k8s 之 StatefulSet
深入理解StatefulSet(一):拓扑状态
k8s有状态与无状态的区别
无状态服务:deployment
Deployment被设计用来管理无状态服务的pod,每个pod完全一致.什么意思呢?
无状态服务内的多个Pod创建的顺序是没有顺序的. 无状态服务内的多个Pod的名称是随机的.pod被重新启动调度后,它的名称与IP都会发生变化. 无状态服务内的多个Pod背后是共享存储的.
有状态服务:StatefulSet
Deployment组件是为无状态服务而设计的,其中的Pod名称,主机名,存储都是随机,不稳定的,并且Pod的创建与销毁也是无序的.这个设计决定了无状态服务并 不适合数据库领域的应用.
而Stateful管理有状态的应用,它的Pod有如下特征:
唯一性: 每个Pod会被分配一个唯一序号. 顺序性: Pod启动,更新,销毁是按顺序进行. 稳定的网络标识: Pod主机名,DNS地址不会随着Pod被重新调度而发生变化. 稳定的持久化存储: Pod被重新调度后,仍然能挂载原有的PV,从而保证了数据的完整性和一致性.
总结: 本文主要介绍了无状态和有状态服务在K8S中的典型应用场景.
通过对Deployment部署无状态服务所遇到问题的分析,引出了Stateful新的部署组件.它是通过支持Pod一些特性(e.g. 名称唯一性,稳定的网络标识, 稳定的持久化存储等)来实现在K8S中部署运维有状态服务.
牢记: Stateful有状态服务,每个Pod有独立的PVC/PV存储组件
StatefulSet 的工作原理之前,必须先为你讲解一个 Kubernetes 项目中非常实用的概念:Headless Service。
Service 是 Kubernetes 项目中用来将 一组 Pod 暴露给外界访问的一种机制。
比如,一个 Deployment 有 3 个 Pod,那么我就可以 定义一个 Service。然后,用户只要能访问到这个 Service,它就能访问到某个具体的 Pod。
那么,这个 Service 又是如何被访问的呢?
第一种方式:通过 VIP(Virtual IP,即:虚拟 IP),如:当访问 10.0.23.1 这个 Service 的 IP 地址时(VIP),它会把请求转发到该 Service 所代理的某一个 Pod 上。
第二种方式: 以service 的 DNS 方式,但可分为2种处理方法:
(1)是 Normal Service。这种情况下,你访问“my-svc.mynamespace.svc.cluster.local”解析到的,正是 my-svc 这个 Service 的 VIP,后面的流程就跟 VIP 方式一致了。
(2)正是 Headless Service,当你访问“my-svc.mynamespace.svc.cluster.local”解析到的,直接就是 my-svc 代理的某一个 Pod 的 IP 地址。
区别在于,Headless Service 不需要分配一个 VIP,而是可以直接以 DNS 记录 的方式解析出被代理 Pod 的 IP 地址。
标准的 Headless Service 对应的 YAML 文件
apiVersion: v1
Kind: Service
metadata:name: nginxlables:app: nginx
spec:ports:- port: 80name: webclusterIP: Noneselector:app: nginx
可以观察看到 ClusterIP 字段的值为 None,也就是所谓的 “无头服务” 没有VIP作为头。
当这个 Service 被创建出来后并不会被分配一个 VIP,而是会以 DNS 记录的方式暴露出它所代理的Pod。
是如何给一组 Pod 暴露端口给外界访问的呢?在 YAML 你是观察到有一个 Selector 字段,他就是使用 Label Selector 机制选择出所有带了 app=nginx 标签的 Pod,都会被这个 Service 代理起来,这样可以做到负载均衡Pod的访问了。
StatefulSet 又是如何使用这个 DNS 记录来维持 Pod 的拓扑状态的呢?
示例编写一个 StatefulSet 的 YAML 文件,如下所示:
apiVersion: apps/v1
kind: StatefulSet
metadata:name: web
spec:serviceName: "nginx" replicas: 2 selector:matchLabels:app: nginx template:metadata:labels:app: nginxspec:containers:- name :nginximage: nginx:1.9.1ports:- containerPort: 80name: web
该 YAML 文件和平时我们写的 Deployment 都差不多,唯一区别就是多一个 ServiceName=nginx 字段。
这个字段的作用,告诉 StatefulSet 控制器,在执行控制循环(Control Loop)时,请使用 nginx 这个 Headless Service 来保证 Pod 的 “可解析身份”
创建完后可以快速实时查看stateful创建的状态:kubectl get pods -w -l app=nginx
试用 nslookup 命令,解析一下 Pod 对应的 Headless Service:
nslookup web-0.nginx
总结:
StatefulSet 控制器作用:使用Pod模版创建 Pod时对他们进行编号,并且按照顺序逐一完成创建工作。StatefulSet 控制循环 发现 Pod的 “实际状态” 与 “期望状态” 不一致,则需要新建或删除 Pod 进行 “调谐” 时会严格按照这些Pod编号的顺序逐一完成这波操作。
深入理解StatefulSet(二):存储状态
在前面的 Stateful 讲解了它是如何保证应用实例的拓扑状态,在 Pod 删除和创建的过程中保持稳定。
今天讲解 StatefulSet 对存储状态的管理机制。
在 Pod 中有个 Volume (卷),想要容器挂载到外面地方三存储或本地机器,只需要在Pod里面加上spec.volumes 字段即可,如 Volume 类型 hostPath就挂在本地机器。
有一个问题,对于开发人员来说,如果你并不知道有哪些 Volume 类型可以用,要怎么办呢?作为开发人员对持久存储项目如Ceph、GlusterFS 都一窍不通,让开发人员来写已经超出了知识储备了
后来 kubernetes 项目引入了一组叫 “Persistent Volume Claim” 和 “Persistent Volume” 的 API 对象,降低用户声明和使用持久 Volume 的门槛。
假设我现在是开发人员,现在想要一个 Volume ,需要两步即可。
第一步:申请。定义一个PVC声明想要的 Volume的属性:
apiVersion: v1
Kind: PersistentVolumeClaim
metadata:name: pv-claim
spec:accessModes:- ReadWirteOnceresources:requests:storage: 1Gi
开发人员定义了一个 PVC,描述只需要的属性定义,如:storage: 1Gi 表示想要 Volume 大小至少为 1GB;accessModes: ReadWirteOnce 表示这个 Volume的挂载方式是可读写,且只能被挂载在一个节点而非多个节点共享。
第二步:在应用的 Pod 中,声明刚才你定义的 PVC 即可使用。
apiVersion: v1
kind: Pod
metadata:name: pv-pod
spec:containers:- name: pv-container image: nginxports:- containerPort: 80name: "http-server"volumeMounts:- mountPath: "/usr/share/nginx/html"name: pv-storeage
volumes:- name: pv-storagepersistentVolumeClaim:claimName: pv-claim
以上就是申请好一个 1GB 大小的 Volume了,不需要关系 Volume 的类型,然后创建这个 PVC 对象,Kubernetes 就会自动为它绑定一个符合条件的 Volume。
可是,这些符合条件的 Volume 又是从哪里来的呢?这个需要运维人员去维护 PV 对象了。
Kubernetes 中 PVC 和 PV 的设计,实际上类似于“接口”和“实现”的思想。开发者 只要知道并会使用“接口”,即:PVC;而运维人员则负责给“接口”绑定具体的实现,即: PV。
而 PVC、PV 的设计,也使得 StatefulSet 对存储状态的管理成为了可能。回顾:
apiVersion: apps/v1
kind: StatefulSet
metadata:name: web
spec:serviceName: "nginx" replicas: 2 selector:matchLabels:app: nginx template:metadata:labels:app: nginxspec:containers:- name :nginximage: nginx:1.9.1ports:- containerPort: 80name: webvolumeMounts:- name: wwwmountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:name: wwwspec:accessModel:- ReadWriteOnceresources:requests:storage: 1Gi
volumeClaimTemplates 字段,从名字就可以 看出来,它跟 Deployment 里 Pod 模板(PodTemplate)的作用类似。
也就是说,凡是被这 个 StatefulSet 管理的 Pod,都会声明一个对应的 PVC;而这个 PVC 的定义,就来自于 volumeClaimTemplates 这个模板字段。更重要的是,这个 PVC 的名字,会被分配一个与这个 Pod 完全一致的编号。
这个自动创建的 PVC,与 PV 绑定成功后,就会进入 Bound 状态,这就意味着这个 Pod 可以 挂载并使用这个 PV 了。
如果你使用 kubectl delete 命令删除这两个 Pod,这些 Volume 里的文件会不会丢失呢?
前面介绍过,在被删除之后这两个 Pod 会被按照编号顺序被重启创建出来。如果你在创建新的容器通过本地访问去访问,会发现请求依然会返回,说明原先与名叫web-0的Pod绑定PV,Pod被重新创建后,依然同新的名字web-0的Pod绑定了在一起。
这是怎么做到的呢?
分析:当你把一个 Pod,比如 web-0,删除之后,这个 Pod 对应的 PVC 和 PV,并不会被删除,而这个 Volume 里已经写入的数据,也依然会保存在远程存储服务里(比如,我们在这个 例子里用到的 Ceph 服务器)。
当删除后,StatefulSet 控制器发现,一个名叫 web-0 的 Pod 消失了。所以,控制器就会重新创建 一个新的、名字还是叫作 web-0 的 Pod 来,“纠正”这个不一致的情况。
需要注意的是,在这个新的 Pod 对象的定义里,它声明使用的 PVC 的名字,还是叫作:wwwweb-0。这个 PVC 的定义,还是来自于 PVC 模板(volumeClaimTemplates),这是 StatefulSet 创建 Pod 的标准流程。
通过这种方式,Kubernetes 的 StatefulSet 就实现了对应用存储状态的管理。
深入理解StatefulSet(三):有状态应用实践
官网:案例
部署一个 MySQL 集群,如何使用 StatefulSet 将它的集群搭建过程“容器化”
首先,用自然语言来描述一下我们想要部署的“有状态应用”。
- 是一个“主从复制”(Maser-Slave Replication)的 MySQL 集群;
- 有 1 个主节点(Master);
- 有多个从节点(Slave);
- 从节点需要能水平扩展;
- 所有的写操作,只能在主节点上执行;
- 读操作可以在所有节点上执行。
在常规环境里,部署这样一个主从模式的 MySQL 集群的主要难点在于:如何让从节点能够拥有 主节点的数据,即:如何配置主(Master)从(Slave)节点的复制与同步。
第一步:通过 XtraBackup 将 Master 节点的数据备份到指定目录。
第二步:配置 Slave 节点。Slave 节点在第一次启动前,需要先把 Master 节点的备份数据,连 同备份信息文件,一起拷贝到自己的数据目录(/var/lib/mysql)下。然后,我们执行这样一句 SQL:
第三步:启动 Slave 节点。在这一步,我们需要执行这样一句 SQL:
第四步:在这个集群中添加更多的 Slave 节点。
将部署 MySQL 集群的流程迁移到 Kubernetes 项目上,需要 能够“容器化”地解决下面的“三座大山”:
-
Master 节点和 Slave 节点需要有不同的配置文件(即:不同的 my.cnf)
-
- Master 节点和 Salve 节点需要能够传输备份信息文件;
-
在 Slave 节点第一次启动之前,需要执行一些初始化 SQL 操作;
“第一座大山:Master 节点和 Slave 节点需要有不同的配置文件”,很容易处理:我们只需要给主从节点分别准备两份不同的 MySQL 配置文件,然后根据 Pod 的序号(Index)挂载进去即可。
配置文件信息保存在 ConfigMap 里供 Pod 使 用。它的定义如下所示:
apiVersion: v1
kind: ConfigMap
metadata:name: mysql labels:app: mysql
data:master.cnf: |[mysql]log-bin
slave.cnf: |[mysql]super-read-only
- master.cnf 开启了 log-bin,即:使用二进制日志文件的方式进行主从复制,这是一个标准 的设置。
- slave.cnf 的开启了 super-read-only,代表的是从节点会拒绝除了主节点的数据同步操作之 外的所有写操作,即:它对用户是只读的。
接下来,我们需要创建两个 Service 来供 StatefulSet 以及用户使用。这两个 Service 的定义如 下所示:
```yaml
# 为 StatefulSet 成员提供稳定的 DNS 表项的无头服务(Headless Service)
apiVersion: v1
kind: Service
metadata:name: mysqllabels:app: mysqlapp.kubernetes.io/name: mysql
spec:ports:- name: mysqlport: 3306clusterIP: None # Headless Service,作用为 Pod 分配 DNS 记录来固定它的拓扑状态selector:app: mysql
---
# 用于连接到任一 MySQL 实例执行读操作的客户端服务
# 对于写操作,你必须连接到主服务器:mysql-0.mysql
apiVersion: v1
kind: Service
metadata:name: mysql-readlabels:app: mysqlapp.kubernetes.io/name: mysqlreadonly: "true"
spec:ports:- name: mysqlport: 3306selector:app: mysql
两个 Service 都代理了所有携带 app=mysql 标签的 Pod,也就是所有的 MySQL Pod。端口映射都是用 Service 的 3306 端口对应 Pod 的 3306 端口。
第二座大山:Master 节点和 Salve 节点需要能够传输备份文件”的 问题。
相关文章:

k8s 之 StatefulSet
深入理解StatefulSet(一):拓扑状态 k8s有状态与无状态的区别 无状态服务:deployment Deployment被设计用来管理无状态服务的pod,每个pod完全一致.什么意思呢? 无状态服务内的多个Pod创建的顺序是没有顺序的. 无状态服务内的多…...

iPhone 17 Air基本确认,3个大动作
近段时间,果粉圈都在讨论一个尚未发布的新品:iPhone 17 Air,苹果又要来整新活了。 从供应链消息来看,iPhone 17 Air本质上是Plus的替代品,主要是在维持“大屏”这一卖点的同时,增加了“轻薄”属性ÿ…...
鸿蒙实现应用通知
目录: 1、应用通知的表现形式2、应用通知消息的实现1、发布普通文本类型通知2、发布进度类型通知3、更新通知4、移除通知 3、设置通知道通展示不同形式通知4、设置通知组5、为通知添加行为意图1、导入模块2、创建WantAgentInfo信息3、创建WantAgent对象4、构造Notif…...
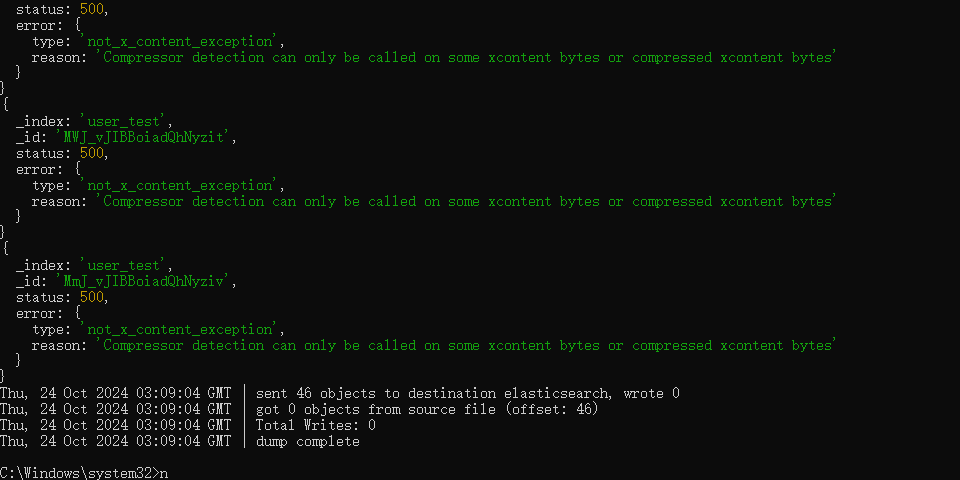
ElasticSearch常见的索引_集群的备份与恢复方案
方案一:使用Elasticsearch的快照和恢复功能进行备份和恢复。该方案适用于集群整体备份与迁移,包括全量、增量备份和恢复。 方案二:通过reindex操作在集群内或跨集群同步数据。该方案适用于相同集群但不同索引层面的迁移,或者跨集…...

vue图片之放大、缩小、1:1、刷新、左切换、全屏、右切换、左旋咋、右旋转、x轴翻转、y轴翻转
先上效果,代码在下面 <template><!-- 图片列表 --><div class"image-list"><img:src"imageSrc"v-for"(imageSrc, index) in images":key"index"click"openImage(index)"error"handleI…...

Docker多架构镜像构建踩坑记
背景 公司为了做信创项目的亮点,需要将现有的一套在X86上运行的应用系统迁移到ARM服务器上运行,整个项目通过后端Java,前端VUEJS开发通过CICD做成Docker镜像在K8S里面运行。但是当前的CICD产品不支持ARM的镜像构建,于是只能手工构…...

“pinn是无网格的”???
“pinn是无网格的”??? PINN,即物理信息神经网络(Physics-Informed Neural Networks),是一种将物理定律作为先验知识整合到神经网络训练过程中的方法。它之所以被称为“无网格”的,…...

换一个ip地址是什么意思?换一个网络ip地址会变吗
在网络的世界里,IP地址如同每台设备的“身份证”,是确保网络信息能够准确传输到指定目标的关键。然而,在某些情况下,我们可能需要更换这个“身份证”,也就是更换IP地址。那么,换一个IP地址究竟是什么意思&a…...
JavaWeb学习--cookie和session,实现登录的记住我和验证码功能
目录 (一)Cookie概述 1.什么叫Cookie 2.Cookie规范 3.Cookie的覆盖 4.cookie的最大存活时间 (Cookie的生命) (二) Cookie的API 1.创建Cookie:new 构造方法 2.保存到客户端浏…...
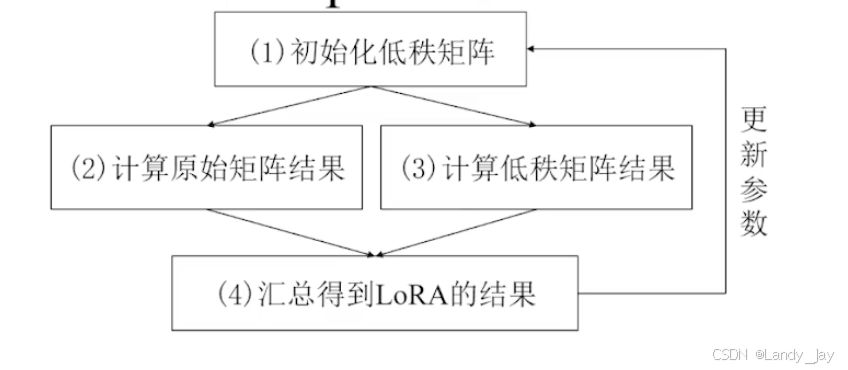
深度学习:基于MindSpore的极简风大模型微调
什么是PEFT?What is PEFT? PEFT(Parameter Efficient Fine-Tuning)是一系列让大规模预训练模型高效适应于新任务或新数据集的技术。 PEFT在保持大部分模型权重冻结,只修改或添加一小部份参数。这种方法极大得减少了计算量和存储开销&#x…...

【LeetCode力扣热题100】【LeetCode 1】两数之和
方法一:暴力循环 两层循环,遍历所有的组合,直到满足条件,返回结果。 class Solution { public:vector<int> twoSum(vector<int>& nums, int target) {for(int i0; i<nums.size()-1 ;i){for(int j i1; j<…...

定制链接类名,两类跳转传参,vue路由重定向,404,模式设置
router-link-exact-active 和 router -link-active两个类名都太长,可以在router路由对象中定制进行简化 // index.js// 路由的使用步骤 52 // 1.下载 v3.6.5 // 2.引入 // 3.安装注册Vue.use(Vue插件) // 4.创建路由对象 // 5.注入到new Vue中,建立关联…...

【ArcGIS微课1000例】0135:自动生成标识码(长度不变,前面自动加0)
文章目录 一、加载实验数据二、BSM计算方法一、加载实验数据 加载专栏《ArcGIS微课实验1000例(附数据)》配套数据中0135.rar中的建筑物数据,如下图所示: 打开属性表,BSM为数据库中要求的字段:以TD_T 1066-2021《不动产登记数据库标准》为例: 计算出来的BSM如下图: 二、B…...

ISO45001职业健康安全管理体系认证流程
前期准备 领导决策:企业高层领导需认识到实施 ISO 45001 体系的重要性和必要性,做出认证决策,并承诺提供必要的资源支持。成立工作小组:由企业各相关部门人员组成工作小组,明确各成员的职责和分工,确保工作…...

VueRouter路由
单页应用程序:例 网易云 多页应用程序:例 京东 网易云导航栏点击任一网页不会跳转京东导航栏点击任一包括导航区域就会实现网页跳转 路由介绍 VueRouter Vue路由介绍 5个步骤写完之后出现 #/,说明当前Vue实例已经被路由所管理 2个关键步骤 新…...
:需求分析)
性能测试攻略(一):需求分析
性能测试成为软件开发和运维过程中不可或缺的一环。性能测试不仅能够帮助我们了解系统在特定条件下的表现,还能帮助我们发现并解决潜在的性能问题。那么我们怎么做一次完整的性能测试呢?首先,我们需要进行需求分析,来明确我们的测…...

【24年新算法时间序列预测】黑翅鸢BKA优化Transformer时间序列预测(评估指标全,出图多)
本文采用黑翅鸢优化算法( BKA,2024年新算法)优化Transformer模型的超参数,形成了BKA-Transformer时间序列预测模型,以进一步提升其在时间序列预测中的性能,本文采用Matlab编写了BKA-Transformer时间序列预测模型代码,代…...

YOLOv8改进,YOLOv8引入CARAFE轻量级通用上采样算子,助力模型涨点
摘要 CARAFE模块的设计目的是在不增加计算复杂度的情况下,提升特征图的质量,特别是在视频超分辨率任务中,提升图像质量和细节。CARAFE结合了上下文感知机制和聚合特征的能力,通过动态的上下文注意力机制来提升细节恢复的效果。 理论介绍 传统的卷积操作通常依赖于局部区域…...

ZooKeeper节点扩容
新节点的准备工作(这里由hadoop05节点,IP地址为192.168.46.131充当) 配置新节点的主机域名映射,并将其通告给集群中的其他节点配置主机间免密登录关闭防火墙并将其加入到开机不启动项同步hadoop01节点的时间将所需要的文件分发给新…...

深度学习的unfold操作
unfold(展开)是深度学习框架中常见的数据操作。与我们熟悉的卷积类似,unfold也是使用一个特定大小的窗口和步长自左至右、自上至下滑动,不同的是,卷积是滑动后与核求乘积(所以取名为卷积)&#…...

边缘计算中的存储挑战与解决方案
边缘计算中的存储挑战与解决方案 背景 作为一个专注于存储架构的技术人,我一直在关注边缘计算的发展。最近团队在部署边缘计算解决方案时,遇到了许多存储相关的挑战。为了帮助团队更好地理解和解决这些挑战,我决定写这篇实践指南。 边缘计算的…...

AI 开发实战:技术决策为什么总失忆,决策日志可以怎么做
AI 开发实战:技术决策为什么总失忆,决策日志可以怎么做 一、这个问题为什么值得专门拿出来做? 在 AI 工程落地里,真正拖慢团队的往往不是模型本身,而是流程和协作方式没有跟上。 围绕“技术决策为什么总失忆࿰…...

FRCRN命令行工具使用详解:从音频文件到降噪输出的完整流程
FRCRN命令行工具使用详解:从音频文件到降噪输出的完整流程 你是不是也遇到过这种情况?手头有一堆录音文件,背景里混杂着各种杂音——可能是空调的嗡嗡声、键盘的敲击声,或者是窗外的车流声。手动处理这些音频不仅费时费力&#x…...

华硕笔记本CPU过热?G-Helper降压调优终极指南帮你降温10℃
华硕笔记本CPU过热?G-Helper降压调优终极指南帮你降温10℃ 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项目…...

BilibiliDown视频下载全攻略:从效率瓶颈到批量管理的进阶之路
BilibiliDown视频下载全攻略:从效率瓶颈到批量管理的进阶之路 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mi…...

实时口罩检测-通用部署教程:Windows WSL2环境下ModelScope模型本地加载
实时口罩检测-通用部署教程:Windows WSL2环境下ModelScope模型本地加载 1. 环境准备与WSL2配置 1.1 WSL2安装与设置 如果你使用的是Windows系统,首先需要安装WSL2(Windows Subsystem for Linux 2)。这是微软提供的Linux兼容层&…...

HAL库定时器双杀技:STM32F401CCU6同时实现PWM输出+输入捕获的避坑指南
HAL库定时器双杀技:STM32F401CCU6同时实现PWM输出输入捕获的避坑指南 在嵌入式开发中,定时器是最基础也最强大的外设之一。对于STM32F4系列微控制器,HAL库提供了丰富的定时器功能,但如何在同一芯片上同时实现PWM输出和输入捕获&am…...

基于迁移学习的口罩检测模型优化
基于迁移学习的口罩检测模型优化 1. 引言 口罩检测作为计算机视觉领域的一个重要应用场景,在实际部署中常常面临数据量不足、训练成本高、模型泛化能力弱等问题。传统从零开始训练检测模型需要大量标注数据和计算资源,而迁移学习技术能够有效解决这些痛…...

Qwen3-0.6B-FP8效果对比:与Phi-3-mini、Gemma-2B在低资源设备上的实测PK
Qwen3-0.6B-FP8效果对比:与Phi-3-mini、Gemma-2B在低资源设备上的实测PK 想在小显存的电脑上跑个大模型,体验一下AI对话的乐趣,是不是总被“显存不足”的提示劝退?别急,今天我们就来一场专为“小显存”设备准备的AI模…...

科研党效率翻倍:Texmaker这些隐藏功能让你的论文排版快人一步
Texmaker科研效率革命:解锁高阶玩家的12个生产力加速器 在深夜实验室的灯光下,你盯着屏幕上纠缠不清的LaTeX代码,参考文献格式突然崩溃,数学公式编号混乱不堪——这场景是否似曾相识?Texmaker作为LaTeX编辑器的隐藏冠军…...