【贪心算法篇】:“贪心”之旅--算法练习题中的智慧与策略(二)
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨
✨ 个人主页:余辉zmh–CSDN博客
✨ 文章所属专栏:贪心算法篇–CSDN博客

文章目录
- 前言
- 例题
- 1.买卖股票的最佳时机
- 2.买卖股票的最佳时机2
- 3.k次取反后的最大化数组和
- 4.按身高排序
- 5.优势洗牌
- 6.最长回文串
- 7.增减字符串匹配
- 8.分发饼干
前言
本篇文章是对贪心算法练习题的讲解,有关贪心算法的讲解可以看本系列的第一篇文章,这里就不再重复讲解,直接继续讲解例题。
例题
1.买卖股票的最佳时机
题目:

算法原理:
本道题的贪心策略很简单,既然要求获取最高的利润,而且本道题限制只能买卖一次,那么就在整个股票价格中选择最低点买入,最高点卖出即可,这样就能保证利润最大化。
设置两个变量,一个用来标记最低的买价,一个用来标记当前利润;遍历整个股票价格,现将当前价格减去最低的买价更新利润,然后更新当前价格是否是最低价。遍历完整个股票价格后,当前利润就是最大的利润。
代码实现:
int maxProfit(vector<int>& prices){//minnum表示最低的买价,ret表示最高的利润int minnum = INT_MAX, ret = INT_MIN;for(auto x : prices){ret = max(ret, x - minnum);minnum = min(minnum, x);}if(ret<0){return 0;}return ret;
}
2.买卖股票的最佳时机2
题目:

算法原理:
本道题和上一道题不同的是,不再局限于只能买卖一次,可以无限次买卖,只要保证最后的利润是最大的即可。
首先需要明白,什么时候买卖才能有利润不亏损,那就是下一个价格比当前价格低,也就是升序排列,所以在上升趋势段买卖,才会有利润,但是在上升趋势段的什么时候买卖才能最大利润,那肯定就是上升趋势段的最低点和最高点买入和卖出。因此找到所有升序段的利润然后相加就是整体的最大利润。这就是本道题的贪心策略。
这里有两种解法:第一种就是找到一个升序段,标记最低点和最高点的价格,然后直接两个端点相减就是当前整个升序段的利润和;第二种就是只要下一个的价格大于当前价格,就买入和卖出。比如说当前有连续三天的价格都是上升趋势,第一种方式就是在第一天买入,第三天卖出,只找开始和结尾。而第二种方式则是,第一天买入,第二天卖出,然后第二天再买入,第三天卖出,将整个升序段的利润拆分成每一天利润,最后每一天的利润和还是整个升序段的利润和。
代码实现:
//方法一:
int maxProfit(vector<int>& prices){//使用双指针找到上升趋势的最低点和最高点进行买卖int ret = 0;for (int buy = 0; buy < prices.size(); buy++){//卖指针从买指针位置开始找int sell = buy;//找到上身趋势的最高点while(sell+1<prices.size()&&prices[sell]<prices[sell+1]){sell++;}//在当前位置买卖ret += prices[sell] - prices[buy];//更新买指针指向当前位置buy = sell;}return ret;
}
//方法二:
int maxProfit(vector<int>& prices){//在上升趋势段,一天一天地买卖获取利润int ret = 0;for (int i = 0; i < prices.size(); i++){//如果下一个值大于当前值,就直接买卖if(i+1<prices.size()&&prices[i+1]>prices[i]){ret += prices[i + 1] - prices[i];}}return ret;
}
3.k次取反后的最大化数组和
题目:

算法原理:
本道题的题意要求,挑选数组中的一个数变化为相反数,总共需要变化k次,最后使变化后的数组和最大。注意一个数可以变化多次,没有次数限制。
既然题意要求变化后的数组和最大,那么每次变化都挑选最小的数变化不就行了吗,这样就能对数组和的影响减小。但是数组中有正数和负数之分,因此两种情况要分类讨论:如果是负数的话,负数的相反数是正数,可以使数组和变大,因此负数只需变化一次即可;如果是正数的话,还要继续分情况讨论:如果当前剩余的k次为偶数,正数变化两次后还是正数,所以变化偶数次后还是当前数,相当于不变,对数组和无影响直接结束;如果当前剩余的k次为奇数,只需让最小的正数变化一次为负数,这样对数组和的影响最小,然后剩余偶数次,变化偶数次后相当于不变,直接结束即可。这就是本道题的贪心策略。
这里我是用小根堆数据结构来实现,每次直接获取堆顶元素,然后判断正负,负数就变化一次,变化后存放到堆中,正数再判断剩余次数的奇偶,如果是偶数,直接结束,相当于变化偶数次不变;如果是奇数,当前正数因为是最小的正数所以变化一次,剩余偶数次,同理直接结束。最后返回变化后的元素和
代码实现:
struct Greater{bool operator()(const int p1,const int p2){return p1 > p2;}
};
int largestSumAfterKNegations(vector<int>& nums, int k){//建立一个小根堆priority_queue<int, vector<int>, Greater> heap(nums.begin(), nums.end());while(k>0){//获取堆顶元素int t = heap.top();heap.pop();//如果堆顶元素是负数,修改为正数if(t<0){heap.push(-t);k--;}//如果堆顶元素是正数,先判断当前剩余次数else{//如果次数为奇数,修改最小的正数为负数,次数减一,剩余次数就是偶数//下一个正数进行偶数次的变换,相当于不变,直接结束if(k%2==1){heap.push(-t);k = 0;}//如果剩余偶数次,当前正数变化完所有次数,相当于不变,直接结束else{heap.push(t);k = 0;}}}int ret = 0;while(!heap.empty()){ret+=heap.top();heap.pop();}return ret;
}
4.按身高排序
题目:

算法原理:
本道题其实并不是贪心算法题,但是本道题使用的策略会在下一道贪心算法题中用到,因此可以先用这道题练习一下。
本道题就是一道简单的排序问题,一个数组存放的是名字,一个数组存放的是身高,两个数组通过下标可以一一对应名字和身高,然后就是按照身高排序,返回排序后的名字。这里就存在了一个细节问题,如果直接对身高这个数组排序,排完序后,名字数组没有变,就会导致不能再通过下标一一对应名字和身高,最后返回的名字顺序也就是错误的。
本道题有多种解法,第一种就是可以使用二元数组,重新创建一个数组,数组里面存放的是键值对pair<string,int>,使每个名字一一对应各自的身高。然后将数组按照身高排序,最后遍历数组返回名字即可。第二种就是可以借助哈希表,建立名字和身高的映射关系,其实和第一种同理,只不过数据存储方式不一样,实现过程还是相同的。
上面两种方式都可以实现,但这里重点要介绍的还是第三种方式:直接对下标进行排序,建立一个新数组,存放的是每一个下标,然后通过Lambda表达式自定义排序规则,[&]是捕获列表,用于排序时可以访问的外部变量,这里排序的外部变量就是身高数组;()内是参数列表,对应下标数组中需要排序的两个下标;{}内是函数体,也就是排序规则的实现,按照下标对应的身高数组中的身高进行排序。这样自定义排序规则就可以实现下标按照身高排序,不改变原有的名字和身高数组,最后再遍历排序好的下标数组,通过下标就可以找到名字,返回即可。
代码实现:
vector<string> sortPeople(vector<string>& names, vector<int>& heights){//建立一个下标数组int n = names.size();vector<int> index(n);for (int i = 0; i < n; i++){index[i] = i;}//对下标数组进行排序sort(index.begin(), index.end(), [&](const int i, const int j){return heights[i] > heights[j]; });//提取结果vector<string> ret;for(auto i : index){ret.push_back(names[i]);}return ret;
}
5.优势洗牌
题目:

算法原理:

代码实现:
vector<int> advantageCount(vector<int>& nums1, vector<int>& nums2){int n = nums1.size(), m = nums2.size();//给数组2创建一个下标数组vector<int> index(m);for (int i = 0; i < m; i++){index[i] = i;}// 数组1直接排序,数组2通过下标数组排序,排升序sort(nums1.begin(), nums1.end());sort(index.begin(), index.end(), [&](const int i, const int j) {return nums2[i] < nums2[j]; });//创建一个结果数组用来存放数组1按题意要求的排序vector<int> ret(n);//两个指针用来指向下标数组的前后位置int left = 0, right = m - 1;for (int i = 0; i < ; i++){//如果第一个数组的值大于第二个数组的当前值,左指针指向下标数组中的位置就是结果数组中存放的下标if(nums1[i]>nums2[index[left]]){ret[index[left++]] = nums1[i];}//如果小于等于,存放到右指针指向的下标位置else{ret[index[right--]] = nums1[i];}}return ret;
}
6.最长回文串
题目:

算法原理:
本道题的贪心策略比较简单,构成回文串时尽可能多地选取字符,先统计所有字符的个数,有奇数个也有偶数个,如果当前字符是偶数个n,那么回文串中一定包含所有的当前字符n个,比如字符a有4个,回文串就是aa|aa,左右两侧平均分;如果当前字符是奇数个n,那么回文串中一定包含当前字符的n-1个,比如字符b有5个,回文串就是bb|bb;当统计完所有字符后,如果最后回文串的长度小于原字符串的长度,说明存在奇数个字符,随便选一个奇数个的字符放到中间|位置,回文串的长度再加一。
代码实现:
int longestPalindrome(string s){//建立哈希表,统计字符的个数unordered_map<char, int> hash;for(auto ch : s){hash[ch]++;}int ret = 0;for(auto& [ch,count] : hash){//不管个数是奇数还是偶数,都是先除以2再乘以2ret += count / 2 * 2;}//如果最后回文串的长度小于原字符串的长度,说明存在奇数个的字符,回文串长度再+1if(ret<s.size()){ret++;}return ret;
}
7.增减字符串匹配
题目:

算法原理:
本道题的贪心策略:原字符串的长度为n,从0到n挑选数字填充数组对应字符串中的每个字符,遇到’I’选择0到n中剩余的最小的数,因为下一个不管位置是字符’I’还是字符’D’,挑选的值都会比当前最小的数大,这样就能满足字符’I’的要求,下一个比当前的大;遇到’D’选择0到n中剩余的最大的数,因为下一个不管位置时字符’I’还是字符’D’,挑选的值都会比当前最大的数小,这样就能满足字符’D’的要求,下一个比当前的小,当遍历完所有的字符后,剩下的一个值填充到数组最后。
代码实现:
vector<int> diStringMatch(string s){//贪心策略:遇到'I'选择最小的数,遇到'D'选择最大的数int n = s.size();//两个指针表示0到n的数字,left表示最小的数,right表示最大的数int left = 0, right = n;vector<int> ret(n + 1);for (int i = 0; i < n; i++){if(s[i]=='I'){ret[i] = left++;}else{ret[i] = right--;}}//最后一个位置用剩下的一个值填充ret[n] = left;return ret;
}
8.分发饼干
题目:

算法原理:
本道题的贪心策略其实和上面优势洗牌一样,同样借助了田忌赛马的原理,只不过本道题比较简单,要求统计的是最多能满足的个数,不用按照数组的格式一一对应返回,所以贪心策略就可以简单化,还是先将两个数组排序然后一一比较,如果两个数能比过,也就是数组s的值大于数组g的值就直接比较下一对,满足个数加一;如果比不过,也就是数组s的值小于数组g的值,不用再和数组g中最大的值比较去拖累最大的值,因为即使和最大的比较也比过,题意要求返回的是满足个数,所以直接跳过当前数组s的值,用下一个比即可。
相较于优势洗牌那道题,本道题还是比较简单的。
代码实现:
int findContentChildren(vector<int>& g, vector<int>& s){//贪心策略,先将两个数组排序,在能满足当前胃口的情况下选择较小的饼干sort(g.begin(),g.end());sort(s.begin(), s.end());int ret = 0;for (int i = 0, j = 0; i < g.size() && j < s.size(); ){//如果当前饼干能满足当前胃口值,直接选择当前饼干if(s[j]>=g[i]){ret++;i++;j++;}//否则,跳过当前饼干else{j++;}}return ret;
}
以上就是关于贪心算法练习题第二部分的讲解,如果哪里有错的话,可以在评论区指正,也欢迎大家一起讨论学习,如果对你的学习有帮助的话,点点赞关注支持一下吧!!!

相关文章:
【贪心算法篇】:“贪心”之旅--算法练习题中的智慧与策略(二)
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨ ✨ 个人主页:余辉zmh–CSDN博客 ✨ 文章所属专栏:贪心算法篇–CSDN博客 文章目录 前言例题1.买卖股票的最佳时机2.买卖股票的最佳时机23.k次取…...

007 JSON Web Token
文章目录 https://doc.hutool.cn/pages/jwt/#jwt%E4%BB%8B%E7%BB%8D JWT是一种用于双方之间安全传输信息的简洁的、URL安全的令牌标准。这个标准由互联网工程任务组(IETF)发表,定义了一种紧凑且自包含的方式,用于在各方之间作为JSON对象安全地传输信息。…...

Windsurf cursor vscode+cline 与Python快速开发指南
Windsurf简介 Windsurf是由Codeium推出的全球首个基于AI Flow范式的智能IDE,它通过强大的AI助手功能,显著提升开发效率。Windsurf集成了先进的代码补全、智能重构、代码生成等功能,特别适合Python开发者使用。 Python环境配置 1. Conda安装…...

将markdown文件和LaTex公式转为word
通义千问等大模型生成的回答多数是markdown类型的,需要将他们转为Word文件 一 pypandoc 介绍 1. 项目介绍 pypandoc 是一个用于 pandoc 的轻量级 Python 包装器。pandoc 是一个通用的文档转换工具,支持多种格式的文档转换,如 Markdown、HTM…...

grpc 和 http 的区别---二进制vsJSON编码
gRPC 和 HTTP 是两种广泛使用的通信协议,各自适用于不同的场景。以下是它们的详细对比与优势分析: 一、核心特性对比 特性gRPCHTTP协议基础基于 HTTP/2基于 HTTP/1.1 或 HTTP/2数据格式默认使用 Protobuf(二进制)通常使用 JSON/…...
)
C#面向对象(封装)
1.什么是封装? C# 封装 封装 被定义为“把一个或多个项目封闭在一个物理的或者逻辑的包中”。 在面向对象程序设计方法论中,封装是为了防止对实现细节的访问。 抽象和封装是面向对象程序设计的相关特性。 抽象允许相关信息可视化,封装则使开发者实现所…...

kamailio-kamctl monitor解释
这段输出是 Kamailio 服务器的运行时信息和统计数据的摘要。以下是对每个部分的详细解释: 1. Kamailio Runtime Details cycle #: 3: 表示 Kamailio 的主循环已经运行了 3 个周期。Kamailio 是一个事件驱动的服务器,主循环用于处理事件和请求。if const…...

39. I2C实验
一、IIC协议详解 1、ALPHA开发板上有个AP3216C,这是一个IIC接口的器件,这是一个环境光传感器。AP3216C连接到了I2C1上: I2C1_SCL: 使用的是UART4_TXD这个IO,复用位ALT2 I2C1_SDA: 使用的是UART4_RXD这个IO。复用为ALT2 2、I2C分为SCL和SDA&…...

GPIO配置通用输出,推挽输出,开漏输出的作用,以及输出上下拉起到的作用
通用输出说明: ①输出原理: 对输出数据寄存器的对应位写0 或 1,就可以控制对应编号的IO口输出低/高电平 ②输出类型 推挽输出:IO口可以输出高电平,也可以输出低电平 开漏输出:IO口只能输出低电平 所以…...

Spring AOP 入门教程:基础概念与实现
目录 第一章:AOP概念的引入 第二章:AOP相关的概念 1. AOP概述 2. AOP的优势 3. AOP的底层原理 第三章:Spring的AOP技术 - 配置文件方式 1. AOP相关的术语 2. AOP配置文件方式入门 3. 切入点的表达式 4. AOP的通知类型 第四章&#x…...

DeepSeek 核心技术全景解析
DeepSeek 核心技术全景解析:突破性创新背后的设计哲学 DeepSeek的创新不仅仅是对AI基础架构的改进,更是一场范式革命。本文将深入剖析其核心技术,探讨 如何突破 Transformer 计算瓶颈、如何在 MoE(Mixture of Experts)…...

90,【6】攻防世界 WEB Web_php_unserialize
进入靶场 进入靶场 <?php // 定义一个名为 Demo 的类 class Demo { // 定义一个私有属性 $file,默认值为 index.phpprivate $file index.php;// 构造函数,当创建类的实例时会自动调用// 接收一个参数 $file,用于初始化对象的 $file 属…...

实现网站内容快速被搜索引擎收录的方法
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/6.html 实现网站内容快速被搜索引擎收录,是网站运营和推广的重要目标之一。以下是一些有效的方法,可以帮助网站内容更快地被搜索引擎发现和收录: 一、确…...

WSL2中安装的ubuntu搭建tftp服务器uboot通过tftp下载
Windows中安装wsl2,wsl2里安装ubuntu。 1. Wsl启动后 1)Windows下ip ipconfig 以太网适配器 vEthernet (WSL (Hyper-V firewall)): 连接特定的 DNS 后缀 . . . . . . . : IPv4 地址 . . . . . . . . . . . . : 172.19.32.1 子网掩码 . . . . . . . .…...

机器学习优化算法:从梯度下降到Adam及其变种
机器学习优化算法:从梯度下降到Adam及其变种 引言 最近deepseek的爆火已然说明,在机器学习领域,优化算法是模型训练的核心驱动力。无论是简单的线性回归还是复杂的深度神经网络,优化算法的选择直接影响模型的收敛速度、泛化性能…...

[SAP ABAP] 静态断点的使用
在 ABAP 编程环境中,静态断点通过关键字BREAK-POINT实现,当程序执行到这一语句时,会触发调试器中断程序的运行,允许开发人员检查当前状态并逐步跟踪后续代码逻辑 通常情况下,在代码的关键位置插入静态断点可以帮助开发…...

129.求根节点到叶节点数字之和(遍历思想)
Problem: 129.求根节点到叶节点数字之和 文章目录 题目描述思路复杂度Code 题目描述 思路 遍历思想(利用二叉树的先序遍历) 直接利用二叉树的先序遍历,将遍历过程中的节点值先利用字符串拼接起来遇到根节点时再转为数字并累加起来,在归的过程中…...
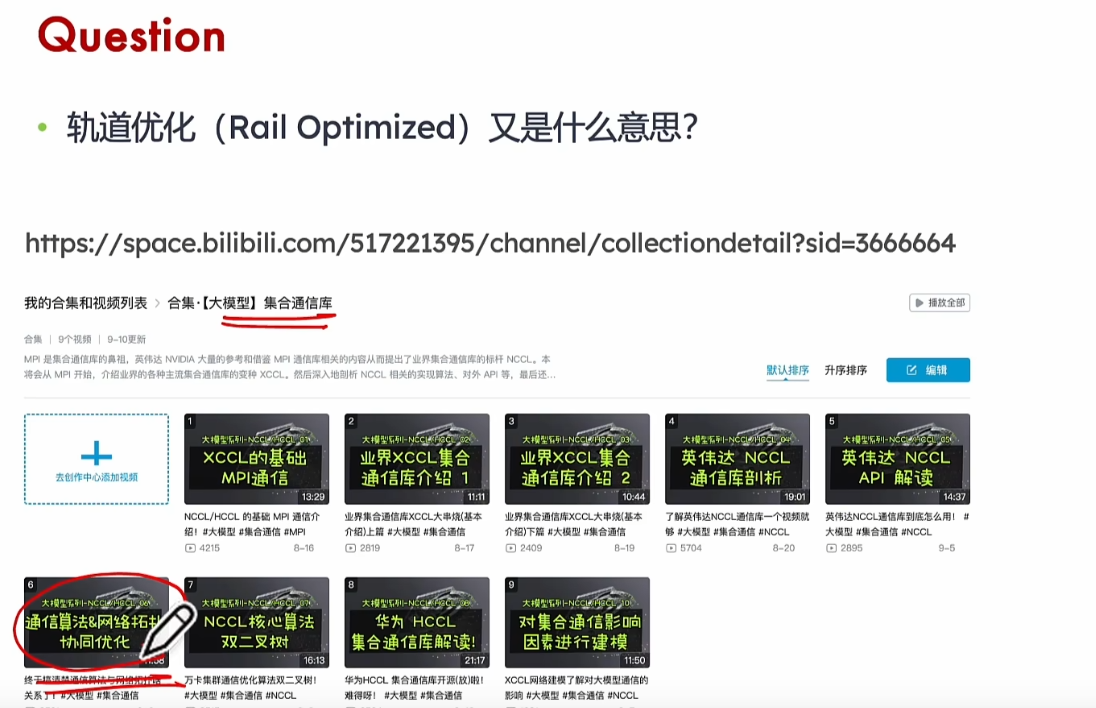
NCCL、HCCL、通信、优化
文章目录 从硬件PCIE、NVLINK、RDMA原理到通信NCCL、MPI原理!通信实现方式:机器内通信、机器间通信通信实现方式:通讯协调通信实现方式:机器内通信:PCIe通信实现方式:机器内通信:NVLink通信实现…...

unity学习21:Application类与文件存储的位置
目录 1 unity是一个跨平台的引擎 1.1 使用 Application类,去读写文件 1.2 路径特点 1.2.1 相对位置/相对路径: 1.2.2 固定位置/绝对路径: 1.3 测试方法,仍然挂一个C#脚本在gb上 2 游戏数据文件夹路径(只读&…...

17 一个高并发的系统架构如何设计
高并发系统的理解 第一:我们设计高并发系统的前提是该系统要高可用,起码整体上的高可用。 第二:高并发系统需要面对很大的流量冲击,包括瞬时的流量和黑客攻击等 第三:高并发系统常见的需要考虑的问题,如内存不足的问题,服务抖动的…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...