生成式AI概览与详解
1. 生成式AI概览:什么是大模型,大模型应用场景(文生文,多模态)
-
生成式AI(Generative AI)是指通过机器学习模型生成新的数据或内容的人工智能技术。生成式AI可以生成文本、图像、音频、视频等多种形式的数据,广泛应用于内容创作、数据增强、自动化生成等领域。
-
大模型(Large Model)是指具有大量参数和复杂结构的深度学习模型。大模型通常基于深度神经网络,特别是Transformer架构,通过在大规模数据集上进行训练,能够捕捉复杂的模式和关系。大模型的代表包括 GPT-3、BERT、T5、DALL-E 等。
-
超大参数自然语言模型+对话交互=生成式AI
-
大模型参数指的是机器学习模型中的参数,这些参数决定了模型的复杂度和性能。参数越多,模型越复杂,能够拟合的数据也就越多,但同时也需要更多的训练数据和计算资源。
-
主流参数单位表示
a. M:百万,1M(million)
b. B:十亿,1B(billion)
c. T:万亿,1T(trillion)
d. 例子
i. GPT-3模型参数量为1750亿,即1.75T参数。
ii. 百度文心大模型ERNIE 3.0的参数量为2600亿,即2.6T参数。
-
参数量与模型性能
a. 一般来说,参数量越多,模型的性能越好,但同时也需要更多的训练数据和计算资源。因此,在实际应用中,需要根据具体场景和需求来选择合适的模型参数量。
-
参数量的未来趋势
a. 随着人工智能技术的不断发展,大模型参数量将会继续增长。未来,参数量达到百亿、千亿甚至万亿级别的大模型将会越来越普遍。
-
大语言模型代码文件解析
a. .gitignore :是一个纯文本文件,包含了项目中所有指定的文件和文件夹的列表,这些文件和文件夹是Git应该忽略和不追踪的
b. MODEL_LICENSE:模型商用许可文件
c. REDAME.md:略
d. config.json:模型配置文件,包含了模型的各种参数设置,例如层数、隐藏层大小、注意力头数及Transformers API的调用关系等,用于加载、配置和使用预训练模型。
e. configuration_chatglm.py:是该config.json文件的类表现形式,模型配置的Python类代码文件,定义了用于配置模型的 ChatGLMConfig 类。
f. modeling_chatglm.py:源码文件,ChatGLM对话模型的所有源码细节都在该文件中,定义了模型的结构和前向传播过程,例如 ChatGLMForConditionalGeneration 类。
g. model-XXXXX-of-XXXXX.safetensors:安全张量文件,保存了模型的权重信息。这个文件通常是 TensorFlow 模型的权重文件。
h. model.safetensors.index.json:模型权重索引文件,提供了 safetensors 文件的索引信息。
i. pytorch_model-XXXXX-of-XXXXX.bin:PyTorch模型权重文件,保存了模型的权重信息。这个文件通常是 PyTorch模型的权重文件。
j. pytorch_model.bin.index.json:PyTorch模型权重索引文件,提供了 bin 文件的索引信息。
k. quantization.py:量化代码文件,包含了模型量化的相关代码。
l. special_tokens_map.json:特殊标记映射文件,用于指定特殊标记(如起始标记、终止标记等)的映射关系。
m. tokenization_chatglm.py:分词器的Python类代码文件,用于chatglm3-6b模型的分词器,它是加载和使用模型的必要部分,定义了用于分词的 ChatGLMTokenizer 类。
n. tokenizer.model:包含了训练好的分词模型,保存了分词器的模型信息,用于将输入文本转换为标记序列;通常是二进制文件,使用pickle或其他序列化工具进行存储和读取。
o. tokenizer_config.json:含了分词模型的配置信息,用于指定分词模型的超参数和其他相关信息,例如分词器的类型、词汇表大小、最大序列长度、特殊标记等
p. LFS:Large File Storage,大文件存储
-
.safetensors格式文件是huggingface设计的一种新格式,大致就是以更加紧凑、跨框架的方式存储Dict[str, Tensor],主要存储的内容为tensor的名字(字符串)及内容(权重)。
-
鉴于大型语言模型(LLM)的解释性较差问题,我们需要开发相应复杂的评估方法,和优化手段。
-
如何训练出一个大语言模型?
a. 从互联网上爬取10TB text文本
b. 用6000张GPU训练12天,花费200万美元,总算力是1*1024次方 浮点运算每秒
c. 你最终得到一个140GB的zip压缩文件
d. 这个就是Llama 2 70B模型的训练过程
-
开源模型数据集数据来源于网页、社交网络对话内容、书籍、新闻、科学数据、代码
-
大模型的参数量越大,应用范围越广
a. 8B问答、语言理解
b. 10B以上有涌现能力
c. 62B问答、语言理解、代码补全、文本总结、翻译、感知解释
d. 540B问答、语言理解、代码补全、文本总结、翻译、感知解释、通用知识理解、阅读总结、图案识别、智能对话、笑话解读、常识理解
-
文生文是指通过大模型生成文本内容的应用场景。大模型在文生文任务中表现出色,能够生成连贯、自然的文本内容。
-
多模态生成是指通过大模型生成多种形式的数据或内容的应用场景。大模型在多模态生成任务中表现出色,能够生成图像、音频、视频等多种形式的内容
-
语言模型——大模型的前身
-
Transformer架构划时代地提升了NLP效果——传统NLP的努力
a. Transformer(2017,谷歌)是一种用于自然语言处理的神经网络模型,使用了一种“注意力机制”的技术,能够更好地捕捉序列中的关键信息,提高模型性能。是当前对序列文本建模的SOTA基础模型架构,可以有效考虑上下文关联。
b. 注意力(attention)机制:让模型在处理序列数据时,更加关注与当前任务相关的部分,而忽略与任务无关的部分。计算输入序列中每个位置与当前位置的相关性,然后根据相关性对输入序列进行加权求和,得到当前位置的表示。
-
GPT 使用 Transformer 的 Decoder 结构,并对 Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention。
-
不同transformer架构模型演进——主流是decoder-only
a. 绝大部分主流模型用decoder-only架构
b. 清华chatGLM用了encoder-decoder架构(成本高、吞吐低,但准确率高,适合toB、toG)
c. Encoder-only架构不适合大模型场景
-
大部分都是微调模型:基于已有大模型做微调,是一种非常有效的训练技术
-
国内知名语言模型
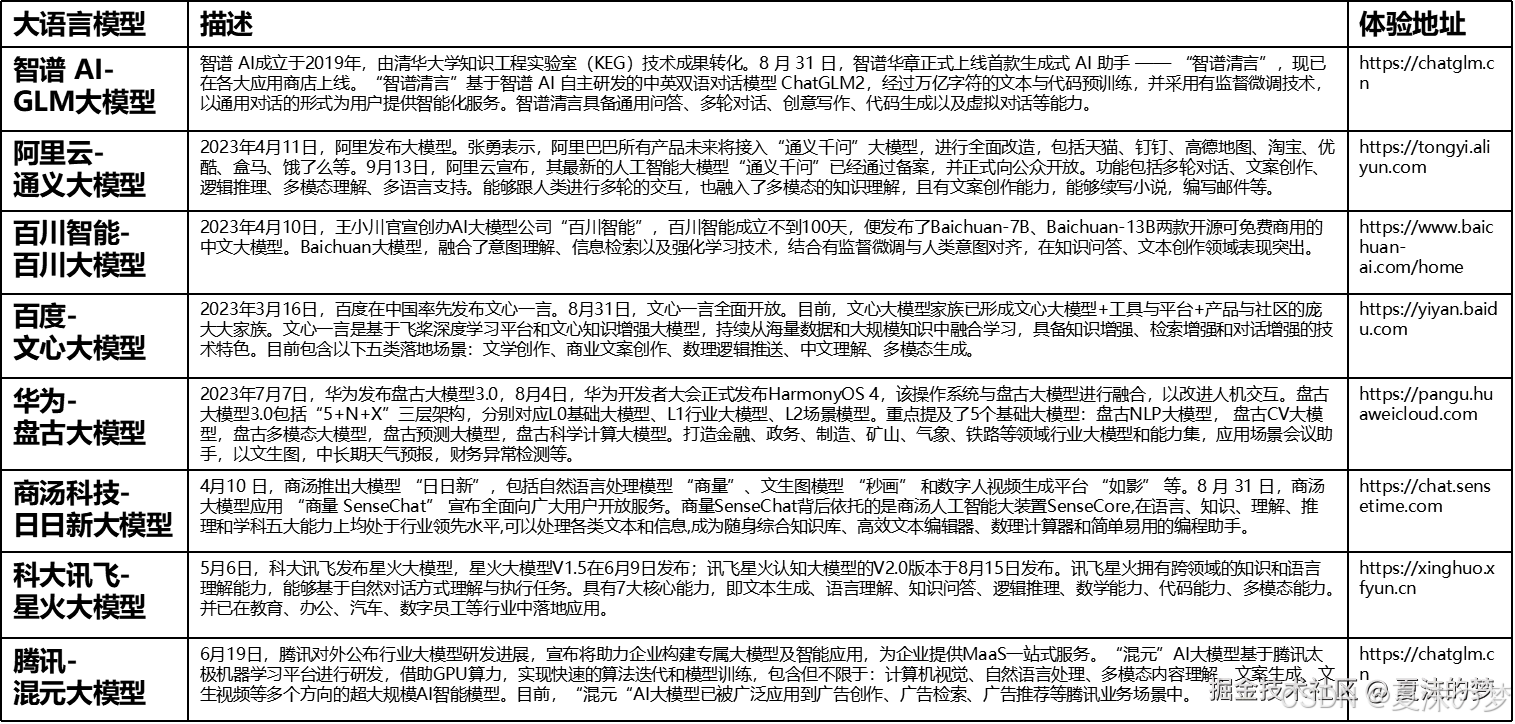
-
基础大模型测评方法-第三方测评机构superclue测评中文大模型方法
-
多模态模型-文生图-stable diffusion模型
-
多模态模型-文生视频-sora
-
Sora文生视频模型工作原理:SORA 模型训练流程
a. Step1:使用 DALLE 3(CLIP ) 把文本和图像对 <text,image> 联系起来;
b. Step2:视频数据切分为 Patches 通过 VAE 编码器压缩成低维空间表示;
c. Step3:基于 Diffusion Transformer 从图像语义生成,完成从文本语义到图像语义进行映射;
d. Step4:DiT 生成的低维空间表示,通过 VAE 解码器恢复成像素级的视频数据;
-
多模态模型-图像、视频理解-GPTo
-
多模态模型-图像、视频理解-GPT-4o
-
优点:
- 强大的生成能力:大模型能够生成高质量的文本、图像、音频、视频等内容,表现出色。
- 自动特征提取:大模型能够自动提取和表示数据的特征,适应不同的应用场景。
- 广泛应用:大模型在文本生成、多模态生成等领域取得了显著的成功,广泛应用于内容创作、数据增强、自动化生成等。
-
缺点:
- 计算资源需求高:训练和推理大模型需要大量的计算资源和时间,通常依赖于高性能计算设备和分布式计算技术。
- 数据依赖:大模型的性能依赖于大规模数据集的质量和数量,数据获取和处理成本高。
- 解释性差:大模型的内部工作机制较为复杂,难以解释其生成过程和决策依据。
-
生成式AI通过大模型生成新的数据或内容,广泛应用于文本生成(文生文)和多模态生成等领域。大模型具有强大的生成能力和自动特征提取能力,但也面临计算资源需求高、数据依赖和解释性差等挑战。通过不断的研究和优化,生成式AI在各个领域取得了显著的成功,并将继续推动人工智能的发展。
相关文章:
生成式AI概览与详解
1. 生成式AI概览:什么是大模型,大模型应用场景(文生文,多模态) 生成式AI(Generative AI)是指通过机器学习模型生成新的数据或内容的人工智能技术。生成式AI可以生成文本、图像、音频、视频等多种…...

数据结构与算法学习笔记----树与图的深度优先遍历
数据结构与算法学习笔记----树与图的深度优先遍历 author: 明月清了个风 first publish time: 2024.12.9 pa⭐️这里只有一道题哈哈。 Acwing 846.树的重心 给定一棵树,树中包含 n n n个节点(编号 1 ∼ n 1 \sim n 1∼n)和 n − 1 n - 1 n…...

IEEE T-RO 软体机器人手指状态估计实现两栖触觉传感
摘要:南方科技大学戴建生院士、林间院士、万芳老师、宋超阳老师团队近期在IEEE T-RO上发表了关于软体机器人手指在两栖环境中本体感知方法的论文。 近日,南方科技大学戴建生院士、林间院士、万芳老师、宋超阳老师团队在机器人顶刊IEEE T-RO上以《Propri…...
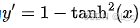
【NLP 14、激活函数 ② tanh激活函数】
学会钝感力,走向美好的方向 —— 24.12.11 一、tanh激活函数 1. tanh函数的定义 tanh是双曲正切函数(Hyperbolic Tangent),数学表达式为 其函数图像是一个S型曲线,以原点 (0,0) 为中心对称,定…...

前端如何实现签名功能
1.JS实现 前端实现签名功能,通常是通过在页面上创建一个可绘制的区域,用户可以用鼠标或触摸设备进行签名。这个区域通常是一个<canvas>元素,结合JavaScript来处理绘制和保存签名。下面是一个简单的实现步骤: 1.1. 创建HTM…...

若依将数据库更改为SQLite
文章目录 1. 添加依赖项2. 更新配置文件 application-druid.yml2.1. 配置数据源2.2. 配置连接验证 3. 更新 MybatisPlusConfig4. 解决 mapper 中使用 sysdate() 的问题4.1. 修改 BaseEntity4.2. 修改 Mapper 5. 更新 YML 配置 正文开始: 前提条件:在您的…...

CRMEB Pro版v3.2源码全开源+PC端+Uniapp前端+搭建教程
一.介绍 crmeb pro版 v3.2正式发布,全新UI重磅上线,焕然一新,不负期待!页面DIY设计功能全面升级,组件更丰富,样式设计更全面;移动端商家管理,让商城管理更便捷,还从页面…...
Docker 安装 Jenkins:2.346.3
准备:已安装Docker,已配置服务器安全组规则 1581 1、拉取镜像 [rootTseng ~]# docker pull jenkins/jenkins:2.346.3 2.346.3: Pulling from jenkins/jenkins 001c52e26ad5: Pull complete 6b8dd635df38: Pull complete 2ba4c74fd680: Pull complet…...
【OpenCV】模板匹配
理论 模板匹配是一种在较大图像中搜索和查找模板图像位置的方法。为此,OpenCV 带有一个函数 cv.matchTemplate() 。它只是在输入图像上滑动模板图像(如在 2D 卷积中),并比较模板图像下的模板和输入图像的补…...

黑马商城微服务复习(5)
MQ 一、同步调用和异步调用1. 同步调用2. 异步调用 二、RabbitMQ1. 基础使用2. 实际操作 怎么用?3. RabbitMQ虚拟主机 数据隔离4. 在JAVA中实现RabbitMQ5. 交换机种类 一、同步调用和异步调用 1. 同步调用 微服务一旦拆分,必然涉及到服务之间的相互调用ÿ…...
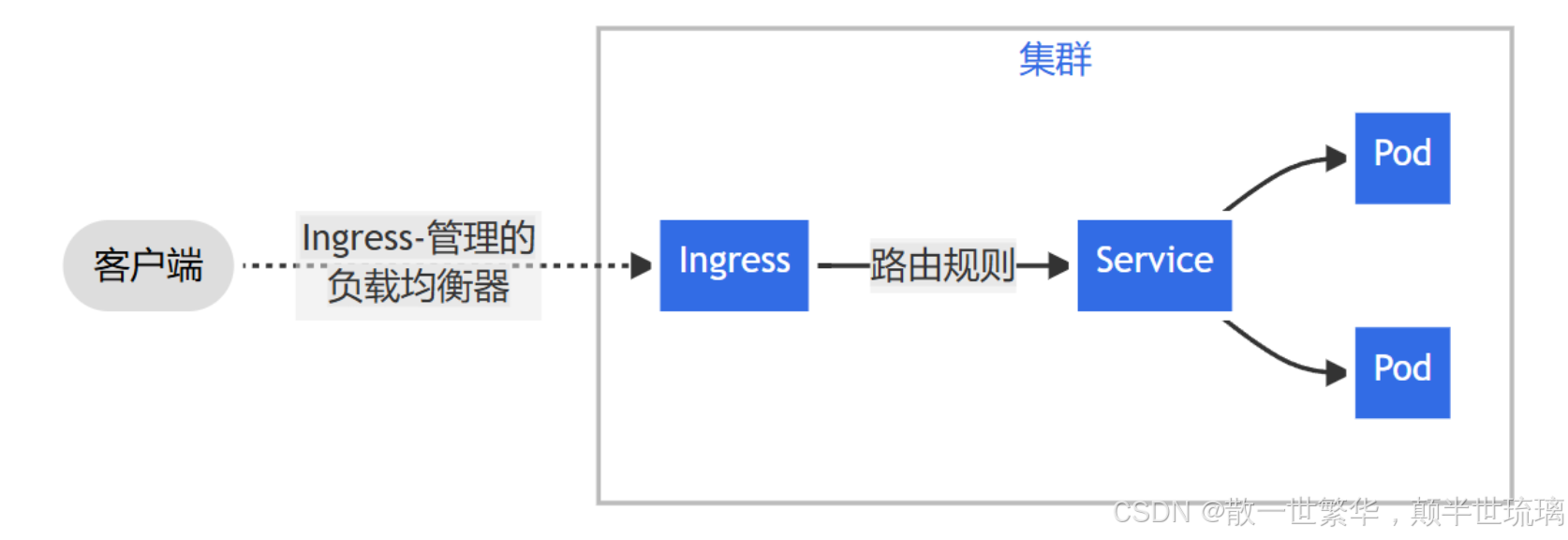
云原生基础设施指南:精通 Kubernetes 核心与高级用法
1. 云原生的诞生 随着互联网规模的不断增长,以及企业对敏捷开发、快速交付和高可用性的需求日益增强,传统的单体架构逐渐暴露出局限性,难以满足现代业务对动态扩展和高效迭代的要求。为此,云原生应运而生。 云原生是为云计算时代…...
人工智能概要
目录 前言1.什么是人工智能(Artificial Intelligence, AI)2.人工智能发展的三次浪潮2.1 人工智能发展的第一次浪潮2.2 人工智能发展的第二次浪潮2.3 人工智能发展的第三次浪潮 3.人工智能发展的必备三要素3.1 数据3.2 算法(algorithm…...

qt QCommandLineParser详解
1、概述 QCommandLineParser是Qt框架中提供的一个类,专门用于解析命令行参数。它简化了命令行参数的处理过程,使得开发者能够轻松定义、解析和验证命令行选项和参数。QCommandLineParser适用于需要从命令行获取输入的控制台应用程序,以及需要…...

力扣 K个一组翻转链表
K个一组翻转链表 /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(ne…...
cnocr配置及训练测试
cnocr配置及训练测试 1,相关链接2,已有模型调用测试(1)下载相关模型(2)Cnstd文本检测模型(3)模型调用解析脚本 3,自定义数据集训练测试(1)标签转换…...

解决 Flutter 在 Mac 上的编译错误
解决 Flutter 在 Mac 上的编译错误 在使用 Flutter 进行项目开发并尝试在 Mac 设备上进行编译时,遇到了一系列的错误信息,这些错误信息给项目的构建与部署带来了阻碍。 一、错误详情 在编译过程中,Xcode 输出了大量的信息,其中…...
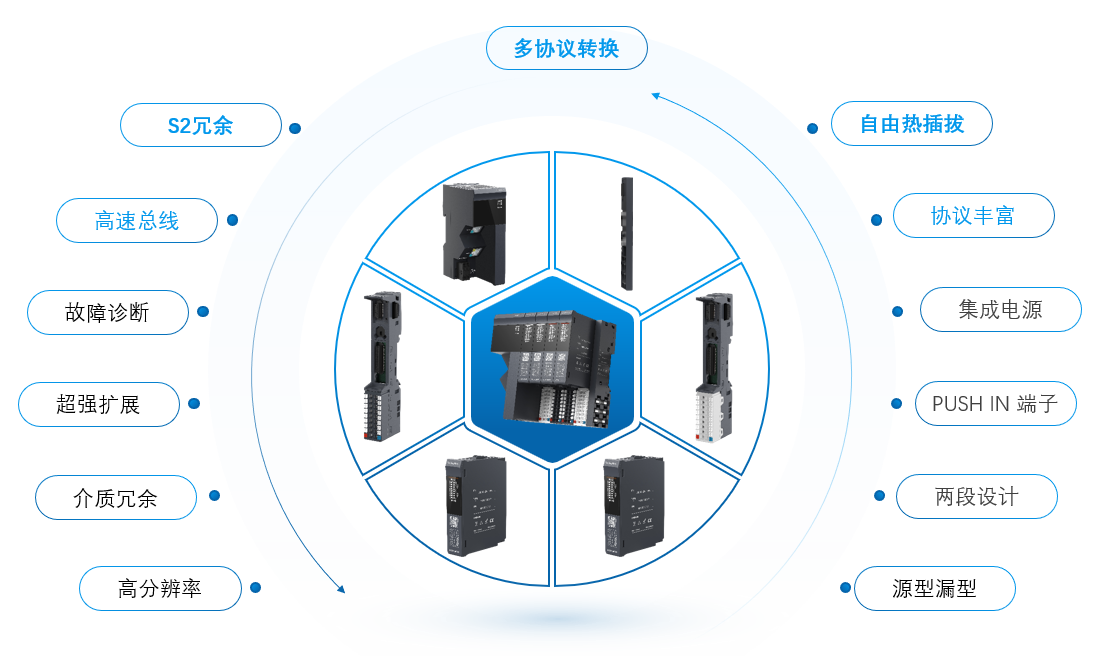
MR30分布式IO在新能源领域加氢站的应用
导读 氢能被誉为21世纪最具发展潜力的清洁能源,氢能科技创新和产业发展持续得到各国青睐。氢能低碳环保,燃烧的产物只有水,是用能终端实现绿色低碳转型的重要载体。氢能产业链分别为上游制氢、中游储运以及下游用氢。上游制氢工艺目前大部分…...
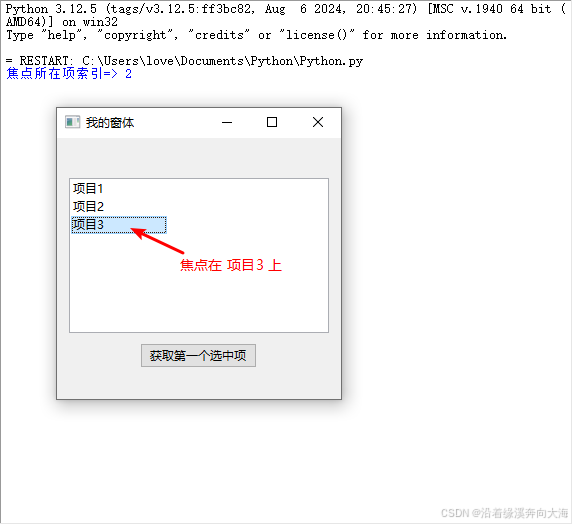
wxPython中wx.ListCtrl用法(二)
wx.ListCtrl是一个列表组件,可以以列表视图(list view)、报表视图(report view)、图标视图(icon view)和小图标视图(small icon view)等多种模式显示列表。 一、方法 __…...

kubernetes 资源汇总
kubernetes 资源汇总 官网 英文文档 官方英文文档 中文文档 官方中文文档 github github源码地址 培训认证 也就是linux基金会的认证,上面也提供培训课程 下载资源 官网下载资源,国内的话k8s镜像下载不了,要去镜像站 在线练习 killer…...
)
每日一题(对标gesp三级答案将在第二天公布)
编程题 题目描述: 小杨为数字4,5,6和7设计了一款表示形式,每个数字占用了66的网格。数字4,5,6和7的表示形式如下(此处自行设计复杂一些的表示形式示例): 数字4: …. …. …. …. *… 数字5: …...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...