Flink四大基石之窗口(Window)使用详解
目录
一、引言
二、为什么需要 Window
三、Window 的控制属性
窗口的长度(大小)
窗口的间隔
四、Flink 窗口应用代码结构
是否分组
Keyed Window --键控窗
Non-Keyed Window
核心操作流程
五、Window 的生命周期
分配阶段
触发计算
六、Window 的分类
滚动窗口- TumblingWindow概念
滑动窗口– SlidingWindow概念
会话窗口 [了解]
七、Windows Function 窗口函数
分类剖析
增量聚合函数(以 AggregateFunction 为例)
全量聚合函数
八、案例实战
案例一
滚动窗口演示
滑动窗口演示
热词统计案例
kafka发送消息的模板代码
九、总结
本文深入探讨 Flink 中高级 API 里窗口(Window)的相关知识,涵盖为什么需要窗口、其控制属性、应用代码结构、生命周期、分类,以及窗口函数的各类细节,并辅以实例进行讲解,旨在助力开发者透彻理解并熟练运用 Flink 的窗口机制处理流数据。

一、引言
在大数据实时处理领域,Apache Flink 凭借其卓越性能与丰富功能占据重要地位。而窗口(Window)作为 Flink 从流处理(Streaming)到批处理(Batch)的关键桥梁,理解与掌握其使用对高效数据处理意义非凡,接下来将全方位剖析其奥秘。
二、为什么需要 Window
在流处理场景中,数据如潺潺溪流般持续涌入、无休无止。但诸多业务场景要求我们对特定时段数据做聚合操作,像统计 “过去的 1 分钟内有多少用户点击了我们的网页”。若不划定范围,面对无尽数据洪流,根本无法开展有针对性计算。窗口恰似神奇 “箩筐”,按规则收集一定时长或一定数据量数据,将无限流拆分成有限 “桶”,便于精准计算,满足如 “每隔 10min,计算最近 24h 的热搜词” 这类实时需求。
三、Window 的控制属性
窗口的长度(大小)
明确要计算最近多久的数据,以时间维度举例,若关注 24 小时内热搜词数据量,那 24 小时即窗口长度;计数维度下,设定统计前 N 条数据,N 就是计数窗口的长度规格。
窗口的间隔
决定隔多久进行一次计算操作。像 “每隔 10min,计算最近 24h 的热搜词” 里,每隔 10 分钟便是间隔设定,它把控着计算频次节奏。
四、Flink 窗口应用代码结构
是否分组
首先要判定是否依 Key 对 DataStream 分组,经 keyBy 操作后,数据流成多组,下游算子多实例可并行跑,提效显著;若用 windowAll 则不分组,所有数据送下游单个实例(并行度为 1),后续窗口操作逻辑与分组情形(Keyed Window)类似,仅执行主体有别。
Keyed Window --键控窗
// Keyed Window
stream.keyBy(...) <- 按照一个Key进行分组.window(...) <- 将数据流中的元素分配到相应的窗口中[.trigger(...)] <- 指定触发器Trigger(可选)[.evictor(...)] <- 指定清除器Evictor(可选).reduce/aggregate/process/apply() <- 窗口处理函数Window FunctionNon-Keyed Window
// Non-Keyed Window
stream.windowAll(...) <- 不分组,将数据流中的所有元素分配到相应的窗口中[.trigger(...)] <- 指定触发器Trigger(可选)[.evictor(...)] <- 指定清除器Evictor(可选).reduce/aggregate/process() <- 窗口处理函数Window Function核心操作流程
借助窗口分配器(WindowAssigner)依时间(Event Time 或 Processing Time)把数据流元素 “分拣” 进对应窗口;待满足触发条件(常是窗口结束时间到等情况),用窗口处理函数(如 reduce、aggregate、process 等常用函数)处理窗口内数据,此外,trigger、evictor 是面向高级自定义需求的触发、销毁附加项,默认配置也能应对常见场景。
五、Window 的生命周期
分配阶段
窗口分配器依据设定规则(像按时间间隔、计数规则等),为流入数据 “找家”,安置到合适窗口 “桶” 内,确定数据归属,构建基础计算单元。
触发计算
当预设触发条件达成,如时间窗口到结束点,对应窗口函数 “登场”,对窗口内数据按既定逻辑聚合处理,不同窗口函数(reduce、aggregate、process)处理细节、能力有差异,像 process 更底层、功能更强大,自带 open/close 生命周期方法且能获取 RuntimeContext。
上图是窗口的生命周期示意图,假如我们设置的是一个10分钟的滚动窗口,第一个窗口的起始时间是0:00,结束时间是0:10,后面以此类推。当数据流中的元素流入后,窗口分配器会根据时间(Event Time或Processing Time)分配给相应的窗口。相应窗口满足了触发条件,比如已经到了窗口的结束时间,会触发相应的Window Function进行计算。注意,本图只是一个大致示意图,不同的Window Function的处理方式略有不同。

从数据类型上来看,一个DataStream经过keyBy转换成KeyedStream,再经过window转换成WindowedStream,我们要在之上进行reduce、aggregate或process等Window Function,对数据进行必要的聚合操作。
六、Window 的分类
Window可以分成两类:
CountWindow按指定数据条数生成窗口,与时间脱钩。
滚动计数窗口:每隔 N 条数据,聚焦统计前 N 条,如每来 10 条统计前 10 条信息。
滑动计数窗口:每隔 N 条数据,统计前 M 条(N≠M),像每过 20 条统计前 15 条情况。
TimeWindow(重点):基于时间划定窗口。
滚动时间窗口:每隔 N 时间,统计前 N 时间范围数据,如每隔 5 分钟统计前 5 分钟车辆通过量,窗口长度与滑动距离均为 5 分钟。
滑动时间窗口:每隔 N 时间,统计前 M 时间范围数据(M≠N),像每隔 30 秒统计前 1 分钟车辆数据,窗口长度 1 分钟、滑动距离 30 秒。
会话窗口:设会话超时时间(如 10 分钟),期间无数据来则结算上一窗口数据,按毫秒精细界定范围,与 Key 值关联紧密,Key 值无新输入达设定时长就统计,不受全局新数据流入干扰。
滚动窗口- TumblingWindow概念
流是连续的,无界的(有明确的开始,无明确的结束)
假设有个红绿灯,提出个问题:计算一下通过这个路口的汽车数量

对于这个问题,肯定是无法回答的,为何?
因为,统计是一种对固定数据进行计算的动作。
因为流的数据是源源不断的,无法满足固定数据的要求(因为不知道何时结束)
那么,我们换个问题:统计1分钟内通过的汽车数量
那么,对于这个问题,我们就可以解答了。因为这个问题确定了数据的边界,从无界的流数据中,取出了一部分有边界的数据子集合进行计算。
描述完整就是:每隔1分钟,统计这1分钟内通过汽车的数量。窗口长度是1分钟,时间间隔是1分钟,所以这样的窗口就是滚动窗口。

那么,这个行为或者说这个统计的数据边界,就称之为窗口。
同时,我们的问题,是以时间来划分被处理的数据边界的,那么按照时间划分边界的就称之为:时间窗口
反之,如果换个问题,统计100辆通过的车里面有多少宝马品牌,那么这个边界的划分就是按照数量的,这样的称之为:计数窗口
同时,这样的窗口被称之为滚动窗口,按照窗口划分依据分为:滚动时间窗口、滚动计数窗口。
滑动窗口– SlidingWindow概念
同样是需求,改为:
每隔1分钟,统计前面2分钟内通过的车辆数
对于这个需求我们可以看出,窗口长度是2分钟,每隔1分钟统计一次,窗口长度和时间间隔不相等,并且是大于关系,就是滑动窗口
或者:每通过100辆车,统计前面通过的50辆车的品牌占比
对于这个需求可以看出,窗口长度是50辆车,但是每隔100辆车统计一次
对于这样的窗口,我们称之为滑动窗口。

那么在这里面,统计多少数据是窗口长度(如统计2分钟内的数据,统计50辆车中的数据)
隔多久统计一次称之为滑动距离(如,每隔1分钟,每隔100辆车)
那么可以看出,滑动窗口,就是滑动距离不等于窗口长度的一种窗口
比如,每隔1分钟 统计先前5分钟的数据,窗口长度5分钟,滑动距离1分钟,不相等
比如,每隔100条数据,统计先前50条数据,窗口长度50条,滑动距离100条,不相等
那如果相等呢?相等就是比如:每隔1分钟统计前面1分钟的数据,窗口长度1分钟,滑动距离1分钟,相等。
对于这样的需求可以简化成:每隔1分钟统计一次数据,这就是前面说的滚动窗口
那么,我们可以看出:
滚动窗口:窗口长度= 滑动距离
滑动窗口:窗口长度!= 滑动距离
总结:其中可以发现,对于滑动窗口:
滑动距离> 窗口长度,会漏掉数据,比如:每隔5分钟,统计前面1分钟的数据(滑动距离5分钟,窗口长度1分钟,漏掉4分钟的数据)这样的东西,没人用。
滑动距离< 窗口长度,会重复处理数据,比如:每隔1分钟,统计前面5分钟的数据(滑动距离1分钟,窗口长度5分钟,重复处理4分钟的数据)
滑动距离= 窗口长度,不漏也不会重复,也就是滚动窗口
窗口的长度(大小) > 窗口的间隔 : 如每隔5s, 计算最近10s的数据 【滑动窗口】

窗口的长度(大小) = 窗口的间隔: 如每隔10s,计算最近10s的数据 【滚动窗口】

窗口的长度(大小) < 窗口的间隔: 每隔15s,计算最近10s的数据 【没有名字,不用】

会话窗口 [了解]
Session 会话,一次会话。就是谈话。
设置一个会话超时时间间隔即可, 如10分钟,那么表示:
如果10分钟没有数据到来, 就计算上一个窗口的数据

代码中,并行度设置为1,测试比较 方便。
窗口的范围:
窗口的判断是按照毫秒为单位
如果窗口长度是5秒
窗口的开始: start
窗口的结束: start + 窗口长度 -1 毫秒
比如窗口长度是5秒, 从0开始
那么窗口结束是: 0 + 5000 -1 = 4999
七、Windows Function 窗口函数
分类剖析
全量函数:耐心缓存窗口所有元素,直至触发条件成熟,才对全量数据 “开刀” 计算,此特性可满足数据排序等复杂需求。
增量函数:保存中间数据 “蓝本”,新元素流入就与之融合更新,持续迭代中间成果,高效且灵活。
增量聚合函数(以 AggregateFunction 为例)
每有新数据 “入局”,立马按规则计算,其接口含输入类型(IN)、累加器类型(ACC)、输出类型(OUT)参数,有对应 add、createAccumulator、merge、extractOutput 等方法,构建严谨聚合流程。

实现方法(常见的增量聚合函数如下):
reduce(reduceFunction)
aggregate(aggregateFunction)
sum()
min()
max()reduce接受两个相同类型的输入,生成一个同类型输出,所以泛型就一个 <T>
maxBy、minBy、sum这3个底层都是由reduce实现的
aggregate的输入值、中间结果值、输出值它们3个类型可以各不相同,泛型有<T, ACC, R>
AggregateFunction 【了解】
AggregateFunction 比 ReduceFunction 更加的通用,它有三个参数:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。
输入类型是输入流中的元素类型,AggregateFunction有一个add方法可以将一个输入元素添加到一个累加器中。该接口还具有创建初始累加器(createAccumulator方法)、将两个累加器合并到一个累加器(merge方法)以及从累加器中提取输出(类型为OUT)的方法。
package com.bigdata.windows;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class _04_AggDemo {public static final Tuple3[] ENGLISH = new Tuple3[] {Tuple3.of("class1", "张三", 100L),Tuple3.of("class1", "李四", 40L),Tuple3.of("class1", "王五", 60L),Tuple3.of("class2", "赵六", 20L),Tuple3.of("class2", "小七", 30L),Tuple3.of("class2", "小八", 50L)};public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);env.setParallelism(1);//2. source-加载数据DataStreamSource<Tuple3<String,String,Long>> dataStreamSource = env.fromElements(ENGLISH);KeyedStream<Tuple3<String,String,Long>, String> keyedStream = dataStreamSource.keyBy(new KeySelector<Tuple3<String,String,Long>, String>() {@Overridepublic String getKey(Tuple3<String,String,Long> tuple3) throws Exception {return tuple3.f0;}});//3. transformation-数据处理转换// 三个参数:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)keyedStream.countWindow(3).aggregate(new AggregateFunction<Tuple3<String,String,Long>, Tuple3<String,Long,Integer>, Tuple2<String,Double>>() {// 初始化一个中间变量Tuple3<String,Long,Integer> tuple3 = Tuple3.of(null,0L,0);@Overridepublic Tuple3<String,Long,Integer> createAccumulator() {return tuple3;}@Overridepublic Tuple3<String,Long,Integer> add(Tuple3<String, String, Long> value, Tuple3<String,Long,Integer> accumulator) {long tempScore = value.f2 + accumulator.f1;int length = accumulator.f2 + 1;return Tuple3.of(value.f0, tempScore,length);}@Overridepublic Tuple2<String, Double> getResult( Tuple3<String,Long,Integer> accumulator) {return Tuple2.of(accumulator.f0,(double) accumulator.f1 / accumulator.f2);}@Overridepublic Tuple3<String, Long, Integer> merge(Tuple3<String, Long, Integer> a, Tuple3<String, Long, Integer> b) {return Tuple3.of(a.f0,a.f1+b.f1,a.f2+b.f2);}}).print();//4. sink-数据输出//5. execute-执行env.execute();}
}全量聚合函数
坚守等窗口数据集齐 “发令枪响” 才运算原则,确保计算基于完整数据集,保障结果准确性、完整性,契合多场景聚合诉求。

实现方法
apply(windowFunction)
process(processWindowFunction)全量聚合: 窗口需要维护全部原始数据,窗口触发进行全量聚合。
ProcessWindowFunction一次性迭代整个窗口里的所有元素,比较重要的一个对象是Context,可以获取到事件和状态信息,这样我们就可以实现更加灵活的控制,该算子会浪费很多性能,主要原因是不增量计算,要缓存整个窗口然后再去处理,所以要设计好内存。
package com.bigdata.day04;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.util.Collector;public class Demo03 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据Tuple3[] ENGLISH = new Tuple3[] {Tuple3.of("class1", "张三", 100L),Tuple3.of("class1", "李四", 40L),Tuple3.of("class1", "王五", 60L),Tuple3.of("class2", "赵六", 20L),Tuple3.of("class2", "小七", 30L),Tuple3.of("class2", "小八", 50L)};// 先求每个班级的总分数,再求每个班级的总人数DataStreamSource<Tuple3<String,String,Long>> streamSource = env.fromElements(ENGLISH);KeyedStream<Tuple3<String, String, Long>, String> keyedStream = streamSource.keyBy(v -> v.f0);// 每个分区中的数据都达到了3条才能触发,哪个分区达到了三条,哪个就触发,不够的不计算// //Tuple3<String, String, Long> 输入类型// //Tuple2<Long, Long> 累加器ACC类型,保存中间状态 第一个值代表总成绩,第二个值代表总人数// //Double 输出类型// 第一个泛型是输入数据的类型,第二个泛型是返回值类型 第三个是key 的类型, 第四个是窗口对象keyedStream.countWindow(3).apply(new WindowFunction<Tuple3<String, String, Long>, Double, String, GlobalWindow>() {@Overridepublic void apply(String s, GlobalWindow window, Iterable<Tuple3<String, String, Long>> input, Collector<Double> out) throws Exception {// 计算总成绩,计算总人数int sumScore = 0,sumPerson=0;for (Tuple3<String, String, Long> tuple3 : input) {sumScore += tuple3.f2;sumPerson += 1;}out.collect((double)sumScore/sumPerson);}}).print();//5. execute-执行env.execute();}
}八、案例实战
案例一
需求为 “每 5 秒钟统计一次,最近 5 秒钟内,各个路口通过红绿灯汽车的数量”,借 Flink 代码实现,底层算法作用下,数据按节奏聚合统计,时间设 1 分钟更易观察效果,能清晰看到各时段车辆数统计产出。
nc -lk 9999
有如下数据表示:
信号灯编号和通过该信号灯的车的数量
9,3
9,2
9,7
4,9
2,6
1,5
2,3
5,7
5,4
没有添加窗口的写法:
package com.bigdata.day03.time;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo07 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStreamSource<String> streamSource = env.socketTextStream("localhost", 9999);// 9,2 --> (9,2)//3. transformation-数据处理转换streamSource.map(new MapFunction<String, Tuple2<Integer,Integer>>() {@Overridepublic Tuple2<Integer, Integer> map(String line) throws Exception {String[] arr = line.split(",");int monitor_id = Integer.valueOf(arr[0]);int num = Integer.valueOf(arr[1]);return Tuple2.of(monitor_id,num);}}).keyBy(tuple->tuple.f0).sum(1).print();//4. sink-数据输出//5. execute-执行env.execute();}
}此处的sum求和,中count ,其实是CartInfo中的一个字段而已。
演示:

滚动窗口演示
package com.bigdata.day03.time;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;public class Demo08 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStreamSource<String> streamSource = env.socketTextStream("localhost", 9999);// 9,2 --> (9,2)//3. transformation-数据处理转换streamSource.map(new MapFunction<String, Tuple2<Integer,Integer>>() {@Overridepublic Tuple2<Integer, Integer> map(String line) throws Exception {String[] arr = line.split(",");int monitor_id = Integer.valueOf(arr[0]);int num = Integer.valueOf(arr[1]);return Tuple2.of(monitor_id,num);}}).keyBy(tuple->tuple.f0).window(TumblingProcessingTimeWindows.of(Time.minutes(1))).sum(1).print();//4. sink-数据输出//5. execute-执行env.execute();}
}以上代码的时间最好修改为1分钟,假如时间间隔是1分钟,那么48分03秒时输入的信号灯数据,49分整点会统计出来结果,原因是底层有一个算法。

滑动窗口的话,不太容易看到效果,因为有些数据被算到了多个窗口中,需要我们拿笔自己计算一下,对比一下:


滑动窗口演示
同样统计各路口汽车数量,但需求改为 “每 5 秒钟统计一次,最近 10 秒钟内”,因数据会在多窗口重复计算,需手动比对梳理,深入体会滑动窗口数据处理逻辑与特点。
package com.bigdata.day03.time;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;public class Demo09 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStreamSource<String> streamSource = env.socketTextStream("localhost", 9999);// 9,2 --> (9,2)//3. transformation-数据处理转换streamSource.map(new MapFunction<String, Tuple2<Integer,Integer>>() {@Overridepublic Tuple2<Integer, Integer> map(String line) throws Exception {String[] arr = line.split(",");int monitor_id = Integer.valueOf(arr[0]);int num = Integer.valueOf(arr[1]);return Tuple2.of(monitor_id,num);}}).keyBy(tuple->tuple.f0).window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5))).sum(1).print();//4. sink-数据输出//5. execute-执行env.execute();}
}热词统计案例
借助 Kafka 随机发送 50000 个热词(200 毫秒间隔),分别基于滚动、滑动窗口统计,编写 Flink 代码时着重体会 apply 方法,兼顾二者效果差异,同时知晓工作中 process 函数因更强大底层能力常成首选。
apply和process都是处理全量计算,但工作中正常用process。
process更加底层,更加强大,有open/close生命周期方法,又可获取RuntimeContext。

package com.bigdata.day03.time;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;public class Demo10 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据Properties properties = new Properties();properties.setProperty("bootstrap.servers","bigdata01:9092");properties.setProperty("group.id","g2");//2. source-加载数据FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<String>("flink-01",new SimpleStringSchema(),properties);DataStreamSource<String> kafkaSource = env.addSource(kafkaConsumer);//3. transformation-数据处理转换kafkaSource.map(new MapFunction<String, Tuple2<String,Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value,1);}}).keyBy(tuple->tuple.f0)//.window(TumblingProcessingTimeWindows.of(Time.seconds(5))).window(SlidingProcessingTimeWindows.of(Time.seconds(5),Time.seconds(2)))// 第一个泛型是输入数据的类型,第二个泛型是返回值类型 第三个是key 的类型, 第四个是窗口对象.apply(new WindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>() {@Overridepublic void apply(String key, // 代表分组key值 五旬老太守国门TimeWindow window, // 代表窗口对象Iterable<Tuple2<String, Integer>> input, // 分组过之后的数据 [1,1,1,1,1]Collector<String> out // 用于输出的对象) throws Exception {SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");long start = window.getStart();long end = window.getEnd();int sum = 0;for (Tuple2<String, Integer> tuple2 : input) {sum += tuple2.f1;}out.collect(key+",窗口开始:"+dateFormat.format(new Date(start))+",结束时间:"+dateFormat.format(new Date(end))+","+sum);//out.collect(key+",窗口开始:"+start+",结束时间:"+end+","+sum);}}).print();//4. sink-数据输出//5. execute-执行env.execute();}
}kafka发送消息的模板代码
package com.bigdata.day03.time;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;
import java.util.Random;public class CustomProducer {public static void main(String[] args) {// Properties 它是map的一种Properties properties = new Properties();// 设置连接kafka集群的ip和端口properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");// 创建了一个消息生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);// 调用这个里面的send方法String[] hotWords= new String[]{"郭有才","歌手2024","五旬老太守国门","师夷长技以制夷"};Random random = new Random();for (int i = 0; i < 50000; i++) {String word = hotWords[random.nextInt(4)];ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("flink-01",word);kafkaProducer.send(producerRecord);}kafkaProducer.close();}
}
九、总结
Flink 窗口机制犹如精密仪器,从控制属性、分类设计到函数运用,各环节紧密相扣。深入理解其原理、熟练实操代码,能为实时流数据处理注入强大动力,解锁更多高效、智能数据聚合分析场景,助力开发者在大数据浪潮中稳立潮头、驾驭数据。后续可深入探索自定义窗口逻辑、优化性能调优等进阶方向,深挖 Flink 窗口潜力。
相关文章:
Flink四大基石之窗口(Window)使用详解
目录 一、引言 二、为什么需要 Window 三、Window 的控制属性 窗口的长度(大小) 窗口的间隔 四、Flink 窗口应用代码结构 是否分组 Keyed Window --键控窗 Non-Keyed Window 核心操作流程 五、Window 的生命周期 分配阶段 触发计算 六、Wi…...

NGINX配置https双向认证(自签一级证书)
一 生成自签证书 以下是生成自签证书(包括服务端和客户端的证书)的步骤,以下命令执行两次,分别生成客户端和服务端证书和私钥。具体执行可以先建两个目录client和server,分别进入到这两个目录下执行下面的命令。 生成私钥: 首先&…...

Flink双流Join
在离线 Hive 中,我们经常会使用 Join 进行多表关联。那么在实时中我们应该如何实现两条流的 Join 呢?Flink DataStream API 为我们提供了3个算子来实现双流 join,分别是: join coGroup intervalJoin 下面我们分别详细看一下这…...

【数据结构实战篇】用C语言实现你的私有队列
🏝️专栏:【数据结构实战篇】 🌅主页:f狐o狸x 在前面的文章中我们用C语言实现了栈的数据结构,本期内容我们将实现队列的数据结构 一、队列的概念 队列:只允许在一端进行插入数据操作,在另一端…...

基于web的海贼王动漫介绍 html+css静态网页设计6页+设计文档
📂文章目录 一、📔网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站演示 五、⚙️网站代码 🧱HTML结构代码 💒CSS样式代码 六、🔧完整源码下载 七、📣更多 一、&#…...

2022 年 9 月青少年软编等考 C 语言三级真题解析
目录 T1. 课程冲突T2. 42 点思路分析T3. 最长下坡思路分析T4. 吃糖果思路分析T5. 放苹果思路分析T1. 课程冲突 此题为 2021 年 9 月三级第一题原题,见 2021 年 9 月青少年软编等考 C 语言三级真题解析中的 T1。 T2. 42 点 42 42 42 是: 组合数学上的第 5 5 5 个卡特兰数字…...

机器学习算法(六)---逻辑回归
常见的十大机器学习算法: 机器学习算法(一)—决策树 机器学习算法(二)—支持向量机SVM 机器学习算法(三)—K近邻 机器学习算法(四)—集成算法 机器学习算法(五…...

计算机科学中的主要协议
1、主要应用层协议: HTTP、FTP、SMTP、POP、IMAP、DNS、TELNET和SSH等 应用层协议的主要功能是支持网络应用,定义了不同应用程序之间的通信规则。它们负责将用户操作转换为网络可以理解的数据格式,并通过传输层进行传输。应用层协议直接与用…...

下载maven 3.6.3并校验文件做md5或SHA512校验
一、下载Apache Maven 3.6.3 Apache Maven 3.6.3 官方下载链接: 二进制压缩包(推荐): ZIP格式: https://archive.apache.org/dist/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.zipTAR.GZ格式: https://archive.apache.org/dist/…...

【Android】View工作原理
View 是Android在视觉上的呈现在界面上Android提供了一套GUI库,里面有很多控件,但是很多时候我们并不满足于系统提供的控件,因为这样就意味这应用界面的同类化比较严重。那么怎么才能做出与众不同的效果呢?答案是自定义View&#…...

TIE算法具体求解-为什么是泊松方程和傅里叶变换
二维泊松方程的通俗理解 二维泊松方程 是偏微分方程的一种形式,通常用于描述空间中某个标量场(如位相场、电势场)的分布规律。其一般形式为: ∇ 2 ϕ ( x , y ) f ( x , y ) \nabla^2 \phi(x, y) f(x, y) ∇2ϕ(x,y)f(x,y) 其…...
截取指定位数的字符等)
postman中获取随机数、唯一ID、时间日期(包括当前日期增减)截取指定位数的字符等
在Postman中,您可以使用内置的动态变量和编写脚本的方式来获取随机数、唯一ID、时间日期以及截取指定位数的字符。以下是具体的操作方法: 一、postman中获取随机数、唯一ID、时间日期(包括当前日期增减)截取指定位数的字符等 获取…...

【计算机网络】实验3:集线器和交换器的区别及交换器的自学习算法
实验 3:集线器和交换器的区别及交换器的自学习算法 一、 实验目的 加深对集线器和交换器的区别的理解。 了解交换器的自学习算法。 二、 实验环境 • Cisco Packet Tracer 模拟器 三、 实验内容 1、熟悉集线器和交换器的区别 (1) 第一步:构建网络…...

flink学习(14)—— 双流join
概述 Join:内连接 CoGroup:内连接,左连接,右连接 Interval Join:点对面 Join 1、Join 将有相同 Key 并且位于同一窗口中的两条流的元素进行关联。 2、Join 可以支持处理时间(processing time)和事件时…...

HTTP协议详解:从HTTP/1.0到HTTP/3的演变与优化
深入浅出:从头到尾全面解析HTTP协议 一、HTTP协议概述 1.1 HTTP协议简介 HTTP(HyperText Transfer Protocol,超文本传输协议)是互联网上应用最广泛的通信协议之一。它用于客户端与服务器之间的数据传输,尤其是在Web…...
张量并行和流水线并行在Transformer中的具体部位
目录 张量并行和流水线并行在Transformer中的具体部位 一、张量并行 二、流水线并行 张量并行和流水线并行在Transformer中的具体部位 张量并行和流水线并行是Transformer模型中用于提高训练效率的两种并行策略。它们分别作用于模型的不同部位,以下是对这两种并行的具体说…...

WEB开发: 丢掉包袱,拥抱ASP.NET CORE!
今天的 Web 开发可以说进入了一个全新的时代,前后端分离、云原生、微服务等等一系列现代技术架构应运而生。在这个背景下,作为开发者,你一定希望找到一个高效、灵活、易于扩展且具有良好性能的框架。那么,ASP.NET Core 显然是一个…...

【论文阅读】Federated learning backdoor attack detection with persistence diagram
目的:检测联邦学习环境下,上传上来的模型是不是恶意的。 1、将一个模型转换为|L|个PD,(其中|L|为层数) 如何将每一层转换成一个PD? 为了评估第𝑗层的激活值,我们需要𝑐个输入来获…...

Gooxi Eagle Stream 2U双路通用服务器:性能强劲 灵活扩展 稳定易用
人工智能的高速发展开启了飞轮效应,实施数字化变革成为了企业的一道“抢答题”和“必答题”,而数据已成为现代企业的命脉。以HPC和AI为代表的新业务就像节节攀高的树梢,象征着业务创新和企业成长。但在树梢之下,真正让企业保持成长…...

【计算机网络】实验2:总线型以太网的特性
实验 2:总线型以太网的特性 一、 实验目的 加深对MAC地址,IP地址,ARP协议的理解。 了解总线型以太网的特性(广播,竞争总线,冲突)。 二、 实验环境 • Cisco Packet Tracer 模拟器 三、 实…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...
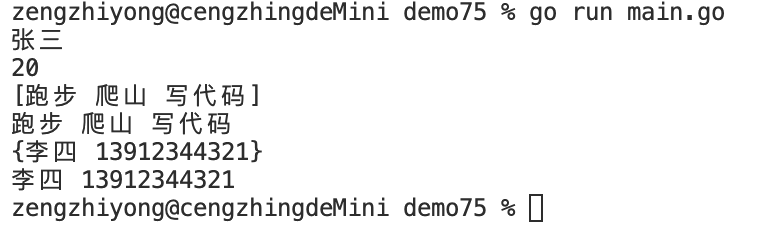
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...