Java 8 Stream API
- 通过 Stream.of 方法直接传入多个元素构成一个流
String[] arr = {“a”, “b”, “c”};
Stream.of(arr).forEach(System.out::println);
Stream.of(“a”, “b”, “c”).forEach(System.out::println);
Stream.of(1, 2, “a”).map(item -> item.getClass().getName())
.forEach(System.out::println);
- 通过 Stream.iterate 方法使用迭代的方式构造一个无限流,然后使用 limit 限制流元素个数
Stream.iterate(2, item -> item * 2).limit(10).forEach(System.out::println);
Stream.iterate(BigInteger.ZERO, n -> n.add(BigInteger.TEN))
.limit(10).forEach(System.out::println);
- 通过 Stream.generate 方法从外部传入一个提供元素的 Supplier 来构造无限流,再使用 limit 限制流元素个数
Stream.generate(() -> “test”).limit(3).forEach(System.out::println);
Stream.generate(Math::random).limit(10).forEach(System.out::println);
- 通过 IntStream 或 DoubleStream 构造基本类型的流
// IntStream 和 DoubleStream
IntStream.range(1, 3).forEach(System.out::println);
IntStream.range(0, 3).mapToObj(i -> “x”).forEach(System.out::println);
IntStream.rangeClosed(1, 3).forEach(System.out::println);
DoubleStream.of(1.1, 2.2, 3.3).forEach(System.out::println);
// 使用 Random 类创建随机流
new Random()
.ints(1, 100) // IntStream
.limit(10)
.forEach(System.out::println);
// 注意基本类型流和装箱后的流的区别
Arrays.asList(“a”, “b”, “c”).stream() // Stream
.mapToInt(String::length) // IntStream
.asLongStream() // LongStream
.mapToDouble(x -> x / 10.0) // DoubleStream
.boxed() // Stream
.mapToLong(x -> 1L) // LongStream
.mapToObj(x -> “”) // Stream
.collect(Collectors.toList());
中间操作
Stream 常用 API:

以下为测试用实体类,代码省略了 getter、settter 和构造方法
订单项
public class OrderItem {
private Long productId;// 商品ID
private String productName;// 商品名称
private Double productPrice;// 商品价格
private Integer productQuantity;// 商品数量
}
订单
public class Order {
private Long id;
private Long customerId;// 顾客ID
private String customerName;// 顾客姓名
private List orderItemList;// 订单商品明细
private Double totalPrice;// 总价格
private LocalDateTime placedAt;// 下单时间
}
消费者
public class Customer {
private Long id;
private String name;// 顾客姓名
}
filter
filter 操作用作过滤,类似于 SQL 中的 where 条件,接收一个 Predicate 谓词对象作为参数,返回过滤后的流
可以连续使用 filter 进行多层过滤
// 查找最近半年的金额大于40的订单
orders.stream()
.filter(Objects::nonNull) // 过滤null值
.filter(order -> order.getPlacedAt()
.isAfter(LocalDateTime.now().minusMonths(6))) // 最近半年的订单
.filter(order -> order.getTotalPrice() > 40) // 金额大于40的订单
.forEach(System.out::println);
map
map 操作用做转换,也叫投影,类似于 SQL 中的 select
// 计算所有订单商品数量
// 1. 通过两次遍历实现
LongAdder longAdder = new LongAdder();
orders.stream().forEach(order ->
order.getOrderItemList().forEach(orderItem -> longAdder.add(orderItem.getProductQuantity())));
System.out.println("longAdder = " + longAdder);
// 2. 使用两次 mapToLong 和 sum 方法实现
long sum = orders.stream().mapToLong(
order -> order.getOrderItemList().stream()
.mapToLong(OrderItem::getProductQuantity)
.sum()
).sum();
flatMap
flatMap 是扁平化操作,即先用 map 把每个元素替换为一个流,再展开这个流
// 统计所有订单的总价格
// 1. 直接展开订单商品进行价格统计
double sum1 = orders.stream()
.flatMap(order -> order.getOrderItemList().stream())
.mapToDouble(item -> item.getProductQuantity() * item.getProductPrice())
.sum();
// 2. 另一种方式 flatMapToDouble,即 flatMap + mapToDouble,返回 DoubleStream
double sum2 = orders.stream()
.flatMapToDouble(order ->
order.getOrderItemList()
.stream().mapToDouble(item ->
item.getProductQuantity() * item.getProductPrice())
)
.sum();
sorted
sorted 是排序操作,类似 SQL 中的 order by 子句,接收一个 Comparator 作为参数,可使用 Comparator.comparing 来由大到小排列,加上 reversed 表示倒叙
// 大于 50 的订单,按照订单价格倒序前 5
orders.stream()
.filter(order -> order.getTotalPrice() > 50)
.sorted(Comparator.comparing(Order::getTotalPrice).reversed())
.limit(5)
.forEach(System.out::println);
skip & limit
skip 用于跳过流中的项,limit 用于限制项的个数
// 按照下单时间排序,查询前 2 个订单的顾客姓名
orders.stream()
.sorted(Comparator.comparing(Order::getPlacedAt))
.map(order -> order.getCustomerName())
.limit(2)
.forEach(System.out::println);
// 按照下单时间排序,查询第 3 和第 4 个订单的顾客姓名
orders.stream()
.sorted(Comparator.comparing(Order::getPlacedAt))
.map(order -> order.getCustomerName())
.skip(2).limit(2)
.forEach(System.out::println);
distinct
distinct 操作的作用是去重,类似 SQL 中的 distinct
// 去重的下单用户
orders.stream()
.map(Order::getCustomerName)
.distinct()
.forEach(System.out::println);
// 所有购买过的商品
orders.stream()
.flatMap(order -> order.getOrderItemList().stream())
.map(OrderItem::getProductName)
.distinct()
.forEach(System.out::println);
终结操作
forEach
上文中已经多次使用,内部循环流中的所有元素,对每一个元素进行消费
forEachOrder 和 forEach 类似,但能保证消费顺序
count
返回流中项的个数
toArray
转换流为数组
anyMatch
短路操作,有一项匹配就返回 true
// 查询是否存在总价在 100 元以上的订单
boolean b = orders.stream()
.filter(order -> order.getTotalPrice() > 50)
.anyMatch(order -> order.getTotalPrice() > 100);
其他短路操作:
allMatch:全部匹配才返回 true
noneMatch:都不匹配才返回 true
findFirst:返回第一项的 Optional 包装
findAny:返回任意一项的 Optional 包装,串行流一般返回第一个
reduce
归纳,一边遍历,一边将处理结果保持起来,代入下一次循环
重载方法有三个,截图来自 IDEA 参数提示:

// 一个参数
// 求订单金额总价
Optional reduce = orders.stream()
.map(Order::getTotalPrice)
.reduce((p, n) -> {
return p + n;
});
// 两个参数
// 可指定一个初始值,初始值类型需要和 p、n 一致
Double reduce2 = orders.stream()
.map(Order::getTotalPrice)
.reduce(0.0, (p, n) -> {
return p + n;
});
三个参数的 reduce 方法:
可以接收一个目标结果类型的初始值,一个串行的处理函数,一个并行的合并函数
// 将所有订单的顾客名字进行拼接
// 第一个参数为目标结果类型,这里设置为空的 StringBuilder
// 第二个参数 BiFunction,参数为上一次的 StringBuilder 和流中的下一项,返回新的 StringBuilder
// 第三个参数 BinaryOperator,参数都是 StringBuilder,返回合并后的 StringBuilder
StringBuilder reduce = orders.stream()
.reduce(new StringBuilder(),
(sb, next) -> {
return sb.append(next.getCustomerName() + “,”);
},
(sb1, sb2) -> {
return sb1.append(sb2);
});
其他归纳方法:
max/min 求最大/最小值,接收一个比较器作为参数
对于 LongStream 等基础类型 Stream,则不需要传入比较器参数
collect
collect 是收集操作,对流进行终结操作,把流导出为我们需要的数据结构
collect 需要接收一个收集器 Collector 对象作为参数,JDK 内置的 Collector 的实现类 Collectors 包含了许多常用的导出方式
collect 常用 API:
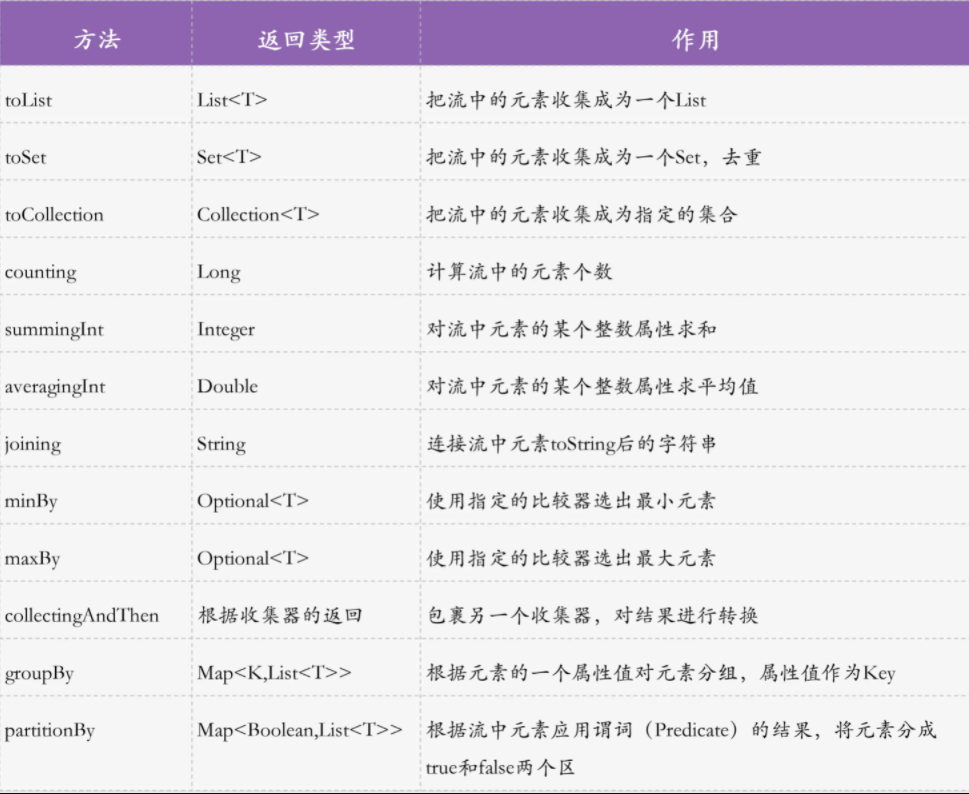
导出流为集合:
- toList 和 toUnmodifiableList
// 转为 List(ArrayList)
orders.stream().collect(Collectors.toList());
// 转为不可修改的 List
orders.collect(Collectors.toUnmodifiableList());
- toSet 和 toUnmodifiableSet
// 转为 Set
orders.stream().collect(Collectors.toSet());
// 转为不可修改的 Set
orders.stream().collect(Collectors.toUnmodifiableSet());
- toCollection 指定集合类型,如 LinkedList
orders.stream().collect(Collectors.toCollection(LinkedList::new));
导出流为 Map:
- toMap,第三个参数可以指定键名重复时选择键值的规则
// 使用 toMap 获取订单 ID + 下单用户名的 Map
orders.stream()
.collect(Collectors.toMap(Order::getId, Order::getCustomerName))
.entrySet().forEach(System.out::println);
//使用 toMap 获取下单用户名 + 最近一次下单时间的 Map
orders.stream()
.collect(Collectors.toMap(Order::getCustomerName, Order::getPlacedAt,
(x, y) -> x.isAfter(y) ? x : y))
.entrySet().forEach(System.out::println);
-
toUnmodifiableMap:返回一个不可修改的 Map
-
toConcurrentMap:返回一个线程安全的 Map
分组导出:
在 toMap 中遇到重复的键名,通过指定一个处理函数来选择一个键值保留
大多数情况下,我们需要根据键名分组得到 Map,Collectors.groupingBy 是更好的选择
重载方法有三个,截图来自 IDEA 参数提示:

一个参数,等同于第二个参数为 Collectors.toList,即键值为 List 类型
// 按照下单用户名分组,键值是该顾客对应的订单 List
Map<String, List> collect = orders.stream()
.collect(Collectors.groupingBy(Order::getCustomerName));
两个参数,第二个参数用于指定键值类型
// 按照下单用户名分组,键值是该顾客对应的订单数量
Map<String, Long> collect = orders.stream()
.collect(Collectors.groupingBy(Order::getCustomerName,
Collectors.counting()));
三个参数,第二个参数用于指定分组结果的 Map 类型,第三个参数用于指定键值类型
// 按照下单用户名分组,键值是该顾客对应的所有商品的总价
Map<String, Double> collect = orders.stream()
.collect(Collectors.groupingBy(Order::getCustomerName,
Collectors.summingDouble(Order::getTotalPrice)));
// 指定分组结果的 Map 为 TreeMap 类型
Map<String, Double> collect = orders.stream()
.collect(Collectors.groupingBy(Order::getCustomerName,
TreeMap::new,
Collectors.summingDouble(Order::getTotalPrice)));
分区导出:
分区使用 Collectors.partitioningBy,就是将数据按照 TRUE 或者 FALSE 进行分组
// 按照是否有下单记录进行分区
customers.stream()
.collect(Collectors.partitioningBy(customer -> orders
.stream()
.mapToLong(Order::getCustomerId)
.anyMatch(id -> id == customer.getId())
));
// 等价于
customers.stream()
.collect(Collectors.partitioningBy(customer -> orders
.stream()
.filter(order -> order.getCustomerId() == customer.getId())
.findAny()
.isPresent()
));
类中间操作:
Collectors 还提供了类似于中间操作的 API,方便在收集时使用,如 counting、summingDouble、maxBy 等
Collectors.maxBy
// 获取下单量最多的商品,三种方式
// 使用收集器 maxBy
Map.Entry<String, Integer> e1 = orders.stream()
.flatMap(order -> order.getOrderItemList().stream())
.collect(Collectors.groupingBy(OrderItem::getProductName,
Collectors.summingInt(OrderItem::getProductQuantity)))
.entrySet()
.stream()
.collect(Collectors.maxBy(Map.Entry.<String, Integer>comparingByValue()))
.get();
// 使用中间操作 max
Map.Entry<String, Integer> e2 = orders.stream()
.flatMap(order -> order.getOrderItemList().stream())
.collect(Collectors.groupingBy(OrderItem::getProductName,
Collectors.summingInt(OrderItem::getProductQuantity)))
.entrySet()
.stream()
.max(Map.Entry.<String, Integer>comparingByValue())
.get();
// 由大到小排序,再 findFirst
Map.Entry<String, Integer> e3 = orders.stream()
.flatMap(order -> order.getOrderItemList().stream())
相关文章:
Java 8 Stream API
通过 Stream.of 方法直接传入多个元素构成一个流 String[] arr {“a”, “b”, “c”}; Stream.of(arr).forEach(System.out::println); Stream.of(“a”, “b”, “c”).forEach(System.out::println); Stream.of(1, 2, “a”).map(item -> item.getClass().getName()…...

亚博microros小车-原生ubuntu支持系列:21 颜色追踪
背景知识 这个测试例子用到了很多opencv的函数,举个例子。 #cv2.findContours函数来找到二值图像中的轮廓。#参数:#参数1:输 入的二值图像。通常是经过阈值处理后的图像,例如在颜色过滤之后生成的掩码。#参数2(cv2.RETR_EXTERNA…...

GESP6级语法知识(六):(动态规划算法(六)多重背包)
多重背包(二维数组) #include <iostream> using namespace std; #define N 1005 int Asd[N][N]; //Asd[i][j]表示前 i 个物品,背包容量是 j 的情况下的最大价值。 int Value[N], Vol[N], S[N];int main() {int n, Volume;cin &g…...

MySQL 事务实现原理( 详解 )
MySQL 主要是通过: 锁、Redo Log、Undo Log、MVCC来实现事务 事务的隔离性利用锁机制实现 原子性、一致性和持久性由事务的 redo 日志和undo 日志来保证。 Redo Log(重做日志):记录事务对数据库的所有修改,在崩溃时恢复未提交的更改,保证事务…...

AI协助探索AI新构型自动化创新的技术实现
一、AI自进化架构的核心范式 1. 元代码生成与模块化重构 - 代码级自编程:基于神经架构搜索的强化学习框架,AI可通过生成元代码模板(框架的抽象层定义)自动组合功能模块。例如,使用注意力机制作为原子单元ÿ…...

九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)
九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位) 文章目录 九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)1. RDB 概述2. RDB 持久化执行流程3. RDB 的详细配置4. RDB 备份&恢…...

mac连接linux服务器
1、mac连接linux服务器 # ssh -p 22 root192.168.1.152、mac指定密码连接linux服务器 (1) 先安装sshpass,下载后解压执行 ./configure && make && makeinstall https://sourceforge.net/projects/sshpass/ (2) 连接linux # sshpass -p \/\\\[\!\\wen12\$ s…...

oracle: 表分区>>范围分区,列表分区,散列分区/哈希分区,间隔分区,参考分区,组合分区,子分区/复合分区/组合分区
分区表 是将一个逻辑上的大表按照特定的规则划分为多个物理上的子表,这些子表称为分区。 分区可以基于不同的维度,如时间、数值范围、字符串值等,将数据分散存储在不同的分区 中,以提高数据管理的效率和查询性能,同时…...

使用Pygame制作“走迷宫”游戏
1. 前言 迷宫游戏是最经典的 2D 游戏类型之一:在一个由墙壁和通道构成的地图里,玩家需要绕过障碍、寻找通路,最终抵达出口。它不但简单易实现,又兼具可玩性,还能在此基础上添加怪物、道具、机关等元素。本篇文章将展示…...

AJAX案例——图片上传个人信息操作
黑马程序员视频地址: AJAX-Day02-11.图片上传https://www.bilibili.com/video/BV1MN411y7pw?vd_source0a2d366696f87e241adc64419bf12cab&spm_id_from333.788.videopod.episodes&p26 图片上传 <!-- 文件选择元素 --><input type"file"…...

Day35-【13003】短文,什么是双端队列?栈和队列的互相模拟,以及解决队列模拟栈时出栈时间开销大的方法
文章目录 第三节进一步讨论栈和队列双端队列栈和队列的相互模拟使用栈来模拟队列类型定义入队出队判空,判满 使用队列来模拟栈类型定义初始化清空操作判空,判满栈长度输出入栈出栈避免出栈时间开销大的方法 第三节进一步讨论栈和队列 双端队列 假设你芷…...

力扣 55. 跳跃游戏
🔗 https://leetcode.cn/problems/jump-game 题目 给一个数组 nums,最开始在 index 0,每次可以跳跃的区间是 0-nums[i]判断是否可以跳到数组末尾 思路 题解是用贪心,实际上模拟也可以过遍历可以到达的下标,判断其可…...

深入剖析 HTML5 新特性:语义化标签和表单控件完全指南
系列文章目录 01-从零开始学 HTML:构建网页的基本框架与技巧 02-HTML常见文本标签解析:从基础到进阶的全面指南 03-HTML从入门到精通:链接与图像标签全解析 04-HTML 列表标签全解析:无序与有序列表的深度应用 05-HTML表格标签全面…...

本地快速部署DeepSeek-R1模型——2025新年贺岁
一晃年初六了,春节长假余额马上归零了。今天下午在我的电脑上成功部署了DeepSeek-R1模型,抽个时间和大家简单分享一下过程: 概述 DeepSeek模型 是一家由中国知名量化私募巨头幻方量化创立的人工智能公司,致力于开发高效、高性能…...

MVC 文件夹:架构之美与实际应用
MVC 文件夹:架构之美与实际应用 引言 MVC(Model-View-Controller)是一种设计模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种架构模式不仅提高了代码的可维护性和可扩展性,而且使得开发流程更加清晰。本文将深入探讨MVC文…...

Redis --- 秒杀优化方案(阻塞队列+基于Stream流的消息队列)
下面是我们的秒杀流程: 对于正常的秒杀处理,我们需要多次查询数据库,会给数据库造成相当大的压力,这个时候我们需要加入缓存,进而缓解数据库压力。 在上面的图示中,我们可以将一条流水线的任务拆成两条流水…...

如何确认设备文件 /dev/fb0 对应的帧缓冲设备是开发板上的LCD屏?如何查看LCD屏的属性信息?
要判断 /dev/fb0 是否对应的是 LCD 屏幕,可以通过以下几种方法: 方法 1:使用 fbset 命令查看帧缓冲设备的属性信息 Linux 的 帧缓冲设备(Framebuffer) 通常在 /dev/fbX 下,/dev/fb0 一般是主屏幕ÿ…...

C++多线程编程——基于策略模式、单例模式和简单工厂模式的可扩展智能析构线程
1. thread对象的析构问题 在 C 多线程标准库中,创建 thread 对象后,必须在对象析构前决定是 detach 还是 join。若在 thread 对象销毁时仍未做出决策,程序将会终止。 然而,在创建 thread 对象后、调用 join 前的代码中ÿ…...

AI与SEO关键词的完美结合如何提升网站流量与排名策略
内容概要 在当今数字营销环境中,内容的成功不仅依赖于高质量的创作,还包括高效的关键词策略。AI与SEO关键词的结合,正是这一趋势的重要体现。 AI技术在SEO中的重要性 在数字营销领域,AI技术的引入为SEO策略带来了前所未有的变革。…...

保姆级教程Docker部署Kafka官方镜像
目录 一、安装Docker及可视化工具 二、单节点部署 1、创建挂载目录 2、运行Kafka容器 3、Compose运行Kafka容器 4、查看Kafka运行状态 三、集群部署 在Kafka2.8版本之前,Kafka是强依赖于Zookeeper中间件的,这本身就很不合理,中间件依赖…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...