【Spark】Spark Join类型及Join实现方式
如果觉得这篇文章对您有帮助,别忘了点赞、分享或关注哦!您的一点小小支持,不仅能帮助更多人找到有价值的内容,还能鼓励我持续分享更多精彩的技术文章。感谢您的支持,让我们一起在技术的世界中不断进步!
Spark Join类型

1. Inner Join (内连接)
- 示例:
val result = df1.join(df2, df1("id") === df2("id"), "inner") - 执行逻辑:只返回那些在两个表中都有匹配的行。
2. Left Join (左外连接)
- 示例:
val result = df1.join(df2, df1("id") === df2("id"), "left") - 执行逻辑:返回左表的所有记录,并且右表的匹配行,若右表没有匹配行则返回
null。
3. Right Join (右外连接)
- 示例:
val result = df1.join(df2, df1("id") === df2("id"), "right") - 执行逻辑:返回右表的所有记录,并且左表的匹配行,若左表没有匹配行则返回
null。
4. Full Join (全外连接)
- 示例:
val result = df1.join(df2, df1("id") === df2("id"), "outer") - 执行逻辑:返回左表和右表的所有记录,若某一方没有匹配,另一方则填充
null。
5. Left Semi Join (左半连接)
- 示例:
val result = df1.join(df2, df1("id") === df2("id"), "left_semi") - 执行逻辑:返回左表中与右表匹配的行,只返回左表数据,不返回右表。
6. Left Anti Join (左反连接)
- 示例:
val result = df1.join(df2, df1("id") === df2("id"), "left_anti") - 执行逻辑:返回左表中不与右表匹配的行。
7. Cross Join (笛卡尔积连接)
- 示例:
val result = df1.crossJoin(df2) - 执行逻辑:返回两表的笛卡尔积,左表的每一行与右表的每一行组合。
Spark Join实现方式
在 Spark 中,
Join操作有多种实现方式,每种方式的实现原理、适用场景和执行性能有所不同。接下来我们详细讨论以下几种常见的
Join实现方式:

1. CPJ(Cartesion Product Join)笛卡尔积连接
工作原理:
- 笛卡尔积连接是最基础的连接方式,它将两个数据集的每一条记录与另一个数据集的每一条记录进行配对,从而生成一个新的结果集。这个操作是非常低效的,因为它会产生
N * M条记录(N和M分别是两个数据集的行数)。- 这种方式不需要连接条件,因此通常不是我们期望的连接类型。
执行性能:
- 效率低:当两个数据集的大小很大时,计算量将急剧增加。通常,笛卡尔积连接仅在明确需要时使用(例如,计算所有可能的配对)。
Spark 选择笛卡尔积的情况:
- 笛卡尔积连接在 Spark 中通常是显式调用
crossJoin()时使用。2. SMJ(Shuffle Sort Merge Join)排序归并连接
工作原理:
- 排序归并连接首先对两个数据集按照连接键进行排序,然后使用
merge操作将排序后的数据集进行合并。数据集会被按连接键进行shuffle,然后在每个分区内执行归并操作。- 这种方法非常适合处理大规模的分布式数据,尤其是当两个数据集都很大并且有良好的分区时。
执行性能:
- 效率较高:适合大数据量的连接,尤其当连接键有排序特性时。
- 由于需要对数据进行排序和
shuffle,这会增加网络和磁盘的 I/O 成本。Spark 选择 SMJ 的情况:
- 当数据集较大并且 Spark 能够进行有效的
shuffle操作时,Spark 会选择SMJ。- 如果连接的表已经分区或有排序字段,则 Spark 会优先选择该方式。
3. SHJ(Shuffle Hash Join)哈希连接
工作原理:
- 哈希连接(SHJ) 是一种基于哈希表的连接方式。其基本思想是将一个表(通常是较小的表)哈希到内存中,然后通过哈希表查找另一个表的匹配记录。该方法特别适合处理大规模的数据集,尤其是当连接的两个数据集都比较大时,或者当连接键不具有顺序或排序特性时。
- 执行步骤:
- 分区阶段(Shuffle):首先,Spark 会将两个数据集根据连接键进行
shuffle(重分区),确保具有相同连接键的记录被发送到同一个节点。此时,数据会按照连接键进行重分区。- 构建哈希表:选择较小的表(通常是内表),在每个节点上对该表进行哈希,构建哈希表。哈希表存储连接键及其对应的记录。
- 匹配查找:然后,在同一个节点上扫描较大的表(外表),对于每一条记录,使用相同的连接键查找哈希表中的匹配项。如果匹配,则生成结果。
执行性能:
- 高效:相比传统的嵌套循环连接(
NLJ),哈希连接通常在处理大数据集时更为高效,特别是当连接条件是等值连接时。Spark 选择 SHJ 的情况:
- 外表大小至少是内表的3倍且内表的数据分片平均大小要小于广播变量阈值,Spark 会选择 Shuffle Hash Join。
4. BNLJ(Broadcast Nested Loop Join)广播嵌套循环连接
工作原理:
- 广播嵌套循环连接是嵌套循环连接的一种优化形式,针对连接的一个表较小的情况。它首先将较小的表(通常是内表)广播到所有执行节点,然后对大表(通常是外表)进行扫描。在每个节点上,将小表加载到内存中,并在每个分区上与外表进行连接。
执行性能:
- 高效:相比于传统的嵌套循环连接(
Nested Loop Join),广播嵌套循环连接的效率较高,因为它通过将小表广播到每个节点,避免了全局的shuffle操作,减少了数据传输的延迟。- 适合当一个表非常小(例如,
broadcast()小表时)时,执行性能特别好。Spark 选择 BNLJ 的情况:
- Spark 会自动选择 Broadcast Nested Loop Join,当数据集中的一个表较小(可以放入内存)时,Spark 会选择该表进行广播,从而提高连接操作的性能。通常,Spark
会根据表的大小和内存限制来决定是否使用广播join。5. BHJ(Broadcast Hash Join)广播哈希连接
工作原理:
- 广播哈希连接通过将一个小表广播到所有执行节点,从而避免了全局的
shuffle操作。大的数据集会被分配到多个节点,而小的数据集会被广播到每个节点。- 这种方式非常高效,适用于连接一个大表和一个小表的情况。
执行性能:
- 效率非常高:适用于大表和小表连接,避免了大规模的
shuffle操作。- 适合当一个表非常小(例如,
broadcast()小表时)时,执行性能特别好。Spark 选择 BHJ 的情况:
- 如果其中一个表很小,Spark 会选择
BHJ,因为将小表广播到所有节点可以大大减少shuffle的开销。Spark 如何选择
Join策略?1. 等值 Join
在等值数据关联中,Spark 会尝试按照以下顺序选择最优的连接策略:
- BHJ(Broadcast Hash Join)
- SMJ(Shuffle Sort Merge Join)
- SHJ(Shuffle Hash Join)
适用场景:
- BHJ(Broadcast Hash Join): 连接类型不能是全连接(Full Outer Join),基表需要足够小,能够放入内存并通过广播发送到所有节点。
- SMJ(Shuffle Sort Merge Join)与 SHJ(Shuffle Hash Join):支持所有连接类型,如Full Outer Join,Anti join
为什么SHJ比SMJ执行效率高,排名却不如SMJ靠前
- 相比 SHJ,Spark优先选择SMJ的原因在于,SMJ的实现方式更加稳定,更不容易OOM
- 在 Spark 中,SHJ(Shuffle Hash Join) 策略要想被选中,需要满足以下两个先决条件:
- a. 外表大小至少是内表的 3 倍:只有当内外表的尺寸悬殊到一定程度时,SHJ 的性能优势才会明显超过 SMJ。
- b. 内表的数据分片平均大小要小于广播变量阈值:内表的数据分片必须足够小,以便能够通过广播传递到各个节点,而不引起内存溢出或性能问题。
- 相比 SHJ,SMJ没有这么多的附加条件,无论是单表排序,还是两表做归并关联,都可以借助磁盘来完成。内存中放不下的数据,可以临时溢出到磁盘
2. 非等值 Join
- 在非等值数据关联中,Spark可选的Join策略只有BNLJ(Broadcast Nested Loop Join)和CPJ(Cartesion Product Join),BNLJ适合内表满足广播情况,否则只能用CPJ兜底
相关文章:
【Spark】Spark Join类型及Join实现方式
如果觉得这篇文章对您有帮助,别忘了点赞、分享或关注哦!您的一点小小支持,不仅能帮助更多人找到有价值的内容,还能鼓励我持续分享更多精彩的技术文章。感谢您的支持,让我们一起在技术的世界中不断进步! Sp…...

meta llama 大模型一个基础语言模型的集合
LLaMA 是一个基础语言模型的集合,参数范围从 7B 到 65B。我们在数万亿个 Token 上训练我们的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而无需诉诸专有的和无法访问的数据集。特别是,LLaMA-13B 在大多数基准测试…...

JAVA爬虫获取1688关键词接口
以下是使用Java爬虫获取1688关键词接口的详细步骤和示例代码: 一、获取API接口访问权限 要使用1688关键词接口,首先需要获取API的使用权限,并了解接口规范。以下是获取API接口的详细步骤: 注册账号:在1688平台注册一…...

操作系统——内存管理
1、什么是虚拟内存?它是如何实现的?虚拟内存与物理内存之间有什么关系? 虚拟内存是操作系统提供的一种内存管理机制,它使程序认为自己拥有连续的内存空间,但实际上内存可能被分散存储在物理内存和磁盘交换空间中。 虚…...

android studio 模拟器不能联网?
模拟器路径: C:\Users\Administrator\AppData\Local\Android\Sdk\emulator\emulator.exe.关闭所有AVD设备实例 导航至: C:\Users\userName\AppData\Local\Android\Sdk\emulator查看模拟器名称 AdministratorDESKTOP-6JB1OGC MINGW64 ~/AppData/Local/…...

CTF-WEB: 目录穿越与模板注入 [第一届国城杯 Ez_Gallery ] 赛后学习笔记
step1 验证码处存在逻辑漏洞,只要不申请刷新验证码就一直有效 字典爆破得到 admin:123456 step2 /info?file../../../proc/self/cmdline获得 python/app/app.py经尝试,读取存在的目录时会返回 A server error occurred. Please contact the administrator./info?file.…...

数据结构6.4——归并排序
基本思想: 归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个…...

【html 常用MIME类型列表】
本表仅列出了常用的MIME类型,完整列表参考文档。 浏览器通常使用 MIME 类型(而不是文件扩展名)来确定如何处理 URL,因此 Web 服务器在响应头中添加正确的 MIME 类型非常重要。 如果配置不正确,浏览器可能会曲解文件内容…...
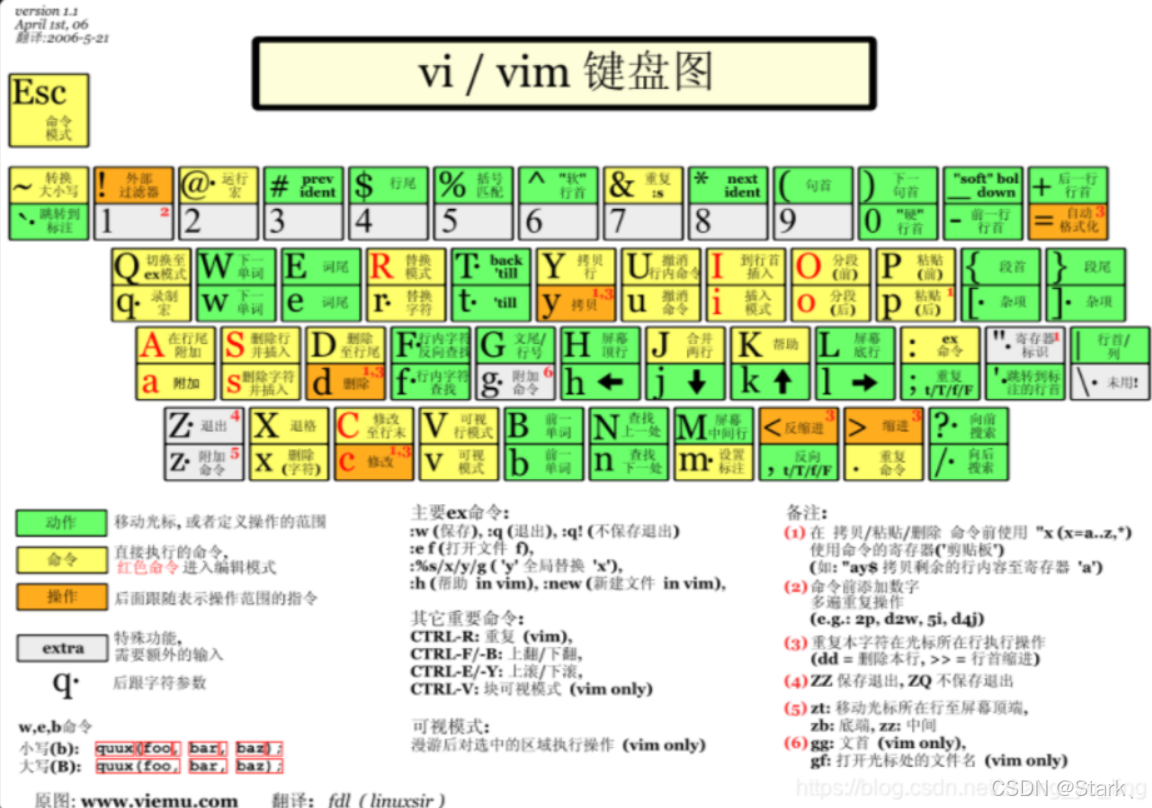
Linux之vim编辑器
vi编辑器是所有Unix及linux系统下标准的编辑器,类似于Windows系统下的记事本。很多软件默认使用vi作为他们编辑的接口。vim是进阶版的vi,vim可以视为一种程序编辑器。 前言: 1.文件准备 复制 /etc/passwd文件到自己的目录下(不…...

【工具介绍】可以批量查看LableMe标注的图像文件信息~
在图像处理和计算机视觉领域,LabelMe是一个广泛使用的图像标注工具,它帮助我们对图像中的物体进行精确的标注。但是,当标注完成后,我们常常需要一个工具来批量查看这些标注信息。 今天,我要介绍的这款exe程序…...
“信息安全管理与评估”赛项规程)
2024年山西省第十八届职业院校技能大赛 (高职组)“信息安全管理与评估”赛项规程
2024年山西省第十八届职业院校技能大赛 (高职组)“信息安全管理与评估”赛项规程 一、赛项名称 赛项名称:信息安全管理与评估 英文名称:Information Security Management and Evaluation 赛项组别:高职教师组 赛项归属…...

STM32完全学习——STemWin的移植小插曲
一、移植编译的一些问题 新版的STemWin的库没有区别编译器,只有一些这样的文件,默认你将这些文件导入到KEIL中,然后编译就会有下面的错误。 ..\MEWIN\STemWin\Lib\STemWin_CM4_wc16.a(1): error: A1167E: Invalid line start ..\MEWIN\STe…...

Java——IO流(下)
一 (字符流扩展) 1 字符输出流 (更方便的输出字符——>取代了缓冲字符输出流——>因为他自己的节点流) (PrintWriter——>节点流——>具有自动行刷新缓冲字符输出流——>可以按行写出字符串,并且可通过println();方法实现自动换行) 在Java的IO流中…...

avue-crud 同时使用 column 与 group 的问题
场景一:在使用option 中的column 和 group 进行表单数据新增操作时,进行里面的控件操作时,点击后卡死问题,文本没问题 其它比如下拉,单选框操作,当删除 column 中的字段后, group 中的可以操作 …...

深入解析 Pytest 中的 conftest.py:测试配置与复用的利器
在 Pytest 测试框架中,conftest.py 是一个特殊的文件,用于定义测试会话的共享配置和通用功能。它是 Pytest 的核心功能之一,可以用于以下目的: 【主要功能】 1、定义共享的 Fixture (1)conftest.py 文件可…...

JAVA |日常开发中Websocket详解
JAVA |日常开发中Websocket详解 前言一、Websocket 概述1.1 定义1.2 优势 二、Websocket 协议基础2.1 握手过程2.2 消息格式2.3 数据传输方式 三、Java 中使用 Websocket3.1 Java WebSocket API(JSR - 356)3.2 第三方库(如 Tyrus&…...

Typora教程
目录 一、下载安装 二、激活 1.激活 2.解决激活提示窗口 一、下载安装 去官网下载Typora安装,我的是1.9.5版本 二、激活 1.激活 根据路径找到Typora/resources/page-dist/static/js 使用记事本打开LicenseIndex文件,如下图: 按住快捷…...

泛微E9常见API保姆级详解!!!!
前言 在泛微前端开发过程中,虽然大部分是对流程以及流程逻辑的调整,但是还是会有一些小的个性化需求是需要借助JS来实现的。 比如:对同一组数据,前后变化不一样时,需要对这组变化后的数据进行标红处理;对提…...

UniApp配置使用原子化tailwindcss
参考视频 创建项目 新建项目选择uniapp - vue版本这里我选择3 - 点击创建即可 创建完成后,如果是要编译到小程序的项目则可以先将项目运行到小程序打开了 初始化package.json 执行 npm init -y安装和配置 安装 npm i -D tailwindcss postcss autoprefixer # 安…...
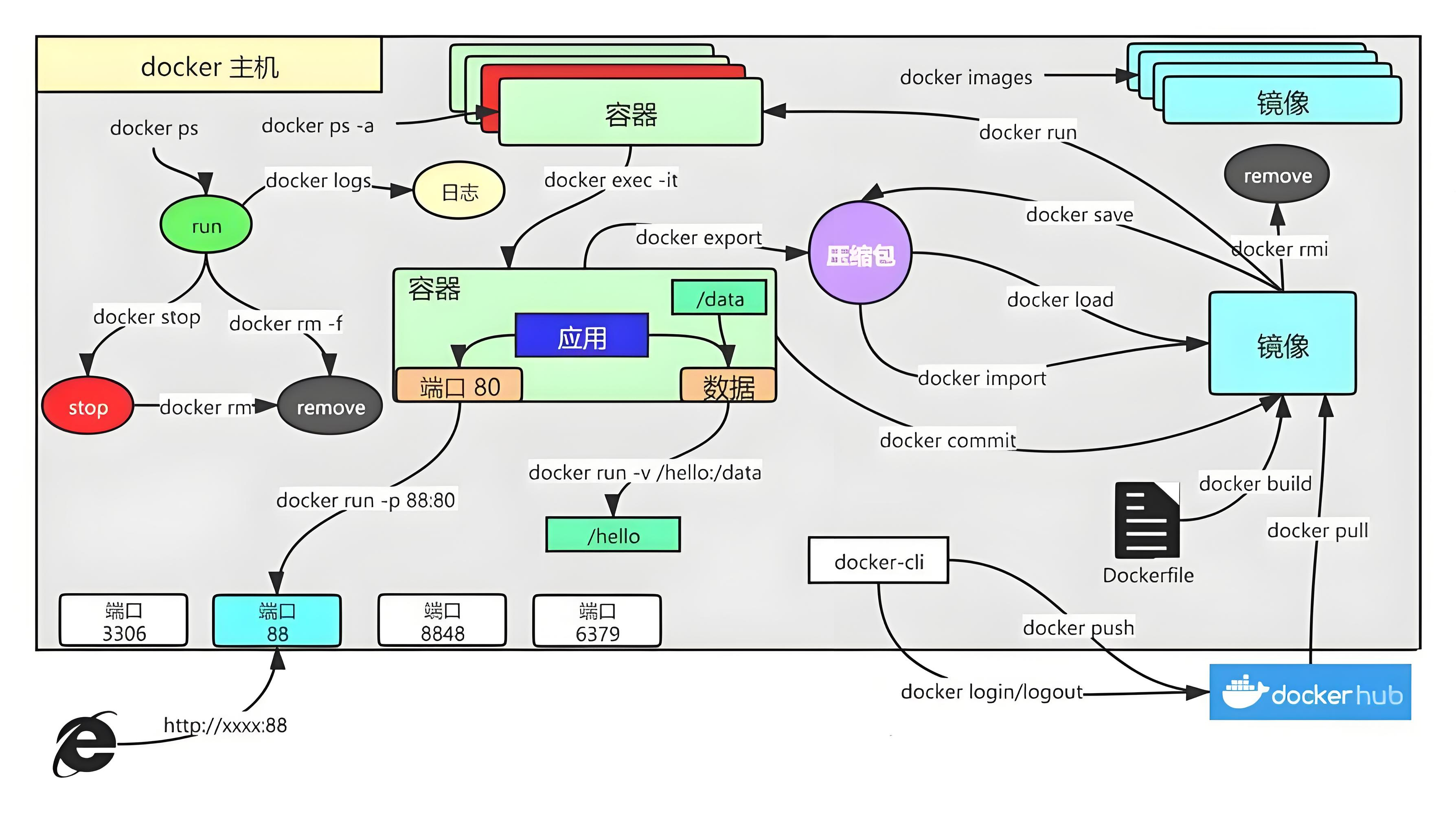
02. Docker:安装和操作
目录 一、Docker的安装方式 1、实验环境准备 1.1 关闭防火墙 1.2 可以访问网络 1.3 配置yum源 2、yum安装docker 2.1 安装docker服务 2.2 配置镜像加速 2.3 启动docker服务 3、二进制安装docker 3.1 下载或上传安装包并解压 3.2 配置使用systemctl管理 3.3 配置镜像…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...
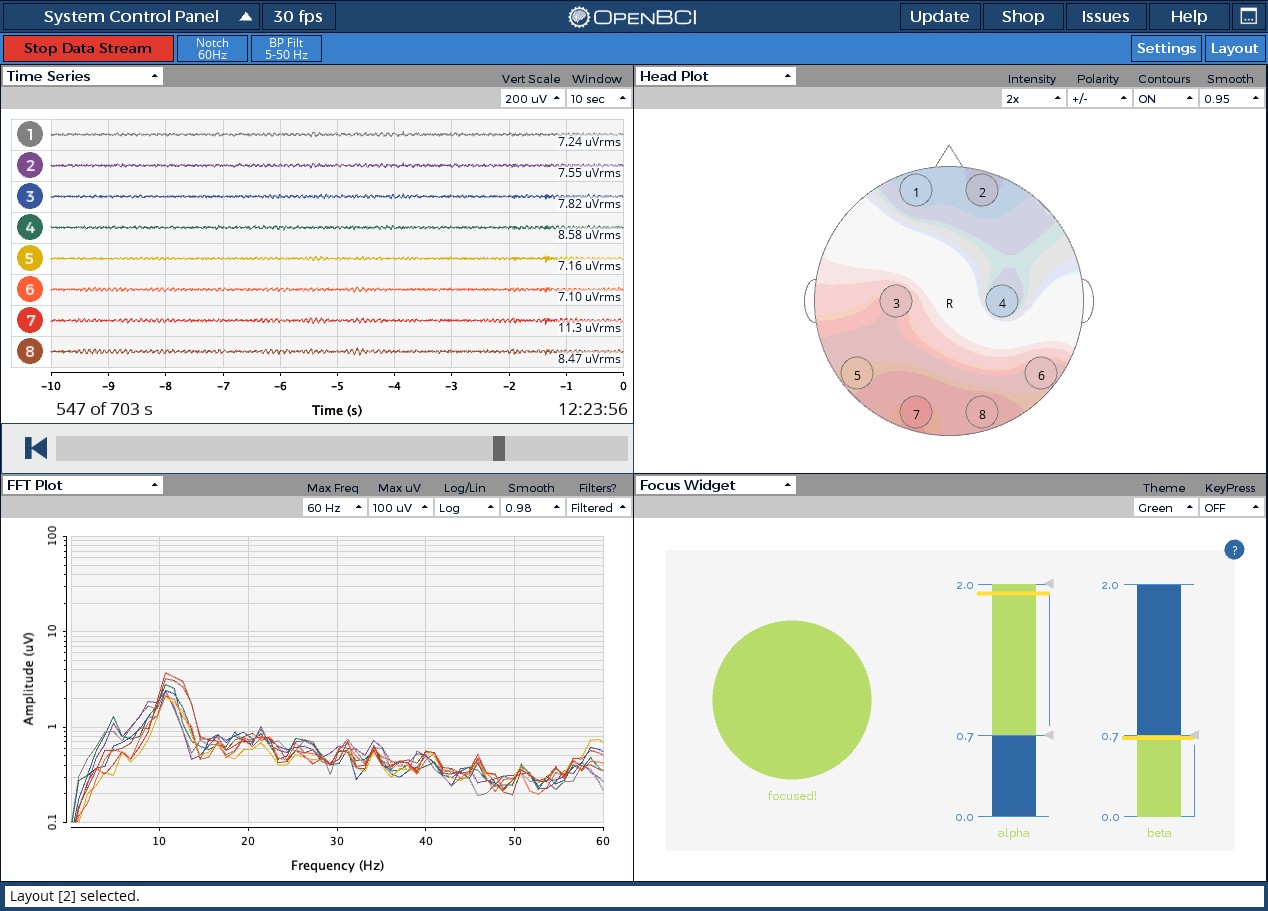
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...