Hadoop3集群实战:从零开始的搭建之旅
目录=
一、概念
1.1 Hadoop是什么
1.2 历史
1.3 三大发行版本(了解)
1.4 优势
1.5 组成💗
1.6 HDFS架构
1.7 YARN架构
1.8 MapReduce概述
1.9 HDFS\YARN\MapReduce关系
二、环境准备
2.1 准备模版虚拟机
2.2 安装必要软件
2.3 安装xshell
2.4 创建用户并赋予root权限
2.5 克隆虚拟机
2.6 时间同步
2.7 ssh免密登录
2.8 xsync脚本分发
2.9 安装JDK和Mysql
安装jdk(三个节点)
安装mysql(主节点)目前不需要
三、完全分布式集群搭建
3.1 安装hadoop(三台)
3.2 集群部署
3.2.1 部署规划
3.2.2 配置文件(三台)
3.2.3 启动集群
参考:
一、概念
1.1 Hadoop是什么
- apache的分布式系统基础架构
- Hadoop实际上是一个生态圈,里面有多个组件,主要解决海量数据存储和分析计算问题
1.2 历史
- Hadoop是Apache Lucene创始人 Doug Cutting 创建的。最早起源于Nutch,它是Lucene的子项目。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题:如何解决数十亿网页的存储和索引问题。
- 2003年Google发表了一篇论文为该问题提供了可行的解决方案。论文中描述的是谷歌的产品架构,该架构称为:谷歌分布式文件系统(GFS),可以解决他们在网页爬取和索引过程中产生的超大文件的存储需求。
- 2004年 Google发表论文向全世界介绍了谷歌版的MapReduce系统。
- 同时期,以谷歌的论文为基础,Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP
- 到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
- 2006年Google发表了论文是关于BigTable的,这促使了后来的Hbase的发展。
因此,Hadoop及其生态圈的发展离不开Google的贡献。
1.3 三大发行版本(了解)
- Apache 最基础的版本,完全开源免费
- CDH,集成了大数据框架 发行版本
- HDP,Ambari是HDP的安装工具和管理界面
Cloudera公司已经正式终止了对CDH的支持。分别在2021年12月、2022年3月,Cloudera正式终止了对HDP(Hortonworks Data Platform)及CDH的支持
后续推出CDP,新一代数据平台产品,它整合了HDP和CDH的功能并进行了优化和扩展。
1.4 优势
- 高可靠性:底层维护多个数据副本,避免故障时数据丢失
- 高扩展性:集群间分配任务数据,方便扩展节点,动态扩容缩减
- 高效性:并行工作
- 高容错性:自动将失败的任务重新分配
1.5 组成💗
Hadoop1.x、2.x、3.x的区别

- Hadoop1.*中MapReduce中计算和资源调度同时处理,耦合性比较大
- Hadoop2.*新增了YARN进行资源调度,MapReduce只用来计算
- Hadoop2和3在组成上没有区别
1.6 HDFS架构
分布式文件系统
- NameNode 数据存储位置(存储文件元数据,如:文件名 目录结构 文件属性 所在位置),相当于目录
- DataNode 存储数据,相当于内容
- 2NN 辅助NameNode工作(每隔一段时间对NameNode做数据备份)

1.7 YARN架构
资源管理器
- Resource Manager 集群资源管理(内存、cup)
- Node Manager 单节点资源管理
- Container 容器,相当于一台独立服务器
- ApplicationMaster,单个任务资源管理

1.8 MapReduce概述
- map阶段,并行处理输入数据
- reduce阶段,对map结果汇总

1.9 HDFS\YARN\MapReduce关系

大数据技术生态体系

二、环境准备
目标:需要准备3台虚拟机(本次使用Ubuntu24.04,但是教程大多是Centos,大差不差),机器名为hadoop102、hadoop103、hadoop104,对应ip:192.168.10.102、192.168.10.103、192.168.10.104
2.1 准备模版虚拟机
软件操作系统安装参考:(这部分没有详细记录,一般使参考视频和博客,要细心)
VMware 虚拟机图文安装和配置 Ubuntu Server 22.04 LTS 教程_00-installer-config.yaml-CSDN博客
19_尚硅谷_Hadoop_入门_Centos7.5软硬件安装_哔哩哔哩_bilibili
- 配置静态ip 192.168.10.100,nat桥接模式
- 配置文件修改/etc/netplan
- 配置主机名称和ip映射:修改服务器hosts文件 192.168.10.100 hadoop100
- 修改一些配置虚拟机和windows上的
2.2 安装必要软件
安装vim、iputils-ping、net-tools、rsync(一般安装最小体积的server版本才需要安装这些)
- sudo apt install vim
- sudo apt update
- sudo apt-get update
- sudo apt install iputils-ping
- sudo apt install net-tools
- sudo apt install rsync
测试网络:ping www.baidu.com
测试:ip ifconfig
2.3 安装xshell
c21_尚硅谷_Hadoop_入门_Xshell远程访问工具_哔哩哔哩_bilibili参考:21_尚硅谷_Hadoop_入门_Xshell远程访问工具_哔哩哔哩_bilibili
主要是做本机和虚拟机的交互和文件上传。因为本地安装了termius就不需要这个了,感觉termius更好用
2.4 创建用户并赋予root权限
给用户mlj root权限:vim /etc/sudoers
mlj ALL=(ALL:ALL) NOPASSWD:ALL2.5 克隆虚拟机
- 在vmware上克隆模版虚拟机
- 修改ip和主机名分别为hadoop102 hadoop103 hadoop104
- 修改ip和主机名的映射:vim /etc/hosts
192.168.10.102 hadoop102192.168.10.103 hadoop103192.168.10.104 hadoop104报错:使用termius进行root用户登录时报错:SSH配置不允许root登录
- 修改/etc/ssh/sshd_config PermitRootLogin:yes
- 重启生效sudo systemctl restart sshd
2.6 时间同步
如果服务器在公网环境(能连接外网),可以不采用集群时间同步
- 安装ntp时间同步服务器(所有节点):apt install ntp
- 查看状态、启动、设置开机自启
systemctl status ntpdsecsystemctl start ntpsecsystemctl enable ntpsec- 重启服务器:reboot
- 所有节点设置时区:中国上海 timedatectl set-timezone Asia/Shanghai
- 修改配置同步时间的机器 vim /etc/ntpsec/ntp.conf
#注释(主节点需要,子节点注释掉)
#集群在局域网中,不使用其他互联网上的时间
pool 0.ubuntu.pool.ntp.org iburst
pool 1.ubuntu.pool.ntp.org iburst
pool 2.ubuntu.pool.ntp.org iburst
pool 3.ubuntu.pool.ntp.org iburst
#pool ntp.ubuntu.com#(子节点配置,使用102作为时间同步机器)
server hadoop102#当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步
#(所有节点需要)
server 127.127.1.0fudge
127.127.1.0 stratum 10#授权网段(主节点需要)
restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap- ntpq -p 查看同步情况
问题:时间和windows实践不一致
(1)安装ntpdate工具:sudo apt-get install ntpdate
(2)同步系统时间与网络时间:sudo ntpdate cn.pool.ntp.org
(3)其他节点同步hadoop102的时间: sudo ntpdate hadoop102
2.7 ssh免密登录
~/.ssh/
(1)102生成公私钥 三次回车 ssh-keygen -t rsa
(2)copy公钥到102 103 104 (本机也要配置)ssh-copy-id hadoop103
(3)103、104执行相同的步骤
(4)验证:ssh hadoop103
2.8 xsync脚本分发
(1)编写分发脚本xsync
注意:每台机器都要有rsync才能分发成功
/home/mlj/bin目录下,新建xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done(2)修改xsync环境变量,否则找不到该命令
export PATH=$PATH:/home/mlj/bin
注意:rsync基于ssh服务需要配置秘钥,免密登录
2.9 安装JDK和Mysql
安装jdk(三个节点)
(1)下载上传到虚拟机:scp .\jdk-8u202-linux-x64.tar.gz root@192.168.10.104:/opt/soft/
(2)解压缩:sudo tar -zxvf jdk-8u202-linux-x64.tar.gz -C /opt/module/
(3)环境变量配置
#JAVA_HOMEexport JAVA_HOME=/opt/module/jdk1.8.0_202export PATH=$PATH:$JAVA_HOME/bin(4)验证:java-version
安装mysql(主节点)目前不需要
步骤:
- 安装docker
- 使用docker安装mysql
- docker-compose启动mysql
问题:
(1)docker-compose报错,缺少python的一个包setuptools
- 安装pipx :sudo apt install pipx
- 安装包setuptools :sudo pipx install setuptools
- docker-compose -version
(2)拉取镜像报错修复:Get "https://registry-1.docker.io/v2/": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
使用第三方镜像库:
AtomHub 可信镜像仓库平台 · OpenAtom Foundation
三、完全分布式集群搭建
3.1 安装hadoop(三台)
(1)上传hadoop包:tar -zxvf hadoop-3.4.1.tar.gz -C /opt/module
(2)解压缩 tar -zxvf hadoop-3.4.1.tar.gz -C /opt/module
(3)环境变量配置
#hadoop环境变量
export HADOOP_HOME=/opt/module/hadoop-3.4.1 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH(4)集群配置
3.2 集群部署
3.2.1 部署规划
- NameNode和SecondaryNameNode不要安装同一台
- ResourceManager也很消耗内存,不要和NameNode和SecondaryNameNode配置在一台机器

3.2.2 配置文件(三台)
自定义配置文件 4个
配置core-site.xml
<!-- 指定 NameNode 的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value></property><!-- 指定 hadoop 数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.4.1/data</value></property><!-- 配置 HDFS 网页登录使用的静态用户为 mlj --><property><name>hadoop.http.staticuser.user</name><value>mlj</value></property>hdfs-site.xml
<!-- nn web 端访问地址-->
<property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value>
</property>
<!--HDFS 中是否启用权限检查-->
<property><name>dfs.permissions</name><value>false</value>
</property>yarn-site.xml
<!-- Site specific YARN configuration properties -->
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property><name>yarn.resourcemanager.hostname</name><value>hadoop10</value>
</property>
<!--是否将对容器实施虚拟内存限制-->
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>mapred-site.xml
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>配置works(不能有空格换行!)
hadoop102hadoop103hadoop1043.2.3 启动集群
- 配置目录权限
sudo chmod -R a+w /opt/module/hadoop-3.4.1/
- 初次启动初始化(初始化失败可能是没有权限,执行上一步)
hdfs namenode -format
- 修改hadoop的环境变量hadoop-env.sh:vim /opt/module/hadoop-3.4.1/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_202- 脚本分发(文件夹需要修改权限),xsync 脚本
- 启动dfs集群:sbin/start-dfs.sh
- jps 验证
- 访问hdfs web页面 http://192.168.10.102:9870/
- 启动yarn sbin/start-yarn.sh
- 登录yarn web页面 http://192.168.10.103:8088/
参考:
尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放_哔哩哔哩_bilibili
Hadoop3.1.4完全分布式集群搭建_hadoop 3.1.4-CSDN博客
相关文章:
Hadoop3集群实战:从零开始的搭建之旅
目录 一、概念 1.1 Hadoop是什么 1.2 历史 1.3 三大发行版本(了解) 1.4 优势 1.5 组成💗 1.6 HDFS架构 1.7 YARN架构 1.8 MapReduce概述 1.9 HDFS\YARN\MapReduce关系 二、环境准备 2.1 准备模版虚拟机 2.2 安装必要软件 2.3 安…...

Kotlin设计模式之桥接模式
桥接模式用于将抽象部分与实现部分分离,使它们可以独立变化。Kotlin中可以通过接口和抽象类来实现桥接模式。以下是桥接模式的实现方法: 一. 基本桥接模式 在这种模式中,定义一个抽象部分和一个实现部分,通过组合将它们连接起来…...

详解组合模式
引言 有一种情况,当一组对象具有“整体—部分”关系时,如果我们处理其中一个对象或对象组合(区别对待),就可能会出现牵一发而动全身的情况,造成代码复杂。这个时候,组合模式就是一种可以用一致的…...

【系统架构设计师论文】云上自动化运维及其应用
随着云计算技术的迅猛发展,企业对云资源的需求日益增长。为了应对这一挑战,云上自动化运维(CloudOps)应运而生,它结合了DevOps理念和技术,通过自动化工具和流程来提高云环境的管理效率和服务质量。本文将探讨云上自动化运维的主要衡量指标,并详细介绍一个实际项目中如何…...

交换排序----快速排序
快速排序 快速排序是一种高效的排序算法,它采用分治法策略,将数组分为较小和较大的两个子数组,然后递归排序两个子数组。 快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序…...

ES 与 MySQL 在较大数据量下查询性能对比
在进行数据查询性能测试的过程中,我的同事幺加明对 ES(Elasticsearch)和 MySQL 进行了相对较大数据量的测试,并整理了相关结果。在得到其授权的情况下,我将此对比案例分享给大家,在此再次向幺加明表示感谢。…...

C# 新语法中的字符串内插$和{}符号用法详解
自C#6.0开始提供一个新的语法糖,即"$" 符号,配合“{}”使用,它的作用除了是对String.format的简化,还可设置其格式模板,实现了对字符串的拼接优化。 语法格式: $"string {变量表达式}” 语…...

Nacos源码学习-本地环境搭建
本文主要记录如何在本地搭建Nacos调试环境来进一步学习其源码,如果你也刚好刷到这篇文章,希望对你有所帮助。 1、本地环境准备 Maven: 3.5.4 Java: 1.8 开发工具:idea 版本控制工具: git 2、下载源码 官方仓库地址 :https://git…...

windows 好工具
Windows文件夹目录大小分析工具WizTree...
计算机运行时提示错误弹窗“由于找不到 quazip.dll,无法继续执行代码。”是什么原因?“quazip.dll文件缺失”要怎么解决?
计算机运行时错误解析:解决“quazip.dll缺失”问题指南 在软件开发和日常计算机使用中,我们经常会遇到各种运行时错误。今天,我们将深入探讨一个常见的错误提示:“由于找不到quazip.dll,无法继续执行代码。”这一弹窗…...

创造未来:The Sandbox 创作者训练营如何赋能全球创造者
创作者训练营让创造者有能力打造下一代数字体验。通过促进合作和提供尖端工具,The Sandbox 计划确保今天的元宇宙是由一个个创造者共同打造。 2024 年 5 月,The Sandbox 推出了「创作者训练营」系列,旨在重新定义数字创作。「创作者训练营」系…...

R语言对简·奥斯汀作品中人物对话的情感分析
项目背景 客户是一家文学研究机构,他们希望通过对简奥斯汀作品中人物对话的情感分析,深入了解作品中人物的情感变化和故事情节的发展。因此,他们委托你进行一项情感分析项目,利用“janeaustenr”包中的数据集来构建情感分析模型。…...

股指期货基差为正数,这是啥意思?
在股指期货的世界里,有个挺重要的概念叫“基差”。说白了,基差就是股指期货的价格和它对应的现货价格之间的差价。今天,咱们就来聊聊当这个基差为正数时,到底意味着啥。 基差是啥? 先复习一下,基差 股指…...

黑马程序员MybatisPlus/Docker相关内容
Day01 MP相关知识 1. mp配置类: 2.条件构造器: 具体的实现例子: ①QuerryWapper: ②LambdaQueryWrapper: 3.MP的自定义SQL 4.MP的Service层的实现 5.IService下的Lambda查询 原SQL语句的写法: Lambda 查询语句的…...

使用 Vue 和 Canvas-Confetti 实现烟花动画特效
在开发中,为用户提供具有视觉冲击力的反馈是一种提升用户体验的好方法。今天,我们将结合 Vue 框架、canvas-confetti 和 Lottie 动画,创建一个动态对话框动画,其中包含炫酷的烟花特效。 效果图: 效果简介 当用户触发…...

【银河麒麟操作系统真实案例分享】内存黑洞导致服务器卡死分析全过程
了解更多银河麒麟操作系统全新产品,请点击访问 麒麟软件产品专区:https://product.kylinos.cn 开发者专区:https://developer.kylinos.cn 文档中心:https://documentkylinos.cn 现象描述 机房显示器连接服务器后黑屏ÿ…...

如何加强游戏安全,防止定制外挂影响游戏公平性
在现如今的游戏环境中,外挂始终是一个困扰玩家和开发者的问题。尤其是定制挂(Customized Cheats),它不仅复杂且隐蔽,更能针对性地绕过传统的反作弊系统,对游戏安全带来极大威胁。定制挂通常是根据玩家的需求…...
SpringBoot整合knife4j,以及会遇到的一些bug
这篇文章主要讲解了“Spring Boot集成接口管理工具Knife4j怎么用”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Spring Boot集成接口管理工具Knife4j怎么用”吧! 一…...

城电科技|光伏廊道是什么?安装光伏廊道有什么好处?
光伏廊道是什么?光伏廊道专门设计用于集中安装太阳能光伏发电系统的建筑物或构筑物,它可以将光伏转换成可以用于供电的清洁绿电。光伏廊道通常由阳能电池板、太阳能电池、控制器、逆变器、混凝土、钢材等材料组成,具备发电、坚固、耐用、防水…...

当DHCP服务器分配了同一个IP地址
当DHCP服务器分配了同一个IP地址给多个设备时,这通常会导致网络问题,如IP地址冲突,进而影响设备的网络连接。以下是详细的分析和解决步骤: 原因分析: IP地址租约未过期: 租约管理:DHCP服务器维…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...
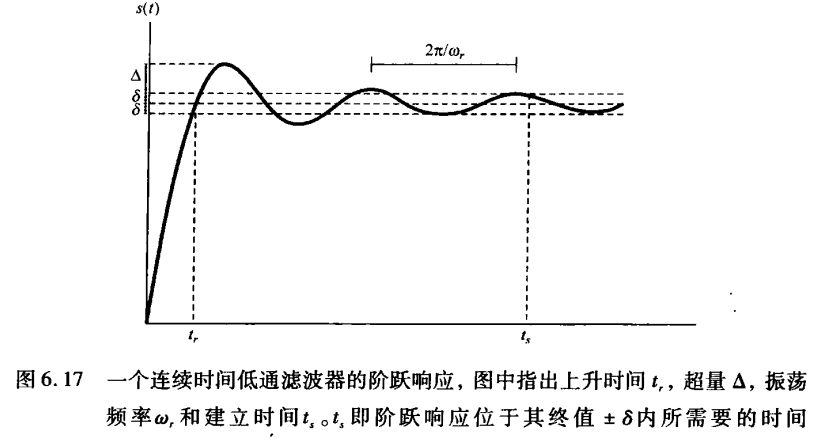
《信号与系统》第 6 章 信号与系统的时域和频域特性
目录 6.0 引言 6.1 傅里叶变换的模和相位表示 6.2 线性时不变系统频率响应的模和相位表示 6.2.1 线性与非线性相位 6.2.2 群时延 6.2.3 对数模和相位图 6.3 理想频率选择性滤波器的时域特性 6.4 非理想滤波器的时域和频域特性讨论 6.5 一阶与二阶连续时间系统 6.5.1 …...

车载诊断架构 --- ZEVonUDS(J1979-3)简介第一篇
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...

比较数据迁移后MySQL数据库和ClickHouse数据仓库中的表
设计一个MySQL数据库和Clickhouse数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...