【隐私计算篇】隐私集合求交(PSI)原理深入浅出
隐私集合求交技术是多方安全计算领域的一个子问题,通常也被称为安全求交、隐私保护集合交集或者隐私交集技术等,其目的是允许持有各自数据集的双方或者多方,执行两方或者多方集合的交集计算,当PSI执行完成,一方或者两方,甚至多方,能够得到交集结果,但是任意一方都无法获得交集以外的其他方集合数据的任何信息。

图1. 两方PSI示例
Alice有集合X,Bob有集合Y。在进行PSI计算后,Alice只能知道集合X与集合Y的交集,即X ∩ Y,而无法知道其他任何信息。Alice无法知道Bob的元素中不属于X ∩ Y的部分。如果Alice试图了解Bob的不匹配数据,Alice将无法成功。
1. PSI解决的业务问题
在介绍具体的PSI原理之前,有必要先介绍PSI的应用场景,能够解决哪些业务问题,带着这样的场景解决方案背景知识,能够更快速的理解PSI的原理实现。这里列举了多种业务活动中,可以使用PSI解决的问题,总结起来可以归纳为“黑/白名单应用”以及“撞库应用”:
1. 黑/白名单系列
1.1 金融机构黑名单共享:银行、信用卡公司等金融机构可以共享黑名单信息,防止被多个机构列入黑名单的客户再次申请贷款或信用卡。
1.2 犯罪调查:不同执法机构可以在不泄露案件详细信息的前提下,合作识别共同嫌疑人或案件线索,提高办案效率。
1.3 租赁公司黑名单共享:汽车租赁公司和房屋租赁公司可以共享不良租客信息,防止有违约或损坏财产记录的租客继续租赁。
1.4 医疗研究:不同医院或研究机构可以在不共享患者详细信息的情况下,识别共同患者,进行协同研究或联合分析。
1.5 身份验证:不同组织可以在不共享用户详细信息的情况下,验证用户的身份,确保用户的隐私安全。
2. 撞库系列
2.1 广告投放和数据合作:广告商和平台可以在不暴露各自用户数据的情况下,确定共同用户,以实现更精准的广告投放。
2.2 市场分析:企业之间可以在保护客户隐私的情况下,合作进行市场分析,识别共同客户和市场趋势。
2.3 社交网络:不同社交网络平台可以在不泄露用户数据的情况下,找出重叠用户,以便更好地提供跨平台服务。
2.4 联邦学习:多个机构可以在保护数据隐私的情况下,共享数据特征,进行联合机器学习模型训练,提升模型性能。
2.5 账户保护合作:不同企业可以在不透露具体用户信息的情况下,合作保护那些使用相同账户信息的用户,防止他们在多个平台上遭受撞库攻击。
2. PSI协议的分类及设计
2.1 分类体系
PSI是一个发展相对成熟的领域,因此有非常多的算法,面向的解决场景也多种多样。这里列举一些分类的维度,有更多或者更好的意见补充的话可以评论留言。
- 参与方的数量:两方PSI、三方PSI、多方PSI;
- 参与方数据量级差异:平衡PSI、非平衡PSI;
- 实现的原理差异:
- 基于PKC(公私钥体系)
- 基于全同态加密
- 基于秘密共享
- 基于OPRF协议
- 基于OPPRF协议
- 基于OKVS
- 基于PCG
- 是否为恶意模型:半诚实安全PSI协议、恶意安全PSI协议;
- 不同通信成本:WAN友好PSI协议、LAN适用PSI协议;
- 是否纯在线计算:Online模式、Offline-Online模式;
- 输出交集结果形式:明文交集结果(普通PSI)、不泄露结果(电路PSI/匿踪PSI);
- 是否可证安全:基于密码学的PSI协议、基于可信硬件环境的PSI协议。
虽然分类的体系比较复杂,但是从PSI的定义出发,设计一个合格的PSI,需要解决三个主要问题:
(1)保护非交集元素, 使用密码学保证不暴露,当两个元素不相等时,无法穷尽计算不匹配的元素。
(2)可以通过比较计算交集元素,当两个元素相等时,相等性能够以某种方式被揭示。
(3)高效率,能够满足所应用业务的性能指标要求。
2.2 算法设计
接下来,通过对不同的PSI的设计分析,来进一步理解PSI算法原理。
2.2.1 基于公钥体系的设计方案
基于Diffie-Hellman密钥交换的PSI,基本思路为双重加密具有交换性,加密隐藏元素,交换性满足可比较,通信成本呈线性关系。 在加密原语(如椭圆曲线)上有许多增强,可以设计一种能满足所有要求的加密方法。
该协议的安全性是建立在离散对数问题(DLP)上,给定p、g、x和y四个大正整数,假设,其中p是一个大素数,已知y、g、p,如何找到x是一个“难题”。其中,计算
是高效的,保证了效率。给定y、g、p找到x是困难的,保证了对原始数据的加密隐藏。
等于
,具备交换性,满足可比较。
两方&三方场景的DH-based PSI设计如下,计算量适中,通信量相对可控,由于底层依赖的加密算法(比如采用ECC)如果有性能优化的话,可以显著提升性能。

图2. DH-based 两方PSI协议示例

图3. DH-based 三方PSI协议示例
另外,补充一个RSA版本的求交【23】:

2.2.2 基于OPRF体系的设计方案
OPRF是Oblivious Pseudo-random Function的简称,称为不经意伪随机函数。在介绍具体算法之前,需要先介绍下什么是PRF?
PRF 是一个确定性的函数,记为𝐹。𝐹是定义在(𝑘,𝑋,𝑌)上的 PRF,其中 𝑘 是密钥空间,𝑋 是输入空间,𝑌 是输出空间。它有两个输入,一个是密钥 𝑘,另一个是输入数据块 𝑥∈𝑋。它的输出𝑦=𝐹(𝑘,𝑥)∈𝑌 。对于 PRF,其安全性要求:给定一个随机产生的密钥 𝑘,函数𝐹(𝑘,.)应该看上去“像”是一个定义在 𝑋 到 𝑌 上的随机函数。
此外,OPRF中的不经意性,体现在如何保护参与方的隐私和信息。具体来说,在OPRF中,发送方和接收方可以执行计算,但彼此不会了解对方的关键信息或输入。发送方使用其私密密钥和接收方的输入数据来生成输出,但不会了解接收方的具体输入内容。接收方也可以获取输出结果,但不会知道发送方使用的具体密钥或如何生成输出的详细过程。无论是发送方还是接收方,在计算和通信过程中不会保留对方的私密信息或详细计算过程。每个参与方只能得到必要的信息来执行协议,而不会暴露其他不必要的信息。
通俗来说,OPRF执行流程包含以下步骤,在计算过程中,发送方不能知道接收方的数据,接收方也不能知道秘密函数,有效做到对关键信息的隐藏。经过秘密函数处理后的数据可以进行比较。大部分操作是高效的加密操作,如哈希和对称密钥加密,只有少量的公钥基础设施操作。
- 发送方对其集合计算一个“秘密”函数,并将结果发送给接收方。
- 接收方也通过与发送方交互来计算其集合在这个“秘密”函数上的结果。
- 接收方将从发送方收到的结果与自己的结果进行比较。
事实上,DH-based PSI也是满足OPRF原理。这里,为了进一步介绍清楚OPRF的原理,这里举一个简单的案例,以帮助能理解其工作逻辑。如图4所示,接收方将其项目X哈希到一个在某个密码安全的椭圆曲线上的点 A 上。然后,接收方选择一个随机数 r,计算点 B = rA,并将其发送给发送方。发送方使用其密钥 K 计算点 C =KB,并将其发送回接收方。接收方收到 C 后,计算椭圆曲线阶数的逆元 并进一步计算
。接收方然后从这个点中提取 OPRF哈希值
,例如通过将其 X坐标哈希到适当的域。
发送方知道 K,因此可以简单地用 替换为
。接收方需要与发送方通信以获取
;一旦接收到这些值,协议就可以如上所述进行。使用OFRF后,接收方了解其查询的部分是否匹配的问题将不复存在。由于所有项都使用只有发送方知道的哈希函数进行哈希,接收方从了解发送方的哈希项的部分中将获益不大。

图4. 基于ECC椭圆曲线的OPRF-based PSI示例
有了上述的示例,我们给出OPRF的执行流程框架。

图5. 一般性的OPRF的执行流程
可以看到,一般性的OPRF,在通信和计算上都比较耗时,对于每一个Xi都需要执行一次OPRF,且每次OPRF都需要计算全部的Y,因此时间复杂度差不多是。那么有没有更优的方案呢?
这里给出KKRT16的一种实现方案,引入了Cuckoo hash和simple hash来分桶,实现性能的提升。先来看一个cuckoo hash的例子,如图6所示,假设接收方有三个元素[1, 2, 3], 发送方也有同样的三个元素[1,2,3]。 如果不做分箱处理,也就是用一般性的OPRF,需要执行复杂度计算。但如果引入cuckoo hash bining,整体复杂度会降低到
, 这里的
是指hash函数的数量,一般是2或者3。当然引入cuckoo hash,分箱数量会有扩增,大概到1.5n的规模,也是相对可控的,发送方的max bin size,在大数据下,一般也就是几十到几百的规模,相对于不做bining处理,收益会非常明显。图7展示了引入cuckoo hash bining之后的OPRF版本。

图6. cuckoo hash bining示例

图7. 引入cuckoo hash bining之后的OPRF-based PSI示例
事实上,KKRT16之所以性能好,除了Cuckoo Hashing外,还改进了OPRF的性能。KKRT16是从运行效率上针对KK13的1-n OTE提升为1-无穷 OTE的一个改进,通过将纠错码改为伪随机编码实现(1-无穷)-OTE,避免了OT数量与元素的大小相关。

图8. KKRT16实现机制
2.2.2.2.1 Single-point OPRF
虽然KKRT16取得了显著的性能提升,但该算法对于带宽的要求依然较高,不同带宽对其求交性能影响显著。如下表所示,在10M带宽下,KKRT16的性能下降明显。

这是因为KKRT16本质上属于单点OPRF,也就是一个OPRF实例仅能对一个元素进行OPRF值的评估。由于每一行的密钥均不同,若直接采用单点-OPRF进行元素比较,则发送方的每个元素需要OPRF评估n次(n为接收方集合大小),即使采用了cuckoo hashing的方案,发送方的每个元素需要OPRF评估hash函数个数+stash大小。图9展示了单点OPRF的计算过程,(a) 如果 x = y,那么无论选择什么 s,。 (b) 如果 x ≠ y,那么
很难猜测。具体的计算步骤如下:
step1: 发送方随机生成
长度的0-1比特串,这里的
以保证生成的比特串的随机性。然后数据Y,需要通过f(Y)函数计算得到新的同等长度
的0-1比特串,这个函数需要具备随机性、确定性。这类函数有很多的不同设计,可以
参考KKRT16的源码实现。有了f(Y)的0-1比特串后,将
与f(Y)按位求异或,得到r1的
0-1比特串。这样得到的
比特串,将会作为后续OT执行的message。
step2:接收方生成随机的选择比特串,长度同样是
素,对应位置为1,则选择
对应位置的元素,这样执行完
q,序列q可以表示成公式
,其中
表示的是与计算。
step3:接收方对自身的X进行同样的f(X)函数转换,得到0-1比特串f(X)。然后将(s, q)作为
OPRF中的秘密k,计算
,同理
。
当
的时候,
将会等于全为0的比特串,刚好被消除,得到
最终的
。当
的时候,
是一个很难猜的对象,因此发送方无法反
推原始的X。说明一下,最后的比较操作,是在图中的发送方一侧计算。这样就实现了
基于单点OPRF的PSI。

图9. 单点OPRF过程
2.2.2.2.2 Multi-point OPRF
由于单点OPRF的不足,因此有必要讨论针对一般带宽资源下的性能更好的OPRF-based PSI算法。这里给出CM20中提到的一种优化方案,CM20提出一种多点OPRF协议。多点OPRF的目的是为了消除发送方的每个元素需要OPRF评估多次的计算和通信开销,使得发送方的每个元素只需要评估一次。
如图10所示的多点OPRF计算过程。整体计算思路基本与单点的类似,需要注意,多点OPRF,是将集合f(Y)映射到一个矩阵中,从step1和step2可以看到,f(y)首先计算出每一列所落的位置,然后将R0矩阵中对应位置的元素拷贝到R1矩阵中。经过对多个y计算f(y), 得到每一个f(y)在矩阵中的位置并拷贝对应的R0矩阵元素到R1中,矩阵R1就同时包含了多个f(y)信息。在step3中,将R1中剩余空缺的位置,在R0中找到对应的位置元素,进行取反,然后填充到R1中对应位置。就得到最终的R1矩阵。Step4,同样左侧参与方生成随机的选择比特串s, 执行次OT,0表示取R0中的对应列元素,1表示取R1中对应列元素。得到矩阵q。此时(q,s)就作为OPRF中的秘密k,然后计算
。即对X进行f(x)计算,得到q中每一列对应的位置,取得对应的元素,图中示例为H(00010)。 与单点OPRF同理,执行
,相当于是获得对应矩阵位置中的r0元素,即H(r0),如果X=Y, 则
为H(00010)。如果不想等,则
是一个难以猜测的值。
CM20的多点OPRF,可以带来cuckoo hash函数的作用,且消除了通信开销。

图10. 多点OPRF过程
step5中左图有点勘误,第二列应该是[1,0,1,0],而不是[0, 1, 1, 0]。这里特别说明下。
为了进一步详细对比原论文中的计算逻辑,这里贴一下【CM20论文】中的步骤,如图11所示,计算顺序上可能有一点点顺序差异,但整理逻辑是一致的,帮助更好的理解实现原理。

图11. CM20论文中PSI协议计算流程
KKRT16 和 CM20在不同带宽下对比,CM20在中带宽(30Mbps - 100Mbps)下,相对于KKRT16有一定的优势。
表1. 不同带宽下的运行耗时对比

2.2.3 基于OKVS+VOLE体系的设计方案
之前提到了KKRT16在高带宽(LAN)场景下性能较佳,而CM20在中带宽(30Mbps-100Mbps),接下来介绍的RR22-PSI,则进一步在通信量优化上做出显著提升,在低带宽(10Mbps-20Mbps)下性能表现优异。
[PRTY20]引入了Probe-and-Xor-of-Strings (PaXoS), 替代Cuckoo Hashing抵抗恶意攻击。
[RR22]把PaXoS抽象成通用工具:Oblivious Key-Value Store (OKVS),且提出了一种改进版本的OKVS结构,提高了计算和通信的效率。使用VOLE替换OT,可以充分利用offline阶段的能力,提升online的计算效率,当然在实际验证中,即使包含offline生成VOLE元组的耗时,整体也很可观,下表展示了相应的通信量分析,可以看到相对于CM20有明显改善。
表2. 不同带宽下的通信量分析

正式分析RR22算法之前,需要先对OKVS和VOLE进行一定的介绍。
2.2.3.1 不经意键值存储OKVS以及VOLE
不经意键值存储(OKVS-oblivious key-value store)是指能够在隐藏key和value内容的前提下,保留key-value映射关系的一种数据结构。假设有一组键值对,那么存在一个OKVS函数f,使得
, 并且对于其他的键
为随机数。OKVS包含了通过key-value构造OKVS的Encode方法和通过key查询value的Decode方法。
举个简单但不安全的示例,将(K, V)通过多项式插值编码,使得
,那么存在以下关系:

刚才提到的基于多项式插值的构造显然是不安全的,因为Key-Value Store 𝑆 包含了输入 (𝐾,𝑉) 的信息。安全的构造例如PaXoS,PaXoS编码生成的 𝑆 具有随机性,所以是安全的。PaXoS的原型是Garbled Bloom Fitler。一些安全的OKVS的形式有多种,如GBF、PaXoS、3H-GCT、2-cuckoo hash,RR22中OKVS 则是通过cuckoo哈希将 key 映射到 随机矩阵H 中(weight 选择为3时,性能最佳),然后通过三角化、后向传播等方法求解 向量P,使得 H · P = V。[RR22] 还设计了一种称为 Clustering 的优化方法:将系数矩阵分块,使得权重相对聚集在某一部分,例如:第一块的权重主要集中在前半部分。这样每个 Clustering 可以单独进行相应的三角化,并支持多线程并行处理。同时,根据论文分析选取 Clustering 参数为 2^14时,性能达到最优。比较直观的可视化展示可以看下【5】。
【6】中提到相关OKVS结构信息见下表所示:
表3. 不同OKVS结构

有了OKVS,如何实现PSI,这里【12】给出了一个小的示例:
Sender将自己的集合编码成OKVS发送给Receiver,Receiver可以查询自己的集合元素是否在OKVS中。如果存在,那么查询结果是1,否则查询结果是一个随机数。
具体地, PSI协议(简化版本)工作如下:
1. Sender将自己的集合编码成S使得
;
2. Sender发送S给Receiver;
3. Receiver对自己集合中的每一个元素进行解码得
;
4. 若说明
,否则
。
乍一看,似乎OKVS自身就可以执行PSI了,但这种方案还是有一定穷举风险。发送方可以使用 Encode 算法对 向量X 和 向量H(X) 进行处理得到 向量P,并把 向量P 发送给接收方;接收方使用 向量Y 和 Decode 算法能得到 向量V,然后将 向量V 发送给发送方。最后,发送方通过比较向量 H(X) 和 向量V,可以计算出它们的交集。然而,这样的方案不能抵御穷举攻击,换而言之,需要一些密码组件来保护 OKVS。
这引出了下一个组件 VOLE。VOLE 也是一种双方协议,通过执行该协议,左侧的一方会得到 向量A 和 向量B,右侧的一方会得到和和向量C,同时,它们还满足
的关系。

图12. VOLE关系图
需要注意的是,向量A 是属于域,当
时,称之为 VOLE 关系;而当
时,又称之为 subfield-VOLE 关系。同时,这两种 VOLE 也对应了RR22-PSI 中的两种使用模式,分别为快速模式和低带宽模式。
快速模式(FastMode):
低带宽模式(LowComm/Small Domain):
VOLE 的构造:
通过Base VOLE协议得到少量的VOLE:
- 基础VOLE协议用于生成初始的VOLE关系。这些初始的VOLE关系数量较少,但它们是后续步骤的基础。
通过Multi-Point VOLE协议得到“稀疏”的VOLE关系:
- Multi-Point VOLE协议用于扩展基础VOLE关系,以获得更多的VOLE关系。这些关系通常是稀疏的,即其中的一部分元素为零或具有特定的稀疏性结构。
通过LPN/Dual-LPN处理“稀疏”的VOLE关系,使其变成均匀随机的VOLE关系:
- 最后一步,通过LPN(Learning Parity with Noise)或Dual-LPN协议对稀疏的VOLE关系进行处理,使其变成均匀随机的VOLE关系。这一步通常涉及对VOLE关系进行某种形式的编码或变换,以确保最终的VOLE关系在统计上是均匀分布的。
有了 VOLE 关系元组信息之后,可以用其保护 OKVS。首先,发送方使用 VOLE 中的向量A' 对 OKVS 中的向量P进行掩盖,并发送给接收方。接收方使用 VOLE 中的 △ 和 向量B,计算出向量K,并使用向量K和向量Y进行 Decode,然后把 Decode 的结果 向量Y' 发给发送方。最后,发送方通过对比向量X' 和向量Y'得到交集。

3. 全匿踪PSI
3.1 行业动态
随着业内对交集信息的合规性保护越来越重视,目前也开始出现一种称为全匿踪PSI的技术,也可以称为全匿踪安全求交、匿踪安全求交、匿踪求交、不泄露交集的安全求交、全流程加密联邦,解决求交过程中交集信息不暴露的合规难题。
富数科技在2022年9月首次提出了全匿踪联邦学习技术,其中引出了对全匿踪安全求交在联邦场景的实现和讨论,并且在发布的专利中提出了两种不同的实现方案,首次引入了基于乱序重排和掺杂混淆的缩量全匿踪联邦学习框架,随后与中信证券联合申请并拿到当年的星河标杆案例,标志着全匿踪隐私计算技术首次在证券行业落地,之后更是因为全匿踪技术在合规方面的突破性进展,拿到了全国首届数商大赛的一等奖。在全匿踪联邦学习技术提出的同年,腾讯团队跟进提出了全匿踪模型推理的实现,在idash大赛同态计算赛题获得冠军,之后提出了基于全匿踪安全求交实现联邦学习xgboost算法。后续其他隐私计算厂商也逐步跟进该领域技术的演进,2023年蓝象智联与交通银行合作采用全流程加密联邦建模技术获得第二届金融密码杯创新赛道一等奖,同年6月联合西安电子科技大学、浙江大学发表了关于全匿踪联邦学习的一种实现iprivjoin,对乱序重排技术做了改进。同盾科技、洞见智慧先后申请了全匿踪联邦学习相关的专利。因全匿踪数据处理技术在合规性方面的突出特点,很多机构都有相应的业务接入需求,各厂商都相继投入了研究力量,并且因为该技术的创新性,在各类大赛中屡次获奖。
在全匿踪数据处理技术中,比较常见的是电路PSI(Circuit-PSI),这类PSI允许两个参与方计算交集,最终交集结果未泄露给任何一方,而是在参与方之间秘密共享,保证元素信息、交集基数等均未被泄露。其后可在秘密共享的交集结果上执行求势、求交集和、门限等功能,但不泄露交集信息。此类PSI协议虽然通信、计算、内存开销较大,但可在交集秘密共享上执行任意的对称函数计算。当然也有基于多方安全计算实现的方案,这里不一一列出。
Circuit-PSI是一种框架,实现的方法又有很多,其中涉及到OPPRF的不经意可编程伪随机函数技术以及多方安全计算技术。这类求交算法相对来说复杂度会更高,后续有机会再继续做分享。这里列举一些该领域的参考文献【3、13、14、15、16、17、18、19】,有兴趣的同学可以继续研读学习。
3.2 OPPRF原理分析
这里简单对OPPRF做一些原理介绍:
OPPRF比OPRF多了programmable可编程的概念,它允许密钥所有者"编程"函数 F,以便对于特定的输入值具有特定的输出(并且在所有其他值上是伪随机数)。 怎么理解这段话,这里给一个示例:假如数据源方持有x0, x1, x2三个数据,当客户端发起查询,其查询的对象属于{x0, x1, x2}集合中的一个,则返回一个预先定义的数值,如果不属于该集合,则返回一个随机值,且数据源不能探究客户端查询的对象,客户端也不知道拿到的结果是预先定义的数值还是随机数。这个特性对于全匿踪技术很关键,后续可以基于该结果进行MPC的比较计算,实现求交结果的秘密分享,任意一方都无法知道结果,但又可以支持模型学习或者统计计算,非常优美。
OPPRF相比OPRF,有一些独特的部分,如下所示:
1. 根据数据点
,生成提示信息
。
2.
, 计算PRF函数在
上的值
。如果是特定的输入,则返回特定
,
否则返回随机数。
安全性:OPPRF的接收者相对OPRF,会多获得ℎ𝑖𝑛𝑡信息,而ℎ𝑖𝑛𝑡是根据发送者的输入数据点生成的,在安全性上,OPPRF需要保证,即使得到了ℎ𝑖𝑛𝑡以及PRF在上的输出,接收者也无法识别某个点𝑥是否属于预定义数值。OPPRF的安全性隐含了对于不属于集合中的点𝑥,PRF在𝑥上的输出是随机的。

实现OPPRF有多种不同的方案【20,21】:
(1)基于多项式
-
KeyGen(P) → (k, hint):为PRF函数F随机选择一个密钥k。根据点集P
,进行多项式插值,得到一个n-1阶的多项式p,将这个多项式的系数,作为hint。
-
上述算法是满足OPPRF的正确性的。对于(x_i, y_i) ∈ P,。在安全性上,只要
是随机选择的,那么多项式p的系数也是随机的,对于任意的点
,
的值也是随机的,因此,上述算法满足OPPRF的安全性。缺点:数据点多的时候,插值计算消耗大。优点:通信友好,只需要发送多项式系数。

(2)基于混淆布隆过滤器GBF
将hint更换为GBF,同样可以实现类似的效果。GBF同样实现了键值对存储功能。
GBF是一个长度为 N 的数组 G,配合 k 个哈希函数 。用GBF可以实现键值对存储的功能,对于一个键 x,其对应的值为
可以按照如下方法,将一个键值对 (x, y)插入到GBF中:
- 将长度为 N的数组 G 中的每个元素,初始化为空,记为空。
- 对于每一个键值对(x, y),设
为 x相关的位置,如果
,退出;否则,
赋随机值,使得等式
成立。
- 对于数组G中仍为null的位置,给它们赋上随机值。
此方案中,将GBF作为hint发送给接收方进行处理。

(3)基于hash表的处理
-
KeyGen(P) → (k, hint):
- 为PRF函数 F 随机选择一个密钥 k。
- 构造一个大小为
的表 T。
- 随机选取 nonce v,使得
中的每个元素互不相同。
- 对于
,计算
,设
。
- 将表 T中其他位置放入随机值。nonce v与哈希表 T 即为 hint。
-
计算:
。

此外,文献【22】实现了基于cuckoo hash的OPPRF方案,使得性能进一步提升,原理图如下,感兴趣可以看下论文。

总结:
本文对PSI应用、原理做了相应分析,相信能够对行业内常用的PSI以及内在原理有了一定的认知,对于后续理解更多的PSI算法希望有一定的帮助。
4. 参考文献
【1】Efficient Batched Oblivious PRF with Applications to Private Set Intersection
【2】Private Set Intersection in the Internet Setting From Lightweight Oblivious PRF
【3】Blazing Fast PSI from Improved OKVS and Subfield VOLE
【4】「隐私计算基础理论」安全求交集和匿踪查询
【5】RR22 Blazing Fast PSI 实现介绍
【6】技术分享 | 隐私集合求交(PSI)技术体系整理
【7】libPSI 开源库中实现的协议
【8】不经意传输协议研究综述
【9】不经意传输扩展(OTE)-不经意伪随机函数(OPRF)-隐私集合求交(PSI)
【10】KKRT-PSI
【11】透明伪随机函数(OPRF)与隐私集合求交(PSI)
【12】隐私求交问题(PSI)与透明键值对存储(OKVS)
【13】Circuit-PSI With Linear Complexity via Relaxed Batch OPPRF
【14】VOLE-PSI: Fast OPRF and Circuit-PSI from Vector-OLE
【15】安全求交、联邦学习模型的训练方法及系统、设备及介质
【16】一种安全高效的全匿踪纵向联邦学习方法
【17】iPrivJoin: An ID-Private Data Join Framework for Privacy-Preserving Machine Learning
【18】一种数据处理方法、装置、计算机设备以及可读存储介质
【19】基于国密的高效匿踪联邦学习方法、系统及相关设备
【20】多方隐私集合求wen xin交(PSI)从原理到实现
【21】多方隐私集合求教技术-MPSI技术概论
【22】Chandran, Nishanth, Divya Gupta, and Akash Shah. "Circuit-PSI with linear complexity via relaxed batch OPPRF." Proceedings on Privacy Enhancing Technologies (2022).
【23】RSA Intersection
相关文章:
【隐私计算篇】隐私集合求交(PSI)原理深入浅出
隐私集合求交技术是多方安全计算领域的一个子问题,通常也被称为安全求交、隐私保护集合交集或者隐私交集技术等,其目的是允许持有各自数据集的双方或者多方,执行两方或者多方集合的交集计算,当PSI执行完成,一方或者两方…...

工作中常用的8种设计模式
前言 设计模式在我们日常的软件开发中无处不在,它们帮助我们编写更易扩展、更具可读性的代码。 今天结合我实际工作场景和源码实例,跟大家一起聊聊工作中最常用的8种设计模式,希望对你会有所帮助。 1. 单例模式 单例模式确保一个类只有一…...

Qwen 论文阅读记录
本文仅作自己初步熟悉大模型,梳理之用,慢慢会更改/增加/删除,部分细节尚未解释,希望不断学习之后,能够完善补充。若有同道之人,欢迎指正探讨。 关于后面的code-qwen and math-qwen,我个人认为依…...

自动驾驶:百年演进
亲爱的小伙伴们😘,在求知的漫漫旅途中,若你对深度学习的奥秘、JAVA 、PYTHON与SAP 的奇妙世界,亦或是读研论文的撰写攻略有所探寻🧐,那不妨给我一个小小的关注吧🥰。我会精心筹备,在…...

SSM 校园一卡通密钥管理系统 PF 于校园图书借阅管理的安全保障
摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装校园一卡通密钥管理系统软件来发挥其高效地信息处理的作用&a…...

什么叫中间件服务器?
什么叫中间件服务器?它在软件架构中扮演着怎样的角色?在现代应用程序开发中,中间件服务器的概念很多人对它并不太熟悉,但其实它的作用却不小。 中间件服务器是一种连接不同软件应用程序的中介。想象一下,在一个大型企…...
【docker】12. Docker Volume(存储卷)
什么是存储卷? 存储卷就是将宿主机的本地文件系统中存在的某个目录直接与容器内部的文件系统上的某一目录建立绑定关系。这就意味着,当我们在容器中的这个目录下写入数据时,容器会将其内容直接写入到宿主机上与此容器建立了绑定关系的目录。 在宿主机上…...

SpringBoot【八】mybatis-plus条件构造器使用手册!
一、前言🔥 环境说明:Windows10 Idea2021.3.2 Jdk1.8 SpringBoot 2.3.1.RELEASE 经过上一期的mybatis-plus 入门教学,想必大家对它不是非常陌生了吧,这期呢,我主要是围绕以下几点展开,重点给大家介绍 里…...

OpenAI直播发布第4天:ChatGPT Canvas全面升级,免费开放!
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,专注于分享AI全维度知识,包括但不限于AI科普,AI工…...

自学高考的挑战与应对:心理调适、学习方法改进与考试技巧提升
一、自学参加高考的成功条件 (一)报名条件 基本要求 自学参加高考,首先需严格遵守国家的法律法规,这是参与高考的基本前提。具备高中同等学力是核心要素之一,意味着考生需通过自学掌握高中阶段的知识体系与学习能力…...

2024年12月11日Github流行趋势
项目名称:maigret 项目维护者:soxoj, kustermariocoding, dependabot, fen0s, cyb3rk0tik项目介绍:通过用户名从数千个站点收集个人档案信息的工具。项目star数:12,055项目fork数:870 项目名称:uv 项目维护…...

Next.js配置教程:构建自定义服务器
更多有关Next.js教程,请查阅: 【目录】Next.js 独立开发系列教程-CSDN博客 目录 前言 1. 什么是自定义服务器? 2. 配置自定义服务器 2.1 基础配置 2.2 集成不同的服务器框架 使用Fastify 使用Koa 3. 自定义服务器的高级功能 3.1 路…...

SpringCloud 题库
这篇文章是关于 SpringCloud 面试题的汇总,包括微服务的概念、SpringCloud 的组成及相关技术,如服务注册与发现、负载均衡、容错等,还涉及 Nacos 配置中心、服务注册表结构等原理,以及微服务架构中的日志采集、服务网关、相关概念…...

基于Filebeat打造高效日志收集流水线
1. 引言 在现代的分布式系统中,日志数据的收集、存储与分析已经成为不可或缺的一部分。随着应用程序、服务和微服务架构的普及,日志数据呈现出爆炸式增长。日志不仅是系统运行的“侦探”,能够帮助我们在出现问题时进行快速排查,还…...

《HTML 的变革之路:从过去到未来》
一、HTML 的发展历程 图片: HTML 从诞生至今,经历了多个版本的迭代。 (一)早期版本 HTML 3.2 在 1997 年 1 月 14 日成为 W3C 推荐标准,提供了表格、文字绕排和复杂数学元素显示等新特性,但因实现复杂且缺乏浏览器…...
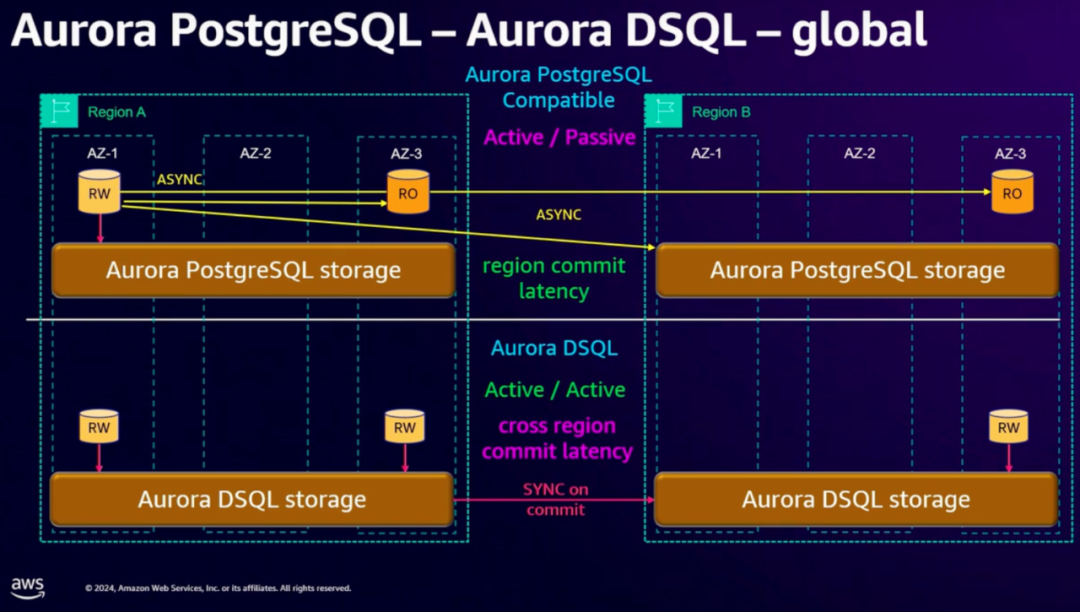
快速了解 Aurora DSQL
上周在 AWS re:Invent大会(类似于阿里云的云栖大会)上推出了新的产品 Aurora DSQL[1] ,在数据库层面提供了多区域、多点一致性写入的能力,兼容 PostgreSQL。并声称,在多语句跨区域的场景下,延迟只有Google …...

计算机视觉与医学的结合:推动医学领域研究的新机遇
目录 引言医学领域面临的发文难题计算机视觉与医学的结合:发展趋势计算机视觉结合医学的研究方向高区位参考文章结语 引言 计算机视觉(Computer Vision, CV)技术作为人工智能的重要分支,已经在多个领域取得了显著的应用成果&…...

Scala的隐式对象
Scala中,隐式对象(implicit object)是一种特殊的对象,它可以使得其成员(如方法和值)在特定的上下文中自动可用,而无需显式地传递它们。隐式对象通常与隐式参数和隐式转换一起使用,以…...

PageHelper自定义Count查询及其优化
PageHelper自定义Count查询及其优化 文章目录 PageHelper自定义Count查询及其优化一:背景1.1、解决方法 二:利用反射判断请求参数是否有模糊查询2.1、分页不执行count2.2、思路2.3、代码示例 三:自定义COUNT查询SQL(只适用于单表)3.1、局限性…...

【数据结构】哈夫曼树
哈夫曼树 路径长度:从树中一个结点到另一个结点之间的分支构成这两个节点之间的路径,路径上的分支数目称为路径长度 树的带权路径长度:树中所有叶子结点的带权路径长度之和,通常记为WPL ∑ k 1 n w k l k \sum^{n}_{k1}w_kl_k …...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...

Visual Studio Code 扩展
Visual Studio Code 扩展 change-case 大小写转换EmmyLua for VSCode 调试插件Bookmarks 书签 change-case 大小写转换 https://marketplace.visualstudio.com/items?itemNamewmaurer.change-case 选中单词后,命令 changeCase.commands 可预览转换效果 EmmyLua…...
2025-05-08-deepseek本地化部署
title: 2025-05-08-deepseek 本地化部署 tags: 深度学习 程序开发 2025-05-08-deepseek 本地化部署 参考博客 本地部署 DeepSeek:小白也能轻松搞定! 如何给本地部署的 DeepSeek 投喂数据,让他更懂你 [实验目的]:理解系统架构与原…...