【Python】九大经典排序算法:从入门到精通的详解(冒泡排序、选择排序、插入排序、归并排序、快速排序、堆排序、计数排序、基数排序、桶排序)
文章目录
- 1. 冒泡排序(Bubble Sort)
- 2. 选择排序(Selection Sort)
- 3. 插入排序(Insertion Sort)
- 4. 归并排序(Merge Sort)
- 5. 快速排序(Quick Sort)
- 6. 堆排序(Heap Sort)
- 7. 计数排序(Counting Sort)
- 8. 基数排序(Radix Sort)
- 9. 桶排序(Bucket Sort)
- 10. 更多实用文章
- 11. 结语

排序算法对比表格
| 排序算法 | 时间复杂度 | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|---|
| 冒泡排序 | O(n²) | O(1) | 稳定 | 小规模数据或几乎有序的数据 |
| 选择排序 | O(n²) | O(1) | 不稳定 | 数据量小且对稳定性无要求 |
| 插入排序 | O(n²) | O(1) | 稳定 | 小规模数据或几乎有序的数据 |
| 归并排序 | O(n log n) | O(n) | 稳定 | 大规模数据需要稳定性的场景 |
| 快速排序 | O(n log n) | O(log n) | 不稳定 | 大规模数据,平均情况高效 |
| 堆排序 | O(n log n) | O(1) | 不稳定 | 大规模数据,不需要稳定性 |
| 计数排序 | O(n + k) | O(k) | 稳定 | 整数且范围有限的数据 |
| 基数排序 | O(d*(n + k)) | O(n + k) | 稳定 | 大规模整数或可以分位处理的数据 |
| 桶排序 | O(n + k) | O(n) | 稳定 | 均匀分布的大规模数据 |
1. 冒泡排序(Bubble Sort)
工作原理
冒泡排序是一种简单的交换排序算法,通过重复遍历要排序的列表,比较相邻元素并交换顺序错误的元素,直到整个列表有序。每一次遍历都会将未排序部分的最大元素“冒泡”到列表末尾。

实现步骤
- 从列表的起始位置开始,比较相邻的两个元素。
- 如果前一个元素比后一个元素大,则交换它们的位置。
- 对整个列表重复上述过程,每完成一轮遍历,未排序部分的元素数量减少一位。
- 当一轮遍历未发生任何交换时,意味着列表已经有序,可以提前终止算法。
Python 实现
def bubble_sort(arr):n = len(arr)for i in range(n):swapped = Falsefor j in range(0, n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j]swapped = Trueif not swapped:breakreturn arr
优点:
- 实现简单,理解容易。
- 对于少量数据或已经基本有序的数据,效率较高。
缺点:
- 时间复杂度高,为 O(n²)。
- 不适合大规模数据排序。
2. 选择排序(Selection Sort)
工作原理
选择排序是一种简单直观的排序算法。它通过多次从未排序部分选择最小(或最大)的元素,放到已排序部分的末尾,逐步完成排序过程。

实现步骤
- 从未排序部分中找到最小的元素。
- 将该最小元素与未排序部分的第一个元素交换位置。
- 缩小未排序部分的范围,重复上述过程,直到所有元素都有序。
Python 实现
def selection_sort(arr):n = len(arr)for i in range(n):min_idx = ifor j in range(i+1, n):if arr[j] < arr[min_idx]:min_idx = jarr[i], arr[min_idx] = arr[min_idx], arr[i]return arr
优点:
- 实现简单,无需额外的内存空间。
- 适用于数据量较小的情况。
缺点:
- 时间复杂度为 O(n²),效率较低。
- 不稳定排序,可能破坏相同元素的相对顺序。
3. 插入排序(Insertion Sort)
工作原理
插入排序通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。类似于扑克牌的排序方式。

实现步骤
- 从第二个元素开始,假设第一个元素为已排序部分。
- 取未排序部分的第一个元素,将其插入到已排序部分的适当位置。
- 重复上述过程,直到整个列表有序。
Python 实现
def insertion_sort(arr):for i in range(1, len(arr)):key = arr[i]j = i-1while j >=0 and key < arr[j]:arr[j+1] = arr[j]j -= 1arr[j+1] = keyreturn arr
优点:
- 实现简单,效率较高,对于少量数据或基本有序的数据效果不错。
- 稳定排序,保持相同元素的相对位置。
缺点:
- 最坏情况下时间复杂度为 O(n²)。
- 对于大规模数据排序效率低下。
4. 归并排序(Merge Sort)
工作原理
归并排序采用分治法,将数组分成两半,分别进行排序后再合并。其核心在于有效地将两个有序数组合并成一个有序数组。
体验最新GPT系列模型、支持自定义助手、文件上传等功能:ChatMoss & ChatGPT-AI中文版

实现步骤
- 如果数组长度小于等于1,直接返回。
- 将数组分成两半,分别对左右两部分进行归并排序。
- 合并两部分,生成有序的数组。
Python 实现
def merge_sort(arr):if len(arr) <=1:return arrmid = len(arr)//2left = merge_sort(arr[:mid])right = merge_sort(arr[mid:])return merge(left, right)def merge(left, right):merged = []i=j=0while i<len(left) and j<len(right):if left[i] < right[j]:merged.append(left[i])i+=1else:merged.append(right[j])j+=1merged.extend(left[i:])merged.extend(right[j:])return merged
优点:
- 时间复杂度稳定为 O(n log n)。
- 稳定排序,保持相同元素的相对位置。
- 适用于大规模数据。
缺点:
- 需要额外的内存空间,空间复杂度为 O(n)。
5. 快速排序(Quick Sort)
工作原理
快速排序同样采用分治策略,通过选择一个“基准”元素,将数组分成两部分,一部分小于基准元素,另一部分大于基准元素,然后递归排序两部分。

实现步骤
- 选择数组中的一个元素作为基准(通常选择第一个元素)。
- 重新排列数组,将小于基准的元素放到左边,大于基准的元素放到右边。
- 递归对左右两部分进行快速排序。
Python 实现
def quick_sort(arr):if len(arr) <=1:return arrpivot = arr[len(arr)//2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)
优点:
- 平均时间复杂度为 O(n log n),表现优异。
- 不需要额外的内存空间(原地排序实现时)。
- 通常比其他 O(n log n) 算法更快,尤其在实践中表现良好。
缺点:
- 最坏情况下时间复杂度为 O(n²),如已排序数据。
- 不稳定排序,可能破坏相同元素的相对位置。
6. 堆排序(Heap Sort)
工作原理
堆排序利用堆这种数据结构,首先将数组构建成一个最大堆(或最小堆),然后依次将堆顶元素(最大或最小)移到数组末尾,调整堆,重复此过程直到整个数组有序。

实现步骤
- 将数组构建成一个最大堆。
- 将堆顶元素与数组末尾元素交换,缩小堆的范围。
- 对堆顶进行堆调整,保持堆性质。
- 重复步骤2和3,直到堆的范围为1。
Python 实现
def heapify(arr, n, i):largest = il = 2*i +1r = 2*i +2if l < n and arr[l] > arr[largest]:largest = lif r < n and arr[r] > arr[largest]:largest = rif largest !=i:arr[i], arr[largest] = arr[largest], arr[i]heapify(arr, n, largest)def heap_sort(arr):n = len(arr)for i in range(n//2 -1, -1, -1):heapify(arr, n, i)for i in range(n-1, 0, -1):arr[i], arr[0] = arr[0], arr[i]heapify(arr, i, 0)return arr
优点:
- 时间复杂度为 O(n log n)。
- 不需要额外的内存空间(原地排序)。
- 对于大规模数据表现稳定。
缺点:
- 通常比快速排序慢,常数因子较大。
- 不稳定排序,可能破坏相同元素的相对位置。
7. 计数排序(Counting Sort)
工作原理
计数排序是一种稳定的线性时间排序算法,适用于元素范围较小的整数排序。它通过统计每个元素出现的次数,计算元素的位置,最后构建有序数组。
体验最新GPT系列模型、支持自定义助手、文件上传等功能:ChatMoss & ChatGPT-AI中文版

实现步骤
- 找到待排序数组的最大值和最小值。
- 创建一个计数数组,统计每个元素的出现次数。
- 计算计数数组的前缀和,确定每个元素在有序数组中的位置。
- 构建有序数组,确保稳定性。
Python 实现
def counting_sort(arr):if not arr:return arrmax_val = max(arr)min_val = min(arr)range_of_elements = max_val - min_val +1count = [0]*range_of_elementsfor num in arr:count[num - min_val] +=1for i in range(1, len(count)):count[i] += count[i-1]output = [0]*len(arr)for num in reversed(arr):output[count[num - min_val] -1] = numcount[num - min_val] -=1return output
优点:
- 时间复杂度为 O(n + k),其中 k 是元素的范围。
- 稳定排序,保持相同元素的相对顺序。
缺点:
- 只能用于整数排序,且元素范围较小。
- 需要额外的内存空间,尤其当元素范围较大时。
8. 基数排序(Radix Sort)
工作原理
基数排序是一种非比较型排序算法,通过将元素按位(如个位、十位等)进行多次排序,实现整体有序。常结合计数排序作为子过程。

实现步骤
- 确定元素的最大位数。
- 从最低位开始,对所有元素进行稳定排序(如使用计数排序)。
- 重复上述过程,直到所有位数排序完成。
Python 实现
def counting_sort_for_radix(arr, exp):n = len(arr)output = [0]*ncount = [0]*10for num in arr:index = num//expcount[index %10] +=1for i in range(1,10):count[i] += count[i-1]for num in reversed(arr):index = num//expoutput[count[index %10] -1] = numcount[index %10] -=1return outputdef radix_sort(arr):if not arr:return arrmax_val = max(arr)exp =1while max_val//exp >0:arr = counting_sort_for_radix(arr, exp)exp *=10return arr
优点:
- 时间复杂度为 O(d*(n + k)),d 是位数,k 是基数。
- 稳定排序,保持相同元素的相对顺序。
- 适用于大规模数据和大位数整数排序。
缺点:
- 只能用于整数排序,或可以拆分为位进行排序的对象。
- 需要额外的内存空间,尤其是基数较大时。
9. 桶排序(Bucket Sort)
工作原理
桶排序将元素分到多个桶中,每个桶内部再采用其他排序算法排序,最后将所有桶中的元素按顺序合并。适用于元素均匀分布的情况。

实现步骤
- 确定桶的数量和范围。
- 将每个元素分配到对应的桶中。
- 对每个桶内部进行排序(如使用插入排序)。
- 按顺序合并所有桶中的元素,得到有序数组。
Python 实现
def bucket_sort(arr):if not arr:return arrbucket_count = 10min_val = min(arr)max_val = max(arr)range_val = (max_val - min_val)/bucket_countbuckets = [[] for _ in range(bucket_count)]for num in arr:index = int((num - min_val)/range_val)if index == bucket_count:index -=1buckets[index].append(num)for bucket in buckets:insertion_sort(bucket)sorted_arr = []for bucket in buckets:sorted_arr.extend(bucket)return sorted_arr
10. 更多实用文章
【IDER、PyCharm】免费AI编程工具完整教程:ChatGPT Free - Support Key call AI GPT-o1 Claude3.5
【VScode】VSCode中的智能编程利器,全面揭秘ChatMoss & ChatGPT中文版
【OpenAI】获取OpenAI API Key的多种方式全攻略:从入门到精通,再到详解教程!!
11. 结语
通过这篇详尽的排序算法教程,希望能帮助你在编程学习和实际项目中游刃有余地应用各种排序技术,提升整体编程技能与算法素养。
相关文章:
【Python】九大经典排序算法:从入门到精通的详解(冒泡排序、选择排序、插入排序、归并排序、快速排序、堆排序、计数排序、基数排序、桶排序)
文章目录 1. 冒泡排序(Bubble Sort)2. 选择排序(Selection Sort)3. 插入排序(Insertion Sort)4. 归并排序(Merge Sort)5. 快速排序(Quick Sort)6. 堆排序&…...

【346】Postgres内核 Startup Process 通过 signal 与 postmaster 交互实现 (5)
1. Startup Process 进程 postmaster 初始化过程中, 在进入 ServerLoop() 函数之前,会先通过调用 StartChildProcess() 函数来开启辅助进程,这些进程的目的主要用来完成数据库的 XLOG 相关处理。 如: 核实 pg_wal 和 pg_wal/archive_status 文件是否存在Postgres先前是否发…...
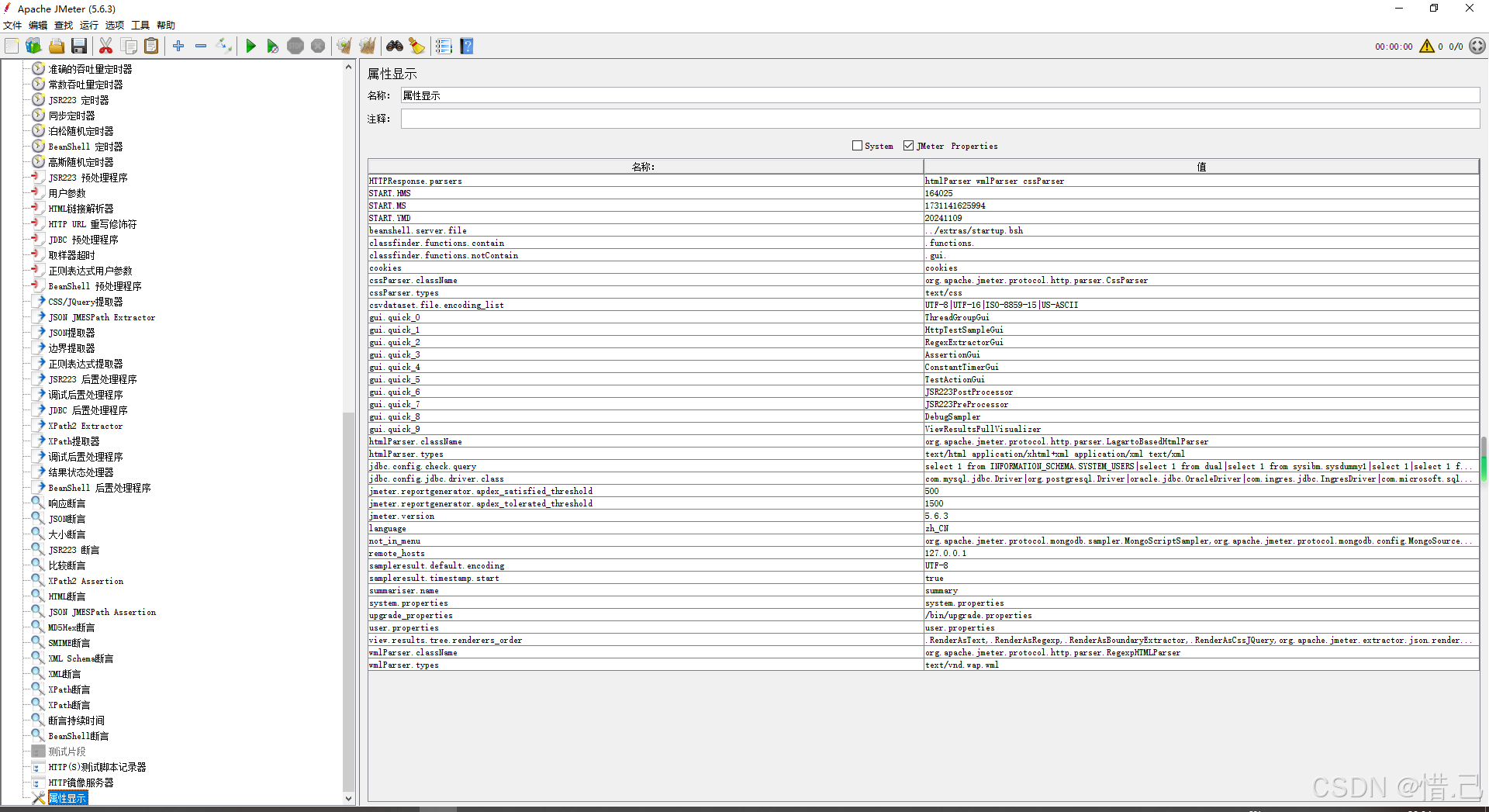
Jmeter中的测试片段和非测试原件
1)测试片段 1--测试片段 功能特点 重用性:将常用的测试元素组合成一个测试片段,便于在多个线程组中重用。模块化:提高测试计划的模块化程度,使测试计划更易于管理和维护。灵活性:可以通过模块控制器灵活地…...
利用 Jsoup 进行高效 Web 抓取与 HTML 处理
Jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 JQuery 的操作方法来取出和操作数据。 官网:https://jsoup.org/ 中文文档:Jsou…...

【Java】二叉树:数据海洋中灯塔式结构探秘(上)
个人主页 🌹:喜欢做梦 二叉树中有一个树,我们可以猜到他和树有关,那我们先了解一下什么是树,在来了解一下二叉树 一🍝、树型结构 1🍨.什么是树型结构? 树是一种非线性的数据结构&…...

微信小程序 WXS 的概念与基本用法教程
微信小程序 WXS 的概念与基本用法教程 引言 在微信小程序的开发中,WXS(WeiXin Script)是一种特殊的脚本语言,旨在解决小程序在逻辑处理和数据处理上的一些限制。WXS 允许开发者在小程序的 WXML 中嵌入 JavaScript 代码,以便实现更复杂的逻辑处理。本文将深入探讨 WXS 的…...

Vue.js 中 v-bind 和 v-model 的用法与异同
简介 在 Vue.js 中,v-bind 和 v-model 是两个非常常用且强大的指令,它们分别用于动态地绑定属性和实现双向数据绑定。理解这两个指令的用法和区别对于构建 Vue.js 应用至关重要。本文将详细介绍 v-bind 和 v-model 的用法,并探讨它们的异同。…...

K8s的水平自动扩容和缩容HPA
HPA全称是Horizontal Pod Autoscaler,翻译成中文是POD水平自动伸缩,HPA可以基于CPU利用率对replication controller、deployment和replicaset中的pod数量进行自动扩缩容(除了CPU利用率也可以基于其他应程序提供的度量指标custom metrics进行自…...

【AI日记】24.11.26 聚焦 kaggle 比赛
【AI论文解读】【AI知识点】【AI小项目】【AI战略思考】【AI日记】 核心工作 1 内容:研究 kaggle 比赛时间:3 小时 核心工作 2 内容:学习 kaggle 比赛 Titanic - Machine Learning from Disaster时间:4 小时备注:这…...
大型语言模型LLM - Finetuning vs Prompting
资料来自台湾大学李宏毅教授机器学课程ML 2023 Spring,如有侵权请通知下架 台大机器学课程ML 2023 Springhttps://speech.ee.ntu.edu.tw/~hylee/ml/2023-spring.php2023/3/10 课程 機器如何生成文句 内容概要 主要探讨了大型语言模型的两种不同期待及其导致的两类…...

【IEEE独立出版 | 厦门大学主办】第四届人工智能、机器人和通信国际会议(ICAIRC 2024,12月27-29日)
第四届人工智能、机器人和通信国际会议(ICAIRC 2024) 2024 4th International Conference on Artificial Intelligence, Robotics, and Communication 重要信息 会议官网:www.icairc.net 三轮截稿时间:2024年11月30日23:59 录…...

【GPT】力量训练是什么,必要吗,有可以替代的方式吗
什么是力量训练? 力量训练是一种通过抵抗力(如重量、阻力带、自身体重等)来刺激肌肉收缩,从而提高肌肉力量、耐力和体积的运动形式。它包括以下常见形式: 自由重量训练:使用哑铃、杠铃、壶铃等。固定器械…...
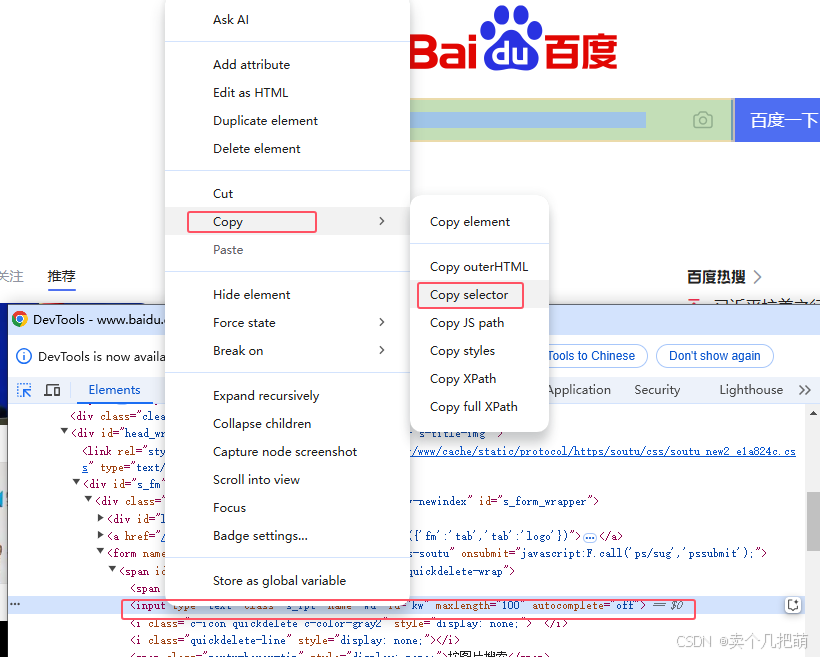
【03】Selenium+Python 八种定位元素方法
操作元素,需要先查找定位到对应的元素。 查找单个元素:driver.find_element() 返回是一个web element 对象 查找多个元素:driver.find_elements() 返回是一个list对象 By 是 Selenium 中一个非常重要的类,用于定位网页元素。 使…...

笔记:jQuery追加js时会自动加“_时间戳“参数,导致百度统计失败
问题描述: $(document.createElement("script")).attr(id, baidutj).attr(src, https://hm.baidu.com/hm.js?xxx).appendTo(body); 会自动给src加_时间戳的参数? 问题解疑: 【未完待续…】 问题解决: 老老实实按它…...

【PyTorch】(基础二)---- 张量
张量 在 PyTorch 中,张量(Tensor)是核心数据结构,类似于 NumPy 中的数组,但具有更强的计算能力和对 GPU 的支持。 创建 从列表或数组创建 import torch# 从列表创建 tensor_from_list torch.tensor([1, 2, 3, 4])…...

充满智慧的埃塞俄比亚狼
非洲的青山 随着地球温度上升,贝尔山顶峰的冰川消失殆尽,许多野生动物移居到海拔3000米以上的高原上生活,其中就包括埃塞俄比亚狼。埃塞俄比亚狼是埃塞俄比亚特有的动物,总数不到500只,为“濒危”物种。 埃塞俄比亚狼…...
基于STM32设计的智能桌面暖风机(华为云IOT)
一、前言 1.1 项目开发背景 随着智能家居技术的迅猛发展,传统家用电器正逐步向智能化方向转型。暖风机作为冬季广泛使用的取暖设备,其智能化升级不仅能够提高用户的使用体验,还能通过物联网技术实现远程控制和数据监控,赋予其更…...

零基础学安全--云技术基础
目录 学习连接 前言 云技术历史 云服务 公有云服务商 云分类 基础设施即服务(IaaS) 平台即服务(PaaS) 软件即服务(SaaS) 云架构 虚拟化 容器 云架构设计 组件选择 基础设施即代码 集成部署…...

Spring Boot中配置Flink的资源管理
在 Spring Boot 中配置 Flink 的资源管理,需要遵循以下步骤: 添加 Flink 依赖项 在你的 pom.xml 文件中,添加 Flink 和 Flink-connector-kafka 的依赖项。这里以 Flink 1.14 版本为例: <!-- Flink dependencies --><de…...
51单片机从入门到精通:理论与实践指南入门篇(二)
续51单片机从入门到精通:理论与实践指南(一)https://blog.csdn.net/speaking_me/article/details/144067372 第一篇总体给大家在(全局)总体上讲解了一下51单片机,那么接下来几天结束详细讲解,从…...

别再只会用ALTER USER了!PostgreSQL密码管理的5种隐藏技巧
PostgreSQL密码管理的5个高阶技巧:安全工程师不会告诉你的秘密 如果你还在用ALTER USER命令直接修改PostgreSQL密码,那么你可能错过了数据库安全防护中最关键的几个环节。作为一款企业级开源数据库,PostgreSQL提供了远比基础密码修改更强大的…...

跨平台开发地图:金三银四你准备好了吗? | 2026年3月
哈喽,我是老刘 转眼间,金三银四的招聘旺季已经到来。在这个焦虑大于机遇的月份,跨平台技术圈仍然按部就班向前推进。 但说实话,在金三银四的压力下,平台怎么卷是次要的,你自己的竞争力够不够大࿰…...

电力负荷预测数据集盘点:从单站到多区域的实战资源指南
1. 电力负荷预测数据集的重要性与选型原则 电力负荷预测是能源管理系统的核心环节,无论是电网调度、电力市场交易还是新能源消纳,都离不开精准的负荷预测。我在实际项目中发现,选对数据集往往比算法调参更重要——就像做饭时食材新鲜度决定菜…...

保姆级教程:LongCat-Image-Edit本地部署,小白也能玩转AI宠物编辑
保姆级教程:LongCat-Image-Edit本地部署,小白也能玩转AI宠物编辑 你是不是也有一堆自家“毛孩子”的萌照,总想着要是能给它换个造型、换个场景该多有趣?以前这需要专业的修图软件和技巧,现在,你只需要一句…...

智慧能碳管理系统核心功能大起底:实时监测、优化如何驱动降本增效?
智慧能碳管理系统:企业双碳时代的破局利器在 “双碳” 目标的大背景下,企业降本增效的需求愈发迫切。然而,传统能碳管理方式依赖人工统计与分散式监控,弊端愈发明显。数据的滞后使得决策出现偏差,核算的误差影响了减排…...

换个角度看魏忠贤:被权力异化的制度标本
换个角度看魏忠贤:被权力异化的制度标本说起魏忠贤,你的脑子里是不是立刻蹦出这几个词:奸臣、宦官误国、阉党祸国?教科书和电视剧早就把这个人钉在了历史的耻辱柱上。但今天咱们不唱这出老戏,换几个角度重新打量这位&q…...

通过adb修改pq_default.ini优化S905X3电视盒硬解画质,告别油画效果
1. 为什么S905X3电视盒硬解画质像油画? 最近一年我一直在用S905X3芯片的电视盒,性能确实比之前的RK3328强不少,但有个问题让我特别头疼——硬解视频时画面总像蒙了一层油,细节全被磨平,人脸像打了十层美颜,…...
)
光纤VS铜缆:实测对比千兆网络下20KM传输延迟差异(附测试方法)
光纤VS铜缆:千兆网络20KM传输延迟实测与选型指南 当企业面临网络基础设施升级时,传输介质的选择往往成为技术决策的难点。尤其在跨楼宇、园区或远距离数据传输场景中,光纤与铜缆的性能差异直接影响到业务系统的响应速度和稳定性。本文将通过实…...

从心理学到机械臂:拆解苹果论文里让机器人更讨喜的3个情感化设计秘诀
从心理学到机械臂:拆解苹果论文里让机器人更讨喜的3个情感化设计秘诀 当台灯不再是冰冷的照明工具,而是会随着音乐律动跳舞、用"犹豫"动作表达故障状态、甚至通过推水杯的动作传递关怀——这正是苹果研究团队在《ELEGNT》论文中描绘的未来人机…...

汇川ITS7100E触摸屏与PLC联调技巧:手把手教你本地调试的5个关键步骤
汇川ITS7100E触摸屏与PLC高效联调实战指南 在工业自动化项目中,触摸屏与PLC的协同调试往往是系统联调的关键环节。作为汇川旗下广受欢迎的HMI产品,ITS7100E凭借其稳定的性能和友好的开发环境,成为许多工程师的首选。但在实际调试过程中&#…...