Hudi-集成Spark之spark-sql方式
Hudi集成Spark之spark-sql方式
启动spark-sql
# 启动spark-sql之前需要先启动Hive的Metastore
nohup hive --service metastore & #针对Spark 3.2
spark-sql \--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'# 如果没有配置hive环境变量,手动拷贝hive-site.xml到spark的conf下
创建表
建表参数:
| 参数名 | 默认值 | 说明 |
|---|---|---|
| primaryKey | uuid | 表的主键名,多个字段用逗号分隔。同 hoodie.datasource.write.recordkey.field |
| preCombineField | 表的预合并字段。同 hoodie.datasource.write.precombine.field | |
| type | cow | 创建的表类型: type = ‘cow’ type = 'mor’同 hoodie.datasource.write.table.type |
(1)创建非分区表
创建一个 cow 表,默认 primaryKey ‘uuid’,不提供 preCombineField
create database spark_hudi;use spark_hudi;create table hudi_cow_nonpcf_tbl (uuid int,name string,price double
) using hudi;
(2)创建一个 mor 非分区表
create table hudi_mor_tbl (id int,name string,price double,ts bigint
) using hudi
tblproperties (type = 'mor',primaryKey = 'id',preCombineField = 'ts'
);
(3)创建分区表
创建一个 cow 分区外部表,指定 primaryKey 和 preCombineField。此刻数据在hdfs上
create table hudi_cow_pt_tbl (id bigint,name string,ts bigint,dt string,hh string
) using hudi
tblproperties (type = 'cow',primaryKey = 'id',preCombineField = 'ts'
)
partitioned by (dt, hh)
location '/opt/hudi/hudi_cow_pt_tbl';
(4)在已有的 hudi 表上创建新表,不需要指定模式和非分区列(如果存在)之外的任何属性,Hudi 可以自动识别模式和配置。
-
非分区表
create table hudi_existing_tbl0 using hudi location 'file:///opt/datas/hudi/dataframe_hudi_nonpt_table'; -
分区表
create table hudi_existing_tbl1 using hudi partitioned by (dt, hh) location 'file:///opt/datas/dataframe_hudi_pt_table';
(5)通过 CTAS (Create Table As Select)建表为了提高向 hudi 表加载数据的性能,CTAS 使用批量插入作为写操作。
-
通过 CTAS 创建 cow 非分区表,不指定 preCombineField
create table hudi_ctas_cow_nonpcf_tbl using hudi tblproperties (primaryKey = 'id') as select 1 as id, 'a1' as name, 10 as price; -
通过 CTAS 创建 cow 分区表,指定 preCombineField
create table hudi_ctas_cow_pt_tbl using hudi tblproperties (type = 'cow', primaryKey = 'id', preCombineField = 'ts') partitioned by (dt) as select 1 as id, 'a1' as name, 10 as price, 1000 as ts, '2021-12-01' as dt; -
通过 CTAS 从其他表加载数据
# 创建内部表 create table parquet_mngd using parquet location 'file:///opt/datas/parquet_dataset/*.parquet'; # 通过 CTAS 加载数据 create table hudi_ctas_cow_pt_tbl2 using hudi location 'file://opt/datas/hudi/hudi_tbl/' options (type = 'cow',primaryKey = 'id',preCombineField = 'ts' ) partitioned by (datestr) as select * from parquet_mngd;
插入数据
默认情况下,如果提供了 preCombineKey,则 insert into 的写操作类型为 upsert,否则使用 insert
(1)向非分区表插入数据
insert into hudi_cow_nonpcf_tbl select 1, 'a1', 20;
insert into hudi_mor_tbl select 1, 'a1', 20, 1000;
(2)向分区表动态分区插入数据
insert into hudi_cow_pt_tbl partition (dt, hh) select 1 as id, 'a1' as name, 1000 as ts, '2021-12-09' as dt, '10' as hh;
(3)向分区表静态分区插入数据
insert into hudi_cow_pt_tbl partition(dt = '2021-12-09', hh='11') select 2, 'a2', 1000;
(4)使用 bulk_insert 插入数据
hudi 支持使用 bulk_insert 作为写操作的类型,只需要设置两个配置:hoodie.sql.bulk.insert.enable 和 hoodie.sql.insert.mode。
-- 向指定 preCombineKey 的表插入数据,则写操作为 upsert
insert into hudi_mor_tbl select 1, 'a1_1', 20, 1001;
select id, name, price, ts from hudi_mor_tbl;
1 a1_1 20.0 1001-- 向指定 preCombineKey 的表插入数据,指定写操作为 bulk_insert
set hoodie.sql.bulk.insert.enable=true;
set hoodie.sql.insert.mode=non-strict;insert into hudi_mor_tbl select 1, 'a1_2', 20, 1002;
select id, name, price, ts from hudi_mor_tbl;
1 a1_1 20.0 1001
1 a1_2 20.0 1002
查询数据
(1)查询
select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0;
(2)时间旅行查询
Hudi 从 0.9.0 开始就支持时间旅行查询。Spark SQL 方式要求 Spark 版本 3.2 及以上。
-- 关闭前面开启的 bulk_insert
set hoodie.sql.bulk.insert.enable=false;-- 数据写入到hdfs上
create table hudi_cow_pt_tbl1 (id bigint,name string,ts bigint,dt string,hh string
) using hudi
tblproperties (type = 'cow',primaryKey = 'id',preCombineField = 'ts'
)
partitioned by (dt, hh)
location '/opt/datas/hudi/hudi_cow_pt_tbl1';-- 插入一条 id 为 1 的数据
insert into hudi_cow_pt_tbl1 select 1, 'a0', 1000, '2021-12-09', '10';
select * from hudi_cow_pt_tbl1;
-- 修改 id 为 1 的数据
insert into hudi_cow_pt_tbl1 select 1, 'a1', 1001, '2021-12-09', '10';
select * from hudi_cow_pt_tbl1;
-- 基于第一次提交时间进行时间旅行
select * from hudi_cow_pt_tbl1 timestamp as of '20220307091628793' where id = 1;
-- 其他时间格式的时间旅行写法
select * from hudi_cow_pt_tbl1 timestamp as of '2022-03-07 09:16:28.100' where id = 1;
select * from hudi_cow_pt_tbl1 timestamp as of '2022-03-08' where id = 1;
更新数据
(1)update
更新操作需要指定 preCombineField。
-
语法
UPDATE tableIdentifier SET column = EXPRESSION(,column = EXPRESSION) [ WHERE boolExpression] -
执行更新
update hudi_mor_tbl set price = price * 2, ts = 1111 where id = 1; update hudi_cow_pt_tbl1 set name = 'a1_1', ts = 1001 where id = 1; -- update using non-PK field update hudi_cow_pt_tbl1 set ts = 1111 where name = 'a1_1';
(2)MergeInto
-
语法
MERGE INTO tableIdentifier AS target_alias USING (sub_query | tableIdentifier) AS source_alias ON <merge_condition> [ WHEN MATCHED [ AND <condition> ] THEN <matched_action> ] [ WHEN MATCHED [ AND <condition> ] THEN <matched_action> ] [ WHEN NOT MATCHED [ AND <condition> ] THEN <not_matched_action> ] <merge_condition> =A equal bool condition <matched_action> =DELETE |UPDATE SET * |UPDATE SET column1 = expression1 [, column2 = expression2 ...] <not_matched_action> =INSERT * |INSERT (column1 [, column2 ...]) VALUES (value1 [, value2 ...])可以看作是一个join操作。
-
执行案例
执行前开启hive的hiveservice2
[root@hadoop102 bin]# ./hiveserver2 start-- 1、准备 source 表:非分区的 hudi 表,插入数据 create table merge_source (id int, name string, price double, ts bigint) using hudi tblproperties (primaryKey = 'id', preCombineField = 'ts');insert into merge_source values (1, "old_a1", 22.22, 2900), (2, "new_a2", 33.33, 2000), (3, "new_a3", 44.44, 2000);merge into hudi_mor_tbl as target using merge_source as source on target.id = source.id when matched then update set * when not matched then insert *; -- 2、准备 source 表:分区的 parquet 表,插入数据 create table merge_source2 (id int, name string, flag string, dt string, hh string) using parquet;insert into merge_source2 values (1, "new_a1", 'update', '2021-12-09', '10'), (2, "new_a2", 'delete', '2021-12-09', '11'), (3, "new_a3", 'insert', '2021-12-09', '12');merge into hudi_cow_pt_tbl1 as target using (select id, name, '2000' as ts, flag, dt, hh from merge_source2 ) source on target.id = source.id when matched and flag != 'delete' then update set id = source.id, name = source.name, ts = source.ts, dt = source.dt, hh = source.hh when matched and flag = 'delete' then delete when not matched then insert (id, name, ts, dt, hh) values(source.id, source.name, source.ts, source.dt, source.hh);
mergeInto会发生的报错:
Could not sync using the meta sync class org.apache.hudi.hive.HiveSyncTooljava.sql.SQLException: Could not open client transport with JDBC Uri: jdbc:hive2://localhost:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.security.AccessControlException: Permission denied: user=hive, access=EXECUTE, inode="/tmp":root:supergroup:drwxrwx---
解决方案:https://blog.csdn.net/weixin_45417821/article/details/128651942
删除数据
语法:
DELETE FROM tableIdentifier [ WHERE BOOL_EXPRESSION]
案例:
delete from hudi_cow_nonpcf_tbl where uuid = 1;
delete from hudi_mor_tbl where id % 2 = 0;-- 使用非主键字段删除
delete from hudi_cow_pt_tbl1 where name = 'a1_1';
覆盖数据
- 使用 INSERT_OVERWRITE 类型的写操作覆盖分区表
- 使用 INSERT_OVERWRITE_TABLE 类型的写操作插入覆盖非分区表或分区表(动态分区)
(1)insert overwrite 非分区表
insert overwrite hudi_mor_tbl select 99, 'a99', 20.0, 900;
insert overwrite hudi_cow_nonpcf_tbl select 99, 'a99', 20.0;
(2)通过动态分区 insert overwrite table 到分区表
insert overwrite table hudi_cow_pt_tbl1 select 10, 'a10', 1100, '2021-12-09', '11';
(3)通过静态分区 insert overwrite 分区表
insert overwrite hudi_cow_pt_tbl1 partition(dt = '2021-12-09', hh='12') select 13, 'a13', 1100;
修改表结构(Alter Table)
语法:
-- Alter table name
ALTER TABLE oldTableName RENAME TO newTableName
-- Alter table add columns
ALTER TABLE tableIdentifier ADD COLUMNS(colAndType (,colAndType)*)
-- Alter table column type
ALTER TABLE tableIdentifier CHANGE COLUMN colName colName colType
-- Alter table properties
ALTER TABLE tableIdentifier SET TBLPROPERTIES (key = 'value')
案例:
--rename to:
ALTER TABLE hudi_cow_nonpcf_tbl RENAME TO hudi_cow_nonpcf_tbl2;
--add column:
ALTER TABLE hudi_cow_nonpcf_tbl2 add columns(remark string);
--change column:
ALTER TABLE hudi_cow_nonpcf_tbl2 change column uuid uuid int;
--set properties;
alter table hudi_cow_nonpcf_tbl2 set tblproperties (hoodie.keep.max.commits = '10');
修改分区
语法:
-- Drop Partition
ALTER TABLE tableIdentifier DROP PARTITION ( partition_col_name = partition_col_val [ , ... ] )
-- Show Partitions
SHOW PARTITIONS tableIdentifier
案例:
--show partition:
show partitions hudi_cow_pt_tbl1;
--drop partition:
alter table hudi_cow_pt_tbl1 drop partition (dt='2021-12-09', hh='10');
注意:show partition 结果是基于文件系统表路径的。删除整个分区数据或直接删除某个分区目录并不精确。
存储过程(Procedures)
语法:
--Call procedure by positional arguments
CALL system.procedure_name(arg_1, arg_2, ... arg_n)
--Call procedure by named arguments
CALL system.procedure_name(arg_name_2 => arg_2, arg_name_1 => arg_1, ... arg_name_n => arg_n)
案例:
可用的存储过程:https://hudi.apache.org/docs/procedures/
--show commit's info
call show_commits(table => 'hudi_cow_pt_tbl1', limit => 10);
相关文章:

Hudi-集成Spark之spark-sql方式
Hudi集成Spark之spark-sql方式 启动spark-sql # 启动spark-sql之前需要先启动Hive的Metastore nohup hive --service metastore & #针对Spark 3.2 spark-sql \--conf spark.serializerorg.apache.spark.serializer.KryoSerializer \--conf spark.sql.catalog.spark_catal…...

快速排序基本原理
快速排序基本原理1.快速排序1.1 基本原理1.2 快速排序执行步骤1.2.1 分区包含步骤1.2.1 分区步骤1.3 快速排序大O记法表示2. 将[0,5,2,1,6,3]进行快速排序 【实战】2.1 第一次分区步骤2.2 第二次分区步骤2.3 第三次分区步骤2.4 第四次分区步骤3.快速排序代码实现1.快速排序 1.…...
)
Android开发笔记-提纲(连载中....)
文章目录Android概述Android开发学习笔记提纲1. 认识AS开发Android的基础入门知识2. 认识Activity的生命周期和基础使用3. 认识Activity之间的跳转和传值4. 认识Intent以及全局Activity的属性的共享5. 认识Service6. 学习跨应用服务【AIDL通信】Android概述 Android系统框架的四…...
React Native(一)
移动端触摸事件example1:<ButtononPress{() > {Alert.alert(你点击了按钮!);}}title"点我!" />Touchable 系列组件TouchableHighlight 此组件的背景会在用户手指按下时变暗TouchableNativeFeedback 会在用户手指按下时形成类似墨水涟…...

Kotlin 26. Kotlin 如何播放音频文件
Kotlin 如何播放音频文件 文章目录Kotlin 如何播放音频文件1 下载并放置音频文件2 activity_main.xml3 MainActivity.kt1 下载并放置音频文件 我们可以随便下载一个音频文件,比如 alarm.mp3,需要将其放置在 /res/raw/ 路径下。 2 activity_main.xml 这…...
recv和明文收包分析
我们CTRLg 跳到recv 分析收包函数 发现函数会断并且收包函数返回值(收包包长)也会不断变化 那么证明recv是真正的收包函数,游戏没有重新实现该函数 我们只要分析该函数即可 在recv函数执行完毕以后下断 eax是包长,esi28是包指针 我们上2个号,让另外…...
【IVIF的超分重建】
Multimodal super-resolution reconstruction of infrared and visible images via deep learning (基于深度学习的红外和可见光图像多模态超分辨率重建) 提出了一种基于编解码器结构的红外-可见光图像融合方法。图像融合任务被重新表述为保持红外-可见…...
“深度学习”学习日记。--加深网络
2023.2.13 深度学习 是加深了层的深度神经网络的学习过程。基于之前介绍的网络,只需要通过 叠加层, 就可以创建深度网络 之前的学习,已经学习到了很多东西,比如构成神经网络的各种层、参数优化方法、误差反向传播法,…...

2023前端面试总结含参考答案
文章目录1. 父子组件生命周期的执行顺序:2. 原型链:3. promise的理解:4. 数组循环,foreach,filter,map,reduce5. 数组去重,set6. 组件通信方式7. 路由钩子8. 首页首屏加载优化:9. th…...
总览 Java 容器--集合框架的体系结构
前言 我们在讲 Java 的数据类型的时候,单独介绍过数组,数组也确实是开发程序中常用的内存类型之一,不过 Java 内置的数组限制颇多,所以此后扩展出了List这种结构,与之类似的Set、Queue 这些内存中的容器都被放在了 Co…...

即便考分很好也不予录取的研究生复试红线,都是原则性问题
在浙大研究生招生录取政策文件中有这么一句话:坚持“按需招生、全面衡量、择优录取、宁缺毋滥”的原则,以提高人才选拔质量为核心,在确保安全性、公平性和科学性的基础上,做到统筹兼顾、精准施策、严格管理。字字体现出研究生招生…...

Android java创建子线程的几种方法
1.新建一个类继承自Thread,并重写run()方法,并在里面编写耗时逻辑。 1 2 3 4 5 6 7 class ThreadTest extends Thread { Override public void run() { //具体的耗时逻辑代码 } } new ThreadTest().st…...
UVa 11212 Editing a Book 编辑书稿 IDA* Iterative Deepening A Star 迭代加深搜剪枝
题目链接:Editing a Book 题目描述: 给定nnn个(1<n<10)1<n<10)1<n<10)数字,数字分别是1,2,3,...,n1, 2, 3, ...,n1,2,3,...,n,但是顺序是打乱的,你可以选择一个索引区间的数字进行剪切操作。问最少进…...
第一章:unity性能优化之内存优化
目录 前言 unity性能优化之内存的优化 一、unity Analysis工具的使用。 二、内存优化方法 1、设置和压缩图片 2、图片格式 3、动画文件 4、模型 5、RenderTexture(RT) 6、分辨率 7、资源的重复利用 8、shader优化 9、对bundle进行良好的管…...
2023年家族办公室研究报告
第一章 概况 家族办公室最早起源于古罗马时期的大“Domus”(家族主管)以及中世纪时期的大“Domo”(总管家)。现代意义上的家族办公室出现于19世纪中叶,一些抓住产业革命机会的大亨将金融专家、法律专家和财务专家集合…...

Typescript快速入门
Typescript快速入门第一章 快速入门0、TypeScript简介1、TypeScript 开发环境搭建2、基本类型3、编译选项4、webpack5、Babel第二章:面向对象0、面向对象简介1、类(class)2、面向对象的特点3、接口(Interface)4、泛型&…...

如何激励你的内容团队产出更好的创意
对于一个品牌而言,如何创造吸引受众并对受众有价值内容是十分关键的。随着市场数字化的推进,优质的创意和内容输出对一个品牌在市场中有着深远的影响。对于很多内容策划和创作者来说,不断地产出高质量有创意的内容是一件非常有挑战性的事情。…...
机械设备管理软件如何选择?机械设备管理软件哪家好?
随着信息化技术的进步与智能制造的发展趋势,很多机械设备制造企业也在一直探寻适合自己的数字化管理转型之路,而企业上ERP管理软件又是实现数字化管理的前提,机械设备管理软件对于企业来说就是关键一环。机械设备管理软件如何选择?…...
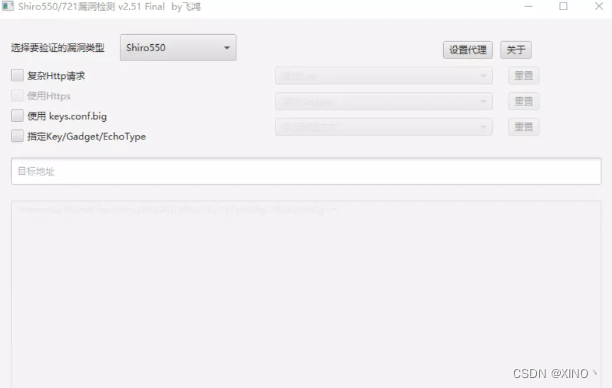
深入浅出带你学习shiro-550漏洞
//发点去年存货 前言 apache shiro是一个java安全框架,作用是提供身份验证,Apache Shiro框架提供了一个Rememberme的功能,存储在cookie里面的Key里面,攻击者可以使用Shiro的默认密钥构造恶意序列化对象进行编码来伪造用户的 Cookie…...

项目(今日指数之环境搭建)
一 项目架构1.1 今日指数技术选型【1】前端技术【2】后端技术栈【3】整体概览1.2 核心业务介绍【1】业务结构预览【2】业务结构预览1.定时任务调度服务XXL-JOB通过RestTemplate多线程动态拉去股票接口数据,刷入数据库; 2.国内指数服务 3.板块指数服务 4.…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...

数学建模-滑翔伞伞翼面积的设计,运动状态计算和优化 !
我们考虑滑翔伞的伞翼面积设计问题以及运动状态描述。滑翔伞的性能主要取决于伞翼面积、气动特性以及飞行员的重量。我们的目标是建立数学模型来描述滑翔伞的运动状态,并优化伞翼面积的设计。 一、问题分析 滑翔伞在飞行过程中受到重力、升力和阻力的作用。升力和阻力与伞翼面…...

微服务通信安全:深入解析mTLS的原理与实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、引言:微服务时代的通信安全挑战 随着云原生和微服务架构的普及,服务间的通信安全成为系统设计的核心议题。传统的单体架构中&…...