【人工智能】深入解析GPT、BERT与Transformer模型|从原理到应用的完整教程
在当今人工智能迅猛发展的时代,自然语言处理(NLP)领域涌现出许多强大的模型,其中GPT、BERT与Transformer无疑是最受关注的三大巨头。这些模型不仅在学术界引起了广泛讨论,也在工业界得到了广泛应用。那么,GPT、BERT与Transformer模型究竟有何不同?它们的工作原理是什么?如何在实际项目中高效应用这些模型?本文将为你详尽解答,并通过实用教程助你快速上手。
文章目录
- 更多实用工具
- Transformer模型详解
- Transformer的起源与发展
- Transformer的核心架构
- Transformer的优势与局限
- BERT模型深度解析
- BERT的基本概念
- BERT的预训练与微调
- BERT在实际中的应用
- GPT模型全面剖析
- GPT的发展历程
- GPT的架构与工作原理
- GPT的实际应用场景
- GPT与BERT的比较分析
- 架构上的区别
- 应用场景的差异
- 性能与效果的对比
- 实战教程:如何应用Transformer、BERT与GPT
- 环境搭建与工具选择
- Transformer模型的实现与优化
- BERT模型的微调与应用
- GPT模型的生成与应用
- 发展趋势
- 结论
更多实用工具
【OpenAI】获取OpenAI API Key的多种方式全攻略:从入门到精通,再到详解教程!!
【VScode】VSCode中的智能编程利器,全面揭秘ChatMoss & ChatGPT中文版
体验最新的GPT系列模型!支持Open API调用、自定义助手、文件上传等强大功能,助您提升工作效率!点击链接体验:CodeMoss & ChatGPT-AI中文版

Transformer模型详解
Transformer的起源与发展
Transformer模型由Vaswani等人在2017年的论文《Attention is All You Need》中首次提出。不同于传统的RNN或卷积神经网络,Transformer完全基于自注意力机制,实现了高效的并行计算,显著提升了训练速度和性能。Transformer的出现标志着NLP领域的一次革命,其架构成为后续众多先进模型的基础。
Transformer的核心架构
Transformer模型主要由两个部分组成:编码器(Encoder)和解码器(Decoder)。每个编码器和解码器由多个相同的层堆叠而成,每一层包括:
- 多头自注意力机制(Multi-Head Self-Attention):通过计算输入序列中每个位置与其他位置的相关性,实现对输入的加权,捕捉全局依赖关系。
- 前馈神经网络(Feed-Forward Neural Network):对每个位置的表示进行独立的非线性变换。
- 残差连接与层归一化(Residual Connection & Layer Normalization):通过残差连接缓解深层网络中的梯度消失问题,层归一化则稳定训练过程。
此外,Transformer使用位置编码(Positional Encoding)为输入序列中的每个位置添加位置信息,因为自注意力机制本身不具备处理序列顺序的能力。

Transformer的优势与局限
优势:
- 并行化处理:不同于RNN的顺序处理,Transformer可以对整个序列进行并行计算,显著提升训练效率。
- 长距离依赖建模:自注意力机制能够直接捕捉序列中任意位置之间的依赖关系,解决了RNN在处理长序列时的困难。
- 灵活性:Transformer架构通用,可用于各种序列到序列的任务,如机器翻译、文本生成等。
局限:
- 计算资源需求高:自注意力机制需要计算序列中每一对位置之间的关系,随着序列长度的增加,计算复杂度呈平方级增长。
- 位置编码的限制:尽管位置编码为模型提供了位置信息,但在处理极长序列时,位置编码可能不够精细,影响模型性能。
BERT模型深度解析
BERT的基本概念
BERT(Bidirectional Encoder Representations from Transformers)由Google在2018年提出,是基于Transformer编码器的双向预训练模型。不同于单向语言模型,BERT通过双向上下文信息的捕捉,显著提升了NLP任务的表现。BERT通过无监督的预训练和有监督的微调两个阶段,实现了在多项任务上的SOTA性能。

BERT的预训练与微调
预训练阶段:
BERT的预训练包括两个任务:
- 掩码语言模型(Masked Language Model, MLM):在输入文本中随机掩盖一些词,模型需预测这些被掩盖的词。这一任务使模型能够学习双向上下文信息。
- 下一句预测(Next Sentence Prediction, NSP):判断两句话是否为连续句子。这一任务帮助模型理解句子级别的关系。
微调阶段:
在预训练完成后,BERT可以通过在特定任务上的微调,适应下游应用。这一过程通常涉及在预训练模型的基础上,添加任务特定的输出层,并在有标注数据的情况下进行训练。例如,在分类任务中,可以在BERT的输出上添加一个全连接层,用于预测类别标签。
BERT在实际中的应用
BERT在多种NLP任务中表现卓越,包括但不限于:
- 文本分类:如情感分析、垃圾邮件检测等。
- 命名实体识别(NER):识别文本中的实体,如人名、地点名等。
- 问答系统:理解用户提问,并从文本中找到准确答案。
- 文本摘要:生成简洁的文本摘要,保留关键信息。
BERT的成功为NLP模型的预训练与微调提供了范式,促使更多基于Transformer的双向模型涌现。
GPT模型全面剖析
GPT的发展历程
GPT(Generative Pre-trained Transformer)由OpenAI于2018年提出,基于Transformer解码器架构。与BERT不同,GPT采用单向(左到右)的语言模型,通过大规模的预训练数据,学习生成连贯的文本。随着版本的迭代,GPT在模型规模与性能上不断提升,最新的GPT-4在多项任务上表现出色,被广泛应用于文本生成、对话系统等领域。

GPT的架构与工作原理
GPT基于Transformer的解码器部分,主要包括多层的自注意力机制和前馈神经网络。与BERT的双向编码器不同,GPT采用单向的自注意力,只关注前文信息,确保生成文本的连贯性。
主要特点:
- 自回归生成:GPT通过逐步生成下一个词,实现连贯的文本生成。
- 大规模预训练:GPT在海量的文本数据上进行预训练,学习语言的语法和语义知识。
- 迁移学习:与BERT类似,GPT可以通过微调适应各种下游任务,提升任务性能。
GPT的实际应用场景
GPT在多个领域展现出强大的能力,包括但不限于:
- 文本生成:如文章撰写、故事生成等。
- 对话系统:构建智能客服、聊天机器人等。
- 代码生成:自动编写代码,提高编程效率。
- 内容推荐:根据用户输入生成个性化内容推荐。
GPT的灵活性和强大生成能力,使其在多个应用场景中成为不可或缺的工具。
GPT与BERT的比较分析
架构上的区别
- 方向性:BERT是双向的,能够同时关注左右上下文;而GPT是单向的,只关注前文信息。
- 编码器与解码器:BERT基于Transformer的编码器部分,侧重于理解任务;GPT基于Transformer的解码器部分,侧重于生成任务。
应用场景的差异
- BERT:更适合需要深度理解的任务,如分类、问答、NER等。
- GPT:更适合生成任务,如文本生成、对话系统、代码编写等。
性能与效果的对比
在理解类任务上,BERT通常表现优于GPT;而在生成类任务上,GPT则展示出更强大的能力。然而,随着GPT模型规模的扩大,其在理解任务上的表现也在不断提升,缩小了与BERT之间的差距。
实战教程:如何应用Transformer、BERT与GPT
本文将通过一个简单的例子,展示如何在实际项目中应用Transformer、BERT与GPT模型。我们将以文本分类任务为例,分别使用BERT和GPT进行实现。
环境搭建与工具选择
首先,确保你的开发环境中安装了以下工具:
- Python 3.7+
- PyTorch或TensorFlow(本文以PyTorch为例)
- Transformers库(由Hugging Face提供)
- 其他依赖库:如numpy、pandas、scikit-learn等
安装必要的库:
pip install torch transformers numpy pandas scikit-learn
Transformer模型的实现与优化
虽然Transformer模型是复杂的架构,但在实际应用中,使用预训练模型可以大大简化流程。以下示例将展示如何使用预训练的Transformer模型进行文本分类。
import torch
from transformers import BertTokenizer, BertForSequenceClassification
from torch.utils.data import DataLoader, Dataset
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 自定义数据集
class TextDataset(Dataset):def __init__(self, texts, labels, tokenizer, max_len):self.texts = textsself.labels = labelsself.tokenizer = tokenizerself.max_len = max_lendef __len__(self):return len(self.texts)def __getitem__(self, idx):encoding = self.tokenizer.encode_plus(self.texts[idx],add_special_tokens=True,max_length=self.max_len,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt',)return {'input_ids': encoding['input_ids'].flatten(),'attention_mask': encoding['attention_mask'].flatten(),'labels': torch.tensor(self.labels[idx], dtype=torch.long)}# 示例数据
texts = ["I love machine learning", "Transformers are amazing", "BERT is great for NLP"]
labels = [1, 1, 1] # 示例标签# 分割数据
train_texts, val_texts, train_labels, val_labels = train_test_split(texts, labels, test_size=0.2, random_state=42
)# 初始化Tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')# 创建数据集
train_dataset = TextDataset(train_texts, train_labels, tokenizer, max_len=32)
val_dataset = TextDataset(val_texts, val_labels, tokenizer, max_len=32)# 创建DataLoader
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=2)# 初始化模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
model = model.to('cuda' if torch.cuda.is_available() else 'cpu')# 优化器
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)# 训练循环
def train(model, loader, optimizer):model.train()for batch in loader:input_ids = batch['input_ids'].to(model.device)attention_mask = batch['attention_mask'].to(model.device)labels = batch['labels'].to(model.device)outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)loss = outputs.lossloss.backward()optimizer.step()optimizer.zero_grad()# 验证函数
def evaluate(model, loader):model.eval()preds = []true = []with torch.no_grad():for batch in loader:input_ids = batch['input_ids'].to(model.device)attention_mask = batch['attention_mask'].to(model.device)labels = batch['labels'].to(model.device)outputs = model(input_ids=input_ids, attention_mask=attention_mask)logits = outputs.logitspreds.extend(torch.argmax(logits, dim=1).tolist())true.extend(labels.tolist())return accuracy_score(true, preds)# 训练与验证
for epoch in range(3):train(model, train_loader, optimizer)acc = evaluate(model, val_loader)print(f"Epoch {epoch+1}: Validation Accuracy = {acc}")BERT模型的微调与应用
上述示例已经展示了如何使用BERT进行文本分类的微调。通过加载预训练的BERT模型,添加分类层,并在特定任务上进行微调,可以快速实现高性能的NLP应用。
GPT模型的生成与应用
虽然GPT主要用于生成任务,但也可以通过适当的调整应用于理解类任务。以下示例展示如何使用GPT进行文本生成。
from transformers import GPT2Tokenizer, GPT2LMHeadModel# 加载预训练模型和Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
model = model.to('cuda' if torch.cuda.is_available() else 'cpu')# 输入提示
prompt = "Artificial Intelligence is"# 编码输入
input_ids = tokenizer.encode(prompt, return_tensors='pt').to(model.device)# 生成文本
output = model.generate(input_ids,max_length=50,num_return_sequences=1,no_repeat_ngram_size=2,early_stopping=True
)# 解码输出
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
发展趋势
随着计算能力的提升和数据规模的扩大,Transformer、BERT与GPT模型将持续演进,呈现以下发展趋势:
- 模型规模的进一步扩大:未来的模型将拥有更多的参数,具备更强的表达能力和泛化能力。
- 高效模型架构的探索:为应对计算资源的限制,研究者将致力于设计更高效的模型架构,如稀疏注意力机制、剪枝技术等。
- 跨模态融合:将NLP模型与计算机视觉、语音识别等技术相结合,推动多模态AI的发展。
- 应用场景的多样化:从文本生成、对话系统到代码编写、医疗诊断,NLP模型将在更多领域发挥重要作用。
- 伦理与安全:随着模型能力的增强,如何确保其应用的伦理性和安全性,将成为重要的研究方向。
结论
Transformer、BERT与GPT模型代表了当前自然语言处理领域的顶尖技术。通过深入理解这些模型的工作原理与应用方法,开发者可以在实际项目中高效应用这些工具,推动AI技术的发展。本文从基础原理到实用教程,为你提供了一份系统、全面的学习资料,希望能助你在NLP的道路上不断前行。未来,随着技术的不断进步,这些模型将继续引领AI的创新潮流,开创更多令人兴奋的应用
相关文章:
【人工智能】深入解析GPT、BERT与Transformer模型|从原理到应用的完整教程
在当今人工智能迅猛发展的时代,自然语言处理(NLP)领域涌现出许多强大的模型,其中GPT、BERT与Transformer无疑是最受关注的三大巨头。这些模型不仅在学术界引起了广泛讨论,也在工业界得到了广泛应用。那么,G…...

彻底理解如何保证ElasticSearch和数据库数据一致性问题
一.业务场景举例 需求: 一个卖房业务,双十一前一天,维护楼盘的运营人员突然接到合作开发商的通知,需要上线一批热门的楼盘列表,上传完成后,C端小程序支持按楼盘的名称、户型、面积等产品属性全模糊搜索热门…...

2024-2025热门留学趋势
在信息爆炸的时代,留学已成为许多人规划未来、拓宽视野的重要途径。随着全球教育格局的不断变化,留学领域也涌现出一系列新热点和趋势。本文将为您解读2024年最热门的留学话题,并提供实用的准备策略,助您在留学之路上一帆风顺。 热…...

寻找视频特效素材的优质网站推荐 轻松提升作品魅力
在短视频、影视和广告制作中,视频特效素材已成为提升作品专业感的关键元素。炫酷的光效、震撼的爆炸、动感的粒子效果和流畅的转场特效,都能让作品更具吸引力。那么,视频特效素材去哪里找呢?今天,小编为大家精心挑选了…...

【英特尔IA-32架构软件开发者开发手册第3卷:系统编程指南】2001年版翻译,2-36
文件下载与邀请翻译者 学习英特尔开发手册,最好手里这个手册文件。原版是PDF文件。点击下方链接了解下载方法。 讲解下载英特尔开发手册的文章 翻译英特尔开发手册,会是一件耗时费力的工作。如果有愿意和我一起来做这件事的,那么ÿ…...
信息安全实验--密码学实验工具:CrypTool
1. CrypTool介绍💭 CrypTool 1的开源教育工具,用于密码学研究。通过CrypTool 1,可以实现加密和解密操作,数字签名。CrypTool1和2有很多区别的。 2. CrpyTool下载🔧 在做信息安全实验--密码学相关实验时,发…...

python的class 类创建、方法调用以及属性赋值
题目:购物车系统 创建一个简单的购物车系统,要求如下: 定义一个 Product 类,表示商品,包含以下属性和方法: 属性: name:商品名称(字符串) price࿱…...
:响应式当红实现signal的详细介绍:它擅长做什么、不能做什么?以及与vue、svelte、react等框架的响应式实现对比)
Angular v19 (二):响应式当红实现signal的详细介绍:它擅长做什么、不能做什么?以及与vue、svelte、react等框架的响应式实现对比
本文紧接着Angular v19 新版本来啦,一起瞧瞧新特性吧!,主要针对它在v18引入了一项全新的响应式技术——Signal,这引起了开发者社区的广泛关注,最新的v19版本推出了更多的signal工具。Signal的加入旨在优化Angular的响应…...

IMX 平台UART驱动情景分析:write篇--从 TTY 层到硬件驱动的写操作流程解析
往期内容 本专栏往期内容:Uart子系统 UART串口硬件介绍深入理解TTY体系:设备节点与驱动程序框架详解Linux串口应用编程:从UART到GPS模块及字符设备驱动 解UART 子系统:Linux Kernel 4.9.88 中的核心结构体与设计详解IMX 平台UART驱…...

网络安全拟态防御技术
一. 拟态防御 拟态现象(Mimic Phenomenon, MP)是指一种生物如果能够在色彩、纹理和形状等特征上模拟另一种生物或环境,从而使一方或双方受益的生态适应现象。按防御行为分类可将其列入基于内生机理的主动防御范畴,又可称之为拟…...

灵活开源低代码平台——Microi吾码(一)
开源低代码平台-Microi吾码-平台简介1. 什么是低代码平台?2. 它能做什么?3. 它的优点是什么? 平台预览图平台亮点版本区别成功案例源码目录说明Microi吾码 - 系列文档 开源低代码平台-Microi吾码-平台简介 技术框架:.NET8 Redis …...
)
frida_hook_libart(简单解释)
一:直接取代码 //frida -U -f com.xingin.xhs -l hook_art.js -o xhsart.log //frida -U -f com.tencent.mobileqq -l hook_art.js -o qqart.logconst STD_STRING_SIZE 3 * Process.pointerSize; class StdString {constructor() {this.handle Memory.alloc(STD_S…...
)
计算机网络八股整理(二)
计算机网络八股整理(二) 应用层 1:dns的全称了解过吗? dns全称domain-name-system,翻译过来就是域名系统,是在计算机网络中将域名转换成ip地址的分布式数据库系统; 域名服务器的层级类似一个树…...

强化学习off-policy进化之路(PPO->DPO->KTO->ODPO->ORPO->simPO)
需要LLM在训练过程中做生成的方法是 On Policy,其余的为Off Policy。 On Policy是包含了反馈机制,Off Policy不包含反馈机制。 若进行环境交互的模型与被更新的模型是相同的模型,通常这种更新策略被称为on-policy的策略。on-policy的方法会有…...

Linux 如何创建逻辑卷并使用
一、逻辑卷的介绍 生成环境中逻辑卷使用率很高 逻辑卷的诞生:如果对磁盘直接使用fdisk分区,那么这中分区,我们叫做Linux的标准分区,Linux的标准分区格式化成文件系统之后,挂载使用,那么一旦文件系统的空间…...

java实现将图片插入word文档
插入图片所用依赖 private static void insertImage(XWPFDocument document, String path) {List<XWPFParagraph> paragraphs document.getParagraphs();for (XWPFParagraph paragraph : paragraphs) {CTP ctp paragraph.getCTP();for (int dwI 0; dwI < ctp.sizeO…...

初识java(3)
大家好,今天我们来讲讲我们的老伙计-变量,在哪一门编程语言中,变量的作用都是不可或缺的,那么下面我们就来详细了解一下java中的变量。 一.变量概念 在程序中,除了有始终不变的常量外,有些内容可能会经常…...

coqui-ai TTS 初步使用
项目地址:https://github.com/coqui-ai/TTS 1. 创建一个新的conda环境,如果自己会管理python环境也可以用其他方法 克隆项目下来 pip install -r requirements.txt # 安装依赖 pip install coqui-tts # 只要命令行工具的话 下载自己想要的模型 …...

matlab代码--卷积神经网络的手写数字识别
1.cnn介绍 卷积神经网络(Convolutional Neural Network, CNN)是一种深度学习的算法,在图像和视频识别、图像分类、自然语言处理等领域有着广泛的应用。CNN的基本结构包括输入层、卷积层、池化层(Pooling Layer)、全连…...

Scala—Map用法详解
Scala—Map用法详解 在 Scala 中,Map 是一种键值对的集合,其中每个键都是唯一的。Scala 提供了两种类型的 Map:不可变 Map 和可变 Map。 1. 不可变集合(Map) 不可变 Map 是默认的 Map 实现,位于 scala.co…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...
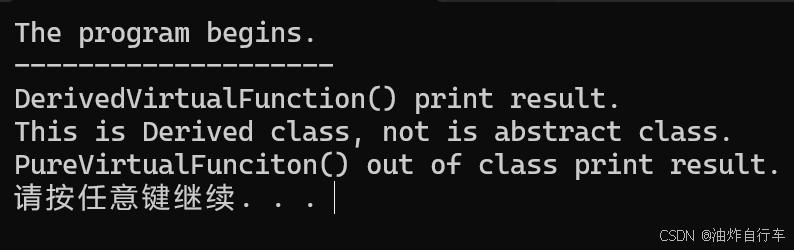
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...

pycharm 设置环境出错
pycharm 设置环境出错 pycharm 新建项目,设置虚拟环境,出错 pycharm 出错 Cannot open Local Failed to start [powershell.exe, -NoExit, -ExecutionPolicy, Bypass, -File, C:\Program Files\JetBrains\PyCharm 2024.1.3\plugins\terminal\shell-int…...