人工智能学习路线全链路解析
一、基础准备阶段(预计 2-3 个月)
(一)数学知识巩固与深化
- 线性代数(约 1 个月):
- 矩阵基础:回顾矩阵的定义、表示方法、矩阵的基本运算(加法、减法、乘法),理解矩阵乘法不满足交换律等特性,通过练习题加深对运算规则的掌握,例如计算简单的矩阵乘法式子、求矩阵的转置等。
- 向量空间与线性变换:学习向量空间的概念,包括向量的线性组合、线性相关与线性无关,掌握线性变换的定义、几何意义以及如何用矩阵表示线性变换,借助图形示例理解向量在不同线性变换下的变化情况。
- 特征值与特征向量:深入理解特征值和特征向量的定义、计算方法(通过求解特征方程)以及它们在数据降维、主成分分析等方面的应用,自己动手推导特征值和特征向量的计算公式,并结合实际的二维或三维矩阵实例进行计算和分析。
- 学习资源:《线性代数及其应用》这本书讲解详细且案例丰富,方便你系统学习;在线课程方面,Coursera 上的 “Linear Algebra for Machine Learning” 课程也很不错,有视频讲解和课后作业辅助巩固知识。
- 概率论与统计学(约 1 个月):
- 概率基础概念:复习概率的定义、古典概型、几何概型等基本概念,掌握条件概率、全概率公式、贝叶斯公式的推导和应用,通过做一些概率计算的练习题,如掷骰子、抽卡片等实际问题来熟悉这些公式。
- 随机变量与概率分布:学习离散型随机变量(如伯努利分布、二项分布、泊松分布)和连续型随机变量(如均匀分布、正态分布、指数分布)的定义、概率密度函数、分布函数以及期望、方差等数字特征,绘制不同分布的概率密度函数图像,直观感受其分布特点,并通过实际例子计算随机变量的期望和方差。
- 统计推断与参数估计:掌握最大似然估计、矩估计等参数估计方法的原理和步骤,理解假设检验的基本思想、步骤以及常见的检验方法(如 t 检验、卡方检验),自己动手利用给定的数据进行参数估计和假设检验的实践操作。
- 学习资源:《概率论与数理统计》教材内容权威全面,可作为主要学习参考;edX 平台上的 “Probability-The Science of Uncertainty and Data” 课程能够帮助你深入理解概率论知识,搭配实际案例和作业巩固所学内容。
- 微积分(约 1 个月):
- 函数极限与连续:复习函数极限的定义、计算方法(如四则运算法则、洛必达法则等),理解函数连续的概念以及间断点的分类,通过求一些简单函数在特定点的极限值、判断函数的连续性等练习来巩固知识点。
- 导数与微分:掌握导数的定义、几何意义、物理意义以及求导法则(基本函数求导公式、复合函数求导法则、隐函数求导法则等),理解微分的概念以及导数和微分的关系,对常见函数进行求导和微分的计算,并应用导数解决一些实际问题,如切线问题、变化率问题等。
- 积分学:学习不定积分和定积分的定义、计算方法(换元积分法、分部积分法等),理解积分在求面积、体积等几何问题以及物理中的应用(如做功、路程计算等),通过大量的积分计算练习题来熟练掌握积分技巧。
- 多元微积分(可选,若时间充裕):了解多元函数的极限、连续、偏导数、全微分等概念,掌握多元复合函数求导法则、隐函数求导法则以及多元函数的极值、最值问题,这部分内容对于理解深度学习中的梯度计算等有一定帮助,但如果时间紧张可以先初步了解,后续随着深度学习学习再深入探究。
- 学习资源:《高等数学》同济大学版是经典教材,涵盖了全面的微积分知识;Khan Academy 网站上有详细的微积分课程视频,从基础概念到复杂的计算都有讲解,方便你随时学习。
(二)Python 语言强化学习(约 1-2 个月)
- Python 基础语法(约 2 周):
- 数据类型:学习 Python 的基本数据类型,如整数、浮点数、字符串、列表、字典、元组等,掌握它们的定义、初始化、访问、修改以及常用的操作方法,例如列表的切片操作、字典的键值对添加和删除等,通过编写简单的代码片段进行练习。
- 控制结构:掌握条件判断语句(if-elif-else)、循环语句(for 循环、while 循环)的语法和使用场景,学会利用控制结构编写逻辑清晰的程序,如实现简单的猜数字游戏、打印九九乘法表等小程序来巩固对控制结构的运用。
- 函数与模块:理解函数的定义、参数传递、返回值等概念,学会自定义函数来封装可复用的代码逻辑,同时了解 Python 的模块机制,如何导入和使用内置模块(如 math 模块用于数学计算)以及自定义模块,通过编写多个函数并组织成模块的方式来实践。
- 学习资源:《Python 编程:从入门到实践》这本书非常适合零基础到入门的学习,语言通俗易懂,案例丰富;在慕课网、网易云课堂等在线学习平台上也有很多 Python 基础语法的免费课程可供选择。
- Python 面向对象编程(约 2 周):
- 类与对象:掌握类的定义、对象的创建以及类的成员变量和成员方法的概念,理解类的封装性、继承性和多态性,通过创建简单的类(如表示学生的类,包含姓名、年龄、成绩等属性以及学习、考试等方法)来实践面向对象编程的基本概念。
- 特殊方法与魔法方法:学习 Python 中一些特殊的方法,如
__init__(构造方法)、__str__(对象的字符串表示方法)等,了解它们在类的初始化、对象的打印输出等方面的作用,通过重写这些方法来定制类的行为。 - 类的继承与多态:深入理解类的继承机制,包括单继承、多继承的实现方式以及如何在子类中重写父类的方法,掌握多态的概念以及通过接口或抽象类实现多态的方法,通过编写具有继承关系的类层次结构并利用多态特性实现不同功能的代码示例来巩固知识。
- 学习资源:《Python 核心编程》这本书对 Python 面向对象编程有深入的讲解,配合书中的示例代码可以更好地理解相关概念;Python 官方文档中关于面向对象编程的部分也是权威的学习资料,详细介绍了各种语法和用法。
- Python 科学计算库(约 2 周):
- Numpy(约 1 周):学习 Numpy 库的基本数据结构(如 ndarray 数组),掌握数组的创建、索引、切片、形状改变等操作,熟悉 Numpy 提供的数学函数(如三角函数、统计函数等)以及线性代数运算函数(如矩阵乘法、求逆等),通过使用 Numpy 解决一些简单的数学计算和数据处理问题,如生成随机矩阵、进行矩阵运算等。
- Pandas(约 1 周):掌握 Pandas 库中 Series 和 DataFrame 这两种核心数据结构的创建、索引、数据筛选、数据合并等操作,学会使用 Pandas 进行数据读取(如读取 CSV 文件)、数据清洗(处理缺失值、重复值等)以及简单的数据分析(计算均值、中位数等统计指标),通过实际的数据集(如泰坦尼克号乘客数据集)进行数据处理和分析的实践操作。
- Matplotlib(约 1 周):学习 Matplotlib 库的基本使用方法,包括绘制折线图、柱状图、散点图、饼图等常见的统计图,掌握如何设置图表的标题、坐标轴标签、图例等元素,通过给定的数据生成不同类型的可视化图表,直观展示数据特征和关系,例如绘制某城市一年的气温变化折线图等。
- 学习资源:《Python 数据科学手册》涵盖了 Numpy、Pandas、Matplotlib 等常用科学计算库的详细讲解,配合大量的代码示例,方便你快速上手;官方文档也是很好的参考资料,对于各库的函数参数、用法细节等都有准确的描述。
二、核心知识学习阶段(预计 3-4 个月)
(一)机器学习基础(约 2-3 个月)
- 机器学习基本概念(约 2 周):
- 定义与分类:深入理解机器学习的定义,即让计算机从数据中学习规律并进行预测或决策的学科。掌握机器学习按照学习方式(监督学习、无监督学习、半监督学习、强化学习)、数据类型(离散型、连续型)、模型结构(线性模型、非线性模型)等不同维度的分类方式,通过列举不同类型的实际应用场景(如监督学习的房价预测、无监督学习的客户聚类等)来加深对分类的理解。
- 模型评估指标(约 1 周):学习常用的模型评估指标,在监督学习中,对于分类问题要掌握准确率、召回率、F1 值、精确率、ROC 曲线、AUC 值等指标的计算方法和含义,对于回归问题要掌握均方误差、平均绝对误差、决定系数(R²)等指标;在无监督学习中,了解聚类的评估指标如轮廓系数、戴维森堡丁指数等。通过实际的分类和回归模型预测结果数据来计算这些指标,体会不同指标在评估模型性能方面的优劣。
- 过拟合与欠拟合(约 1 周):理解过拟合(模型在训练数据上表现很好,但在测试数据上表现差,对噪声过度拟合)和欠拟合(模型过于简单,不能很好地拟合训练数据和捕捉数据规律)的概念、产生原因以及如何通过调整模型复杂度、增加数据量、使用正则化等方法来防止过拟合和改善欠拟合情况,通过对比不同复杂度模型在相同数据集上的表现来直观认识这两种现象。
- 学习资源:《机器学习》(周志华著)的前几章对机器学习的基本概念有清晰且深入的讲解,搭配书中的案例分析可以帮助你很好地理解;Coursera 上 Andrew Ng 教授的 “Machine Learning” 课程也会详细介绍这些基础知识,并且有相应的编程作业让你实践。
- 经典机器学习算法(约 2-3 个月):
- 线性回归(约 2 周):
- 原理推导:从最小二乘法的角度出发,推导线性回归模型的损失函数(均方误差)以及通过求导等方式找到最优参数的过程,理解如何通过最小化损失函数来使模型拟合数据,自己动手推导整个推导过程,加深对原理的理解。
- 代码实现:使用 Python(结合 Numpy、Pandas 等库)实现简单的线性回归模型,包括数据的准备(读取、预处理等)、模型的训练(计算参数)以及预测功能,通过对简单的线性数据集(如模拟的房屋面积与价格关系的数据)进行训练和预测,验证模型的正确性,并尝试调整不同的参数观察模型效果。
- 拓展应用:了解线性回归的一些变体,如岭回归(加入 L2 正则化)、Lasso 回归(加入 L1 正则化),理解它们在解决过拟合等问题上的作用以及如何实现,通过对比不同回归方法在含有噪声的数据集上的表现来体会其优势。
- 逻辑回归(约 2 周):
- 原理推导:理解逻辑回归作为一种分类模型,是如何将线性回归的输出通过 Sigmoid 函数等激活函数转化为概率值,进而进行分类决策的,推导其损失函数(对数似然损失)以及参数更新的梯度下降算法过程,自己动手推导逻辑回归的数学原理,包括从概率角度的理解和优化过程。
- 代码实现:同样使用 Python 实现逻辑回归模型,实现数据的处理、模型训练(利用梯度下降等优化算法更新参数)和预测功能,通过对简单的二分类数据集(如鸢尾花数据集的部分类别划分)进行实验,验证模型分类效果,并尝试调整学习率等参数优化模型性能。
- 多分类拓展:学习逻辑回归如何扩展到多分类问题,如采用一对多(One-vs-Rest)或一对一(One-vs-One)的策略,通过实际的多分类数据集(如手写数字识别的简化数据集)进行实践,对比不同策略的优缺点。
- 决策树(约 2 周):
- 原理与构建:理解决策树的基本原理,即通过对特征进行划分来构建一棵类似树状的决策结构,掌握决策树的构建算法,如 ID3(基于信息增益选择特征)、C4.5(基于信息增益比选择特征)、CART(基于基尼指数选择特征进行分类和基于均方误差选择特征进行回归)等算法的原理和区别,通过手动构建简单的决策树示例(如根据天气、温度等特征判断是否适合户外运动)来理解特征选择和树的构建过程。
- 剪枝处理:学习决策树的剪枝技术,包括预剪枝(在树构建过程中提前停止生长)和后剪枝(构建完树后对一些子树进行修剪)的方法和作用,理解它们是如何防止决策树过拟合的,通过对比剪枝前后决策树在测试数据集上的性能来体会剪枝的效果。
- 代码实现与应用:使用 Python 中的相关库(如 Scikit-learn)实现决策树模型,对不同的数据集(如分类的蘑菇数据集、回归的汽车价格预测数据集)进行训练和应用,调整不同的参数(如树的最大深度、最小样本数等)观察模型性能变化。
- 支持向量机(约 2 周):
- 原理与几何解释:深入理解支持向量机的基本思想,从最大间隔分类器的角度出发,理解如何通过寻找最优超平面来划分不同类别的数据,掌握其基于拉格朗日对偶和 KKT 条件的数学推导过程(可以先理解大致原理,再逐步深入推导细节),通过二维平面上简单的数据分布示例,从几何角度直观解释支持向量机的工作原理以及支持向量的概念。
- 核函数与非线性分类:学习支持向量机中核函数(如线性核、多项式核、高斯核等)的作用,即如何将低维空间的数据映射到高维空间,使得原本线性不可分的数据在高维空间变得线性可分,通过实际的非线性可分数据集(如月牙形数据集)对比使用不同核函数的支持向量机模型的分类效果,体会核函数的神奇之处。
- 代码实现与参数调整:使用 Python 实现支持向量机模型,学会调整参数(如惩罚参数、核函数参数等)来优化模型性能,通过在多个标准数据集(如鸢尾花数据集、手写数字数据集等)上进行实验,观察不同参数设置下模型的准确率、召回率等指标变化情况。
- K 近邻(约 2 周):
- 原理与距离度量:掌握 K 近邻算法的基本原理,即根据给定的测试样本,在训练集中找到与其距离最近的 K 个样本,然后根据这 K 个样本的类别(多数表决原则)来确定测试样本的类别(对于分类问题)或根据这 K 个样本的数值特征(平均等计算方式)来预测测试样本的数值(对于回归问题),学习常用的距离度量方法(如欧几里得距离、曼哈顿距离、闵可夫斯基距离等)及其特点,通过简单的二维坐标点数据计算不同距离度量下的近邻情况,对比不同距离度量对分类或回归结果的影响。
- K 值选择与权重设定:理解 K 值的选择对 K 近邻模型性能的影响(K 值过小容易过拟合,K 值过大容易欠拟合),掌握如何通过交叉验证等方法来选择合适的 K 值,同时了解可以给不同距离的近邻赋予不同权重(如距离越近权重越大)来优化模型性能,通过实际数据集(如鸢尾花数据集)进行不同 K 值和权重设置的实验,观察模型准确率等指标变化。
- 代码实现与优化:使用 Python 实现 K 近邻算法,对不同类型的数据集(分类和回归数据集)进行训练和预测,尝试采用数据预处理(如归一化、标准化)等手段优化模型性能,提高预测的准确性。
- K-Means 聚类(约 2 周):
- 原理与算法流程:理解 K-Means 聚类算法的基本思想,即通过初始化 K 个聚类中心,然后将数据点分配到距离最近的聚类中心所属的类别,再重新计算每个类别的聚类中心,不断迭代直到聚类中心不再变化或达到设定的迭代次数为止,通过手动模拟简单数据集(如二维平面上的散点数据)的聚类过程,熟悉算法的每一步操作。
- 聚类中心初始化与评价指标:了解不同的聚类中心初始化方法(如随机初始化、K-Means++ 初始化等)对聚类结果的影响,掌握常用的聚类评价指标(如轮廓系数、戴维森堡丁指数等)的计算方法和含义,通过对比不同初始化方法在相同数据集上得到的聚类结果以及使用评价指标来评估聚类质量,选择合适的初始化方法和聚类数量。
- 代码实现与拓展应用:使用 Python 实现 K-Means 聚类算法,对实际的数据集(如客户消费行为数据进行客户群体聚类、图像像素数据进行图像分割等)进行聚类分析,尝试将 K-Means 聚类与其他算法结合(如先聚类再进行分类)拓展应用场景,观察聚类效果并进行分析。
- 学习资源:《机器学习实战》(Hands-On Machine Learning with Scikit-Learn and TensorFlow)这本书通过大量的代码示例详细展示了如何使用 Python 实现上述机器学习算法,非常适合实践操作;Coursera 和 edX 平台上也有。
- 线性回归(约 2 周):
二、核心知识学习阶段(预计 3-4 个月)
(一)机器学习基础(约 2-3 个月)
- 经典机器学习算法(约 2-3 个月)续:
- 集成学习(约 2 周):
- 原理与思想:理解集成学习的基本概念,即通过结合多个机器学习模型来提高预测性能。掌握常见的集成学习方法,如 Bagging(自助采样后并行训练多个基模型,例如随机森林就是基于决策树的 Bagging 方法)和 Boosting(串行训练基模型,后一个模型重点关注前一个模型的错误样本,像 Adaboost、梯度提升树等)的原理和区别,通过简单的比喻或示例来理解这两种集成策略的运作方式,比如把 Bagging 想象成一群人各自独立做决策然后综合结果,而 Boosting 类似一个人不断根据之前的错误去改进决策。
- 随机森林(约 1 周):深入学习随机森林作为 Bagging 的典型代表,它是如何在构建决策树的过程中引入随机特征选择来增加模型的多样性,掌握随机森林的参数(如树的数量、每棵树的最大深度、特征采样比例等)对模型性能的影响,通过实际的分类和回归数据集(如波士顿房价数据集用于回归、信用卡欺诈检测数据集用于分类)进行实验,对比不同参数设置下随机森林的表现,体会其在处理高维数据、防止过拟合等方面的优势。
- 梯度提升树(约 1 周):对于梯度提升树,理解它是如何基于梯度下降的思想来依次训练基模型(通常也是决策树),使得损失函数逐步减小,掌握其重要的参数(如学习率、树的深度、迭代次数等)调整方法以及正则化手段(如子采样、收缩等),通过在一些复杂数据集上(如竞赛数据集的简化版本)进行训练和优化,观察其在提升模型性能方面的效果,并且对比它与随机森林在相同数据集上的不同表现,了解各自适用的场景。
- 学习资源:除了前面提到的《机器学习实战》等书籍外,《统计学习导论:基于 R 应用》这本书也对上述机器学习算法有详细且深入浅出的讲解,同时提供了很多实例帮助理解;在在线课程方面,Coursera 上的 “Advanced Machine Learning Specialization” 课程会对集成学习等内容进行更深入的探讨,并有相应的编程作业辅助巩固知识。
- 集成学习(约 2 周):
(二)深度学习基础(约 1-2 个月)
- 神经网络原理(约 2 周):
- 神经元与神经网络结构:从生物神经元的启发入手,理解人工神经元的基本结构(输入、权重、激活函数、输出),进而掌握神经网络的分层结构(输入层、隐藏层、输出层)以及各层之间是如何传递信息的,通过简单的示意图画出不同层数的神经网络结构,标注出各部分的组成,理解信息从前向后传播的过程(前向传播)。
- 激活函数(约 1 周):深入学习常见的激活函数,如 Sigmoid 函数、Tanh 函数、ReLU 函数(及其变体,如 Leaky ReLU 等)的表达式、图像特点、优缺点以及适用场景,理解激活函数在引入非线性因素、避免梯度消失等方面的重要作用,通过绘制不同激活函数的图像,对比它们在不同区间的取值变化,分析为何在不同的网络结构中会选择不同的激活函数,例如在隐藏层常用 ReLU 来解决梯度消失问题,在输出层根据是分类还是回归任务选择合适的激活函数。
- 损失函数与优化算法(约 1 周):掌握不同任务对应的常见损失函数,如分类任务中的交叉熵损失、回归任务中的均方误差损失等的计算方法和原理,理解为什么要选择这样的损失函数来衡量模型预测结果与真实值的差异;同时学习常用的优化算法,如梯度下降(包括批量梯度下降、随机梯度下降、小批量梯度下降)及其改进版本(如 Adagrad、Adadelta、Adam 等)的原理、更新规则以及各自的优缺点,通过简单的数学推导理解优化算法是如何根据损失函数的梯度来更新神经网络的权重,以逐步减小损失函数值,达到优化模型的目的。
- 学习资源:《深度学习》(Ian Goodfellow 著)这本书的开篇部分对神经网络的基础原理有着非常全面且深入的讲解,配合书中的数学推导和实际案例能让你很好地理解这些核心概念;Coursera 上的 “Deep Learning Specialization” 课程的前几门课也会系统地介绍神经网络的基础知识,并有配套的编程作业和代码示例供你实践。
- 深度学习框架(约 2-4 周):
- TensorFlow(约 1-2 周):
- 基本概念与安装:学习 TensorFlow 的基本概念,如张量(Tensor)的定义、操作以及计算图(Computation Graph)的构建方式,掌握如何在本地环境或云端环境(如 Google Colab,方便快捷且无需复杂的本地配置)安装 TensorFlow,按照官方文档的指引完成安装步骤,并通过简单的代码示例验证安装是否成功,例如创建一个简单的张量并输出其信息。
- 模型构建与训练(约 1 周):了解如何使用 TensorFlow 的高级 API(如 Keras,它集成在 TensorFlow 中,方便快捷地构建模型)来构建常见的神经网络模型(如简单的多层感知机用于分类或回归任务),掌握模型的编译(指定损失函数、优化器、评估指标等)、训练(传入训练数据进行多轮迭代训练)以及预测(对新的数据进行预测输出)的完整流程,通过一个小型的数据集(如 MNIST 手写数字数据集的简化版本)进行模型构建和训练的实践操作,观察训练过程中的损失值、准确率等指标变化情况。
- 模型保存与部署(约 1 周):学习如何保存训练好的 TensorFlow 模型,以便后续在不同的环境中进行部署和使用,掌握常见的模型保存格式(如 SavedModel 格式)以及加载模型进行预测的方法,同时了解如何将 TensorFlow 模型部署到服务器端(如使用 TensorFlow Serving)或者移动端(如通过 TensorFlow Lite 进行模型压缩和移动端适配),通过实际操作将一个简单的分类模型进行保存并尝试在本地模拟的服务器环境或移动端模拟器中进行部署和预测验证。
- PyTorch(约 1-2 周):
- 基本概念与安装:类似地,学习 PyTorch 的基本概念,如张量(torch.Tensor)的操作、自动求导机制(基于 torch.autograd 模块,与 TensorFlow 的计算图机制有所不同,但都能实现自动计算梯度的功能),掌握在本地环境安装 PyTorch 的方法,通过官方文档和示例代码进行安装,并创建简单的张量进行一些基本运算(如加法、乘法、求梯度等)来熟悉其操作。
- 模型构建与训练(约 1 周):掌握在 PyTorch 中构建神经网络模型的方式,通过定义类继承自 torch.nn.Module 来构建自定义的网络结构,了解如何使用 PyTorch 提供的各种层(如线性层、卷积层、循环层等)进行组合搭建模型,掌握模型的训练流程,包括定义损失函数、选择优化器以及进行多轮迭代训练(利用循环结构实现前向传播、计算损失、反向传播更新参数等操作),同样以 MNIST 数据集为例,使用 PyTorch 构建模型并进行训练,对比与 TensorFlow 在模型构建和训练流程上的异同点。
- 模型保存与部署(约 1 周):学习 PyTorch 中模型保存的方法(如保存模型的参数状态字典或者整个模型结构和参数)以及如何加载保存的模型进行后续的预测操作,了解 PyTorch 在部署方面的一些工具和方法(如将模型转换为 ONNX 格式以便在不同的框架和平台上兼容使用等),通过实际操作对训练好的模型进行保存和部署验证,体会其在实际应用中的便利性。
- 对比与选择(约 1 周):通过对 TensorFlow 和 PyTorch 在模型构建的便捷性、训练速度、对不同硬件(如 GPU 的支持情况)、社区活跃度、文档丰富度等多方面进行对比分析,了解它们各自的优势和适用场景,以便在后续不同的项目实践中能够根据具体需求合理选择使用的深度学习框架,例如在科研领域可能 PyTorch 的动态图机制更便于快速实验和调试,而在工业界大规模部署时 TensorFlow 的生态系统可能更具优势。
- 学习资源:TensorFlow 官方文档和 PyTorch 官方文档都是非常权威且详细的学习资料,涵盖了从基础概念到高级应用的所有内容,并且有大量的代码示例可供参考;此外,《Python 深度学习》这本书对使用 Python 结合 TensorFlow 和 PyTorch 进行深度学习实践有很好的指导作用,通过书中的案例可以快速上手这两个框架。
- TensorFlow(约 1-2 周):
三、进阶学习阶段(预计 4-6 个月)
(一)自然语言处理(约 2-3 个月)
- 基础技术(约 1-2 个月):
- 文本预处理(约 2 周):
- 编码与字符集:学习计算机中字符的编码方式,如 ASCII 码、UTF-8 等,理解不同编码方式在表示文本时的特点和适用范围,掌握如何在 Python 中处理不同编码的文本文件,避免出现编码错误等问题,通过实际的文本文件读取和转换操作来熟悉编码相关知识。
- 分词与词性标注(约 1 周):掌握常见的中文和英文分词方法,对于中文,了解基于规则、基于统计(如隐马尔可夫模型、最大熵模型等)以及基于深度学习的分词算法原理;对于英文,学习基于空格和标点符号的简单分词方式以及一些改进的方法。同时学习词性标注的概念和常用的词性标注工具(如 NLTK 库中的词性标注功能,在英文处理上有较好的应用),通过实际的文本段落进行分词和词性标注实践,观察不同方法的效果差异。
- 命名实体识别(约 1 周):理解命名实体识别的任务定义,即识别文本中具有特定意义的实体(如人名、地名、组织机构名等),学习基于规则、机器学习(如支持向量机、条件概率模型等应用于特征工程后的实体识别)以及深度学习(如卷积神经网络、循环神经网络及其组合应用)的命名实体识别方法,通过公开的命名实体识别数据集(如 CoNLL2003 数据集)进行模型训练和识别效果验证,对比不同方法在准确率、召回率等指标上的表现。
- 词向量表示(约 2 周):
- One-Hot 向量与词袋模型(约 1 周):学习 One-Hot 向量这种简单的词表示方法,理解其优缺点(如维度高、稀疏性强、无法表示词与词之间的语义关系等),进而掌握词袋模型(将文本看作是词的集合,忽略词序,通过统计词频来构建文本表示)的概念、构建方法以及在文本分类等简单任务中的应用,通过对一些短文本(如新闻标题、产品评论等)构建 One-Hot 向量和词袋模型表示,进行文本相似度计算等简单操作,体会其局限性。
- 分布式词向量(约 1 周):深入学习分布式词向量(如 Word2Vec 的 CBOW 和 Skip-gram 模型、GloVe 模型等)的原理、算法流程以及如何通过大量的文本数据训练得到词向量,理解这些词向量能够捕捉词与词之间的语义关系(如通过计算词向量的余弦相似度来衡量词的相似性,像 “国王” 和 “王后” 的词向量相似度较高),通过使用预训练的词向量(如 Google 提供的 Word2Vec 预训练模型或者斯坦福大学的 GloVe 预训练模型)在一些文本任务(如类比推理、文本聚类等)中进行应用,体会分布式词向量的优势,同时也可以尝试自己利用开源代码库(如 Python 的 gensim 库)基于小型文本数据集训练词向量,观察训练过程和结果。
- 学习资源:《自然语言处理入门》这本书对自然语言处理的基础技术有详细且系统的讲解,结合大量的代码示例和实际案例,便于你快速入门;NLTK 官方文档提供了丰富的关于英文自然语言处理工具和方法的介绍,可以帮助你掌握英文文本处理的一些基础操作;对于中文自然语言处理,开源的结巴分词工具的文档以及相关的学术论文能让你了解中文分词等方面的技术细节。
- 文本预处理(约 2 周):
- 深度学习应用(约 1-2 个月):
- 循环神经网络(约 2 周):
- 原理与结构(约 1 周):深入理解循环神经网络(RNN)的基本结构,特别是其独特的循环连接方式,使得它能够处理序列数据,掌握不同类型的 RNN(如基本的 Elman 网络、Jordan 网络等)的特点和区别,通过绘制简单的 RNN 结构示意图,标注出各个时间步的输入、隐藏状态、输出等信息,理解信息在时间维度上的传递和处理过程,同时理解 RNN 在处理长序列数据时存在的梯度消失和梯度爆炸问题的原因。
- 长短期记忆网络(LSTM)与门控循环单元(GRU)(约 1 周):学习 LSTM 和 GRU 这两种改进的循环神经网络结构,掌握它们通过引入门控机制(如遗忘门、输入门、输出门等)来解决梯度消失和梯度爆炸问题的原理,对比它们与基本 RNN 在结构、计算复杂度、对长序列数据处理能力等方面的差异,通过实际的序列数据(如时间序列的气温预测数据、文本序列数据等)分别使用 RNN、LSTM、GRU 构建模型进行预测,观察它们在不同长度序列上的表现,体会 LSTM 和 GRU 的优势。
- 注意力机制(约 2 周):
- 原理与作用(约 1 周):理解注意力机制的基本概念,即模拟人类在处理信息时能够聚焦重点内容的能力,在自然语言处理中,它可以帮助模型更好地关注文本中的关键部分,提高对长文本等复杂序列数据的处理能力。学习不同类型的注意力机制(如基于内容的注意力、基于位置的注意力等)的原理和实现方式,通过简单的示例(如机器翻译中对源语言句子不同部分的关注情况)来直观理解注意力机制是如何工作的。
- 应用与拓展(约 1 周):掌握注意力机制在自然语言处理中的广泛应用,如在机器翻译、文本摘要、问答系统等任务中的应用,通过使用开源的深度学习框架(如 TensorFlow 或 PyTorch)结合注意力机制构建相应的自然语言处理模型,对比添加注意力机制前后模型在任务准确率、召回率等指标上的表现,体会其对提升模型性能的重要作用,同时了解基于注意力机制的一些前沿研究和拓展应用方向,如多头注意力机制在 Transformer 架构中的应用等。
- 自然语言处理任务实践(约 2 周):选择几个典型的自然语言处理任务,如文本分类(如情感分析、新闻分类等)、机器翻译、文本生成(如自动写诗、故事生成等)进行实践操作,综合运用前面所学的分词、词向量、循环神经网络、注意力机制等知识,使用深度学习框架构建完整的模型,从数据准备(收集、清洗、标注等)、模型构建、训练到评估的全过程进行实践,通过对比不同模型结构、参数设置等在相同任务上的表现,不断优化模型性能,同时积累实际项目经验,了解自然语言处理任务在实际应用中的难点和挑战。
- 学习资源:斯坦福大学的 “Natural Language Processing with Deep Learning” 课程对自然语言处理中的深度学习应用有非常深入的讲解,课程中有很多前沿的研究成果分享以及编程实践作业;《基于深度学习的自然语言处理》这本书结合了大量的实际案例和代码示例,详细介绍了如何利用深度学习解决各种自然语言处理任务,是很好的参考资料。
- 循环神经网络(约 2 周):
(二)计算机视觉(约 2-3 个月)
- 图像处理基础(约 1-2 个月):
- 图像基本概念与表示(约 2 周):
- 图像的数字化与像素(约 1 周):学习图像是如何从现实世界中的物体通过光学设备(如相机)转化为计算机能够处理的数字图像的过程,理解像素的概念,即图像的最小单元,掌握图像的分辨率、颜色模式(如 RGB、灰度模式等)等基本概念,通过查看不同分辨率、不同颜色模式的图像文件,观察其在计算机中的显示效果,理解这些概念对图像质量和处理方式的影响。
- 图像的读取与存储(约 1 周):掌握在 Python 中使用 OpenCV 库或其他图像处理库(如 Pillow 库)读取不同格式(如 JPEG、PNG 等)图像文件的方法,了解图像数据在内存中的存储结构(如二维或三维数组表示不同颜色通道的像素值),学会将处理后的图像保存为指定格式的文件,通过实际操作读取、显示和保存各种图像文件,熟悉图像的基本操作流程。
- 图像变换与滤波(约 2 周):
- 灰度变换(约 1 周):学习常见的灰度变换方法,如线性变换(调整图像的亮度、对比度等)、非线性变换(如对数变换、幂次变换等用于增强图像特定区域的对比度等)的原理和实现方式,通过对实际的灰度图像或彩色图像转换为灰度图像后进行不同的灰度变换操作,观察图像在亮度、对比度等方面的变化效果,理解不同灰度变换方法的适用场景。
- 滤波与卷积(约 1 周):深入理解滤波的概念,即通过对图像像素进行加权平均等操作来去除噪声、增强图像边缘等,掌握常见的滤波方法(如均值滤波、中值滤波、高斯滤波等)的原理和实现方式,了解卷积运算在图像处理中的核心作用(滤波操作本质上就是一种卷积运算),通过对含有噪声的图像进行不同滤波方法的处理,对比处理前后图像的质量变化(如噪声去除效果、边缘清晰度等),体会不同滤波方法的优缺点。
- 边缘检测与特征提取(约 2 周):
- 特征提取(约 1 周):掌握传统的手工特征提取方法,如尺度不变特征变换(SIFT)、加速稳健特征(SURF)、方向梯度直方图(HOG)等的原理和应用场景。了解这些特征是如何从图像中提取具有代表性、对图像变换(如旋转、缩放、平移等)相对不变的信息,用于后续的图像匹配、目标识别等任务。通过实际的图像数据库(如 Caltech 101、Caltech 256 等)进行特征提取操作,可视化提取出的特征向量,体会不同特征在描述图像内容方面的特点,比如 HOG 特征常用于行人检测等任务,能有效捕捉图像中物体的轮廓形状信息。
- 边缘检测(约 1 周):学习边缘检测的重要性以及常见的边缘检测算法,如基于一阶导数的 Sobel 算子、Prewitt 算子,基于二阶导数的 Laplacian 算子、Canny 算子等的原理和实现方式。理解这些算子是如何通过计算图像像素灰度值的变化来确定边缘位置的,通过对不同类型的图像(如简单几何图形图像、自然场景图像等)应用各种边缘检测算法,观察并对比它们检测出的边缘效果,分析不同算法在抗噪能力、边缘定位准确性等方面的优劣,例如 Canny 算子通常具有较好的检测精度和对噪声的鲁棒性,能同时检测出强边缘和弱边缘并进行合理的边缘连接。
- 学习资源:《数字图像处理》(冈萨雷斯著)这本书是图像处理领域的经典教材,涵盖了从图像基础概念到各类图像处理技术的详细讲解,配合书中的大量示例图像能帮助你很好地理解相关知识;OpenCV 官方文档提供了全面且详细的关于使用 OpenCV 库进行图像处理操作的介绍,包括各种函数的参数说明和代码示例,便于你快速上手实践。
-
深度学习应用(约 1 - 2 个月):
- 卷积神经网络(CNN)原理(约 2 周):
- 卷积层(约 1 周):深入理解卷积神经网络中卷积层的核心概念,包括卷积核(滤波器)的定义、作用以及如何通过卷积核在图像上滑动进行卷积操作来提取图像特征。掌握卷积核的参数(如大小、步长、填充方式等)对卷积结果的影响,理解卷积操作如何实现局部连接和权值共享,有效减少网络参数数量并降低计算复杂度,同时又能捕捉图像的局部特征。通过手动模拟卷积操作过程(例如使用简单的二维数组代表图像和卷积核进行计算)以及使用 Python 结合深度学习框架(如 TensorFlow 或 PyTorch)对实际图像进行卷积操作的实践,观察不同参数设置下卷积后的图像特征变化情况。
- 池化层(约 1 周):学习池化层(如最大池化、平均池化等)的原理和作用,理解它是如何在保留图像重要特征的基础上进一步减少数据量,降低后续层的计算负担,同时提高模型的抗噪能力和对图像变形的鲁棒性。掌握池化操作的参数(如池化窗口大小、步长等)对特征图尺寸和特征保留效果的影响,通过对比有无池化层以及不同池化方式在相同卷积神经网络结构下对图像分类等任务的影响,体会池化层的重要性。
- 经典 CNN 架构及应用(约 2 周):
- LeNet、AlexNet 等早期架构(约 1 周):了解早期具有代表性的卷积神经网络架构,如 LeNet - 5(常用于手写数字识别等简单任务)、AlexNet(在 ImageNet 图像分类竞赛中取得重大突破,推动了深度学习在计算机视觉领域的广泛应用)的网络结构特点、创新点以及它们在图像分类等任务上的历史贡献。学习如何使用深度学习框架复现这些经典架构,并在相应的标准数据集(如 MNIST 数据集对应 LeNet - 5、ILSVRC 2012 数据集对应 AlexNet)上进行训练和评估,对比它们的性能表现和局限性,分析随着网络架构发展改进的方向。
- VGG、ResNet 等现代架构(约 1 周):深入研究现代更先进的卷积神经网络架构,如 VGG(以其简洁的网络结构和通过堆叠多个小卷积核来增加网络深度的特点而闻名)、ResNet(引入残差连接有效解决了深层网络训练时的梯度消失问题,使得网络能够训练得更深,性能更优)等的原理、结构细节以及在各种计算机视觉任务(如图像分类、目标检测、图像分割等)中的卓越表现。通过使用这些架构在大型图像数据集(如 CIFAR - 10、CIFAR - 100 等)上进行实践,尝试调整不同的参数(如网络层数、每层的通道数等),观察对模型性能的影响,体会它们在实际应用中的优势和适用场景。
- 目标检测、图像分割等应用(约 2 周):
- 目标检测(约 1 周):学习目标检测的任务定义,即识别图像中不同类别的目标物体并确定它们的位置(通常用边界框表示)。掌握常见的目标检测算法框架,如基于区域的卷积神经网络(R - CNN)系列(包括 R - CNN、Fast R - CNN、Faster R - CNN 等,逐步改进检测速度和精度)、YOLO(You Only Look Once,以其快速的实时检测性能著称)、SSD(Single Shot MultiBox Detector,兼顾检测速度和精度)等的原理、结构特点以及它们在不同场景下的应用优势。通过使用开源的目标检测代码库(如基于 PyTorch 的 Detectron2、基于 TensorFlow 的 Object Detection API 等)在公开的目标检测数据集(如 PASCAL VOC 数据集、COCO 数据集等)上进行模型训练和测试,对比不同算法在检测准确率、召回率以及检测速度等指标上的表现,了解目标检测在实际应用中的难点和挑战,如小目标检测、遮挡问题等。
- 图像分割(约 1 周):理解图像分割的任务,即将图像划分为不同的区域,每个区域对应一个语义类别(语义分割)或者每个区域对应图像中的一个物体(实例分割)。学习常见的图像分割算法,如基于全卷积神经网络(FCN)的方法(开创了端到端的语义分割先河,将传统的卷积神经网络的全连接层替换为卷积层,实现对图像像素级别的分类)、U - Net(在医学图像分割等领域应用广泛,具有编码 - 解码结构,能较好地保留图像细节信息)、Mask R - CNN(在 Faster R - CNN 基础上增加了用于图像分割的分支,实现了实例分割功能)等的原理、结构特点以及在不同类型图像(如自然场景图像、医学图像等)分割任务中的应用。通过在相应的图像分割数据集(如 Cityscapes 数据集用于城市街景图像分割、CamVid 数据集用于视频图像分割等)上进行实践,对比不同算法在分割精度、分割效率等方面的表现,体会图像分割在实际应用中的重要性和技术难度。
- 学习资源:《计算机视觉:算法与应用》这本书全面系统地介绍了计算机视觉领域的各种算法和应用场景,涵盖了从传统图像处理到现代深度学习方法的内容,是深入学习计算机视觉的优质参考资料;Fast.ai 网站上的 “Practical Deep Learning for Coders” 课程中有很多关于计算机视觉应用实践的内容,通过实际案例和代码讲解,能帮助你快速上手并深入理解相关技术;同时,各大深度学习框架(TensorFlow、PyTorch 等)的官方文档也提供了丰富的关于计算机视觉相关模型构建和应用的示例与教程,方便你进行实践操作。
- 卷积神经网络(CNN)原理(约 2 周):
-
四、实践与项目阶段(预计 6 - 12 个月)
(一)参与开源项目(长期进行)
- 选择合适的开源项目:在 GitHub 等开源平台上,根据自己感兴趣的人工智能领域方向(如自然语言处理、计算机视觉、机器学习等)以及自身目前的技能水平,筛选合适的开源项目。可以从一些星标数量较多、文档相对完善、活跃度较高的项目入手,例如在自然语言处理领域,有 NLP - Chinese - Corpus 这样的中文语料库项目,或者在计算机视觉领域的 OpenCV 相关的拓展项目等。查看项目的 README 文件,了解项目的目标、功能、技术栈以及参与方式等基本信息。
- 熟悉项目代码结构和开发流程:下载项目代码到本地后,通过阅读项目的代码文件、注释以及文档,梳理项目的整体架构,包括各个模块的功能、模块之间的调用关系等。例如,在一个深度学习项目中,了解数据加载模块如何读取和预处理数据、模型构建模块如何定义网络结构、训练模块的参数设置和训练流程以及评估模块如何计算模型性能指标等。同时,关注项目的开发流程,如代码提交规范、分支管理方式、问题反馈和解决机制等,这有助于你顺利融入项目团队并按照规范进行开发工作。
- 参与代码贡献:从简单的任务开始,如修复代码中的小 bug(通过阅读报错信息、调试代码来定位问题所在,然后修改相应的代码片段)、完善项目文档(补充函数注释、更新 README 文件中的使用说明等)。随着对项目的熟悉程度增加,可以尝试参与更复杂的功能开发,如为项目添加新的模型结构、优化现有的算法实现等。在参与过程中,积极与项目的其他开发者进行沟通交流,通过提交 Pull Request、参与项目讨论组等方式,接受他人的建议和反馈,不断提升自己的代码质量和开发能力,同时也能学习到其他优秀开发者的经验和思路。
-
(二)参加竞赛(可多次参加,每次 2 - 3 个月)
- 选择合适的竞赛:关注 Kaggle、天池等知名的数据科学竞赛平台,根据自己的知识储备和兴趣选择合适的竞赛项目。竞赛项目通常涵盖了各种人工智能相关的主题,如图像识别、文本分类、预测分析等。可以从新手入门类的竞赛开始,这类竞赛一般数据集相对较小、任务难度较低,便于你熟悉竞赛流程和积累经验,例如 Kaggle 上的 Titanic 生存预测竞赛(一个经典的机器学习入门竞赛项目,通过乘客的各种特征预测其是否在泰坦尼克号沉没事件中幸存);随着能力的提升,再选择更具挑战性的竞赛,如涉及复杂的深度学习应用和大规模数据集的竞赛项目。
- 组队与准备工作:如果竞赛允许组队,可以寻找志同道合、技能互补的队友组成团队,例如可以有擅长数据分析、模型构建、数据可视化等不同方面的成员。在竞赛开始前,仔细阅读竞赛规则、了解评估指标(如准确率、AUC 值、均方误差等,不同竞赛任务对应的评估指标不同,这决定了模型优化的方向)以及数据格式和内容等信息。下载并分析竞赛提供的数据集,进行初步的数据探索性分析(EDA),如查看数据的分布情况、缺失值情况、特征之间的相关性等,为后续的模型构建和优化打下基础。
- 模型构建与优化:根据竞赛任务的类型(分类、回归、聚类等),选择合适的机器学习或深度学习方法构建初始模型。例如,对于图像分类竞赛,可能会选择卷积神经网络架构(如 ResNet、VGG 等);对于文本分类竞赛,可能会运用循环神经网络结合注意力机制等方法。在模型训练过程中,通过调整模型的参数(如神经网络的层数、学习率、批量大小等)、采用不同的优化算法、进行数据增强(针对图像数据,如旋转、翻转、裁剪等操作来增加数据量和多样性;针对文本数据,如同义词替换、句子打乱等方式)等手段不断优化模型性能,同时密切关注竞赛排行榜上其他团队的成绩,分析差距并借鉴优秀团队的方法和思路,持续改进自己的模型。
- 结果提交与总结:按照竞赛要求的格式和时间节点提交模型预测结果,等待竞赛官方的评估和反馈。无论竞赛结果如何,都要对整个竞赛过程进行总结复盘,分析自己在模型选择、数据处理、团队协作等方面存在的优点和不足,积累经验教训,以便在后续的竞赛或实际项目中能够表现得更好。
-
(三)自主项目实践(长期进行,可分阶段完成多个项目)
- 项目选题:从简单的、自己熟悉领域相关的人工智能应用项目开始选题,例如,如果你之前有 Java 开发中涉及数据库相关的经验,可以考虑做一个基于机器学习的数据库性能预测项目,通过收集数据库的各种运行指标(如查询执行时间、内存占用、磁盘 I/O 等)作为特征,构建模型来预测数据库在未来某个时间段的性能情况;或者基于计算机视觉做一个简单的图像分类项目,比如识别宠物猫狗的照片分类等。随着能力的提升,再选择更复杂、跨领域的项目,如结合自然语言处理和计算机视觉做一个图像内容描述生成的项目(根据输入的图像,输出一段描述图像内容的文字)等。
- 项目规划与数据收集:确定项目选题后,制定详细的项目计划,包括项目的各个阶段(如需求分析、数据收集与预处理、模型构建、训练与评估、部署应用等)的时间安排、预期目标以及关键里程碑等。对于数据收集,如果是公开数据集能满足需求的项目,可以从 Kaggle、UCI 机器学习库等知名的数据平台上获取相关数据集;如果需要自己收集数据,要明确数据来源(如通过网络爬虫收集网页文本数据、使用摄像头采集图像数据等)以及数据收集的标准和规范,确保收集到的数据质量和合法性。
- 项目实施与优化:按照项目计划逐步推进项目实施,在数据收集完成后,进行数据预处理(如数据清洗、归一化、特征工程等操作),然后根据项目的任务类型选择合适的模型进行构建、训练和评估。在这个过程中,不断对模型进行优化,如尝试不同的算法组合、调整模型参数、改进数据处理方式等,同时要对项目的关键指标(如准确率、召回率、均方误差等,根据项目任务确定)进行监控和记录,以便直观地看到项目的进展和模型性能的变化情况。
- 项目部署与展示:当模型性能达到预期目标后,考虑将项目进行部署应用,使其能够真正发挥作用。对于一些简单的项目,可以将模型部署在本地服务器或者个人电脑上,通过编写简单的接口程序(如使用 Flask 等 Python web 框架创建 API 接口),让其他应用能够方便地调用模型进行预测;对于更复杂的项目,可能需要考虑部署到云端服务器(如使用阿里云、腾讯云等云服务平台),并进行相应的安全防护、性能优化等工作。最后,将整个项目的成果以报告、演示文稿等形式进行整理展示,可以分享给同行、同事或者发布在个人技术博客上,一方面展示自己的学习成果,另一方面也能接受他人的建议和反馈,进一步提升自己的能力。
- 图像基本概念与表示(约 2 周):
相关文章:

人工智能学习路线全链路解析
一、基础准备阶段(预计 2-3 个月) (一)数学知识巩固与深化 线性代数(约 1 个月): 矩阵基础:回顾矩阵的定义、表示方法、矩阵的基本运算(加法、减法、乘法)&…...

C++语言的学习路线
C语言的学习路线 C是一种强大的高级编程语言,广泛应用于系统软件、游戏开发、嵌入式系统和高性能应用等多个领域。由于其丰富的功能和灵活性,C是一门值得深入学习的语言。本文旨在为初学者制定一条系统的学习路线,帮助他们循序渐进地掌握C语…...
用于与多个数据库聊天的智能 SQL 代理问答和 RAG 系统(3) —— 基于 LangChain 框架的文档检索与问答功能以及RAG Tool的使用
介绍基于 LangChain 框架的文档检索与问答功能,目标是通过查询存储的向量数据库(VectorDB),为用户的问题检索相关内容,并生成自然语言的答案。以下是代码逻辑的详细解析: 代码结构与功能 初始化环境与加载…...
20250110doker学习记录
1.本机创建tts环境。用conda. 0.1安装。我都用的默认,你也可以。我安装过一次,如果修复,后面加 -u bash Anaconda3-2024.10-1-Linux-x86_64.sh等待一会。 (base) ktkt4028:~/Downloads$ conda -V conda 24.9.2学习资源 Conda 常用命令大…...

MPU6050: 卡尔曼滤波, 低通滤波
对于MPU6050(一种集成了三轴加速度计和三轴陀螺仪的惯性测量单元),对加速度值进行卡尔曼滤波,而对角速度进行低通滤波的选择是基于这两种传感器数据的不同特性和应用需求。以下是详细解释: 加速度值与卡尔曼滤波 为什么使用卡尔曼滤波? 噪声抑制: 加速度计信号通常包含…...

C++的标准和C++的编译版本
C的标准和C的编译版本:原理和概念 理解 C标准 和 C编译版本 的关系是学习 C 的一个重要部分。这两者虽然看似相关,但实际上分别涉及了不同的概念和技术。下面将通过层次清晰的解释,帮助新手理解这两个概念的差异、特点及其相互关系。 一、C标…...
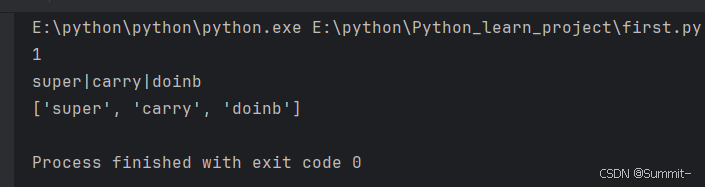
python学习笔记—17—数据容器之字符串
1. 字符串 (1) 字符串能通过下标索引来获取其中的元素 (2) 旧字符串无法修改特定下标的元素 (3) index——查找字符串中任意元素在整个字符串中的起始位置(单个字符或字符串都可以) tmp_str "supercarrydoinb" tmp_position1 tmp_str.index("s") tmp_p…...
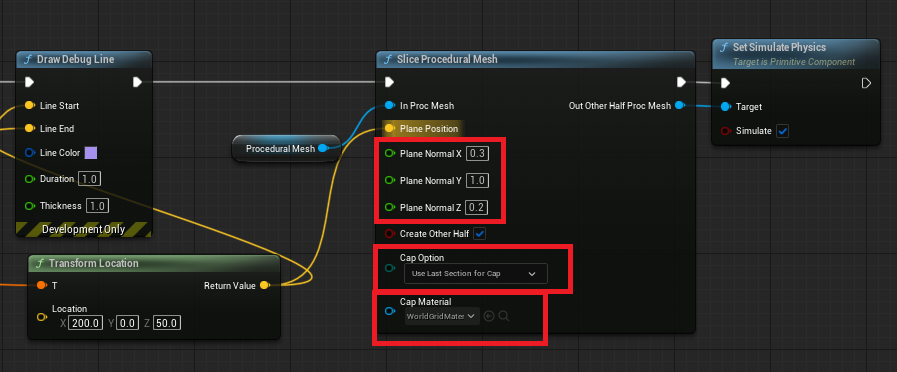
UE5 使用内置组件进行网格切割
UE引擎非常强大,直接内置了网格切割功能并封装为蓝图节点,这项功能在UE4中就存在,并且无需使用Chaos等模块。那么就来学习下如何使用内置组件实现网格切割。 1.配置测试用StaticMesh 对于被切割的模型,需要配置一些参数。以UE5…...
51单片机——串口通信(重点)
1、通信 通信的方式可以分为多种,按照数据传送方式可分为串行通信和并行通信; 按照通信的数据同步方式,可分为异步通信和同步通信; 按照数据的传输方向又可分为单工、半双工和全双工通信 1.1 通信速率 衡量通信性能的一个非常…...

Taro+Vue实现图片裁剪组件
cropper-image-taro-vue3 组件库 介绍 cropper-image-taro-vue3 是一个基于 Vue 3 和 Taro 开发的裁剪工具组件,支持图片裁剪、裁剪框拖动、缩放和输出裁剪后的图片。该组件适用于 Vue 3 和 Taro 环境,可以在网页、小程序等平台中使用。 源码 https:…...
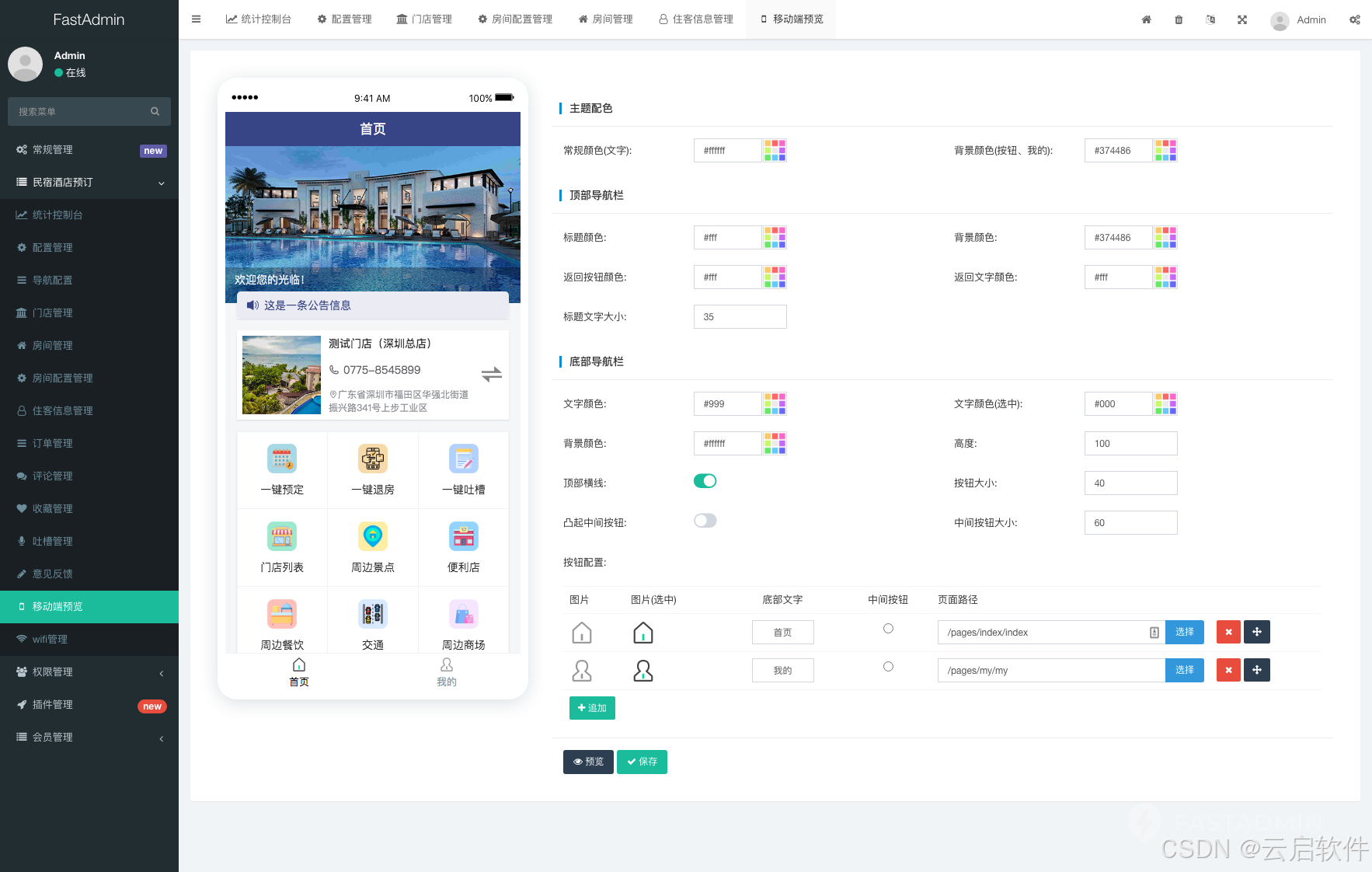
PHP民宿酒店预订系统小程序源码
🏡民宿酒店预订系统 基于ThinkPHPuniappuView框架精心构建的多门店民宿酒店预订管理系统,能够迅速为您搭建起专属的、功能全面且操作便捷的民宿酒店预订小程序。 该系统不仅涵盖了预订、退房、WIFI连接、用户反馈、周边信息展示等核心功能,更…...
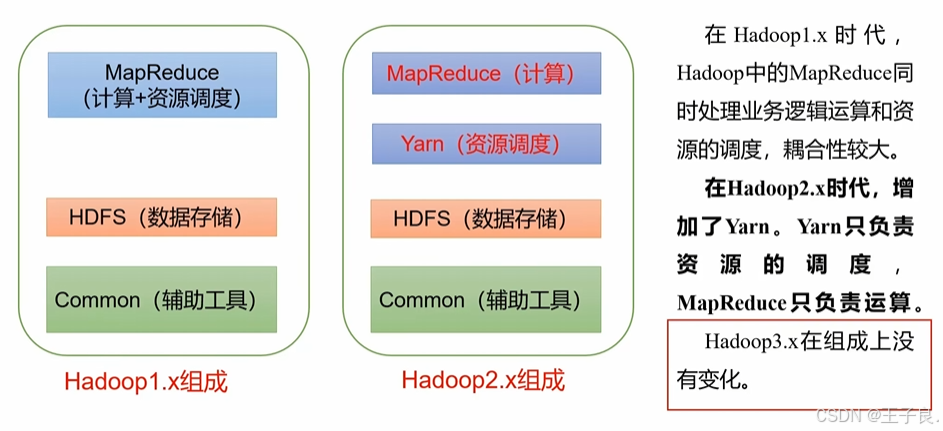
Hadoop3.x 万字解析,从入门到剖析源码
💖 欢迎来到我的博客! 非常高兴能在这里与您相遇。在这里,您不仅能获得有趣的技术分享,还能感受到轻松愉快的氛围。无论您是编程新手,还是资深开发者,都能在这里找到属于您的知识宝藏,学习和成长…...

VUE3 常用的组件介绍
Vue 组件简介 Vue 组件是构建 Vue 应用程序的核心部分,组件帮助我们将 UI 分解为独立的、可复用的块,每个组件都有自己的状态和行为。Vue 组件通常由模板、脚本和样式组成。组件的脚本部分包含了各种配置选项,用于定义组件的逻辑和功能。 组…...

deepin-Wine 运行器合并打包器和添加从镜像提取 DLL 的功能
Wine 运行器是一个图形化工具,旨在简化 Wine 环境的管理和使用。它不仅提供了运行和管理 Wine 容器的功能,还增加了打包器和从镜像提取 DLL 的功能。以下是该工具的详细介绍和使用方法。 一、工具概述 Wine 运行器是一个使用 Python3 的 tkinter 构建的图…...

[大模型]本地离线运行openwebui+ollama容器化部署
本地离线运行Openweb-ui ollama容器化部署 说明安装internet操作内网操作问题线程启动错误最终命令总结说明 最近公司有一个在内网部署一个离线大模型的需求,网络是离线状态,服务器有A100GPU,一开始是想折腾开源chatGML4大模型,因为使用过gml3,所以想着部署gml4应该不难。…...
再次梳理ISP的大致流程
前言: 随着智能手机的普及,相机与我们的生活越来越紧密相关。在日常生活中,我们只需要轻轻按下手机上的拍照按钮,就能记录下美好时刻。那么问题来了:从我们指尖按下拍照按钮到一张色彩丰富的照片呈现在我们面前&#x…...
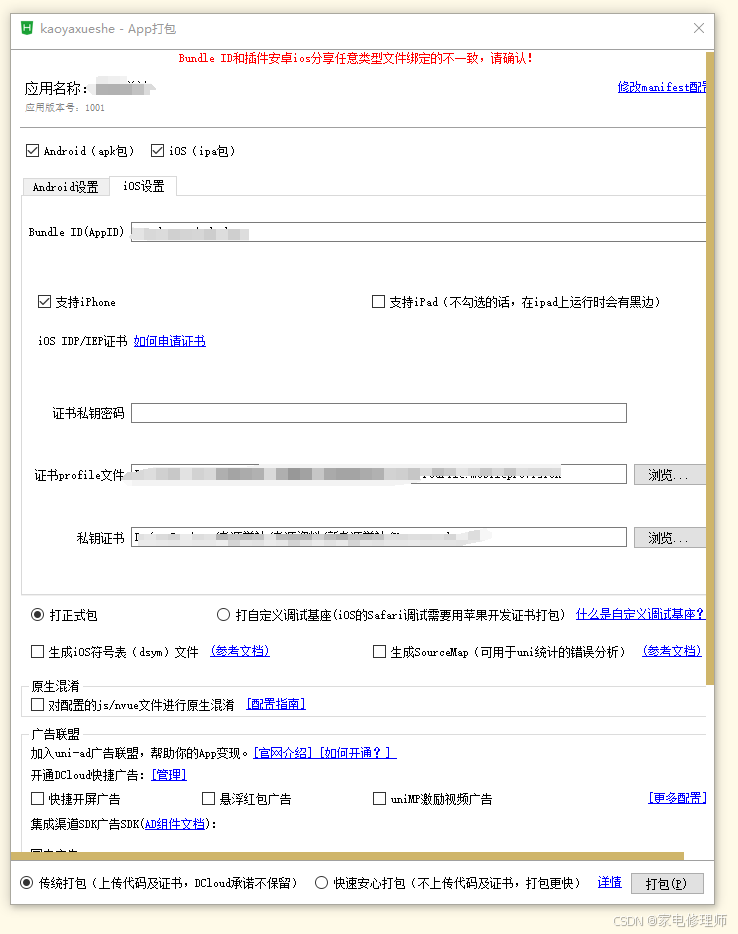
HBuilderX打包ios保姆式教程
1、登录苹果开发者后台并登录已认证开发者账号ID Sign In - Apple 2、创建标识符(App ID)、证书,描述文件 3、首先创建标识符,用于新建App应用 3-1、App的话直接选择第一个App IDs,点击右上角继续 3-2、选择App&#x…...

《解锁鸿蒙系统AI能力,开启智能应用开发新时代》
在当今科技飞速发展的时代,鸿蒙系统以其独特的分布式架构和强大的AI能力,为开发者们带来了前所未有的机遇。本文将深入探讨开发者如何利用鸿蒙系统的AI能力开发更智能的应用,开启智能应用开发的新时代。 鸿蒙系统构筑了15系统级的AI能力&…...

rhcsa练习(3)
1 、创建文件命令练习: ( 1 ) 在 / 目录下创建一个临时目录 test ; mkdir /test ( 2 )在临时目录 test 下创建五个文件,文件名分别为 passwd , group , bashrc &#x…...
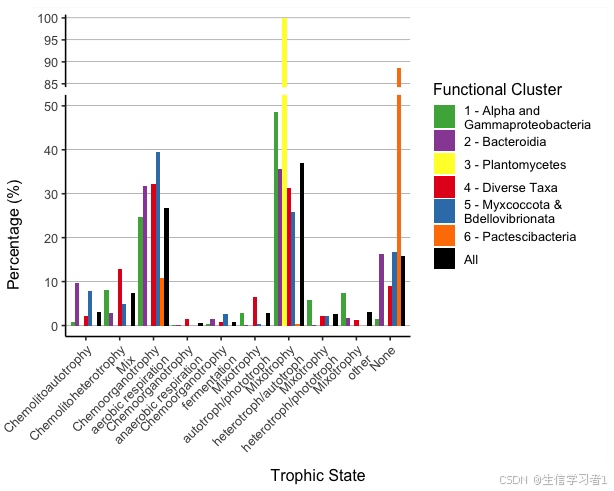
科研绘图系列:R语言绘制Y轴截断分组柱状图(y-axis break bar plot)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍特点意义加载R包数据下载导入数据数据预处理画图输出总结系统信息介绍 Y轴截断分组柱状图是一种特殊的柱状图,其特点是Y轴的刻度被截断,即在某个范围内省略了部分刻度。这种图表…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

解决:Android studio 编译后报错\app\src\main\cpp\CMakeLists.txt‘ to exist
现象: android studio报错: [CXX1409] D:\GitLab\xxxxx\app.cxx\Debug\3f3w4y1i\arm64-v8a\android_gradle_build.json : expected buildFiles file ‘D:\GitLab\xxxxx\app\src\main\cpp\CMakeLists.txt’ to exist 解决: 不要动CMakeLists.…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...

vue3 daterange正则踩坑
<el-form-item label"空置时间" prop"vacantTime"> <el-date-picker v-model"form.vacantTime" type"daterange" start-placeholder"开始日期" end-placeholder"结束日期" clearable :editable"fal…...
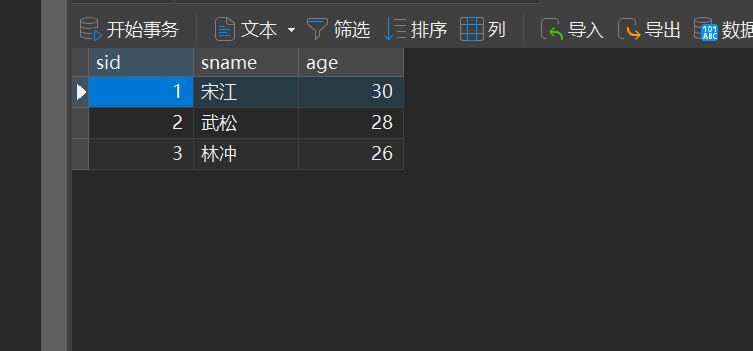
MySQL的pymysql操作
本章是MySQL的最后一章,MySQL到此完结,下一站Hadoop!!! 这章很简单,完整代码在最后,详细讲解之前python课程里面也有,感兴趣的可以往前找一下 一、查询操作 我们需要打开pycharm …...