[NeurlPS 2022] STaR 开源代码实现解读
- STaR 方法代码开源,这里给出一个中文代码解读地址:repo
- 入口点:
iteration_train.py; - 关键代码:
device_train.py,device_inference.py, andcreate_finetune_tfrecords.py; - 基于 JAX、RAY,在 Google TPU 上实现;
入口点:iteration_train.py
if __name__ == "__main__":args = parse_args()print(args)task = args.task # 选择数据集/任务:论文中有 CommonsenseQA、GSM8Kexperiment_name = "_".join(sys.argv[1:]) # 实验参数以_分割,拼接在一起命名experiment_name = ''.join(ch for ch in experiment_name if ch.isalnum() or ch == "_")# 确保 name 只有字母、数字、下划线(符合文件命名格式)if args.no_prompt:eval_seq = 128 + args.gen_lengthos.makedirs(f"configs/{experiment_name}", exist_ok=True)shutil.copy(f"configs/qa_base.json", f"configs/{experiment_name}/base.json") # 复制一份实验配置模版prev_config = f"configs/{experiment_name}/base.json" # 实验配置模版的路径(后续代码会修改这个复制文件)new_json = make_first_config()os.makedirs(f'data/{experiment_name}', exist_ok=True)os.makedirs(f'{task}/{experiment_name}', exist_ok=True)os.makedirs(f'result_logs/', exist_ok=True)with open(f"result_logs/{experiment_name}.txt", "a+") as f:print("================================", file=f) # 类似 f.writeprint(args, file=f)for cur_iter in range(1, args.n_iters): # 论文中的外循环迭代次数,重复多少次 STaR 微调方法exp_iteration = f"{experiment_name}_{cur_iter}"gen_train() # Generate the training settrain_set = gen_records() # Create the tfrecords from the data # "{experiment_name}/{exp_iteration}.index"config_name = gen_config(train_set) # Create the new configuration file # 核心是修改 total_stepstrain_model() # Train the new modeleval_model() # Evaluate the new modelprev_config = config_name # Prepare for next iterationif args.copy_n > 0:copy_files() # [TODO] 复制上次外循环的一些配置文件,暂时不知道有啥用parse_args() 标准的解析命令行参数,但是这里代码参数非常多。论文中,对一些技术细节写的比较模糊或者看不明白,这里需要结合代码分析。、
启动命令参数 parse_args()
- 说明:对于 bool 参数,在启动命令中带 --bool_params 或者不带这个参数即可提现,不用具体赋值
| 参数 | 取值范围 | 默认值 | 说明 |
|---|---|---|---|
--no_prompt | bool | true | eval时是否移出prompts (不用few-shot prompting,训练默认都是用的,对比实验不用) |
--base_epochs | float | 1.0 | 第一次 iter 的 epoch |
--add_epochs | float | 0.2 | 不同 iter 中需要 add 的 epoch |
--few_shot_train | bool | false | 是否使用 few-shot 训练 |
--steady_grow | bool | false | 是否使用固定数量的 epoch |
--start_steps | float | 40.0 | 第一次外循环的步数(不同外循环步数可能不同) |
--exponential_grow | bool | false | 是否使用指数增长 |
--add_steps | float | 20.0 | steady_grow 配对参数,每次迭代中增加的步数 |
--grow_steps | float | 1.2 | exponential_grow 配对参数,每次迭代中按比例增长 |
--p_rationalization | float | 1.0 | 使用合理化的错误样本比例 |
--p_show_hint_save | float | 0.0 | 保存合理化提示的比例 [TODO] |
--rationalize | bool | false | 是否使用合理化 |
--start_iter | int | 1 | 起始迭代数 |
--n_iters | int | 64 | 外部循环迭代的最大次数 (论文中的外循环,使用多少次 STaR 微调) |
--copy_n | int | 0 | 每次迭代中需要复制的文件数 |
--n_train_samples | int | 10000 | 训练样本数 |
--gradient_accumulation_steps | int | 8 | 梯度累积的步数 Batch size |
--task | str | “commonsenseqa” | 运行的任务类型 ,论文中有 CommonsenseQA、GSM8K 两个数据集 |
--direct | bool | false | 是否直接预测(不使用scratchpad) |
--gen_length | int | 96 | 生成输出的长度 |
--sequence_count | int | 10 | 每个batch的平均序列数量 |
--base_model_location | str | “gs://checkpoint-bucket/step_383500/” | 微调模型的检查点路径 |
--dry_run | bool | false | 是否进行快速运行以可视化输出 |
--skip_eval | bool | false | 是否跳过评估(例如算术任务) |
训练epoch、step是否随着外循环迭代而增长?
epoch 控制参数:
step 控制参数:steady_grow、exponential_grow 或者都不选。三选一。选了 steady_grow、exponential_grow 分别还有一个配对的配置参数:add_steps、grow_steps(比例)。不选的话根据下面计算步数:
# Count data pointstotal_count = 0for cur_file in sorted(os.listdir(record_folder(cur_iter - 1)), key=lambda x: int(x.split('.')[0].split("_")[-1])):with open(f"{record_folder(cur_iter - 1)}/{cur_file}", encoding='utf-8') as train_file:train_file_text = train_file.read()total_count += len(train_file_text.split("\n\n"))print(len(train_file_text.split("\n\n")))train_epochs = args.base_epochs + args.add_epochs * (cur_iter - 1)cur_steps = int(total_count * train_epochs // (args.gradient_accumulation_steps * args.sequence_count))return cur_steps
配置文件
qa_base.json
configs/qa_base.json 是实验的基础配置文件,运行实验会复制这个 template 然后不断修改这里的 value。
{"layers": 28,"d_model": 4096,"n_heads": 16,"n_vocab": 50400,"norm": "layernorm","pe": "rotary","pe_rotary_dims": 64,"seq": 1536, // 模型上下文窗口长度"cores_per_replica": 8, // device_inference 中用到,模型并行的参数,模型要分散到多个cores上来进行模型的计算"per_replica_batch": 1, // device_inference 中用到,数据并行的参数,数据并行中每个模块并行的batch大小"gradient_accumulation_steps": 8, // 始终是 args.gradient_accumulation_steps"warmup_steps": 100,"anneal_steps": 300000,"lr": 1e-06,"end_lr": 1e-06,"weight_decay": 0.0,"total_steps": 383500, // 来自 get_n_steps(),有三种配置模式,见上面"tpu_size": 8,"p_rationalization": 1.0, // 始终是 args.p_rationalization"bucket": "checkpoint-bucket", // 模型 ckpt 存储桶名"model_dir": "full_qa_4", // 模型存储路径"train_set": "qa_train_4.index","val_set": {"index": "qa.val.index"},"eval_harness_tasks": ["lambada","piqa","hellaswag","winogrande","mathqa","pubmedqa"],"val_batches": 100,"val_every": 10000,"ckpt_every": 10000,"keep_every": 10000,"name": "slow_grow_full_epoch_0", // 这里会不断修改为 "{experiment_name}_0""wandb_project": "full_6", // wandb是一个日志服务,这里是日志记录的所属项目"comment": "","target_save_folder": "commonsenseqa/iterative_full/iterative_full_0", // 文件存储所在文件夹路径"target_save": "commonsenseqa/slow_grow_full_epoch/slow_grow_full_epoch_0/slow_grow_full_epoch_0.txt" // 文件存储位置:文件和 name 同名,target_save_folder+name+".txt"}
训练核心代码

外层调用:iteration_train.py
调用侧代码(iteration_train.py):
# main:for cur_iter in range(1, args.n_iters): # 论文中的外循环迭代次数,重复多少次 STaR 微调方法exp_iteration = f"{experiment_name}_{cur_iter}"gen_train() # Generate the training set (第一次不执行)train_set = gen_records() # Create the tfrecords from the data # "{experiment_name}/{exp_iteration}.index"config_name = gen_config(train_set) # Create the new configuration file # 核心是修改 total_stepstrain_model() # Train the new model
在训练前,需要先生成训练数据集(rationale generation)。核心是:gen_train(),然后通过 train_model() 开始微调模型。
def gen_records():gen_cmd = f'python3 create_finetune_tfrecords.py {record_folder(cur_iter - 1)} {record_folder(cur_iter - 1)}'print(f"Creating records for finetuning {cur_iter}: {gen_cmd}")if not args.dry_run and (cur_iter >= args.start_iter):os.system(gen_cmd)train_set = f"{experiment_name}/{exp_iteration}.index"with open(f"data/{train_set}", "w") as new_data_file:new_data_file.write(f"{record_folder(cur_iter - 1)}.tfrecords")return train_set
def train_model():model_cmd = f"python3 device_train.py --config {config_name} --tune-model-path={args.base_model_location}"print(f"Train model {cur_iter}: {model_cmd}")if not args.dry_run and (cur_iter >= args.start_iter):os.system(model_cmd)
rationale generation 代码 gen_train:device_inference.py
device_inference.py
| 参数 | 取值范围 | 默认值 | 说明 |
|---|---|---|---|
--config | str | None | 配置文件路径 |
--direct | bool | false | 是否直接预测(不使用scratchpad) |
--rationalize | bool | false | 是否使用合理化 |
--no_prompt | bool | false | eval时是否移出prompts (不用few-shot prompting,训练默认都是用的,对比实验不用) |
--few_shot_train | bool | false | 训练时是否移除few-shot-prompts |
--show_hint_prompt | bool | false | 是否需要提示提示 |
--split | str | “dev” | split的数据集(train,dev) gen_train里是–split=train,eval_model 里是 dev |
--dataset_mode | str | “cqa” | 使用的数据集(注意cqa在另一个文件默认值是全写,有代码做了兼容,这里默认值不能改,必须是cqa) |
--n_train_samples | int | 3000 | 训练样本数量 |
--gen_length | int | 96 | 生成长度 |
--eval_batch_size | int | 8 | 评估时的批量大小 |
--p_show_hint_save | float | 0.0 | 保存合理化提示的比例 |
--ckpt_step | int | -1 | 要评估的检查点,-1表示最终检查点 |
--eval_seq | int | -1 | 序列长度,-1表示使用参数文件中的配置 (seq是模型上下文tokens最大长度) |
此时传入的参数是:
- prev_config:用的上次迭代的配置,因为这里用上一次学习好的模型来生成数据集;
- gen_length 输出长度;
if args.no_prompt:eval_seq = 128 + args.gen_length
如果按默认值,这里gen_length是128+96=224
- p_show_hint_save:合理化相关的参数
- n_train_samples:训练样本,默认是 10000(论文里始终保持这个数)
def gen_train():train_cmd = f"python3 device_inference.py --config={prev_config} --split=train --gen_length={args.gen_length} --p_show_hint_save={args.p_show_hint_save} "if task != "commonsenseqa":train_cmd += f" --dataset_mode={task} "if args.rationalize:train_cmd += " --rationalize "if args.few_shot_train:train_cmd += " --few_shot_train "if cur_iter > 1 and args.no_prompt:train_cmd += f" --no_prompt --eval_seq {eval_seq} "train_cmd += f" --n_train_samples={args.n_train_samples} "train_cmd += f" >> result_logs/{experiment_name}.txt"print(f"Generating training set {cur_iter} using model {cur_iter - 1}: {train_cmd}")if not args.dry_run and (cur_iter >= args.start_iter):if (cur_iter == 1) and os.path.exists(record_folder(0) + f"/{experiment_name}_0.txt"):print("First file cached") # 第一次不执行else:os.system(train_cmd)
注意:第一次运行 gen_train 的时候不执行,需要先微调后才执行合理化。
接下来分析 device_inference.py 中的代码:
if __name__ == "__main__":# 参数解析args = parse_args()print(args)split = args.split # 'dev'params = json.load(smart_open(args.config)) # smart_open 是一个用于打开文件的函数,支持多种文件格式和存储后端,本地文件,aws s3,gcs 等等# 初始化 wandbproject = params.get("wandb_project", "mesh-transformer-jax") # 日志服务所属的项目,随便什么值,这里不重要experiment_details = params["name"].split("_")wandb_name = "_".join(experiment_details[:-1])wandb_iteration = int(experiment_details[-1])wandb.init(project=project, name=wandb_name, config=params, resume=True) # resume=True: 表示如果有相同名称的实验已经存在,则恢复该实验的状态,而不是创建一个新的实验。# 根据配置加载不同的 prompt 设置prompts_file = "prompts.txt" if not args.direct else "prompts_direct.txt" # 默认不带 direct,即用带 few-shot 和 rationales 的 promptprompts_file = f"{args.dataset_mode}/{prompts_file}" if args.no_prompt:commonsense_prompts = []else:with basic_open(prompts_file) as prompts:commonsense_prompts = prompts.read().split("\n\n")prompts_hint_file = "prompts_answer_key.txt" if not args.direct else "prompts_direct_answer_key.txt"prompts_hint_file = f"{args.dataset_mode}/{prompts_hint_file}"if args.no_prompt and not args.show_hint_prompt:commonsense_prompts_hint = []else:with basic_open(prompts_hint_file) as prompts:commonsense_prompts_hint = prompts.read().split("\n\n")# 参数设置per_replica_batch = params["per_replica_batch"] # 数据并行参数:1cores_per_replica = params["cores_per_replica"] # 模型并行参数:模型并行中的每个 replica 的核心数,默认是 8target_save = params["target_save"] if split != "dev" else f'{args.dataset_mode}/new_dev.txt'seq = params["seq"] if args.eval_seq == -1 else args.eval_seqhint_seq = seqset_opt(params)mesh_shape = (jax.device_count() // cores_per_replica, cores_per_replica) # (replica 数量,每个 replica 的核心数)devices = np.array(jax.devices()).reshape(mesh_shape) # 为每个 replica 划分 cores,形成一个资源分配矩阵ckpt_path = get_ckpt_path(params, args.ckpt_step) # 默认用最新的 ckptwith jax.experimental.maps.mesh(devices, ('dp', 'mp')): # 并行策略的维度:dp,数据并行,mp,模型并行network = load_model(params, ckpt_path, devices, mesh_shape)dataset = get_dataset(args)dataset_keys = set([datakey for datakey, _ in dataset])total_batch = per_replica_batch * jax.device_count() // cores_per_replica * args.eval_batch_size # 数据并行侧,一次性输入的数据 batch 大小gen_params = {"top_p": np.ones(total_batch) * 0.9, "temp": np.ones(total_batch) * 0.01} # top_p: 控制生成文本的多样性的一种采样策略, Nucleus Sampling; temp: 温度参数,用于控制生成文本的随机性。温度越高,生成的文本越随机;温度越低,生成的文本越确定。accurate_count = eval_examples(dataset, commonsense_prompts, commonsense_prompts_hint, direct=args.direct)for cur_key, cur_counts in accurate_count.items():print(f"{split}, {cur_key}, {get_score(cur_counts)}")wandb.log({f"{split}_{cur_key}_accuracy": get_score(cur_counts), "iteration": wandb_iteration})- 最开始,参数解析,注意一方面参数来自于外层调用传入的(前文分析了),另一部分来自配置文件 json;
- 初始化 wandb:Weights & Biases(通常简称为 WandB)是一个用于机器学习实验管理和可视化的工具。它提供了一系列功能,帮助研究人员和开发者更好地跟踪、管理和可视化他们的机器学习实验。
- 然后是根据配置加载不同的 prompt 设置
- arg.direct:不用带 rationales 的 prompt,默认是用;
- 加载不带合理化(但有rationales或者无rationales的配置)/ 或者不使用 few-shot;
- 加载带合理化(hint)的 prompt (且带有 rationales);
- 然后是从config读一些配置:注意数据集分 train、dev
# seq 是模型上下文窗口长度,input tokens 不能超过这个
seq = params["seq"] if args.eval_seq == -1 else args.eval_seq
hint_seq = seq
"cores_per_replica": 8, // device_inference 中用到,模型并行的参数,模型要分散到多个cores上来进行模型的计算"per_replica_batch": 1, // device_inference 中用到,数据并行的参数,数据并行中每个模块并行的batch大小
- replica 指的应该是大模型并行的其中一个部分。per_replica_batch 是数据并行的参数。cores_per_replica 是每个 replia 分配的核心数,是模型并行的参数,模型要分散到多个cores上来进行模型的计算。
- 数据并行:数据并行是将训练数据分割成多个小批次,并在多个设备上并行处理这些小批次。每个设备都有一个完整的模型副本,计算梯度后再进行参数更新。
- 模型并行:模型并行是将一个模型的不同部分分布在多个计算设备上。适用于模型非常大,以至于单个设备无法容纳整个模型的情况。
mesh_shape = (jax.device_count() // cores_per_replica, cores_per_replica) # (replica 数量,每个 replica 的核心数)devices = np.array(jax.devices()).reshape(mesh_shape) # 为每个 replica 划分 cores,形成一个资源分配矩阵ckpt_path = get_ckpt_path(params, args.ckpt_step) # 默认用最新的 ckptwith jax.experimental.maps.mesh(devices, ('dp', 'mp')): # 并行策略的维度:dp,数据并行,mp,模型并行
注意:eval_batch_size 主要是 cache 样本,样本缓存到这个数,才执行(减少模型io开销)。
eval_examples
def eval_examples(data_examples, few_shot_prompts, few_shot_prompts_hint, direct=False):accurate_count = {}tokenizer = transformers.GPT2TokenizerFast.from_pretrained('gpt2')main_examples, hint_examples = [], []pbar = tqdm(data_examples, smoothing=0)for data_example in pbar: # 逐个遍历:而单个样本的执行和合理化样本的执行都是 cache 到一个 batch 再执行main_examples.append(data_example)if len(main_examples) == args.eval_batch_size: # 默认值 8successful_examples = eval_batch( # 评估main_examples, few_shot_prompts, seq, tokenizer,args.gen_length, gen_params, accurate_count, target_save, direct=direct)for example_idx, example in enumerate(main_examples):if (example_idx not in successful_examples) and (random.random() < params.get('p_rationalization', 1.)): # p_rationalization 默认值是 1hint_examples.append(example) # 如果回答失败,加入 hint 合理化样本中main_examples = [] # 清空队列if args.rationalize and len(hint_examples) >= args.eval_batch_size: # 合理化cur_hint_examples = hint_examples[:args.eval_batch_size]cur_hint_examples = [ # hint 样本修改 key(hint_example_key + "_r", hint_example) for hint_example_key, hint_example in cur_hint_examples]eval_batch( # 评估cur_hint_examples, few_shot_prompts_hint, hint_seq, tokenizer,args.gen_length, gen_params, accurate_count, target_save, hint=True, direct=direct # 开启 hint 合理化)hint_examples = hint_examples[args.eval_batch_size:] # 清空当前合理化的样本pbar.set_description(f"{split} " + ", ".join([f"{cur_key}: {get_score(cur_counts):0.4f}" for cur_key, cur_counts in accurate_count.items()]))return accurate_count
eval_batch
def eval_batch(examples, few_shot_prompts, seq, tok, gen_length, gen_params, accuracy, target_save, hint=False, direct=False):batch = examples_to_batch(examples, few_shot_prompts, seq, tok, hint=hint, direct=direct, p_show_hint_save=args.p_show_hint_save) # 把example批处理成合适的promptoutput = network.generate(batch["padded_batch"], batch["lengths"], gen_length, gen_params) # 实际上执行输出的代码return eval_output( # 评估输出结果,记录回答正确的样本output, batch["answers"], batch["base_context"], batch["classes"], accuracy, target_save, tok, direct=direct)def examples_to_batch(data_examples, few_shot_prompts, seq, tokenizer, hint=False, direct=False, p_show_hint_save=0.1):batch = {"base_context": [],"initial_batch": [],"lengths": [],"padded_batch": [],"answers": [],"classes": [] # 分类}for data_class, data_example in data_examples:batch['classes'].append(data_class)# Context, without the few-shot prompthintless_base_context = question_to_context(data_example, hint=False, dataset_mode=args.dataset_mode, direct=direct) # 不带 hintbase_context = question_to_context(data_example, hint=hint, dataset_mode=args.dataset_mode, direct=direct)if args.dataset_mode == "arithmetic":few_shot_prompts = base_context.split("\n\n")[:-1]base_context = base_context.split("\n\n")[-1]hintless_base_context = hintless_base_context.split("\n\n")[-1]if random.random() < p_show_hint_save: # 默认是 0hintless_base_context = base_context# We always want to act as if no hint was givenif args.few_shot_train:if args.dataset_mode == "arithmetic":raise NotImplementedErrorelse:save_context = "\n\n".join(commonsense_prompts) + "\n\n"save_context += hintless_base_contextbatch['base_context'].append(save_context)else:batch['base_context'].append(hintless_base_context)# Input tokensif args.no_prompt:context = ""else:context = "\n\n".join(few_shot_prompts) + "\n\n" # 最终prompt部分 1:默认带 few-shotcontext += base_context # 最终prompt部分 2:当前问题(可能带有合理化)tokens = tokenizer.encode(context) # tokenizerbatch['initial_batch'].append(tokens)# Input lengthsbatch['lengths'].append(len(tokens))# Padded tokensprovided_ctx = len(tokens)pad_amount = max(seq - provided_ctx, 0) # seq 是最大窗口长度,如果不够这个长度需要 padif provided_ctx > seq:tokens = tokens[-seq:] # 如果超出,需要截断batch['padded_batch'].append(np.pad(tokens, ((pad_amount, 0),)).astype(np.uint32))# Answerif args.dataset_mode == "arithmetic":if len(data_example.split("\n")) >= 3:target = data_example.split("\n")[-3]else:target = "invalid"elif args.dataset_mode == "cqa":target = data_example['answerKey']elif args.dataset_mode == "gsm":target = data_example['answer'].split("#### ")[-1]batch['answers'].append(target)batch["lengths"] = np.asarray(batch["lengths"], dtype=np.uint32)batch["padded_batch"] = np.array(batch["padded_batch"])return batch
def question_to_context(data_example, hint=False, dataset_mode='cqa', direct=False):""""将问题转为 prompt- hint: 是否开启合理化"""if dataset_mode == 'cqa':context = f"Q: {data_example['question']['stem']}\nAnswer Choices:\n"for choice in data_example['question']['choices']:if hint and (choice['label'].lower() == data_example['answerKey'].lower()):context += f"({choice['label'].lower()}) {choice['text']} (CORRECT)\n"else:context += f"({choice['label'].lower()}) {choice['text']}\n"context += "A:"elif dataset_mode == 'gsm':context = f"Q: {data_example['question']}"if hint:chosen_hint = data_example['answer'] # gsm 竟然直接把答案作为 hintcontext += f" ({chosen_hint})"context += "\nA:"elif dataset_mode == "arithmetic":context = ""for example_split, next_example_split in zip(data_example.split('Target:')[:-1], data_example.split('Target:')[1:]):if direct and "</scratch>" in example_split:context += example_split.split("</scratch>")[-1]else:context += example_splitcontext += "Target:"if hint:context += " " + next_example_split.split("\n")[-5]return context
eval_output
def eval_output(output, answers, context, example_classes, accuracy, target_save, tokenizer, show=False, direct=False, endoftext="<|endoftext|>"):"""评估输出结果,统计准确率,并将成功的示例保存到指定文件中。参数:- output (list): 模型的输出结果。- answers (list): 正确答案列表。- context (list): 上下文列表。- example_classes (list): 示例类别列表。- accuracy (dict): 用于统计准确率的字典。- target_save (str): 成功示例保存的文件路径。- tokenizer (transformers.PreTrainedTokenizer): 用于处理文本的分词器。- show (bool, optional): 是否打印成功示例到控制台。默认为 False。- direct (bool, optional): 是否使用直接预测,跳过scratchpad。默认为 False。- endoftext (str, optional): 用于标记文本结束的字符串。默认为 "<|endoftext|>"。返回:- list: 成功示例的索引列表。"""successful_examples = []enum_outputs = enumerate(output[1][0][:, :, 0])for (idx, o), target, cur_base_context, example_class in zip(enum_outputs, answers, context, example_classes):cur_output = tokenizer.decode(o)output_numbers = cur_output.split('\n')if example_class not in accuracy:accuracy[example_class] = {'accurate': 0, 'total': 0}accuracy[example_class]['total'] += 1if len(output_numbers) == 0:continuetry:if args.dataset_mode == "cqa":output_numbers = output_numbers[0]if "<|endoftext|>" in output_numbers:output_numbers = output_numbers.split("<|endoftext|>")[0]output_prediction = output_numbers[-3] # 选项elif args.dataset_mode == "gsm":output_prediction = ""for line_idx, line in enumerate(output_numbers):if "####" in line:output_numbers = "\n".join(output_numbers[:line_idx + 1])if "<|endoftext|>" in output_numbers:output_numbers = output_numbers.split("<|endoftext|>")[0]output_prediction = output_numbers.split("####")[-1].strip()breakelif args.dataset_mode == "arithmetic":if len(output_numbers) == 0:continueelif "<|endoftext|>" in output_numbers:prediction_index = output_numbers.index("<|endoftext|>") - 1elif "</scratch>" in output_numbers:prediction_index = output_numbers.index("</scratch>") + 1if prediction_index == len(output_numbers):continueelse:if direct and len(output_numbers) > 1:prediction_index = 1else:prediction_index = 0output_prediction = output_numbers[prediction_index] # 计算结果if "<|endoftext|>" in output_prediction:output_prediction = output_prediction.split("<|endoftext|>")[0]correct = output_prediction.lower() == target.lower() # 判断输出是否和目标一致if correct:accuracy[example_class]['accurate'] += 1 # 回答正确,计数++with basic_open(target_save, 'a+') as new_train_f:if args.dataset_mode == "cqa" or args.dataset_mode == "gsm":new_example = cur_base_context + output_numbers + endoftext # 正确回答的样本作为新的训练样本elif args.dataset_mode == "arithmetic":if args.few_shot_train:raise NotImplementedErrorjoined_output = "\n".join(output_numbers[:prediction_index + 1])if "<|endoftext|>" in joined_output:joined_output = joined_output.split("<|endoftext|>")[0]new_example = cur_base_context + joined_output + endoftext # 正确回答的样本作为新的训练样本if show:print(new_example)print(new_example, file=new_train_f, end="") # 把回答正确的样本写入文件中successful_examples.append(idx)except IndexError:passreturn successful_examples
合理化部分代码总结
结合代码以及论文解读[NeurlPS 2022] STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning 现在重新来理解论文。
论文基本思路是,先给出few-shot,让模型参考few-shot在回答answer前带上rationales,如果回答不正确,就加上hint回答,最终把回答正确的样本留下进行下一轮微调。
在具体代码实现上,首先在 eval_examples 中,对样本做了个 batch 级别的 cache,每满8个,才执行对应的推理(回答)。这里维护了两个cache 队列,一个是回答正确的队列,一个是直接回答失败的队列(因此,用合理化修改了原始prompt)。两个队列分别满8时分别执行重新的回答操作,具体是在 eval_batch 中实现。先通过 examples_to_batch 对 batch 样本批量处理prompt,比如加上few-shot template 等等(或者加上hint)。然后批量推理。然后通过eval_output评估是否回答正确。如果没有回答正确,那么加入hint的样本中。所有回答正确的样本都会保存作为下一次微调的数据集【注意,对于合理化的样本,保存的问题不带hint】。
所以,根据这个实现,再回答阅读论文中的问题:

注意:这个标里的细节。文字部分说“Note the final STaR model is trained on 78.2% of the training dataset with rationale generation, and an additional 8.5% from rationalization”,而表格里不带合理化的STaR准确率只有68.8%,这里78.2%和68.8%有个差值!这里要怎么理解:因为带有合理化后,fine tune,导致模型处理hard问题的能力提升,所以在之后的实验中,部分问题不需要合理化就可以解出,所以涨了近10个点。
相关文章:
[NeurlPS 2022] STaR 开源代码实现解读
STaR 方法代码开源,这里给出一个中文代码解读地址:repo入口点:iteration_train.py;关键代码:device_train.py, device_inference.py, and create_finetune_tfrecords.py;基于 JAX、RAY,在 Googl…...

Android笔记【15】跳转页面返回信息
一、问题 学习一段代码 val intent Intent(thisSecondActivity, MainActivity::class.java) intent.putExtra("extra_data", data) startActivity(intent) 二、内容 这段代码是在 Android 应用中启动一个新的活动(Activity),具…...

使用 Qt 打造高效的 .run 软件包管理器
在软件开发领域,.run 软件包因其便携性和自解压特性而备受青睐,特别是由 makeself 工具生成的 .run 软件包。这些软件包通常包含一个完整的程序或库,以及一个用于解压和安装的脚本。然而,手动管理这些软件包(尤其是进行…...
python学opencv|读取视频(二)制作gif
【1】引言 前述已经完成了图像和视频的读取学习,本次课学习制作gif格式动图。 【2】教程 实际上想制作gif格式动图是一个顺理成章的操作,完成了图像和视频的处理,那就自然而然会对gif的处理也产生兴趣。 不过在opencv官网、matplotlib官网…...

19. Three.js案例-创建一个带有纹理映射的旋转平面
19. Three.js案例-创建一个带有纹理映射的旋转平面 实现效果 知识点 WebGLRenderer (WebGL渲染器) WebGLRenderer 是 Three.js 中用于渲染场景的主要类。它利用 WebGL 技术在浏览器中绘制 3D 图形。 构造器 new THREE.WebGLRenderer(parameters)参数类型描述parametersobj…...

ASP.NET|日常开发中常用属性详解
JAVA |日常开发中常用属性详解 前言一、控件属性(以 TextBox 控件为例)1.1 Text 属性:1.2 MaxLength 属性:1.3 ReadOnly 属性:1.4 IsPostBack 属性(在ASP.NET Web Forms 中)…...

vscode CMakeLists中对opencv eigen的引用方法
CMakeLists.txt 项目模式(只有一个main函数入口) cmake_minimum_required(VERSION 3.5)project(vsin01 VERSION 0.1 LANGUAGES CXX)set(CMAKE_CXX_STANDARD 17) set(CMAKE_CXX_STANDARD_REQUIRED ON)set(OpenCV_DIR G:/MinGW_Opencv/opencv4.10/opencv…...

使用Goland对6.5840项目进行go build出现异常
使用Goland对6.5840项目进行go build出现异常 Lab地址: https://pdos.csail.mit.edu/6.824/labs/lab-mr.html项目地址: git://g.csail.mit.edu/6.5840-golabs-2024 6.5840运行环境: mac系统 goland git clone git://g.csail.mit.edu/6.5840-golabs-2024 6.5840 cd 6.5840/src…...

Plugin - 插件开发06_开源项目JPom中的插件实现机制
文章目录 Pre工程结构概述1. 插件接口与实现分析2. 插件工厂初始化分析3. 插件项包装类解析4. 插件工厂方法解析5. 插件加载与资源释放机制6. 实现类小结附PluginFactory Pre 插件 - 通过SPI方式实现插件管理 插件 - 一份配置,离插件机制只有一步之遥 插件 - 插件…...

关于成功插入 SQLite 但没有数据的问题
背景 技术栈:SpringBoot Mybatis-flex SQLite 项目中集成了SQLite,配置如下: spring:datasource:url: jdbc:sqlite::resource:db/project.dbdriver-class-name: org.sqlite.JDBC在进行测试时,使用Mybatis-flex往表中插入数据&…...

单片机+Qt上位机
目录 一、引言 通信方式 优势 案例 常见问题及解决方法 二、单片机与 Qt 上位机的通信方式 (一)使用 QT 上位机和 STC 单片机实现串口通信 三、单片机 Qt 上位机的优势 (一)高效便捷的 USB 通信上位机解决方案 …...

C++ 类和对象(中)
1.类的六个默认成员函数 如果一个类中什么成员都没有,简称为空类。 空类中真的什么都没有吗?其实并不是,任何类在什么都不写时,编译器会自动生成以下六个默认成员函数。 默认成员函数:用户没有显式实现,编…...

在做题中学习(79):最小K个数
解法:快速选择算法 说明:堆排序也是经典解决问题的算法,但时间复杂度为:O(NlogK),K为k个元素 而将要介绍的快速选择算法的时间复杂度为: O(N) 先看我的前两篇文章,分别学习:数组分三块&#…...

spark3 sql优化:同一个表关联多次,优化方案
目录 1.合并查询2.使用 JOIN 条件的过滤优化3.使用 Map-side Join 或 Broadcast Join4.使用 Partitioning 和 Bucketing5.利用 DataFrame API 进行优化假设 A 和 B 已经加载为 DataFramePerform left joins with specific conditions6.使用缓存或持久化7.避免笛卡尔积总结 1.合…...

JavaWeb学习(4)(四大域、HttpSession原理(面试)、SessionAPI、Session实现验证码功能)
目录 一、web四大域。 (1)基本介绍。 (2)RequestScope。(请求域) (3)SessionScope。(会话域) (4)ApplicationScope。(应用域) (5)PageScope。(页面域) 二、Ht…...

Ubuntu22.04系统源码编译OpenCV 4.10.0(包含opencv_contrib)
因项目需要使用不同版本的OpenCV,而本地的Ubuntu22.04系统装了ROS2自带OpenCV 4.5.4的版本,于是编译一个OpenCV 4.10.0(带opencv_contrib)版本,给特定的项目使用,这就不用换个设备后重新安装OpenCV 了&…...

【Unity高级】在编辑器中如何让物体围绕一个点旋转固定角度
本文介绍如何在编辑器里让物体围绕一个点旋转固定角度,比如上图里的Cube是围绕白色圆盘的中心旋转45度的。 目标: 创建一个在 Unity 编辑器中使用的旋转工具,使开发者能够在编辑模式下快速旋转一个物体。 实现思路: 编辑模式下…...

2024.11.29——[HCTF 2018]WarmUp 1
拿到题,发现是一张图,查看源代码发现了被注释掉的提示 <!-- source.php--> step 1 在url传参看看这个文件,发现了这道题的源码 step 2 开始审计代码,分析关键函数 //mb_strpos($haystack,$needle,$offset,$encoding):int|…...

AGameModeBase和游戏模式方法
AGameModeBase和游戏模式方法有着密切的关系: AGameModeBase是游戏模式的基础类: 它提供了控制游戏规则的基本框架包含了一系列管理游戏流程的核心方法是所有自定义游戏模式类的父类 主要的游戏模式方法包括: // 游戏初始化时调用 virtua…...

Swift 扩展
Swift 扩展 Swift 是一种强大的编程语言,由苹果公司开发,用于iOS、macOS、watchOS和tvOS应用程序的开发。自2014年发布以来,Swift因其易于阅读和编写的语法、现代化的设计以及出色的性能而广受欢迎。本文将探讨Swift的一些关键特性ÿ…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

鸿蒙HarmonyOS 5军旗小游戏实现指南
1. 项目概述 本军旗小游戏基于鸿蒙HarmonyOS 5开发,采用DevEco Studio实现,包含完整的游戏逻辑和UI界面。 2. 项目结构 /src/main/java/com/example/militarychess/├── MainAbilitySlice.java // 主界面├── GameView.java // 游戏核…...
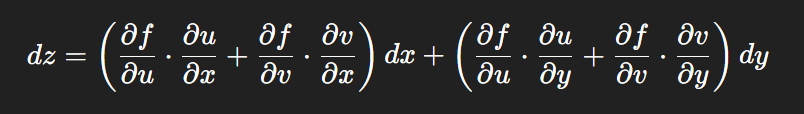
链式法则中 复合函数的推导路径 多变量“信息传递路径”
非常好,我们将之前关于偏导数链式法则中不能“约掉”偏导符号的问题,统一使用 二重复合函数: z f ( u ( x , y ) , v ( x , y ) ) \boxed{z f(u(x,y),\ v(x,y))} zf(u(x,y), v(x,y)) 来全面说明。我们会展示其全微分形式(偏导…...

SQL进阶之旅 Day 22:批处理与游标优化
【SQL进阶之旅 Day 22】批处理与游标优化 文章简述(300字左右) 在数据库开发中,面对大量数据的处理任务时,单条SQL语句往往无法满足性能需求。本篇文章聚焦“批处理与游标优化”,深入探讨如何通过批量操作和游标技术提…...

Ansible+Zabbix-agent2快速实现对多主机监控
ansible Ansible 是一款开源的自动化工具,用于配置管理(Configuration Management)、应用部署(Application Deployment)、任务自动化(Task Automation)和编排(Orchestration…...
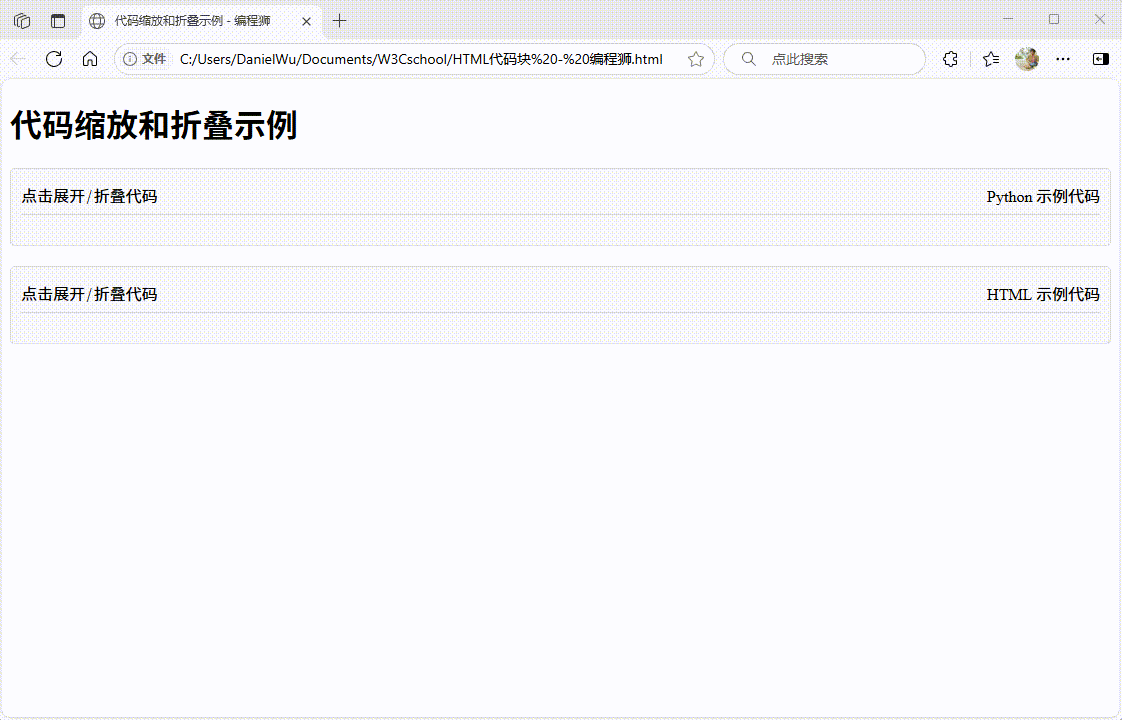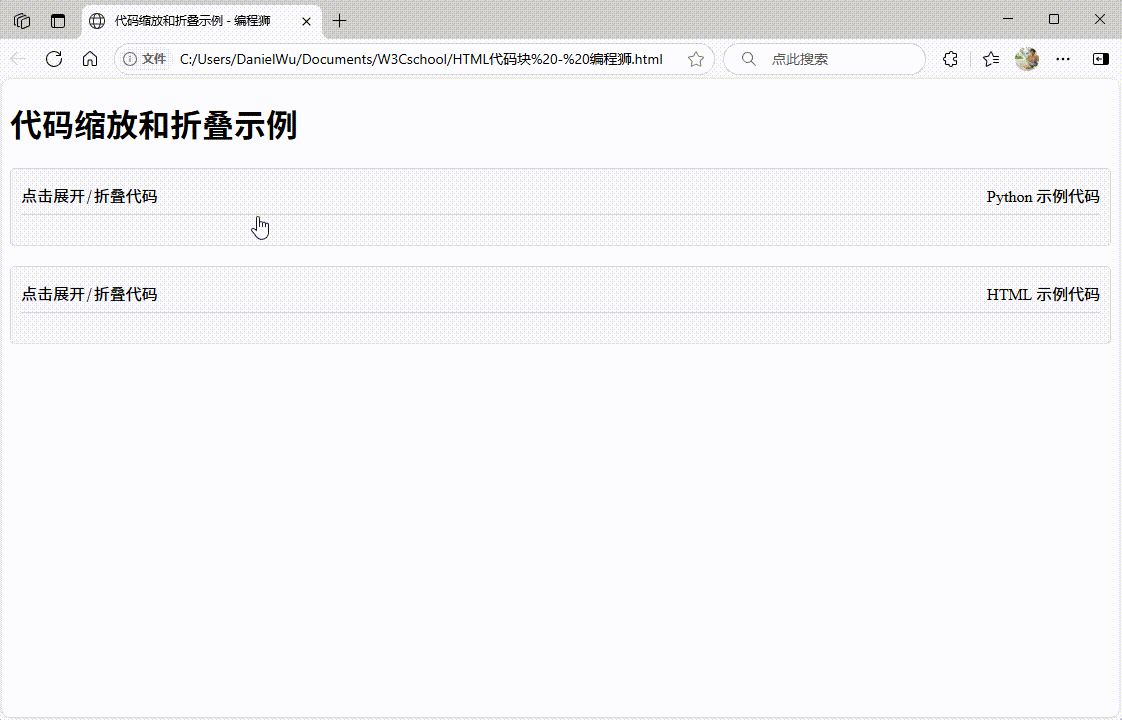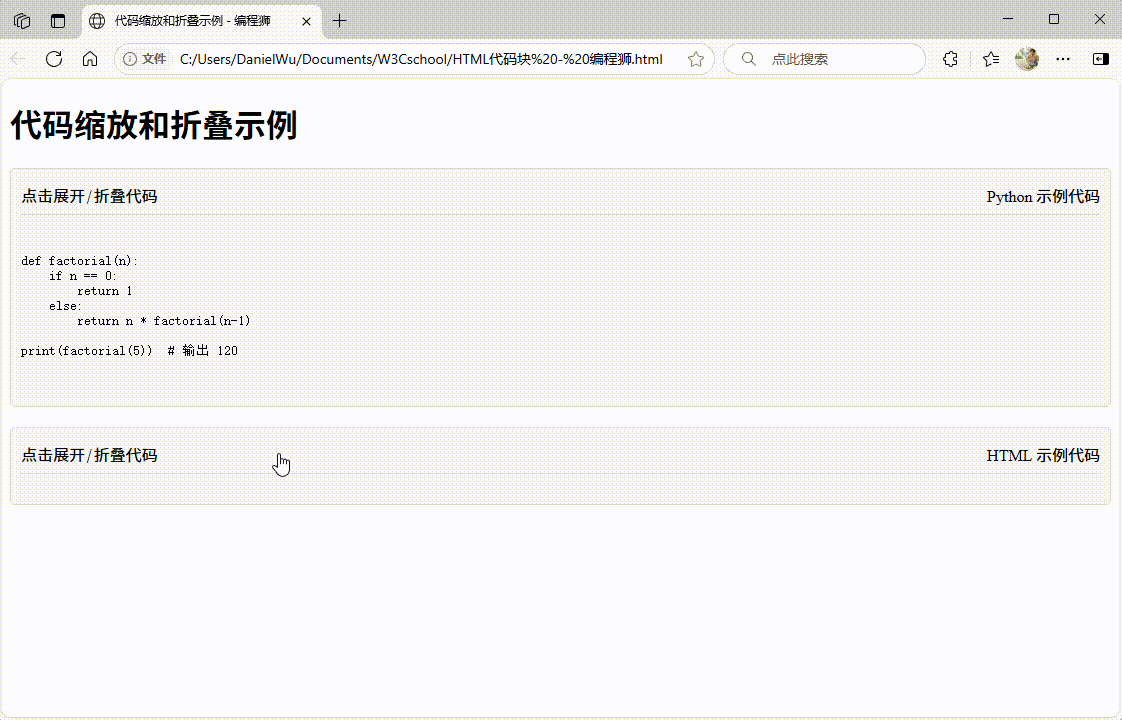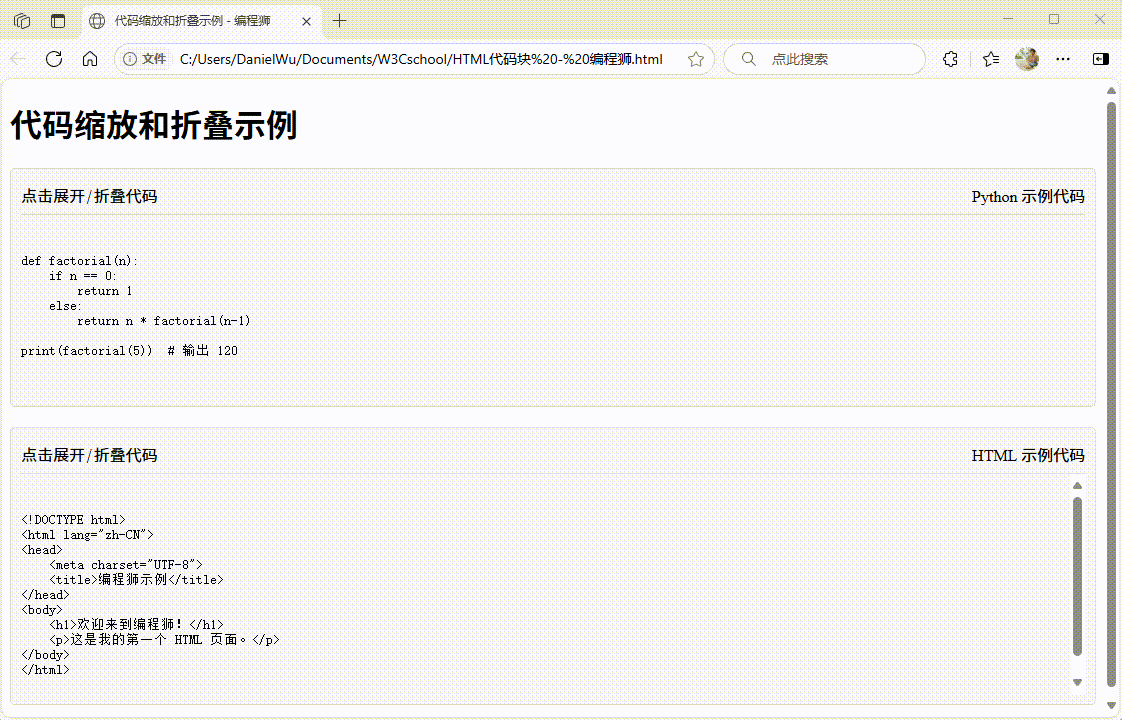
如何用 HTML 展示计算机代码
原文:如何用 HTML 展示计算机代码 | w3cschool笔记 (请勿将文章标记为付费!!!!) 在编程学习和文档编写过程中,清晰地展示代码是一项关键技能。HTML 作为网页开发的基础语言&#x…...