将HTML转换为PDF:使用Spire.Doc的详细指南(二)无水印版
目录
引言
一、准备工作
1. 下载Spire.Doc for Java破解版
2. 将JAR包安装到本地Maven
(1) 打开命令提示符
(2) 输入安装命令
(3) 在pom.xml中导入依赖
二、实现HTML到PDF的转换
1. 创建Java类
2. 完整代码示例
3. 代码解析
4. 处理图像
5. 性能优化
6. 错误处理与日志管理
三、测试与优化
1. 测试文件的准备
2. 代码执行
3. 进一步的优化
四、总结
在现代应用需求中,HTML文件转换为PDF文件的功能越来越受到重视,尤其是在文档生成、报告制作等场景中。Spire.Doc for Java是一个强大的Java文档处理库,支持各种文档格式的操作。本文将详细介绍如何使用Spire.Doc for Java破解版将HTML文件转换为PDF文件。我们将通过实际操作步骤指导您完成整个过程。
引言
随着信息化的发展,越来越多的企业和开发者需要将动态的网页内容以PDF文档的形式呈现。虽然Spire.Doc for Java有试用版可供使用,但试用版生成的PDF文件上会有水印,影响最终文档的美观性。因此,使用破解版成为一个必要的选择。通过使用Spire.Doc for Java破解版,我们可以获得更为完整和美观的PDF文件。
一、准备工作
1. 下载Spire.Doc for Java破解版
首先,您需要从以下链接中下载Spire.Doc for Java破解版。
下载链接:
https://download.csdn.net/download/Chaochao1984a/89306550?utm_medium=distribute.pc_relevant_download.none-task-download
-2~default~OPENSEARCH~XGB-1-89306550-download-89582629.257%5Ev16%5Epc_dl_relevant_base1_c&depth_1-utm_source=distribute.
pc_relevant_download.none-task-download-2~default~OPENSEARCH~XG
B-1-89306550-download-89582629.257%5Ev16%5Epc_dl_relevant_base1_c&spm=1003.2020.3001.6616.1
2. 将JAR包安装到本地Maven
下载完成后,我们需要将此JAR包添加到本地Maven库中,以便在项目中使用。以下是安装JAR包的步骤:
(1) 打开命令提示符
在您保存JAR包的目录下,打开命令提示符窗口。可以在文件资源管理器中按住Shift键并右键点击空白处,选择“在此处打开命令窗口”。
(2) 输入安装命令
在命令提示符中输入以下命令,将JAR包安装到Maven本地库:
mvn install:install-file -DgroupId=e-iceblue -DartifactId=spirej.doc -Dversion=11.4.2 -Dpackaging=jar -DgeneratePom=true -Dfile=spirej.doc.cracked-11.4.2.jar这里,groupId、artifactId和version可以根据需要自定义,以适应您的项目需求。
(3) 在pom.xml中导入依赖
安装完成后,您需要在您的Maven项目的pom.xml中添加依赖项。打开pom.xml文件,并在<dependencies>标签内添加以下代码:
<dependency> <groupId>e-iceblue</groupId> <artifactId>spirej.doc</artifactId> <version>11.4.2</version>
</dependency>确保保存修改后的配置文件。
二、实现HTML到PDF的转换
在完成了环境准备和依赖配置后,我们将开始实现HTML到PDF的转换功能。以下是实现步骤。
1. 创建Java类
接下来,我们创建一个Java类,命名为DocToPdfConverter,该类用于实现从HTML文件读取内容并将其转化为PDF文件。
2. 完整代码示例
请看以下完整代码实现:
package com.dahua.saas.illegalpunish.controller;import com.sini.com.spire.doc.Document;
import com.sini.com.spire.doc.FileFormat;
import com.sini.com.spire.doc.Section;import javax.net.ssl.*;
import java.security.cert.X509Certificate;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class DocToPdfConverter {public static void main(String[] args) throws IOException {disableSSLVerification();String inputHtml = "C:\\cloud\\dahua\\VIASBIllegalPunish\\file\\1912202400023.doc";Document doc = new Document();Section sec = doc.addSection();String htmlText = readTextFromFile(inputHtml);sec.addParagraph().appendHTML(replaceImagesWithHighRes(htmlText));doc.saveToFile("C:\\cloud\\dahua\\VIASBIllegalPunish\\file\\1912202400023.pdf", FileFormat.PDF);doc.dispose();}/*** 读取文本文件内容** @param fileName 文件名* @return 文件内容字符串* @throws IOException 文件读取异常*/public static String readTextFromFile(String fileName) throws IOException {StringBuilder sb = new StringBuilder();BufferedReader br = new BufferedReader(new FileReader(fileName));String content;while ((content = br.readLine()) != null) {sb.append(content);sb.append(System.lineSeparator()); // Maintain original line structure}return sb.toString();}/*** 替换HTML中的图片链接为高清图片链接** @param html HTML字符串* @return 替换后的HTML字符串*/public static String replaceImagesWithHighRes(String html) {String imageUrlPattern = "https?://[^\\s\"'<>]+";Pattern pattern = Pattern.compile(imageUrlPattern);Matcher matcher = pattern.matcher(html);StringBuffer resultHtml = new StringBuffer();while (matcher.find()) {String imageUrl = matcher.group(); // Get the matched URLString highResImage = downloadImage(imageUrl); // Download high-resolution imagematcher.appendReplacement(resultHtml, highResImage); // Replace found URL}matcher.appendTail(resultHtml); // Append the rest of the unmatched textreturn resultHtml.toString(); // Return replaced HTML}/*** 下载图片** @param imageUrl 图片URL* @return 下载成功返回处理后的图片数据/路径,下载失败返回原URL*/public static String downloadImage(String imageUrl) {try {URL url = new URL(imageUrl);HttpURLConnection connection = (HttpURLConnection) url.openConnection();connection.setDoInput(true);connection.connect();InputStream input = connection.getInputStream();return imageUrl;} catch (IOException e) {e.printStackTrace();return imageUrl;}}/*** 禁用SSL证书验证*/public static void disableSSLVerification() {try {TrustManager[] trustAllCerts = new TrustManager[]{new X509TrustManager() {public X509Certificate[] getAcceptedIssuers() {return null;}public void checkClientTrusted(X509Certificate[] certs, String authType) {}public void checkServerTrusted(X509Certificate[] certs, String authType) {}}};SSLContext sc = SSLContext.getInstance("SSL");sc.init(null, trustAllCerts, new java.security.SecureRandom());HttpsURLConnection.setDefaultSSLSocketFactory(sc.getSocketFactory());HttpsURLConnection.setDefaultHostnameVerifier((hostname, session) -> true);} catch (Exception e) {e.printStackTrace();}}}3. 代码解析
- 文档创建:首先,我们创建了一个
Document对象,这个对象代表一个Spire.Doc文档。 - 添加HTML内容:我们使用
appendHTML()方法将HTML内容加入到文档中。 - 文件保存:调用
saveToFile()方法保存文档为PDF格式。 - 异常处理:在整个操作中,我们使用了try-catch块来处理潜在的异常,确保程序的健壮性。
4. 处理图像
在本示例中,downloadImage 方法返回的是原始的图像 URL。在实际应用中,您可能需要将下载的图片以适当的格式嵌入 PDF,例如将其转换为 Base64 字符串。下面是一个简单的实现示例:
public static String downloadImage(String imageUrl) { try { URL url = new URL(imageUrl); HttpURLConnection connection = (HttpURLConnection) url.openConnection(); connection.setDoInput(true); connection.connect(); InputStream input = connection.getInputStream(); // Convert InputStream to byte array byte[] imageBytes = input.readAllBytes(); String base64Image = Base64.getEncoder().encodeToString(imageBytes); return "data:image/png;base64," + base64Image; // Assuming image is PNG } catch (IOException e) { e.printStackTrace(); return imageUrl; }
}5. 性能优化
在本示例中,downloadImage 方法返回的是原始的图像 URL。在实际应用中,您可能需要将下载的图片以适当的格式嵌入 PDF,例如将其转换为 Base64 字符串。下面是一个简单的实现示例:
在处理大量图像时,批量处理或异步下载可以显著提高程序的性能和响应速度。以下是一些优化建议和具体实现策略。
5.1 异步下载图像
使用 Java 的并发 API,可以实现异步下载图像。这意味着在处理 HTML 的同时,可以在后台下载图像,不阻塞主线程。
示例代码
使用 CompletableFuture 来实现异步下载图像的能力::
import java.util.concurrent.CompletableFuture; public static CompletableFuture<String> downloadImageAsync(String imageUrl) { return CompletableFuture.supplyAsync(() -> { try { URL url = new URL(imageUrl); HttpURLConnection connection = (HttpURLConnection) url.openConnection(); connection.setDoInput(true); connection.connect(); InputStream input = connection.getInputStream(); byte[] imageBytes = input.readAllBytes(); String base64Image = Base64.getEncoder().encodeToString(imageBytes); return "data:image/png;base64," + base64Image; // 假设图像为 PNG } catch (IOException e) { e.printStackTrace(); return imageUrl; } });
}6. 错误处理与日志管理
在处理网络请求和文件操作时,错误处理至关重要。应确保在项目中实现有效的日志记录和错误处理机制。
6.1 错误处理
确保任何网络请求、文件读取和转换操作都能妥善处理异常情况。以下是一些建议:
捕获并记录异常:应在每个网络请求和文件操作中捕获异常并记录详细信息,以便后期调试。
使用重试机制:对于短暂的网络问题,可以使用重试逻辑重新尝试下载图像。
示例代码:
public static String downloadImageWithRetry(String imageUrl, int retryCount) { for (int i = 0; i < retryCount; i++) { try { return downloadImage(imageUrl); // 使用之前定义的下载逻辑 } catch (IOException e) { if (i == retryCount - 1) { e.printStackTrace(); // 记录最终失败的情况 } } } return imageUrl; // 默认返回原始的 URL
}6.2 日志管理
可以使用日志框架(如 SLF4J、Log4j)来进行日志管理。将日志记录在适当的级别(例如 INFO、WARN、ERROR),可以帮助开发人员在出现问题时快速定位。
示例代码
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; public class DocToPdfConverter { private static final Logger logger = LoggerFactory.getLogger(DocToPdfConverter.class); public static void main(String[] args) { try { // 主逻辑 } catch (Exception e) { logger.error("Error occurred during PDF conversion", e); } } 三、测试与优化
1. 测试文件的准备
在进行实际测试之前,您可以准备一些简单的HTML文件,确保它们包含基本内容和图片链接,以便可以验证转换后的PDF的效果。
2. 代码执行
确保IDE或命令行环境中的配置正确后,您可以直接运行DocToPdfConverter类。在控制台中查看输出,确保转化过程没有错误,并且可以在指定的输出路径找到生成的PDF文件。
3. 进一步的优化
- 性能优化:对于大型HTML文件,您可能需要考虑如何提高代码的执行效率,比如使用流式处理。
- 图片处理:在
downloadImage方法内实现完整的图片下载并存储处理,提高转换后的PDF质量。
四、总结
本文介绍了如何使用Spire.Doc for Java专业版将HTML文件转换为PDF文件的完整步骤。通过准备工作、依赖管理、代码实现、测试与优化等环节,我们已经建立了一个稳健且易于使用的转换工具。
利用Spire.Doc为Java开发人员提供的强大功能,您可以在您的项目中轻松地实现HTML转PDF的需求。同时,通过适当的配置和代码优化,可以确保处理的高效性和可靠性。希望本文能为您在实际开发中提供帮助和启发。如有任何问题,欢迎在评论区留言讨论。
继续关注我们的后续文章,我们将深入探讨更多Java文档处理的技巧和案例,为您的开发之路增添助力。
相关文章:
无水印版)
将HTML转换为PDF:使用Spire.Doc的详细指南(二)无水印版
目录 引言 一、准备工作 1. 下载Spire.Doc for Java破解版 2. 将JAR包安装到本地Maven (1) 打开命令提示符 (2) 输入安装命令 (3) 在pom.xml中导入依赖 二、实现HTML到PDF的转换 1. 创建Java类 2. 完整代码示例 3. 代码解析 4. 处理图像 5. 性能优化 6. 错误处理…...

V900新功能-电脑不在旁边,通过手机给PLC远程调试网关配置WIFI联网
您使用BDZL-V900时,是否遇到过以下这种问题? 去现场配置WIFI发现没带电脑,无法联网❌ 首次配置WIFI时需使用网线连电脑,不够快捷❌ 而博达智联为解决该类问题,专研了一款网关配网工具,实现用户现场使用手机…...
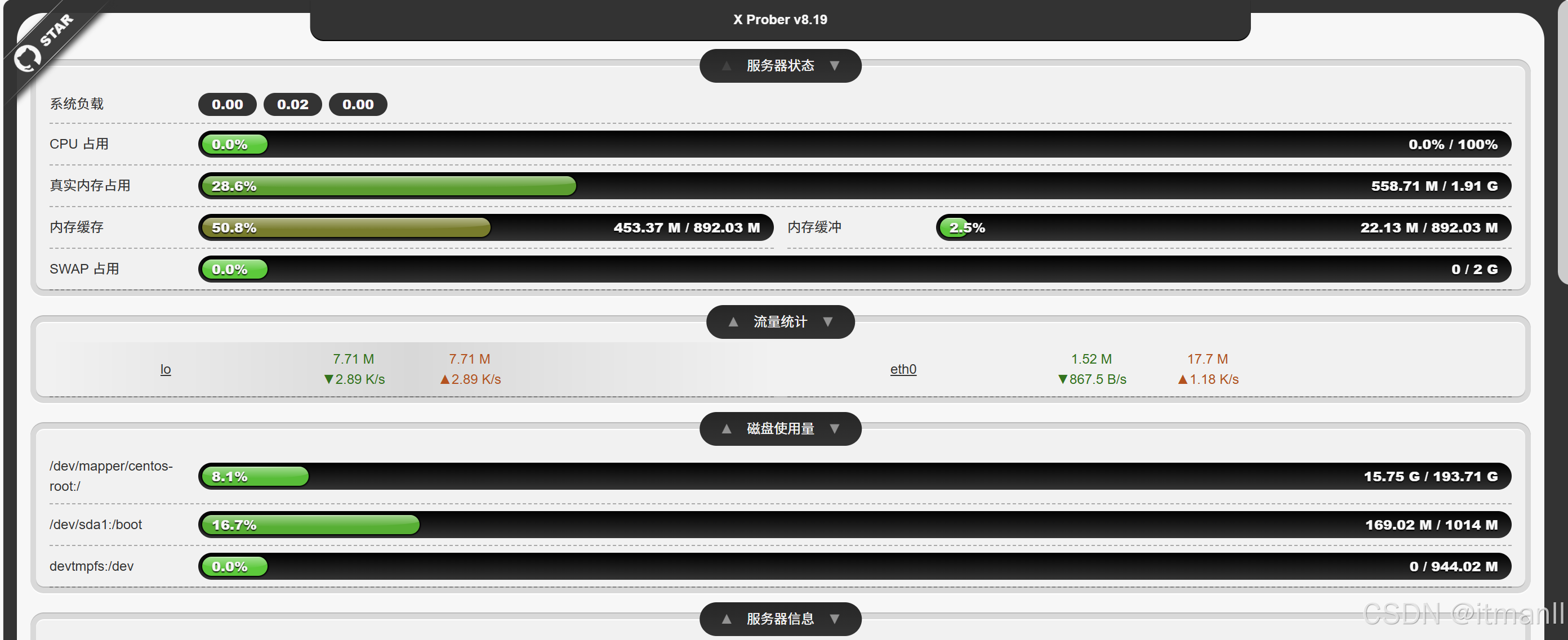
prober.php探针
raw.githubusercontent.com/kmvan/x-prober/master/dist/prober.php...
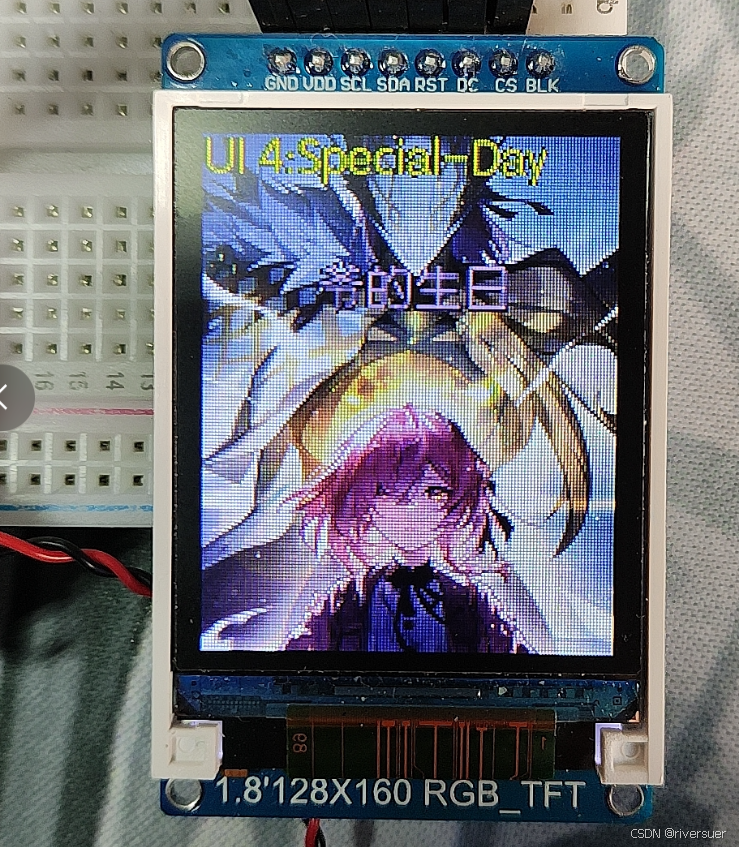
esp8266_TFTST7735语音识别UI界面虚拟小助手
文章目录 一 实现思路1 项目简介1.1 项目效果1.2 实现方式 2 项目构成2.1 软硬件环境2.2 完整流程总结(重点整合)(1) 功能逻辑图(2) 接线(3) 使用esp8266控制TFT屏(4)TFT_espI库配置方法(5) TFT_esp库常用代码详解(6)TFT屏显示图片(7) TFT屏显示汉字(8) …...

【CSS in Depth 2 精译_086】14.3:CSS 剪切路径(clip-path)的用法
当前内容所在位置(可进入专栏查看其他译好的章节内容) 第四部分 视觉增强技术 ✔️【第 14 章 蒙版、形状与剪切】 ✔️ 14.1 滤镜 14.1.1 滤镜的类型14.1.2 背景滤镜 14.2 蒙版 14.2.1 带渐变效果的蒙版特效14.2.2 基于亮度来定义蒙版14.2.3 其他蒙版属…...

【服务器】MyBatis是如何在java中使用并进行分页的?
MyBatis 是一个支持普通 SQL 查询、存储过程和高级映射的持久层框架。它消除了几乎所有的 JDBC 代码和参数的手动设置以及结果集的检索。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java 的 POJO(Plain Old Java Objects,普通老式 …...

vue 文本域 展示的内容格式要和填写时保持一致
文本域 展示的内容格式要和填写时保持一致 <el-inputtype"textarea":rows"5"placeholder"请输入内容"v-model"formCredit.point"style"width:1010px;" > </el-input> 样式加个: white-space: pre-w…...

linux-----进程及基本操作
进程的基本概念 定义:在Linux系统中,进程是正在执行的一个程序实例,它是资源分配和调度的基本单位。每个进程都有自己独立的地址空间、数据段、代码段、栈以及一组系统资源(如文件描述符、内存等)。进程的组成部分&am…...
[Python学习日记-73] 面向对象实战1——答题系统
[Python学习日记-73] 面向对象实战1——答题系统 简介 需求模型——5w1h8c 领域模型 设计模型 实现模型 案例:年会答题系统 简介 在学习完面向对象之后你会发现,你还是不会自己做软件做系统,这是非常正常的,这是因为计算机软…...
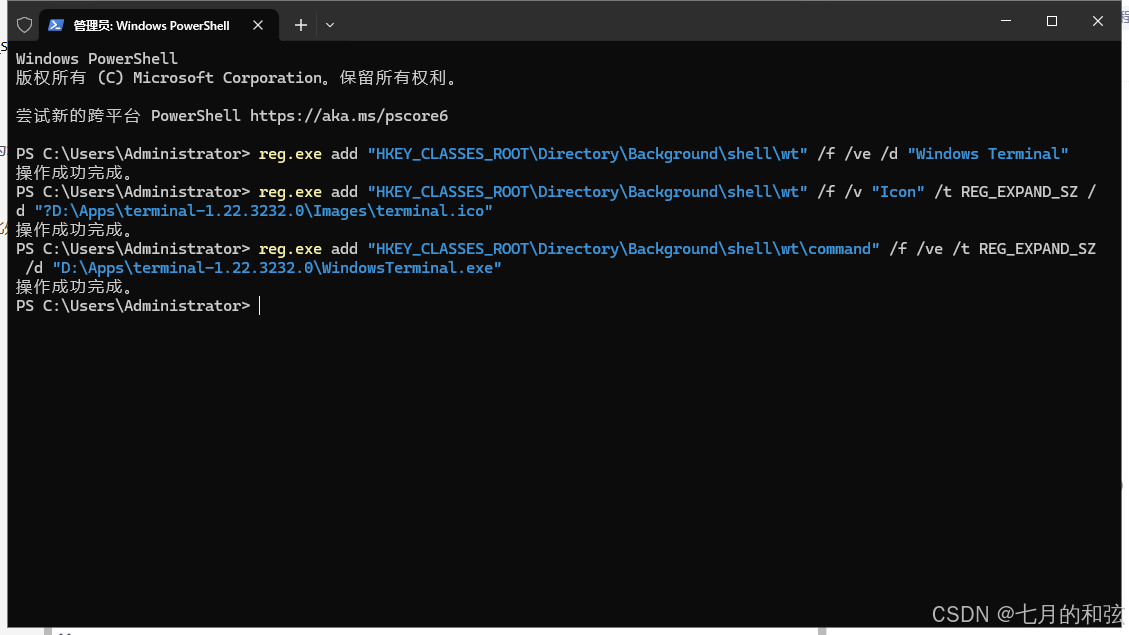
Win10将WindowsTerminal设置默认终端并添加到右键(无法使用微软商店)
由于公司内网限制,无法通过微软商店安装 Windows Terminal,本指南提供手动安装和配置新版 Windows Terminal 的步骤,并添加右键菜单快捷方式。 1. 下载新版终端安装包: 访问 Windows Terminal 的 GitHub 发布页面:https://githu…...

AOI外观缺陷检测机
主要功能: 快速检测产品装配缺陷,包括螺丝、元器件、端子排线、二维码、一维条码、识别读码、产品外观 Logo缺陷以及产品标签、字符缺陷检测等产品的缺陷检测。 设备优势:1.采用轻型可移动支架,可以快速对接产线工艺工序&am…...
精读 84页华为BLM战略规划方法论
这篇文档主要介绍了华为的BLM战略规划方法论,该方法论旨在帮助企业制定战略规划,并确保战略规划的可执行性和有效性。以下是该文档的核心知识点和重点需要关注的内容: 战略规划的定义:战略规划是企业依据企业外部环境和企业自身的…...

工业摄像机基于电荷耦合器件的相机
工业摄像机系列产品及其识别技术的详细介绍: 一、工业摄像机概述 工业摄像机是利用光学成像技术获取视觉信息,并通过图像处理算法分析这些信息的设备。它通常具有高图像稳定性、高传输能力和高抗干扰能力等特性,适用于各种复杂的工业环境。 …...

13.罗意文面试
1、工程化与架构设计(考察项目管理和架构能力) 1.1 你负责的可视化编排项目中,如何设计组件的数据结构来支持"拖拉拽"功能?如何处理组件间的联动关系? // 组件数据结构示例 {components: [{id: comp1,type…...

xxljob window免安装
gitee地址: https://gitee.com/xuxueli0323/xxl-job idea打开 1、配置maven环境 2、修改数据库连接,网页端口 3、修改执行器中连接的网页端口 右侧-xxljob-生命周期-package 生成: D:\xxx\Gitee\xxl-job\xxl-job-admin\target 目录下 x…...
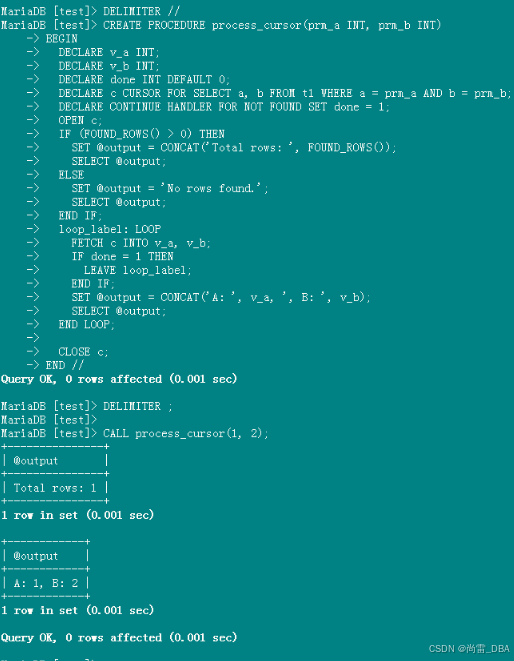
MariaDB 设置 sql_mode=Oracle 和 Oracle 对比验证
功能Oracle语法MariaDB语法Oracle执行结果MariaDB执行结果创建存储过程未使用参数和变量CREATE PROCEDURE p1 ASBEGINNULL;END p1;/ DELIMITER // CREATE PROCEDURE p1()ISBEGINNULL;END // DELIMITER ; 带有参数和变量CREATE PROCEDURE p1(p_input IN NUMBER, p_output OUT NU…...

【AI驱动的数据结构:包装类的艺术与科学】
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:“没有罗马,那就自己创造罗马~” 文章目录 包装类装箱和拆箱阿里巴巴面试题 包装类 在Java中基本数据类型不是继承来自Object,为了…...

初学stm32 --- PWM输出
目录 STM32 PWM工作过程编辑 STM32 PWM工作过程(通道1为例) PWM模式1 & PWM模式2 向上计数配置说明编辑 STM32 定时器3输出通道引脚 自动重载的预装载寄存器 编辑 PWM输出相关库函数 输出比较初始化函数: 设置比较值函数&a…...
)
ES6学习Iterator遍历器(七)
这里写目录标题 一、概念1.1、遍历器1.2、作用1.3、遍历过程 二、代码学习 一、概念 JavaScript 原有的表示“集合”的数据结构,主要是数组( Array )和对象( Object ),ES6 又添加了 Map 和Set 。这样就有了…...

重建大师软件做任务提示引擎错误?
原因1:打开工程用的本地路径,导致访问失败;解决方案:用网络路径打开工程,重新提交空三。 原因2:引擎主机对工程目录没有访问权限;解决方案:找到相应的引擎主机设置访问权限 重建大…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...

学习一下用鸿蒙DevEco Studio HarmonyOS5实现百度地图
在鸿蒙(HarmonyOS5)中集成百度地图,可以通过以下步骤和技术方案实现。结合鸿蒙的分布式能力和百度地图的API,可以构建跨设备的定位、导航和地图展示功能。 1. 鸿蒙环境准备 开发工具:下载安装 De…...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...

小木的算法日记-多叉树的递归/层序遍历
🌲 从二叉树到森林:一文彻底搞懂多叉树遍历的艺术 🚀 引言 你好,未来的算法大神! 在数据结构的世界里,“树”无疑是最核心、最迷人的概念之一。我们中的大多数人都是从 二叉树 开始入门的,它…...