使用Java代码操作Kafka(五):Kafka消费 offset API,包含指定 Offset 消费以及指定时间消费
文章目录
- 1、指定 Offset 消费
- 2、指定时间消费
1、指定 Offset 消费
auto.offset.reset = earliest | latest | none 默认是 latest
(1)earliest:自动将偏移量重置为最早的偏移量,–from-beginning
(2)latest(默认值):自动将偏移量重置为最新偏移量。
(3)none:如果未找到消费者组的先前偏移量,则向消费者抛出异常
这个参数的力度太大了,不是从头,就是从尾
kafka提供了seek方法,可以让我们从分区的固定位置开始消费
seek(TopicPartition topicPartition,offset offset)
示例代码:
package com.bigdata.kafka.consumer;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
import java.util.Set;public class CustomConsumerSeek {public static void main(String[] args) {Properties properties = new Properties();// 连接kafkaproperties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node01:9092");// 字段反序列化 key 和 valueproperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());// 关闭自动提交offsetproperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());// 配置消费者组(组名任意起名) 必须properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);// 2 订阅一个主题ArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);// 执行计划// 此时的消费计划是空的,因为没有时间生成Set<TopicPartition> assignment = kafkaConsumer.assignment();while(assignment.size() == 0){// 这个本身是拉取数据的代码,此处可以帮助快速构建分区方案出来kafkaConsumer.poll(Duration.ofSeconds(1));// 一直获取它的分区方案,什么时候有了,就什么时候跳出这个循环assignment = kafkaConsumer.assignment();}// 获取所有分区的offset =5 以后的数据/*for (TopicPartition tp:assignment) {kafkaConsumer.seek(tp,5);}*/// 获取分区0的offset =5 以后的数据//kafkaConsumer.seek(new TopicPartition("bigdata",0),5);for (TopicPartition tp:assignment) {if(tp.partition() == 0){kafkaConsumer.seek(tp,5);}}while(true){//1 秒中向kafka拉取一批数据ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String,String> record :records) {// 打印一条数据System.out.println(record);// 可以打印记录中的很多内容,比如 key value offset topic 等信息System.out.println(record.value());}}}
}
2、指定时间消费
示例代码:
package com.bigdata.consumer;import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.*;/*** 从某个特定的时间开始进行消费*/
public class Customer05 {public static void main(String[] args) {// 其实就是mapProperties properties = new Properties();// 连接kafkaproperties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node01:9092");// 字段反序列化 key 和 valueproperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());// 配置消费者组(组名任意起名) 必须properties.put(ConsumerConfig.GROUP_ID_CONFIG, "testf");// 指定分区的分配方案 为轮询策略//properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "org.apache.kafka.clients.consumer.RoundRobinAssignor");// 指定分区的分配策略为:Sticky(粘性)ArrayList<String> startegys = new ArrayList<>();startegys.add("org.apache.kafka.clients.consumer.StickyAssignor");properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, startegys);// 创建一个kafka消费者的对象KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);// 消费者消费的是kafka集群的数据,消费哪个主题的数据呢?List<String> topics = new ArrayList<>();topics.add("five");// list总可以设置多个主题的名称kafkaConsumer.subscribe(topics);// 因为消费者是不停的消费,所以是while true// 指定了获取分区数据的起始位置。// 这样写会报错的,因为前期消费需要指定计划,指定计划需要时间// 此时的消费计划是空的,因为没有时间生成Set<TopicPartition> assignment = kafkaConsumer.assignment();while(assignment.size() == 0){// 这个本身是拉取数据的代码,此处可以帮助快速构建分区方案出来kafkaConsumer.poll(Duration.ofSeconds(1));// 一直获取它的分区方案,什么时候有了,就什么时候跳出这个循环assignment = kafkaConsumer.assignment();}Map<TopicPartition, Long> hashMap = new HashMap<>();for (TopicPartition partition:assignment) {hashMap.put(partition,System.currentTimeMillis()- 60*60*1000);}Map<TopicPartition, OffsetAndTimestamp> map = kafkaConsumer.offsetsForTimes(hashMap);for (TopicPartition partition:assignment) {OffsetAndTimestamp offsetAndTimestamp = map.get(partition);kafkaConsumer.seek(partition,offsetAndTimestamp.offset());}while(true){// 每隔一秒钟,从kafka 集群中拉取一次数据,有可能拉取多条数据ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));// 循环打印每一条数据for (ConsumerRecord record:records) {// 打印数据中的值System.out.println(record.value());System.out.println(record.offset());// 打印一条数据System.out.println(record);}}}
}
相关文章:
:Kafka消费 offset API,包含指定 Offset 消费以及指定时间消费)
使用Java代码操作Kafka(五):Kafka消费 offset API,包含指定 Offset 消费以及指定时间消费
文章目录 1、指定 Offset 消费2、指定时间消费 1、指定 Offset 消费 auto.offset.reset earliest | latest | none 默认是 latest (1)earliest:自动将偏移量重置为最早的偏移量,–from-beginning (2)lates…...

Ubuntu安装不同版本的opencv,并任意切换使用
参考: opencv笔记:ubuntu安装opencv以及多版本共存 | 高深远的博客 https://zhuanlan.zhihu.com/p/604658181 安装不同版本opencv及共存、切换并验证。_pkg-config opencv --modversion-CSDN博客 Ubuntu下多版本OpenCV共存和切换_ubuntu20如同时安装o…...

突破内存限制:Mac Mini M2 服务器化实践指南
本篇文章,我们聊聊如何使用 Mac Mini M2 来实现比上篇文章性价比更高的内存服务器使用,分享背后的一些小的思考。 希望对有类似需求的你有帮助。 写在前面 在上文《ThinkPad Redis:构建亿级数据毫秒级查询的平民方案》中,我们…...

【排版教程】Word、WPS 分节符(奇数页等) 自动变成 分节符(下一页) 解决办法
毕业设计排版时,一般要求每章节的起始页为奇数页,空白页不显示页眉和页脚。具体做法如下: 1 Word 在一个章节的内容完成后,在【布局】中,点击【分隔符】,然后选择【奇数页】 这样在下一章节开始的时&…...

【在Linux世界中追寻伟大的One Piece】多线程(二)
目录 1 -> 分离线程 2 -> Linux线程互斥 2.1 -> 进程线程间的互斥相关背景概念 2.2 -> 互斥量mutex 2.3 -> 互斥量的接口 2.4 -> 互斥量实现原理探究 3 -> 可重入VS线程安全 3.1 -> 概念 3.2 -> 常见的线程不安全的情况 3.3 -> 常见的…...

flink学习(8)——窗口函数
增量聚合函数 ——指窗口每进入一条数据就计算一次 例如:要计算数字之和,进去一个12 计算结果为20, 再进入一个7 ——结果为27 reduce aggregate(aggregateFunction) package com.bigdata.day04;public class _04_agg函数 {public static …...

「实战应用」如何用图表控件LightningChart .NET实现散点图?(一)
LightningChart .NET完全由GPU加速,并且性能经过优化,可用于实时显示海量数据-超过10亿个数据点。 LightningChart包括广泛的2D,高级3D,Polar,Smith,3D饼/甜甜圈,地理地图和GIS图表以及适用于科…...
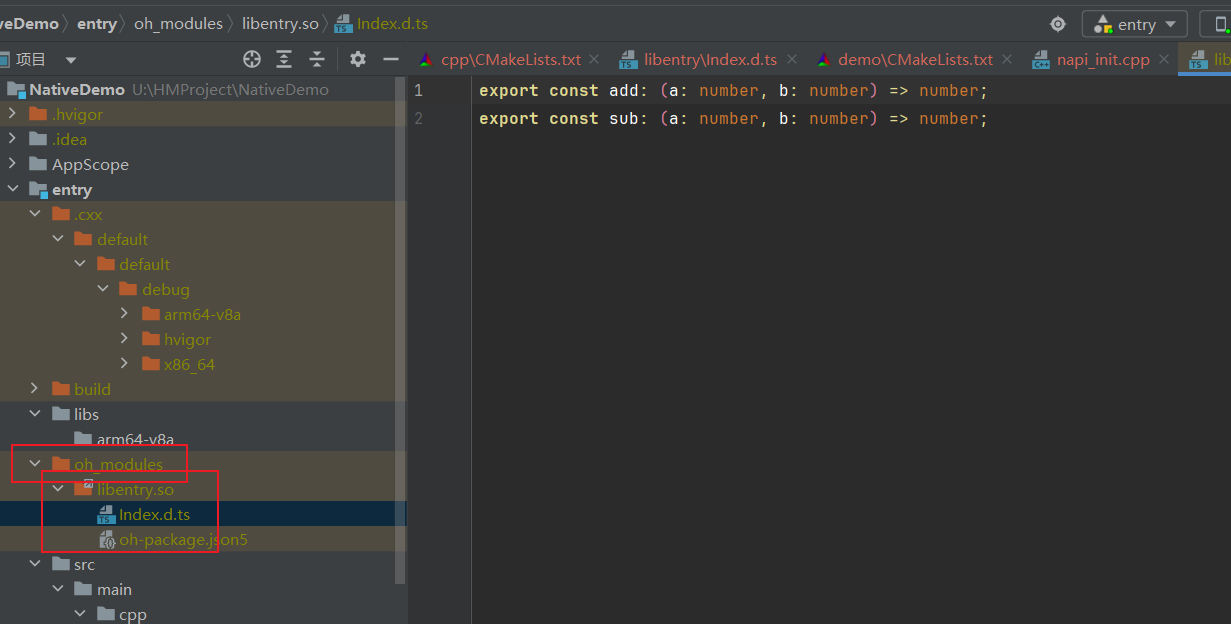
鸿蒙Native使用Demo
DevecoStudio使用Native 今天,给大家带来的是关于DevecoStudio中使用Native进行开发 个人拙见:为什么要使用Native?无论是JS还是TS在复杂的情况下运行速度,肯定不如直接操作内存的C/C的运行速度快,所以,会选择使用Native;这里面的过程是什么?通过映射转化,使用napi提供的接口…...

29.UE5蓝图的网络通讯,多人自定义事件,变量同步
3-9 蓝图的网络通讯、多人自定义事件、变量同步_哔哩哔哩_bilibili 目录 1.网络通讯 1.1玩家Pawn之间的同步 1.2事件同步 1.3UI同步 1.4组播 1.5变量同步 1.网络通讯 1.1玩家Pawn之间的同步 创建一个第三人称项目 将网络模式更改为监听服务器,即将房主作为…...

Scala—列表(可变ListBuffer、不可变List)用法详解
Scala集合概述-链接 大家可以点击上方链接,先对Scala的集合有一个整体的概念🤣🤣🤣 在 Scala 中,列表(List)分为不可变列表(List)和可变列表(ListBuffer&…...

【论文复现】偏标记学习+图像分类
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀ 偏标记学习图像分类 概述算法原理核心逻辑效果演示使用方式参考文献 概述 本文复现论文 Progressive Identification of True Labels for Pa…...

C嘎嘎探索篇:栈与队列的交响:C++中的结构艺术
C嘎嘎探索篇:栈与队列的交响:C中的结构艺术 前言: 小编在之前刚完成了C中栈和队列(stack和queue)的讲解,忘记的小伙伴可以去我上一篇文章看一眼的,今天小编将会带领大家吹奏栈和队列的交响&am…...

AIGC-----AIGC在虚拟现实中的应用前景
AIGC在虚拟现实中的应用前景 引言 随着人工智能生成内容(AIGC)的快速发展,虚拟现实(VR)技术的应用也迎来了新的契机。AIGC与VR的结合为创造沉浸式体验带来了全新的可能性,这种组合不仅极大地降低了VR内容的…...

Django 路由层
1. 路由基础概念 URLconf (URL 配置):Django 的路由系统是基于 urls.py 文件定义的。路径匹配:通过模式匹配 URL,并将请求传递给对应的视图处理函数。命名路由:每个路由可以定义一个名称,用于反向解析。 2. 基本路由配…...
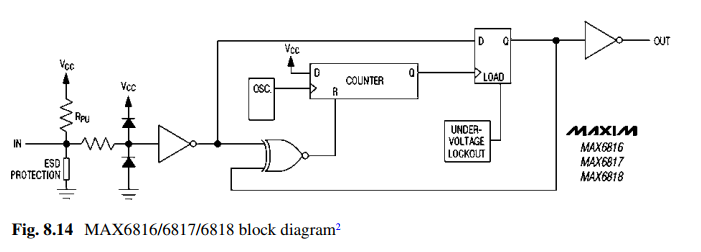
《硬件架构的艺术》笔记(八):消抖技术
简介 在电子设备中两个金属触点随着触点的断开闭合便产生了多个信号,这就是抖动。 消抖是用来确保每一次断开或闭合触点时只有一个信号起作用的硬件设备或软件。(就是每次断开闭合只对应一个操作)。 抖动在某些模拟和逻辑电路中可能产生问…...

Spring 与 Spring MVC 与 Spring Boot三者之间的区别与联系
一.什么是Spring?它解决了什么问题? 1.1什么是Spring? Spring,一般指代的是Spring Framework 它是一个开源的应用程序框架,提供了一个简易的开发方式,通过这种开发方式,将避免那些可能致使代码…...

【算法】连通块问题(C/C++)
目录 连通块问题 解决思路 步骤: 初始化: DFS函数: 复杂度分析 代码实现(C) 题目链接:2060. 奶牛选美 - AcWing题库 解题思路: AC代码: 题目链接:687. 扫雷 -…...

如何选择黑白相机和彩色相机
我们在选择成像解决方案时黑白相机很容易被忽略,因为许多新相机提供鲜艳的颜色,鲜明的对比度和改进的弱光性能。然而,有许多应用,选择黑白相机将是更好的选择,因为他们产生更清晰的图像,更好的分辨率&#…...

Rust 力扣 - 740. 删除并获得点数
文章目录 题目描述题解思路题解代码题目链接 题目描述 题解思路 首先对于这题我们如果将所有点数装入一个切片f中,该切片f中的i号下标表示所有点数为i的点数之和 那么这题就转换成了打家劫舍这道题,也就是求选择了切片中某个下标的元素后,该…...

OpenCV从入门到精通实战(七)——探索图像处理:自定义滤波与OpenCV卷积核
本文主要介绍如何使用Python和OpenCV库通过卷积操作来应用不同的图像滤波效果。主要分为几个步骤:图像的读取与处理、自定义卷积函数的实现、不同卷积核的应用,以及结果的展示。 卷积 在图像处理中,卷积是一种重要的操作,它通过…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...
)
C++课设:简易日历程序(支持传统节假日 + 二十四节气 + 个人纪念日管理)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、为什么要开发一个日历程序?1. 深入理解时间算法2. 练习面向对象设计3. 学习数据结构应用二、核心算法深度解析…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...