【机器学习算法】——数据可视化
1. 饼图:显示基本比例关系
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# ——————————————————————————————————————————————————————————
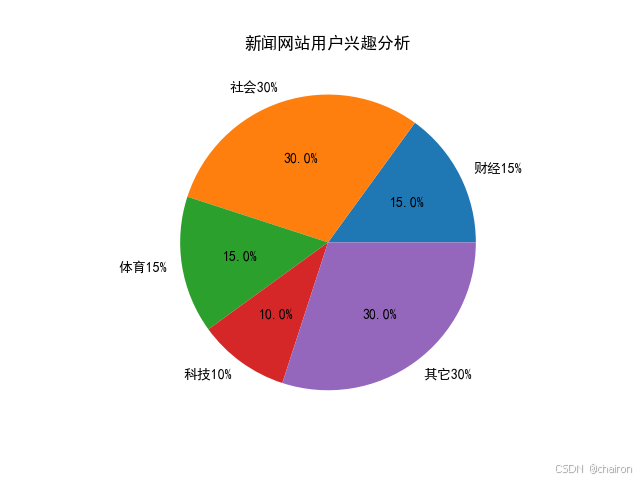
#1.饼图:显示基本比例关系# 定义饼图的标签,对应不同的用户兴趣类别
labels = '财经15%', '社会30%', '体育15%', '科技10%', '其它30%'# 定义饼图的大小,对应每个类别的用户兴趣比例
datas = [15, 30, 15, 10, 30]# 创建一个figure对象和axes对象,用于绘制饼图
fig1, ax1 = plt.subplots()
pie = ax1.pie(datas, labels=labels, autopct='%1.1f%%')# 设置整个图表的标题
plt.title('新闻网站用户兴趣分析')# 显示图表
plt.show()
2. 堆叠柱形图
它将两个或多个变量的值在同一个轴上以堆叠的形式展示出来,使得观察者可以清晰地看到每个变量的总和以及它们各自的部分。
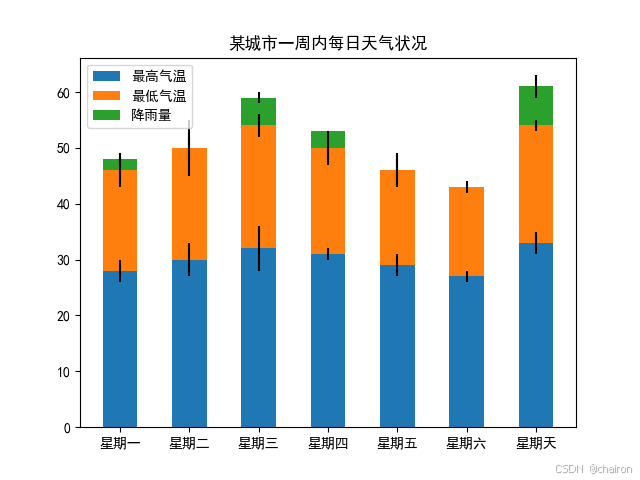
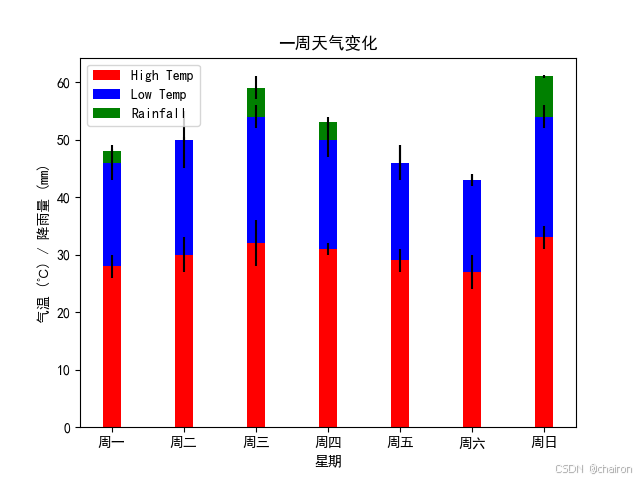
#练习2:某城市一周内每日天气状况
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 一周内每天的日期
days = ['周一', '周二', '周三', '周四', '周五', '周六', '周日']# 一周内每天的最高气温、最低气温和降雨量
high_temps = [28, 30, 32, 31, 29, 27, 33]
low_temps = [18, 20, 22, 19, 17, 16, 21]
rainfall = [2, 0, 5, 3, 0, 0, 7]# 使用arange函数生成一个数组,表示条形图的x坐标位置
x = np.arange(7)
# 设置柱状图的宽度
bar_width = 0.25# 误差条
high= (2, 3, 4, 1, 2,3,2)
low = (3, 5, 2, 3, 3,1,2)
rain= (0.3, 0.5, 2, 1, 3,1,0.2)
# 绘制柱状图
plt.bar(x, high_temps,color='red', width=bar_width,yerr=high, label='High Temp')
plt.bar(x, low_temps, bottom=high_temps,color='blue', width=bar_width, yerr=low, label='Low Temp')
plt.bar(x, rainfall, bottom=(np.array(low_temps)+np.array(high_temps)),color='green', width=bar_width, yerr=rain, label='Rainfall')# 添加图例
plt.legend()# 添加标题和标签
plt.xlabel('星期')
plt.ylabel('气温 (℃) / 降雨量 (mm)')
plt.title('一周天气变化')# 设置x轴的刻度标签
plt.xticks(x,('周一', '周二', '周三', '周四', '周五', '周六', '周日'))
# # 添加图例
# plt.legend((p1[0], p2[0], p3[0]), ('最高温度', '最低温度', '降雨量'))# 显示图形
plt.show()
3. 板块层级图
- 通常是一种用于展示不同板块之间层级关系或分类的图表,可以是组织结构图、分类图或其他类型的层级表示方法。
- 安装squarify:
pip install squarify
# 练习3:公司部门年度收入分布
import matplotlib.pyplot as plt
import squarify
# 定义部门和对应的收入
departments = ['技术部', '市场部', '人力资源部', '财务部']
revenues = [10, 15, 50, 30] # 转换为相同的数量级以方便计算
# 定义每个部门的颜色
colors = ['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728']
# 绘制板块层级图
squarify.plot(sizes=revenues, label=departments, color=colors, alpha=0.7)
plt.axis('off')
plt.title('公司部门年度收入分布')
plt.show()
4. 堆叠面积图
安装seaborn: pip install seaborn
- 用于显示每个数值所占大小随时间或类别变化的趋势线,展示的是部分与整体的关系。
- 堆叠面积图上的最大的面积代表了所有的数据量的总和,是一个整体。
- 各个叠起来的面积表示各个数据量的大小,这些堆叠起来的面积图在表现大数据的总量分量的变化情况时格外有用,所以堆叠面积图不适用于表示带有负值的数据集。非常适用于对比多变量随时间变化的情况。
import numpy as np
# 导入seaborn库,用于高级的统计图表绘制
import seaborn as snsx = range(21, 26)# 定义x轴的数据,这里表示年龄范围
# 定义y轴的数据,这里是一个二维数组,表示不同组在不同年龄的分值
y = [[10, 4, 6, 5, 3],[12, 2, 7, 10, 1],[8, 18, 5, 7, 6],[1, 8, 3, 5, 9]]
labels = ['组A', '组B', '组C', '组D']# 定义每个组的标签
pal = sns.color_palette("Set1")# 使用seaborn的color_palette函数生成一组颜色
# 使用plt.stackplot函数绘制堆叠面积图
plt.stackplot(x, y, labels=labels, colors=pal, alpha=0.7)# alpha参数指定透明度,colors=pal, alpha=0.7:可选项
plt.ylabel('分值')
plt.xlabel('年龄')
plt.title('不同组用户区间分值比较')
plt.legend(loc='upper right')
plt.show()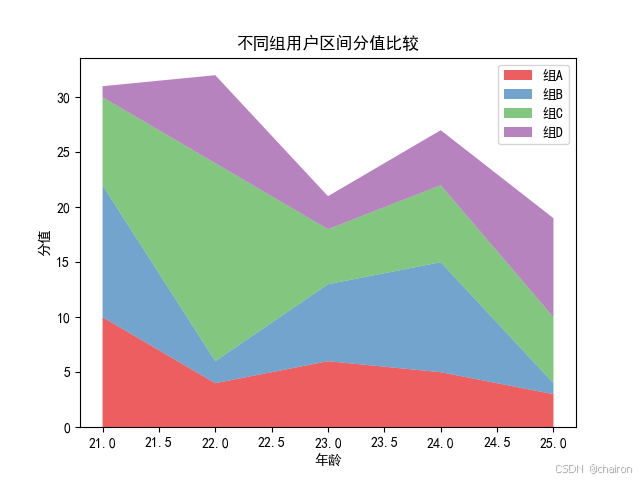
5. 散点图和气泡图
散点图(Scatter Plot)是一种用于显示两个变量之间关系的图表,通过在坐标平面上描绘点来展示数据的分布和趋势。
import numpy as np
import matplotlib.pyplot as plt
import randomplt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 设置随机种子,确保结果的可重现性
np.random.seed(42)# ------------------------------------------------------------------
#1.生成散点图
data = {'城市': ['A', 'B', 'C', 'D', 'E'],'温度': [22, 24, 26, 23, 25],'相对湿度': [60, 65, 70, 55, 68],}x = data['温度']
y = data['相对湿度']
print(x)
print(y)
# #气泡图需要修改颜色和大小
# #------------------------------
# color = np.random.rand(5)
color1 = ["red",'blue','yellow','black','green']
# size = np.random.rand(5)*1000#【0,1)-->[0,1000)
size1 = [100,20,30,600,400]
# #---------------------------------# 使用scatter函数绘制散点图,s=100表示点的大小,c='black'表示点的颜色为黑色,alpha=0.8表示点的透明度
# plt.scatter(x, y)
plt.scatter(x, y,s=size1,c=color1, alpha=0.6)plt.title("随机生成的数字散点")
plt.ylabel('Y坐标值')
plt.xlabel('X坐标值')
# 显示图表
plt.show()散点图:

气泡图:就是改变散点图的大小和颜色(随机生成)

6.直方图
一种用于展示数据分布特征的统计图表,它通过将数据分组并计算每组中的频数或频率来表示数据的分布情况。
##3.直方图:
"""用于展示数据分布特征的统计图表,
它通过将数据分组并计算每组中的频数或频率来表示数据的分布情况。"""
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
np.random.seed(19680801)mu = 100 # 均值
sigma = 15 # 标准差
x = mu + sigma * np.random.randn(500)# 根据正态分布生成随机样本数据num_bins = 10# 设置直方图的箱数fig, ax = plt.subplots()# fig是整个图形的容器,ax是图形的轴
ax.hist(x, num_bins, density=True, alpha=0.6,edgecolor='black')#density=True表示y轴显示概率密度而非计数
ax.set_xlabel('智商IQ')
ax.set_ylabel('概率密度')
ax.set_title(r'智商分布情况直方图')# plt.hist(x,num_bins,density=False)
# plt.xlabel('学生人数')
# plt.ylabel('考试成绩')
# plt.title('学生考试成绩分布')plt.show()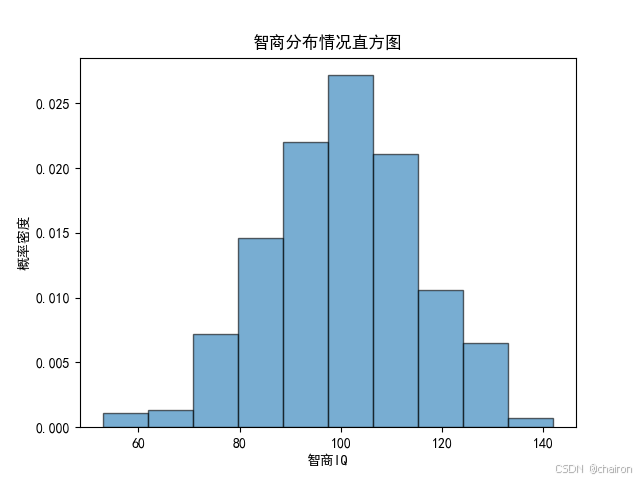
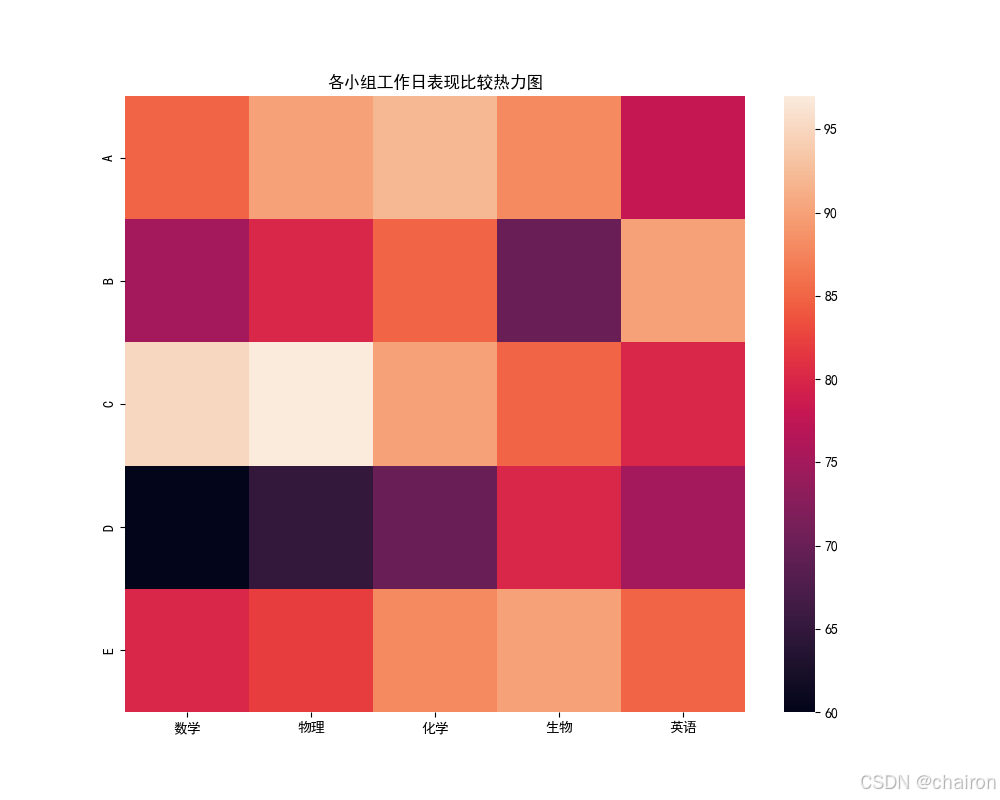
7. 热力图(heatmap)
是一种数据可视化技术,它通过颜色的变化来展示数据矩阵中数值的大小。
##4.heatmap热力图:通过颜色的变化来展示数据矩阵中数值的大小。
import seaborn as sns
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as pltplt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=Falsestudents = ['A', 'B', 'C', 'D', 'E']
subjects = ['数学', '物理', '化学', '生物', '英语']# 生成随机成绩数据
#np.random.seed(0) # 为了结果的可重复性
data = { '数学': [85, 75, 95, 60, 80],'物理': [90, 80, 97, 65, 82],'化学': [92, 85, 90, 70, 88],'生物': [88, 70, 85, 80, 90],'英语': [78, 90, 80, 75, 85]}print(data)# 创建DataFrame
df = pd.DataFrame(data, index=students,columns=subjects)
print(df)# 使用Seaborn绘制热力图
plt.figure(figsize=(10, 8))
sns.heatmap(df, xticklabels=subjects, yticklabels=students)
# 设置图表标题
plt.title('各小组工作日表现比较热力图')
# 显示图表
plt.show()
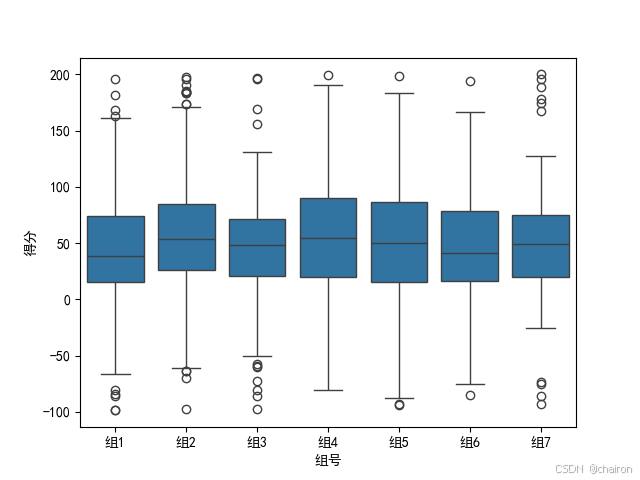
8. 箱型图
是一种非常有用的数据可视化工具,它不仅可以展示数据的中位数、四分位数,还可以直观地表示异常值,帮助用户快速了解数据的集中趋势、分散程度和异常情况。
#5.box:小组成员的得分情况
"""箱型图:展示数据的中位数、四分位数,还可以直观地表示异常值,
帮助用户快速了解数据的集中趋势、分散程度和异常情况。
"""
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import randomplt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号# 设置随机种子以确保结果的可重现性
np.random.seed(42)# 生成组号列表
day_list = ['组1', '组2', '组3', '组4', '组5', '组6', '组7']
day = [random.choice(day_list) for _ in range(1000)]#从day_list随机选取1000个数据存入day
print(day)
# 重新设置随机种子,生成数据(800个正常数据,200个离群数据)
np.random.seed(666)
spread = np.random.rand(800) * 100 # 生成800个0~100之间的随机数,np.random.rand(800) :800个[0,1)的数据
flier_high = np.random.rand(100) * 100 + 100 # 生成100个100~200之间的随机数
flier_low = np.random.rand(100) *100 -100 # 生成100个-100~0之间的随机数
# #
# # # 将数据合并为一个数组
data = np.concatenate((spread, flier_high, flier_low), 0)
# data1={'组号': day,
# '得分': data}
# # # 创建DataFrame
# df = pd.DataFrame(data1)
df = pd.DataFrame({'组号': day,'得分': data})
print(df)
# # 使用Seaborn绘制箱型图
sns.boxplot(x='组号', y='得分', data=df)
#
# # 设置x轴的刻度标签
# plt.xticks(range(len(day_list)), day_list)
plt.xticks(range(7), day_list)
#
# # 显示图表
plt.show()
相关文章:
【机器学习算法】——数据可视化
1. 饼图:显示基本比例关系 import matplotlib.pyplot as pltplt.rcParams[font.sans-serif] [SimHei] plt.rcParams[axes.unicode_minus] False# ——————————————————————————————————————————————————————…...

如何在 Android 项目中实现跨库传值
背景介绍 在一个复杂的 Android 项目中,我们通常会有多个库(lib),而主应用程序(app)依赖所有这些库。目前遇到的问题是,在这些库中,libAd 需要获取 libVip 的 VIP 等级状态…...

JavaCV之FFmpegFrameFilter视频转灰度
1、代码 package com.example.demo.ffpemg;import lombok.SneakyThrows; import org.bytedeco.javacv.*;public class FFmpegFrameFilterVideoExample {SneakyThrowspublic static void main(String[] args) {// 输入视频文件路径String inputVideoPath "f:/2222.mp4&qu…...

Redis:基于PubSub(发布/订阅)、Stream流实现消息队列
Redis - PubSub、Stream流 文章目录 Redis - PubSub、Stream流1.基于List的消息队列2.基于PubSub的消息队列3.基于Stream的消息队列1.Redis Streams简介2.Redis Streams基本命令1.XADD 添加消息到末尾2.XLEN 获取消息长度3.XREAD 读取消息 (单消费模式)4…...
)
C#飞行棋(新手简洁版)
我们要在主函数的顶部写一些全局静态字段 确保能在后续的静态方法中能够获取到这些值和修改 static int[] Maps new int[100];static string[] PlayerName new string[2];static int[] PlayerScore new int[2];static bool[] Flags new bool[2] {true,true }; static int[]…...

【OpenCV】图像转换
理论 傅立叶变换用于分析各种滤波器的频率特性。对于图像,使用 2D离散傅里叶变换(DFT) 查找频域。快速算法称为 快速傅立叶变换(FFT) 用于计算DFT。 Numpy中的傅立叶变换 首先,我们将看到如何使用Numpy查…...

力扣 重排链表-143
重排链表-143 /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next)…...
)
【Kubernetes理论篇】容器集群管理系统Kubernetes(K8S)
Kubernetes集群部署基本管理实战 这么好的机会,还在等什么! 01、Kubernetes 概述 K8S是什么 K8S 的全称为 Kubernetes (K12345678S),PS:“嘛,写全称也太累了吧,写”。不如整个缩写 K8s 作为缩写的结果…...

Kubernetes 常用操作大全:全面掌握 K8s 基础与进阶命令
Kubernetes(简称 K8s)作为一种开源的容器编排工具,已经成为现代分布式系统中的标准。它的强大之处在于能够自动化应用程序的部署、扩展和管理。在使用 Kubernetes 的过程中,熟悉常用操作对于高效地管理集群资源至关重要。本文将详…...

爬虫基础之Web网页基础
网页的组成 网页可以分为三大部分–HTML、CSS 和 JavaScript。如果把网页比作一个人,那么 HTML 相当于骨架、JavaScript 相当于肌肉、CSS 相当于皮肤,这三者结合起来才能形成一个完善的网页。下面我们分别介绍一下这三部分的功能。 HTML HTML(Hypertext…...

k8s, deployment
控制循环(control loop) for {实际状态 : 获取集群中对象X的实际状态(Actual State)期望状态 : 获取集群中对象X的期望状态(Desired State)if 实际状态 期望状态{什么都不做} else {执行编排动作…...

使用ensp搭建OSPF+BGP和静态路由,底层PC使用dhcp,实现PC互通
1.4种方式,实现PC2可以互通底层的所有设备 OSPF:OSPF是一种用于互联网协议网络的链路状态路由协议 BGP:是一种用于互联网上进行路由和可达性信息传递的外部网关协议(EGP) 静态路由: 静态路由是一种路由方…...

TÜLU 3: Pushing Frontiers in Open Language Model Post-Training
基本信息 📝 原文链接: https://arxiv.org/abs/2411.15124👥 作者: Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V. Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Sau…...

深入解读 MySQL EXPLAIN 与索引优化实践
MySQL 是当今最流行的关系型数据库之一,为了提升查询性能,合理使用 EXPLAIN 工具和优化索引显得尤为重要。本文将结合实际示例,探讨如何利用 EXPLAIN 分析查询执行计划,并分享索引优化的最佳实践。 一、EXPLAIN 工具简介 EXPLAIN …...

Flume——进阶(agent特性+三种结构:串联,多路复用,聚合)
目录 agent特性ChannelSelector描述: SinkProcessor描述: 串联架构结构图解定义与描述配置示例Flume1(监测端node1)Flume3(接收端node3)启动方式 复制和多路复用结构图解定义描述配置示例node1node2node3启…...

ragflow连ollama时出现的Bug
ragflow和ollama连接后,已经添加了两个模型但是ragflow仍然一直warn:Please add both embedding model and LLM in Settings > Model providers firstly.这里可能是我一开始拉取的镜像容器太小,容不下当前添加的模型,导…...

基于centos7.7编译Redis6.0
背景: OS:CentOs 7.7 Redis: 6.0.6 编译构建报错如下: In file included from server.c:30:0: server.h:1044:5: error: expected specifier-qualifier-list before ‘_Atomic’_Atomic unsigned int lruclock; /* Clock for LRU eviction …...

uni-app项目无法在Android Studio模拟器上运行
目录 1 问题描述2 尝试解决3 引发原因4 解决方法4.1 换用 MuMu 模拟器 5 结语 1 问题描述 在使用 uni-app 开发 Pad 端 App 时,初始化项目后打算先运行一下确保初始化正常。打开 Android Studio 模拟器后,然后在 HbuilderX 中选择使用 App 标准基座 运…...
)
第一部分:Linux系统(基础及命令)
Linux操作系统的实操性非常强,纯操作,不适用于日常的办公使用 1.初始Linux 1.1 操作系统概述 1.1.1 了解OS的作用 OS:是计算机软件的一种,主要负责:作为用户和计算机硬件之间的桥梁,调度和管理计算机硬…...

No module named ‘_ssl‘ No module named ‘_ctypes‘
如果你使用的是基于 yum 的 Linux 发行版(例如 CentOS、RHEL、Fedora),安装 libc6-dev 的方式稍有不同。在这些系统中,通常对应的包是 glibc-devel。 No module named ‘_ctypes’ 使用 yum 安装 glibc-devel 更新系统的软件包列…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

MinIO Docker 部署:仅开放一个端口
MinIO Docker 部署:仅开放一个端口 在实际的服务器部署中,出于安全和管理的考虑,我们可能只能开放一个端口。MinIO 是一个高性能的对象存储服务,支持 Docker 部署,但默认情况下它需要两个端口:一个是 API 端口(用于存储和访问数据),另一个是控制台端口(用于管理界面…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...