LLMs之DeepSeek:Math-To-Manim的简介(包括DeepSeek R1-Zero的详解)、安装和使用方法、案例应用之详细攻略
LLMs之DeepSeek:Math-To-Manim的简介(包括DeepSeek R1-Zero的详解)、安装和使用方法、案例应用之详细攻略
目录
Math-To-Manim的简介
1、特点
2、一个空间推理测试—考察不同大型语言模型如何解释和可视化空间关系
3、DeepSeek R1-Zero的简介:处理更长的上下文窗口+改进注意力机制
(1)、核心思想:迁移学习+指令微调+长上下文神经架构
(2)、理论基础:基于Transformer架构、扩展上下文窗口(分布式位置编码+基于段的注意力机制)、指令微调(精心策划的提示语料数据)、语义压缩(编码器侧)
(3)、模型架构:参数量(6.7B)+词汇表(32k)+基于T5架构(32个头/36层)+位置编码(绝对位置编码+针对8k token的学习型分段位置编码)+优化交叉注意力机制+8K上下文+层堆叠策略(提高多GPU环境中的吞吐量)
(4)、部署细节:分片检查点+Accelerate集成+分段编码+并行交叉注意力+量化(4位/8位)
(5)、性能基准:与GPT-3.5接近
(6)、潜在限制(上下文有限+存在训练偏差+可解释性),未来发展(集成高级内存系统+整合flash attention+优化RAG)
Math-To-Manim的安装和使用方法
1、安装
克隆和设置
环境设置
安装依赖项
安装FFmpeg (根据操作系统选择合适的命令)
启动界面
渲染选项
2、开发技巧
Math-To-Manim的案例应用
1、动画示例
Benamou-Brenier-Wasserstein (BBW)
Electroweak Symmetry
Quantum Electrodynamics (QED)
Gale-Shapley Algorithm
Math-To-Manim的简介
2025年1月20日,Math-To-Manim项目利用DeepSeek AI模型,通过模型优化和训练,一键生成数学动画(使用Manim库)。该项目包含各种复杂数学概念的动画可视化示例,旨在自动绘制超越大多数人可视化能力的复杂数学和物理概念之间的联系,并以一键式动画呈现。
总而言之,Math-To-Manim是一个利用AI自动生成数学动画的创新项目,它结合了提示工程、模型微调和Manim库,为数学和物理概念的可视化提供了一种新的途径。 项目文档全面,代码示例丰富,方便用户学习和使用。
GitHub地址:GitHub - HarleyCoops/Math-To-Manim
1、特点

LaTeX锚定:这是基本的提示工程技术,使代码准确率提高了62%。
双流输出:同时生成动画代码和学习笔记。
错误恢复能力:通过模型自省自动更正了38%的Manim代码错误。
实时推理显示:聊天界面实时显示AI的推理过程,包括模型的思维链和最终答案。
LaTeX到Manim桥接:基于正则表达式的数学表达式清理。
动画验证:自动化的场景图分析预渲染。
文档引擎:Markdown/LaTeX双输出系统。
2、一个空间推理测试—考察不同大型语言模型如何解释和可视化空间关系
一个空间推理测试,旨在考察不同大型语言模型如何解释和可视化空间关系。测试的挑战是:将二维图像映射到旋转的三维空间中,其基础原理是“所有方程都是形状,所有形状都是方程”,没有任何其他上下文信息。测试中,DeepSeek和OpenAI Pro这两个模型都接受了这一挑战。它们的处理方法和结果揭示了其推理过程的有趣差异:
DeepSeek 的方法:DeepSeek 采取了一种循序渐进、分层构建的方法。
OpenAI Pro 的方法:OpenAI Pro 尝试以类似的系统性方式推理空间关系。

虽然两个模型都产生了有趣但技术上不正确的解释,但关键发现不在于它们的准确性,而在于它们的方法。DeepSeek 采取了分层构建的方法,而 OpenAI Pro 则尝试直接推理空间关系。
这个实验是更广泛研究的一部分,该研究致力于解决来自“人类的最后考试”(HLE)库中的数学和空间推理问题。 从中获得的关键见解是:提示工程的精细程度再次变得至关重要——当提供详细的上下文信息时,DeepSeek 特别是在其可视化能力方面展现出显著的改进。 这暗示了高质量提示在引导大型语言模型进行复杂空间推理中的关键作用。

3、DeepSeek R1-Zero的简介:处理更长的上下文窗口+改进注意力机制
DeepSeek R1-Zero是一个定制的、指令微调的LLM,旨在处理高级推理和知识补全任务。虽然它在概念上受到了谷歌T5框架的启发,但在架构上进行了大量修改,使其能够处理更长的上下文窗口、改进注意力机制,并在零样本和少样本范式中展现出强大的性能。其核心目标是提供一个单一的、通用的编码器-解码器模型,能够处理复杂阅读理解(最多8192个token)、基于场景的指令遵循(例如,“给定一组约束条件,制定一个简短的计划”)以及技术和编码任务(包括代码生成、转换和调试辅助)。虽然R1-Zero是T5的“后代”,但在注意力机制、上下文管理和参数初始化方面的修改使其与传统的T5实现有显著区别。
总而言之,DeepSeek R1-Zero是一个功能强大且具有创新性的LLM,但仍有改进空间。其长上下文处理能力、指令遵循能力和多位量化能力使其在处理复杂任务方面具有显著优势。 未来的研究方向将致力于解决其局限性,并进一步提升其性能和可解释性。
(1)、核心思想:迁移学习+指令微调+长上下文神经架构
DeepSeek R1-Zero的核心思想是通过结合迁移学习、指令微调和长上下文神经架构来构建一个能够处理各种复杂任务的通用大型语言模型。它试图在模型能力和效率之间取得平衡,通过改进的架构设计来提升模型在长文本处理和复杂推理任务上的性能。
(2)、理论基础:基于Transformer架构、扩展上下文窗口(分布式位置编码+基于段的注意力机制)、指令微调(精心策划的提示语料数据)、语义压缩(编码器侧)
DeepSeek R1-Zero的理论基础建立在Transformer模型的“注意力机制”之上,并在此基础上进行了扩展和改进:
>> 扩展的上下文窗口:通过采用分布式位置编码和基于段的注意力机制,R1-Zero能够容忍长达8192个token的序列。在某些层中利用分块局部注意力来减轻内存使用的二次方缩放问题。这超越了标准Transformer模型的上下文长度限制,使其能够处理更长的文本序列,从而更好地理解上下文信息。
>> 指令微调:类似于FLAN-T5或InstructGPT等框架,R1-Zero接受了精心策划的提示(指令、问答、对话)的训练,以提高零样本和少样本性能。这种方法有助于模型产生更稳定、更上下文相关的答案,并减少“幻觉”事件。指令微调使得模型能够更好地理解和执行各种指令,从而提高其在不同任务上的泛化能力。
>> 语义压缩:编码器可以将文本片段压缩成“语义槽”,从而在解码器阶段实现更有效的交叉注意力。这在理论上是基于流形假设的,其中文本输入可以被视为位于低维流形上,因此适合压缩表示。从认知科学的角度来看,R1-Zero力求模仿分层知识同化方法,平衡短期“工作记忆”(序列token)和长期“知识表示”(模型参数)。语义压缩提高了模型的效率,减少了计算和内存的消耗。
·
(3)、模型架构:参数量(6.7B)+词汇表(32k)+基于T5架构(32个头/36层)+位置编码(绝对位置编码+针对8k token的学习型分段位置编码)+优化交叉注意力机制+8K上下文+层堆叠策略(提高多GPU环境中的吞吐量)
DeepSeek R1-Zero的架构基于修改后的T5架构(自定义配置名为deepseek_v3),主要修改如下:
>> 参数数量:约67亿个参数。
>> 编码器-解码器结构:保持了T5的文本到文本方法,但在交叉注意力块中使用了专门的门控和部分重新排序。
>> 上下文窗口:8192个token(比许多标准T5模型扩展了4倍)。
>> 层堆叠:修改允许对注意力头进行动态调度,从而在多GPU环境中提高吞吐量。
更详细的规格如下:
| 特性 | 说明 |
| 架构类型 | 修改后的T5 (自定义配置 deepseek_v3) |
| 注意力头数量 | 32个头(在较深的层中) |
| 层数 | 36个编码器块,36个解码器块 |
| 词汇量 | 32k个token (基于SentencePiece) |
| 位置编码 | 绝对位置编码 + 针对8k token的学习型分段位置编码 |
| 训练范式 | 指令微调 + 附加领域任务 |
| 精度 | FP32, FP16, 4位,8位量化 (通过BnB) |
(4)、部署细节:分片检查点+Accelerate集成+分段编码+并行交叉注意力+量化(4位/8位)
>> 分片检查点:模型被分成多个分片;每个分片在下载后都会被验证。大型分片可以被内存映射,因此系统需求还包括磁盘I/O开销。
>> Accelerate集成:通过利用Accelerate,可以将模型分片分布在多个GPU上,或者如果GPU内存不足,则执行CPU卸载。
>> 旋转和分段编码:在较长的序列长度下,标准的绝对位置可能会降低性能。R1-Zero的混合方法(受T5、LongT5和RoFormer的启发)有助于即使在8k个token时也能保持稳定的梯度。
>> 并行交叉注意力:解码器在某些层中采用专门的并行交叉注意力机制,这可以减少多GPU设置中的开销。
>> 量化:支持4位和8位量化以减少内存占用。4位量化可将VRAM使用量降至约8GB,但可能导致精度略微下降;8位量化可将VRAM使用量降至约14GB,精度损失更小。
(5)、性能基准:与GPT-3.5接近
DeepSeek R1-Zero在标准生成基准测试中的性能通常与GPT-3.5接近:
>> 推理延迟:4位量化:每个token约100-200毫秒(取决于GPU);FP16:每个token约200-400毫秒;FP32:每个token约400-800毫秒。
>> 质量指标:
BLEU和ROUGE:在摘要任务(CNN/DailyMail)上,R1-Zero的得分比GPT-3.5低约1-2分;
开放域问答:在NaturalQuestions上,当正确指导时,R1-Zero与强大的基线(例如T5-XXL)非常接近。
需要注意的是,硬件设置和并行化策略会显著影响这些基准测试结果。
(6)、潜在限制(上下文有限+存在训练偏差+可解释性),未来发展(集成高级内存系统+整合flash attention+优化RAG)
尽管R1-Zero具有诸多优势,但仍然存在一些局限性:
>> token上下文限制:8192个token虽然很高,但在某些极端情况下(例如,在大型文档中进行全文搜索),可能需要桥接或分块处理。
>> 训练偏差:虽然指令微调减少了幻觉,但领域差距仍然存在。对于高度专业化或新兴的知识,模型可能会产生不确定或过时的信息。
>> 可解释性:像所有基于Transformer的LLM一样,R1-Zero的功能如同“黑盒”。高级的可解释性工具仍然是一个活跃的研究领域。
未来的发展方向包括:
>> 集成高级内存系统以处理超过8k个token的提示。
>> 整合flash attention以进一步提高速度。
>> 研究检索增强生成模块以减少对过时知识的依赖。
Math-To-Manim的安装和使用方法
1、安装
克隆和设置
git clone https://github.com/HarleyCoops/Math-To-Manim
cd Math-To-Manim环境设置
创建.env文件并配置DeepSeek API密钥:
echo "DEEPSEEK_API_KEY=your_key_here" > .env安装依赖项
pip install -r requirements.txt # 或者使用 pip install -r requirements.txt --no-cache-dir 加速安装安装FFmpeg (根据操作系统选择合适的命令)
Windows:下载并安装FFmpeg,并将其添加到系统PATH环境变量中,或者使用 choco install ffmpeg。
Linux:sudo apt-get install ffmpeg
macOS:brew install ffmpeg
启动界面
python app.py渲染选项
质量设置:-ql (480p), -qm (720p), -qh (1080p), -qk (4K)
附加标志:-p (预览动画), -f (显示输出文件), --format gif (导出为GIF)
输出位置:media/videos/[SceneName]/[quality]/[SceneName].[format]
自定义输出目录:使用 manim cfg write -l
2、开发技巧
快速开发:python -m manim -pql YourScene.py YourSceneName
最终渲染:python -m manim -qh YourScene.py YourSceneName
调试辅助:在.env文件中设置LOG_LEVEL=DEBUG以获取详细的生成日志
Math-To-Manim的案例应用
1、动画示例
项目还包含一个空间推理测试,比较了DeepSeek和OpenAI Pro模型在将2D图像映射到旋转3D空间方面的能力。
Benamou-Brenier-Wasserstein (BBW)
该动画演示了最优传输的概念,包含详细的文档(Benamou-Brenier-Wasserstein.md 和 Benamou-Brenier-Wasserstein.tex),以及预渲染的场景指南PDF。渲染命令:python -m manim -qh CosmicProbabilityScene.py CosmicProbabilityScene
Electroweak Symmetry
该动画演示了电弱对称性。文档:ElectroweakMeaning.md。渲染命令:python -m manim -qh ElectroweakSymmetryScene.py ElectroweakSymmetryScene
Quantum Electrodynamics (QED)
该动画演示了量子电动力学。源文件:QED.py, Verbose_QED.py。渲染命令:python -m manim -qh QED.py QEDScene
Gale-Shapley Algorithm
该动画演示了Gale-Shapley算法(稳定匹配算法)。文档位于/docs目录。渲染命令:python -m manim -qh gale-shaply.py GaleShapleyVisualization
相关文章:
LLMs之DeepSeek:Math-To-Manim的简介(包括DeepSeek R1-Zero的详解)、安装和使用方法、案例应用之详细攻略
LLMs之DeepSeek:Math-To-Manim的简介(包括DeepSeek R1-Zero的详解)、安装和使用方法、案例应用之详细攻略 目录 Math-To-Manim的简介 1、特点 2、一个空间推理测试—考察不同大型语言模型如何解释和可视化空间关系 3、DeepSeek R1-Zero的简介:处理更…...

在C语言中使用条件变量实现线程同步
互斥量、原子操作都是实现线程同步的方法,今日介绍使用条件变量来实现线程同步。在多线程应用中,当某个线程的执行依赖于另一个线程对数据的处理时,这个线程可能没有被阻塞,只是不断地检查某个条件是否成立了(这个条件…...

图书管理系统 Axios 源码__新增图书
目录 功能介绍 核心代码解析 源码:新增图书功能 总结 本项目基于 HTML、Bootstrap、JavaScript 和 Axios 开发,实现了图书的增删改查功能。以下是新增图书的功能实现,适合前端开发学习和项目实践。 功能介绍 用户可以通过 模态框…...

Maven全解析:从基础到精通的实战指南
概念: Maven 是跨平台的项目管理工具。主要服务基于 Java 平台的构建,依赖管理和项目信息管理项目构建:高度自动化,跨平台,可重用的组件,标准化的流程 依赖管理: 对第三方依赖包的管理…...

数据密码解锁之DeepSeek 和其他 AI 大模型对比的神秘面纱
本篇将揭露DeepSeek 和其他 AI 大模型差异所在。 目录 编辑 一本篇背景: 二性能对比: 2.1训练效率: 2.2推理速度: 三语言理解与生成能力对比: 3.1语言理解: 3.2语言生成: 四本篇小结…...

python算法和数据结构刷题[5]:动态规划
动态规划(Dynamic Programming, DP)是一种算法思想,用于解决具有最优子结构的问题。它通过将大问题分解为小问题,并找到这些小问题的最优解,从而得到整个问题的最优解。动态规划与分治法相似,但区别在于动态…...

Ollama+OpenWebUI部署本地大模型
OllamaOpenWebUI部署本地大模型 前言 Ollama是一个强大且易于使用的本地大模型推理框架,它专注于简化和优化大型语言模型(LLMs)在本地环境中的部署、管理和推理工作流。可以将Ollama理解为一个大模型推理框架的后端服务。 Ollama Ollama安…...
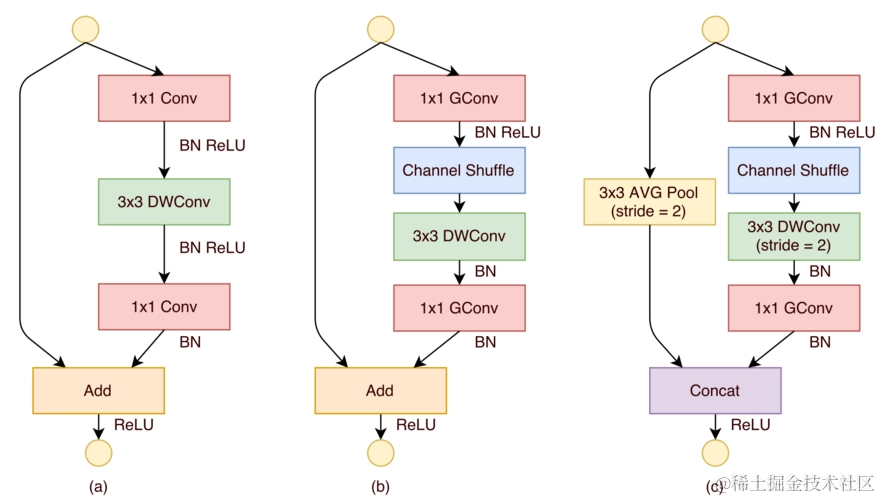
Python从0到100(八十六):神经网络-ShuffleNet通道混合轻量级网络的深入介绍
前言: 零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Pyth…...

【网络】传输层协议TCP(重点)
文章目录 1. TCP协议段格式2. 详解TCP2.1 4位首部长度2.2 32位序号与32位确认序号(确认应答机制)2.3 超时重传机制2.4 连接管理机制(3次握手、4次挥手 3个标志位)2.5 16位窗口大小(流量控制)2.6 滑动窗口2.7 3个标志位 16位紧急…...

海思ISP开发说明
1、概述 ISP(Image Signal Processor)图像信号处理器是专门用于处理图像信号的硬件或处理单元,广泛应用于图像传感器(如 CMOS 或 CCD 传感器)与显示设备之间的信号转换过程中。ISP通过一系列数字图像处理算法完成对数字…...

实验十 Servlet(一)
实验十 Servlet(一) 【实验目的】 1.了解Servlet运行原理 2.掌握Servlet实现方式 【实验内容】 1、参考课堂例子,客户端通过login.jsp发出登录请求,请求提交到loginServlet处理。如果用户名和密码相同则视为登录成功,…...

doris:聚合模型的导入更新
这篇文档主要介绍 Doris 聚合模型上基于导入的更新。 整行更新 使用 Doris 支持的 Stream Load,Broker Load,Routine Load,Insert Into 等导入方式,往聚合模型(Agg 模型)中进行数据导入时,都…...

Java NIO_非阻塞I/O的实现与优化
1. 引言 1.1 背景介绍 随着互联网应用的快速发展,传统的阻塞I/O模型已经无法满足高并发、高性能的需求。Java NIO(Non-blocking I/O)提供了高效的非阻塞I/O操作,使得开发者能够构建高性能的网络应用和文件处理系统。 1.2 Java NIO的重要性 Java NIO通过非阻塞I/O和多路…...

代码随想录算法训练营Day51 | 101.孤岛的总面积、102.沉没孤岛、103.水流问题、104.建造最大岛屿
文章目录 101.孤岛的总面积思路与重点 102.沉没孤岛思路与重点 103.水流问题思路与重点 104.建造最大岛屿思路与重点 101.孤岛的总面积 题目链接:101.孤岛的总面积讲解链接:代码随想录状态:直接看题解了。 思路与重点 nextx或者nexty越界了…...
Games202Lecture 6 Real-time Environment Mapping
RTRT RTRT(real time ray tracing): path tracingdenoising PRT PRT (Precomputed radiance transfer):离线预计算,运行时快速内积。 预计算(Offline Precomputation): 传输函数(Transfer Function&…...

在 Zemax 中使用布尔对象创建光学光圈
在 Zemax 中,布尔对象用于通过组合或减去较简单的几何形状来创建复杂形状。布尔运算涉及使用集合运算(如并集、交集和减集)来组合或修改对象的几何形状。这允许用户在其设计中为光学元件或机械部件创建更复杂和定制的形状。 本视频中…...
)
MySQL知识点总结(十八)
说明你对InnoDB集群的整体认知。 MySQL组复制技术是InnoDB集群实现的基础,组复制安装在集群中的每个服务器实例上。组复制能够创建弹性复制拓扑,在集群中的服务器脱机时可以自动重新配置自己。必须至少有三台服务器才能组成一个可以提供高可用性的组。组…...

[论文总结] 深度学习在农业领域应用论文笔记14
当下,深度学习在农业领域的研究热度持续攀升,相关论文发表量呈现出迅猛增长的态势。但繁荣背后,质量却不尽人意。相当一部分论文内容空洞无物,缺乏能够落地转化的实际价值,“凑数” 的痕迹十分明显。在农业信息化领域的…...

MySQL和Redis的区别
MySQL和Redis都是流行的数据存储解决方案,但它们在设计、用途和特性上有显著区别。理解这些区别有助于选择合适的数据库来满足不同的应用需求。本文将详细介绍MySQL和Redis的区别,包括它们的架构、使用场景、性能和其他关键特性。 一、基本概述 MySQL&…...

Rust 中的注释使用指南
Rust 中的注释使用指南 注释是代码中不可或缺的一部分,它帮助开发者理解代码的逻辑和意图。Rust 提供了多种注释方式,包括行注释、块注释和文档注释。本文将详细介绍这些注释的使用方法,并通过一个示例展示如何在实际代码中应用注释。 1. 行…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

C++ 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...