70和0.88,分别为中等和显著。结果和LR方程见表2。所有2020年7月和9月1:00 p.m.获得的数据都通过训练好的DNN和XGB模型进行了检验。然而,与2020年8月1:00 p.m.的结果相比,DNN模型在预测2020年7月和9月1:00 p.m.的空气温度时表现更好。此外,与XGB模型显著下降的表现相比,DNN模型在不同数据下的表现没有出现大幅恶化。尽管2020年7月1:00 p.m.的数据未能明确解释城市规划指标提取的结果,但DNN模型的MAE仍保持在1以下,结果可接受。这表明,DNN模型在不熟悉的情况下比XGB模型更为适用。
使用机器学习模型学习和识别城市规划指标与空气温度之间的关系。训练数据集通过增加FVC、BCR或FARa值进行了编辑,以模拟具有编辑城市规划指标的环境,结果见表1。两个机器学习模型在FVC、BCR和FARa变化方面表现出与现场测量相同的趋势。只有使用FARa模拟的机器学习模型表现与现场测量结果大相径庭,未能反映空气温度的上升。然而,机器学习模型的整体表现是可接受和合理的。根据DNN和XGB模型的模拟结果,FVC每增加10%,空气温度平均降低1.40°C和1.14°C。此外,BCR每增加10%,空气温度平均增加0.48°C和0.52°C。机器学习模型的模拟结果揭示了与现场测量相似的现象,表明空气温度随着城市发展和城市化强度的增加而升高。
由于其更高的实用性,DNN模型的性能集中在后续内容中。然而,由于DNN模型模拟中FARa的影响不明确,因此后续分析仅探讨了FVC和BCR的影响。为进一步探讨城市规划应用,调查了增加FVC和BCR值的特征(见图5)。图5显示了不同BCR值下FVC值增加的平均趋势。结果表明,背景BCR值的增加使FVC值增加时的降温效果明显增强,意味着在高度城市化地区增加绿地具有良好的降温效果。还计算了不同背景FVC值下BCR值增加的平均趋势(见图5)。结果表明,背景FVC值增加时,空气温度明显上升,意味着在农村地区和绿地的城市发展和建设增加了空气温度,并带来了严重的城市热问题。尽管通过DNN模拟获得的空气温度变化在某些情况下极端,但DNN模型模拟中的趋势仍可作为参考。

【讨论】
4.1. 机器学习模型性能
尽管机器学习(ML)模型在预测空气温度方面表现良好,但也发现了一些问题,值得讨论。首先,尽管已确认使用从卫星影像中提取的城市规划指标来描述和预测空气温度的可行性,但在七月的数据集与八月和九月的数据集之间观察到了一些性能差异。七月的数据集的线性回归(LR)模型的R²值较低。因此,为了应对这个问题,国家减灾科学技术中心调查了2020年七月的气候情况。根据发布的报告,2020年七月存在一些主要的气候问题,包括没有台风和几天的极高气温(Wu et al., 2020)。在异常气候情况下,空气温度可能变得不规则和不可预测。这意味着,从卫星影像中提取的城市规划指标更适合用于描述正常气候情况下的空气温度。其次,虽然两种机器学习模型在训练和测试数据集上的空气温度预测表现良好,但与深度神经网络(DNN)模型相比,XGB模型的性能在评估不同月份的数据时明显下降。这表明,XGB模型在2020年八月下午1点准确学习了城市规划指标与空气温度之间的关系,但不适用于其他情况。相比之下,DNN模型在正常情况下学习了城市规划指标与空气温度之间的关系,并能够反映大多数正常气候情况,尽管其训练过程中表现低于XGB模型。最后,从现场测量得到的结果通常略高于从ML模型模拟中得到的结果。如表1所示,只有通过XGB模型预测模拟的每10% FVC值的平均变化低于现场测量结果。空气温度的增加可能是由于其他因素,如盆地地形、车辆的存在以及空调的使用(Chang, 2016; Akbari et al., 2016)。在进一步的城市规划工作中,只有常见的城市规划指标被考虑在内。尽管这些因素存在于现实场景中,但在ML模型中并未考虑,这可能是ML模型低估空气温度变化的原因。即使这些结果可以在城市规划方面提供帮助,未来的工作中仍应考虑这些因素。
4.2. 机器学习模型在空气温度绘制中的表现
鉴于DNN模型的实用性,使用该模型估算并绘制了台北市和新北市的空气温度分布。为了研究城市热岛效应,使用了2020年8月25日下午1点的数据(数据集中最高的空气温度)。将这些绘制结果与通过Kriging插值法创建的地图进行了比较。插值是一种流行的方法,广泛用于估计区域内的空气温度(Stahl et al., 2006)。本研究中使用了2020年8月25日下午1点从HiSAN和CWB获得的数据,通过Kriging插值法绘制了空气温度。接下来,将来自台北东区的HiSAN测量点的参考空气温度输入到DNN模型中,以估算台北市和新北市的空气温度分布。绘制结果见图6。从插值结果来看,Kriging插值法显示的温度范围为36.7°C至37.8°C。Kriging插值法还显示了严重城市热岛问题区域的平滑空气温度分布。除了插值结果外,DNN模型估算了2020年8月25日下午1点的空气温度分布。然而,与插值结果相比,DNN模型显示了不同的空气温度范围,即34.18°C至36.19°C。如前所述,从卫星影像中提取的城市规划指标适用于描述正常气候情况,因此插值与DNN模型预测之间的差异是合理且可接受的。此外,大多数低空气温度情况出现在农村地区,这并未影响对城市热岛的识别。DNN模型提供的空气温度分布图与插值结果相似。这张地图不仅基于参考空气温度和空气温度统计数据,还考虑了背景城市规划指标,从而揭示了城市热岛问题严重的区域。除了强城市热岛区域外,DNN模型还反映了绿地的降温贡献。尽管DNN模型的预测足以反映台北市和新北市的城市热岛情况,但某些区域的结果与插值结果显著不同,例如万华区、中正区和信义区。在万华区和中正区,由于位于台北盆地中心,导致严重的城市热岛问题。此外,信义区的情况则不同。信义区是一个更新区,具有改善的通风条件,没有地形问题,尽管有几个高层建筑。由于这种改善的地形和通风,现场测量的空气温度可能与其他强城市热岛区域有所不同。尽管DNN模型在绘制空气温度分布方面表现良好,但未来的研究中应通过测试其他算法或添加更多气象和城市信息来提高绘图性能。
为了比较城市内通过插值和机器学习(ML)预测绘制的空气温度结果,收集了以前使用插值法绘制空气温度的研究。为了更好的比较,选择并比较了台北市的研究。不同方法生成的台北市空气温度地图包括各种Kriging插值、回归和模拟(Hsu et al., 2017; Taheri-Shahraiyni & Sodoudi, 2017)。插值生成的空气温度地图分布更平滑。每个单元的空气温度与邻近单元相似,除非与测量点重叠。另一方面,ML和非线性回归生成的空气温度地图显示了更复杂的分布,体现了空气温度与城市因素之间的关系。除了空气温度数据外,地图生成中还考虑了更多因素,如土地利用和城市发展的强度。从比较中可以看出,插值被认为是生成空气温度地图的良好工具,使用方便。而ML和非线性回归生成的空气温度地图则更详细。经过良好训练的ML模型和良好采样的回归模型可以提高空气温度绘制的准确性。尽管ML和非线性回归可以生成更好的空气温度地图,但必须处理和确定空气温度与变量之间的良好特征提取和清晰关系。
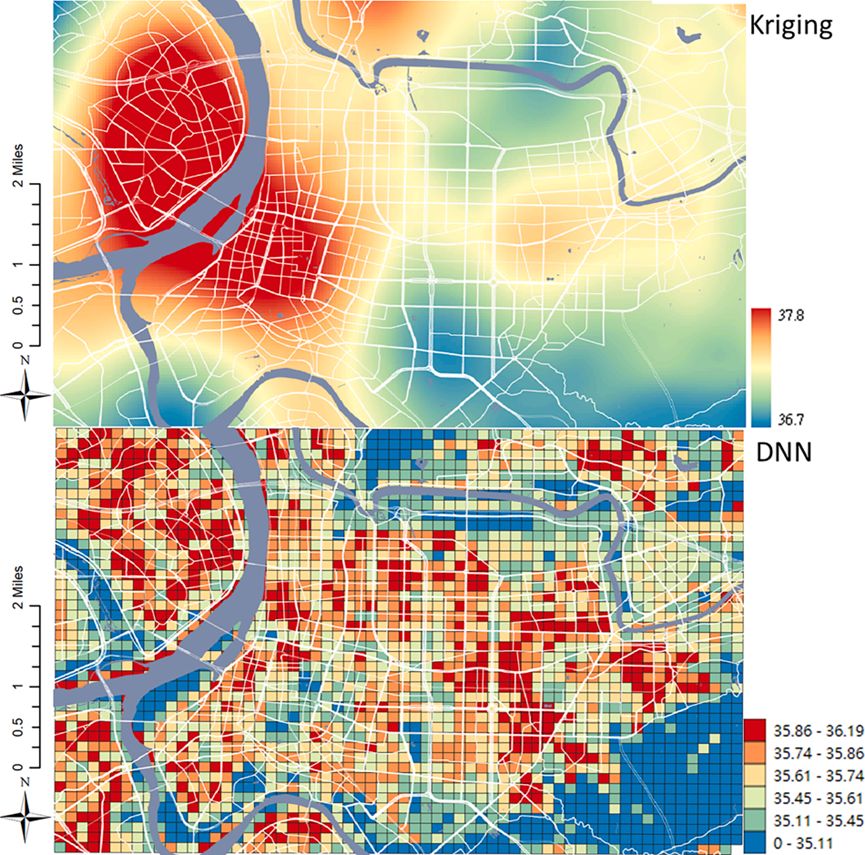
图6. 2020年8月25日下午1点DNN模型预测与插值算法空气温度绘制的比较。上方显示的是Kriging插值结果,下方为DNN预测结果。
4.3. 局限性与建议
尽管结果展示得很出色,但本研究仍存在一些限制,值得讨论。首先,为了深入展示台北市的热岛问题,本研究分析了2020年8月下午1点的空气温度。尽管高温表现良好且热岛问题显而易见,但在2020年8月最热时段的数据可能导致了过高的估计。这些数据呈现了台北市的极端热环境,有助于识别高温与城市规划指标之间的关系。然而,2020年8月最热时段的数据虽然对展示台北市的热环境仍有参考价值,但研究中提出的关系可能不适用于台北市每小时的情况。尽管本研究提出的关系是可靠的,并可为未来的城市规划提供帮助,但应进一步获取和分析台北市的长期小时温度数据,以探究不同时间段城市因素与温度之间的关系。
为了建立一个易于使用的城市规划参考,本研究利用了三个城市规划指标:FVC、BCR和FARa,以简化城市热环境。虽然多项式方程显示了高温与这些城市规划指标之间的关系,但还有许多因素对空气温度有强烈影响,包括地形、土地使用/覆盖和各种人类活动。尽管收集和准备这些因素的数据较为困难,但仍应予以考虑。由于未考虑上述因素,本研究中的多项式方程的可靠性相对较差。虽然本研究的结果仍具有信息价值和可接受性,但仍需改进,特别是要更多地考虑其他城市因素对空气温度的影响。此外,简单的线性和多项式方程可能无法表达城市环境与空气温度之间的复杂关系。虽然本研究应用了机器学习方法来帮助研究城市环境与空气温度之间的关系,并取得了高R²值和低MAE与RMSE的良好结果,但仍需改进,包括更多地考虑上述城市因素。虽然本研究的结果展示了空气温度与提出的城市规划指标之间的关系,且对城市规划者具有参考价值,但仍需减少上述限制,并为城市规划者提供更有价值的参考。
【 结论】
本研究探讨了使用从卫星影像提取的城市规划指标预测空气温度的可行性。这些指标适用于分析正常气候条件。研究还开发了一种经济且便捷的城市规划指标提取方法,并强调了空气温度与城市发展强度之间的关系。结果表明,空气温度随着FVC的增加而升高,同时随着BCR和FAR的增加而降低。尽管使用机器学习模型得到的结果与现场测量的结果有所不同,但这些结果是合理且可接受的。机器学习模型的模拟结果也显示出与现场测量结果相似的趋势。这些结果表明,城市发展强度的增加与空气温度的升高相关联。这可以帮助城市规划者通过控制和平衡城市化和植被水平来建立热舒适环境。此外,本研究确认了使用机器学习算法和从卫星影像提取的城市规划指标进行空气温度预测的可行性。结果显示,尽管DNN模型在使用训练数据集时表现低于XGB模型,但在不熟悉的情况下,DNN模型比XGB模型更适合预测空气温度。总体而言,DNN模型在正常情况下更适合估算和绘制空气温度分布图。DNN模型创建的空气温度分布图还反映了城市热分布和背景城市规划指标下绿地的降温效果。这些预测和绘图能力可以帮助估算没有测量仪器的区域的热环境条件。
为了更准确地识别高空气温度的成因,未来的研究应考虑额外因素,包括地形、人为热源和大气环境,并评估其他机器学习算法。最后,应调查更多数据,包括不同时间点或季节的气象数据和历史数据。这些数据可能有助于识别不同时间序列中城市规划指标的影响,以及城市化变化如何影响气候。
致谢
作者感谢台湾国家科学技术委员会资助本研究(合同号:111-2221-E-006-053-MY3)。感谢台湾气候变化预测信息与适应知识平台(TCCIP)的额外支持。

相关文章:
【论文分享】采用现场测量、卫星影像和机器学习方法研究空气温度与城市发展强度之间的关系
鉴于城市热问题的严重性,城市化与空气温度之间的关系已成为全球关注的关键问题。本次我们给大家带来一篇SCI论文的全文翻译。该论文提取了常见城市规划指标,这些指标通过卫星影像来确定城市发展的强度。该论文确定的关系可以帮助在城市化和植被平衡的决策…...

Linux -初识 与基础指令1
博客主页:【夜泉_ly】 本文专栏:【Linux】 欢迎点赞👍收藏⭐关注❤️ 文章目录 📚 前言🖥️ 初识🔐 登录 root用户👥 两种用户➕ 添加用户🧑💻 登录 普通用户⚙️ 常见…...

页的初步认识
关于准备 我们在之前的学习中,已经学习了相当一部分有关段的知识,CPU提供了段的机制来给我们的内存进行保护,但实际上我们在x86下的段base是0,实际上并没有偏移 两种分页模式 我们有两种分页模式,29912分页和101012…...

[C++]:IO流
1. IO 流 1.1 流的概念 在C中,存在一种被称为“流”的概念,它描述的是信息流动的过程,具体来说就是信息从外部输入设备(比如常见的键盘)传输到计算机内部(像内存区域),以及信息从内…...
Excel如何批量导入图片
这篇文章将介绍在Excel中如何根据某列数据,批量的导入与之匹配的图片。 准备工作 如图,我们准备了一张员工信息表以及几张员工的照片 可以看到,照片名称是每个人的名字,与Excel表中的B列(姓名)对应 的卢易…...
TCP socket api详解
文章目录 netstat -nltpaccept简单客户端工具 telnet 指定服务连接connect异常处理version 1 单进程版version 2 多进程版version 3 -- 多线程版本version 4 ---- 线程池版本 应用-简单的翻译系统服务器细节write 返回值 客户端守护进程化前台和后台进程的原理Linux的进程间关系…...

《C++搭建神经网络基石:开启智能编程新征程》
在人工智能的璀璨星空中,神经网络无疑是最为耀眼的星座之一。而 C以其卓越的性能和高效的执行效率,成为构建神经网络模型的有力武器。今天,就让我们一同探索如何使用 C构建一个基础的神经网络模型,踏上智能编程的奇妙旅程。 一、…...
 { return true; } return false; 简写为 return 条件 详解)
if (条件) { return true; } return false; 简写为 return 条件 详解
在 Java 中,将以下代码: if (条件) {return true; } return false;简写为: return 条件;原理 在 Java 中,条件 是一个布尔表达式,它直接返回 true 或 false。所以,if-else 结构中的逻辑判断和返回值的逻…...
)
Pytorch使用手册-Datasets DataLoaders(专题三)
数据集与数据加载器(Datasets & DataLoaders) 在 PyTorch 中,torch.utils.data.Dataset 和 torch.utils.data.DataLoader 是数据处理的两种核心工具。它们通过模块化的方式,将数据加载与模型训练分离,提高代码的可读性和可维护性。 1. 加载数据集 以 Fashion-MNIST …...
【数据结构】双向链表、单向循环链表、双向循环链表、栈、链栈
目录 一、双向链表 定义类和封装函数以及测试样例如下: 注意事项: 二、循环链表 单循环列表的类和函数封装如下: 注意事项: 三、双向循环链表 结点类和双循环链表的定义部分 函数封装之判空和尾插 双循环链表遍历 双循…...

(动画)Qt控件 QProgressBar
文章目录 QProgressBar1. 介绍一、基本特性二、核心属性 2. 代码实现3. 动画效果 QProgressBar 1. 介绍 QProgressBar是Qt框架中的一个控件,主要用于显示进度条,以图形化的方式表示任务的完成进度或操作的进度。 一、基本特性 显示方向:…...

【AI】基础原理
文章目录 前言1. AI 是如何学习的?2. AI 怎么做决定?3. AI 的“大脑”是什么样的?4. AI 为什么会犯错?5. AI 的不同类型总结:AI 的本质是什么? 前言 人工智能(AI)这个词对很多人来说…...
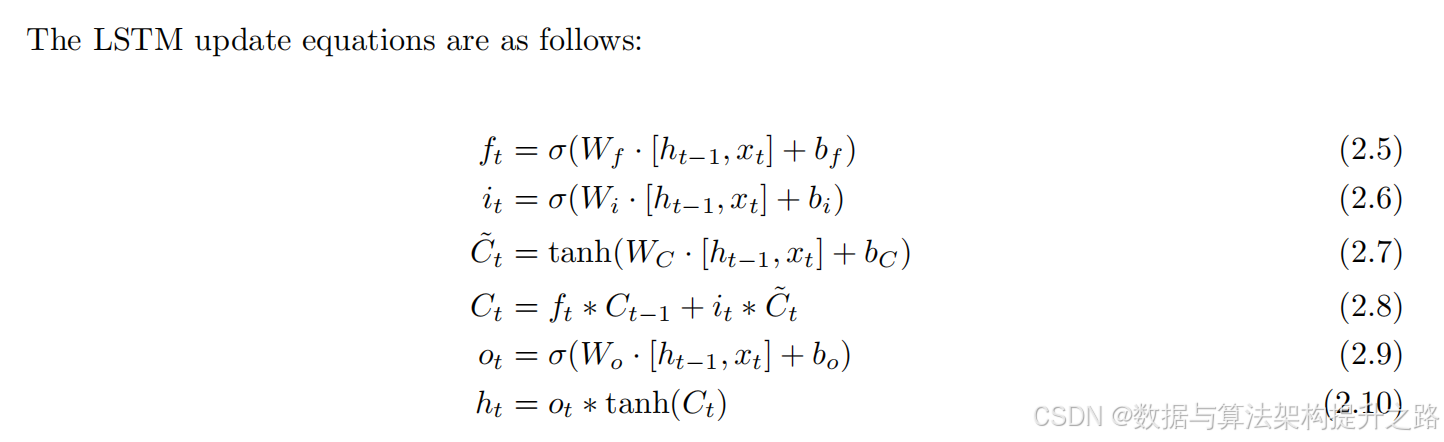
多模态大型语言模型(MLLM)综述
目录 多模态大语言模型的基础 长短期网络结构(LSTM) 自注意力机制 基于Transformer架构的自然语言处理模型 多模态嵌入概述 多模态嵌入关键步骤 多模态嵌入现状 TF-IDF TF-IDF的概念 TF-IDF的计算公式 TF-IDF的主要思路 TF-IDF的案例 训练和微调多模态大语言模…...
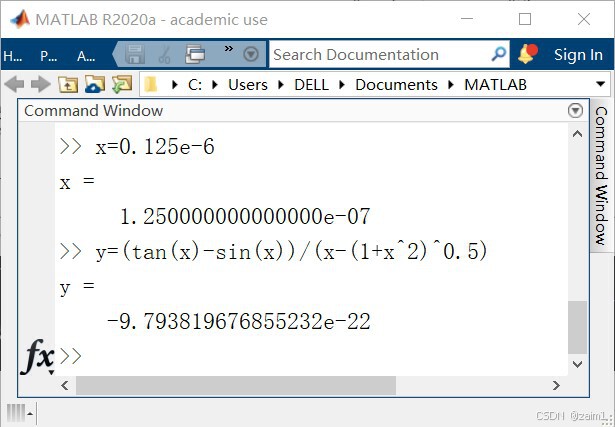
计算机的错误计算(一百六十六)
摘要 探讨 MATLAB 关于算式 的计算误差。 例1. 已知 计算 直接贴图吧: 然而,16位的正确结果为 -0.9765626220703239e-21(ISRealsoft 提供)。这样,MATLAB输出的有效数字的错误率为 (16-2)/16 87.5% . 注&…...

typeof 和 as 关键字
在编程语言中,类型系统是确保代码正确性和可维护性的关键。JavaScript和TypeScript作为现代前端开发的两大支柱,它们在处理类型方面有着不同的机制。本文将探讨typeof和as这两个关键字在JavaScript和TypeScript中的应用,帮助开发者更好地理解…...

Python酷库之旅-第三方库Pandas(237)
目录 一、用法精讲 1116、pandas.tseries.offsets.BusinessHour.is_year_end方法 1116-1、语法 1116-2、参数 1116-3、功能 1116-4、返回值 1116-5、说明 1116-6、用法 1116-6-1、数据准备 1116-6-2、代码示例 1116-6-3、结果输出 1117、pandas.tseries.offsets.Cu…...

git提交到远程仓库如何撤回?
git提交到远程仓库如何撤回? 要撤回已经提交到远程仓库的更改,你可以使用以下步骤: 首先,确保你的本地仓库是最新状态。如果不是,请先执行 git pull 来更新你的本地仓库。 使用 git log 查看提交历史,找到你想要撤回…...

微信小程序常用全局配置项及窗口组成部分详解
微信小程序常用全局配置项及窗口组成部分详解 引言 微信小程序作为一种新兴的应用形态,凭借其轻量级、便捷性和丰富的功能,已成为开发者和用户的热门选择。在开发小程序的过程中,了解全局配置项和窗口组成部分是至关重要的。本文将详细介绍微信小程序的常用全局配置项及窗…...

ThingsBoard规则链节点:Azure IoT Hub 节点详解
目录 引言 1. Azure IoT Hub 节点简介 2. 节点配置 2.1 基本配置示例 3. 使用场景 3.1 数据传输 3.2 数据分析 3.3 设备管理 4. 实际项目中的应用 4.1 项目背景 4.2 项目需求 4.3 实现步骤 5. 总结 引言 ThingsBoard 是一个开源的物联网平台,提供了设备…...

「Mac玩转仓颉内测版32」基础篇12 - Cangjie中的变量操作与类型管理
本篇将深入探讨 Cangjie 编程语言中的变量操作与类型管理,涵盖变量的定义、作用域、类型推断、常量、变量遮蔽、类型转换等方面的知识。通过这些概念的学习,开发者将更好地理解和灵活掌握变量的使用与管理技巧。 关键词 变量定义类型推断常量变量作用域…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...