如何运用python爬虫爬取知网相关内容信息?
爬取知网内容的详细过程
爬取知网内容需要考虑多个因素,包括网站的结构、反爬虫机制等。以下是一个详细的步骤和代码实现,帮助你使用Python爬取知网上的论文信息。
1. 数据准备
首先,需要准备一些基础数据,如知网的URL、请求头等。
2. 模型构建
使用requests库发送HTTP请求,使用BeautifulSoup库解析HTML内容。
3. 模型训练
由于知网有反爬虫机制,可能需要使用Selenium来模拟浏览器行为,绕过反爬虫机制。
4. 模型评估
评估爬取的数据是否完整,是否符合预期。
5. 数据保存
将爬取的数据保存到本地或数据库中,以便后续使用。
详细步骤
1. 安装依赖
bash复制
pip install requests beautifulsoup4 selenium
2. 使用Selenium模拟浏览器行为
Python复制
from selenium import webdriver
from selenium.webdriver.common.by import By
import time# 初始化WebDriver
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 无头模式
driver = webdriver.Chrome(options=options)# 打开目标网页
url = 'https://www.cnki.net/' # 替换为知网的搜索页面URL
driver.get(url)# 等待页面加载
time.sleep(5)# 获取页面源码
html_content = driver.page_source# 关闭浏览器
driver.quit()
3. 解析HTML内容,提取论文信息
Python复制
from bs4 import BeautifulSoup# 解析HTML内容,提取论文信息
def parse_html(html):soup = BeautifulSoup(html, 'html.parser')papers = []for item in soup.find_all('div', class_='search_res_c'):title = item.find('a', class_='fz14').get_text()authors = item.find('span', class_='author').get_text()papers.append({'title': title, 'authors': authors})return papers# 解析HTML内容
papers = parse_html(html_content)
4. 保存爬取的数据
Python复制
import json# 保存爬取的数据到本地文件
def save_data(papers, filename='papers.json'):with open(filename, 'w', encoding='utf-8') as file:json.dump(papers, file, ensure_ascii=False, indent=4)print(f"Data saved to {filename}")# 保存数据
save_data(papers)
主函数
Python复制
def main():url = 'https://www.cnki.net/' # 替换为知网的搜索页面URLhtml_content = get_html(url)papers = parse_html(html_content)save_data(papers)if __name__ == "__main__":main()
注意事项
- 遵守法律法规:在爬取网站内容时,务必遵守相关法律法规和网站的使用条款。
- 合理设置爬取频率:过于频繁的爬取请求可能会对目标网站造成压力,甚至导致你的IP被封禁。
- 处理反爬虫机制:如果遇到反爬虫机制(如验证码、IP封禁等),可以尝试设置请求头、使用代理IP等方法。
完整代码
Python复制
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import json# 使用Selenium模拟浏览器行为
def get_html(url):options = webdriver.ChromeOptions()options.add_argument('--headless') # 无头模式driver = webdriver.Chrome(options=options)driver.get(url)time.sleep(5) # 等待页面加载html = driver.page_sourcedriver.quit()return html# 解析HTML内容,提取论文信息
def parse_html(html):soup = BeautifulSoup(html, 'html.parser')papers = []for item in soup.find_all('div', class_='search_res_c'):title = item.find('a', class_='fz14').get_text()authors = item.find('span', class_='author').get_text()papers.append({'title': title, 'authors': authors})return papers# 保存爬取的数据到本地文件
def save_data(papers, filename='papers.json'):with open(filename, 'w', encoding='utf-8') as file:json.dump(papers, file, ensure_ascii=False, indent=4)print(f"Data saved to {filename}")# 主函数
def main():url = 'https://www.cnki.net/' # 替换为知网的搜索页面URLhtml_content = get_html(url)papers = parse_html(html_content)save_data(papers)if __name__ == "__main__":main()
通过上述步骤和代码,你可以成功爬取知网的论文信息。希望这些内容对你有所帮助。
相关文章:

如何运用python爬虫爬取知网相关内容信息?
爬取知网内容的详细过程 爬取知网内容需要考虑多个因素,包括网站的结构、反爬虫机制等。以下是一个详细的步骤和代码实现,帮助你使用Python爬取知网上的论文信息。 1. 数据准备 首先,需要准备一些基础数据,如知网的URL、请求头…...

2025年数学建模美赛 A题分析(2)楼梯使用频率数学模型
2025年数学建模美赛 A题分析(1)Testing Time: The Constant Wear On Stairs 2025年数学建模美赛 A题分析(2)楼梯磨损分析模型 2025年数学建模美赛 A题分析(3)楼梯使用方向偏好模型 2025年数学建模美赛 A题分…...
云原生:构建现代化应用的基石
一、什么是云原生? 云原生是一种构建和运行应用程序的方法,旨在充分利用云计算的分布式系统优势,例如弹性伸缩、微服务架构、容器化技术等。云原生应用程序从设计之初就考虑到了云环境的特点,能够更好地适应云平台的动态变化&…...

18.Word:数据库培训课程❗【34】
目录 题目 NO1.2.3.4 NO5设置文档内容的格式与样式 NO6 NO7 NO8.9 NO10.11标签邮件合并 题目 NO1.2.3.4 FnF12:打开"Word素材.docx”文件,将其另存为"Word.docx”在考生文件夹下之后到任务9的所有操作均基于此文件:"Word.docx”…...

批量创建ES索引
7.x from elasticsearch import Elasticsearch# 配置 Elasticsearch 连接 # 替换为你的 Elasticsearch 地址、端口、用户名和密码 es Elasticsearch([http://10.10.x.x:43885],basic_auth(admin, XN272G9THEAPYD5N5QORX3PB1TSQELLB) )# # 测试连接 # try: # # 尝试获取集…...

RoboVLM——通用机器人策略的VLA设计哲学:如何选择骨干网络、如何构建VLA架构、何时添加跨本体数据
前言 本博客内解读不少VLA模型了,包括π0等,且如此文的开头所说 前两天又重点看了下openvla,和cogact,发现 目前cogACT把openvla的动作预测换成了dit,在模型架构层面上,逼近了π0那为了进一步逼近&#…...

25美赛ABCDEF题详细建模过程+可视化图表+参考论文+写作模版+数据预处理
详情见该链接!!!!!! 25美国大学生数学建模如何准备!!!!!-CSDN博客文章浏览阅读791次,点赞13次,收藏7次。通过了解比赛基本…...

基于RIP的MGRE VPN综合实验
实验拓扑 实验需求 1、R5为ISP,只能进行IP地址配置,其所有地址均配为公有IP地址; 2、R1和R5间使用PPP的PAP认证,R5为主认证方; R2与R5之间使用ppp的CHAP认证,R5为主认证方; R3与R5之间使用HDLC封…...

如何获取小程序的code在uniapp开发中
如何获取小程序的code在uniapp开发中,也就是本地环境,微信开发者工具中获取code,这里的操作是页面一进入就获取code登录,没有登录页面的交互,所以写在了APP.vue中,也就是小程序一打开就获取用户的code APP.…...

【Linux】 冯诺依曼体系与计算机系统架构全解
Linux相关知识点可以通过点击以下链接进行学习一起加油!初识指令指令进阶权限管理yum包管理与vim编辑器GCC/G编译器make与Makefile自动化构建GDB调试器与Git版本控制工具Linux下进度条 冯诺依曼体系是现代计算机设计的基石,其统一存储和顺序执行理念推动…...

RDMA 工作原理 | 支持 RDMA 的网络协议
注:本文为 “RDMA” 相关文章合辑。 英文引文机翻未校。 图片清晰度受引文所限。 Introduction to Remote Direct Memory Access (RDMA) Written by: Dotan Barak on March 31, 2014.on February 13, 2015. What is RDMA? 什么是 RDMA? Direct me…...

Autosar-Os是怎么运行的?(多核系统运行)
写在前面: 入行一段时间了,基于个人理解整理一些东西,如有错误,欢迎各位大佬评论区指正!!! 目录 1.Autosar多核操作系统 1.1多核启动过程 1.2多核运行过程 1.2.1核间任务同步 1.2.2Counte…...

golang命令大全4--测试与调试
Go 语言提供了一系列强大的工具和命令来帮助开发者进行代码的测试与性能调优。 1、go test 功能 go test是 Go 语言内置的测试工具,用于执行 Go 项目中的单元测试。它会查找当前包中所有以 _test.go 结尾的文件,运行其中定义的测试函数,并…...

第27篇 基于ARM A9处理器用C语言实现中断<三>
Q:基于ARM A9处理器怎样设计C语言工程,同时使用按键中断和定时器中断在红色LED上计数? A:基本原理:设置HPS Timer 0和按键中断源,主程序调用set_A9_IRQ_stack( )函数设置中断模式的ARM堆栈指针,…...

linux下使用脚本实现对进程的内存占用自动化监测
linux系统中常用cat /proc/{pid}/status和pmap -x {pid}来监测某个进程的内存资源占用情况。 其中注意各参数的含义如下: VmSize:表示进程当前虚拟内存大小 VmPeak:表示进程所占用最大虚拟内存大小 VmRSS:表示进程当前占用物理内…...

安宝特方案 | 智能培训:安宝特AR如何提升企业技能培训的效率与互动性
随着企业不断推进数字化转型,传统培训方式已无法满足现代企业对高效、灵活培训的需求。尤其在技术更新频繁、工艺流程复杂、员工流动性大的环境中,传统培训模式的局限性愈加明显。为了提升培训质量、降低培训成本,并帮助员工迅速掌握新技能&a…...

golang通过AutoMigrate方法自动创建table详解
一.AutoMigrate介绍 1.介绍 在 Go 语言中,GORM支持Migration特性,支持根据Go Struct结构自动生成对应的表结构,使用 GORM ORM 库的 AutoMigrate 方法可以自动创建数据库表,确保数据库结构与定义的模型结构一致。AutoMigrate 方法非常方便&am…...

【信息系统项目管理师-选择真题】2013上半年综合知识答案和详解
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20题】【第…...

智能调度体系与自动驾驶技术优化运输配送效率的研究——兼论开源AI智能名片2+1链动模式S2B2C商城小程序的应用潜力
摘要:随着全球化和数字化进程的加速,消费者需求日益呈现出碎片化和个性化的趋势,这对物流运输行业提出了前所未有的挑战。传统的物流调度体系与调度方式已难以满足当前复杂多变的物流需求,因此,物流企业必须积极引入大…...

【软件测试项目实战 】淘宝网:商品购买功能测试
一、用例设计方法分析 在对淘宝网商品下单功能进行测试时,不同的测试角度和场景适合运用不同的用例设计方法,以下是针对该功能各方面测试所适用方法及其原因的分析: 商品数量相关测试:对于商品数量的测试,主要采用等…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...
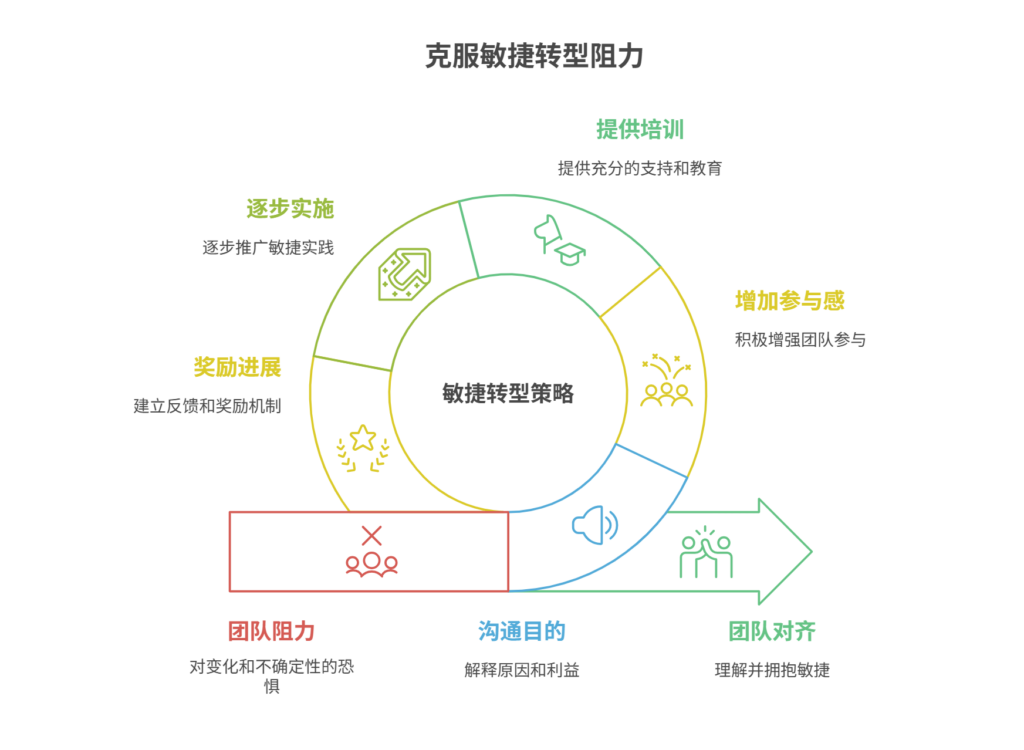
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...

6️⃣Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙
Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙 一、前言:离区块链还有多远? 区块链听起来可能遥不可及,似乎是只有密码学专家和资深工程师才能涉足的领域。但事实上,构建一个区块链的核心并不复杂,尤其当你已经掌握了一门系统编程语言,比如 Go。 要真正理解区…...
鸿蒙Navigation路由导航-基本使用介绍
1. Navigation介绍 Navigation组件是路由导航的根视图容器,一般作为Page页面的根容器使用,其内部默认包含了标题栏、内容区和工具栏,其中内容区默认首页显示导航内容(Navigation的子组件)或非首页显示(Nav…...

LeetCode 0386.字典序排数:细心总结条件
【LetMeFly】386.字典序排数:细心总结条件 力扣题目链接:https://leetcode.cn/problems/lexicographical-numbers/ 给你一个整数 n ,按字典序返回范围 [1, n] 内所有整数。 你必须设计一个时间复杂度为 O(n) 且使用 O(1) 额外空间的算法。…...