使用真实 Elasticsearch 进行高级集成测试
作者:来自 Elastic Piotr Przybyl

掌握高级 Elasticsearch 集成测试:更快、更智能、更优化。
在上一篇关于集成测试的文章中,我们介绍了如何通过改变数据初始化策略来缩短依赖于真实 Elasticsearch 的集成测试的执行时间。在本期中,我们将进一步缩短测试套件的持续时间,这次我们将通过将高级技术应用于运行 Elasticsearch 的 Docker 容器和 Elasticsearch 本身。
请注意,下面描述的技术通常可以精挑细选:你可以选择最适合你特定情况的技术。
这里有“龙”:权衡取舍
在我们深入探讨各种性能优化方法之前,必须明白一个道理:并非所有优化都应该无条件应用。尽管优化通常能带来提升,但它们也可能让整体设置变得更难理解,尤其是对于不熟悉的人来说。换句话说,在接下来的章节中,我们不会修改测试本身,而是重新设计其周围的 “基础架构代码”。这些改动可能会让代码对经验不足的团队成员来说更加晦涩。文中介绍的技术并非高深莫测,但在使用时仍需谨慎,并且有一定经验会更好。
快照
当我们停止演示代码时,我们仍在使用每个测试的数据初始化 Elasticsearch。这种方法有一些优势,特别是如果我们的数据集在测试用例之间有所不同,例如,我们有时会索引略有不同的文档。但是,如果我们所有的测试用例都可以依赖相同的数据集,我们可以使用快照和恢复方法。
了解快照和恢复在 Elasticsearch 中的工作方式很有帮助,官方文档对此进行了解释。
在我们的方法中,我们不是通过 CLI 或 DevOps 方法处理这个问题,而是将其集成到测试周围的设置代码中。这确保了在开发人员机器以及 CI/CD 中顺利执行测试。
这个想法很简单:我们不是删除索引并在每次测试之前从头开始重新创建它们,而是:
- 在容器的本地文件系统中创建快照(如果它尚不存在,因为这在以后会变得必要)。
- 在每次测试之前恢复快照。
准备快照位置
需要注意的一件重要事情 —— 这使得 Elasticsearch 与许多关系数据库不同 —— 在发送创建快照的请求之前,我们首先需要注册一个可以存储快照的位置,即所谓的存储库。有许多可用的存储选项(这对于云部署非常方便);在我们的例子中,将它们保存在容器内的本地目录中就足够了。
注意:
此处使用的 /tmp/... 位置仅适用于易变集成测试,切勿在生产环境中使用。在生产环境中,请始终将快照存储在安全可靠的位置以进行备份。
为了避免将备份存储在不安全的位置,我们首先将其添加到我们的测试中:
static final String REPO_LOCATION = "/tmp/bad_backup_location";接下来,我们配置 ElasticsearchContainer 以确保它可以使用此位置作为备份位置:
static ElasticsearchContainer elasticsearch =new ElasticsearchContainer(ELASTICSEARCH_IMAGE)// other instructions.withEnv("path.repo", REPO_LOCATION);更改设置
现在我们准备将以下逻辑附加到我们的 @BeforeAll 方法中:
if (!snapshotExists()) {setupDataInContainer();createSnapshotInContainer();
}我们的 @BeforeEach 方法应该以以下内容开头:
restoreSnapshot();可以通过验证 REPO_LOCATION 目录是否存在并包含一些文件来检查快照是否存在:
static boolean snapshotExists() throws IOException, InterruptedException {ExecResult execResult = elasticsearch.execInContainer("sh", "-c", "[ -d \"" + REPO_LOCATION + "\" ] && [ \"$(ls -A " + REPO_LOCATION + ")\" ]");return execResult.getExitCode() == 0;
}setupDataInContainer() 方法略有变化:它不再在 @BeforeEach 中调用(我们在需要时按需执行它),并且可以删除 DELETE books 请求(因为不再需要它)。
要创建快照,我们首先需要注册一个快照位置,然后在那里存储任意数量的快照(尽管我们只保留一个,因为测试不需要更多):
static void createSnapshotInContainer() throws IOException, InterruptedException {// Register REPO_LOCATION for backupsExecResult result = elasticsearch.execInContainer("curl", "https://localhost:9200/_snapshot/init_backup", "-u", "elastic:changeme","--cacert", "/usr/share/elasticsearch/config/certs/http_ca.crt","-H", "Content-Type: application/json","-X", "PUT","-d", """{"type":"fs","settings":{"location":"%s"}}""".formatted(REPO_LOCATION));assert result.getExitCode() == 0 && result.getStdout().contains("\"acknowledged\":true");// Create the snapshot and wait for completionresult = elasticsearch.execInContainer("curl", "https://localhost:9200/_snapshot/init_backup/snapshot_1?wait_for_completion=true", "-u", "elastic:changeme","--cacert", "/usr/share/elasticsearch/config/certs/http_ca.crt","-H", "Content-Type: application/json","-X", "PUT","-d", """{"indices": ["books"]}""");assert result.getExitCode() == 0;
}一旦创建快照,我们可以在每次测试之前恢复它,如下所示:
static void restoreSnapshot() {Container.ExecResult execResult;try {execResult = elasticsearch.execInContainer("/bin/sh", "-c", """curl --cacert /usr/share/elasticsearch/config/certs/http_ca.crt -s -u elastic:changeme -X DELETE "https://localhost:9200/books" \&& \curl --cacert /usr/share/elasticsearch/config/certs/http_ca.crt -s -u elastic:changeme -X POST https://localhost:9200/_snapshot/init_backup/snapshot_1/_restore?wait_for_completion=true""");} catch (Exception e) {throw new RuntimeException(e);}if (execResult.getExitCode() != 0) {throw new RuntimeException("Error when restoring backup: [%s] [%s]".formatted(execResult.getStdout(), execResult.getStderr()));}
}请注意以下几点:
- 在恢复索引之前,索引不能存在,因此我们必须先将其删除。
- 如果你需要删除多个索引,则可以在单个 curl 调用中执行此操作,例如 “https://localhost:9200/indexA,indexB”。
- 要在容器中链接多个命令,你无需将它们包装在单独的 execInContainer 调用中;运行简单的脚本可以提高可读性(并减少一些网络往返)。
在示例项目中,此技术将我的构建时间缩短至 26 秒。虽然乍一看这似乎不是一个显着的收益,但该方法是一种通用技术,可以在切换到 _bulk 摄取(在上一篇文章中讨论)之前甚至代替它应用。换句话说,你可以以任何方式在 @BeforeAll 中为测试准备数据,然后对其进行快照以在 @BeforeEach 中使用。如果你想最大限度地提高效率,甚至可以使用 elasticsearch.copyFileFromContainer(...) 将快照复制回测试机器,使其作为一种缓存形式,仅在你需要更新数据集(例如,测试新功能)时才会清除。有关完整示例,请查看标签 snapshots。
将数据保存在 RAM 中
有时,我们的测试用例明显包含大量数据,这可能会对性能产生负面影响,尤其是在底层存储速度较慢的情况下。如果你的测试需要读取和写入大量数据,而 SSD 甚至硬盘速度非常慢,你可以指示容器将数据保存在 RAM 中 - 前提是你有足够的可用内存。
这本质上是一行代码,需要在容器定义中添加 .withTmpFs(Map.of("/usr/share/elasticsearch/data", "rw"))。容器设置将如下所示:
static ElasticsearchContainer elasticsearch =new ElasticsearchContainer(ELASTICSEARCH_IMAGE)// other instructions.withTmpFs(Map.of("/usr/share/elasticsearch/data", "rw"));存储速度越慢,性能提升就越显著,因为 Elasticsearch 现在将写入和读取 RAM 中的临时文件系统。
注意:
顾名思义,这是一个临时文件系统,也就是说它不是持久性的。因此,此解决方案仅适用于测试。请勿在生产中使用它,因为它可能会导致数据丢失。
要评估此解决方案可以在多大程度上提高硬件性能, 你可以尝试标签 tmpfs。
更多工作,相同时间
产品代码库的大小在活跃开发阶段增长最快。然后,当它进入维护阶段(如果适用)时,通常只涉及错误修复。但是,测试库的大小会不断增长,因为功能和错误都需要通过测试来覆盖,以防止回归。理想情况下,错误修复应始终伴随着测试,以防止错误再次出现。这意味着即使开发不是特别活跃,测试的数量也会不断增加。本节中描述的方法提供了有关如何在不显着增加测试套件持续时间的情况下管理不断增长的测试库的提示,前提是有足够的资源来实现并行化。
为简单起见,我们假设示例中的测试用例数量增加了一倍(而不是编写额外的测试,我们将复制现有的测试用例来进行此演示)。
在最简单的方法中,我们可以向 BookSearcherIntTest 类添加三个 @Test 方法。然后,我们可以以一种有点非正统的方式使用 Java 的一个分析器:Java Flight Recorder 来观察 CPU 和内存消耗。由于我们已将其添加到 POM 中,因此在运行测试后,我们可以在主目录中打开 recording-1.jfr。结果在 Environment -> Processes 中可能如下所示:

如你所见,在一个类中运行六个测试使所需时间增加了一倍。此外,上面的 CPU 使用率图表中的主要颜色是……根本没有颜色,因为 CPU 利用率在高峰时刻几乎达不到 20%。当你为使用时间付费时(无论是向云提供商付费还是以你自己的挂钟时间来获得有意义的反馈),未充分利用 CPU 是一种浪费。
你使用的 CPU 很可能有多个核心。这里的优化是将工作负载分成两部分,这应该大约将持续时间减半。为了实现这一点,我们将新添加的测试移到另一个名为 BookSearcherAnotherIntTest 的类中,并指示 Maven 使用 -DforkCount=2 运行两个分支进行测试。完整命令变为:
./mvnw test '-Dtest=*IntTest*' -DforkCount=2
在这里,CPU 的利用率更高。
不应将重点放在确切的数字上来解释此示例。相反,重要的是不仅适用于 Java 的总体趋势:
- 检查你的 CPU 在测试期间是否得到正确利用。
- 如果没有,请尝试尽可能多地并行化你的测试(尽管其他资源有时可能会限制你)。
- 请记住,不同的环境可能需要不同的并行化因素(例如,Maven 中的 -DforkCount=N)。最好避免在构建脚本中硬编码这些因素,而是根据项目和环境对其进行调整:
- 如果只运行一个测试类,则可以跳过开发人员机器(developer machines)的这一步骤。
- 对于功能较弱的 CI 环境,较低的数字可能就足够了。
- 对于功能更强大的 CI 设置,较高的数字可能效果很好。
对于 Java,重要的是避免使用一个大类,而是尽可能将测试分成较小的类。不同的并行化技术和参数适用于其他技术堆栈,但总体目标仍然是充分利用你的硬件资源。
为了进一步完善,请避免在测试类中重复设置代码。将测试本身与基础架构/设置代码分开。例如,应将配置元素(如镜像版本声明)放在一个地方。在 Java 版 Testcontainers 中,我们可以使用(或稍微重新利用)继承来确保在测试之前加载(并执行)包含基础架构代码的类。结构如下所示:
class CommonTestBase {// Containers' declarations, startup, and data handling code here
}class BookSearcherIntTest extends CommonTestBase {// Integration tests, ideally for one service
}class AnotherServiceIntTest extends CommonTestBase {// More integration tests, ideally for another service
}如需完整的演示,请再次参考 GitHub 上的示例项目。
重用 - 仅启动一次
本文中介绍的最后一种技术对于开发人员机器(eveloper machines)特别有用。它可能不适用于传统的 CI(例如,内部托管的 Jenkins),并且对于临时 CI 环境(如基于云的 CI,其中构建机器是一次性使用的,每次构建后都会退役)通常是不必要的。此技术依赖于 Testcontainers 的预览功能,称为重用。
通常,测试套件完成后会自动清理容器。这种默认行为非常方便,尤其是在长期运行的 CI 中,因为它可以确保无论测试结果如何都不会剩余容器。但是,在某些情况下,我们可以让容器在测试之间保持运行,以便后续测试不会浪费时间再次启动它。这种方法对于在较长时间内(有时是几天)开发功能或修复错误(其中重复运行相同的测试(类))的开发人员特别有益。
如何启用重用
启用重用是一个两步过程:
1. 在声明容器时将其标记为可重用:
static ElasticsearchContainer elasticsearch =new ElasticsearchContainer(ELASTICSEARCH_IMAGE)// other instructions.withReuse(true);2. 选择在合适的环境中启用重用功能(例如,在你的开发机器上)。在开发人员工作站上执行此操作的最简单、最持久的方法是确保 $HOME 目录中的配置文件具有正确的内容。在 ~/.testcontainers.properties 中,包含以下行:
testcontainers.reuse.enable=true就这样!首次使用时,测试不会更快,因为容器仍需要启动。但是,在初始测试之后:
- 运行 docker ps 将显示容器仍在运行(这现在是一项功能,而不是错误)。
- 后续测试将更快。
注意:
一旦启用重用,手动停止容器就成为你的责任。
利用快照或初始化数据实现重用
重用功能与仅将初始化数据文件复制到容器一次或使用快照等技术结合使用效果特别好。启用重用后,无需为后续测试重新创建快照,从而节省更多时间。所有优化部分都开始落实到位。
重复使用分叉容器
虽然重复使用在许多情况下效果很好,但在第二次运行期间将重复使用与多个分叉相结合时会出现问题。这可能会导致与容器或 Elasticsearch 处于不正确状态相关的错误或乱码输出。如果你希望同时使用这两项改进(例如,在提交 PR 之前在功能强大的工作站上运行许多集成测试),则需要进行额外的调整。
问题
问题可能表现为以下错误:
co.elastic.clients.elasticsearch._types.ElasticsearchException: [es/esql.query] failed: [illegal_index_shard_state_exception] CurrentState[RECOVERING] operations only allowed when shard state is one of [POST_RECOVERY, STARTED]发生这种情况的原因在于 Testcontainers 如何识别可重复使用的容器。
当两个分支都启动且没有 Elasticsearch 容器运行时,每个分支都会初始化自己的容器。 但是,重新启动后,每个分支都会查找可重复使用的容器并找到一个。 由于所有容器看起来与 Testcontainers 相同,因此两个分支可能会选择同一个容器。 这会导致竞争条件,其中多个分支尝试使用同一个 Elasticsearch 实例。 例如,一个分支可能正在恢复快照,而另一个分支正在尝试执行相同操作,从而导致上述错误。
解决方案
为了解决这个问题,我们需要引入容器之间的差异,并确保分支根据这些差异确定性地选择容器。
步骤 1:更新 pom.xml
修改 pom.xml 中的 Surefire 配置以包含以下内容:
<environmentVariables><fork>fork_${surefire.forkNumber}</fork>
</environmentVariables>这会为每个 fork 添加一个唯一标识符 (fork_${surefire.forkNumber}) 作为环境变量。
第 2 步:修改容器声明
调整代码中的 Elasticsearch 容器声明,以包含基于 fork 标识符的标签:
static ElasticsearchContainer elasticsearch =new ElasticsearchContainer(ELASTICSEARCH_IMAGE)// other settings.withLabel("fork", System.getenv().getOrDefault("fork", "fork_1"));效果
这些更改确保每个分支都会创建并使用自己的容器。由于标签独特,容器略有不同,允许测试容器将它们确定性地分配给特定分支。
这种方法消除了竞争条件,因为没有两个分支会尝试重复使用同一个容器。重要的是,容器内的 Elasticsearch 功能保持不变,并且可以在分支之间动态分配测试而不会影响结果。
它真的值得吗?
正如本文开头所警告的那样,这里介绍的改进应谨慎应用,因为它们会使我们的测试设置代码变得不那么直观。有什么好处?
我们以在我的计算机上大约 25 秒的三个集成测试开始本文。在应用所有改进并将实际测试数量增加一倍至六个之后,我笔记本电脑上的执行时间下降到 8 秒。测试数量增加了一倍;构建时间缩短了三分之二。由你来决定它是否适合你的情况。;-)
它不止于此
这个关于使用真实 Elasticsearch 进行测试的迷你系列到此结束。在第一部分中,我们讨论了何时模拟 Elasticsearch 索引是有意义的,以及何时进行集成测试是一个更好的主意。在第二部分中,我们解决了导致集成测试变慢的最常见错误。第三部分更加努力,使集成测试运行得更快,只需几秒钟而不是几分钟。
还有更多方法可以优化你的体验并降低使用 Elasticsearch 进行系统集成测试相关的成本。不要犹豫,探索这些可能性并尝试你的技术堆栈。
如果你的案例涉及上述任何技术,或者你有任何疑问,请随时通过我们的讨论论坛或社区 Slack 频道与我们联系。
想要获得 Elastic 认证?了解下一次 Elasticsearch 工程师培训何时开始!
Elasticsearch 包含新功能,可帮助你为你的用例构建最佳搜索解决方案。深入了解我们的示例笔记本以了解更多信息,开始免费云试用,或立即在你的本地机器上试用 Elastic。
原文:Advanced integration tests with real Elasticsearch - Elasticsearch Labs
相关文章:
使用真实 Elasticsearch 进行高级集成测试
作者:来自 Elastic Piotr Przybyl 掌握高级 Elasticsearch 集成测试:更快、更智能、更优化。 在上一篇关于集成测试的文章中,我们介绍了如何通过改变数据初始化策略来缩短依赖于真实 Elasticsearch 的集成测试的执行时间。在本期中࿰…...

SQL进阶实战技巧:如何分析浏览到下单各步骤转化率及流失用户数?
目录 0 问题描述 1 数据准备 2 问题分析 3 问题拓展 3.1 跳出率计算...
机器学习--概览
一、机器学习基础概念 1. 定义 机器学习(Machine Learning, ML):通过算法让计算机从数据中自动学习规律,并利用学习到的模型进行预测或决策,而无需显式编程。 2. 与编程的区别 传统编程机器学习输入:规…...

低代码系统-产品架构案例介绍、炎黄盈动-易鲸云(十二)
易鲸云作为炎黄盈动新推出的产品,在定位上为低零代码产品。 开发层 表单引擎 表单设计器,包括设计和渲染 流程引擎 流程设计,包括设计和渲染,需要说明的是:采用国际标准BPMN2.0,可以全球通用 视图引擎 视图…...
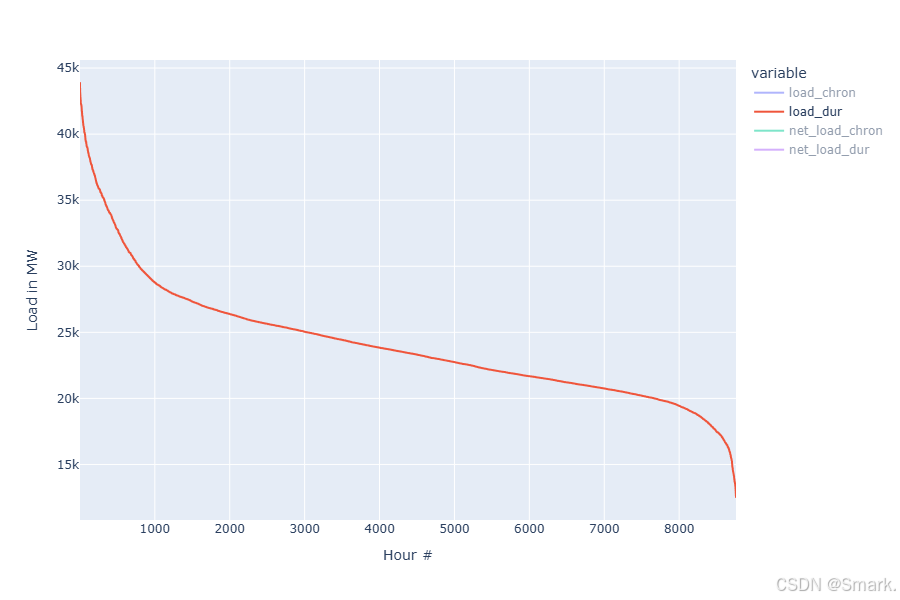
Electricity Market Optimization 探索系列(二)
本文参考链接link 负荷持续时间曲线 (Load Duration Curve),是根据实际的符合数据进行降序排序之后得到的一个曲线 这个曲线能够发现负荷在某个区间时,将会持续多长时间,有助于发电容量的规划 净负荷(net load) 是指预期负荷和预期可再生…...

OpenAI 实战进阶教程 - 第一节:OpenAI API 架构与基础调用
目标 掌握 OpenAI API 的基础调用方法。理解如何通过 API 进行内容生成。使用实际应用场景帮助零基础读者理解 API 的基本用法。 一、什么是 OpenAI API? OpenAI API 是一种工具,允许开发者通过编程方式与 OpenAI 的强大语言模型(例如 gpt-…...
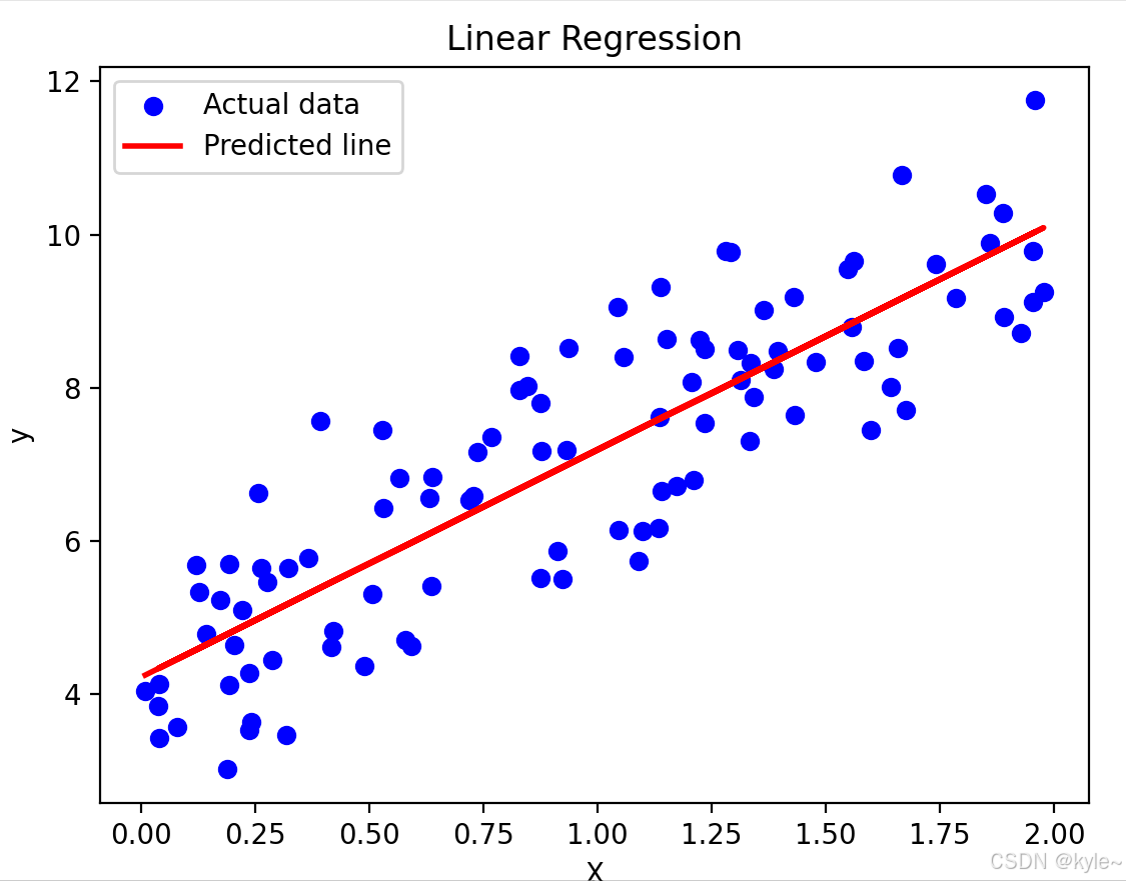
TensorFlow简单的线性回归任务
如何使用 TensorFlow 和 Keras 创建、训练并进行预测 1. 数据准备与预处理 2. 构建模型 3. 编译模型 4. 训练模型 5. 评估模型 6. 模型应用与预测 7. 保存与加载模型 8.完整代码 1. 数据准备与预处理 我们将使用一个简单的线性回归问题,其中输入特征 x 和标…...

【视频+图文详解】HTML基础4-html标签的基本使用
图文教程 html标签的基本使用 无序列表 作用:定义一个没有顺序的列表结构 由两个标签组成:<ul>以及<li>(两个标签都属于容器级标签,其中ul只能嵌套li标签,但li标签能嵌套任何标签,甚至ul标…...

在Arm芯片苹果Mac系统上通过homebrew安装多版本mysql并解决各种报错,感谢deepseek帮助解决部分问题
背景: 1.苹果设备上安装mysql,随着苹果芯片的推出,很多地方都变得不一样了。 2.很多时候为了老项目能运行,我们需要能安装mysql5.7或者mysql8.0或者mysql8.2.虽然本文编写时最新的默认mysql已经是9.2版本。 安装步骤 1.执行hom…...

c++可变参数详解
目录 引言 库的基本功能 va_start 宏: va_arg 宏 va_end 宏 va_copy 宏 使用 处理可变参数代码 C11可变参数模板 基本概念 sizeof... 运算符 包扩展 引言 在C编程中,处理不确定数量的参数是一个常见的需求。为了支持这种需求,C标准库提供了 &…...
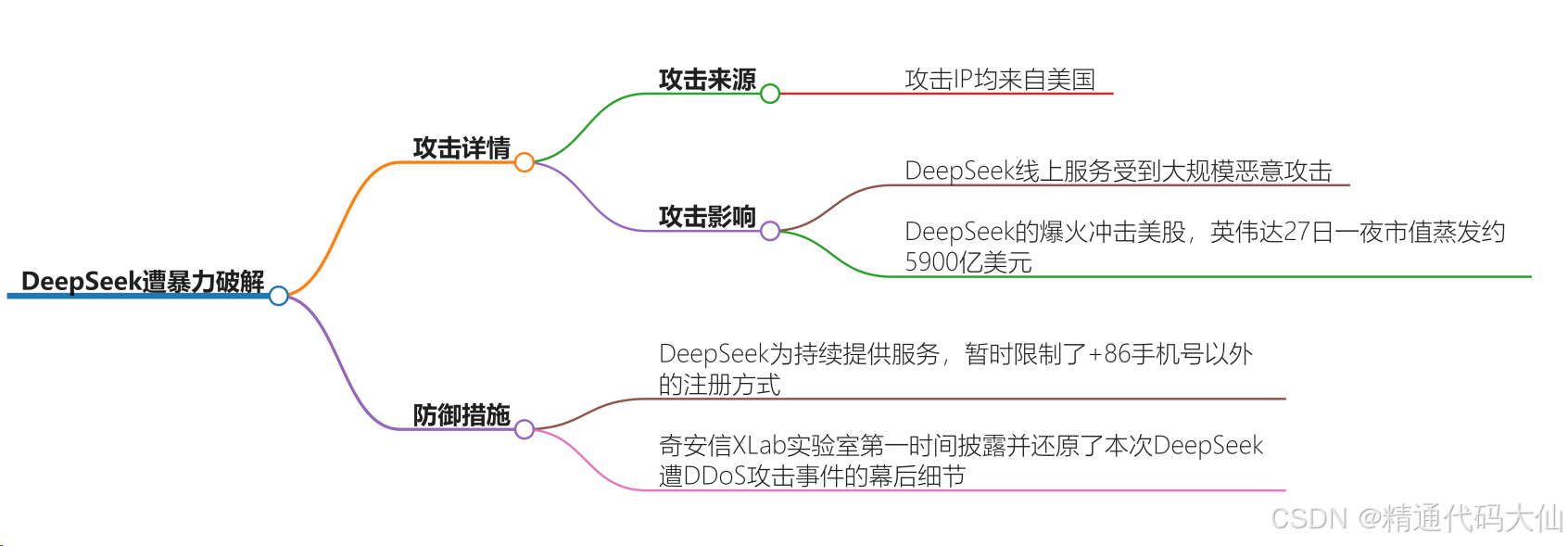
【深度分析】DeepSeek 遭暴力破解,攻击 IP 均来自美国,造成影响有多大?有哪些好的防御措施?
技术铁幕下的暗战:当算力博弈演变为代码战争 一场针对中国AI独角兽的全球首例国家级密码爆破,揭开了数字时代技术博弈的残酷真相。DeepSeek服务器日志中持续跳动的美国IP地址,不仅是网络攻击的地理坐标,更是技术霸权对新兴挑战者的…...
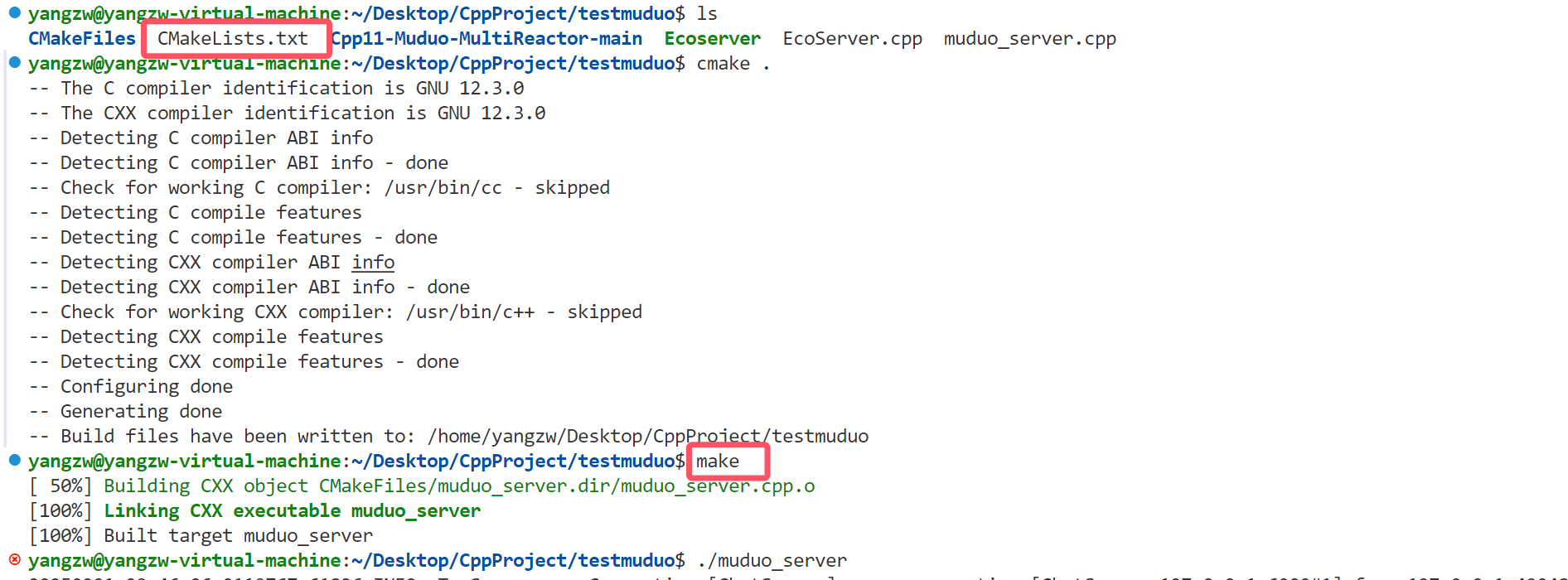
CMake项目编译与开源项目目录结构
Cmake 使用简单方便,可以跨平台构建项目编译环境,尤其比直接写makefile简单,可以通过简单的Cmake生成负责的Makefile文件。 如果没有使用cmake进行编译,需要如下命令:(以muduo库echo服务器为例)…...

完全卸载mysql server步骤
1. 在控制面板中卸载mysql 2. 打开注册表,运行regedit, 删除mysql信息 HKEY_LOCAL_MACHINE-> SYSTEM->CurrentContolSet->Services->EventLog->Application->Mysql HKEY_LOCAL_MACHINE-> SYSTEM->CurrentContolSet->Services->Mysql …...
)
C#方法(练习)
1.定义一个函数,输入三个值,找出三个数中的最小值 2.定义一个函数,输入三个值,找出三个数中的最大值 3.定义一个函数,输入三个值,找出三个数中的平均值 4.定义一个函数,计算一个数的 N 次方 Pow(2, 3)返回8 5.传入十一…...
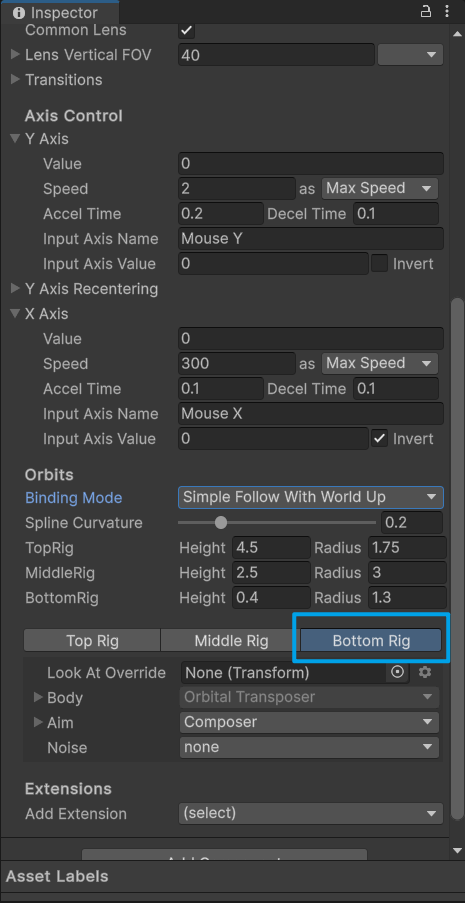
Unity游戏(Assault空对地打击)开发(3) 摄像机的控制
详细步骤 打开My Assets或者Package Manager。 选择Unity Registry。 搜索Cinemachine,找到 Cinemachine包,点击 Install按钮进行安装。 关闭窗口,新建一个FreeLook Camera,如下。 接着新建一个对象Pos,拖到Player下面…...

ChatGPT-4o和ChatGPT-4o mini的差异点
在人工智能领域,OpenAI再次引领创新潮流,近日正式发布了其最新模型——ChatGPT-4o及其经济实惠的小型版本ChatGPT-4o Mini。这两款模型虽同属于ChatGPT系列,但在性能、应用场景及成本上展现出显著的差异。本文将通过图文并茂的方式࿰…...

SQL进阶实战技巧:某芯片工厂设备任务排产调度分析 | 间隙分析技术应用
目录 0 技术定义与核心原理 1 场景描述 2 数据准备 3 间隙分析法 步骤1:原始时间线可视化...

【力扣】438.找到字符串中所有字母异位词
AC截图 题目 思路 我一开始是打算将窗口内的s子字符串和p字符串都重新排序,然后判断是否相等,再之后进行窗口滑动。不过缺点是会超时。 class Solution { public:vector<int> findAnagrams(string s, string p) {vector<int> vec;if(s.siz…...
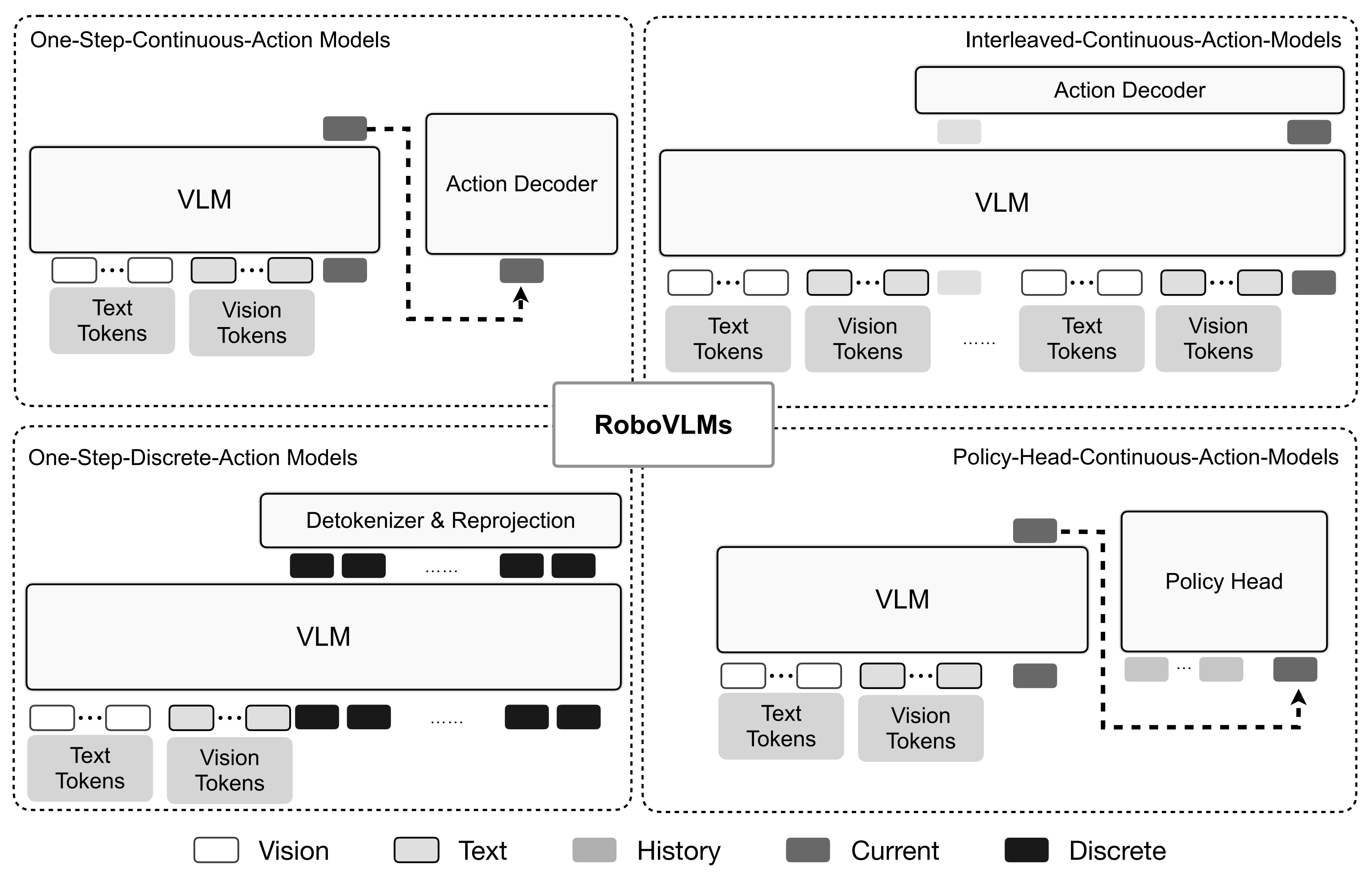
2024具身智能模型汇总:从训练数据、动作预测、训练方法到Robotics VLM、VLA
前言 本文一开始是属于此文《GRAPE——RLAIF微调VLA模型:通过偏好对齐提升机器人策略的泛化能力》的前言内容之一(该文发布于23年12月底),但考虑到其重要性,加之那么大一张表格 看下来 阅读体验较差,故抽出取来独立成文且拆分之 …...

Day33【AI思考】-函数求导过程 的优质工具和网站
文章目录 **函数求导过程** 的优质工具和网站**一、动态图形工具**1. **Desmos(网页端)**2. **GeoGebra(全平台)** **二、分步推导工具**3. **Wolfram Alpha(网页/App)**4. **Symbolab(网页/App…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...
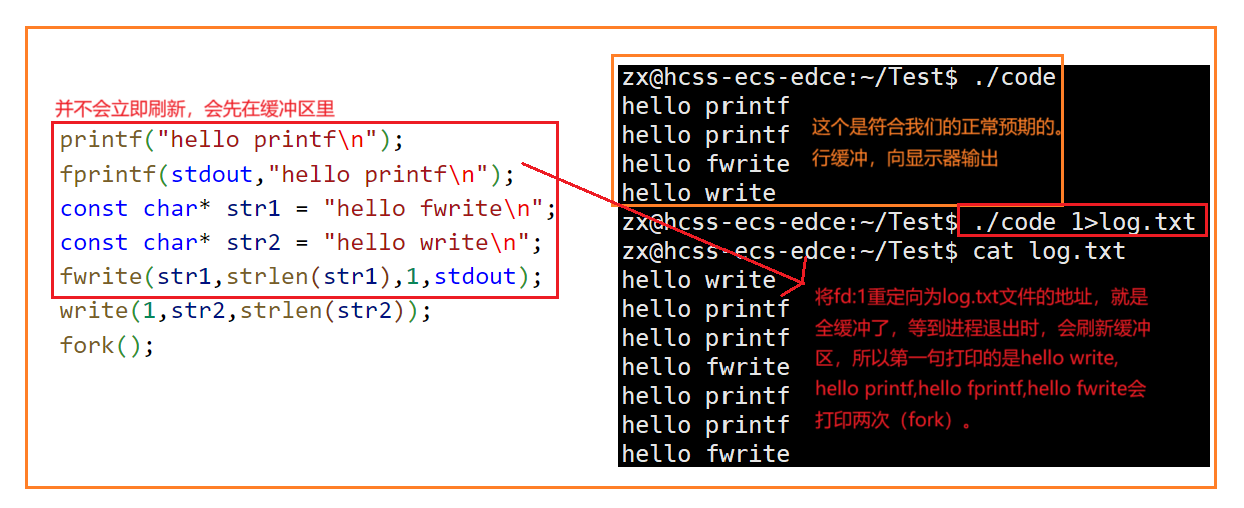
Linux中《基础IO》详细介绍
目录 理解"文件"狭义理解广义理解文件操作的归类认知系统角度文件类别 回顾C文件接口打开文件写文件读文件稍作修改,实现简单cat命令 输出信息到显示器,你有哪些方法stdin & stdout & stderr打开文件的方式 系统⽂件I/O⼀种传递标志位…...

使用SSE解决获取状态不一致问题
使用SSE解决获取状态不一致问题 1. 问题描述2. SSE介绍2.1 SSE 的工作原理2.2 SSE 的事件格式规范2.3 SSE与其他技术对比2.4 SSE 的优缺点 3. 实战代码 1. 问题描述 目前做的一个功能是上传多个文件,这个上传文件是整体功能的一部分,文件在上传的过程中…...