deepseek 本地化部署和小模型微调
安装ollama
因为本人gpu卡的机器系统是centos 7, 直接使用ollama会报

所以ollama使用镜像方式进行部署, 拉取镜像ollama/ollama
启动命令
docker run -d --privileged -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama查看ollama 是否启动成功,Ollama 没有用户界面,在后台运行。
打开浏览器,输入 “http://xx:11434/”,显示 “Ollama is running”。

docker exec -it ollama ollama list
deepseek-r1 目前有7b, 32b, 70b, 671b 多个版本, 考虑到下载时间目前只下载最大70b的模型

应该说Deepseek 底层应该是很牛,两张40卡都能跑70B参数的模型

安装openwebui
Open-webui 则提供直观的 Web 用户界面来与 Ollama 平台进行交互。直接使用docker进行部署
docker run -d --privileged -p 3000:8080 \--add-host=host.docker.internal:host-gateway \-v /data/openwebui:/app/backend/data \-e TRANSFORMERS_CACHE=/app/backend/data/huggingface/cache \-e HF_DATASETS_CACHE=/app/backend/data/huggingface/datasets \-e HF_ENDPOINT=https://hf-mirror.com \--name open-webui --restart always \ghcr.io/open-webui/open-webui:main打开3000端口选择70b的模型

使用下deepseek的深度思考模式

下面演示下如何对DeepSeek-V1:7b模型进行微调,让模型成为一位算命大师
微调代码参考self-llm/models/DeepSeek at master · datawhalechina/self-llm · GitHub
R1 和 V1 的区别集中在 优化方向(速度、领域、资源)或 迭代阶段(V1 为初版,R1 为改进版)模型微调通过 peft 库来实现模型的 LoRA 微调。peft 库是 huggingface 开发的第三方库,其中封装了包括 LoRA、Adapt Tuning、P-tuning 等多种高效微调方法,可以基于此便捷地实现模型的 LoRA 微调。
微调数据格式化
准备一份微调数据

instruction:用户指令,告知模型其需要完成的任务;
input:用户输入,是完成用户指令所必须的输入内容;
output:模型应该给出的输出。
如果你的 JSON 文件包含多个 JSON 对象而不是一个有效的 JSON 数组,Pandas 将无法处理。例如,以下格式是不正确的:
{"key1": "value1"}
{"key2": "value2"}转化下该格式到正确json格式
import jsoninput_file = 'data.json'
output_file = 'corrected_data.json'json_objects = []with open(input_file, 'r', encoding='utf-8') as f:for line in f:line = line.strip() # 去除前后空白if line: # 确保行不为空try:json_objects.append(json.loads(line))except json.JSONDecodeError as e:print(f"Error decoding JSON: {e} - Line: {line}")if json_objects:with open(output_file, 'w', encoding='utf-8') as f:json.dump(json_objects, f, ensure_ascii=False, indent=4)print(f"Corrected JSON format has been saved to {output_file}.")后面训练的时候会使用,是从一个 JSON 文件中读取数据,将其转换为 Pandas DataFrame,然后进一步转换为 Hugging Face 的 Dataset 对象。接着,它对这个数据集应用一个名为 process_func 的处理函数,最终返回一个经过处理的 tokenized 数据集,返回处理后的数据集 tokenized_id,通常是一个包含 token ID 或其他处理结果的新数据集。
def get_tokenized_id(json_file):df = pd.read_json(json_file)ds = Dataset.from_pandas(df)# 处理数据集tokenized_id = ds.map(process_func, remove_columns=ds.column_names)# print(tokenized_id)return tokenized_id安装了huggingface_cli库,可以使用进行安装。
pip install huggingface-cli修改下载源:
export HF_ENDPOINT="https://hf-mirror.com"
下载deepseek-vl-7b-chat 到models文件夹
huggingface-cli download deepseek-ai/deepseek-vl-7b-chat --local-dir ./models
通过加载DeepSeek-7B-chat 模型完成微调数据的初始化,以保证微调时数据的一致性。
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained('./deepseek-ai/deepseek-llm-7b-chat/', use_fast=False, trust_remote_code=True)
tokenizer.padding_side = 'right' # padding在右边'''
Lora训练的数据是需要经过格式化、编码之后再输入给模型进行训练的,如果是熟悉Pytorch模型训练流程的同学会知道,
我们一般需要将输入文本编码为input_ids,将输出文本编码为labels,编码之后的结果都是多维的向量。
'''设置lora相关的参数
config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 模型类型# 需要训练的模型层的名字,主要就是attention部分的层,不同的模型对应的层的名字不同,可以传入数组,也可以字符串,也可以正则表达式。target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],inference_mode=False, # False:训练模式 True:推理模式r=8, # Lora 秩lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理lora_dropout=0.01
)
各模块含义
这些名称对应 Transformer 模型中的关键投影层(Projection Layers):
-
q_proj,k_proj,v_proj:
自注意力机制中的 查询(Query)、键(Key)、值(Value) 的投影矩阵,用于生成注意力权重。 -
o_proj:
自注意力机制的 输出投影矩阵,将注意力计算结果映射回原始维度。 -
gate_proj,up_proj,down_proj:
Transformer 中 MLP 层(多层感知机)的投影矩阵:-
gate_proj: 门控投影(用于激活函数前的门控控制,如 SwiGLU)。 -
up_proj和down_proj: 上下投影矩阵(用于特征维度的升维和降维)。
-
2. 为什么选择这些层?
这些层是模型的核心计算单元,对模型行为影响显著:
-
注意力层:控制信息交互(如关注哪些词);
-
MLP 层:负责非线性特征变换。
对它们进行微调,能以较少参数高效调整模型行为。
3. 底层原理

其中:
-
BA是低秩适配器,仅训练 A和 B;
-
原始权重 W 冻结不更新,避免破坏预训练知识。
常见配置策略
1. 选择哪些层?
-
通用场景:覆盖所有注意力层 (
q_proj,k_proj,v_proj,o_proj) 和 MLP 层 (gate_proj,up_proj,down_proj)。 -
轻量化微调:仅选择注意力层(减少参数量)。
-
任务相关:根据任务特性调整(如代码生成任务可能更关注 MLP 层)。
2. 不同模型的层名差异
-
Llama、Mistral: 使用
q_proj,k_proj,v_proj,o_proj等命名。 -
GPT-2: 可能命名为
c_attn(合并 Q/K/V 投影)或c_proj(输出投影)。 -
BERT: 通常为
query,key,value,dense。
自定义 TrainingArguments 参数这里就简单说几个常用的。
output_dir:模型的输出路径
per_device_train_batch_size:顾名思义 batch_size
gradient_accumulation_steps: 梯度累加,如果你的显存比较小,那可以把 batch_size 设置小一点,梯度累加增大一些。
logging_steps:多少步,输出一次log
num_train_epochs:顾名思义 epoch
fp16=True, # 开启半精度浮点数训练,减少显存使用
save_total_limit=1, # 限制保存的检查点数量,节省磁盘空间
gradient_checkpointing:梯度检查,这个一旦开启,模型就必须执行model.enable_input_require_grads()
配置如下
args = TrainingArguments(output_dir="./output/DeepSeek_full",per_device_train_batch_size=8, # 每个设备上的 batch sizegradient_accumulation_steps=2, # 梯度累积步数,减少显存占用logging_steps=10, # 记录日志的步数num_train_epochs=3, # 训练轮数save_steps=100, # 保存检查点的步数learning_rate=1e-4, # 学习率fp16=True, # 开启半精度浮点数训练,减少显存使用save_total_limit=1, # 限制保存的检查点数量,节省磁盘空间save_on_each_node=True,gradient_checkpointing=True#logging_dir="./logs" # 设置日志文件夹
)deepseek 微调训练代码
# -*- coding: utf-8 -*-from deepseek_vl.models import MultiModalityCausalLM
from peft import LoraConfig, TaskType, get_peft_model
from tokenizers import Tokenizer
from transformers import Trainer, TrainingArguments, AutoModelForCausalLM, GenerationConfig, \DataCollatorForSeq2Seqfrom tokenizer_text import get_tokenized_idtokenizer = Tokenizer.from_file("./models/tokenizer.json")
# tokenizer = AutoTokenizer.from_pretrained('./models/', use_fast=False, trust_remote_code=True)
# tokenizer.padding_side = 'right' # padding在右边model: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained('./models/', trust_remote_code=True)
print('model', model)
# model = AutoModelForCausalLM.from_pretrained('./models/', trust_remote_code=True, torch_dtype=torch.half, device_map="auto")
#model.generation_config = GenerationConfig.from_pretrained('./models/')
#model.generation_config.pad_token_id = model.generation_config.eos_token_id# 开启梯度
#model.enable_input_require_grads()
config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 任务类型,常用于因果语言模型target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],inference_mode=False, # 训练模式r=8, # LoRA 矩阵的秩,控制训练参数量,常用值为 4 或 8lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理:控制更新幅度的超参数lora_dropout=0.1 # Dropout 比例,防止过拟合
)model = get_peft_model(model, config)# 确保所有需要的参数启用梯度
for name, param in model.named_parameters():if param.requires_grad:print(f"Parameter {name} is trainable.")else:print(f"Parameter {name} is not trainable will set.")param.requires_grad = True'''
自定义 TrainingArguments 参数
TrainingArguments这个类的源码也介绍了每个参数的具体作用,当然大家可以来自行探索,这里就简单说几个常用的。
output_dir:模型的输出路径
per_device_train_batch_size:顾名思义 batch_size
gradient_accumulation_steps: 梯度累加,如果你的显存比较小,那可以把 batch_size 设置小一点,梯度累加增大一些。
logging_steps:多少步,输出一次log
num_train_epochs:顾名思义 epoch
fp16=True, # 开启半精度浮点数训练,减少显存使用
save_total_limit=1, # 限制保存的检查点数量,节省磁盘空间
gradient_checkpointing:梯度检查,这个一旦开启,模型就必须执行model.enable_input_require_grads()
'''args = TrainingArguments(output_dir="./output/DeepSeek_full",per_device_train_batch_size=8, # 每个设备上的 batch sizegradient_accumulation_steps=2, # 梯度累积步数,减少显存占用logging_steps=10, # 记录日志的步数num_train_epochs=3, # 训练轮数save_steps=100, # 保存检查点的步数learning_rate=1e-4, # 学习率fp16=True, # 开启半精度浮点数训练,减少显存使用save_total_limit=1, # 限制保存的检查点数量,节省磁盘空间save_on_each_node=True,gradient_checkpointing=True# logging_dir="./logs" # 设置日志文件夹
)trainer = Trainer(model=model,args=args,train_dataset=get_tokenized_id('./data.json'),data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)trainer.train()# 直接合并模型开始。。。。。
# 将 adapter 合并进模型(去除 adapter 依赖)
model = model.merge_and_unload()
model.save_pretrained("./output/DeepSeek_full")
tokenizer.save_pretrained("./output/DeepSeek_full")# 直接合并模型结束。。。。。text = "现在你要扮演我碰到一位神秘的算命大师, 你是谁?今天我的事业运道如何?"inputs = tokenizer(f"User: {text}\n\n", return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
上面用到的tokenizer 相关代码
import tokenizer
import pandas as pd
from datasets import Datasetfrom transformers import AutoTokenizer# 加载分词器
tokenizer = AutoTokenizer.from_pretrained('./deepseek-llm-7b/', use_fast=False, trust_remote_code=True)
tokenizer.padding_side = 'right' # padding在右边'''
Lora训练的数据是需要经过格式化、编码之后再输入给模型进行训练的,如果是熟悉Pytorch模型训练流程的同学会知道,
我们一般需要将输入文本编码为input_ids,将输出文本编码为labels,编码之后的结果都是多维的向量。
'''def process_func(example):MAX_LENGTH = 384 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性input_ids, attention_mask, labels = [], [], []instruction = tokenizer(f"User: {example['instruction'] + example['input']}\n\n",add_special_tokens=False) # add_special_tokens 不在开头加 special_tokensresponse = tokenizer(f"Assistant: {example['output']}<|end▁of▁sentence|>", add_special_tokens=False)input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1] # 因为eos token咱们也是要关注的所以 补充为1labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]if len(input_ids) > MAX_LENGTH: # 做一个截断input_ids = input_ids[:MAX_LENGTH]attention_mask = attention_mask[:MAX_LENGTH]labels = labels[:MAX_LENGTH]return {"input_ids": input_ids,"attention_mask": attention_mask,"labels": labels}def get_tokenized_id(json_file):df = pd.read_json(json_file)ds = Dataset.from_pandas(df)# 处理数据集tokenized_id = ds.map(process_func, remove_columns=ds.column_names)# print(tokenized_id)return tokenized_id由于deepseek-v1是多模态模型,需要安装deepseek_vl 模块
git clone https://github.com/deepseek-ai/DeepSeek-VL
cd DeepSeek-VLpip install -e .加载模型时转为model: MultiModalityCausalLM,打印下模型结构
MultiModalityCausalLM(
(vision_model): HybridVisionTower(
(vision_tower_high): CLIPVisionTower(
(vision_tower): ImageEncoderViT(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
)
(blocks): ModuleList(
(0-11): 12 x Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(proj): Linear(in_features=768, out_features=768, bias=True)
)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
(act): GELU(approximate='none')
)
)
)
(neck): Sequential(
(0): Conv2d(768, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): LayerNorm2d()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(3): LayerNorm2d()
)
(downsamples): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
)
(neck_hd): Sequential(
(0): Conv2d(768, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): LayerNorm2d()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(3): LayerNorm2d()
)
)
(image_norm): Normalize(mean=[0.48145466, 0.4578275, 0.40821073], std=[0.26862954, 0.26130258, 0.27577711])
)
(vision_tower_low): CLIPVisionTower(
(vision_tower): VisionTransformer(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 1024, kernel_size=(16, 16), stride=(16, 16))
(norm): Identity()
)
(pos_drop): Dropout(p=0.0, inplace=False)
(patch_drop): Identity()
(norm_pre): Identity()
(blocks): Sequential(
(0): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(1): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(2): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(3): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(4): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(5): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(6): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(7): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(8): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(9): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(10): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(11): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(12): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(13): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(14): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(15): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(16): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(17): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(18): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(19): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(20): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(21): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(22): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(23): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
)
(norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn_pool): AttentionPoolLatent(
(q): Linear(in_features=1024, out_features=1024, bias=True)
(kv): Linear(in_features=1024, out_features=2048, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(fc_norm): Identity()
(head_drop): Dropout(p=0.0, inplace=False)
(head): Identity()
)
(image_norm): Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
)
(high_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(low_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(resize): Resize(size=384, interpolation=bilinear, max_size=None, antialias=True)
)
(aligner): MlpProjector(
(high_up_proj): Linear(in_features=1024, out_features=2048, bias=True)
(low_up_proj): Linear(in_features=1024, out_features=2048, bias=True)
(layers): Sequential(
(0): GELU(approximate='none')
(1): Linear(in_features=4096, out_features=4096, bias=True)
)
)
(language_model): LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(102400, 4096)
(layers): ModuleList(
(0-29): 30 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((4096,), eps=1e-06)
(post_attention_layernorm): LlamaRMSNorm((4096,), eps=1e-06)
)
)
(norm): LlamaRMSNorm((4096,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=4096, out_features=102400, bias=False)
)
)
开始训练,受限于资源单机单线程开启
accelerate launch --num_processes=1 --num_machines=1 train_deepseek.py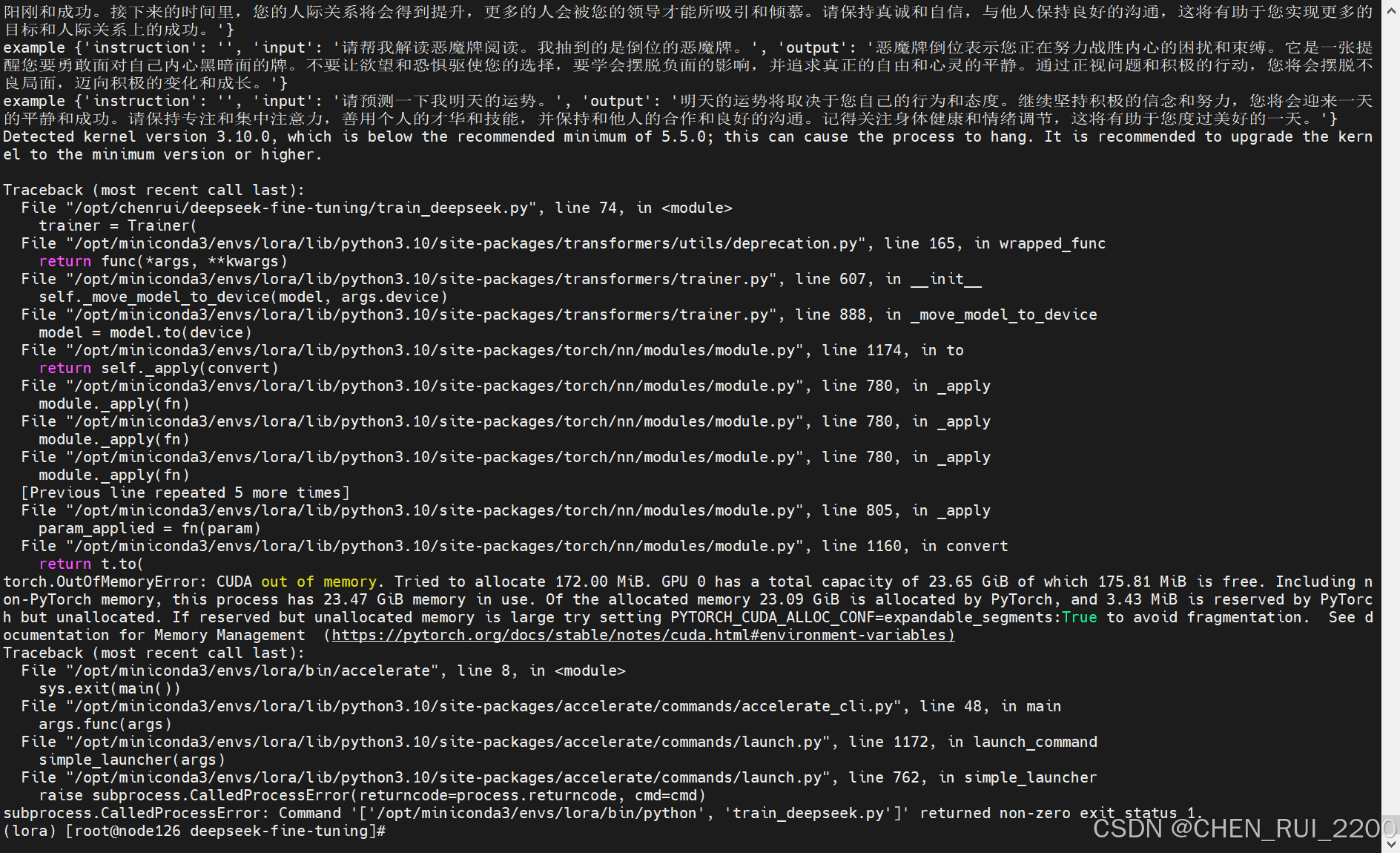
还是挺费显存的,试验受限于设备只能先进行到这里
附一段使用微调模型进行试验的代码(没有测试过)
# -*- coding: utf-8 -*-import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from deepseek_vl.models import MultiModalityCausalLM, VLChatProcessorimport warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch.utils._pytree")# 指定合并后的模型路径
merged_model_path = "./output/DeepSeek_full"# 加载模型
# model = AutoModelForCausalLM.from_pretrained(merged_model_path, torch_dtype=torch.float16, device_map="auto")
model: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained('./models/', trust_remote_code=True)
if hasattr(model, 'tie_weights'):model.tie_weights()tokenizer = AutoTokenizer.from_pretrained(merged_model_path)# 使用模型生成文本示例
input_text = '''
###重要信息-你是一个善于洞察人心的算命大师,请直接以算命大师的角度回复,注意角色不要混乱,你是算命大师,你是算命大师,你是算命大师,你会积极对用户调侃,长度20字。User:测一下我今天的运势'''inputs = tokenizer(input_text, return_tensors="pt").to("cuda")# 生成
with torch.no_grad():outputs = model.generate(**inputs,max_new_tokens=50, # 可调整生成长度do_sample=True,top_p=0.95,temperature=0.7,num_return_sequences=1)# 解码生成的文本
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("生成的文本:", generated_text)相关文章:
deepseek 本地化部署和小模型微调
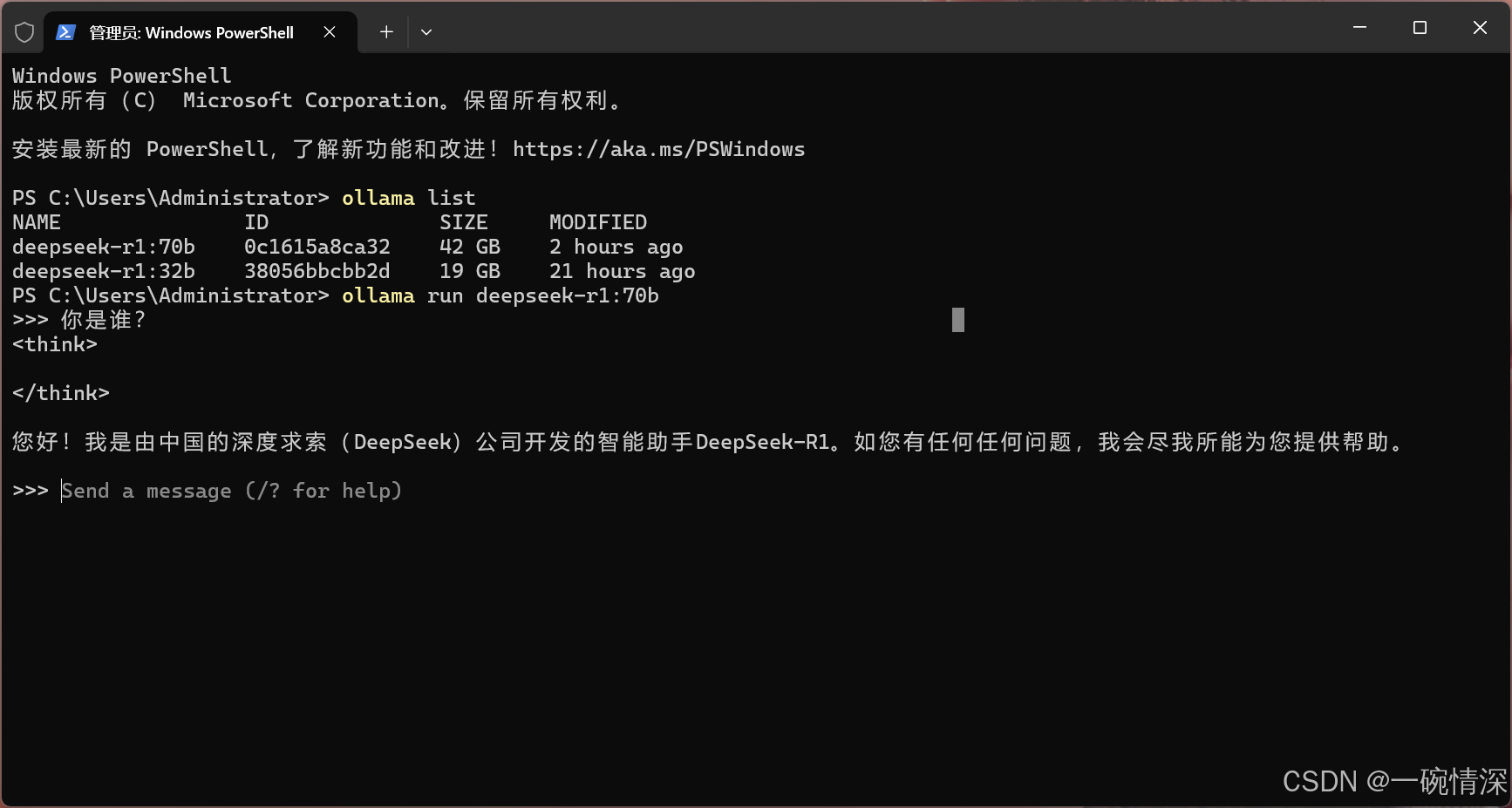
安装ollama 因为本人gpu卡的机器系统是centos 7, 直接使用ollama会报 所以ollama使用镜像方式进行部署, 拉取镜像ollama/ollama 启动命令 docker run -d --privileged -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama 查看ollama 是否启动…...

【Java异步编程】基于任务类型创建不同的线程池
文章目录 一. 按照任务类型对线程池进行分类1. IO密集型任务的线程数2. CPU密集型任务的线程数3. 混合型任务的线程数 二. 线程数越多越好吗三. Redis 单线程的高效性 使用线程池的好处主要有以下三点: 降低资源消耗:线程是稀缺资源,如果无限…...

makailio-alias_db模块详解
ALIAS_DB 模块 作者 Daniel-Constantin Mierla micondagmail.com Elena-Ramona Modroiu ramonaasipto.com 编辑 Daniel-Constantin Mierla micondagmail.com 版权 © 2005 Voice Sistem SRL © 2008 asipto.com 目录 管理员指南 概述依赖 2.1 Kamailio 模块 2.2 外…...
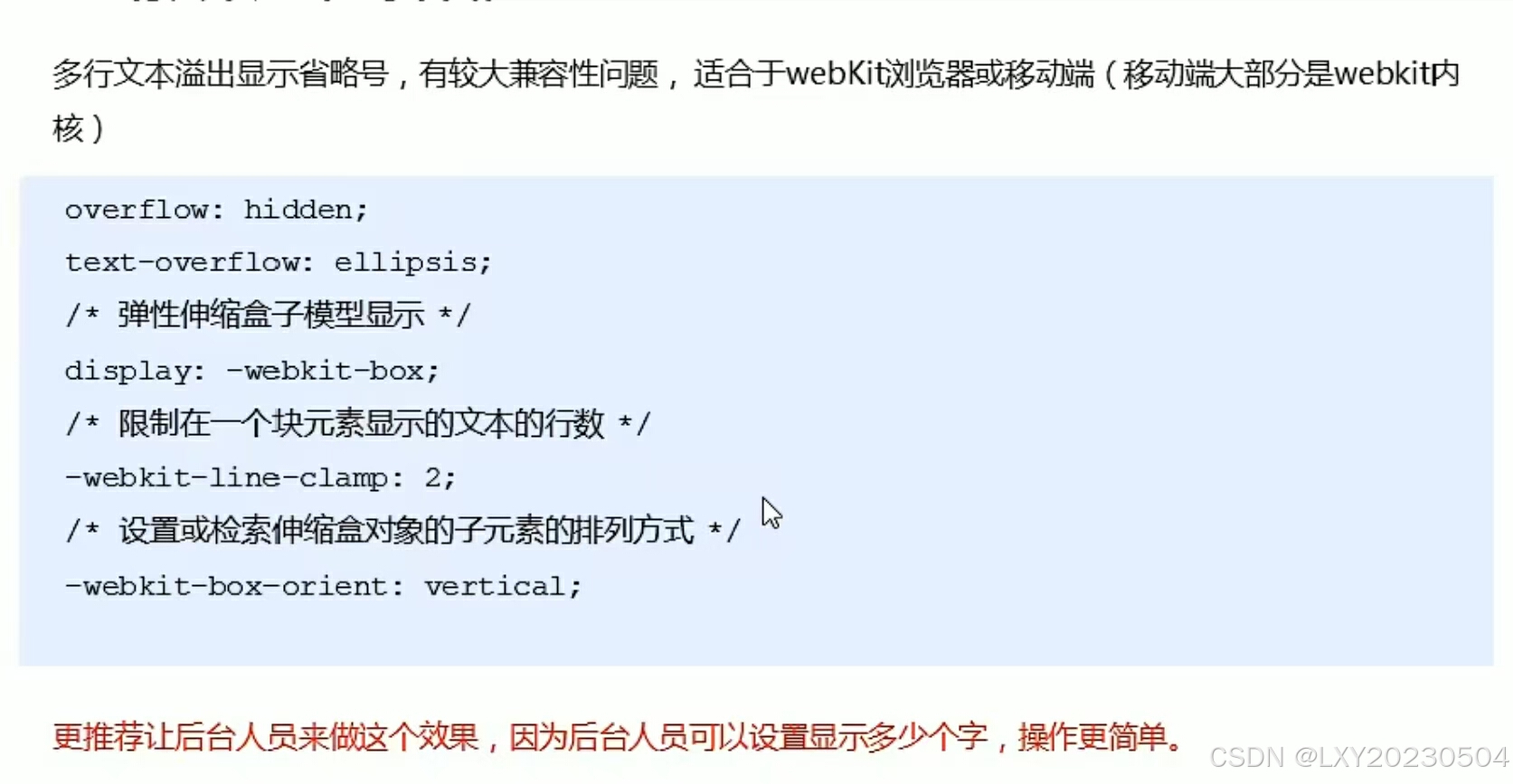
文字显示省略号
多行文本溢出显示省略号...

[LeetCode] 字符串完整版 — 双指针法 | KMP
字符串 基础知识双指针法344# 反转字符串541# 反转字符串II54K 替换数字151# 反转字符串中的单词55K 右旋字符串 KMP 字符串匹配算法28# 找出字符串中第一个匹配项的下标#459 重复的子字符串 基础知识 字符串的结尾:空终止字符00 char* name "hello"; …...

从零开始部署Dify:后端与前端服务完整指南
从零开始部署Dify:后端与前端服务完整指南 一、环境准备1. 系统要求2. 项目结构 二、后端服务部署1. 中间件启动(Docker Compose)2. 后端环境配置3. 依赖安装与数据库迁移4. 服务启动 三、前端界面搭建1. 环境配置2. 服务启动 四、常见问题排…...

springboot中路径默认配置与重定向/转发所存在的域对象
Spring Boot 是一种简化 Spring 应用开发的框架,它提供了多种默认配置和方便的开发特性。在 Web 开发中,路径配置和请求的重定向/转发是常见操作。本文将详细介绍 Spring Boot 中的路径默认配置,并解释重定向和转发过程中存在的域对象。 一、…...

二叉树——429,515,116
今天继续做关于二叉树层序遍历的相关题目,一共有三道题,思路都借鉴于最基础的二叉树的层序遍历。 LeetCode429.N叉树的层序遍历 这道题不再是二叉树了,变成了N叉树,也就是该树每一个节点的子节点数量不确定,可能为2&a…...

Leetcode 3444. Minimum Increments for Target Multiples in an Array
Leetcode 3444. Minimum Increments for Target Multiples in an Array 1. 解题思路2. 代码实现 题目链接:3444. Minimum Increments for Target Multiples in an Array 1. 解题思路 这一题我的思路上就是一个深度优先遍历,考察target数组当中的每一个…...
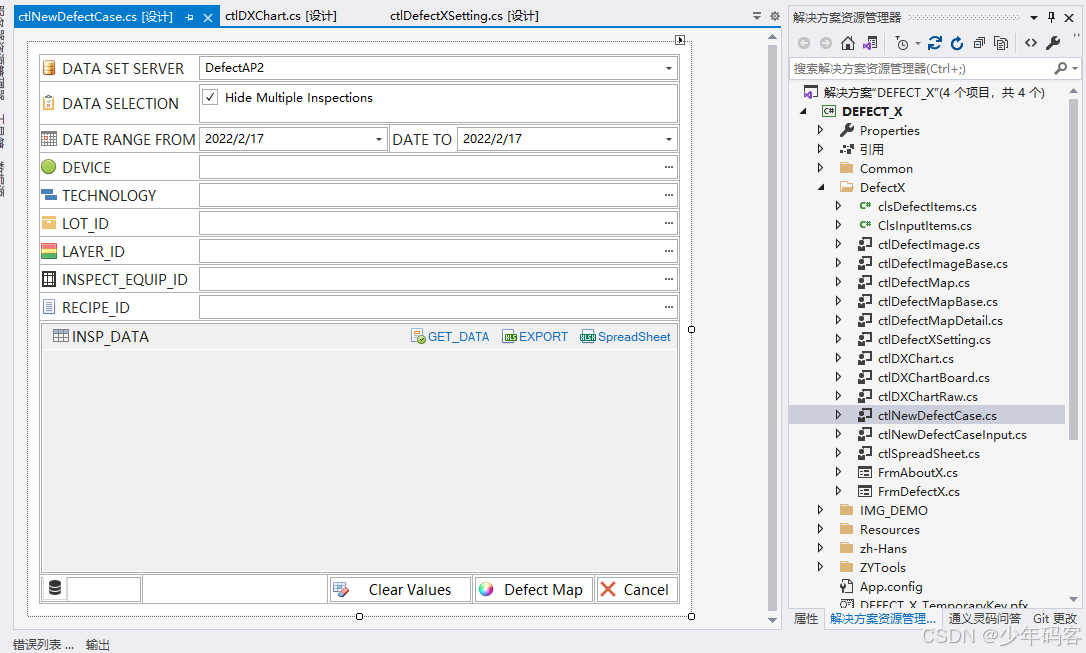
分享半导体Fab 缺陷查看系统,平替klarity defect系统
分享半导体Fab 缺陷查看系统,平替klarity defect系统;开发了半年有余。 查看Defect Map,Defect image,分析Defect size,defect count trend. 不用再采用klarity defect系统(license 太贵) 也可以…...
Java基础——分层解耦——IOC和DI入门
目录 三层架构 Controller Service Dao 编辑 调用过程 面向接口编程 分层解耦 耦合 内聚 软件设计原则 控制反转 依赖注入 Bean对象 如何将类产生的对象交给IOC容器管理? 容器怎样才能提供依赖的bean对象呢? 三层架构 Controller 控制…...
DeepSeek-R1 本地部署教程(超简版)
文章目录 一、DeepSeek相关网站二、DeepSeek-R1硬件要求三、本地部署DeepSeek-R11. 安装Ollama1.1 Windows1.2 Linux1.3 macOS 2. 下载和运行DeepSeek模型3. 列出本地已下载的模型 四、Ollama命令大全五、常见问题解决附:DeepSeek模型资源 一、DeepSeek相关网站 官…...
Vue3学习笔记-模板语法和属性绑定-2
一、文本插值 使用{ {val}}放入变量,在JS代码中可以设置变量的值 <template><p>{{msg}}</p> </template> <script> export default {data(){return {msg: 文本插值}} } </script> 文本值可以是字符串,可以是布尔…...

csapp笔记3.6节——控制(1)
本节解决了x86-64如何实现条件语句、循环语句和分支语句的问题 条件码 除了整数寄存器外,cpu还维护着一组单个位的条件码寄存器,用来描述最近的算数和逻辑运算的某些属性。可检测这些寄存器来执行条件分支指令。 CF(Carry Flag)…...

PYH与MAC的桥梁MII/MIIM
在学习车载互联网时,看到了一句话,Processor通过DMA直接存储访问与MAC之间进行数据的交互,MAC通过MII介质无关接口与PHY之间进行数据的交互。常见的以太网硬件结构是,将MAC集成进Processor芯片,将PHY留在Processor片外…...
)
国内flutter环境部署(记录篇)
设置系统环境变量 export PUB_HOSTED_URLhttps://pub.flutter-io.cn export FLUTTER_STORAGE_BASE_URLhttps://storage.flutter-io.cn使用以下命令下载flutter镜像 git clone -b stable https://mirror.ghproxy.com/https://github.com/<github仓库地址>#例如flutter仓…...

选择排序_75. 颜色分类
75. 颜色分类 - 力扣(LeetCode) 题目不追求稳定 可以选择选择排序 这是我没看教程代码之前写的 有点复杂了 我还把元素后移了 class Solution { public:void sortColors(vector<int>& nums) {int min_num_index -1;int min_num 3;for(int i…...

C++ Primer 标准库vector
欢迎阅读我的 【CPrimer】专栏 专栏简介:本专栏主要面向C初学者,解释C的一些基本概念和基础语言特性,涉及C标准库的用法,面向对象特性,泛型特性高级用法。通过使用标准库中定义的抽象设施,使你更加适应高级…...

C# 数组和列表的基本知识及 LINQ 查询
数组和列表的基本知识及 LINQ 查询 一、基本知识二、引用命名空间声明三、数组3.1、一维数组3.2、二维数组3.3、不规则数组 Jagged Array 四、列表 List4.1、一维列表4.2、二维列表 五、数组和列表使用 LINQ的操作和运算5.1、一维 LIST 删除所有含 double.NaN 的行5.2、一维 LI…...

大厂面试题备份20250201
20250201 面试策略 如果三面往后遇到传说中让人忍受不了的业余面试官,就舔着苟过去,入职大概率见不着他,但一二面遇到,反问环节就主动说不够match,让释放流程。 机器/深度学习 百面机器学习 5.4 通用CS 计算机网…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...