RT-DETR代码详解(官方pytorch版)——参数配置(1)
前言
RT-DETR虽然是DETR系列,但是它的代码结构和之前的DETR系列代码不一样。
它是通过很多的yaml文件进行参数配置,和之前在train.py的parser = argparse.ArgumentParser()去配置所有参数不同,所以刚开始不熟悉代码的时候可能不知道在哪儿修改参数。
RT-DETR有官方版和ultralytics版两个版本代码,可以参考以下链接,分别使用两种方法对代码进行复现:
详解RT-DETR网络结构/数据集获取/环境搭建/训练/推理/验证/导出/部署_rt-dert-CSDN博客
下述内容主要是针对参数配置的代码实现进行解读,因为刚开始我拿着代码都不知道是怎么运行的,模型在哪儿加载参数都找不到
一、train.py文件
在RT-DETR中,train.py文件需要配置的内容很少,因为需要的参数配置全都放在了rtdetr_rxxvd_6x_coco.yml(骨干网络可选)文件中。在这个文件中又包含了其他所有的文件,可以依需修改:

左边是可以选择的backbone骨干网络,后续以ResNet18为例。

二、rtdetr_r18vd_6x_coco.yaml文件
__include__: ['../dataset/coco_detection.yml', # 数据集'../runtime.yml', # 运行参数配置'./include/dataloader.yml', # 定义数据加载器参数'./include/optimizer.yml', # 定义优化器通用设置'./include/rtdetr_r50vd.yml', # 定义 RT-DETR 模型的结构参数(如 backbone 和解码器层数等
]output_dir: ./output/rtdetr_r18vd_6x_coco # 输出的文件地址PResNet:depth: 18freeze_at: -1 # 不冻结任何层(如果设置为正数,则冻结 ResNet 的前几层)freeze_norm: False # 不冻结归一化层(如 BatchNorm)pretrained: True # 加载预训练权重(通常是基于 ImageNet 数据集的权重)HybridEncoder:in_channels: [128, 256, 512] # 编码器的输入特征通道数,分别对应 ResNet-18 不同尺度的特征图输出hidden_dim: 256expansion: 0.5 # 特征通道扩展比例RTDETRTransformer:eval_idx: -1 # 指定在哪一层解码器输出进行评估(-1 表示最后一层)num_decoder_layers: 3 # 解码器的层数num_denoising: 100 # 去噪查询的数量optimizer:type: AdamW # 该优化器改进了 Adam,支持权重衰减以减轻过拟合params: # 参数分组,针对不同模块的参数设置不同的学习率和权重衰减- params: '^(?=.*backbone)(?=.*norm).*$' # 匹配骨干网络中的归一化层参数,设置较低学习率和无权重衰减lr: 0.00001weight_decay: 0.- params: '^(?=.*backbone)(?!.*norm).*$' # 匹配骨干网络中非归一化参数lr: 0.00001- params: '^(?=.*(?:encoder|decoder))(?=.*(?:norm|bias)).*$' # 匹配 Transformer 中归一化层或偏置参数weight_decay: 0.lr: 0.0001betas: [0.9, 0.999] # Adam 优化器的 beta 参数weight_decay: 0.0001 # 权重衰减值上面的注释只是为了解释各行代码意思,但是运行代码过程中,yaml文件不能有注释,否则会报错:

三、yaml_config.py文件
在train.py文件中,实际是通过YAMLConfig()这个类读取rtdetr_r18vd_6x_coco.yaml中的配置信息。通过加载 YAML 配置文件,将不同的模型、优化器、数据加载器等组件以模块化的方式创建

主要功能
1. 动态加载 YAML 配置文件:
- 使用
load_config函数加载 YAML 文件,读取其中的配置数据。- 支持通过
merge_dict将命令行或其他来源的参数覆盖 YAML 文件中的默认配置。2. 组件动态创建:
- 根据 YAML 文件的配置,动态创建模型(
model)、损失函数(criterion)、优化器(optimizer)、学习率调度器(lr_scheduler)和数据加载器(dataloader)等。3. 参数分组和正则匹配:
- 支持为优化器指定不同模块的参数组,并通过正则表达式选择分组的参数。
4. 支持扩展功能:
- 支持 EMA(Exponential Moving Average,指数滑动平均) 和 AMP(Automatic Mixed Precision,自动混合精度)。
- 自动处理模型参数的冻结、梯度裁剪等功能。
5. 模块化设计:
- 配置组件通过
create函数动态实例化,便于扩展和自定义。
3.1 类初始化与加载配置
class YAMLConfig(BaseConfig):def __init__(self, cfg_path: str, **kwargs) -> None:super().__init__()cfg = load_config(cfg_path) # 加载 YAML 配置文件merge_dict(cfg, kwargs) # 合并外部输入的参数(高优先级)self.yaml_cfg = cfg # 保存解析后的 YAML 配置# 一些常见配置的提取self.log_step = cfg.get('log_step', 100)self.checkpoint_step = cfg.get('checkpoint_step', 1)self.epoches = cfg.get('epoches', -1)self.resume = cfg.get('resume', '')self.tuning = cfg.get('tuning', '')self.sync_bn = cfg.get('sync_bn', False)self.output_dir = cfg.get('output_dir', None)self.use_ema = cfg.get('use_ema', False)self.use_amp = cfg.get('use_amp', False)self.autocast = cfg.get('autocast', dict())self.find_unused_parameters = cfg.get('find_unused_parameters', None)self.clip_max_norm = cfg.get('clip_max_norm', 0.0)
- 功能:
- 从 YAML 配置文件中加载配置,初始化训练流程中常用的参数。
cfg_path:YAML 配置文件路径。kwargs:支持通过外部传入参数(如命令行参数)覆盖 YAML 中的默认配置。- 使用
get方法设置默认值,避免配置文件缺失某些字段时程序报错。
3.1.1 yaml_config.py文件
通过cfg = load_config(cfg_path)已经将所有的配置信息传递给cfg了
尽管传入的只有一个rtdetr_r18vd_6x_coco.yaml文件,但它里面包含了其他的配置文件地址:


load_config()函数在yaml_utils.py文件中
def load_config(file_path, cfg=dict()):"""加载 YAML 配置文件,并支持递归加载包含的其他 YAML 文件。Args:file_path (str): 要加载的 YAML 文件路径。cfg (dict): 全局配置字典,默认为空字典。Returns:dict: 加载并合并后的配置字典。"""# 获取文件扩展名并确保是 YAML 文件_, ext = os.path.splitext(file_path)assert ext in ['.yml', '.yaml'], "仅支持 YAML 文件(.yml 或 .yaml)"# 打开并加载 YAML 文件with open(file_path, 'r') as f:file_cfg = yaml.load(f, Loader=yaml.Loader)if file_cfg is None:return {} # 如果文件为空,则返回空字典# 检查是否需要加载包含的 YAML 配置(递归加载)if INCLUDE_KEY in file_cfg:# 提取 'include' 键的值,通常是其他 YAML 文件路径的列表base_yamls = list(file_cfg[INCLUDE_KEY])for base_yaml in base_yamls:# 将路径展开为完整路径(支持用户目录 ~ 和相对路径)if base_yaml.startswith('~'):base_yaml = os.path.expanduser(base_yaml)if not base_yaml.startswith('/'): # 如果是相对路径base_yaml = os.path.join(os.path.dirname(file_path), base_yaml)# 递归加载被包含的 YAML 文件base_cfg = load_config(base_yaml, cfg)# 合并当前加载的配置到全局配置中merge_config(base_cfg, cfg)# 最终合并当前文件的配置到全局配置中return merge_config(file_cfg, cfg)
- 通过
include字段,可以将配置拆分成多个 YAML 文件,便于管理和维护。- 支持递归加载多个 YAML 文件,并通过
merge_config实现配置合并,确保最终配置完整。
3.2 动态加载组件(如模型、优化器等)
通过 @property 装饰器,延迟加载组件,仅在实际使用时创建对象
@property装饰器
是 Python 的一个内置装饰器,常用于定义一个类的方法,并将其伪装成“属性”。
- 保护类的封装特性
- 让开发者可以使用“对象.属性”的方式操作操作类属性
通过 @property 装饰器,可以直接通过方法名来访问方法,不需要在方法名后添加一对“()”小括号。
语法格式:
@property def 方法名(self)代码块更多@property装饰器内容可看,其中包含延时加载的应用:@property装饰器-CSDN博客
3.2.1 模型加载
@property
def model(self) -> torch.nn.Module:if self._model is None and 'model' in self.yaml_cfg:merge_config(self.yaml_cfg) # 合并全局配置self._model = create(self.yaml_cfg['model']) # 动态创建模型return self._model
- 检查
_model是否已经创建,若未创建且配置中包含model字段,则动态创建模型。(self.yaml_cfg已经存储了所有的配置信息,见3.1.1 图,提取model键的值)- 使用
create函数按照yaml_cfg['model']中的定义实例化模型。在rtdetr_r18vd_6x_coco.yml--->./include/rtdetr_r50vd.yml中 :

3.2.2 优化器延迟加载
@property
def optimizer(self):if self._optimizer is None and 'optimizer' in self.yaml_cfg:merge_config(self.yaml_cfg) # 合并全局配置params = self.get_optim_params(self.yaml_cfg['optimizer'], self.model) # 获取参数分组self._optimizer = create('optimizer', params=params) # 动态创建优化器return self._optimizer
- 获取优化器参数分组(
get_optim_params),根据配置动态创建优化器实例。

3.2.3 学习率调度器加载
@property
def lr_scheduler(self):if self._lr_scheduler is None and 'lr_scheduler' in self.yaml_cfg:merge_config(self.yaml_cfg)self._lr_scheduler = create('lr_scheduler', optimizer=self.optimizer)print('Initial lr: ', self._lr_scheduler.get_last_lr())return self._lr_scheduler
- 动态创建学习率调度器对象,并与优化器绑定
在rtdetr_r18vd_6x_coco.yml--->./include/optimizer.yml中 :
基于MultiStepLR生成对应的学习率调度器
MultiStepLR是 PyTorch 中torch.optim.lr_scheduler提供的一种学习率调度器- 它会在指定的训练步骤(
milestones)调整学习率根据配置,初始学习率为
0.1,在第1000步时,学习率会乘以gamma=0.1,变为0.01。输出如下:Step 0: Learning Rate = 0.1 Step 500: Learning Rate = 0.1 Step 1000: Learning Rate = 0.01 Step 1500: Learning Rate = 0.01

3.3 数据加载器
@property
def train_dataloader(self):if self._train_dataloader is None and 'train_dataloader' in self.yaml_cfg:merge_config(self.yaml_cfg)self._train_dataloader = create('train_dataloader')self._train_dataloader.shuffle = self.yaml_cfg['train_dataloader'].get('shuffle', False)return self._train_dataloader
- 动态加载训练数据加载器,并根据配置调整
shuffle参数
3.4 参数分组(正则表达式匹配)
@staticmethod
def get_optim_params(cfg: dict, model: nn.Module):'''E.g.:^(?=.*a)(?=.*b).*$ means including a and b^((?!b.)*a((?!b).)*$ means including a but not b^((?!b|c).)*a((?!b|c).)*$ means including a but not (b | c)'''assert 'type' in cfg, ''cfg = copy.deepcopy(cfg)if 'params' not in cfg:return model.parameters() # 如果未定义参数分组,返回默认模型参数assert isinstance(cfg['params'], list), ''param_groups = []visited = []for pg in cfg['params']:pattern = pg['params']params = {k: v for k, v in model.named_parameters() if v.requires_grad and len(re.findall(pattern, k)) > 0}pg['params'] = params.values()param_groups.append(pg)visited.extend(list(params.keys()))names = [k for k, v in model.named_parameters() if v.requires_grad]if len(visited) < len(names):unseen = set(names) - set(visited)params = {k: v for k, v in model.named_parameters() if v.requires_grad and k in unseen}param_groups.append({'params': params.values()})visited.extend(list(params.keys()))assert len(visited) == len(names), ''return param_groups
- 根据正则表达式匹配模型中的参数(
named_parameters方法返回<参数名, 参数>的映射)。- 支持按模块或特定规则分组优化器参数(如设置不同学习率、权重衰减)。
- 未匹配的参数会自动归为默认组。
^(?=.*backbone)(?=.*norm).*$:匹配键名中包含backbone和norm的参数。^(?=.*encoder)(?!.*bias).*$:匹配键名中包含encoder且不包含bias的参数。
相关文章:

RT-DETR代码详解(官方pytorch版)——参数配置(1)
前言 RT-DETR虽然是DETR系列,但是它的代码结构和之前的DETR系列代码不一样。 它是通过很多的yaml文件进行参数配置,和之前在train.py的parser argparse.ArgumentParser()去配置所有参数不同,所以刚开始不熟悉代码的时候可能不知道在哪儿修…...

腾讯云AI代码助手编程挑战赛-凯撒密码解码编码器
作品简介 在CTFer选手比赛做crypto的题目时,一些题目需要自己去解密,但是解密的工具大部分在线上,而在比赛过程中大部分又是无网环境,所以根据要求做了这个工具 技术架构 python语言的tk库来完成的GUI页面设计,通过…...

搭建docker私有化仓库Harbor
Docker私有仓库概述 Docker私有仓库介绍 Docker私有仓库是个人、组织或企业内部用于存储和管理Docker镜像的存储库。Docker默认会有一个公共的仓库Docker Hub,而与Docker Hub不同,私有仓库是受限访问的,只有授权用户才能够上传、下载和管理其中的镜像。这种私有仓库可以部…...

【Vim Masterclass 笔记09】S06L22:Vim 核心操作训练之 —— 文本的搜索、查找与替换操作(第一部分)
文章目录 S06L22 Search, Find, and Replace - Part One1 从光标位置起,正向定位到当前行的首个字符 b2 从光标位置起,反向查找某个字符3 重复上一次字符查找操作4 定位到目标字符的前一个字符5 单字符查找与 Vim 命令的组合6 跨行查找某字符串7 Vim 的增…...
)
GIC中断分组介绍(IMX6ull为例)
一、Cortex-A7内核中断 Cortex-A7内核具有多个中断类型,但其中最重要的是复位中断和IRQ(普通中断请求)中断。对于IMX6ULL而言,主要关注的是IRQ中断,因为外部设备和内部事件通常都会触发这类中断。 从左到右 中断控制…...

计算机网络期末复习(知识点)
概念题 在实际复习之前,可以看一下这个视频将网络知识串一下,以便更好地复习:【你管这破玩意叫网络?】 网络规模的分类 PAN(个人区域网络):用于个人设备间的连接,如手机与蓝牙耳机…...

Apache XMLBeans 一个强大的 XML 数据处理框架
Apache XMLBeans 是一个用于处理 XML 数据的 Java 框架,它提供了一种方式将 XML Schema (XSD) 映射到 Java 类,从而使得开发者可以通过强类型化的 Java 对象来访问和操作 XML 文档。下面将以一个简单的案例说明如何使用 Apache XMLBeans 来解析、生成和验…...

飞凌嵌入式i.MX8M Mini核心板已支持Linux6.1
飞凌嵌入式FETMX8MM-C核心板现已支持Linux6.1系统,此次升级不仅使系统功能更加丰富,还通过全新BSP实现了内存性能的显著提升。 基于NXP i.MX8M Mini处理器设计开发的飞凌嵌入式FETMX8MM-C核心板,拥有4个Cortex-A53高性能核和1个Cortex-M4实时…...
)
【数据链电台】洛克希德·马丁(Lockheed Martin)
洛克希德马丁公司(Lockheed Martin)是全球领先的航空航天、国防、先进技术和安全领域的供应商之一。 公司为美军及盟国军队提供了广泛的通信系统,包括数据链电台和相关的通信系统。 洛克希德马丁的许多产品用于战术通信、卫星通信、电子战、…...

python关键字(保留字)用法、保留的标识符类(1)
python关键字(保留字)用法、保留的标识符类(1) 一、python保留字(关键字) 1.1、python关键字 以下标识符为保留字,或称 关键字,不可用于普通标识符,即我们不能把它们用作任何标识符名称。 python 保留字(关键字) 关键…...

Ubuntu平台虚拟机软件学习笔记
Ubuntu平台上常见虚拟机软件 VirtualBox [Download]KVM/QEMU 1. VirtualBox 1.1 查看安装版本 VBoxManage -V2. KVM/QEMU KVM: Kernel-based Virtual Machine QEMU: Quick EMUlator 通义千问: virt-manager 既不是QEMU也不是KVM,而是用于管理和创建…...

【数据库系统概论】数据库恢复技术
目录 11.1 事务的基本概念 事务的定义 事务的开始与结束 事务的ACID特性 破坏ACID特性的因素 11.2 数据库恢复概述 11.3 故障的种类 1. 事务内部的故障 2. 系统故障 3. 介质故障 4. 计算机病毒 11.4 恢复的实现技术 如何建立冗余数据 数据转储 登记日志文件 11…...

R 语言科研绘图 --- 折线图-汇总
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

基于 Python 和 OpenCV 的人脸识别上课考勤管理系统
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...

工业 4G 路由器赋能远程医疗,守护生命线
在医疗领域,尤其是偏远地区的医疗救治场景中,工业 4G 路由器正发挥着无可替代的关键作用,宛如一条坚韧的 “生命线”,为守护患者健康持续赋能。 偏远地区医疗资源相对匮乏,常常面临着专业医生短缺、诊疗设备有限等困境…...

Windows安装Ubuntu子系统图形化工具
Windows如何使用WSL方式安装Ubuntu,可以参考:https://blog.csdn.net/xiangzhihong8/article/details/145044370。接下来,我们说一下如何安装Ubuntu的图形化系统。 为了测试,这里介绍两种常见的图形化工具。第一种为VcXsrv Gnome…...

MiniMind - 从0训练语言模型
文章目录 一、关于 MiniMind 📌项目包含 二、📌 Environment三、📌 Quick Start Test四、📌 Quick Start Train0、克隆项目代码1、环境安装2、如果你需要自己训练3、测试模型推理效果 五、📌 Data sources1、分词器&am…...

sql正则表达
MySQL中的正则表达式使用REGEXP关键字来指定匹配模式。常见的正则表达式符号包括: .:匹配任意单个字符 ^:匹配字符串的开始位置 $:匹配字符串的结束位置 *:匹配前面的字符或字符集出现零次或多次 :匹配前面…...

基于华为Maas(大模型即服务)和开源的Agent三方框架构建AI聊天助手实践
引言 随着人工智能技术的快速发展,AI聊天助手已经成为企业与用户之间沟通的重要桥梁。为了构建一个高效、智能且易于扩展的AI聊天助手,我们可以利用华为云提供的Maas(Model-as-a-Service,大模型即服务)平台,结合开源的Agent三方框架来实现。本文将详细介绍这一实践过程,…...

微信小程序——创建滑动颜色条
在微信小程序中,你可以使用 slider 组件来创建一个颜色滑动条。以下是一个简单的示例,展示了如何实现一个颜色滑动条,该滑动条会根据滑动位置改变背景颜色。 步骤一:创建小程序项目 首先,使用微信开发者工具创建一个新…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...

springboot 日志类切面,接口成功记录日志,失败不记录
springboot 日志类切面,接口成功记录日志,失败不记录 自定义一个注解方法 import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;/***…...
自然语言处理——文本分类
文本分类 传统机器学习方法文本表示向量空间模型 特征选择文档频率互信息信息增益(IG) 分类器设计贝叶斯理论:线性判别函数 文本分类性能评估P-R曲线ROC曲线 将文本文档或句子分类为预定义的类或类别, 有单标签多类别文本分类和多…...
路由基础-路由表
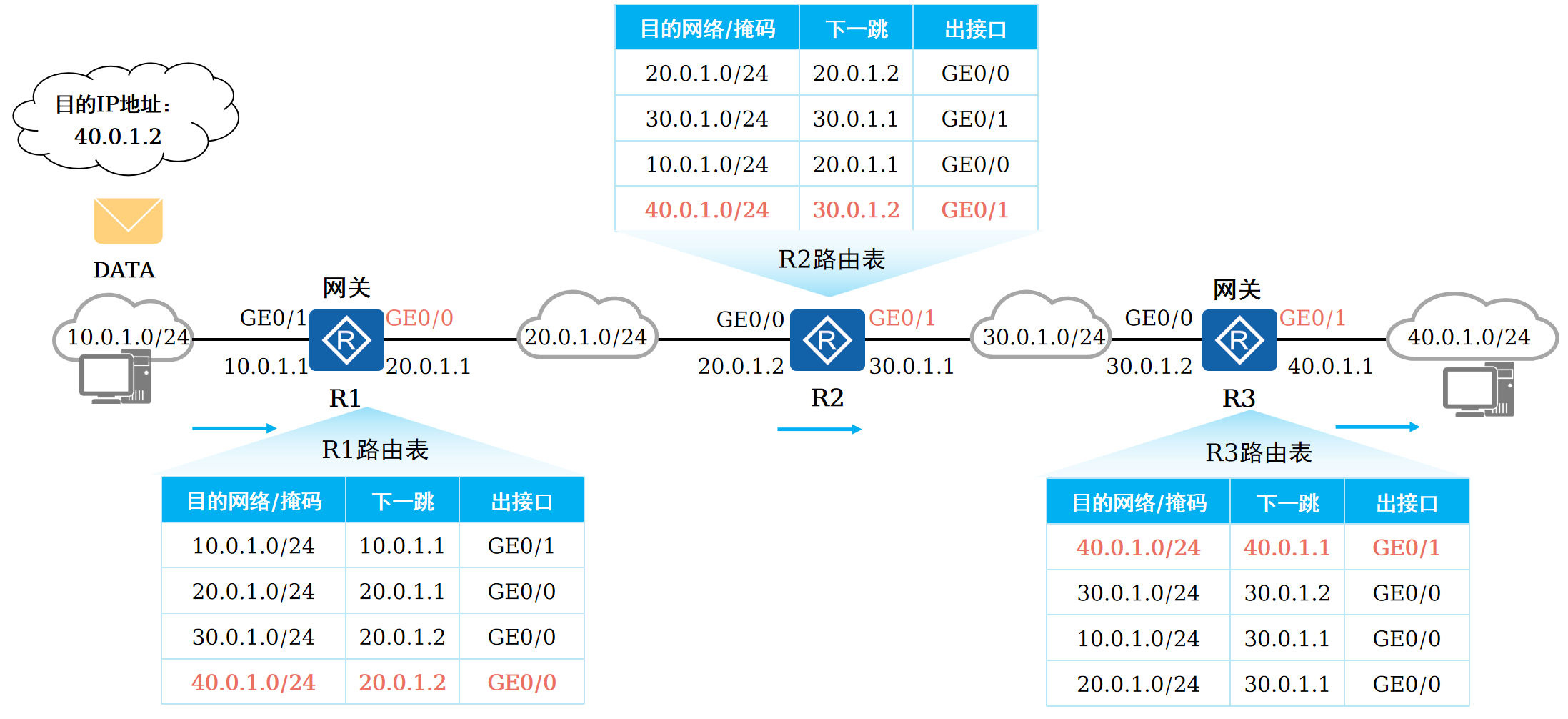
本篇将会向读者介绍路由的基本概念。 前言 在一个典型的数据通信网络中,往往存在多个不同的IP网段,数据在不同的IP网段之间交互是需要借助三层设备的,这些设备具备路由能力,能够实现数据的跨网段转发。 路由是数据通信网络中最基…...

【大模型】RankRAG:基于大模型的上下文排序与检索增强生成的统一框架
文章目录 A 论文出处B 背景B.1 背景介绍B.2 问题提出B.3 创新点 C 模型结构C.1 指令微调阶段C.2 排名与生成的总和指令微调阶段C.3 RankRAG推理:检索-重排-生成 D 实验设计E 个人总结 A 论文出处 论文题目:RankRAG:Unifying Context Ranking…...

python打卡第47天
昨天代码中注意力热图的部分顺移至今天 知识点回顾: 热力图 作业:对比不同卷积层热图可视化的结果 def visualize_attention_map(model, test_loader, device, class_names, num_samples3):"""可视化模型的注意力热力图,展示模…...