Transformers快速入门代码解析(六):注意力机制——Transformer Encoder:执行顺序解析
Transformer Encoder:执行顺序解析
- 引言
- 执行顺序解析
- 1. 设置模型检查点和分词器
- 2. 输入预处理
- 操作说明:
- 3. 加载模型配置`config`
- `config` 包含的主要参数
- 常见配置(BERT-base)
- 4. 初始化 TransformerEncoder
- 5. Transformer Encoder 的前向传播
- 完整代码
引言
请注意!!!本博客使用了教程Transformers快速入门中的全部代码!!!
只在我个人理解的基础上为代码添加了注释!!!
详细教程请查看Transformers快速入门!!!
万分感谢!!!
自用!!!
执行顺序解析
Transformer 模型的执行顺序由嵌入层、编码器层和注意力机制等核心模块构成。在下面的详细分析中,我们一步步梳理代码的执行流程,并解释每一步的输入、处理过程和输出。
1. 设置模型检查点和分词器
model_ckpt = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model_ckpt: 定义我们要使用的预训练模型(如 BERT)的名称。- 加载分词器:
AutoTokenizer.from_pretrained(model_ckpt)加载一个与 BERT 兼容的分词器。- 分词器的任务是将自然语言文本转换为整数 token ID,供模型处理。
2. 输入预处理
text = "time flies like an arrow"
inputs = tokenizer(text, return_tensors="pt", add_special_tokens=False)
操作说明:
- 输入文本:
"time flies like an arrow"。 - 使用分词器将文本分成 tokens(例如,
["time", "flies", "like", "an", "arrow"])。 - 每个 token 转换为词汇表中的索引值(token IDs)。
- 例如,在本例子中为:
[2051, 10029, 2066, 2019, 8612]。 - 示例输出:
inputs.input_ids = [[2051, 10029, 2066, 2019, 8612]]
- 例如,在本例子中为:
- 结果存储为张量
inputs.input_ids,形状为[batch_size, seq_length],里面的内容是[[2051, 10029, 2066, 2019, 8612]]。- 形状:
[1, 5](1 表示批大小,5 表示 token 数量)。
- 形状:
- 生成 PyTorch 张量:
- 设置
return_tensors="pt",将输出格式指定为 PyTorch 张量。
- 设置
3. 加载模型配置config
config = AutoConfig.from_pretrained(model_ckpt)
config 是 Transformer 模型的配置对象,包含模型的超参数和结构定义。它用于初始化模型的各种模块,如嵌入层、注意力机制和前馈网络。该对象的值通常通过预训练模型加载,或者手动设置。
config 包含的主要参数
常见配置(BERT-base)
{"hidden_size": 768,"vocab_size": 30522,"max_position_embeddings": 512,"num_attention_heads": 12,"intermediate_size": 3072,"hidden_dropout_prob": 0.1,"num_hidden_layers": 12,"attention_probs_dropout_prob": 0.1
}
-
hidden_size- 描述:Transformer 的隐藏层维度,表示每个 token 的特征向量维度。
- 示例:对于 BERT-base 模型,
hidden_size = 768。 - 用途:
- 决定嵌入层(
nn.Embedding)的输出维度。 - 决定多头注意力和前馈网络中各层的特征维度。
- 决定嵌入层(
-
vocab_size- 描述:词汇表的大小,表示模型可以处理的不同 token 的数量。
- 示例:对于 BERT-base 模型,
vocab_size = 30522。 - 用途:
- 决定嵌入层的输入大小(
nn.Embedding(config.vocab_size, config.hidden_size))。
- 决定嵌入层的输入大小(
-
max_position_embeddings- 描述:支持的最大序列长度,表示模型可以处理的最长 token 序列。
- 示例:对于 BERT-base 模型,
max_position_embeddings = 512。 - 用途:
- 决定位置嵌入矩阵的大小(
nn.Embedding(config.max_position_embeddings, config.hidden_size))。
- 决定位置嵌入矩阵的大小(
-
num_attention_heads- 描述:注意力头的数量,决定多头注意力机制中并行的头数。
- 示例:对于 BERT-base 模型,
num_attention_heads = 12。 - 用途:
- 每个注意力头的特征维度由
head_dim = hidden_size // num_attention_heads计算。 - 决定
MultiHeadAttention模块的头数。
- 每个注意力头的特征维度由
-
intermediate_size- 描述:前馈网络中间层的维度。
- 示例:对于 BERT-base 模型,
intermediate_size = 3072。 - 用途:
- 决定前馈网络第一层的输出维度(
nn.Linear(hidden_size, intermediate_size))。
- 决定前馈网络第一层的输出维度(
-
hidden_dropout_prob- 描述:Dropout 的概率,用于防止过拟合。
- 示例:对于 BERT-base 模型,
hidden_dropout_prob = 0.1。 - 用途:
- 用于嵌入层和前馈网络中的 Dropout 层。
-
num_hidden_layers- 描述:Transformer 编码器层的数量。
- 示例:对于 BERT-base 模型,
num_hidden_layers = 12。 - 用途:
- 决定 Transformer 编码器堆叠的层数(
nn.ModuleList([TransformerEncoderLayer(config) for _ in range(config.num_hidden_layers)]))。
- 决定 Transformer 编码器堆叠的层数(
-
attention_probs_dropout_prob- 描述:注意力分布的 Dropout 概率。
- 示例:对于 BERT-base 模型,
attention_probs_dropout_prob = 0.1。 - 用途:
- 用于多头注意力模块的 Dropout 层。
4. 初始化 TransformerEncoder
encoder = TransformerEncoder(config)
-
嵌入层:生成 token 嵌入和位置嵌入。
- 调用
Embeddings(config)。 - 包括:
token_embeddings:将 token ID 转换为嵌入向量。position_embeddings:根据序列/句子的长度为序列位置生成嵌入向量。LayerNorm和Dropout:归一化和防止过拟合。
- 调用
-
多层 Transformer 编码器层:逐层提取输入序列的上下文特征。
nn.ModuleList构建多个TransformerEncoderLayer。- 每个编码器层包含:
- 多头注意力机制(
MultiHeadAttention)。 - 前馈神经网络(
FeedForward)。 - 层归一化(
LayerNorm)和跳跃连接(Skip-Connection)。
- 多头注意力机制(
5. Transformer Encoder 的前向传播
# encoder.forward(inputs.input_ids)
encoder(inputs.input_ids)
-
嵌入层处理
x = self.embeddings(x)- 输入
inputs.input_ids,形状为[1, 5]。- token ID(形状
[batch_size, seq_length])经过Embeddings模块
- token ID(形状
- Token 嵌入:使用嵌入矩阵将 token ID 映射为高维嵌入向量
- 使用嵌入矩阵
self.token_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)将 token ID 映射为高维嵌入向量。- 嵌入矩阵形状:
[30522, 768](30522 是词汇表大小,768 是嵌入维度)。- 词汇表:已知/预训练的模型/分词器有多少个单词/token,这里是有30522个单词/token。
- 每个 token ID 被映射为一个 768 维向量。
- 嵌入维度:每个单词/token具有的特征的数量,这里每个单词/token有768个特征。
- 嵌入矩阵形状:
- 按照
inputs.input_ids中token的ID在self.token_embeddings中查找对应ID的特征值(768个特征)。因为给定的句子有5个单词/token,所以会找到5组768个特征的向量)。为每个 token 添加特征的特征信息 - 输出形状:
[batch_size, seq_length, hidden_size]。 - 输出特征嵌入的形状为:
[1, 5, 768]。- 表示 1 个样本,包含 5 个 token,每个 token 对应一个 768 维特征特征嵌入。
- 使用嵌入矩阵
- 位置嵌入:为每个 token 添加位置嵌入
- 首先生成它们在序列中的位置:
[0, 1, 2, 3, 4]。 - 然后使用嵌入矩阵
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)将位置信息映射为高维嵌入向量。- 位置嵌入矩阵形状:
[512, 768](512 是最大序列长度,768 是嵌入维度)。 - 例如,第一个 token 对应第 0 个位置,第二个 token 对应第 1 个位置。
- 位置嵌入矩阵形状:
- 同理,根据序列中单词/token的位置在
self.position_embeddings中找到对应位置的特征(768个特征)。因为给定的句子有5个单词/token,所以会找到5组768个特征的向量)。为每个 token 添加位置的特征信息。 - 输出形状:
[batch_size, seq_length, hidden_size]。 - 输出位置嵌入的形状为
[1, 5, 768]。- 表示 1 个样本,包含 5 个 token,每个 token 对应一个 768 维位置特征嵌入。
- 首先生成它们在序列中的位置:
- 将 token 特征的特征信息和 token 位置的特征信息相加。
- 归一化和 Dropout:
- 对嵌入加权后归一化,结果形状为
[1, 5, 768]。
- 对嵌入加权后归一化,结果形状为
- 输入
-
编码器层逐层处理
for layer in self.layers:x = layer(x, mask=mask)- 逐层调用
TransformerEncoderLayer。- 每层都包含:
- 多头注意力机制: 捕获序列中不同 token 之间的关系。
- 前馈神经网络: 提取更复杂的特征表示。
- 跳跃连接和层归一化: 确保梯度流动和数值稳定。
- 每层都包含:
- 输入
x:结合了token 特征的特征信息和 token 位置的特征信息的数组,形状为[1, 5, 768]。 - 每一层包括以下步骤:
-
层归一化:
hidden_state = self.layer_norm_1(x)- 追溯到的
code是:self.layer_norm_1 = nn.LayerNorm(config.hidden_size) # config.hidden_size = 768 - 对输入
x进行标准化,消除特征的均值和方差差异,减少数值波动。 - 输出形状为
[batch_size, seq_length, hidden_size] -> [1, 5, 768]。
- 追溯到的
-
多头注意力机制:
x = x + self.attention(hidden_state, hidden_state, hidden_state, mask=mask)- 追溯到的
code是:self.attention = MultiHeadAttention(config) - 输入
query=key=value=hidden_state,形状为[1, 5, 768]。query,key,value均为归一化后的hidden_state(自注意力机制)。
- 每个注意力头独立计算注意力权重并生成上下文向量,并且将
hidden_state转为低维向量(如[1, 5, 64])。- 将
query,key,value分别通过线性变换映射到12(config.num_attention_heads)个注意力头的特征空间。 - 每个头的维度:
head_dim = 768 / 12 = 64。简单来说可以想象成64个query,key,value的组合。 - 使用下面函数将这64个
[query, key, value](形状:[1, 5, 768])转为低维向量:self.q = nn.Linear(embed_dim, head_dim) # 768, 64 self.k = nn.Linear(embed_dim, head_dim) # 768, 64 self.v = nn.Linear(embed_dim, head_dim) # 768, 64self.q(query), self.k(key), self.v(value), - 得到新的64个
[query, key, value](形状:[1, 5, 64])。
- 将
- 计算点积注意力得分:
-
将新的64个
[query, key, value](形状:[1, 5, 64])依次传输到scaled_dot_product_attention()方程中计算点积注意力得分:scores = Q ⋅ K T head_dim \text{scores} = \frac{Q \cdot K^T}{\sqrt{\text{head\_dim}}} scores=head_dimQ⋅KT
-
得分矩阵形状:
[1, 5, 5]。因为是5个单词/token,这个得分可以想象成5个单词/token之间的关系强度,即是否有很强/弱的关联性。
-
- 使用 Softmax 归一化后,生成注意力分布。
weights = F.softmax(scores, dim=-1) - 计算上下文表示:
context = weights ⋅ V \text{context} = \text{weights} \cdot V context=weights⋅V- 将单词/token之间的关系强度和每个单词/token自己的特征关联起来:
[1, 5, 5] x [1, 5, 64] -> [1, 5, 64]
- 将单词/token之间的关系强度和每个单词/token自己的特征关联起来:
- 每个头的输出形状:
[1, 5, 64]。 - 所有12个注意力头的输出通过
torch.cat拼接并线性变换,得到[1, 5, 768]。 - 跳跃连接: 将注意力机制的输出与输入
x相加,增强信息流动,保留原始输入信息。
- 追溯到的
-
前馈网络:
x = x + self.feed_forward(self.layer_norm_2(x))- 前馈网络:
- 先做归一化。
- 再输入归一化之后的变量,形状:
[1, 5, 768]。 - 中间层线性升维至
3072:扩展维度帮助模型捕获更多的特征模式,形状:[1, 5, 3072]。 - 使用GELU 激活函数,维度不变。
- 最终线性降维回原始维度,形状:
[1, 5, 768]。 - 应用 Dropout 防止过拟合。
- 跳跃连接: 将前馈网络的输出与上一层的结果相加,增强梯度流动。
- 前馈网络:
-
- 得到形状为
[1, 5, 768]的结果之后被不断的送入到hidden_layers。
- 逐层调用
-
输出结果:
- 最终输出形状为
[1, 5, 768]。 - 每个 token 的向量表示与上下文序列的关系。
- 最终输出形状为
完整代码
from torch import nn
import torch
import torch.nn.functional as F
from math import sqrtfrom transformers import AutoConfig
from transformers import AutoTokenizer# query_mask, key_mask:
#### 用于屏蔽某些查询或键的位置。如果指定,通常是 [batch_size, seq_length] 的张量。
#### 这些掩码可以屏蔽不需要参与计算的序列位置(例如,填充位置)。
# mask:
#### 更通用的掩码,形状通常为 [batch_size, seq_length, seq_length],
#### 用于屏蔽具体的查询-键对。
def scaled_dot_product_attention(query, key, value, query_mask=None, key_mask=None, mask=None):dim_k = query.size(-1)scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(dim_k)# 应用掩码(屏蔽不相关的输入)if query_mask is not None and key_mask is not None:# query_mask.unsqueeze(-1) 将查询掩码扩展为 [batch_size, seq_length, 1]。# key_mask.unsqueeze(1) 将键掩码扩展为 [batch_size, 1, seq_length]。# torch.bmm 计算两者的外积,得到形状为 [batch_size, seq_length, seq_length] 的掩码矩阵 mask。# 掩码矩阵中的值为 1 表示对应的查询-键对有效,0 表示无效。mask = torch.bmm(query_mask.unsqueeze(-1), key_mask.unsqueeze(1))if mask is not None:# 如果存在 mask,使用 masked_fill 方法将 mask == 0 的位置填充为 -inf,# 这些位置的得分被屏蔽。# Softmax 在处理 -inf 时会将其归一化为 0,从而屏蔽这些位置。scores = scores.masked_fill(mask == 0, -float("inf"))weights = F.softmax(scores, dim=-1)return torch.bmm(weights, value)# AttentionHead:
#### 每个注意力头会独立地从输入中学习查询(query)、键(key)和值(value)的表示,
#### 并通过注意力机制聚合上下文信息。
# nn.Module:
#### 继承自 PyTorch 的 nn.Module,是构建神经网络的基础类。
#### 提供了模块参数管理和自动求导的能力。
class AttentionHead(nn.Module):# embed_dim:#### 输入嵌入的维度。#### 表示输入序列中每个 token 的特征向量大小。# head_dim:#### 注意力头的维度。#### 每个注意力头会将输入嵌入维度 embed_dim 映射到更低的 head_dim 维度。# nn.Linear:#### 定义了三个线性变换层:######## self.q:将输入映射到查询(query)向量。######## self.k:将输入映射到键(key)向量。######## self.v:将输入映射到值(value)向量。#### 每个线性层的参数如下:######## 输入维度:embed_dim######## 输出维度:head_dim#### 通过这些线性变换,将原始输入嵌入的特征空间变换为注意力机制需要的特征空间。# =================================================================================================# 降维/升维(通过线性变换)def __init__(self, embed_dim, head_dim): # 768, 64super().__init__()self.q = nn.Linear(embed_dim, head_dim)self.k = nn.Linear(embed_dim, head_dim)self.v = nn.Linear(embed_dim, head_dim)# self.q(query):将查询向量通过线性层映射到头的特征空间,输出形状为 [batch_size, seq_length, head_dim]。# self.k(key) 和 self.v(value):同理,将键和值映射到特征空间。def forward(self, query, key, value, query_mask=None, key_mask=None, mask=None):attn_outputs = scaled_dot_product_attention(self.q(query), self.k(key), self.v(value), query_mask, key_mask, mask)return attn_outputs# 每个注意力头独立计算注意力分布,最终将所有头的结果连接起来并通过一个线性变换聚合。
class MultiHeadAttention(nn.Module):# config:#### 一个配置对象,通常用于存储模型的超参数。#### 必须包含以下字段:######## hidden_size:输入嵌入的总维度。######## num_attention_heads:注意力头的数量。def __init__(self, config):super().__init__()embed_dim = config.hidden_size# print("embed_dim的数量:")# print(embed_dim)# print("==================")num_heads = config.num_attention_heads# print("num_heads的数量:")# print(num_heads)# print("==================")# 实践中一般将 head_dim 设置为 embed_dim 的因数,# 这样 token 嵌入式表示的维度就可以保持不变,# 例如 BERT 有 12 个注意力头,因此每个头的维度被设置为 768 / 12 = 64# 确保总的注意力头输出维度与输入嵌入维度一致。head_dim = embed_dim // num_heads# print("head_dim的数量:")# print(head_dim)# print("==================")# 使用 nn.ModuleList 创建多个 AttentionHead 实例。# 每个 AttentionHead 独立计算注意力分布和上下文聚合。self.heads = nn.ModuleList([AttentionHead(embed_dim, head_dim) for _ in range(num_heads)])# 定义一个线性层,用于将所有注意力头的结果进行聚合和变换。# 输入维度和输出维度都是 embed_dim,确保注意力模块的输入和输出形状一致。self.output_linear = nn.Linear(embed_dim, embed_dim)# query, key, value:#### 输入序列的查询、键和值向量。#### 形状为 [batch_size, seq_length, embed_dim]。# query_mask, key_mask, mask:#### 掩码,用于屏蔽不需要计算的查询或键,避免影响注意力计算。def forward(self, query, key, value, query_mask=None, key_mask=None, mask=None):# 遍历每个注意力头(self.heads),调用 AttentionHead 的 forward 方法。# 每个注意力头独立地处理查询、键和值,并返回其上下文输出。# 每个头的输出形状为 [batch_size, seq_length, head_dim]。# 将所有头的输出在最后一个维度(dim=-1)拼接起来。# 拼接后,形状为 [batch_size, seq_length, embed_dim],因为:# embed_dim = num_heads \times head_dimx = torch.cat([h.forward(query, key, value, query_mask, key_mask, mask) for h in self.heads], dim=-1)# print("==================")# print("x的size:")# print(x.size())# print("==================")# 使用 self.output_linear 对拼接后的结果进行线性变换。# 线性变换可以引入头之间的交互信息,并生成最终的注意力输出。# 输出形状仍为 [batch_size, seq_length, embed_dim]。x = self.output_linear(x)return x# 这段代码实现了 前馈神经网络(Feed-Forward Neural Network, FFN),
# 这是 Transformer 模型的核心组件之一。
# FFN 在多头注意力之后对特征进行非线性变换和映射,帮助模型学习更复杂的特征表示。
class FeedForward(nn.Module):def __init__(self, config):# hidden_size:输入和输出的特征维度(与 Transformer 的嵌入维度相同)。# intermediate_size:前馈网络中间层的特征维度。# hidden_dropout_prob:Dropout 的概率。super().__init__()# 第一层线性变换(self.linear_1):# 将输入特征从 hidden_size 映射到更高维度的 intermediate_size。# 扩展维度帮助模型捕获更多的特征模式。# print("FeedForward中config.hidden_size的数量:")# print(config.hidden_size)# print("FeedForward中config.intermediate_size的数量:")# print(config.intermediate_size)# print("==================")self.linear_1 = nn.Linear(config.hidden_size, config.intermediate_size)# 第二层线性变换(self.linear_2):# 将特征从中间维度 intermediate_size 映射回原始维度 hidden_size。self.linear_2 = nn.Linear(config.intermediate_size, config.hidden_size)# 激活函数(self.gelu):# 使用 GELU(高斯误差线性单元)作为非线性激活函数。# 相比于 ReLU,GELU 提供更平滑的激活效果,通常在 Transformer 模型中效果更好。# gelu(x) = 0.5 * x * (1 + np.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * x**3)))self.gelu = nn.GELU()# Dropout 层(self.dropout):# 在输出层添加 Dropout,以防止过拟合。# Dropout 会以概率 hidden_dropout_prob 随机将一些特征置为零。self.dropout = nn.Dropout(config.hidden_dropout_prob)# 输入张量,形状为 [batch_size, seq_length, hidden_size]。# 这是从多头注意力层传递过来的上下文特征。def forward(self, x):# 第一层线性变换:#### 输入形状为 [batch_size, seq_length, hidden_size]。#### 通过线性变换后,形状变为 [batch_size, seq_length, intermediate_size]。x = self.linear_1(x)# 激活函数:#### 对第一层的输出应用 GELU 激活函数,形状保持不变。x = self.gelu(x)# 第二层线性变换:#### 将特征从中间维度 intermediate_size 映射回原始维度 hidden_size。#### 输出形状为 [batch_size, seq_length, hidden_size]。x = self.linear_2(x)# Dropout:#### 对输出应用 Dropout,形状保持不变。x = self.dropout(x)# 返回结果:#### 返回经过两层线性变换和激活后的结果,形状为 [batch_size, seq_length, hidden_size]。return x# 这段代码实现了一个 Transformer 编码器层(Transformer Encoder Layer),是 Transformer 模型的基础构建模块之一。
# 它结合了多头注意力机制(Multi-Head Attention)、
# 前馈网络(Feed-Forward Neural Network, FFN)
# 以及跳跃连接(Skip Connection)
# 和层归一化(Layer Normalization)。
# 定义 TransformerEncoderLayer 类
#### TransformerEncoderLayer:
######## 表示一个 Transformer 编码器层,包含多头注意力、前馈网络和归一化。
######## 编码器层的核心目标是通过注意力机制和非线性变换捕获输入序列的上下文信息。
class TransformerEncoderLayer(nn.Module):def __init__(self, config):super().__init__()# 层归一化(self.layer_norm_1 和 self.layer_norm_2):#### 对输入进行标准化,减小数值波动,提高模型收敛速度。#### 每次归一化后,数据均值为 0,标准差为 1。self.layer_norm_1 = nn.LayerNorm(config.hidden_size)self.layer_norm_2 = nn.LayerNorm(config.hidden_size)# 多头注意力机制(self.attention):#### 使用 MultiHeadAttention 模块来实现多头注意力。#### 通过多个注意力头并行处理输入,捕获不同特征模式。self.attention = MultiHeadAttention(config)# 前馈网络(self.feed_forward):#### 使用 FeedForward 模块实现两层线性变换和非线性激活。#### 进一步处理多头注意力的输出,增强模型的表达能力。self.feed_forward = FeedForward(config)def forward(self, x, mask=None):# 输入参数x:#### 输入张量,形状为 [batch_size, seq_length, hidden_size]。#### 这是从嵌入层或前一层 Transformer 编码器传递过来的特征。# 输入参数mask:#### 可选的掩码,用于屏蔽特定的查询-键对。#### 常用于处理填充位置(padding tokens),以防止它们影响注意力计算。# 第一层归一化:#### Apply layer normalization and then copy input into query, key, value#### 对输入 x 进行归一化,结果存储在 hidden_state 中。#### 归一化减少了输入的数值波动,帮助模型更稳定地训练。hidden_state = self.layer_norm_1(x)# 多头注意力机制:#### Apply attention with a skip connection#### 调用多头注意力机制:######## query = key = value = hidden_state(自注意力机制)。mask 用于屏蔽不相关的输入。#### 跳跃连接(Skip Connection):######## 将多头注意力的输出与原始输入 x 相加,增强信息流动。######## 形状保持为 [batch_size, seq_length, hidden_size]。x = x + self.attention(hidden_state, hidden_state, hidden_state, mask=mask)# Apply feed-forward layer with a skip connection# 第二层归一化:#### 对多头注意力的输出进行归一化。#### 调用前馈网络对归一化结果进行非线性变换。#### 跳跃连接:######## 将前馈网络的输出与多头注意力的结果相加。######## 形状保持为 [batch_size, seq_length, hidden_size]。x = x + self.feed_forward(self.layer_norm_2(x))return x# 这段代码实现了 Transformer 模型中的嵌入层(Embeddings Layer),
# 负责将输入的 token ID 转换为高维连续向量,并为每个 token 添加位置信息。
# 这是 Transformer 模型的第一层,为后续的多头注意力和前馈神经网络提供输入。
# Embeddings:
#### 嵌入层模块,包含 token 嵌入(token embeddings)、
#### 位置嵌入(position embeddings)、
#### 层归一化(LayerNorm)和 Dropout。
#### 目标是将离散的 token ID 转换为高维向量,并加上位置信息。
class Embeddings(nn.Module):def __init__(self, config):# vocab_size: 词汇表的大小(token ID 的取值范围)。# hidden_size: 嵌入的维度,Transformer 的特征维度。# max_position_embeddings: 支持的最大序列长度(用于位置嵌入)。super().__init__()# Token 嵌入(self.token_embeddings):#### 将离散的 token ID 映射到连续向量空间。#### 嵌入矩阵的形状为 [vocab_size, hidden_size]。#### 输入形状为 [batch_size, seq_length],输出形状为 [batch_size, seq_length, hidden_size]。 self.token_embeddings = nn.Embedding(config.vocab_size,config.hidden_size)# print("Embeddings中config.vocab_size的数量:")# print(config.vocab_size)# print("==================")# print("Embeddings中config.max_position_embeddings的数量:")# print(config.max_position_embeddings)# print("==================")# print("Embeddings中config.hidden_size的数量:")# print(config.hidden_size)# print("==================")# 位置嵌入(self.position_embeddings):#### 为每个序列位置生成位置信息的嵌入。#### 嵌入矩阵的形状为 [max_position_embeddings, hidden_size]。#### 用于表示序列中每个 token 的位置。self.position_embeddings = nn.Embedding(config.max_position_embeddings,config.hidden_size)# 层归一化(self.layer_norm):#### 对嵌入向量进行归一化,减小数值波动,提高训练稳定性。#### eps=1e-12 是一个小常数,用于避免除以零。self.layer_norm = nn.LayerNorm(config.hidden_size, eps=1e-12)self.dropout = nn.Dropout()# 输入的 token ID,形状为 [batch_size, seq_length]。# 每个值是一个整数,表示词汇表中的索引。def forward(self, input_ids):# 创建位置 ID:# Create position IDs for input sequence#### 获取序列长度 seq_length,生成位置 ID:seq_length = input_ids.size(1)#### torch.arange(seq_length) 生成 [0, 1, ..., seq_length-1]。#### unsqueeze(0) 扩展为 [1, seq_length],以适配批量处理。position_ids = torch.arange(seq_length, dtype=torch.long).unsqueeze(0)# 生成 token 嵌入:# Create token and position embeddings#### 输入 token ID,通过 self.token_embeddings 映射到嵌入向量。#### 输出形状为 [batch_size, seq_length, hidden_size]。token_embeddings = self.token_embeddings(input_ids)# 生成位置嵌入:#### 使用位置 ID 通过 self.position_embeddings 生成位置信息。#### 输出形状为 [1, seq_length, hidden_size]。position_embeddings = self.position_embeddings(position_ids)# 组合 token 和位置嵌入:# Combine token and position embeddings#### 将 token 嵌入和位置嵌入逐元素相加,结合语义信息和位置信息。#### 输出形状为 [batch_size, seq_length, hidden_size]。embeddings = token_embeddings + position_embeddings# 归一化和 Dropout:#### 对嵌入进行层归一化,确保数值稳定。#### 通过 Dropout 防止过拟合。embeddings = self.layer_norm(embeddings)embeddings = self.dropout(embeddings)return embeddings# 这段代码实现了一个完整的 Transformer 编码器(Transformer Encoder)。
# 这是 Transformer 模型中的核心模块之一,
# 结合了嵌入层(Embeddings)和多层编码器层(TransformerEncoderLayer),
# 用于处理输入序列并生成上下文相关的特征表示。
class TransformerEncoder(nn.Module):def __init__(self, config):# vocab_size: 词汇表大小。# hidden_size: 嵌入向量的维度,也是 Transformer 的特征维度。# max_position_embeddings: 最大序列长度。# num_hidden_layers: 编码器的层数。# 其他参数如 num_attention_heads、intermediate_size 等。super().__init__()self.embeddings = Embeddings(config)# 使用 nn.ModuleList 构建多个 TransformerEncoderLayer 实例。# config.num_hidden_layers 指定编码器层的数量。# 每个编码器层通过多头注意力机制和前馈网络对输入特征进行处理。self.layers = nn.ModuleList([TransformerEncoderLayer(config)for _ in range(config.num_hidden_layers)])# x:#### 输入的 token ID,形状为 [batch_size, seq_length]。#### 每个值是一个整数,表示词汇表中的索引。# mask:#### 可选的掩码,用于屏蔽序列中的特定位置(如填充 token)。#### mask 的形状为 [batch_size, seq_length, seq_length],在多头注意力计算中用于屏蔽无效的注意力分布。def forward(self, x, mask=None):# 调用 Embeddings 模块,将输入 token ID 转换为高维嵌入向量。# 同时添加位置嵌入,生成初始特征表示。# 输出形状为 [batch_size, seq_length, hidden_size],# 输出的应该是带有位置信息的初始特征。x = self.embeddings(x)# 遍历编码器层列表,依次调用每个 TransformerEncoderLayer。# 每个编码器层通过多头注意力机制和前馈网络对特征进行处理,提取更深层次的上下文信息。# 输入和输出形状在每一层保持一致,为 [batch_size, seq_length, hidden_size]。for layer in self.layers:x = layer(x, mask=mask)return x# 设置模型检查点
# model_ckpt:指定 Hugging Face 模型的名称或路径,这里是 bert-base-uncased。
# bert-base-uncased 是一个预训练的 BERT 模型,大小适中,分词器会将所有文本转换为小写(uncased)。
# 你也可以选择其他模型,如 bert-large-uncased 或 distilbert-base-uncased。
model_ckpt = "bert-base-uncased"
# 加载分词器
# AutoTokenizer.from_pretrained():根据 model_ckpt 加载与预训练模型对应的分词器。
# 分词器用于将输入的自然语言文本转换为模型可以处理的 token ID。
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)# 对文本进行分词和编码
# text:输入的文本数据。
text = "time flies like an arrow"
# 将输入文本转换为 token ID,返回一个 PyTorch 张量(return_tensors="pt")。
# add_special_tokens=False:不添加特殊 token(如 [CLS] 和 [SEP])。如果为 True,
# 分词器会自动在句首和句末添加这些特殊符号。
# 每个数字表示一个 token 的 ID,具体含义可通过 tokenizer.decode 转换回原始单词。
inputs = tokenizer(text, return_tensors="pt", add_special_tokens=False)
# AutoConfig.from_pretrained():
# 加载与 model_ckpt 对应的模型配置。
# config 包含模型的所有超参数(如隐藏层大小、词汇表大小、层数等)。
config = AutoConfig.from_pretrained(model_ckpt)encoder = TransformerEncoder(config)
print("encoder(inputs.input_ids)的形状:")
print(encoder(inputs.input_ids).size())
print("==================")
相关文章:
Transformers快速入门代码解析(六):注意力机制——Transformer Encoder:执行顺序解析
Transformer Encoder:执行顺序解析 引言执行顺序解析1. 设置模型检查点和分词器2. 输入预处理操作说明: 3. 加载模型配置configconfig 包含的主要参数常见配置(BERT-base) 4. 初始化 TransformerEncoder5. Transformer Encoder 的…...

图像小波去噪与总变分去噪详解与Python实现
目录 图像小波去噪与总变分去噪详解与实现1. 基础概念1.1 噪声类型及去噪问题定义1.2 小波去噪算法基础1.3 总变分去噪算法基础2. 小波去噪算法2.1 理论介绍2.2 Python实现及代码详解2.3 案例分析3. 总变分去噪算法3.1 理论介绍3.2 Python实现及代码详解3.3 案例分析4. 两种算法…...

【深度学习基础】预备知识 | 微积分
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...
)
CTF-PWN glibc源码阅读[1]: 寻找libc中堆结构的定义(2.31-0ubuntu9.16)
源代码在这里下载 来到malloc/malloc.c 在980行发现这段代码 // 定义最大 mmap 值为 -4 #define M_MMAP_MAX -4// 如果没有定义 DEFAULT_MMAP_MAX,则将其定义为 65536 #ifndef DEFAULT_MMAP_MAX #define DEFAULT_MMAP_MAX (65536) #endif// 引…...

宏集eXware物联网网关在水务管理系统上的应用
一、前言 水务管理系统涵盖了对城市水网、供水、排水、污水处理等多个环节的监控与管理。随着物联网(IoT)技术的快速发展,物联网网关逐渐成为水务管理系统中的关键组成部分。 宏集物联网网关以其高效的数据采集、传输和管理功能,…...

【大数据学习 | Spark-SQL】定义UDF和DUAF,UDTF函数
1. UDF函数(用户自定义函数) 一般指的是用户自己定义的单行函数。一进一出,函数接受的是一行中的一个或者多个字段值,返回一个值。比如MySQL中的,日期相关的dateDiff函数,字符串相关的substring函数。 先…...

#Java-JDK7、8的时间相关类,包装类
1. JDK7-Date类 我们先来看时间的相关知识点 世界标准时间: 格林尼治时间/格林威治时间(Greenwich Mean Time)简称GMT。目前世界标准时间(UTC)已经替换为:原子钟中国标准时间: 世界标准时间8小时 时间单位换算: 1秒1000毫秒 1毫秒1000微秒 1微秒1000纳秒 Date类 Date类…...

tc 命令
Windows Network Shaper目前只能在win10及以下版本使用,在github上有源码。 iperf 是一个网络性能测试工具,可以测试网络带宽和延迟。 webrtc M96版本的GCC sudo tc qdisc del dev eth1 root //关闭限速 sudo tc qdisc add dev eth1 root handle 1: ht…...
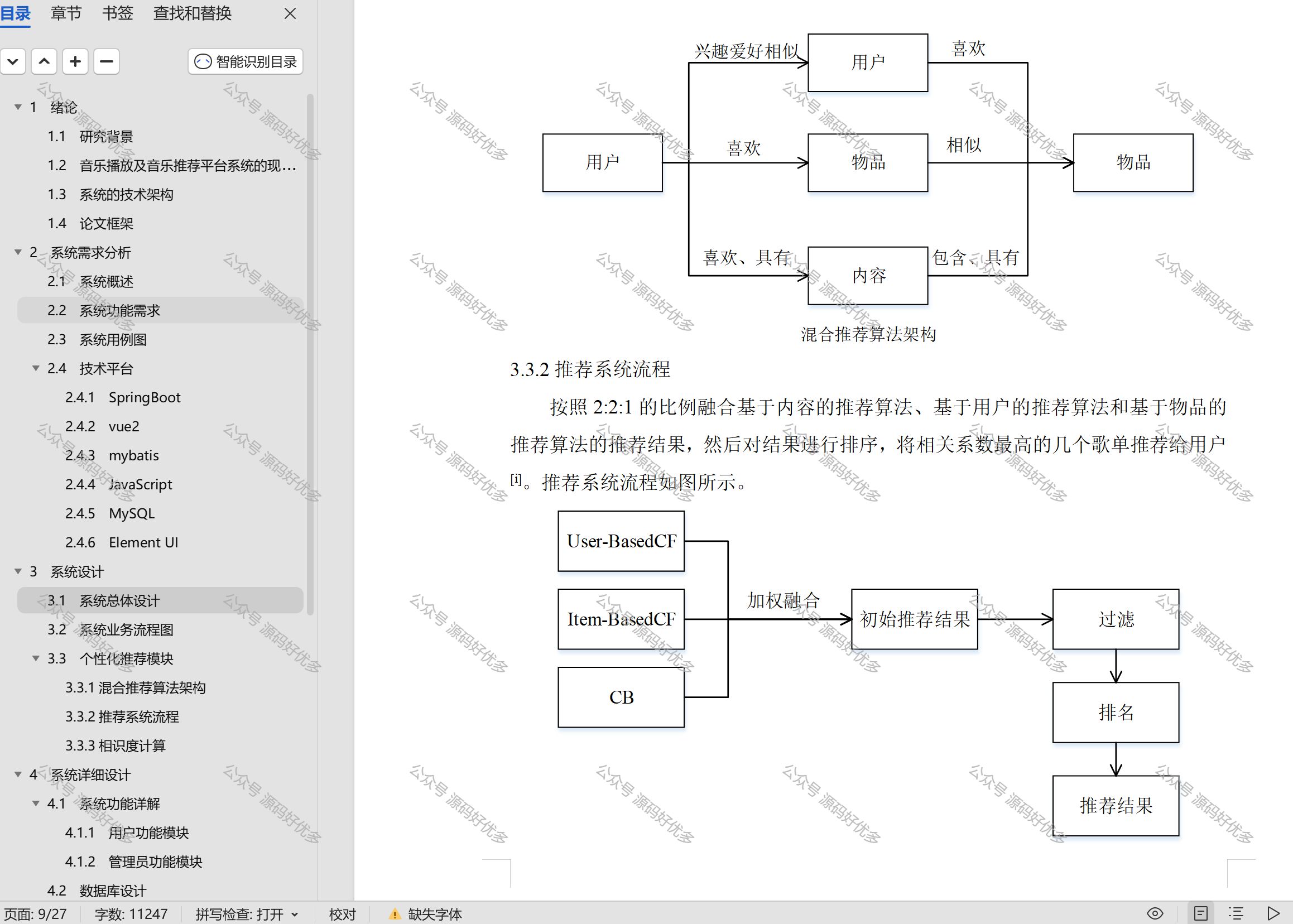
基于Java Springboot 协同过滤算法音乐推荐系统
一、作品包含 源码数据库设计文档万字全套环境和工具资源部署教程 二、项目技术 前端技术:Html、Css、Js、Vue2、Element-ui 数据库:MySQL 后端技术:Java、Spring Boot、MyBatis 三、运行环境 开发工具:IDEA 数据库&#x…...

MyBatis框架-关联映射
MyBatis关联映射-一对一 1.1 实体关系 实体–数据实体,实体关系指的就是数据与数据之间的关系 例如:订单和商品,用户和角色 实体关系分为以下四种: **一对一关联:**用户表和用户详情表 数据表关系: 主键关…...

Web开发技术栈选择指南
互联网时代的蓬勃发展,让越来越多人投身软件开发领域。面对前端和后端的选择,很多初学者往往陷入迷茫。让我们一起深入了解这两个领域的特点,帮助你做出最适合自己的选择。 在互联网发展的早期,前端开发主要负责页面布局和简单的…...

工具类的魔力:深入理解 Java 的 String、Math 和 Arrays
Java 提供了许多实用的工具类,帮助开发者简化代码,提升效率。这些工具类包含了各种常见的操作,比如字符串处理、数学计算、数组操作等。掌握这些工具类的高效使用方法,不仅能让你写出更简洁、优雅的代码,还能在性能上有…...

Linux下一次性关闭多个同名进程
要一次性关闭多个同名的 Python 进程,例如: 你可以使用以下几种方法。在执行这些操作之前,请务必确认这些进程确实是你希望终止的,以避免意外关闭其他重要的进程。 方法一:使用 pkill 命令 pkill 是一个用于根据名称…...

记录一些虚拟机桥接网络,windows网络遇到的小问题
1 virtual box 桥接的虚拟系统无 ipv4 地址 https://blog.csdn.net/qq_44847649/article/details/122582954 原因是 wlan 无线网卡没开共享给 virtual box host only (之前用过 vmware 也类似) 2 无法两台 windows10 物理机无法相互 ping 通 https://blog.csdn.net/qq_35…...

MATLAB —— 机械臂工作空间,可达性分析
系列文章目录 前言 本示例展示了如何使用可操作性指数对不同类型的机械手进行工作空间分析。工作空间分析是一种有用的工具,可用于确定机器人工作空间中最容易改变末端效应器位置和方向的区域。本示例的重点是利用不同的可操控性指数类型来分析各种机械手的工作空间。了解工作…...

18:(标准库)DMA二:DMA+串口收发数据
DMA串口收发数据 1、DMA串口发送数据2、DMA中断串口接收定长数据包3、串口空闲中断DMA接收不定长数据包4、串口空闲中断DMA接收不定长数据包DMA发送数据包 1、DMA串口发送数据 当串口的波特率大于115200时,可以通过DMA1进行数据搬运,以防止数据的丢失。如…...

【C++】 算术操作符与数据类型溢出详解
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C 文章目录 💯前言💯C 算术操作符详解基本算术操作符整数除法与取模行为类型转换在算术运算中的作用自增与自减操作符 💯数值溢出:当值超出类型范围时数据类型的取值范围…...

柔性芯片:实现万物互联的催化剂
物联网 (IoT) 市场已经非常成熟,麦肯锡预测,物联网将再创高峰,到 2030 年将达到 12.5 万亿美元的估值。然而,万物互联 (IoE) 的愿景尚未实现,即由数十亿台智能互联设备组成,提供大规模洞察和效率。 究竟是…...

FFmpeg 简介与编译
1. ffmpeg 简介: FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。采用LGPL或GPL许可证。它提供了录制、转换以及流化音视频的完整解决方案。它包含了非常先进的音频/视频编解码库libavcodec,为了保证高可移…...

低代码与微服务融合在医疗集团中的补充应用探究
摘要 本论文深入探讨了低代码与微服务融合在医疗系统集群中的应用。分析了其优势,包括提高开发效率、降低技术门槛、灵活适应需求变化和易于维护扩展等;阐述了面临的挑战,如数据安全与隐私保护、技术应用复杂性等;并展望了其在医…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...
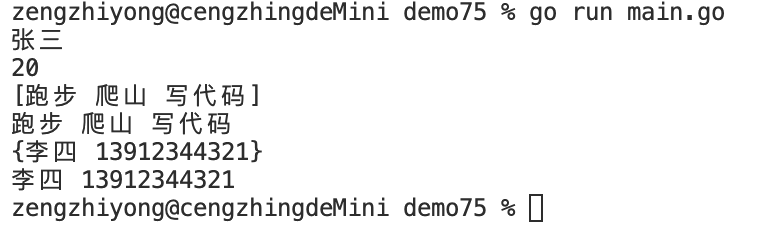
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...
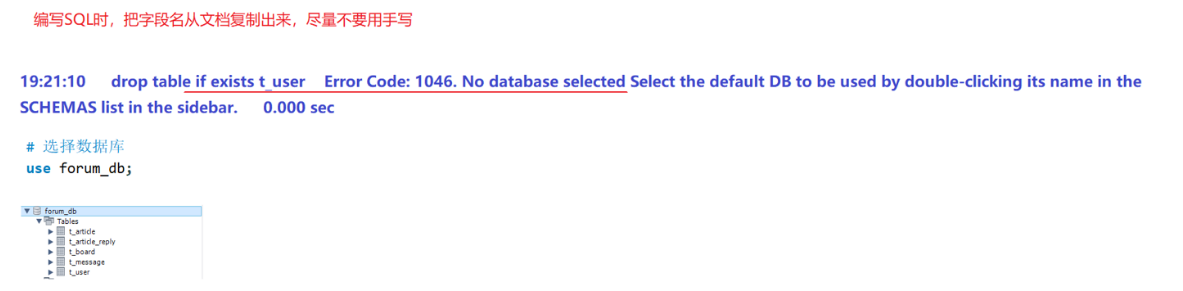
篇章二 论坛系统——系统设计
目录 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 1. 数据库设计 1.1 数据库名: forum db 1.2 表的设计 1.3 编写SQL 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 通过需求分析获得概念类并结合业务实现过程中的技术需要&#x…...