ELK(Elasticsearch + logstash + kibana + Filebeat + Kafka + Zookeeper)日志分析系统
文章目录
- 前言
- 架构
- 软件包下载
- 一、准备工作
- 1. Linux 网络设置
- 2. 配置hosts文件
- 3. 配置免密登录
- 4. 设置 NTP 时钟同步
- 5. 关闭防火墙
- 6. 关闭交换分区
- 7. 调整内存映射区域数限制
- 8. 调整文件、进程、内存资源限制
- 二、JDK 安装
- 1. 解压软件
- 2. 配置环境变量
- 3. 验证软件
- 三、安装 ElasticSearch 集群
- 1. 下载 elasticsearch 安装包
- 2. 创建用户
- 3. 创建日志文件夹
- 4. 解压并重命名
- 5. 创建ca证书
- 6. 设置节点 HTTP 证书
- 7. 修改配置文件
- 8. 启动 es 集群
- 9. 验证
- 查询节点状态
- 查看 ES 集群状态
- 查看 ES 中有哪些用户
- 四、安装 Kibana
- 1. 下载 Kibana 安装包
- 2. 解压并重命名
- 3. 给kibana 生成证书
- 4. ES为kibana创建用户
- 5. 修改配置文件
- 6. 启动 Kibana
- 7. 浏览器访问
- 五、安装 zookeeper 集群
- 1. 下载 zookeeper 安装包
- 2. 解压并重命名
- 3. 修改配置文件
- 4. 创建文件夹并指定myid文件
- 5. 拷贝文件到其他服务器
- 6. 启动 zookeeper
- 7. 配置 zookeeper 启动脚本
- 六、安装 kafka 集群
- 1. 下载安装包
- 2. 解压并重命名
- 3. 修改配置文件
- 4. 拷贝配置文件到其他服务器
- 5. 启动 kafka 集群
- 6. 验证
- 7. 配置 kafka 启动脚本
- 七、安装 Logstash
- 1. 下载 logstash 安装包
- 2. 解压并重命名
- 3. 新建日志文件夹
- 3. 修改配置文件
- 4. 启动 logstash
- 5. 验证
- 八、安装Filebeat
- 1. 下载 Filebeat 安装包
- 2. 解压并重命名
- 3. 修改配置文件
- 4. 启动 filebeat
- 5. 启动脚本
- 6. 验证
- 补充知识
- 1. docker 安装
前言
架构
| 主机名 | IP | 软件 |
|---|---|---|
| elk1 | 192.168.75.130 | elasticsearch、zookeeper、kafka、filebeat |
| elk2 | 192.168.75.131 | elasticsearch、zookeeper、kafka、filebeat |
| elk3 | 192.168.75.132 | elasticsearch、zookeeper、kafka、filebeat |
| elk4 | 192.168.75.133 | logstash、kibana |
整体流程:各个服务日志.log --> filebeat --> kafka --> logstash --> zokeeper --> kibana

每层实现的功能和含义分别介绍如下:
- 数据采集层:数据采集层位于最左边的业务服务器集群上,在每个业务服务器上面安装了fiebeat做日志收集,然后把采集到的原始日志发送到 Kafka+zookeeper 集群上。
- 消息队列层:原始日志发送到 Kafka+zookeeper 集群上后,会进行集中存储此时,filbeat 是消息的生产者,存储的消息可以随时被消费。
- 数据分析层:Logstash作为消费者,会去 Kafka+zookeeper 集群节点实时拉取原始日志然后将获取到的原始日志根据规则进行分析、清洗、过滤,最后将清洗好的日志转发至Elasticsearch焦群,
- 数据持久化存储:Elasticsearch焦群在接收到logstash发送过来的数据后,执行写磁盘,建索引库等操作,最后将结构化的数据存储到 Elasticsearch 集群。
- 数据查询、展示层:Kibana是一个可视化的数据展示平台,当有数据检索请求时,它从Elasticsearch集群上读取数据,然后进行可视化出图和多维度分析。
软件包下载
ES 官网:https://www.elastic.co
zookeeper官网:https://archive.apache.org/dist/zookeeper/
kafka 官网:https://kafka.apache.org/downloads.html
下载的软件上传到服务器的 /opt/software文件夹下。
一、准备工作
1. Linux 网络设置
查看 ip 命令:ip addr
[root@localhost ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
BOOTPROTO=static #修改
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=78085897-65c9-472d-831b-ebc34fb54667
DEVICE=ens33
ONBOOT=yes #修改
IPADDR=192.168.1.22 #修改
NETMASK=255.255.255.0 #修改
GATEWAY=192.168.1.1 #修改
DNS1=8.8.8.8 #修改[root@localhost ~]# cat /etc/resolv.conf
search localdomain
nameserver 127.0.0.1
nameserver 8.8.8.8
nameserver 114.114.114.114# 重启网络
service network restart
centos7 -bash: ifconfig: 未找到命令
执行命令:sudo yum install net-tools
在centos7中使用yum命令时候报错:
Loading mirror speeds from cached hostfile
Could not retrieve mirrorlist http://mirrorlist.centos.org/?release=7&arch=x86_64&repo=os&infra=stock error was
14: curl#6 - "Could not resolve host: mirrorlist.centos.org; 未知的错误"
问题原因:
出现这个错误是因为使用的 CentOS 7 仓库已经被归档,当前的镜像地址无法找到所需的文件。CentOS 7 的官方支持已经结束,部分仓库已被移至归档库。这导致了你的 yum 命令无法找到所需的元数据文件。CentOS 7 的官方仓库在 2024 年 6 月 30 日之后已经停止维护。因此,使用最新的 CentOS 7 官方仓库可能会遇到问题。
解决方法:
进入/etc/yum.repos.d目录下找到 CentOS-Base.repo
进入目录:cd /etc/yum.repos.d
cp CentOS-Base.repo CentOS-Base.repo.backup
vi CentOS-Base.repo
# CentOS-Base.repo
#
# The mirror system uses the connecting IP address of the client and the
# update status of each mirror to pick mirrors that are updated to and
# geographically close to the client. You should use this for CentOS updates
# unless you are manually picking other mirrors.
#
# If the mirrorlist= does not work for you, as a fall back you can try the
# remarked out baseurl= line instead.
#
#[base]
name=CentOS-$releasever - Base
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=os&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/os/$basearch/
#baseurl=http://vault.centos.org/7.9.2009/x86_64/os/
baseurl=http://vault.centos.org/7.9.2009/os/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7#released updates
[updates]
name=CentOS-$releasever - Updates
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=updates&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/updates/$basearch/
#baseurl=http://vault.centos.org/7.9.2009/x86_64/os/
baseurl=http://vault.centos.org/7.9.2009/updates/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7#additional packages that may be useful
[extras]
name=CentOS-$releasever - Extras
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=extras&infra=$infra
#$baseurl=http://mirror.centos.org/centos/$releasever/extras/$basearch/
#baseurl=http://vault.centos.org/7.9.2009/x86_64/os/
baseurl=http://vault.centos.org/7.9.2009/extras/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7#additional packages that extend functionality of existing packages
[centosplus]
name=CentOS-$releasever - Plus
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=centosplus&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/centosplus/$basearch/
#baseurl=http://vault.centos.org/7.9.2009/x86_64/os/
baseurl=http://vault.centos.org/7.9.2009/centosplus/$basearch/
gpgcheck=1
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
sudo yum clean all
sudo yum makecache
参考:https://www.cnblogs.com/kohler21/p/18331060
2. 配置hosts文件
# 修改主机名称
vi/etc/hostname# 设置域名
vi /etc/hosts# 配置内容
190.168.75.130 elk1
190.168.75.131 elk2
190.168.75.132 elk3
190.168.75.133 elk4
3. 配置免密登录
# 生成密钥对
[root@elk1 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:HN6G18wMYBmiGHqpablW7Hy4wyVx2u6wpSJEgLhV3Fs root@elk1
The key's randomart image is:
+---[RSA 2048]----+
|o .o... +o |
|+..+...oE. |
|oo+ . o. . |
|.=o. ..o + * |
|+o o= S + = |
|..=o.o o |
|.o.=+o |
|o. oB. |
|. .+o. |
+----[SHA256]-----+# 发送公钥
ssh-copy-id -i /root/.ssh/id_rsa.pub root@elk2
ssh-copy-id -i /root/.ssh/id_rsa.pub root@elk3
scp:用于将文件或者目录从一个Linux系统拷贝到另一个Linux系统下。scp传输数据用的是SSH协议,保证了数据传输的安全。
scp 本地Linux系统文件路径 远程用户名@IP地址:远程系统文件绝对路径名举例:
scp -r /opt/module/ root@192.168.75.131:/opt/
注意:这里的 .ssh 不是一个文件。
scp适用于简单的小规模文件传输;rsync适用于高效的文件同步和增量备份;
# scp、 拷贝完全相同
scp -r /opt/software/ root@elk2:/opt/
# rsync、拷贝有差异的文件
rsync -rvl /opt/software/a.txt root@elk2:/opt/software/a.txt
4. 设置 NTP 时钟同步
# 安装ntpdate
yum -y install ntpdate# 同步时钟
ntpdate ntp.aliyun.com# 配置时钟同步定时任务
echo "*/5 * * * * ntpdate ntp.aliyun.com > /dev/null 2>&1" > /var/spool/cron/root
5. 关闭防火墙
# 查看虚拟机防火墙状态
systemctl status firewalld# 如何关闭防火墙
systemctl stop firewalld# 禁止firewall开机启动
systemctl disable firewalld.service# 将SELinux设置为宽容模式
setenforce 0
6. 关闭交换分区
# 临时生效
swapoff -a# 永久生效
vi /etc/fstab
# swap 相关的行
7. 调整内存映射区域数限制
rm -rf /etc/sysctl.d/99-sysctl.confvi /etc/sysctl.conf# 在文件中增加下面内容:
# 一个进程可以拥有的 VMA(虚拟内存区域)的数量,默认值为 65536
vm.max_map_count=262144# 重新加载
sysctl -p
8. 调整文件、进程、内存资源限制
vi /etc/security/limits.conf# 文件最后添加以下内容:
* soft nofile 65535
* hard nofile 65535
* soft nproc 10240
* hard nproc 10240
* soft memlock unlimited
* hard memlock unlimited# 注: * 带表 Linux 所有用户名称
二、JDK 安装
官网下载地址:https://www.oracle.com/java/technologies/downloads/archive/
# 查看系统版本
[root@hadoop1 yum.repos.d]# uname -a
Linux hadoop1 3.10.0-1127.el7.x86_64 #1 SMP Tue Mar 31 23:36:51 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
# 查询系统位数(32位或64位)
[root@hadoop1 yum.repos.d]# getconf LONG_BIT
64
说明:要判断Cent0S系统是x64还是ARM架构,可以使用命令行工具lscpu1、uname-m或arch_linux2、或者直接输入命令uname-a34。如果lscpu命令的"Architecture”字段的值为”x86_64”,则表示系统是x64架构;如果值为"armv7l"、“aarch64"或类似的ARM架构标识,则表示系统是ARM架构1。如果uname-m或arch_linux命令的输出是”x86 64”,则表示系统是x64架构;如果输出是"armv7l"或以"arm"开头的其他值,则表示系统是ARM架构23。如果uname-a命令的输出中包含关键词“x86_64",则表示系统是x64架构;如果显示的是“aarch64,则表示系统是ARM架构34。
1. 解压软件
tar -zxvf jdk-8u421-linux-x64.tar -C /usr/java/
2. 配置环境变量
vi /etc/profile# 文件尾部编辑,添加下面内容
# 配置jdk的按照目录JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_421
# 配置CLASSPATH环境变量(可以不配置)
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# 配置环境变量PATH
export PATH=$JAVA_HOME/bin:$PATH
3. 验证软件
# 执行以下命令使修改生效
source /etc/profile# 验证安装
[root@elk3 ~]# java -version
java version "1.8.0_421"
Java(TM) SE Runtime Environment (build 1.8.0_421-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.421-b09, mixed mode)
三、安装 ElasticSearch 集群
需要在 elk1、elk2、elk3 三台机器都装 ES。
1. 下载 elasticsearch 安装包
cd /opt/software
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.14.0-linux-x86_64.tar.gz
2. 创建用户
# 创建用户
useradd elastic# 为用户设置密码(elastic)
passwd elastic
3. 创建日志文件夹
# 创建目录并授权
mkdir -p /data/elasticsearch
mkdir -p /logs/elasticsearchchown -R elastic:elastic /data/elasticsearch
chown -R elastic:elastic /logs/elasticsearch
4. 解压并重命名
mkdir -p /opt/moduletar -zxvf elasticsearch-8.14.0-linux-x86_64.tar.gz -C /opt/module/cd /opt/module/mv elasticsearch-8.14.0/ elasticsearch# 文件夹所有者
chown -R elastic:elastic /opt/module/elasticsearchsu - elastic
5. 创建ca证书
注意:
- 这里的证书只需要在 elk1 节点上生成,剩下的机器将文件拷贝过去即可。
- 这里我们没有设置ca的密码,如果设置了后面在配置文件需要加上。
- 一定要在 elastic 用户下执行创建证书命令。
cd /opt/module/elasticsearch/# 签发 ca 证书,过程中需按两次回车键
./bin/elasticsearch-certutil ca
# 用 ca 证书签发节点证书,过程中需按三次回车键
./bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12# 将生成的文件移动到 config/certs 中
mkdir /opt/module/elasticsearch/config/certs
mv elastic-certificates.p12 elastic-stack-ca.p12 ./config/certs/
6. 设置节点 HTTP 证书
[elastic@elk1 elasticsearch]$ ./bin/elasticsearch-certutil http
warning: ignoring JAVA_HOME=/usr/java/jdk1.8.0_421; using bundled JDK## Elasticsearch HTTP Certificate UtilityThe 'http' command guides you through the process of generating certificates
for use on the HTTP (Rest) interface for Elasticsearch.This tool will ask you a number of questions in order to generate the right
set of files for your needs.## Do you wish to generate a Certificate Signing Request (CSR)?A CSR is used when you want your certificate to be created by an existing
Certificate Authority (CA) that you do not control (that is, you don't have
access to the keys for that CA). If you are in a corporate environment with a central security team, then you
may have an existing Corporate CA that can generate your certificate for you.
Infrastructure within your organisation may already be configured to trust this
CA, so it may be easier for clients to connect to Elasticsearch if you use a
CSR and send that request to the team that controls your CA.If you choose not to generate a CSR, this tool will generate a new certificate
for you. That certificate will be signed by a CA under your control. This is a
quick and easy way to secure your cluster with TLS, but you will need to
configure all your clients to trust that custom CA.# 当询问你是否要生成 CSR 时,输入 n。
Generate a CSR? [y/N]n## Do you have an existing Certificate Authority (CA) key-pair that you wish to use to sign your certificate?If you have an existing CA certificate and key, then you can use that CA to
sign your new http certificate. This allows you to use the same CA across
multiple Elasticsearch clusters which can make it easier to configure clients,
and may be easier for you to manage.If you do not have an existing CA, one will be generated for you.# 当询问你是否要使用现有 CA 时,输入 y。
Use an existing CA? [y/N]y## What is the path to your CA?Please enter the full pathname to the Certificate Authority that you wish to
use for signing your new http certificate. This can be in PKCS#12 (.p12), JKS
(.jks) or PEM (.crt, .key, .pem) format.
# 输入新 CA 证书的绝对路径,例如 ca.crt 文件的路径。
CA Path: certs/elastic-stack-ca.p12
Reading a PKCS12 keystore requires a password.
It is possible for the keystore's password to be blank,
in which case you can simply press <ENTER> at the prompt
# 设置证书密码
Password for elastic-stack-ca.p12:## How long should your certificates be valid?Every certificate has an expiry date. When the expiry date is reached clients
will stop trusting your certificate and TLS connections will fail.Best practice suggests that you should either:
(a) set this to a short duration (90 - 120 days) and have automatic processes
to generate a new certificate before the old one expires, or
(b) set it to a longer duration (3 - 5 years) and then perform a manual update
a few months before it expires.You may enter the validity period in years (e.g. 3Y), months (e.g. 18M), or days (e.g. 90D)# 输入证书的到期值。你可以输入年、月或日的有效期。例如,输入 5y 表示一年。
For how long should your certificate be valid? [5y] 5y## Do you wish to generate one certificate per node?If you have multiple nodes in your cluster, then you may choose to generate a
separate certificate for each of these nodes. Each certificate will have its
own private key, and will be issued for a specific hostname or IP address.Alternatively, you may wish to generate a single certificate that is valid
across all the hostnames or addresses in your cluster.If all of your nodes will be accessed through a single domain
(e.g. node01.es.example.com, node02.es.example.com, etc) then you may find it
simpler to generate one certificate with a wildcard hostname (*.es.example.com)
and use that across all of your nodes.However, if you do not have a common domain name, and you expect to add
additional nodes to your cluster in the future, then you should generate a
certificate per node so that you can more easily generate new certificates when
you provision new nodes.# 当询问你是否要为每个节点生成一个证书时,输入 n。
Generate a certificate per node? [y/N]n## Which hostnames will be used to connect to your nodes?
# 每个证书都有自己的私钥,并针对特定的主机名或IP 地址颁发。These hostnames will be added as "DNS" names in the "Subject Alternative Name"
(SAN) field in your certificate.You should list every hostname and variant that people will use to connect to
your cluster over http.
Do not list IP addresses here, you will be asked to enter them later.If you wish to use a wildcard certificate (for example *.es.example.com) you
can enter that here.Enter all the hostnames that you need, one per line.
When you are done, press <ENTER> once more to move on to the next step.# 出现提示时,输入集群中第一个节点的名称。使用与 elasticsearch.yml 文件中 node.name 参数的值相同的节点名称。
elk1
elk2
elk3You entered the following hostnames.- elk1- elk2- elk3Is this correct [Y/n]y## Which IP addresses will be used to connect to your nodes?If your clients will ever connect to your nodes by numeric IP address, then you
can list these as valid IP "Subject Alternative Name" (SAN) fields in your
certificate.If you do not have fixed IP addresses, or not wish to support direct IP access
to your cluster then you can just press <ENTER> to skip this step.Enter all the IP addresses that you need, one per line.
When you are done, press <ENTER> once more to move on to the next step.# 输入用于连接到你的第一个节点的所有主机名。这些主机名将作为 DNS 名称添加到证书的主题备用名称 (SAN) 字段中。
192.168.75.130
192.168.75.131
192.168.75.132You entered the following IP addresses.- 192.168.75.130- 192.168.75.131- 192.168.75.132Is this correct [Y/n]y## Other certificate optionsThe generated certificate will have the following additional configuration
values. These values have been selected based on a combination of the
information you have provided above and secure defaults. You should not need to
change these values unless you have specific requirements.Key Name: elk1
Subject DN: CN=elk1
Key Size: 2048# 您想更改这些选项中的任何一个吗
Do you wish to change any of these options? [y/N]n## What password do you want for your private key(s)?Your private key(s) will be stored in a PKCS#12 keystore file named "http.p12".
This type of keystore is always password protected, but it is possible to use a
blank password.If you wish to use a blank password, simply press <enter> at the prompt below.
# 设置http证书密码
Provide a password for the "http.p12" file: [<ENTER> for none]## Where should we save the generated files?A number of files will be generated including your private key(s),
public certificate(s), and sample configuration options for Elastic Stack products.These files will be included in a single zip archive.# 输出zip文件应该使用什么文件名?
What filename should be used for the output zip file? [/opt/module/elasticsearch/elasticsearch-ssl-http.zip] Zip file written to /opt/module/elasticsearch/elasticsearch-ssl-http.zi
# 安装 unzip 软件
sudo yum install unzip# 解压刚刚生成的zip包
unzip elasticsearch-ssl-http.zip
# 将解压后的证书文件移动到config/certs 目录中
mv elasticsearch/http.p12 kibana/elasticsearch-ca.pem config/certs
7. 修改配置文件
# 虚拟机占用大小
vi jvm.options# 修改内容,默认是4g
-Xms2g
-Xmx2g
cd /opt/module/elasticsearch/config
cp elasticsearch.yml elasticsearch.yml.bak
vi elasticsearch.yml
- 修改内容如下:
# 集群名称
cluster.name: elk-elasticsearch# 节点名称(每个节点需唯一)
node.name: elk1 # 其他节点分别命名为 elk2、elk3# 数据和日志路径
path.data: /data/elasticsearch
path.logs: /logs/elasticsearch# 锁定物理内存地址,防止es内存被交换出去,也就是避免es使用swap交换分区,频繁的交换,会导致IOPS变高
bootstrap.memory_lock: true# 网络设置
network.host: 192.168.75.130 # 配置为当前elasticsearch节点主机的ip# 端口
http.port: 9200# head 插件需要这打开这两个配置(新增)
transport.port: 9300
http.cors.enabled: true
http.cors.allow-origin: /.*/# 集群节点发现(9300为默认的集群通信端口)
discovery.seed_hosts: ["192.168.75.130:9300", "192.168.75.131:9300", "192.168.75.132:9300"]# 初始主节点(第一次启动指定)
cluster.initial_master_nodes: ["elk1"]# SSL权限认证(新增)
xpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /opt/module/elasticsearch/config/certs/elastic-certificates.p12
#xpack.security.transport.ssl.keystore.password: your-password
xpack.security.transport.ssl.truststore.path: /opt/module/elasticsearch/config/certs/elastic-certificates.p12
#xpack.security.transport.ssl.truststore.password: your-password# https方式访问 ES(新增)
xpack.security.http.ssl.enabled: true
xpack.security.http.ssl.keystore.path: /opt/module/elasticsearch/config/certs/http.p12
#xpack.security.http.ssl.keystore.password: your-password
xpack.security.http.ssl.truststore.path: /opt/module/elasticsearch/config/certs/http.p12
#xpack.security.http.ssl.truststore.password: your-passwordhttp.host: [_local_, _site_]
ingest.geoip.downloader.enabled: false
# 客户端证书验证,默认就是none
xpack.security.http.ssl.client_authentication: none
注意:修改每个配置文件的 节点名称、ip 地址。节点名称为集群节点的唯一标识,不能重复,可以不配置,elasticsearch也可以自动生成;
# 这里是我们不设置https协议时执行的命令
# 这里需要为4个用户分别设置密码,elastic, kibana, logstash_system,beats_system。(interactive 手动设置, auto 自动生成密码)
# ./bin/elasticsearch-setup-passwords interactive# 如果执行上面命令报错,需要删除.security-7索引文件
# curl -XDELETE 127.0.0.1:9200/.security-7
8. 启动 es 集群
cd /opt/module/elasticsearch
# 启动
./bin/elasticsearch
# 后台启动
./bin/elasticsearch -d
- 查看日志显示用户名和密码
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
✅ Elasticsearch security features have been automatically configured!
✅ Authentication is enabled and cluster connections are encrypted.ℹ️ Password for the elastic user (reset with `bin/elasticsearch-reset-password -u elastic`):xpMY4LD2-xbhm5yKb3WS
# 解释: 系统为 elastic 用户生成了一个随机密码。你可以使用这个密码进行登录和管理。
# 如果需要重置密码,可以使用 `bin/elasticsearch-reset-password -u elastic` 命令。❌ Unable to generate an enrollment token for Kibana instances, try invoking `bin/elasticsearch-create-enrollment-token -s kibana`.
# 解释: 使用命令 `bin/elasticsearch-create-enrollment-token -s node` 创建一个节点注册令牌。❌ An enrollment token to enroll new nodes wasn't generated. To add nodes and enroll them into this cluster:
• On this node:⁃ Create an enrollment token with `bin/elasticsearch-create-enrollment-token -s node`.⁃ Restart Elasticsearch.
• On other nodes:⁃ Start Elasticsearch with `bin/elasticsearch --enrollment-token <token>`, using the enrollment token that you generated.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━9. 验证
# 查看是否启动
netstat -tnulp | grep 9200 # 根据端口查看# 查看集群内部通信
netstat -anpl | grep 9300
查询节点状态
浏览器中输入地址:https://192.168.75.130:9200/

查看 ES 集群状态
浏览器中输入地址:https://192.168.75.130:9200/_cat/nodes

查看 ES 中有哪些用户
浏览器中输入地址:https://192.168.75.130:9200/_security/user
启动报错:
ERROR: [1] bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch.
bootstrap check failure [1] of [1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
ERROR: Elasticsearch did not exit normally - check the logs at /logs/elasticsearch/ycyh-elasticsearch.log
解决方案参考:https://blog.csdn.net/qq_21348527/article/details/114822914
四、安装 Kibana
只需要在 elk4 机器上装。
1. 下载 Kibana 安装包
cd /opt/software
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.14.0-linux-x86_64.tar.gz
2. 解压并重命名
tar -zxvf kibana-8.14.0-linux-x86_64.tar.gz -C /opt/module/
cd /opt/module/
mv kibana-8.14.0/ kibana
chown -R elastic:elastic /opt/module/kibana/
# 创建日志文件夹
mkdir -p /logs/kibana/
chown -R elastic:elastic /logs/kibana/
# 切换用户
su - elastic
3. 给kibana 生成证书
# 在 es 服务器生成证书,输入回车即可
cd /opt/module/zookeeper
./bin/elasticsearch-certutil csr -name kibana -dns elk1# 解压文件
unzip csr-bundle.zip# 将解压后的文件移动到 kibana 的config 目录下
cd kibana
mv kibana.csr kibana.key /opt/module/kibana/config/# 生成crt文件
cd /opt/module/kibana/config/
openssl x509 -req -in kibana.csr -signkey kibana.key -out kibana.crt
4. ES为kibana创建用户
cd /opt/module/zookeeper/
./bin/elasticsearch-reset-password -i -u kibana_system
#输入y 回车
5. 修改配置文件
cp kibana.yml kibana.yml.bakvi kibana.yml
- 修改内容如下:
# Kibana 后端服务器使用的端口。默认为 5601
server.port: 5601# Kibana 服务器绑定的地址
server.host: "elk4"# Kibana 服务器的名称,用于显示
server.name: "elk4"# Elasticsearch 服务器的 URL 列表
elasticsearch.hosts: ["https://192.168.75.130:9200","https://192.168.75.131:9200","https://192.168.75.132:9200"]# Elasticsearch 基本认证的用户名和密码
elasticsearch.username: "kibana_system"
elasticsearch.password: "1qaz2wsx"# 启用 SSL 并指定证书和密钥路径
server.ssl.enabled: true
server.ssl.certificate: /opt/module/kibana/config/kibana.crt
server.ssl.key: /opt/module/kibana/config/kibana.key# Elasticsearch 实例的 CA 证书路径
elasticsearch.ssl.certificateAuthorities: [ "/opt/module/elasticsearch/config/certs/elasticsearch-ca.pem" ]# SSL 证书验证模式
elasticsearch.ssl.verificationMode: none# Kibana 的语言环境设置
i18n.locale: "zh-CN"
其他参数说明参考官网:https://www.elastic.co/guide/cn/kibana/current/settings.html
6. 启动 Kibana
注意:Kibana不建议使用root用户直接运行,如使用root,需加上–allow-root。建议新建普通用户,使用普通用户运行。
cd /opt/module/kibana
# 启动
./bin/kibana
# 后台启动
nohup ./bin/kibana &# 停止kibana
netstat -tunlp|grep 5601
kill -9 111235
启动报错官网说明:

从 7.17.13 开始,Kibana 已将其运行时环境 Node.js 从版本 16 升级到版本 18,并将 OpenSSL 的底层版本升级到版本 3。被 OpenSSL 3 视为遗留的算法已重新启用,以避免在 Kibana 的次要版本中发生潜在的重大更改。如果为 Kibana 配置的 SSL 证书未使用 OpenSSL 旧版提供程序文档中提到的任何旧版算法,我们建议通过删除 node.options 配置文件中的 --openssl-legacy-provider 来禁用此设置。
7. 浏览器访问
https://192.168.75.130:5601 登录 Kibana,单击“Create Index Pattern ”按钮添加名称 “elk-collect-logs”,索引“collect-logs-*”,单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。

五、安装 zookeeper 集群
需要在 elk1、elk2、elk3 三台机器都装 ES。
1. 下载 zookeeper 安装包
cd /opt/software
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
2. 解压并重命名
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
mv apache-zookeeper-3.5.7-bin/ zookeeper
chown -R elastic:elastic /opt/module/zookeeper/
3. 修改配置文件
su - elastic
cd /opt/module/zookeeper/conf
cp zoo_sample.cfg zoo.cfgvim zoo.cfg
- 修改内容
tickTime=2000 #通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10 #Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5 #Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/opt/module/zookeeper/data #修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/opt/module/zookeeper/logs #添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连接端口#添加集群信息
server.1=192.168.75.130:3188:3288
server.2=192.168.75.131:3188:3288
server.3=192.168.75.132:3188:3288
server.A=B:C:D 说明:
- A是一个数字,表示这个是第几号服务器。集群模式下需要在zoo.cfg中dataDir指定的目录下创建一个文件myid,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
- B是这个服务器的地址。
- C是这个服务器Follower与集群中的Leader服务器交换信息的端口。
- D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
4. 创建文件夹并指定myid文件
# 在每个节点上创建数据目录和日志目录
mkdir /opt/module/zookeeper/data
mkdir /opt/module/zookeeper/logs
分别在每台机器的 dataDir 指定的目录下创建一个 myid 的文件
[root@elk1 ~]# echo 1 > /opt/module/zookeeper/data/myid[root@elk2 ~]# echo 2 > /opt/module/zookeeper/data/myid[root@elk3 ~]# echo 3 > /opt/module/zookeeper/data/myid
5. 拷贝文件到其他服务器
scp -r /opt/module/zookeeper/conf/zoo.cfg root@192.168.75.131:/opt/module/zookeeper/conf/zoo.cfg
scp -r /opt/module/zookeeper/conf/zoo.cfg root@192.168.75.132:/opt/module/zookeeper/conf/zoo.cfg
6. 启动 zookeeper
cd /opt/module/zookeeper
# 启动
./bin/zkServer.sh start# 停止
./bin/zkServer.sh stop# 查看服务状态
./bin/zkServer.sh status# 后台启动
nohup ./zkServer.sh start >> /logs/zookeeper.file 2>&1 &# 连接zk服务端
./bin/zkCli.sh
7. 配置 zookeeper 启动脚本
cd /usr/local/bin# 创建文件
vi zookeeper.sh# 添加执行权限
chmod 777 zookeeper.sh
#!/bin/shcase $1 in
"start"){for i in elk1 elk2 elk3doecho "********$i --> zkServer.sh start **********"ssh $i 'source /etc/profile; /opt/module/zookeeper/bin/zkServer.sh start;exit'done
};;
"stop"){for i in elk1 elk2 elk3doecho "********$i --> zkServer.sh stop **********"ssh $i 'source /etc/profile; /opt/module/zookeeper/bin/zkServer.sh stop;exit'done
};;
"status"){for i in elk1 elk2 elk3doecho "********$i --> zkServer.sh status **********"ssh $i 'source /etc/profile; /opt/module/zookeeper/bin/zkServer.sh status;exit'done
};;
"restart"){for i in elk1 elk2 elk3doecho "********$i --> zkServer.sh restart **********"ssh $i 'source /etc/profile; /opt/module/zookeeper/bin/zkServer.sh restart;exit'done
};;
esac
# 可在任何位置执行该脚本
zookeeper.sh start# 查看启动状态
zookeeper.sh status
六、安装 kafka 集群
需要在 elk1、elk2、elk3 三台机器都装 ES。
1. 下载安装包
cd /opt/software
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz
2. 解压并重命名
tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
cd /opt/module
mv kafka_2.12-3.0.0/ kafka/
mkdir /opt/module/kafka/logs
chown -R elastic:elastic /opt/module/kafka/
3. 修改配置文件
su - elastic
cd /opt/module/kafka/config
cp server.properties server.properties.bak
vi server.properties
- 修改内容如下:
# 21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2 ------修改
broker.id=1
# 31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
listeners=PLAINTEXT://192.168.75.130:9092
# 42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.network.threads=3
# 45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
num.io.threads=8
# 48行,发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
# 51行,接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
# 54行,请求套接字的缓冲区大小
socket.request.max.bytes=104857600
# 60行,kafka运行日志存放的路径,也是数据存放的路径 ------修改
log.dirs=/opt/module/kafka/logs
# 65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.partitions=1
# 69行,用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
# 103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.retention.hours=168
# 110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
log.segment.bytes=1073741824
# 123行,配置连接Zookeeper集群地址 ------修改
zookeeper.connect=192.168.75.130:2181,192.168.75.131:2181,192.168.75.132:2181
# 连接zookeeper超时时间
zookeeper.connection.timeout.ms=1800
4. 拷贝配置文件到其他服务器
scp server.properties root@elk2:`pwd`
scp server.properties root@elk3:`pwd`
注意:要修改配置文件中 broker.id 参数不相同。
5. 启动 kafka 集群
cd /opt/module/kafka
nohup ./bin/kafka-server-start.sh ./ config/server.properties > kafka.log 2>&1 &
特别注意:一定要先启动 ZooKeeper 再启动Kafka 顺序不可以改变。 先关闭kafka ,再关闭zookeeper。
6. 验证
jps# 查看 ZK 中是否注册成功
cd /opt/module/zookeeper/bin/
./zkCli.sh -server elk1:2181
ls /brokers
ls /brokers/ids
get ls /brokers/ids/1# 创建topic
cd /opt/module/kafka/
./bin/kafka-topics.sh --create --bootstrap-server 192.168.75.130:9092,192.168.75.131:9092,192.168.75.132:9092 --replication-factor 1 --partitions 1 --topic test
# 查看所有topic
./bin/kafka-topics.sh --list --bootstrap-server 192.168.75.130:9092,192.168.75.131:9092,192.168.75.132:9092
7. 配置 kafka 启动脚本
cd /usr/local/bin# 创建文件
vi kafka.sh# 添加执行权限
chmod 777 kafka.sh
#!/bin/shcase $1 in
"start"){for i in elk1 elk2 elk3doecho "******** $i --> kafka-server-start.sh **********"ssh $i 'source /etc/profile; /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties'done
};;
"stop"){for i in elk1 elk2 elk3doecho "******** $i --> kafka-server-stop.sh **********"ssh $i 'source /etc/profile; /opt/module/kafka/bin/kafka-server-stop.sh /opt/module/kafka/config/server.properties;exit'done
};;
esac
# 可在任何位置执行该脚本
kafka.sh start# 停止kafka
kafka.sh stop
七、安装 Logstash
只需要在 elk4 机器上装。
官网输入插件:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
1. 下载 logstash 安装包
cd /opt/software
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.17.24-linux-x86_64.tar.gz
2. 解压并重命名
tar -zxvf logstash-8.14.0-linux-x86_64.tar.gz -C /opt/module/
cd /opt/module/
mv logstash-8.14.0/ logstash
chown -R elastic:elastic /opt/module/logstash/
3. 新建日志文件夹
mkdir /logs/logstash
mkdir /data/logstash
chown -R elastic:elastic /logs/logstash
chown -R elastic:elastic /data/logstash
3. 修改配置文件
su - elastic
cd /opt/module/logstash/config
cp logstash.yml logstash.yml.bakvi logstash.yml
- 修改内容如下
# 节点名称,在进群中具备唯一性
node.name: elk4
# logstash及其插件所使用的数据路径
path.data: /data/logstash
# 管道id
#pipeline.id: main
# 输入、输出及过滤器的总工作数量
pipeline.workers: 4
# 使用分层表单来设置管道的批处理大小
pipeline.batch.size: 125
# 管道的批处理延迟
pipeline.batch.delay: 50
# 设置为true时,在强制关机logstash期间,即使内存还有事件,也会强制关闭导致数据丢失,默认为false,在强制关闭logstash期间,将拒绝退出,直到所有在管道的事件被安全输出再关闭
#pipeline.unsafe_shutdown: false
# 设置为true时,将完全编译的配置显示为调试日志消息
#config.debug: true
# 度量标准rest端点的绑定地址
api.http.host: 192.168.75.132
# 端口
api.http.port: 9600-9700
# 用于事件缓冲的内部队列模式,可以指定内存memory或磁盘persisted,默认是内存
queue.type: persisted
# 启用持久队列时将存储数据文件的目录
path.queue: /data/logstash/queue
# 启用持久队列时使用的页面数据文件大小
queue.page_capacity: 128mb
# 队列的总容量
queue.max_bytes:1024mb
# 日志级别
log.level: info
# 日志目录位置
path.logs: /logs/logstash
配置文件详细说明:https://blog.51cto.com/u_16213667/9785165
- 新建文件
logstash.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.input {kafka {id => "input_kafka_node1"bootstrap_servers => ["192.168.75.130:9092,192.168.75.131:9092,192.168.75.132:9092"]topics => ["collect-logs"]# 拉取kafka指定topiccodec => json {charset => "UTF-8"}# 解析json格式的日志数据decorate_events => true# 传递给es的数据额外增加kafka的属性数据auto_offset_reset => "latest"# 拉取最近数据,earliest为从头开始拉取}
}output {stdout {codec => rubydebug}elasticsearch {hosts => ["https://192.168.75.130:9200","https://192.168.75.131:9200","https://192.168.75.132:9200"]index => "collect-logs-%{+YYYY.MM.dd}"user => "elastic"password => "xpMY4LD2-xbhm5yKb3WS"}
}
参数说明:https://blog.csdn.net/wangnan9279/article/details/79287820
4. 启动 logstash
# 简单测试启动
./logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'# 启动
cd /opt/module/logstash
nohup ./bin/logstash -f ./config/logstash.conf &
5. 验证
jps
八、安装Filebeat
需要在 elk1、elk2、elk3 三台机器都装 ES。
1. 下载 Filebeat 安装包
cd /opt/software
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.14.0-linux-x86_64.tar.gz
2. 解压并重命名
tar -zxvf filebeat-8.14.0-linux-x86_64.tar.gz -C /opt/module/
cd /opt/module
mv filebeat-8.14.0-linux-x86_64/ filebeat
3. 修改配置文件
cd /opt/module/filebeat
cp filebeat.yml filebeat.yml.bakvi filebeat.yml
- 修改内容如下:
filebeat.inputs:
- type: logid: elk1enabled: truepaths:- /opt/module/zookeeper/logs/zookeeper-root-server-elk1.out- /opt/module/kafka/logs/server.logtype: filestreamfilebeat.config.modules:path: ${path.config}/modules.d/*.ymlreload.enabled: falsesetup.template.setttings:index.number_of_shards: 1# 将 Elasticsearch Output 下的注释掉,因为我们连接的是kafka# 并添加下面代码
# ---------------------------- Elasticsearch Output ----------------------------
output.kafka:enabled: truehosts: ["192.168.75.130:9092","192.168.75.131:9092","192.168.75.132:9092"]topic: collect-logspartition.round_robin:reachable_only: falserequired_acks: 1compression: gzipmax_message_bytes: 1000000
4. 启动 filebeat
cd /opt/module/filebeat
nohup ./filebeat -e -c filebeat.yml &
5. 启动脚本
- startup.sh
#!/bin/bash
echo "start filebeat......"
nohup /opt/module/filebeat/filebeat -e -c /opt/module/filebeat/filebeat.yml > /dev/null 2>&1 &sleep 2ps -ef | grep filebeat | grep -v grep
- shutdown.sh
#!/bin/bash
echo "shutdown filebeat......"
ps -ef | grep -v grep | grep filebeat | awk '{print $2}' | xargs kill -9
6. 验证
cd /opt/module/kafka/
# 查看所有topic
./bin/kafka-topics.sh --list --bootstrap-server 192.168.75.130:9092,192.168.75.131:9092,192.168.75.132:9092
# 消费 topic
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.75.130:9092,192.168.75.131:9092,192.168.75.132:9092 --topic collect-logs --from-beginning
补充知识
1. docker 安装
参考地址:https://blog.csdn.net/weixin_43755251/article/details/127512751
- 查看服务器内核版本
uname -r
注意:Docker要求CentOS系统的内核版本高于3.10
- 安装依赖包
yum install -y yum-utils device-mapper-persistent-data lvm2
- 设置阿里云docker-ce镜像源
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
- 安装docker
yum install -y docker-ce
- 启动并设置开机自启动
#启动docker命令
systemctl start docker
#设置开机自启命令
systemctl enable docker
#查看docker版本命令
docker version
- 配置阿里云加速器
#创建docker配置文件目录
mkdir -p /etc/docker#添加配置内容
tee /etc/docker/daemon.json <<-'EOF'{"registry-mirrors": ["https://docker.1panelproxy.com","https://2m11665s.mirror.aliyuncs.com","https://registry.docker-cn.com","https://dockerhub.azk8s.cn","https://docker.mirrors.ustc.edu.cn","http://hub-mirror.c.163.com","https://k8s.gcr.io","https://github-releases.githubusercontent.com","https://vsxcs7sq.mirror.aliyuncs.com","https://ustc-edu-cn.mirror.aliyuncs.com"]
}
EOF#重启docker
systemctl restart docker
- docker查用命令
# 搜索仓库镜像
docker search --镜像名
# 拉取镜像
docker pull --镜像名
# 查看目前正在运行的所有容器 (-a 显示包括已经停止的容器)
docker ps
# 删除镜像
docker rmi image_id/image_name
# 使用Dockerfile创建镜像
docker build
# 运行容器
docker run
# 进入容器中执行命令 (例如:docker exec -it container_id/container_name /bin/bash)
docker exec
# 查看容器日志(例如:docker logs -f -t --tail 10 container_id )
docker logs container_id/container_name
# 启动容器
docker start container_id/container_name
# 重启容器
docker restart container_id/container_name
# 停止容器
docker stop container_id/container_name
# 删除容器(只能删除已停止的容器)
docker rm container_id/container_name# 更多的命令可以通过docker help命令来查看。
以上是文章的全部内容。
如果有收获!希望老铁们来个三连,点赞、收藏、转发。
可以让更多的人看到这篇文章,顺便鼓励我写出更好的博客。
相关文章:
ELK(Elasticsearch + logstash + kibana + Filebeat + Kafka + Zookeeper)日志分析系统
文章目录 前言架构软件包下载 一、准备工作1. Linux 网络设置2. 配置hosts文件3. 配置免密登录4. 设置 NTP 时钟同步5. 关闭防火墙6. 关闭交换分区7. 调整内存映射区域数限制8. 调整文件、进程、内存资源限制 二、JDK 安装1. 解压软件2. 配置环境变量3. 验证软件 三、安装 Elas…...

07.ES11 08.ES12
7.1、Promise.allSettled 调用 allsettled 方法,返回的结果始终是成功的,返回的是promise结果值 <script>//声明两个promise对象const p1 new Promise((resolve, reject) > {setTimeout(() > {resolve("商品数据 - 1");}, 1000)…...

linux一键部署apache脚本
分享一下自己制作的一键部署apache脚本: 脚本已和当前文章绑定,请移步下载(免费!免费!免费!) (单纯的分享!) 步骤: 将文件/内容上传到终端中 …...

2022 年 6 月青少年软编等考 C 语言三级真题解析
目录 T1. 制作蛋糕思路分析T2. 找和最接近但不超过K的两个元素思路分析T3. 数根思路分析T4. 迷信的病人思路分析T5. 算 24思路分析T1. 制作蛋糕 小 A 擅长制作香蕉蛋糕和巧克力蛋糕。制作一个香蕉蛋糕需要 2 2 2 个单位的香蕉, 250 250 250 个单位的面粉, 75 75 75 个单位的…...

MySQL - Why Do We Need a Thread Pool? - mysql8.0
MySQL - Why Do We Need a Thread Pool? - mysql8.0 本文主要由于上次写的感觉又长又臭, 感觉学习方法有问题, 我们这次直接找来了 thread pool 的原文,一起来看看官方的开发者给出的blog – 感觉是个大神 但是好像不是最官方的 ,…...

Linux互斥量读写锁
一、互斥量 1.临界资源 同一时刻只允许一个进程/线程访问的共享资源(比如文件、外设打印机) 2.临界区 访问临界资源的代码 3.互斥机制 mutex互斥锁,用来避免临界资源的访问冲突,访问临界资源前申请互斥锁,访问完释放…...

网络安全之IP伪造
眼下非常多站点的涉及存在一些安全漏洞,黑客easy使用ip伪造、session劫持、xss攻击、session注入等手段危害站点安全。在纪录片《互联网之子》(建议搞IT的都要看下)中。亚伦斯沃茨(真实人物,神一般的存在)涉…...

ARM CCA机密计算安全模型之硬件强制安全
安全之安全(security)博客目录导读 [要求 R0004] Arm 强烈建议所有 CCA 实现都使用硬件强制的安全(CCA HES)。本文件其余部分假设系统启用了 CCA HES。 CCA HES 是一个可信子系统的租户——一个 CCA HES 主机(Host),见下图所示。它将以下监控安全域服务从应用处理元件(P…...

【论文笔记】A Token-level Contrastive Framework for Sign Language Translation
🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。 基本信息 标题: A Token-level Contrastiv…...

C#窗体简单登录
创建一个Windows登录程序,创建两个窗体,一个用来登录,一个为欢迎窗体,要求输入用户名和密码(以个人的姓名和学号分别作为用户名和密码),点击【登录】按钮登录,登录成功后显示欢迎窗体…...

基于ZYNQ-7000系列的FPGA学习笔记3——开发环境搭建点亮一个LED
基于ZYNQ-7000系列的FPGA学习笔记3——开发环境搭建&点亮一个LED 1. 搭建开发环境2. FPGA的开发流程3. 点亮一个LED3.1 实验要求3.2 新建工程3.3 原理图3.4 绘制系统框图3.5 绘制波形图3.6 编写RTL代码3.7 软件仿真3.8 Vivado软件创建工程3.9 分析与综合3.10 设计实现 在上…...
)
队列-链式描述(C++)
定义 使用链表描述队列时,通常包含以下几个基本要素: 队头指针(Front Pointer):指向队列中第一个(即最早进入队列的)元素的节点。队尾指针(Rear Pointer):指…...

Kali Linux使用Netdiscover工具的详细教程
Kali Linux使用Netdiscover工具的详细教程 引言 在网络安全和渗透测试的过程中,网络发现是一个至关重要的步骤。Netdiscover是Kali Linux中一个非常实用的网络发现工具,它可以帮助用户快速识别局域网中的活动设备。本文将详细介绍如何使用Netdiscover工…...
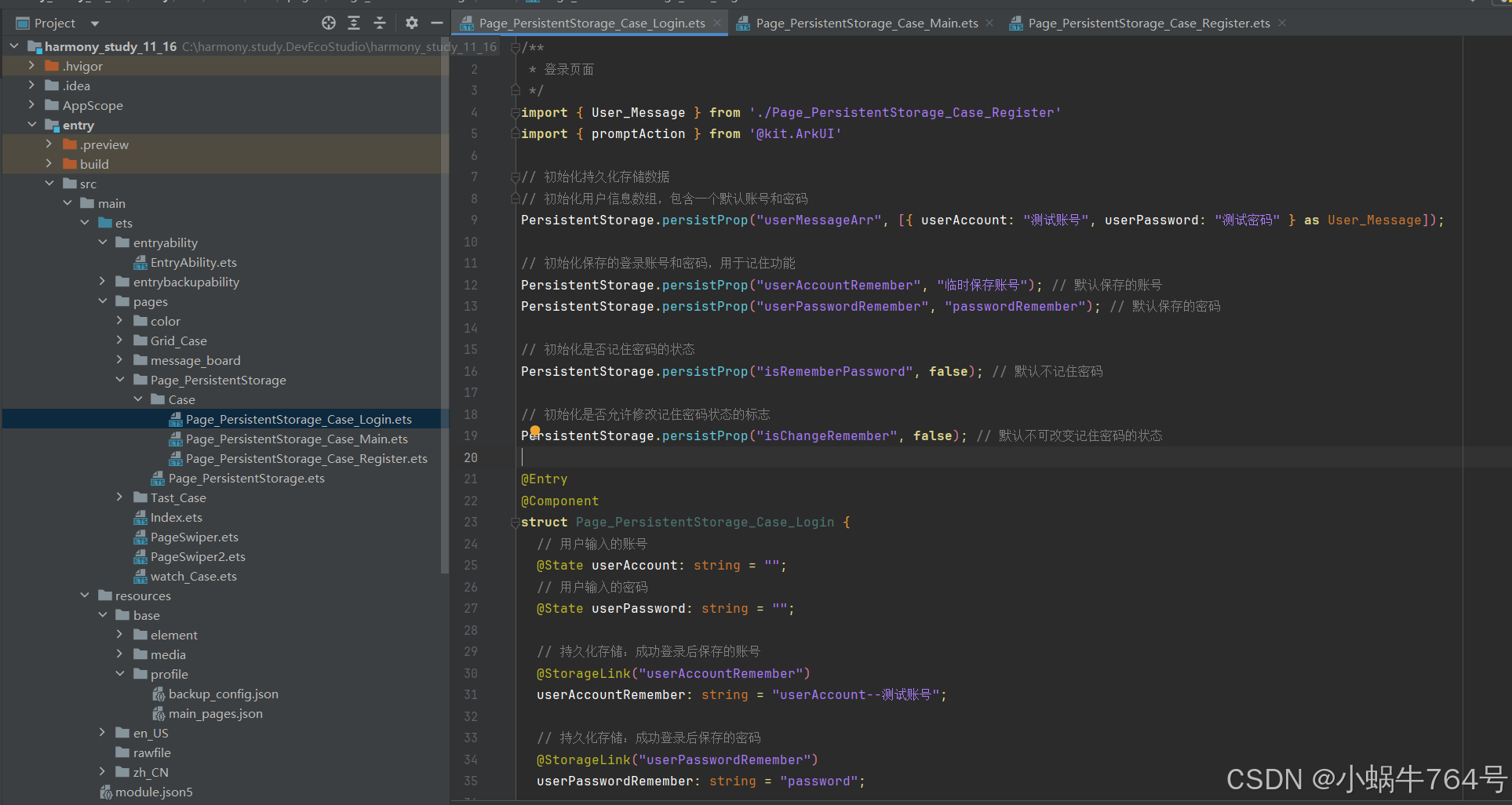
arkTS:使用ArkUI实现用户信息的持久化管理与自动填充(PersistentStorage)
arkUI:使用ArkUI实现用户信息的持久化管理与自动填充(PersistentStorage) 1 主要内容说明2 例子2.1 登录页2.1.1登陆页的相关说明2.1.1.1 持久化存储的初始化2.1.1.2 输入框2.1.1.3 记住密码选项2.1.1.4 登录按钮的逻辑2.1.1.5 注册跳转 2.1.…...
IntelliJ+SpringBoot项目实战(二十)--基于SpringSecurity实现Oauth2服务端和客户端
在前面的帖子中介绍了SpringSecurityJWT实现了认证和授权的功能。因为基于Oauth2的统一认证在项目需求中越来越多,所以有必要将OAuth2的解决方案也整合进来,这样我们的产品既可以作为一个业务系统,也可以作为一个独立的统一认证服务器。下面详…...

如何实现剪裁功能
文章目录 1 概念介绍2 使用方法2.1 ClipOval2.2 ClipRRect3 示例代码我们在上一章回中介绍了AspectRatio Widget相关的内容,本章回中将介绍剪裁类组件(Clip).闲话休提,让我们一起Talk Flutter吧。 1 概念介绍 我们在这里说的剪裁类组件主要是指对子组件进行剪裁操作,常用的…...

LeetCode 动态规划 爬楼梯
爬楼梯 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n 2 输出:2 解释:有两种方法可以爬到楼顶。 1 阶 1 阶 2 阶 示例 2ÿ…...

Java 工厂模式:深度解析与应用指南
在 Java 编程的广袤天地里,设计模式宛如璀璨星辰,照亮了开发者构建高效、灵活且可维护软件系统的道路。其中,工厂模式作为创建型设计模式的关键成员,在对象创建环节扮演着举足轻重的角色,极大地增强了代码的适应性与扩…...
-- SVG 集成详解)
HTML5系列(5)-- SVG 集成详解
前端技术探索系列:HTML5 SVG 集成详解 🎨 开篇寄语 👋 前端开发者们, 在前五篇文章中,我们探讨了 HTML5 的多个特性。今天,让我们深入了解 SVG 的魅力,看看如何创建可缩放的矢量图形。 一、…...

深度学习常见数据集处理方法
1、数据集格式转换(json转txt) import json import os 任务:实例分割,labelme的json文件, 转txt文件 Ultralytics YOLO format <class-index> <x1> <y1> <x2> <y2> ... <xn> <yn> # 类…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...
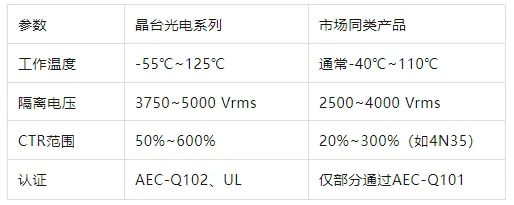
高抗扰度汽车光耦合器的特性
晶台光电推出的125℃光耦合器系列产品(包括KL357NU、KL3H7U和KL817U),专为高温环境下的汽车应用设计,具备以下核心优势和技术特点: 一、技术特性分析 高温稳定性 采用先进的LED技术和优化的IC设计,确保在…...