CLIP-Adapter: Better Vision-Language Models with Feature Adapters 论文解读
abstract
大规模对比视觉-语言预训练在视觉表示学习方面取得了显著进展。与传统的通过固定一组离散标签训练的视觉系统不同,(Radford et al., 2021) 引入了一种新范式,该范式在开放词汇环境中直接学习将图像与原始文本对齐。在下游任务中,通常需要精心设计的文本提示来进行零样本预测。为避免复杂的提示工程,(Zhou et al., 2021) 提出了上下文优化方法,利用少量样本学习连续向量作为任务特定的提示。在本文中,我们展示了除了提示调优之外,还有一条实现更优视觉-语言模型的替代路径。提示调优是针对文本输入的,而我们提出的 CLIP-Adapter 则通过在视觉或语言分支上应用特征适配器来进行微调。具体而言,CLIP-Adapter 采用了额外的瓶颈层来学习新特征,并通过残差式特征融合与原始预训练特征相结合。因此,CLIP-Adapter 能够在保持简单设计的同时超越上下文优化。我们在各种视觉分类任务上进行了实验和广泛的消融研究,证明了我们方法的有效性。
introduction
视觉理解任务(如分类任务【Krizhevsky et al., 2012; He et al., 2016; Howard et al., 2017; Dosovitskiy et al., 2021; Touvron et al., 2021; Gao et al., 2021a; Mao et al., 2021】、目标检测【Ren et al., 2015; Carion et al., 2020; Gao et al., 2021b】和语义分割【Long et al., 2015】)已经因更优的架构设计和大规模高质量数据集而显著改善。然而,为每个视觉任务收集高质量大规模数据集非常耗费人力和成本,难以扩展。为了解决这个问题,视觉领域普遍采用了“预训练-微调”的范式,即先在如 ImageNet【Krizhevsky et al., 2012】这样的超大规模数据集上预训练模型,再在各种下游任务上进行微调。然而,这种方法在许多下游任务上仍需大量标注数据来进行微调。
最近,对比语言-图像预训练(Contrastive Language-Image Pretraining,CLIP)【Radford et al., 2021】被提出,它通过利用大规模噪声图文对的对比学习来解决视觉任务。CLIP 无需任何标注即可在各种视觉分类任务中取得令人振奋的性能(即零样本迁移),其方法是将视觉类别嵌入到合适的手工设计模板中作为提示。
尽管基于提示的零样本迁移学习显示出了良好的性能,但设计优质的提示依然是一个需要大量时间和领域知识的工程问题。为了解决这一问题,上下文优化(Context Optimization, CoOp)【Zhou et al., 2021】进一步提出通过少量样本学习连续的软提示,以替代精心设计的硬提示。CoOp 在零样本 CLIP 和线性探针 CLIP 的设置下,实现了显著的少样本分类性能提升,展现了提示调优在大规模预训练视觉-语言模型上的潜力。
本文提出了一种不同的方法,通过特征适配器而非提示调优来更好地适应视觉-语言模型。与 CoOp 使用软提示优化不同,我们只在轻量化的额外特征适配器上进行微调。由于 CLIP 过参数化以及缺乏足够的训练样本,直接对整个 CLIP 模型进行微调会导致特定数据集的过拟合,并且训练过程因涉及所有 CLIP 层的正向与反向传播而非常缓慢。受到参数高效迁移学习中适配器模块【Houlsby et al., 2019】的启发,我们提出了 CLIP-Adapter,它只需微调少量额外权重,而不是优化 CLIP 的所有参数。
CLIP-Adapter 采用轻量化的瓶颈架构,通过减少参数数量来防止少样本学习中的潜在过拟合问题。同时,CLIP-Adapter 在以下两个重要方面不同于 Houlsby 等人的方法:
- CLIP-Adapter 仅在视觉或语言主干网络的最后一层后添加两个额外的线性层,而原始适配器模块则插入语言主干网络的所有层中;
- CLIP-Adapter 通过残差连接将原始的零样本视觉或语言嵌入与相应的微调特征进行混合。通过这种“残差式融合”,CLIP-Adapter 能够同时利用存储在原始 CLIP 中的知识以及从少样本训练样本中学到的新知识。
我们的贡献可以总结如下:
- 提出 CLIP-Adapter,通过残差式特征融合实现高效的少样本迁移学习。
- 与 CoOp 相比,CLIP-Adapter 在保持设计简单的同时,实现了更优的少样本分类性能,证明了其作为提示调优的有力替代方案。
- 在 11 个分类数据集上对 CLIP-Adapter 进行了广泛的消融研究,以分析其特性。代码将在以下网址公开:
https://github.com/gaopengcuhk/CLIP-Adapter。
- 过参数化(Over - parameterization)
- 定义:过参数化是指模型的参数数量远远超过了训练数据所包含的信息量。在CLIP这个案例中,它有大量的参数。例如,CLIP模型的架构可能包含许多层的神经网络,每层都有众多的神经元,这些神经元对应的权重等参数数量巨大。
- 后果:过多的参数使得模型具有很强的表达能力,它可以拟合非常复杂的函数。但这也带来了问题,模型可能会过度关注训练数据中的噪声或者一些不重要的细节。就好像一个记忆力超强的学生,他不仅记住了知识的重点,还把一些无关紧要的细节(如书本上印刷的小瑕疵等类似噪声)也记住了。
- 微调缺乏足够的训练样本
- 定义:这意味着用于训练CLIP模型的数据量相对其庞大的参数数量来说是不够的。如果把模型比作一个饥饿的人,那么训练样本就是食物,食物量太少,无法满足这个“人”的需求。
2 相关工作
2.1 模型微调
深度神经网络对数据有很高的需求。然而,收集和标注大量高质量数据的成本非常高,对于某些特殊领域甚至是不可能的。“预训练-微调”范式为不同的计算机视觉【Krizhevsky et al., 2012; Simonyan and Zisserman, 2015; He et al., 2016】和自然语言处理【Kenton and Toutanova, 2019; Dong et al., 2019; Conneau et al., 2020】任务提供了一个良好的解决方案,并且已经被广泛应用多年。
为了在下游任务中实现数据高效的微调,适配器模块(adapter modules)【Houlsby et al., 2019】被提出,其通过冻结主干网络的权重并在每个 Transformer 层中插入可学习的线性层实现数据高效的迁移学习。不同于传统适配器模块,本文提出的 CLIP-Adapter 通过对 CLIP 生成的特征嵌入或分类器权重应用简单的残差变换层来实现功能优化。依靠残差连接和瓶颈线性层,CLIP-Adapter 在少样本学习环境下可以显著提高 CLIP 的性能,并且优于最近提出的 CoOp 方法。
为了缓解分布转移(distribution shifting)下的性能差距,WiSE-FT【Wortsman et al., 2021】提出了一种后置集成(post-ensemble)方法来提升 CLIP 的分布外鲁棒性。虽然 WiSE-FT 在微调过程中冻结了图像分支的权重,CLIP-Adapter 则可以同时应用于图像和文本分支,并通过一个可学习的门控比率动态平衡和混合来自原始特征和 CLIP-Adapter 输出的知识。
- 分布转移(Distribution Shifting)
- 定义:在机器学习和数据处理的背景下,分布转移是指训练数据和测试数据(或者在模型实际应用中的数据)的概率分布发生了变化。例如,假设我们训练一个图像分类模型来识别不同种类的动物,训练数据中的动物图像是在自然环境下拍摄的,颜色、角度等特征具有一定的分布规律。但在实际应用中,模型遇到的可能是经过艺术加工(如漫画风格)的动物图像,此时数据的分布就发生了转移。
- 影响:这种分布的变化会导致模型性能下降,因为模型是基于训练数据的分布来学习特征和模式的,当新数据的分布不同时,模型可能无法准确地进行判断。
- 可学习的门控比率动态平衡和混合来自原始特征和CLIP - Adapter输出的知识
- 原始特征和CLIP - Adapter输出的知识:CLIP模型本身会输出原始的特征表示,这些特征包含了模型对输入数据(如视觉 - 语言数据)的初步理解。CLIP - Adapter是一种改进的模块,它也会输出经过处理后的特征。这两种特征都有各自的价值。
- 门控比率(Gating Ratio):这是一个可学习的参数,就像是一个可以调节的阀门。它可以控制来自原始特征和CLIP - Adapter输出特征的比例。
- 动态平衡和混合:在模型的运行过程中,这个门控比率不是固定不变的,而是可以根据数据的情况和模型的学习过程动态调整。例如,在某些数据样本上,可能原始CLIP特征更有用,门控比率就会调整为让更多的原始特征通过;而在另一些情况下,CLIP - Adapter输出的特征可能更具优势,门控比率就会倾向于它,从而实现对两种知识的动态平衡和混合,以得到更好的特征表示用于后续的任务,如分类等。
- 分布外鲁棒性(Out - of - Distribution Robustness)
- 定义:鲁棒性(Robustness)是指系统(在这里是机器学习模型)在面对异常情况或者不确定性时仍能保持良好性能的能力。分布外鲁棒性则是指模型在面对与训练数据分布不同(即分布外)的数据时的鲁棒性。
- 重要性:在实际应用中,我们很难保证模型遇到的数据都和训练数据的分布完全一致。具有良好的分布外鲁棒性的模型,在遇到新的、未曾在训练中出现过的情况(如数据分布转移)时,依然能够给出相对合理的结果。例如,一个具有高分布外鲁棒性的图像分类模型,即使面对风格迥异的图像,也能尽可能准确地进行分类,而不是完全失效。
2.2 提示设计
提示设计(Prompt Design)【Liu et al., 2021a】因 GPT 系列模型的成功而受到广泛关注【Radford et al., 2019; Brown et al., 2020】。GPT-3 展示了一种全新的能力:通过在大规模数据集上训练的大型自回归语言模型,可以在无需微调基础架构的情况下,以零样本或少样本的方式执行各种 NLP 任务。随着这一全新的“预训练-提示-预测”(pre-train, prompt, and predict)范式的提出,最近涌现了多种提示设计方法。其中一种方法聚焦于提示工程,通过挖掘或生成适当的离散提示【Jiang et al., 2020; Shin et al., 2020; Gao et al., 2021c】。
相比之下,连续提示(continuous prompts)绕过了预训练语言模型的限制,并被应用于 NLP 任务【Li and Liang, 2021; Liu et al., 2021b; Lester et al., 2021; Gu et al., 2021】。受 GPT-3 的启发,CLIP 在 4 亿对图像-文本配对数据上训练了一个大规模的对比学习模型,并展现了基于提示的零样本视觉分类的潜力。在以 CLIP 作为骨干网络的基础上,CoOp【Zhou et al., 2021】和 CPT【Yao et al., 2021】进一步表明,优化连续提示在视觉任务中的表现可以远远优于手动设计的离散提示。
本文展示,提示调优并非实现更优视觉-语言模型的唯一路径。通过微调少量参数,同样可以以更简单的设计实现与提示调优相当甚至更好的视觉任务性能。
- 离散提示(Discrete Prompts)
- 定义:离散提示是一种在自然语言处理(NLP)等任务中使用的提示方式,它是由离散的、明>确的符号(如单词、短语等)组成的提示。这些提示通常是通过挖掘或者人工生成的。
- 举例:在文本分类任务中,如果要判断一段文本是关于体育还是科技,离散提示可能是像“体育相关词汇”(如“比赛”“运动员”)和“科技相关词汇”(如“芯片”“软件”)这样的单词或短语集合。研究人员通过挖掘大量文本找到这些与不同类别相关的词汇,作为提示来引导模型进行分类。就像是给模型一个明确的清单,让它去文本中寻找这些清单上的内容来做出判断。
- 应用场景和限制:离散提示在一些任务中很有效,特别是当我们能够明确地找到与任务相关的特定词汇或短语时。然而,它的局限性在于受到预训练语言模型词汇表和语言结构的限制。例如,模型可能只能处理它预训练时见过的词汇作为提示,而且很难灵活地组合这些离散提示来适应复杂多变的任务场景。
- 连续提示(Continuous Prompts)
- 定义:连续提示是一种相对更灵活的提示方式,它不是由离散的符号组成,而是通过一些连续的向量表示来绕过预训练语言模型的限制。可以将其看作是在一个连续的向量空间中进行操作的提示。
- 举例:假设我们把语言模型的输入空间看作是一个多维的向量空间,连续提示就是这个空间中的一些向量。这些向量可以通过一定的数学运算(如线性组合等)来动态地调整和生成适合不同任务的提示。例如,在情感分析任务中,连续提示可能是一个经过调整的向量,这个向量能够引导模型对文本中的情感倾向进行判断,而且这个向量可以根据不同的文本风格、主题等因素进行动态变化。
- 应用场景和优势:连续提示的优势在于它能够更灵活地适应各种任务。因为它是在连续的空间中操作,所以可以通过学习和调整来生成更适合特定任务的提示,而不像离散提示那样受到词汇和固定结构的限制。它能够更好地利用模型的参数和表示能力,从而在一些视觉任务(如以CLIP为骨干网络的视觉分类任务)等中表现出优于离散提示的性能。
2.3 视觉-语言模型
探索视觉和语言之间的交互是人工智能的核心研究课题之一。过去,基于注意力的方法主导了视觉-语言任务,例如自下而上的和自上而下的注意力【Anderson et al., 2018】、BAN【Kim et al., 2018】、Intra-Inter【Gao et al., 2019】以及 MCAN【Yu et al., 2019】。受 BERT【Kenton and Toutanova, 2019】成功的启发,ViLBERT【Lu et al., 2019】、LXMERT【Tan and Bansal, 2019】、UNITER【Chen et al., 2020】和 Oscar【Li et al., 2020】进一步推动了多模态推理的研究。
最近,CLIP【Radford et al., 2021】和 ALIGN【Jia et al., 2021】展现了视觉-语言对比表征学习的强大能力。它们无需微调便在一系列视觉任务中取得了惊人的结果。为进一步缩小 CLIP 和监督训练之间的差距,CoOp 提出了连续提示优化方法,用以改善视觉分类任务的性能。
与 CoOp 从提示设计角度改进视觉-语言模型不同,本文提出的 CLIP-Adapter 通过轻量化特征适配器的简单微调方法探索了另一种改进途径。
3 我们的方法
本节中,我们介绍所提出的 CLIP-Adapter。在 3.1 节,我们从分类器权重生成的角度回顾了 CLIP 和 CoOp。在 3.2 节,我们详细阐述了 CLIP-Adapter 的设计。在 3.3 节,我们提供了 CLIP-Adapter 的几种变体。

3.1 少样本学习的分类器权重生成
首先回顾深度神经网络用于图像分类的基本框架:给定一张图像 I ∈ R H × W × 3 I \in \mathbb{R}^{H \times W \times 3} I∈RH×W×3,其中 H H H 和 W W W 分别表示图像的高度和宽度,一个由基本组件(例如 CNN、Transformer[Vaswani et al., 2017]或两者的混合)级联组成的神经网络主干模型会将 I I I 转换为一个特征表示 f ∈ R D f \in \mathbb{R}^D f∈RD,其中 D D D 是特征的维度。为了执行分类,图像特征向量 f f f 与分类器权重矩阵 W ∈ R D × K W \in \mathbb{R}^{D \times K} W∈RD×K 相乘,其中 K K K 表示类别的数量。矩阵乘法后,可以得到一个 K K K-维的 logit(未归一化概率)。Softmax 函数将 logit 转换为 K K K 个类别上的概率向量 p ∈ R K p \in \mathbb{R}^K p∈RK。整个过程可表示为以下公式:
f = Backbone ( I ) , p i = exp ( W i T f ) / τ ∑ j = 1 K exp ( W j T f ) / τ ( 1 ) f = \text{Backbone}(I), \quad p_i = \frac{\exp(W_i^T f)/\tau}{\sum_{j=1}^{K} \exp(W_j^T f)/\tau}(1) f=Backbone(I),pi=∑j=1Kexp(WjTf)/τexp(WiTf)/τ(1)
其中, τ \tau τ 表示 Softmax 的温度超参数, W i W_i Wi 表示类别 i i i 的原型权重向量, p i p_i pi 表示类别 i i i 的概率。
与监督训练不同,本文关注的是在少样本场景下的图像分类。通过少量样本从头训练主干网络和分类器容易导致特定数据集的过拟合,并可能在测试集上表现大幅下降。通常,少样本学习的典型范式是先在大规模数据集上预训练主干网络,然后通过以下方式将学习到的知识迁移到下游任务中:直接进行零样本预测或进一步在少样本样本上进行微调。
CLIP 遵循零样本迁移风格:它首先通过在大规模的噪声图文对数据上进行对比学习来预训练视觉主干和文本编码器,随后直接进行图像分类,而无需任何微调。对于一个包含 K K K 个类别及其自然语言名称 { C 1 , C 2 , … , C K } \{C_1, C_2, \dots, C_K\} {C1,C2,…,CK} 的下游图像分类数据集,CLIP 将每个类别名称 C i C_i Ci 放入预定义的硬提示模板 H H H 中。然后,语言特征提取器将生成的提示编码为分类器权重 W i W_i Wi。我们将分类器权重生成过程表示为:
W i = BERT ( Tokenizer ( [ H ; C i ] ) ) ( 2 ) W_i = \text{BERT}(\text{Tokenizer}([H; C_i])) (2) Wi=BERT(Tokenizer([H;Ci]))(2)
另一方面,CoOp 创建了一组随机初始化的可学习软标记 S ∈ R L × D S \in \mathbb{R}^{L \times D} S∈RL×D,其中 L L L 是软标记序列的长度。软标记序列 S S S 与每个类别名称 C i C_i Ci 拼接,从而形成提示。整个过程表示为:
W i = BERT ( [ S ; Tokenizer ( C i ) ] ) ( 3 ) W_i = \text{BERT}([S; \text{Tokenizer}(C_i)]) (3) Wi=BERT([S;Tokenizer(Ci)])(3)
对于 CLIP 和 CoOp,生成的分类器权重 W i ( i = 1 , … , K ) W_i \ (i = 1, \dots, K) Wi (i=1,…,K) 可以通过前述公式(公式 1)计算类别 i i i 的预测概率 p i p_i pi。
3.2 CLIP-Adapter
与 CoOp 的提示调优不同,本文提出了一种替代框架,通过微调额外的特征适配器实现更优的视觉-语言模型少样本图像分类性能。我们认为,传统广泛采用的“预训练-微调”范式在少样本环境下难以成功微调整个 CLIP 主干网络,原因是其参数量庞大且缺乏足够的训练样本。因此,我们提出了 CLIP-Adapter,它仅在 CLIP 的语言和图像分支中添加少量可学习的瓶颈线性层,同时在少样本微调中保持原始 CLIP 主干网络冻结。
然而,仅通过额外的层进行简单的微调可能仍然会导致对少样本数据的过拟合。为了解决过拟合问题并提高 CLIP-Adapter 的鲁棒性,我们进一步采用残差连接,将微调得到的知识与原始 CLIP 主干中的知识动态融合。
具体来说,给定输入图像 I I I 和类别的自然语言名称集合 { C i } i = 1 K \{C_i\}_{i=1}^K {Ci}i=1K,通过公式 (1) 和 (2) 可从原始 CLIP 主干网络中计算得到图像特征 f f f 和分类器权重 W W W。随后,引入两个可学习的特征适配器 A v ( ⋅ ) A_v(\cdot) Av(⋅) 和 A t ( ⋅ ) A_t(\cdot) At(⋅),分别包含两层线性变换,用于转换 f f f 和 W W W。为了避免遗忘预训练 CLIP 中编码的原始知识,特征适配器采用了残差连接。我们引入两个常数 α \alpha α 和 β \beta β 作为“残差比率”,用于调整保留原始知识的程度以优化性能。特征适配器的公式如下:
A v ( f ) = ReLU ( f T W 1 v ) W 2 v ( 4 ) A_v(f) = \text{ReLU}(f^T W_1^v) W_2^v (4) Av(f)=ReLU(fTW1v)W2v(4)
A t ( W ) = ReLU ( W T W 1 t ) W 2 t ( 5 ) A_t(W) = \text{ReLU}(W^T W_1^t) W_2^t (5) At(W)=ReLU(WTW1t)W2t(5)
通过残差连接将微调捕获的新知识与原始特征相加:
f ∗ = α A v ( f ) T + ( 1 − α ) f ( 6 ) f^* = \alpha A_v(f)^T + (1 - \alpha) f (6) f∗=αAv(f)T+(1−α)f(6)
W ∗ = β A t ( W ) T + ( 1 − β ) W ( 7 ) W^* = \beta A_t(W)^T + (1 - \beta) W (7) W∗=βAt(W)T+(1−β)W(7)
在获得新的图像特征 f ∗ f^* f∗ 和分类器权重 W ∗ W^* W∗ 后,我们仍通过公式 (1) 计算类别概率向量 P = { p i } i = 1 K P = \{p_i\}_{i=1}^K P={pi}i=1K,并预测图像类别为概率最高的类 i ∗ = arg max i p i i^* = \arg\max_i p_i i∗=argmaxipi。
在少样本训练中,特征适配器 A v ( ⋅ ) A_v(\cdot) Av(⋅) 和 A t ( ⋅ ) A_t(\cdot) At(⋅) 的权重通过交叉熵损失进行优化:
L = − ∑ i = 1 K y i log ( y ^ i ) L = -\sum_{i=1}^{K} y_i \log(\hat{y}_i) L=−i=1∑Kyilog(y^i)
其中, N N N 为训练样本总数;当类别 i i i 等于真实类别标签 i ∗ i^* i∗ 时, y i = 1 y_i = 1 yi=1,否则 y i = 0 y_i = 0 yi=0; y ^ i = p i \hat{y}_i = p_i y^i=pi 是类别 i i i 的预测概率; θ = { W 1 v , W 2 v , W 1 t , W 2 t } \theta = \{W_1^v, W_2^v, W_1^t, W_2^t\} θ={W1v,W2v,W1t,W2t} 表示所有可学习的参数。
3.3 CLIP-Adapter 的变体
CLIP-Adapter 有三种结构变体:
- 仅微调图像分支的特征适配器,而保持文本分支冻结;
- 仅微调文本分支的特征适配器,而保持图像分支冻结;
- 同时微调 CLIP 主干的图像和文本分支。
对于超参数 α \alpha α 和 β \beta β,我们观察到不同的数据集具有不同的最优取值。手动选择这些超参数既耗时又繁琐。因此,我们还探索了以可微分方式学习 α \alpha α 和 β \beta β,即将它们设置为可学习的参数。通过这种方式, α \alpha α 和 β \beta β 可以通过超网络 Q Q Q 动态地从视觉特征 f f f 或分类器权重 W W W 中预测:
α , β = Q ( f , W ) \alpha, \beta = Q(f, W) α,β=Q(f,W)
4 实验
4.1 少样本学习
4.1.1 训练设置
根据 CLIP【Radford et al., 2021】和 CoOp【Zhou et al., 2021】的实验设置,我们选择了 11 个图像分类数据集来验证 CLIP-Adapter 的有效性:
- ImageNet【Deng et al., 2009】
- StanfordCars【Krause et al., 2013】
- UCF101【Soomro et al., 2012】
- Caltech101【Fei-Fei et al., 2004】
- Flowers102【Nilsback and Zisserman, 2008】
- SUN397【Xiao et al., 2010】
- DTD【Cimpoi et al., 2014】
- EuroSAT【Helber et al., 2019】
- FGVCAircraft【Maji et al., 2013】
- OxfordPets【Parkhi et al., 2012】
- Food101【Bossard et al., 2014】
具体而言,我们在少样本场景下(1、2、4、8 和 16 个样本)训练 CLIP-Adapter,并在完整的测试集上测试微调后的模型性能。所有实验均在一台 Nvidia A100 GPU 上完成。
如果未作特别说明,我们默认采用 CLIP-Adapter 的第一种变体,即仅微调图像特征而冻结分类器权重。换句话说,CLIP-Adapter 仅在视觉适配器上实现。激活文本适配器的其他变体的结果在 4.1.5 节 中呈现。
我们与 CoOp 使用相同的训练超参数,包括每批 32 个样本的批大小以及 1×10⁻⁵ 的学习率,但对残差比率 α \alpha α 进行了超参数搜索,并在每个数据集上报告搜索空间内的最佳性能。视觉主干网络(视觉编码器)采用 ResNet-50【He et al., 2016】,分类器权重生成器(文本编码器)采用 BERT【Kenton and Toutanova, 2019】。视觉和文本瓶颈层的隐藏嵌入维度均设置为 256,为原始嵌入维度的四分之一。
与 CoOp 中可学习的连续提示不同,CLIP-Adapter 使用简单的手工设计硬提示作为文本输入,与 CLIP 相同。对于通用类别的图像数据集(例如 ImageNet),我们采用硬提示模板 “a photo of a {CLASS}”;对于细粒度分类数据集,我们为模板指定相应的领域关键词以获得更好的性能,例如 EuroSAT 的模板为 “a centered satellite photo of {CLASS}”,其他细粒度数据集的模板以此类推。
4.1.2 基线模型
我们将 CLIP-Adapter 与以下三个基线模型进行比较:
- Zero-shot CLIP【Radford et al., 2021】
- Linear probe CLIP【Radford et al., 2021】
- CoOp【Zhou et al., 2021】
在实现中,CLIP-Adapter 与 Zero-shot CLIP 共享相同的手工硬提示以保证公平比较。CoOp 使用可学习的连续向量替代离散标记,因此可以在提示模板的多个位置放置类别标记(例如前、中、后)。我们选择 CoOp 的最佳性能变体,即将类别标记放在 16 标记软提示的末尾,并在不同类别之间共享上下文。
Linear probe CLIP 在其视觉编码器上训练了一个额外的线性分类器,并以少样本训练方式运行。与 CLIP-Adapter 的瓶颈适配器不同,后者以动态和残差方式微调图像特征和分类器权重。
4.1.3 性能比较与分析

主要结果如图 2 所示。从左上角显示的 11 个数据集的平均准确率来看,CLIP-Adapter 在所有不同的少样本训练设置下都明显优于其他三个基线模型,证明了其卓越的少样本学习能力。特别是在 1-shot 或 2-shot 等极端条件下,CLIP-Adapter 相较于基线模型实现了更大的性能提升,表明其在数据匮乏的训练场景中具有更好的泛化能力。

与 Zero-shot CLIP【Radford et al., 2021】相比,CLIP-Adapter 在所有 11 个数据集上都取得了显著的性能提升。在 16-shot 训练设置下,各数据集的绝对性能提升如图 3 所示。对于前五个细粒度数据集(从 EuroSAT 到 FGVCAircraft),CLIP-Adapter 的性能提升范围为 20% 到 50%。在更具挑战性和通用性的 Caltech101 和 ImageNet 等数据集上,性能提升相对较小。而对于 OxfordPets 和 Food101,CLIP-Adapter 的提升有限,因为 Zero-shot CLIP 的原始结果已经非常优秀。
与 Linear probe CLIP【Radford et al., 2021】相比,CLIP-Adapter 展示了全面的性能优势。在 1-shot 和 2-shot 训练设置下,Linear probe CLIP 的性能几乎达不到 Zero-shot CLIP 的水平,但 CLIP-Adapter 总是能够超越 Zero-shot CLIP 并大幅超过 Linear probe CLIP。例如,在 OxfordPets 数据集上,1-shot 和 2-shot 的绝对性能提升分别为 53.6% 和 42.16%;在 ImageNet 数据集上,分别为 37.17% 和 27.58%。
与 CoOp【Zhou et al., 2021】相比,尽管 CoOp 已经相较于 Zero-shot CLIP 实现了显著提升,CLIP-Adapter 在所有数据集和不同的少样本设置中仍表现优越。值得注意的是,CLIP-Adapter 从完全不同的角度(即微调)处理少样本学习,而非 CoOp 的提示调优。这表明,使用带有残差连接的轻量化适配器微调预训练的视觉-语言模型,可以实现比提示工程【Liu et al., 2021a】更好的性能。
4.1.4 对最优残差比率的观察
有趣的是,我们发现最佳残差比率 α \alpha α 在某种程度上反映了“预训练-微调”范式下不同数据集的特性。预训练数据集与微调数据集之间的语义差距越大,CLIP-Adapter 就需要从新适配的特征中学习更多的知识,而不是依赖于原始 CLIP 的输出,从而导致更大的最佳残差比率;反之亦然。
对于专用领域的细粒度数据集(例如 EuroSAT 的卫星图像和 DTD 的纹理图像),最佳残差比率通常在 0.6 到 0.8 的范围内。而对于综合性和通用性的图像数据集(例如 Caltech-101 和 ImageNet),最佳值通常约为 0.2。
4.1.5 含文本适配器的变体
在这里,我们研究了 3.3 节 中提到的 CLIP-Adapter 的另外两种变体:
- 微调文本适配器,同时冻结视觉适配器;
- 同时微调文本和视觉适配器。
与其为每个数据集手动选择残差比率,我们利用可学习参数 α \alpha α 和 β \beta β,因为这种方法更高效,并且可以获得令人满意的性能。我们在四个数据集上对比了它们的性能,这些数据集分为两类:细粒度数据集(EuroSAT 和 DTD)以及通用数据集(Caltech101 和 ImageNet)。如图 4 所示,文本适配器和视觉适配器都能显著提升分类准确率,相较于 Zero-shot CLIP 表现出色。
此外,仅采用视觉适配器优于仅采用文本适配器。这表明,对于少样本图像分类,调整图像特征比调整文本特征更重要,因为预训练数据集与微调数据集之间的视觉特征语义差距通常大于文本特征的语义差距。令人意外的是,同时使用两个适配器的性能并未超过仅使用视觉适配器的性能。这表明,文本适配器和视觉适配器可能会捕获冗余信息,甚至彼此冲突。
4.2 特征流形的可视化
我们使用 t-SNE【Van der Maaten and Hinton, 2008】对以下模型在 EuroSAT 数据集上训练后的特征流形进行了可视化:CLIP、CoOp、不带残差连接的 CLIP-Adapter,以及带残差连接的 CLIP-Adapter。t-SNE 的可视化结果如图 5 所示,其中数字 0 到 9 分别表示以下类别:
- AnnualCrop(年作物)
- Forest(森林)
- Herbaceous Vegetation Land(草本植被地)
- Highway or Road(公路或道路)
- Industrial Buildings(工业建筑)
- Pasture Land(牧场)
- Permanent Crop Land(多年作物地)
- Residential Buildings(住宅建筑)
- River(河流)
- Sea or Lake(海洋或湖泊)
在高维分类空间中,子图 (d) 中带残差连接的 CLIP-Adapter 展现了更为明显的类别特征分离效果。对于一些容易混淆的类别,例如公路或道路(红色点)、多年作物地(粉色点)和牧场(棕色点),与其他方法相比,CLIP-Adapter 在检测同类图像流形的相似性方面表现更为出色。
总之,实验结果证明,在少样本训练场景下,CLIP-Adapter 在学习更优特征流形方面具有良好的效果。
4.3 消融研究
在本节中,我们对 CLIP-Adapter 进行了一系列消融研究。我们选择性能最优的变体(仅激活视觉适配器),并选取两个数据集 —— DTD 和 ImageNet —— 作为细粒度和通用数据集的代表来进行实验。
4.3.1 瓶颈层维度
我们首先通过改变瓶颈层的隐藏维度进行消融实验。结果如表 1 所示,其中 (D) 表示原始图像特征的维度。当将隐藏维度从 (D) 减少到 (D/32) 时,我们观察到过小或过大的中间维度都会显著降低模型性能。最佳瓶颈维度为 (D/4),它能够在保留足够语义信息的同时避免冗余。
4.3.2 残差比率
此外,我们对残差比率 α \alpha α 进行了消融研究。从表 2 可以看出,细粒度数据集 DTD 的最佳残差比率为 0.6,而通用数据集 ImageNet 的最佳残差比率为 0.2。这验证了我们在 4.1.4 节 中的观察,即适配细粒度数据集需要从新知识中学习更多内容,而通用数据集则相反,更依赖于原始知识。
需要注意的是,当 α = 0 \alpha = 0 α=0 时,相当于 Zero-shot CLIP,因为没有学习任何新知识。当 α = 1.0 \alpha = 1.0 α=1.0 时,分类完全依赖于适配特征(CLIP-Adapter w/o Res)。然而,这并不是最佳选择,因为 CLIP-Adapter 在这种情况下容易出现过拟合。
结合表 2 和图 5,我们可以得出残差连接在 CLIP-Adapter 中的优势:
- 避免少样本训练中的过拟合,并通过利用零样本知识提高 CLIP-Adapter 的泛化能力;
- 在少样本微调中保留学习更优图像特征或分类器权重的自由度。
5 结论与未来工作
我们提出了 CLIP-Adapter 作为一种少样本图像分类中提示调优方法的替代方案。CLIP-Adapter 通过仅微调少量额外的瓶颈层,重新激活了“预训练-微调”范式。为了进一步提升泛化能力,我们引入了以残差比率为参数的残差连接,动态融合了零样本知识与新适配特征。
根据实验结果,CLIP-Adapter 在不同的少样本设置下,在 11 个图像分类数据集上均优于竞争性基线模型。广泛的消融研究验证了我们方法的设计,并证明了 CLIP-Adapter 在学习更优特征流形方面的能力。
未来,我们计划将 CLIP-Adapter 扩展到更多的视觉-语言应用中。此外,我们还将尝试将 CLIP-Adapter 与软提示(soft prompts)结合,以进一步释放 CLIP 主干网络的潜力。
相关文章:
CLIP-Adapter: Better Vision-Language Models with Feature Adapters 论文解读
abstract 大规模对比视觉-语言预训练在视觉表示学习方面取得了显著进展。与传统的通过固定一组离散标签训练的视觉系统不同,(Radford et al., 2021) 引入了一种新范式,该范式在开放词汇环境中直接学习将图像与原始文本对齐。在下游任务中,通…...

Spring Boot 开发环境搭建详解
下面安装spring boot的详细步骤,涵盖了从安装 JDK 和 Maven 到创建和运行一个 Spring Boot 项目的全过程。 文章目录 1. 安装 JDK步骤 1.1:下载 JDK步骤 1.2:安装 JDK步骤 1.3:配置环境变量 2. 安装 Maven步骤 2.1:下载…...

网络安全中的数据科学如何重新定义安全实践?
组织每天处理大量数据,这些数据由各个团队和部门管理。这使得全面了解潜在威胁变得非常困难,常常导致疏忽。以前,公司依靠 FUD 方法(恐惧、不确定性和怀疑)来识别潜在攻击。然而,将数据科学集成到网络安全中…...

安装数据库客户端工具
如果没有勾选下面的,可以运行下面的两个命令 红框为自带数据库 新建数据库 右键运行mysql文件,找到数据库,并刷新...

GoogleTest做单元测试
目录 环境准备GoogleTest 环境准备 git clone https://github.com/google/googletest.git说cmkae版本过低了,解决方法 进到googletest中 cmake CMakeLists.txt make sudo make installls /usr/local/lib存在以下文件说明安装成功 中间出了个问题就是,…...

深入解析 EasyExcel 组件原理与应用
✨深入解析 EasyExcel 组件原理与应用✨ 官方:EasyExcel官方文档 - 基于Java的Excel处理工具 | Easy Excel 官网 在日常的 Java 开发工作中,处理 Excel 文件的导入导出是极为常见的需求。 今天,咱们就一起来深入了解一款非常实用的操作 Exce…...

JSON数据转化为Excel及数据处理分析
在现代数据处理中,JSON(JavaScript Object Notation)因其轻量级和易于人阅读的特点而被广泛使用。然而,有时我们需要将这些JSON数据转化为Excel格式以便于进一步的分析和处理。本文将介绍如何将JSON数据转化为Excel文件࿰…...

(计算机网络)期末
计算机网络概述 物理层 信源就是发送方 信宿就是接收方 串行通信--一次只发一个单位的数据(串行输入) 并行通信--一次可以传输多个单位的数据 光纤--利用光的反射进行传输 传输之前,要对信源进行一个编码,收到信息之后要进行一个…...

【AI技术赋能有限元分析应用实践】将FEniCS 软件安装在Ubuntu22.04
FEniCS 完整介绍 FEniCS 是一个开源的计算工具包,专门用于解决偏微分方程(PDE)的建模和求解。它以灵活的数学抽象和高效的计算性能著称,可以让用户使用高层次的数学表达来定义问题,而无需关注底层的数值实现细节。 具体来看,FEniCS 是一个开源的高性能计算工具包,用于…...
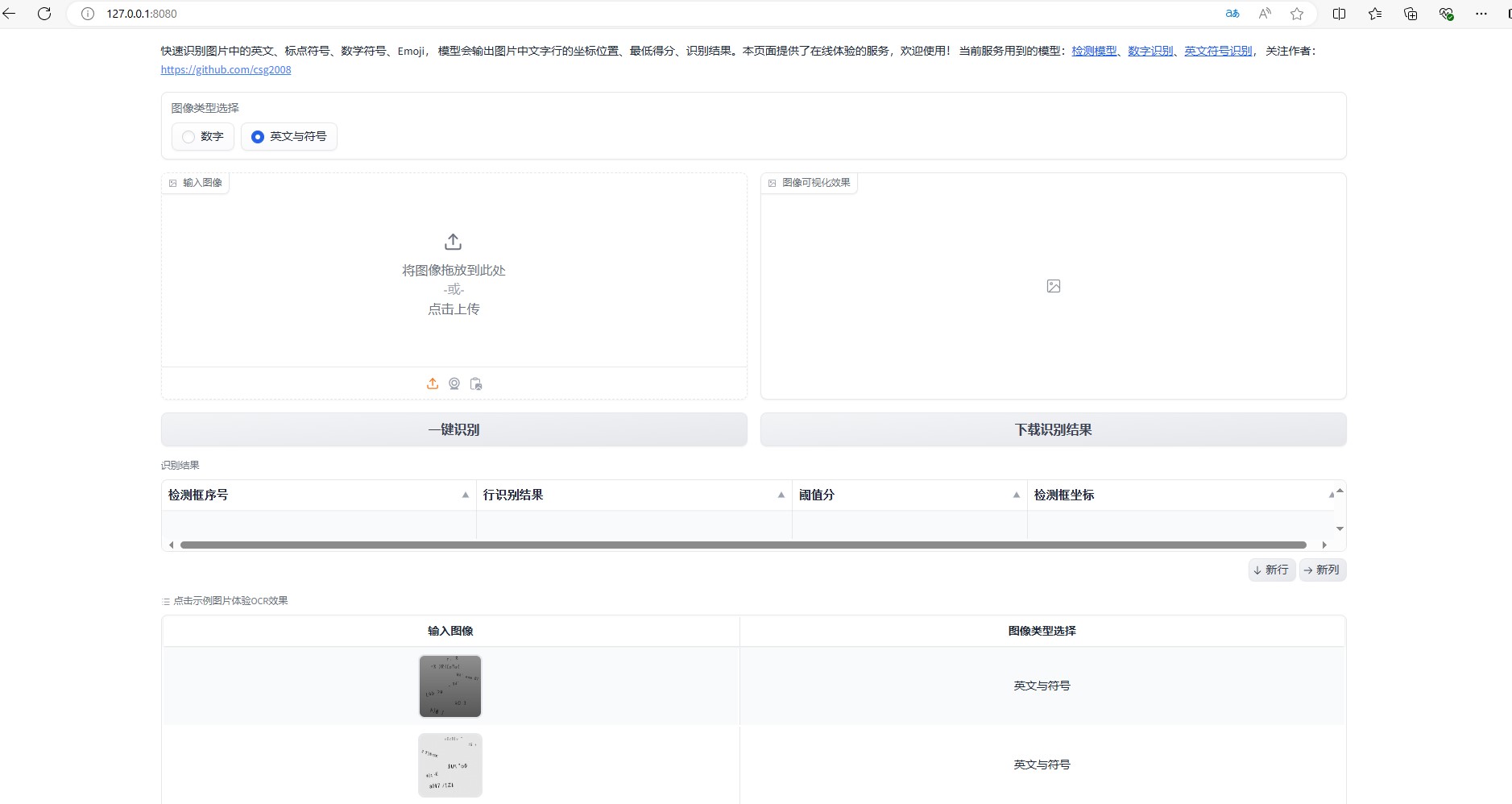
快速识别模型:simple_ocr,部署教程
快速识别图片中的英文、标点符号、数学符号、Emoji, 模型会输出图片中文字行的坐标位置、最低得分、识别结果。当前服务用到的模型:检测模型、数字识别、英文符号识别。 一、部署流程 1.更新基础环境 apt update2.安装miniconda wget https://repo.anaconda.com/…...

【C/C++】数据库链接入门教程:从零开始的详细指南!MySQL集成与操作
文章目录 环境配置:搭建开发环境的基础步骤2.1 安装MySQL数据库2.2 配置C/C开发环境2.3 下载并安装MySQL Connector/C 基础操作:实现C/C与MySQL的基本交互3.1 建立数据库连接3.2 执行SQL语句3.3 处理查询结果 进阶技巧:提升数据库操作效率与安…...

C#中面试的常见问题005
1、重载和重写 重载(Overloading) 重载是指在同一个类中定义多个同名方法,但参数列表不同(参数的数量、类型或顺序不同)。返回类型可以相同也可以不同。重载方法允许你根据传入的参数类型和数量来调用不同的方法。 …...

使用Redis生成全局唯一id
为了生成一个符合要求的分布式全局ID,我们可以使用 StringRedisTemplate 来实现。这个ID由三部分组成: 符号位(1 bit):始终为0,表示正数。时间戳(31 bit):表示从某个起始…...
pnpm:包管理的新星,平替 npm 和 yarn
pnpm,一个老牌的 node.js 包管理器,支持 npm 的所有功能,完全足以用来替代 npm。它采用全局存储,每个项目内部使用了硬链接,所以很省空间,安装速度快。 本文介绍下 pnpm 的基本概念,安装、…...

Android调起系统分享图片到其他应用
Android调起系统分享图片到其他应用 有时候分享不想接第三方的,其实如果你的分享要求不是很高,调系统的分享也是可以的。 一、思路: 用intent.action Intent.ACTION_SEND 二、效果图: 三、关键代码: //这个是分享…...

详解Qt QBuffer
文章目录 **QBuffer 的详解****前言****QBuffer 是什么?****QBuffer 的主要用途****构造函数****主要成员函数详解****1. open()****原型:****作用:****参数:****返回值:****示例代码:** **2. write()****原…...

Python基础学习-11函数参数
1、"值传递” 和“引用传递” 1)不可变的参数通过“值传递”。比如整数、字符串等 2)可变的参数通过“引用参数”。比如列表、字典。 3)避免可变参数的修改 4)内存模型简介 2、函数参数类型 1) def func() #无参…...

GTK#框架让C# Winform程序跨平台运行
在软件开发领域,跨平台能力是一个重要的考量因素。对于C#开发者来说,Winform是构建桌面应用的强大工具,但原生Winform只支持Windows平台。幸运的是,GTK#框架的出现让C# Winform程序跨平台运行成为可能。本文将详细介绍如何使用GTK…...
)
在Kubernetes使用CronJob实现定时删除指定天数外的文件(我这里使用删除备份mysql数据库文件为例)
文章目录 一、代码使用方式1、golang代码2、使用方法二、容器镜像使用方式1、制作镜像2、我公开的镜像3、使用方法一、代码使用方式 1、golang代码 vim cleanfile.go package mainimport ("flag""fmt""io/ioutil""os""path/fi…...

使用 Elastic 收集 Windows 遥测数据:ETW Filebeat 输入简介
作者:来自 Elastic Chema Martinez 在安全领域,能够使用 Windows 主机的系统遥测数据为监控、故障排除和保护 IT 环境开辟了新的可能性。意识到这一点,Elastic 推出了专注于 Windows 事件跟踪 (ETW) 的新功能 - 这是一种强大的 Windows 原生机…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...